什么是TAO以及如何安装和使用TAO
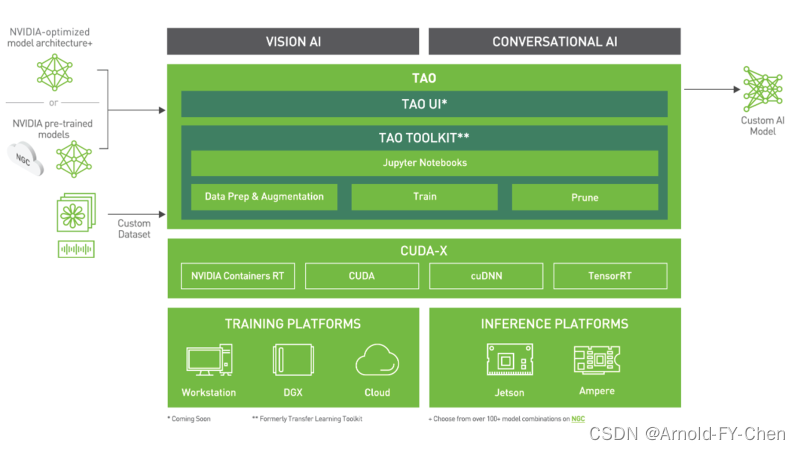
NVIDIA的TAO(Train, Adapt, Optimize)Toolkit以前叫TLT(Tranfer Learning Toolkit),即迁移学习工具,关于什么是迁移学习,网上资料大把,这里只说TAO,故不多说迁移学习。只要是干过模型的,看看NVIDIA官网上给出的这张关于TAO的架构图,也能大概明白了七八分:
近来琢磨熟悉TAO的使用并写PPT给组内培训,所以对TAO的相关文档仔细过了一遍,也在不连贯的文档说明指导下琢磨了从TAO的环境安装到训练数据及预训练模型的准备和模型训练再到模型的导出成etlt文件和转换成TensorRT engine文件的全过程,感觉TAO配套的说明文档有点混乱不连贯,有部分内容还有点陈旧了,所以按照自己走通了的路写了个PPT,记录了全部过程。
TAO目前有三个docker image,参见相关说明:
TAO Toolkit for CV | NVIDIA NGCDocker container with workflows implemented in TensorFlow as part of the Train Adapt Optimize (TAO) Toolkit.![]() https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/containers/tao-toolkit-tf
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/containers/tao-toolkit-tf
TAO Toolkit for Conv AI | NVIDIA NGCDocker container with workflows implemented in PyTorch as part of the Train Adapt Optimize (TAO) Toolkit.![]() https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/containers/tao-toolkit-pytTAO Toolkit for Language Model (Conv AI) | NVIDIA NGCDocker containing implementations to train a Language Model with TAO Toolkit
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/containers/tao-toolkit-pytTAO Toolkit for Language Model (Conv AI) | NVIDIA NGCDocker containing implementations to train a Language Model with TAO Toolkit![]() https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/containers/tao-toolkit-lmTAO的预训练模型放在几个docker image里,我们可以看上面三个docker image的说明文档仔细看里面的模型列表,例如:
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/containers/tao-toolkit-lmTAO的预训练模型放在几个docker image里,我们可以看上面三个docker image的说明文档仔细看里面的模型列表,例如:
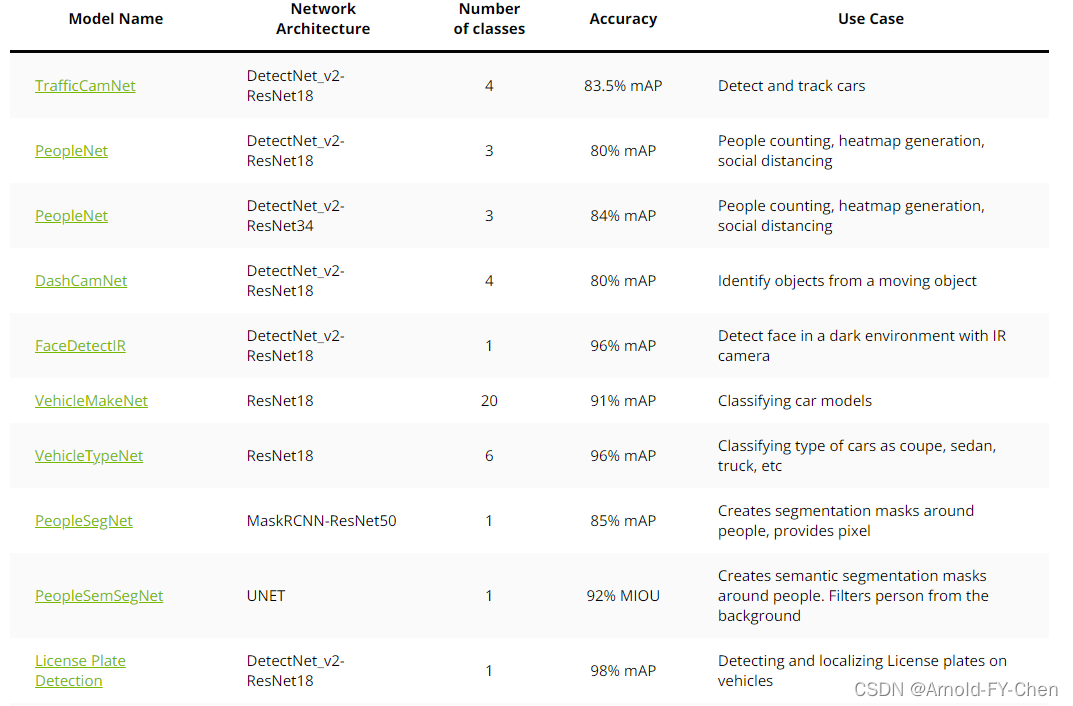
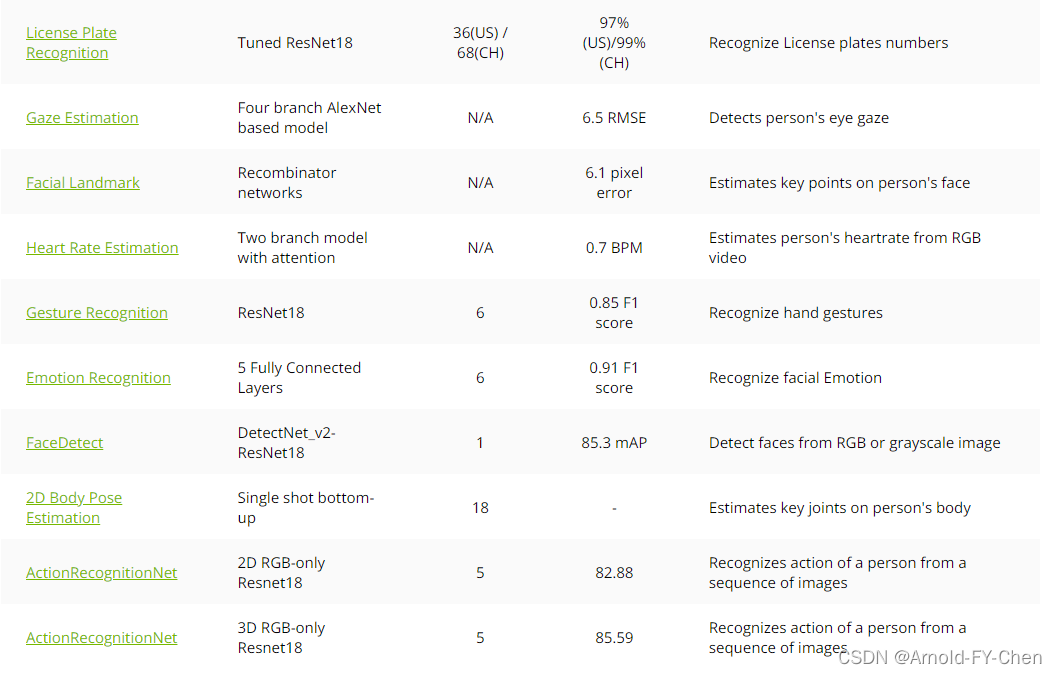
寻找自己需要的合适模型来在它的基础上做迁移学习。第一个docker image里收集的是CV相关的模型,安装的训练框架是tensorflow,第二个docker image里收集的是语音和文本相关的模型,安装的训练框架是pytorch,第三个里面是语言模型,这些docker image并不需要手工拉取并创建container,当在第一次执行tao train ... 之类的命令时会自动拉取对应的docker image到本地并创建容器(创建容器时对容器内的路径和host上的路径映射都是定义在~/.tao_mounts.json里,所以需要手工创建这个文件,后面会提到),容器应该是用完即删,训练数据和预训练模型以及训练的结果模型等文件都是通过路径映射机制保存到host上,知道了这些并且对docker比较熟悉,对后面的步骤就能很快明白为何要那样做。
为了偷懒省点能量,下面很多步骤说明我就直接抠NVIDIA官网文档里的内容或者我自己写的PPT的内容来直接粘贴。
1.安装TAO
硬件软件要求:


安装TAO之前需要做的:
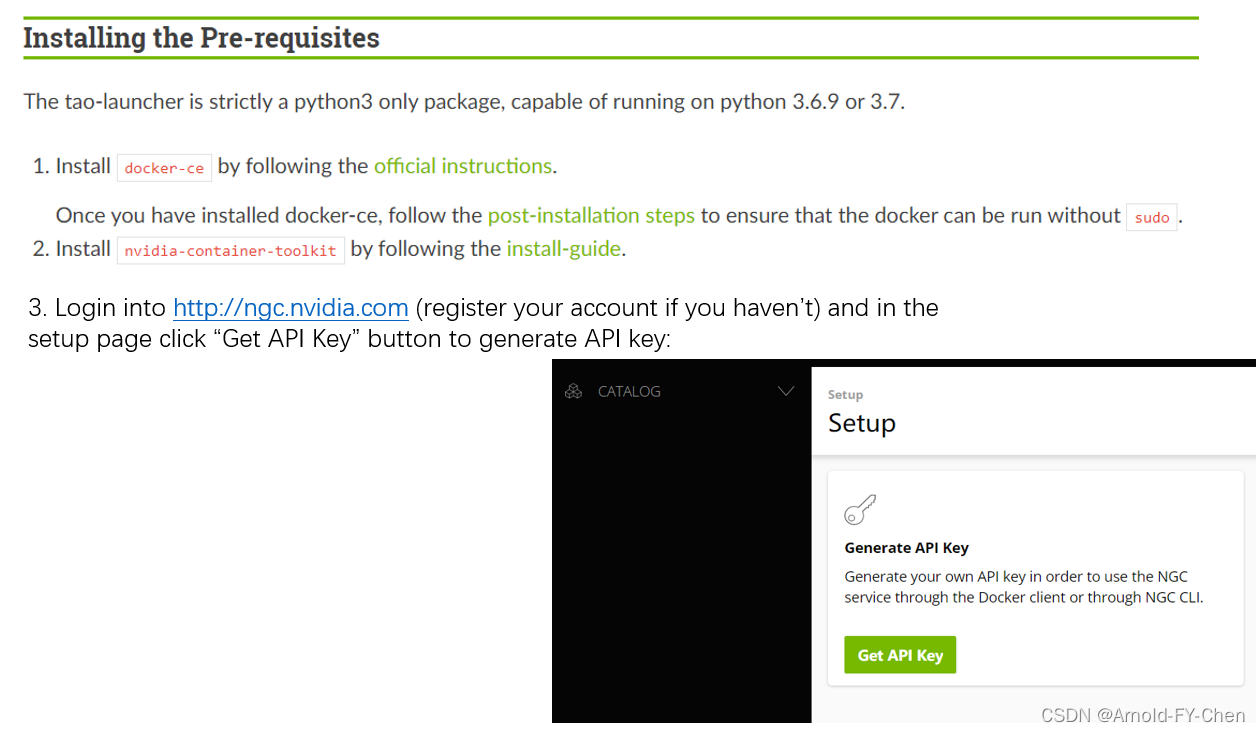
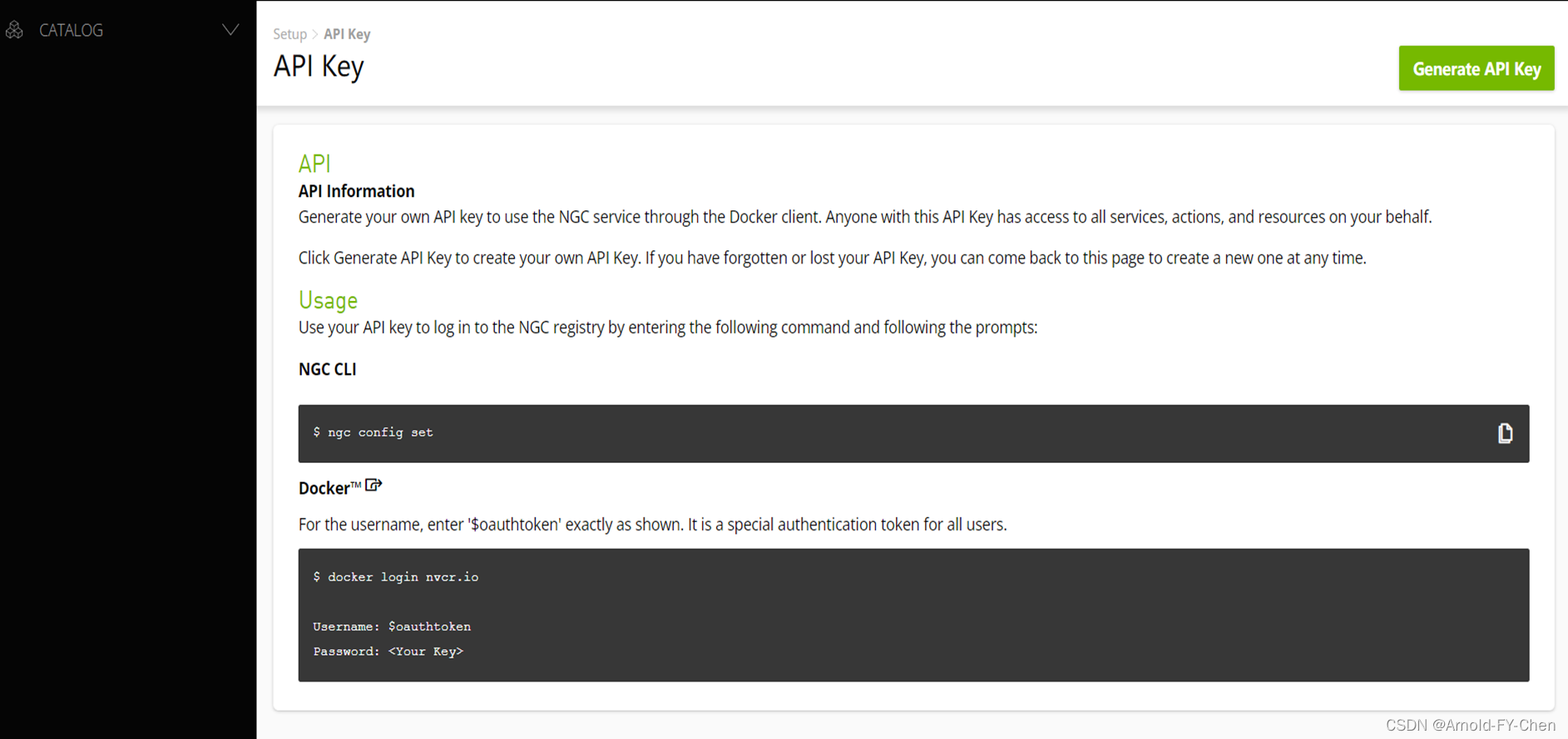
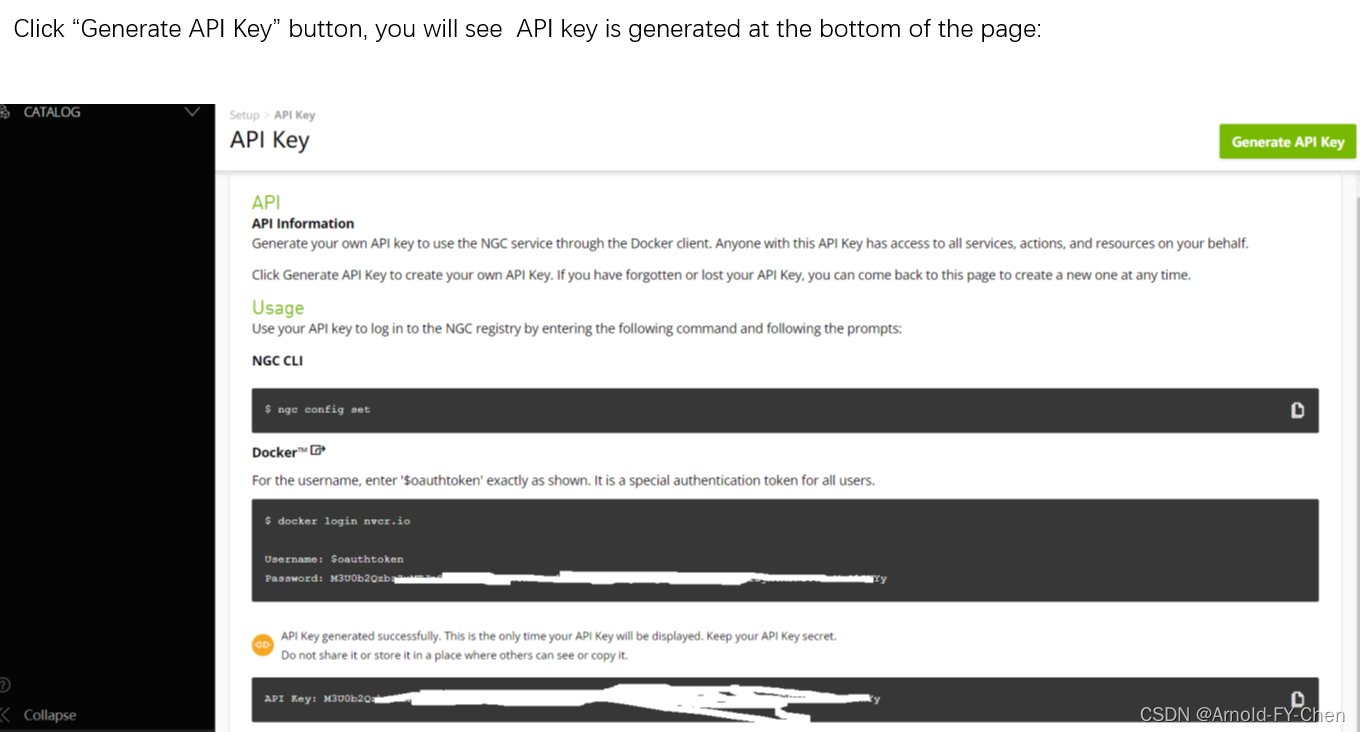
Login into nvcr.io docker:root@ubuntu-rtx3090:/data/workspace# docker login nvcr.ioUsername: $oauthtokenPassword: Once you input your API key and press ENTER, you will see the following messages:WARNING! Your password will be stored unencrypted in /root/.docker/config.json.Configure a credential helper to remove this warning. Seehttps://docs.docker.com/engine/reference/commandline/login/#credentials-storeLogin Succeeded 我们该安装哪个版本的TAO取决于我们使用的DeepStream的版本,假如由TAO里导出的模型需要在Deepstream中使用的话: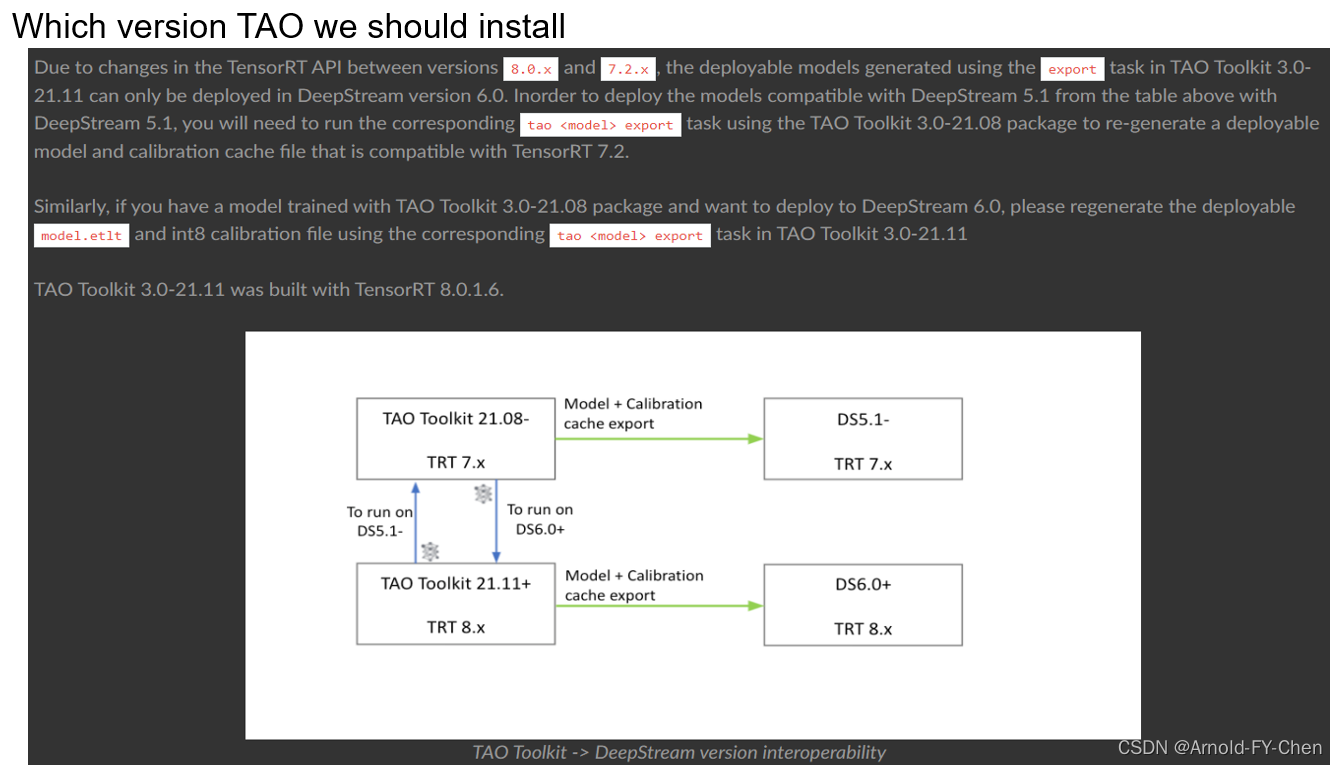

We create ~/.tao_mounts.json by the following steps on host (not in tao-* container!):Set four environmental variables with your own paths and key, e.g: export HOST_DATA_DIR=/data/workspace/tao-experiments/data export HOST_SPECS_DIR=/data/workspace/tao-experiments/specs export HOST_RESULTS_DIR=/data/workspace/tao-experiments/results export KEY=nvidia_tao For permanent use, add the above lines into ~/.bashrc and execute ‘source ~/.bashrc’2) Create the directories to make sure the paths exist: mkdir -p $HOST_DATA_DIR mkdir -p $HOST_SPECS_DIR mkdir -p $HOST_RESULTS_DIR 

安装一定步骤从官网上下载训练用的脚本和预训练模型:
Example Jupyter notebooks for all the tasks that are supported in TAO Toolkit are available in NGC resources. TAO Toolkit provides sample workflows for Computer Vision and Conversational AI.As of now, we only care CV models, to run the available CV examples, download this sample resource by using the following commands:wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/cv_samples/versions/v1.3.0/zip -O cv_samples_v1.3.0.zipunzip -u cv_samples_v1.3.0.zip -d ./cv_samples_v1.3.0 && rm -rf cv_samples_v1.3.0.zip && cd ./cv_samples_v1.3.0You will see multi directories, under each directory, there is a *. ipynb file for training model in notebook. 
# if you want to train actionrecognitionnet, copy the specs scripts for it to $HOST_SPECS_DIR:cp -r action_recognition_net/specs/* $HOST_SPECS_DIRList the files under $HOST_SPECS_DIR, you will see these file : 
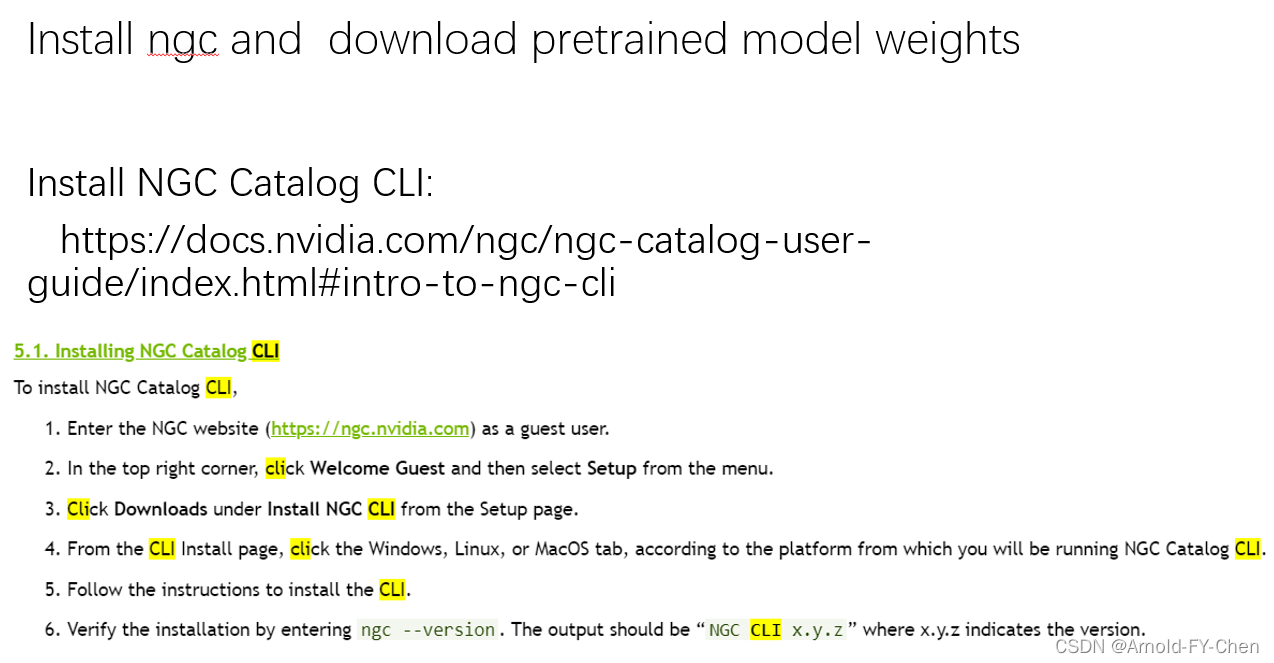
The actual steps are :#download and configure ngc cliwget -O ngccli_linux.zip https://ngc.nvidia.com/downloads/ngccli_linux.zip && unzip -o ngccli_linux.zip && chmod u+x ngc#check if the file downloaded is OK or not:md5sum -c ngc.md5echo "export PATH=\"\$PATH:$(pwd)\"" >> ~/.bashsrc && source ~/.bashsrc## browse the the model list for Transfer Learning:#ngc registry model list nvidia/tao/*# download model by command:ngc registry model download-version -dest #e.g. download model to $HOST_RESULTS_DIR/pretrained/:ngc registry model download-version nvidia/tao/actionrecognitionnet:trainable_v1.0 --dest $HOST_RESULTS_DIR/pretrained/Now, preparation is done, we can run commands in terminal to do model training/testing or inference, or launch jupyter notebook under the directory cv_samples_v1.3.0 and run the commands in the .ipynb file.Here I only present how to use jupyter notebook: #run jupyterjupyter notebook --ip 0.0.0.0 --port 8888 --allow-root To access the notebook, open this file in a browser: file:///root/.local/share/jupyter/runtime/nbserver-8943-open.html Or copy and paste one of these URLs: http://ubuntu-rtx3090:8888/?token=051c9f3f9bdffa585b75b22509b11714cd7c1f7670b4ac40 or http://127.0.0.1:8888/?token=051c9f3f9bdffa585b75b22509b11714cd7c1f7670b4ac40copy the URL and open the page in browser, you will see: 
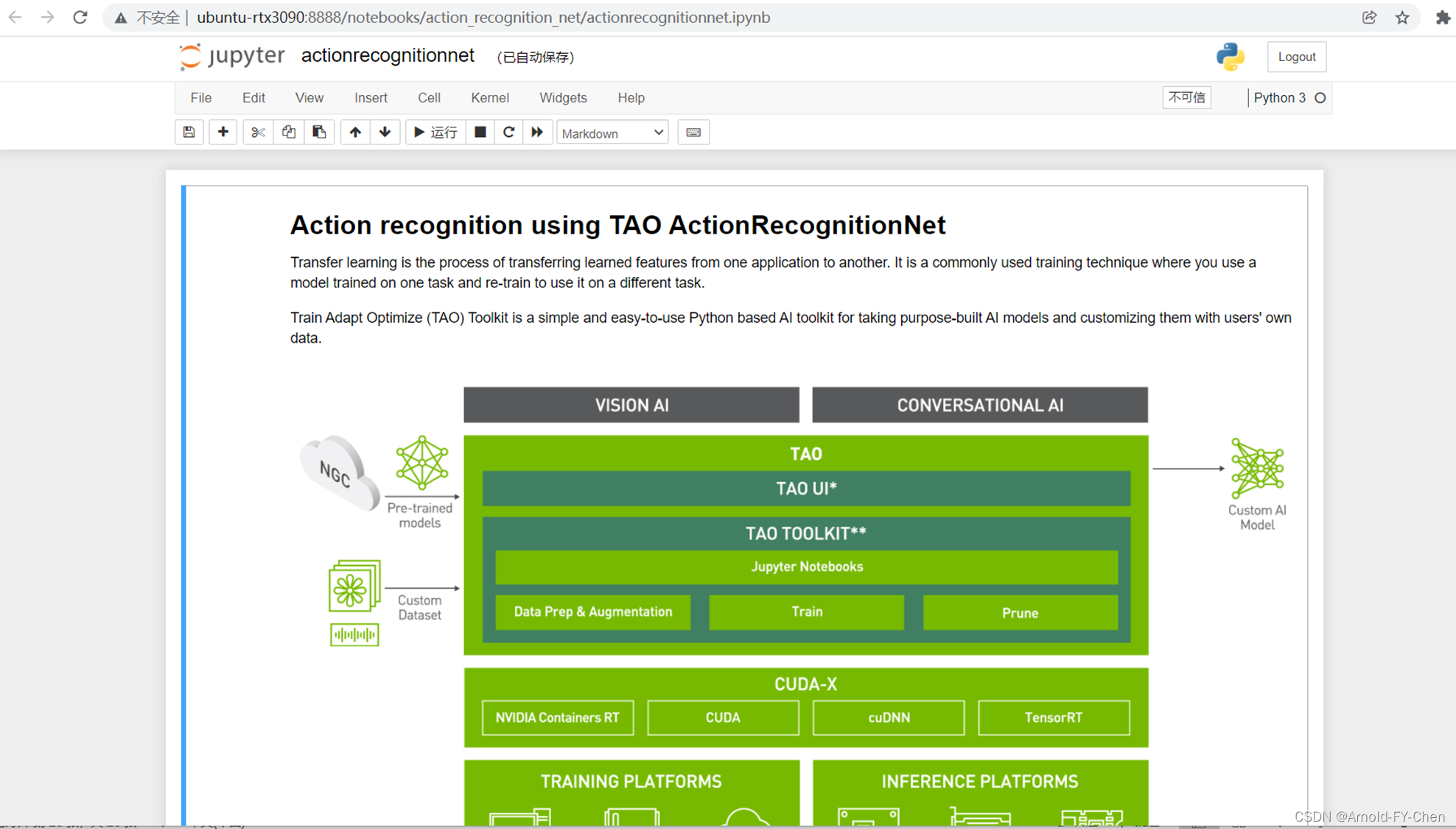
2.训练数据准备
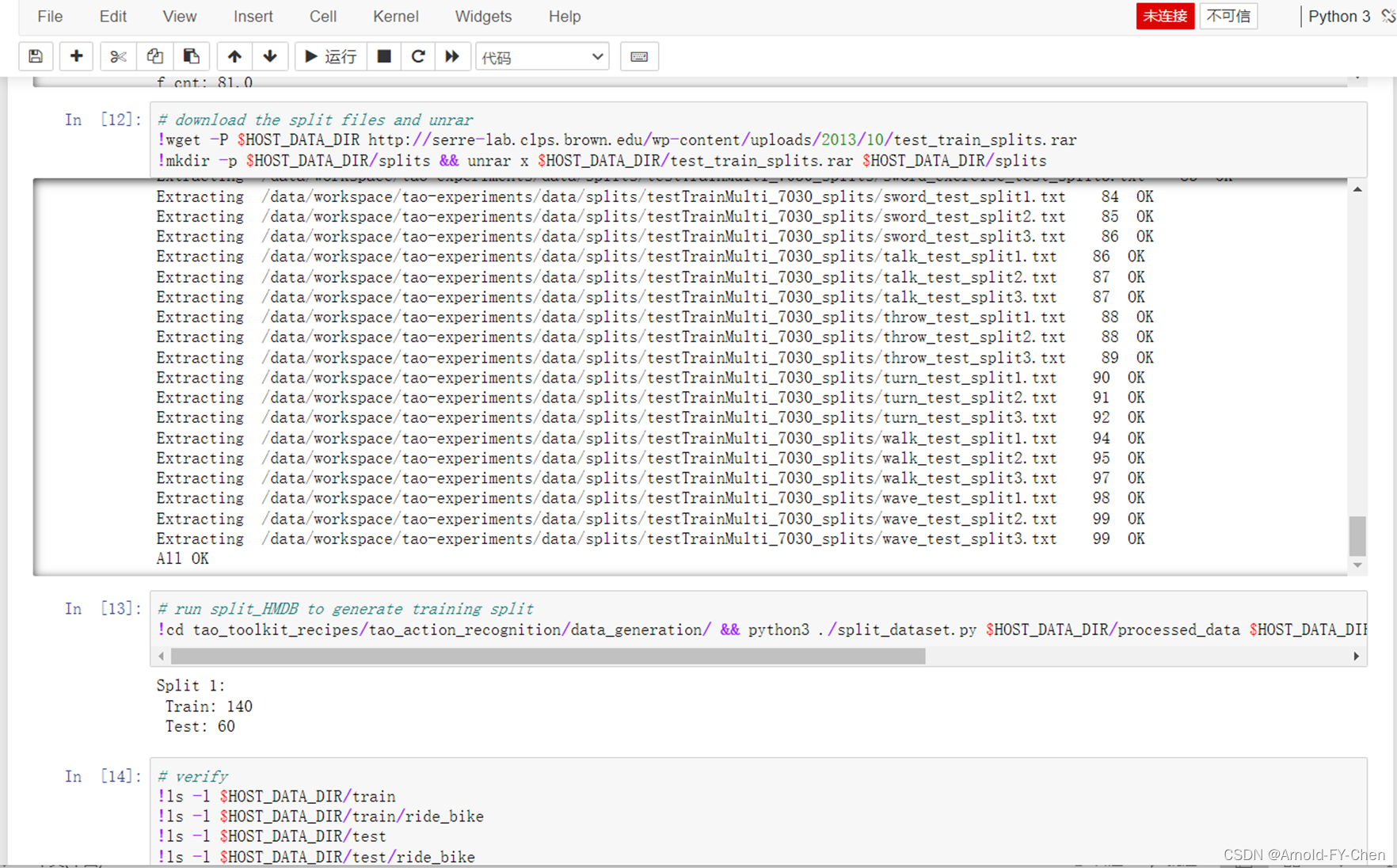
以action recognition使用的hmdb51 dataset为例: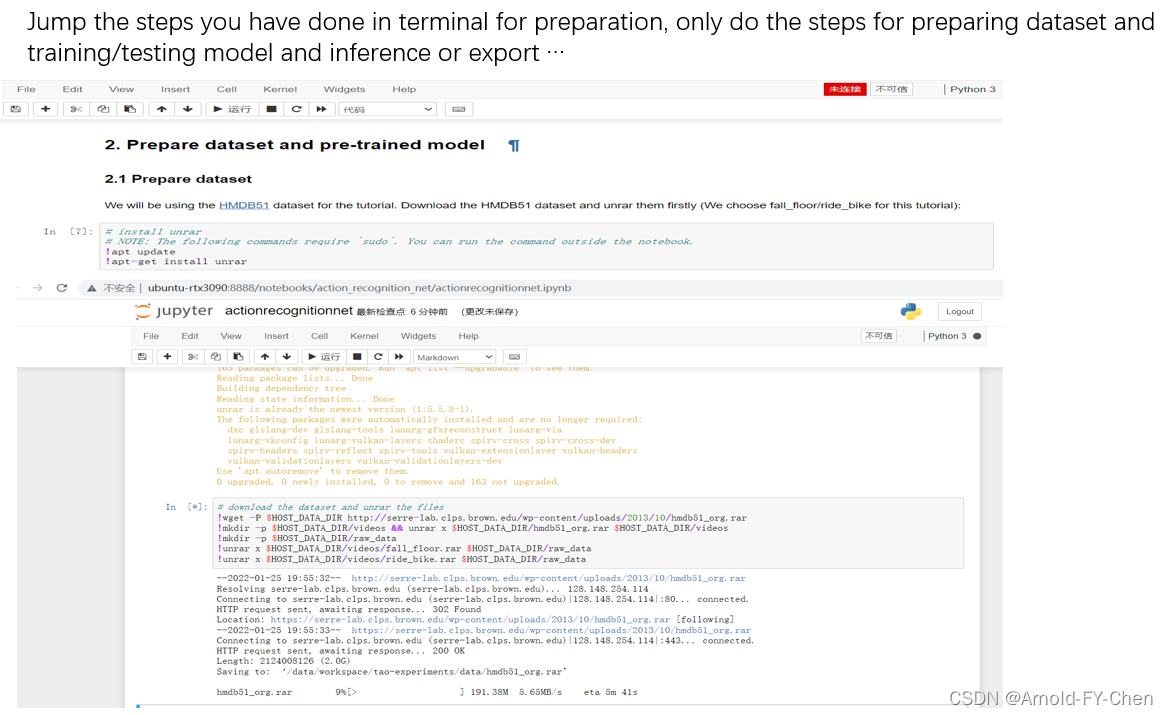
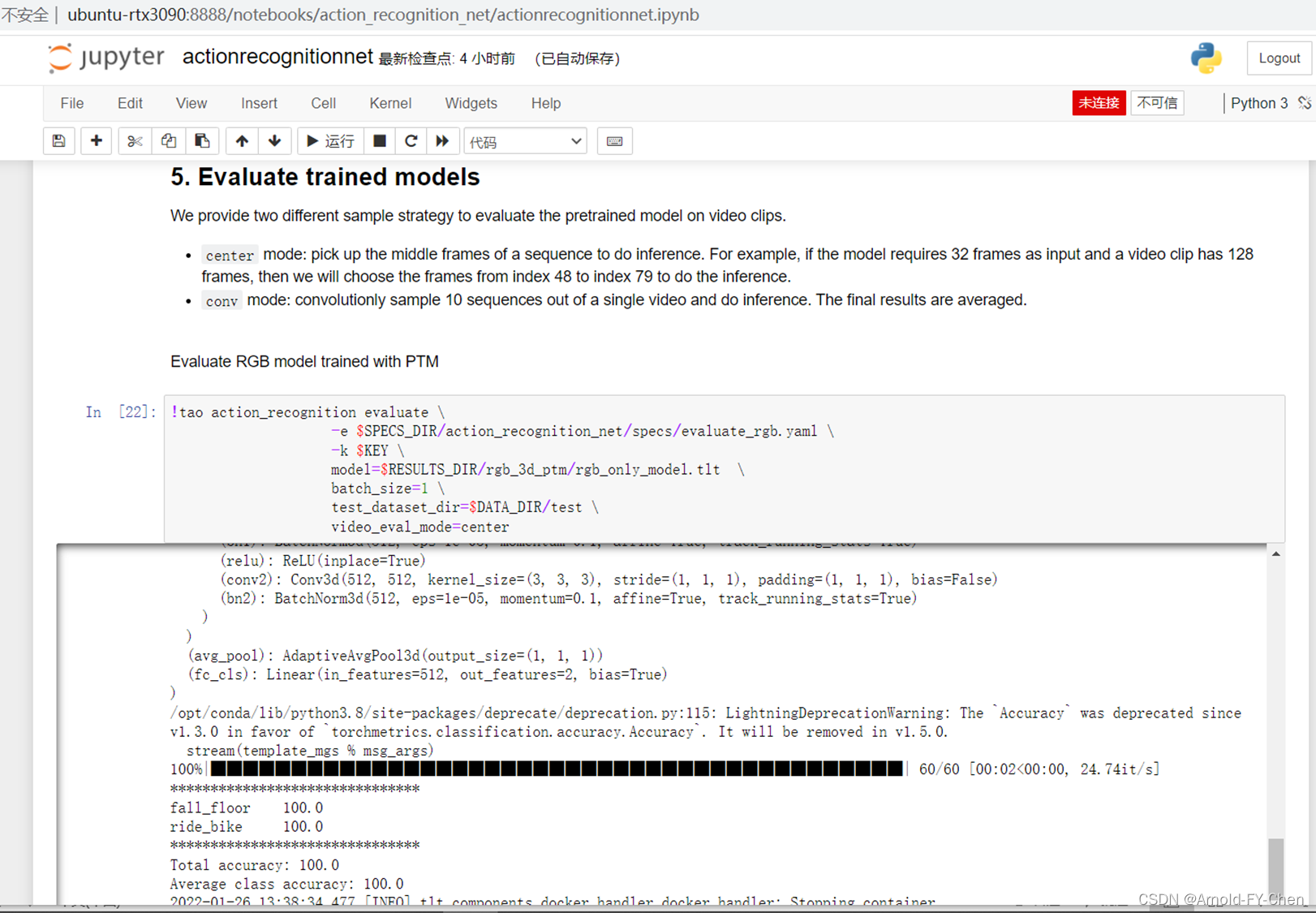
3.使用TAO训练和测试模型以及模型推理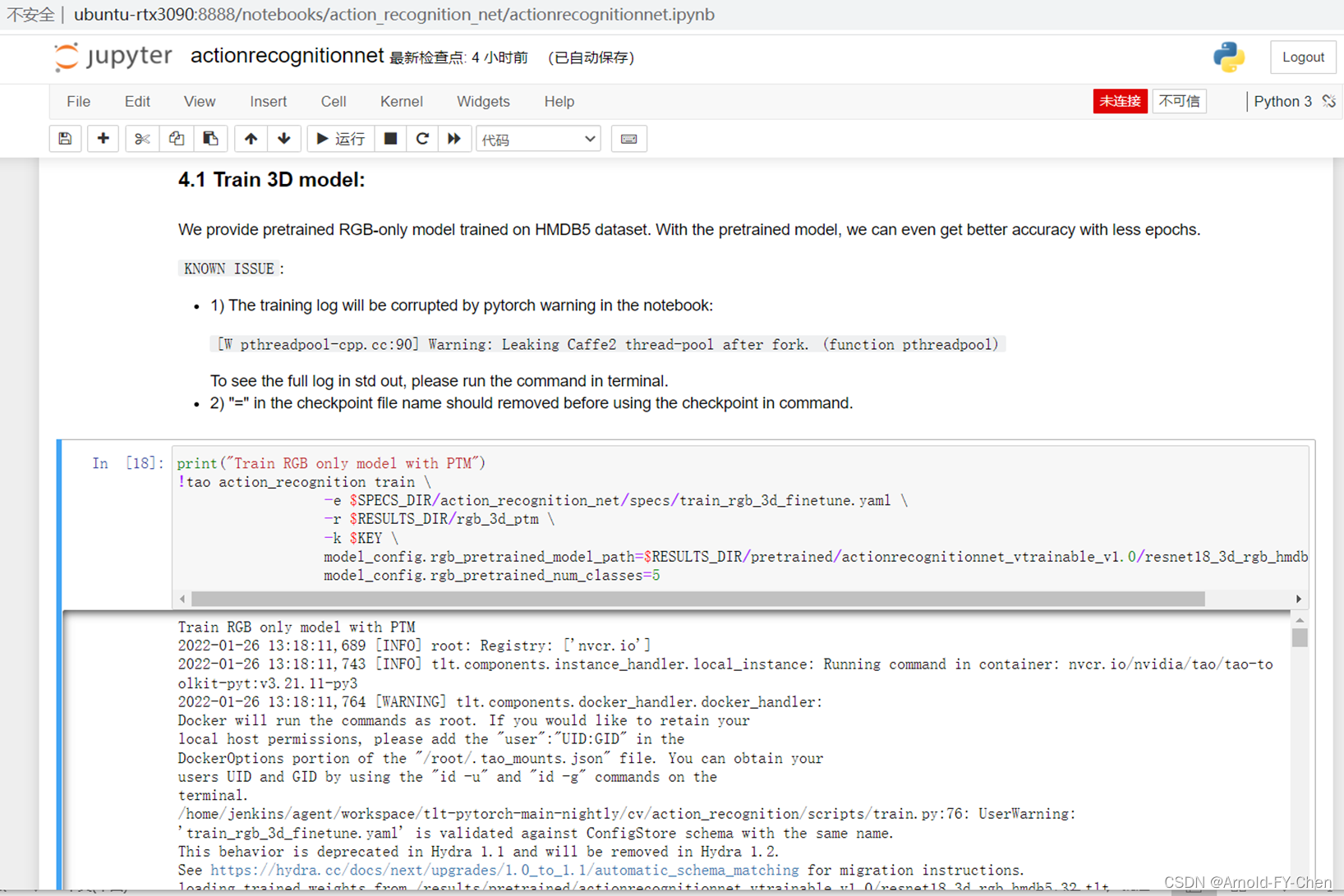
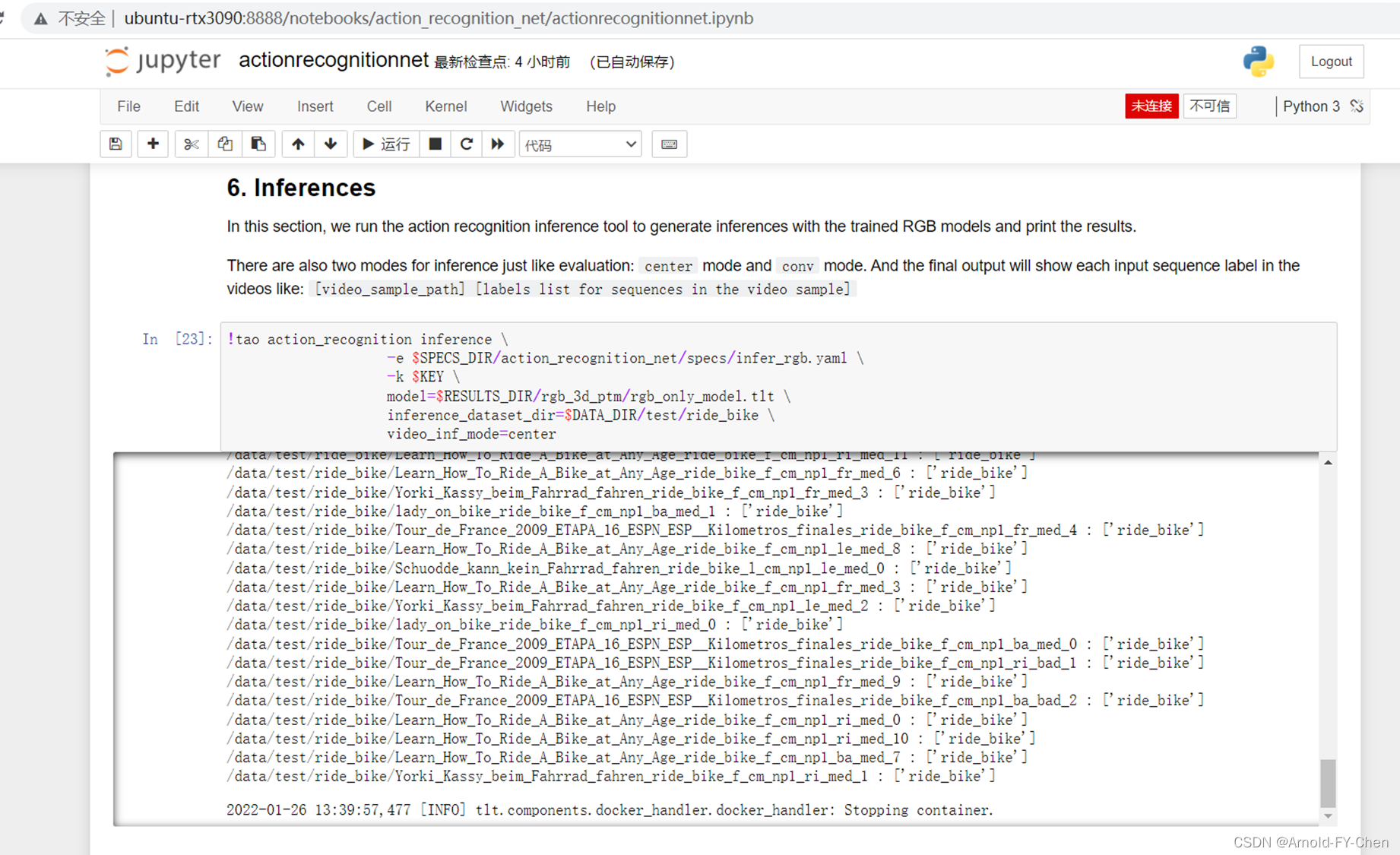
4.导出TAO模型以及模型的集成与转换
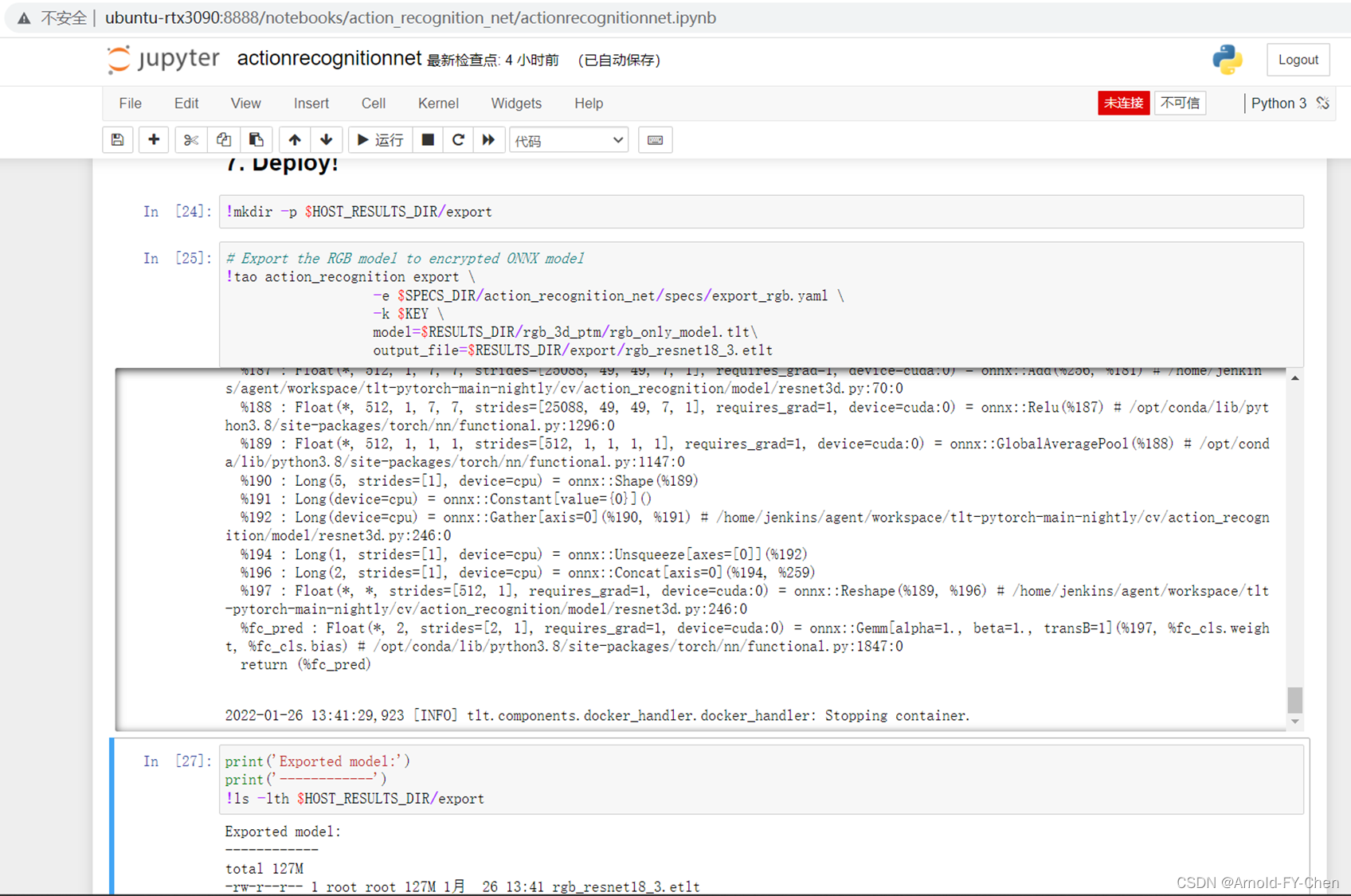

直接将TAO导出的etlt文件集成进DeepStream:

安装TAO Converter并使用TAO Converter将模型的etlt文件转换成TensorRT engine文件然后给Deepstream使用:
安装Tao Converter参见: https://docs.nvidia.com/tao/tao-toolkit/text/tensorrt.html#id2
|
TAO Converter Support Matrix for x86 |
||
|
CUDA/CUDNN |
TensorRT |
Platform |
|
10.2/8.0 |
7.2 |
cuda102-cudnn80-trt72 |
|
11.0/8.0 |
7.2 |
cuda110-cudnn80-trt72 |
|
11.1/8.0 |
7.2 |
cuda111-cudnn80-trt72 |
|
11.2/8.0 |
7.2 |
cuda112-cudnn80-trt72 |
|
10.2/8.0 |
7.1 |
cuda102-cudnn80-trt71 |
|
11.0/8.0 |
7.1 |
cuda110-cudnn80-trt71 |
|
11.3/8.1 |
8.0 |
cuda113-cudnn80-trt72 |
|
TAO Converter Support Matrix for Jetson |
||
|
Platform |
JetPack Version |
Availability |
|
Jetson |
4.4 |
jp44 |
|
Jetson |
4.5 |
jp45 |
|
Jetson |
4.6 |
jp46 |
|
Jetson + dGPU |
4.5 |
jp45 + dgpu |
我们需要在Jetson板子上部署模型的话,就需要安装Jetson版的TAO Converter:
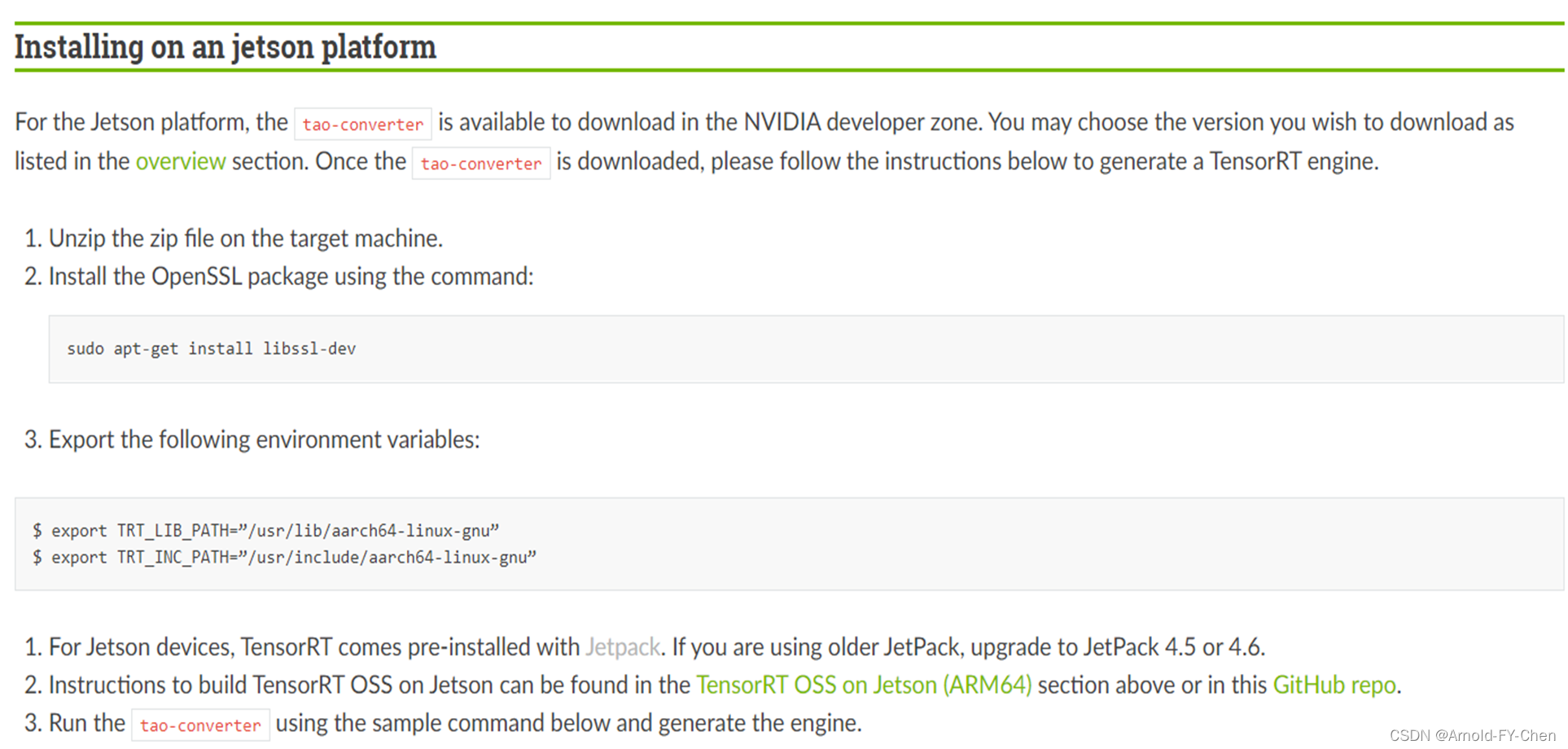
然后使用Tao Converter将etlt文件转换成TensorRT engine文件:


将actionrecognitionnet模型的etlt文件转换成engine的过程中出了错,等解决这个问题后再补充完善这最后一步,初步判断是低一点版本的TAO converter在使用-p 参数时不支持5维,待节后使用最新版的Jetpack4.6(使用的TensorRT8)里安装最新的TAO后验证这个猜测的正确性。
这个问题我调查后已经明确了,只有Jetpack4.6版的tao-converter的-p才支持5维,JP4.5或以下版本的tao-converter都不支持,这个问题很好fix,预计NVIDIA会在后续新版中推出Jetson上支持JP4.4和4.5的fixed版本。

