Python100天精通指南 之 re正则表达式【Million words】
re模块
- 每篇前言:
- 0.正则表达式所面向的问题
- 1.正则表达式RE
-
- (1)基础:
-
- 1.代码演示:
- 3.常用匹配规则(元字符):
-
- (1)什么是元字符?
- (2)常用元字符有哪些 ?
- 4.正则表达式的转义:
- 5.贪婪模式和非贪婪模式:
- (2)函数:
-
- (1)re.findall(pattern,string,flags=0)
- (2)re.match(pattern,string,flags=0)
-
- 第一部分:
- 第二部分:
- (3)re.search(pattern,string,flags=0)
- (4)re.sub(pattern,replace,string,max,flags=0)
- (5)re.compile(pattern, flags=0):
- (3)实战—猫眼电影TOP100电影信息爬取:
每篇前言:
🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者
- 🔥🔥本文已收录于Python全栈系列专栏:《Python全栈基础教程》以及爬虫专栏:《爬虫从入门到精通系列教程》
- 📝📝广大非前端程序猿,为的是大家快速入门并掌握前端基础知识【HTML,JavaScript,CSS】,同时穿插有前端小设计习题,巩固学习。
- 🎉🎉订阅专栏后可私聊进一千多人Python全栈交流群(手把手教学,问题解答); 进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
👇
👉🚔直接跳到末尾🚔👈 ——>领取专属粉丝福利💖
☝️
开源中国提供的正则表达式测试工具点我!
0.正则表达式所面向的问题
-
判断一个字符串是否匹配给定的格式;
如判断用户注册帐号是否满足格式
【这点在web服务器中使用尤为多哦~我们甚至可以在任何地方使用正则表达式自定义校验器!具体可以看看这个专栏:《Django框架从入门到实战》,Free的哦!!!】 -
从一个字符串中按指定格式提取信息;
如判断用户提交的邮箱的格式是否正确。
我们知道邮箱格式是【一个或多个字母或数字@一个或多个字母或数字.com】
对应正则表达式就是【r‘^[a-zA-Z0-9]+@[a-zA-Z0-9]+\.com$'】
看不懂也没关系哦!等你认认真真把本文琢磨透你就会发现这狠简单,甚至你会感觉我这种方法有点LOW,那当然更好了!!! -
抓取页面中的链接。
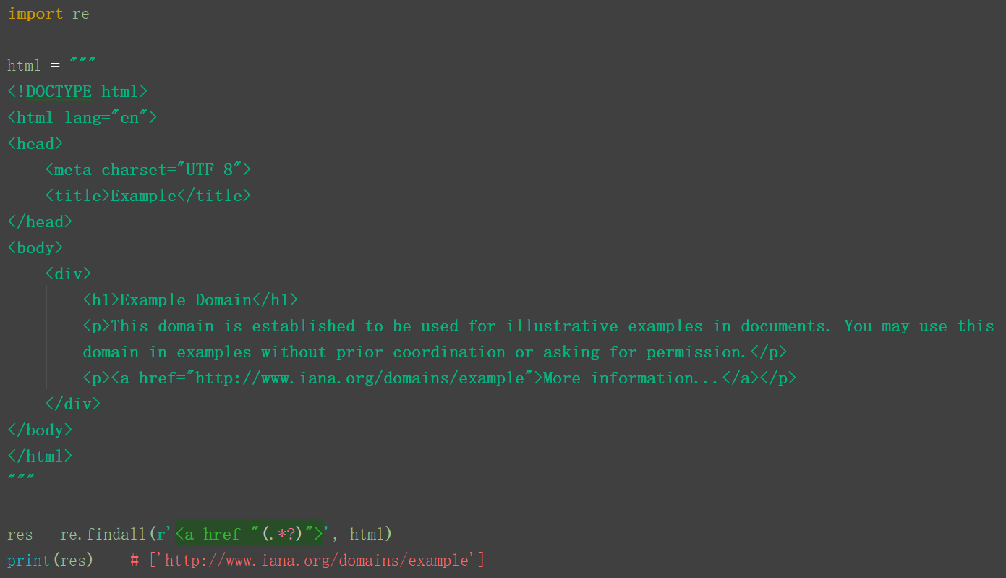
1.正则表达式RE
- 为什么使用?
因为很多重要信息隐藏在复杂的文本中,re可以找到哦! - 是什么?
从文本中定位需求内容的技术/规则。 - 怎么玩?
见下:
(1)基础:
1.代码演示:
正则表达式并不是python所特有的,它也可以用在其它编程语言中。但是Python的re库提供了整个正则表达式的实现,利用这个库,可以在Python中使用正则表达式。
所以开头我就先来点实战小例子带大家简单操作一下(希望大家不要只是看,切勿眼高手低,安安稳稳的跟着我这敲一遍哦~
):
import restr="网络爬虫大hEllo声告1231诉的433根深345蒂固7789网allen.时光飞逝股嘛份的嘛\n广泛嘛地吧自动安排"##第一部分:字符#普通字符#1.匹配规则:每个普通字符匹配其对应的字符print(re.findall("自动",str)) #输出为:['自动']# 拓展:匹配字符串中的.print(re.findall("\.",str)) #输出为:['.']#或关系 元字符:|#2.匹配规则:匹配|两侧任意的正则表达式即可print(re.findall("网|嘛",str)) #输出为:['网', '网', '嘛', '嘛']#元字符 .#3.匹配规则:匹配除换行外的任意一个字符print(re.findall("嘛.",str)) #输出为:['嘛份', '嘛地']print(re.findall("嘛.",str,re.S)) #输出为:['嘛份', '嘛\n', '嘛地']# 注意:正则表达式中, re.S的作用:# “.”的作用是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。这里的“行”是以“\n”进行区分的。# 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。# 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。print("第二部分:字符集","*"*50)#第二部分:字符集#元字符: [字符集]#4.匹配规则:匹配字符集中的任意一个字符[0-9],[a-z],[A-Z]print(re.findall("[大的时光]",str)) #输出为:['大', '的', '时', '光', '的']print(re.findall("[0123456789]",str))#输出为:['1', '2', '3', '1', '4', '3', '3', '3', '4', '5', '7', '7', '8', '9']#拓展:{}可以选择数量:{4}表示选择四个在一起的;{m,n}表示匹配m次到n次的。print(re.findall("[0123456789]{2}",str)) #输出为:['12', '31', '43', '34', '77', '89']print(re.findall("[a-zA-Z]{5}",str)) #输出为:['hEllo', 'allen']print("第三部分:常用","*"*50)##第三部分:常用#元字符:^#匹配规则:匹配目标字符串的开头位置print(re.findall("^hEllo","hEllodfdff")) #不管hEllo后面是什么样的,只要开头符合就可匹配到#元字符: $s#匹配规则:匹配目标字符串的结尾位置print(re.findall("hEllo$","sdfsdfsdfdfhEllo")) #不管hEllo前面是什么,只要结尾符合就可匹配到#匹配字符重复#元字符 *#匹配规则:匹配前面的字符出现0次或多次print(re.findall("wo*","wooooooooo#$#w>>")) #输出为:['wooooooooo', 'w']#元字符 +#匹配规则:匹配前面的字符出现1次或多次print(re.findall("wo+","wooooooooo#$#w>>")) #输出为:['wooooooooo']#元字符 ?#匹配规则:匹配前面的字符出现0次或1次print(re.findall("wo?","wooooooooo#$#w>")) #输出为:['wo', 'w']#元字符 {n}#匹配规则:匹配前面的字符出现n次print(re.findall('1[0-9]{10}',"Jame:15659264582bir200001110052"))#输出为:['15659264582']#元字符 {m,n}#匹配规则:匹配前面的字符出现m-n次print(re.findall('[0-9]{5,10}',"Broon:095594 660956780"))#匹配任意(非)数字字符#元字符: \d \D#匹配规则:\d匹配任意数字字符 \D匹配任意非数字字符print(re.findall("\d{2,4}","Mysql:3306,http:88"))#匹配任意(非)普通字符#元字符 \w \W#匹配规则:\w匹配普通字符 \W匹配非普通字符#说明:普通字符指数字,字母,下划线,汉子print(re.findall("\w+","路灯serve=? #8888"))#匹配任意(非)空字符#元字符: \s \S#匹配规则:\s匹配空格符 \S匹配非空字符#说明:空字符指 空格 \r \n \t \v \f字符print(re.findall("\w\S+\w+","hello \r \n \t\f word"))#匹配开头结尾位置#元字符:\A \Z#匹配规则:\A表示开头位置,或者^ \Z表示结尾位置,或者$print(re.findall("^h.....","hello path"))print(re.findall("\Ah.....","hello path"))print(re.findall(".h\Z","sddfh"))print(re.findall(".h$","sddfh"))#匹配(非)单词的边界位置#元字符:\b \B#规则:\b表示单词边界 \B表示非单词边界#说明:单词边界指数字字母(汉子)下划线与其他字符的交界位置print(re.findall(r'\ba',"The a is asb"))

3.常用匹配规则(元字符):
(1)什么是元字符?
- 本身具有特殊含义的字符
(2)常用元字符有哪些 ?
- 如下:
| 规则 | 描述 |
|---|---|
| \w | 匹配字母、数字及下划线 |
| \W | 匹配不是字母、数字及下划线 |
| \s | 匹配任意空白字符,等价于[\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于[0-9] |
| \D | 匹配任意非数字的字符 |
| \A | 匹配字符串开头 |
| \Z | 匹配字符串结尾,如果存在换行,只匹配到换行前得结束字符串 |
| \z | 匹配字符串结尾,如果存在换行,同时还会匹配换行符 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配一行字符串的开头 |
| $ | 匹配一行字符串的结尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 |
| […] | 用来表示一组字符,单独列出,比如[amk]匹配a,m或k |
| [^…] | 不在[]的字符,比如[^abc]匹配除了a,b,c的字符 |
| * | 匹配0个或多个表达式 |
| + | 匹配1个或多个表达式 |
| ? | 匹配0个或一个前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面的表达式 |
| {n:m} | 匹配n到m次由前面正则表达式定义的片段,贪婪方式 |
| a | b |
| () | 匹配括号内的表达式,也表示一个组 |
4.正则表达式的转义:

5.贪婪模式和非贪婪模式:
- 定义:
贪婪模式:默认情况下,匹配重复的元字符总是尽可能多的向后匹配内容,比如:*+。
非贪婪模式(懒惰模式):让匹配重复的元字符尽可能少的向后匹配内容。 - 贪婪模式转换为非贪婪模式
在匹配重复元字符后加"?"即可

举例讲解二者区别:
使用通用匹配.*时,有时候匹配到的可能并不是我们想要的结果!如下:
import recontent = 'Hello 1234567 World_This is a Regex Demo'result = re.match('^Hello.*(\d+).*World', content)print(result)print(result.group(1))我们依然想获取中间的数字,所以中间依然写的是(\d+)。数字两侧内容杂乱,所以直接使用.*。最后,组成^Hello.*(\d+).*World,看样子都OK,下面看运行结果:
我们只得到了数字7,分析: 此处就涉及到了一个贪婪匹配和非贪婪匹配的问题!在贪婪模式下,.*会匹配尽可能多的字符。正则表达式中.*后面是\d+,也就是至少一个数字,但并没有指定具体多少个数字,因此,.*就尽可能匹配多的字符,这里就把123456都匹配了,给\d+留下一个可满足条件的数字7,最后内容就只剩下数字7了! 但这很明显会给我们带来很大的不便,有时候,匹配结果会莫名其妙的少了一部分的内容。其实,只要使用非贪婪模式就可以解决这个问题。非贪婪匹配的写法是.*?,多了一个?。
import recontent = 'Hello 1234567 World_This is a Regex Demo'result = re.match('^Hello.*?(\d+).*World', content)print(result)print(result.group(1))
此时就可以成功获取1234567了。分析:贪婪匹配是尽可能匹配多的字符,非贪婪匹配就是尽可能匹配少的字符。当.*?匹配到Hello后面的空白字符时,再后面就是数字了,而\d+恰好可以匹配,那么这里.*?就不再进行匹配,交给\d+去匹配后面的数字了。所以这样,.*?就匹配了尽可能少的字符,\d+的结果就是1234567了!所以:在做匹配的时候,字符串中间尽量使用非贪婪匹配,以免出现匹配结果缺失的情况!!!但是需要注意,如果匹配的结果在字符串结尾,.*?就有可能匹配不到任何内容了,因为它会匹配尽可能少的字符。例如:import recontent = 'Hello 1234567 World_This is a Regex Demo'result = re.match('^Hello.*?Regex\s(.*?)', content)result2 = re.match('^Hello.*?Regex\s(.*)', content)print(result.group(1))print(result2.group(1))
(2)函数:
小讲解:修饰符!
正则表达式还包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。
import recontent = """Hello 1234567 World_This is a Regex Demo"""result = re.match('^Hello.*?(\d+).*?Demo$', content)print(result.group(1))- 我们在字符串中加入换行符,正则表达式也OK,用来匹配字符串中的数字。会发现报错!

- 也就是正则表达式没有匹配到这个字符串,返回结果是None,而我们又调用了方法group(),所以导致AttributeError。
- 分析:为何加入一个换行符就匹配不到了呢?这是因为.匹配的是除了换行符之外的任意字符,当遇到换行符的时候,它就不行了,这里只需要加入一个修饰符re.S即可修正这个错误!
import recontent = """Hello 1234567 World_This is a Regex Demo"""result = re.match('^Hello.*?(\d+).*?Demo$', content, re.S)print(result.group(1))
- 此修饰符的作用是使.匹配包括换行符在内的所有字符!
一些常见的修饰符见下表:
| 标志 | 含义 |
|---|---|
| re.S(DOTALL) | 使.匹配包括换行在内的所有字符 |
| re.I(IGNORECASE) | 使匹配对大小写不敏感 |
| re.L(LOCALE) | 做本地化识别(locale-aware)匹配,法语等 |
| re.M(MULTILINE) | 多行匹配,影响^和$ |
| re.X(VERBOSE) | 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解 |
| re.U | 根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B |
(1)re.findall(pattern,string,flags=0)
- 功能:根据正则表达式匹配所有目标字符串内容,并返回一个列表,如果没有找到匹配的,则返回空列表
- 参数:pattern正则表达式
string目标字符串
flags功能标志位,扩展正则表达式的匹配 - 返回值:匹配到的内容列表,如果正则表达式有子组织,只能获取到子组对应的内容。
import reres_style = "'Date': 'Thu, 16 Apr 2020 03:53:52 GMT', 'Content-Type': 'application/json', 'Content-Length': '308', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'"print(re.findall( "'Content-Length': '(.*?)'",res_style,re.S)) #注意:匹配到的内容放在了列表里print(re.findall( "'Content-Length': '(.*?)'",res_style,re.S)[0])#从列表中拿到匹配到的内容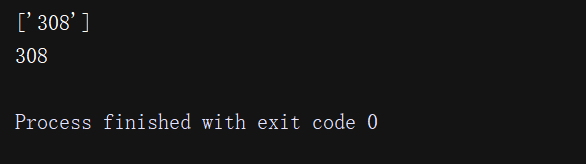
(2)re.match(pattern,string,flags=0)
第一部分:
位置限制
- 功能:匹配某个目标字符串开始位置
- 参数:
pattern正则表达式
string目标字符串 - 返回值:
如果匹配就是匹配内容match object;
如果不匹配,就返回None
print(re.match('www','www.baidu.com'))print(re.match('www','http://www.baidu.com'))#注意:不在开头拿不到!print(re.match('www','www.baidu.com').group())
小拓展:
- span()方法可以输出匹配的范围(注意是匹配到的结果字符串在原字符串中的位置范围!);
- group()方法可以输出匹配到的内容!
比如:
import recontent = "Hello 2021 123 World_good This is a beautiful world"print(len(content))result = re.match('^Hello\s\d\d\d\d\s\d{3}\s\w{10}', content)print(result)print(result.group())print(result.span())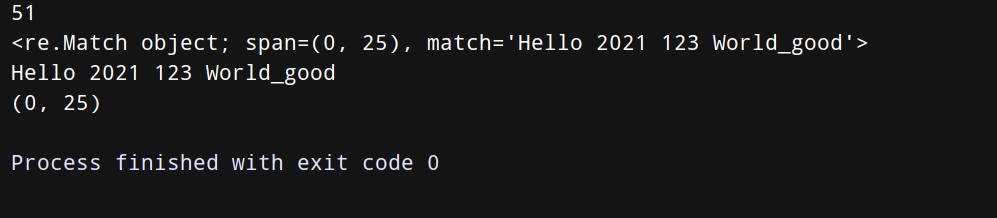
第二部分:
上面可以得到匹配到的字符串内容,但是如果想从字符串中提取一部分内容,该如何做?
这里可以使用()括号将想要提取的子字符串括起来。()实际上标记了一个子表达式的开始和结束位置,被标记的每个子表达式会依此对应每一个分组,调用group()方法传入分组的索引即可获取提取的结果!
import recontent = 'Hello 1234567 World_This is a Regex Demo'result = re.match('^Hello\s(\d+)\sWorld', content)print(result)print(result.group())print(result.group(1))print(result.span())- group(1)会输出第一个被()包围的匹配结果,如果正则表达式后面还有()包括的内容,那么可以依此使用group(2),group(3)等来获取;group()会输出完整的匹配结果。
(3)re.search(pattern,string,flags=0)
在匹配时会扫描整个字符串,匹配成功 返回的是第一个成功匹配的结果(是一个对象哦!这个对象包含了我们匹配的信息)
数量限制!
- 功能:匹配目标字符串第一个符合的内容
- 参数:pattern正则表达式
string目标字符串 - 返回值:匹配内容match object
注意:search也只能匹配到一个,找到符合规则的就返回,不会一直往后找
print(re.search('www','www.baidu.com'))print(re.search('www','www.baidu.com').group()) #只匹配第一个print(re.search('www','http:// www.baidu.com').group())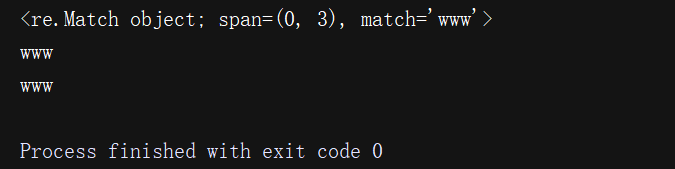
- re.match与re.search的区别:
re.match只匹配字符串的开始位置找,如果字符串开始不符合正则表达式,则匹配失败;
re.search:匹配整个字符串,如果一直找不到则,返回是空的,没有结果。
(4)re.sub(pattern,replace,string,max,flags=0)
除了使用正则表达式提取信息外,我们还可以借助它来修改文本。
- 功能:使用一个字符串替换正则表达式匹配到的内容
- 参数:pattern正则表达式
replace替换的字符串
string目标字符串
max最多替换几处,默认替换全部
flags功能标志位,扩展正则表达式的匹配 - 返回值:替换后的字符串
phone = "2004-956-559 # 这是一个国外电话号码"#删除字符串中的python注释num = re.sub(r'#.*',"",phone)print(num)# 删除非数字(-)的字符串num2 = re.sub(r'\D',"",phone)print(num2)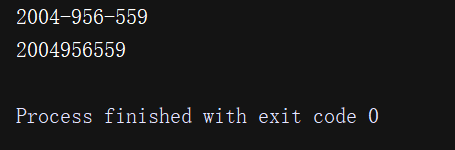
(5)re.compile(pattern, flags=0):
上述的方法都是用来处理字符串的方法,此方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
- 比如下面有三个日期,我们想要去掉它们里面的时间,可以借助sub()方法,但是如果写三遍正则表达式过于复杂,所以我们可以先将正则表达式编译成一个正则表达式对象,以便下面复用!
import recontent1 = '2016-12-15 12:00'content2 = '2016-1-12 16:00'content3 = '2016-6-5 12:30'pattern = re.compile('\d{2}:\d{2}')result1 = re.sub(pattern, '', content1)result2 = re.sub(pattern, '', content2)result3 = re.sub(pattern, '', content3)print(result1, result2, result3)
- 此外,compile()还可以传入修饰符,例如re.S,这样在search(),findall()的时候就不需要额外传了。可以说compile()方法是给正则表达式做了一层封装!
(3)实战—猫眼电影TOP100电影信息爬取:
- 看这里:《爬虫实战之抓取猫眼电影排行TOP100(使用正则表达式提取数据)》
👇🏻可通过点击下面——>关注本人运营 公众号👇🏻
【可以公众号里私聊并标明来自CSDN,会拉你进入技术交流群(群内涉及各个领域大佬级人物,任何问题都可讨论~)--->互相学习&&共同进步(非诚勿扰)】

