R语言时空数据分析-数据处理及可视化基础
本章有两个主要目标。
1.数据整理
时空建模和预测通常涉及大量数据,这些数据以各种形式提供给用户,但通常以 CSV 文件或文本文件中的表格形式提供。通常会花费大量时间来加载数据并对其进行预处理,以便将它们转化为适合分析的形式。R 中有几个包可以帮助用户快速实现这些目标;在这里,我们专注于使用tidyverse工作流处理删失,它们包含特别适合所需数据操作技术的函数。我们首先加载所需的包,以及 STRbook(访问 https://spacetimewithr.org 获取有关如何安装 STRbook 的说明)
library(tidyverse)library(STRbook)作为运行示例,我们将考虑 NOAA 数据集,该数据集以表格中的文本形式提供给我们,并随包 STRbook 提供。有六个数据表:
- Stationinfo.dat。该表包含 328 行(每个站点一列)和三列(站点 ID、纬度坐标和经度坐标),包含站点位置信息。
- Times_1990.dat。该表包含 1461 行(1990 年 1 月 1 日至 1993 年 12 月 30 日之间的每一天)和包含数据时间戳的四列(Julian公立日期、年、月、日)。
- Tmax_1990.dat。该表包含 1461 行(每个时间点一行)和 328 列(每个站点位置一列),其中包含所有最高温度数据,缺失值编码为 -9999。
- Tmin_1990.dat。与 Tmax_1990.dat 相同,但包含最低温度数据。
- TDP_1990.dat。与 Tmax_1990.dat 相同,但包含温度露点数据,缺失值编码为 −999.90001。
- Precip_1990.dat。与 Tmax_1990.dat 相同,但包含缺失值编码为 -99.989998 的降水数据。
第一项任务是将所有这些数据协调到一个对象中。在了解如何使用时空数据类来执行此操作之前,我们首先考虑将它们处理为长格式long format的标准 R 数据格式。
1.1处理长格式的时空数据
站点位置、时间和最高温度数据可以从 STRbook 加载到 R 中,如下所示。
locs <- read.table(system.file("extdata", "Stationinfo.dat", package = "STRbook"), col.names = c("id", "lat", "lon"))Times <- read.table(system.file("extdata", "Times_1990.dat", package = "STRbook"), col.names = c("julian", "year", "month", "day"))Tmax <- read.table(system.file("extdata", "Tmax_1990.dat", package = "STRbook"))在这种情况下,system.file 及其参数用于定位包 STRbook 中的数据,而 read.table 是 R 中用于从文本文件读取数据输入的最重要的函数。默认情况下, read.table 假定数据项由空格分隔,但这可以使用参数 sep进行更改。其他值得查找的重要数据输入函数包括用于逗号分隔值文件的 read.csv 和 read.delim。
上面我们已将列名添加到数据位置和时间,因为这些在原始文本表中不可用。由于我们没有给 Tmax 分配列名,所以列名是 read.table 分配的默认列名,即 V1、V2、…、V328。由于这些与站 ID 没有任何关系,我们使用 locs 中的数据适当地重命名这些列。
names(Tmax) = locs$id其他数据的加载方式与 Tmax 类似;我们将结果变量分别表示为 Tmin、TDP 和 Precip。应该使用函数 head 和 tail 来检查加载的数据是否合理。
现在考虑 NOAA 数据集中的最高温度数据。由于 Tmax 中的每一行都与一个时间点相关联,我们可以使用 cbind 将其按列附加到数据框 Times。
Tmax = cbind(Times, Tmax)现在 Tmax 包含前四列中的时间信息和其他列中的温度数据。要将 Tmax 转换为长格式 long format,我们需要确定一个键值对 key-value。在我们的例子中,数据采用全空间格式,其中键key是站 ID,值是最高温度(我们存储在名为 z 的字段中)。我们用来将数据帧放入长格式的函数是pivot_longer。
用 tidyr 包中的 pivot_longer() 函数来实现宽表变长表,其基本格式为: pivot_longer(data, cols, names_to, values_to, values_drop_na, …)
- data: 要重塑的数据框
- cols: 用选择列语法选择要变形的列
- names_to: 为存放变形列的列名中的 ‘‘值’’,指定新列名 values_to: 为存放变形列中的 ‘‘值’’,指定新列名 values_drop_na: 是否忽略变形列中的NA
若变形列的列名除了 ‘‘值’’ 外,还包含前缀、变量名 + 分隔符、正则表达式分组 捕获模式,则可以借助参数 names_prefix, names_sep, names_pattern 来提取 出 ‘‘值’’。此函数将数据作为第一个参数,即键值对,然后下一个参数是要作为值排除的任何列的名称(在这种情况下与时间戳相关的列)。
Tmax_long = Tmax %>% pivot_longer(-c(julian, year, month, day), names_to = "id", values_to = "z")head(Tmax_long)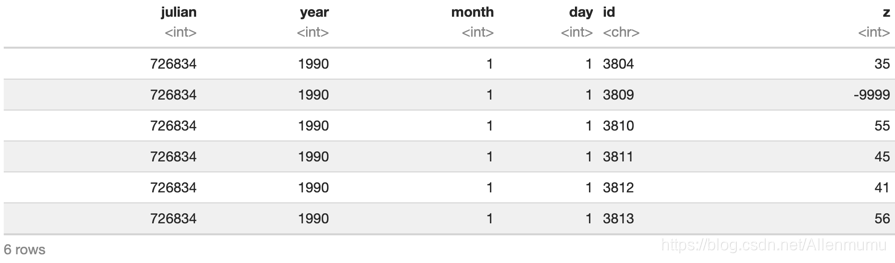
请注意pivot_longer 如何帮助我们实现目标:我们现在每个测量只有一行,并且多个行可能与同一时间点相关联。照原样,列 id 是类字符character,因为它是从列名中提取的。由于站 ID 是整数,因此应确保该字段是整数类integer。
Tmax_long = Tmax_long %>% mutate(id = as.integer(id))class(Tmax_long$id)## [1] "integer"当数据为长格式时,保留丢失的数据(在我们的例子中编码为 -9999)几乎没有用。为了过滤掉这些数据,我们可以使用函数filter。通常,由于存储数据时的截断错误,以这种方式过滤时最好使用不等式标准(例如,小于)而不是等价标准(等于)。这就是我们下面所做的,过滤掉值小于-9998 的数据而不是值等于-9999 的数据。这在处理其他变量时尤为重要,例如降水,其中缺失值为 -99.989998。
nrow(Tmax_long)## [1] 479208Tmax_long = Tmax_long %>% filter(!(z <= -9998))nrow(Tmax_long)## [1] 196253请注意我们数据集中的行数(从函数 nrow 返回)现在减少了一半以上。也可以使用 R 函数subset;然而,对于大型数据集,filter往往更快。subset和filter都将逻辑表达式作为如何过滤掉不需要的行的指令。逻辑表达式中的列名不会显示为字符串。在 R 中,这种提供参数的方法被称为非标准评估,我们将在实验过程中看到它的几个实例。
现在假设我们也希望在这个数据框中包含最低温度和其他变量。我们需要做的第一件事是首先确保每个测量值 z 都归因于一个过程。在我们的例子中,我们需要添加一个列,比如 proc,表明测量与哪个过程相关。
Tmax_long = Tmax_long %>% mutate(proc = "Tmax")head(Tmax_long)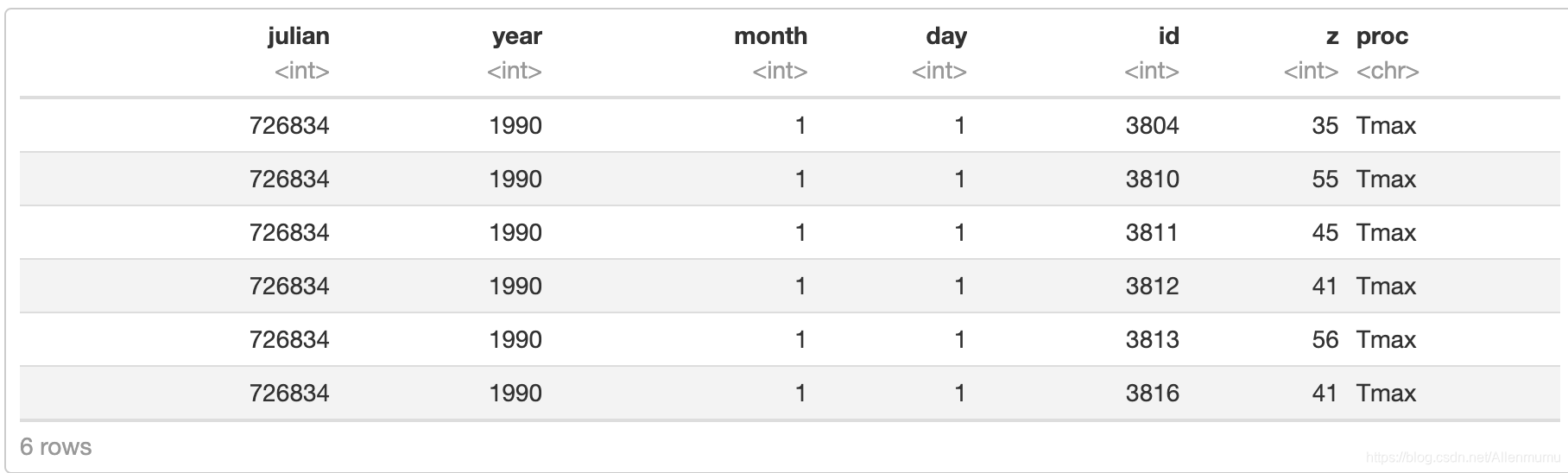
现在对其他变量重复相同的过程以获得数据帧 Tmin_long、TDP_long 和 Precip_long(记住缺失值的不同编码!)。为了节省时间,结果数据帧也可以直接从 STRbook 加载,如下所示。
data(Tmin_long, package = "STRbook")data(TDP_long, package = "STRbook")data(Precip_long, package = "STRbook")我们现在可以通过使用函数 rbind 将所有这些(按行)简单地连接在一起,以长格式构建我们的最终数据帧。
NOAA_df_1990 <- rbind(Tmax_long, Tmin_long, TDP_long, Precip_long)以长格式保存数据有很多优点。例如,它使分组和汇总特别容易。假设我们想找到每年每个变量的平均值。我们使用函数 group_by 和 summarise 来做到这一点。函数 group_by 创建一个分组数据框,而summary 对分组数据框内的每个组进行操作。
summ <- NOAA_df_1990 %>% group_by(year, proc) %>% # 分组 summarise(mean_proc = mean(z)) # 求均值或者,我们可能希望找出每年 6 月份每个站点没有下雨的天数。我们可以先过滤掉其他变量,然后使用summarise。
NOAA_precip = NOAA_df_1990 %>% filter(proc == "Precip" & month == 6)summ1 = NOAA_precip %>% group_by(year, id) %>% summarise(days_no_precip = sum(z == 0))head(summ1)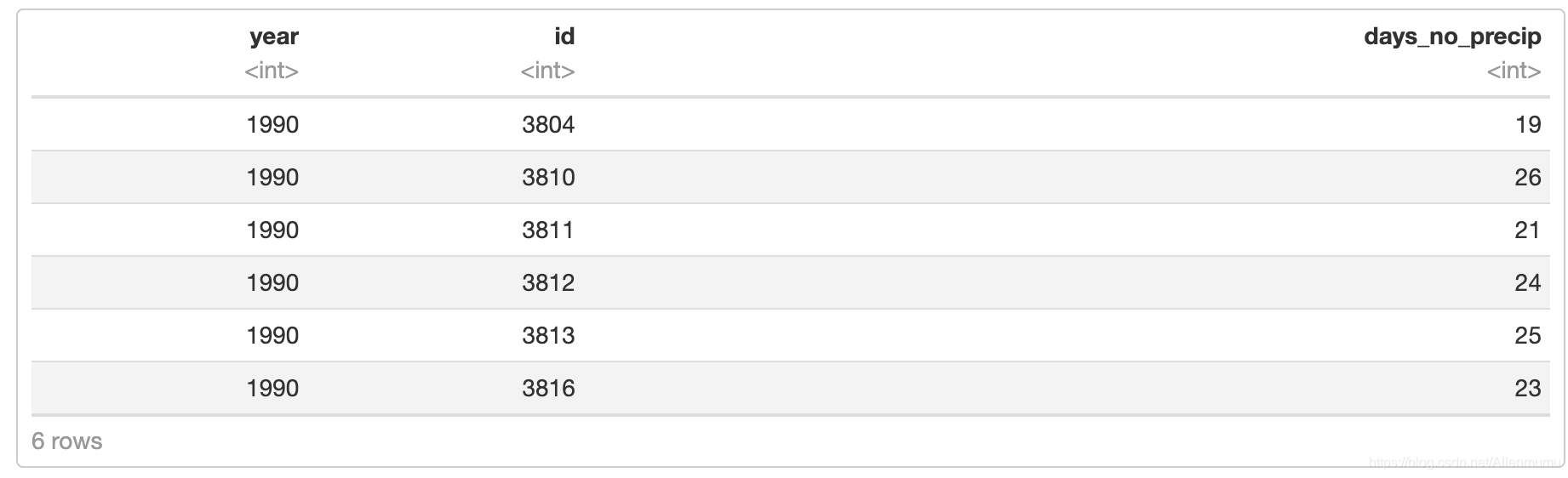
没有记录降水的中位数天数是
median(summ1$days_no_precip)## [1] 20目前,我们的长数据框不包含附加的空间信息。但是,对于每个站 ID,我们在数据框 locs 中有一个关联的坐标。我们可以使用函数 left_join合并loc到 NOAA_df_1990;使用 left_join 我们需要提供要合并的列字段名称。在我们的例子中,两个数据集的共同字段是“id”。
NOAA_df_1990 = left_join(NOAA_df_1990, locs , by = "id")最后,可能的情况是人们希望从长格式恢复到空间范围或时间范围的格式。这可以通过pviot_wider函数来实现,将值“加宽”到一个表中,而键则用于标记列。例如,下面的代码构建了一个空间范围的最高温度数据框,每行表示不同的日期,每列包含来自特定站 id 的数据 z。
Tmax_wide = Tmax_long %>% pivot_wider(names_from = id, values_from = z, values_fill = 0)dim(Tmax_wide)## [1] 1461 1421.2 创建时空数据对象
接下来,我们将数据转换为 STIDF 和 STFDF 类的对象;在这些类名中,“DF”是“数据框”的缩写,表示除了时空位置(只需要 STI 或 STF 对象),对象还包含数据。这些类在包 spacetime 中定义。由于有时我们使用空间对象构建时空对象,因此我们还需要加载包 sp。
library(sp)library(spacetime)(1)创建STIDF对象
不规则数据的时空对象 STIDF 可以使用两个函数构建:stConstruct 和 STIDF。让我们关注 Tmax_long 中的最高温度。在调用 stConstruct函数 之前,我们唯一需要做的就是从年、月、日字段中定义一个正式的时间戳。使用函数 paste 以年-月-日格式显示日期,该函数将字符串连接在一起。
NOAA_df_1990$date = with(NOAA_df_1990, paste(year, month, day, sep = "-"))head(NOAA_df_1990$date)## [1] "1990-1-1" "1990-1-1" "1990-1-1" "1990-1-1" "1990-1-1" "1990-1-1"字段日期是字符类型。现在可以使用 as.Date 将此字段转换为 Date 对象。
NOAA_df_1990$date = as.Date(NOAA_df_1990$date)class(NOAA_df_1990$date)## [1] "Date"现在我们已准备好构建最高温度的 STIDF 类的时空对象。最简单的方法是使用 stConstruct,其中我们以长格式提供数据框并指示哪些是空间和时间坐标。这是构建时空数据集所需的最低限度。
Tmax_long2 = NOAA_df_1990 %>% filter(proc == "Tmax")Tmax_long2 = as.data.frame(Tmax_long2)STObj = stConstruct(x = Tmax_long2, #数据集 space = c("lon", "lat"), #空间信息 time = "date") #时间信息class(STObj)## [1] "STIDF"## attr(,"package")## [1] "spacetime"函数class可用于确认我们已成功生成类 STIDF 的对象。
函数 STIDF 与 stConstruct 略有不同,因为它也需要将空间部分指定为包 sp 中的类 Spatial 的对象。在我们的例子中,空间组件只是一个包含不规则间隔数据的对象,它在包 sp 中是一个 SpatialPoints 对象。可以使用函数 SpatialPoints 并通过提供坐标作为参数来构造 SpatialPoints 对象。
spat_part <- SpatialPoints(coords = Tmax_long2[, c("lon", "lat")])temp_part <- Tmax_long2$dateSTObj2 <- STIDF(sp = spat_part, time = temp_part, data = select(Tmax_long2, -date, -lon, -lat))class(STObj2)## [1] "STIDF"## attr(,"package")## [1] "spacetime"(2)创建 STFDF 对象
可以使用类似的方法来构造 STFDF 对象。当空间点在时间上固定时,我们只需要提供与空间点一样多的空间坐标,在这种情况下是站点位置的空间坐标。我们还需要提供常规时间戳,即 1990 年 1 月 1 日至 1993 年 12 月 30 日之间的每一天。最后,数据可以使用 stConstruct 以空间或时间格式提供,也可以以长格式提供与 STFDF。
空间和时间部分可以从原始数据中获得如下。
spat_part <- SpatialPoints(coords = locs[, c("lon", "lat")])temp_part <- with(Times, paste(year, month, day, sep = "-"))temp_part <- as.Date(temp_part)数据需要以长格式提供,但现在它们也必须包含所有缺失值,因为必须为每个空间和时间组合提供一个数据点。
Tmax_long3 = Tmax %>% pivot_longer(-c(julian, year, month, day), names_to = "id", values_to = "z")非常重要的是,提供给 STFDF 的长格式数据帧的空间索引移动速度快于时间索引,并且空间索引的顺序与提供的空间组件的顺序相同。
Tmax_long3$id <- as.integer(Tmax_long3$id)Tmax_long3 <- arrange(Tmax_long3,julian,id)确认 Tmax_long3 中的空间排序是正确的可以按如下方式完成。
all(unique(Tmax_long3$id) == locs$id)## [1] TRUE现在可以来构建 STFDF 对象了。
STObj3 <- STFDF(sp = spat_part, time = temp_part, data = Tmax_long3)class(STObj3)## [1] "STFDF"## attr(,"package")## [1] "spacetime"那么现在关于时空数据处理及构建时空数据对象的基本流程已经完成,接下来可以对时空数据进行一些简单的可视化才做。
2.时空数据可视化
在本实验中,我们将可视化 NOAA 数据集中的最高温度数据。具体而言,我们考虑了 1993 年 5 月至 1993 年 9 月(含)之间的最高记录温度。我们需要的包是animation、dplyr、ggplot2、gstat、maps和STRbook。
library("animation") library("dplyr") library("ggplot2") library("gstat") library("maps") library("STRbook")我们现在加载数据集并使用函数filter获取其中的一个子集。
data("NOAA_df_1990", package = "STRbook")Tmax <- filter(NOAA_df_1990, #选择数据集 proc == "Tmax" & #只选取最大温度值 month %in% 5:9 & #时间是5月-9月 year == 1993) # 1993年的数据第一个记录的julian日期为 728050,对应于 1993 年 5 月 1 日。为了简化以下操作,我们创建了一个新变量 t,当 julian == 728050 时等于 1,并且记录中的每一天都增加 1。
Tmax$t = Tmax$julian - 728049时空建模面临的第一个任务是数据可视化。这是一项重要的初步任务,需要在探索性数据分析阶段和建模阶段之前执行。在整个过程中,我们将广泛使用图形包 ggplot2 的语法。
2.1空间图 Spatial plots
可视化技术因所分析的数据而异。 NOAA 数据是在空间固定的站点上收集的;因此,初始图应该让建模者了解观测数据的整体空间变化。如果有很多时间点,通常只选择一部分时间点进行可视化。在这种情况下,我们选择三个时间点。
Tmax_1 <- subset(Tmax, t %in% c(1, 15, 30)) # 提取数据变量 Tmax_1 包含与 Tmax 中的第一天、第十五天和第三十天相关联的数据。我们现在使用 ggplot2 绘制这个数据子集。请注意,下面的 col_scale 函数只是 ggplot2 函数 scale_colour_distiller 的包装器,并随 包STRbook 一起提供。
# 设置ggplot默认主题为theme_bw()theme_set(theme_bw())NOAA_plot = ggplot(Tmax_1) + geom_point(aes(x = lon, y = lat, # 描点 colour = z), # 根据温度赋予颜色 size = 2) + # 让点更大一点 col_scale(name = "degF") +# 修改配色 xlab("Longitude (deg)") + ylab("Latitude (deg)") + geom_path(data = map_data("state"), aes(x = long, y = lat, group = group)) + # 加入美国州的地图 facet_grid(~date) + # 按时间画分面图 coord_fixed(xlim = c(-105, -75),ylim = c(25, 50)) # 设置坐标轴范围print(NOAA_plot)
NOAA_plot 是站点空间位置图。 geom_point 的函数 aes(美学的缩写)标识数据帧 Tmax_1 中的哪个字段是 x 坐标,哪个是 y 坐标。 命令 print(NOAA_plot) 生成如图所示的图形。可以看出,站点在整个区域内大致有规律地间隔开。
在处理地理数据时,通过将国家或州边界与数据位置一起绘制,将数据的空间位置置于透视中也是一种很好的做法。上面,美国州界是通过命令map_data(“state”)从maps包中获取的。然后使用 geom_path 将边界覆盖在图上,它只是连接点并绘制带有 x 对 y 的结果路径。
在这个例子中,我们使用了 ggplot2 来绘制点参考数据。规则点阵数据的图,如图 2.2 所示,类似地使用 geom_tile 生成。使用 geom_polygon 生成不规则点阵数据图。作为后者的一个例子,考虑 BEA 收入数据集。这些数据可以从 STRbook 加载如下。
data("BEA", package = "STRbook") head(BEA %>% select(-Description), 3)
从前三条记录可以看出,数据集包含个人收入,在
1970 年、1980 年和 1990 年按县和年计算。这些数据需要
与包含地理空间信息的密苏里县数据合并。
data("MOcounties", package = "STRbook") head(MOcounties %>% select(long, lat, NAME10), 3)数据集包含县的边界点,以及我们在此不探讨的其他几个变量。例如,要绘制第一个县的边界,只需键入
County1 <- filter(MOcounties, NAME10 == "Clark, MO") plot(County1$long, County1$lat)
为了将 BEA 收入数据添加到包含地理空间信息的数据中,我们使用了 left_join。
MOcounties <- left_join(MOcounties, BEA, by = "NAME10")现在只需使用 geom_polygon 调用 ggplot 即可将 BEA 收入数据显示为空间多边形。我们还使用 geom_path 来绘制县边界。下面我们展示了 1970 年的代码; 1980 年和 1990 年需要类似的代码。请注意使用 group 参数来确定哪些点对应于哪个县。结果如图所示。
g1 <- ggplot(MOcounties) + geom_polygon(aes(x = long, y = lat, # 县界 group = NAME10, # 县分组 fill = log(X1970))) + # 收入的对数 geom_path(aes(x = long, y = lat, # 县界 group = NAME10)) + #县分组 fill_scale(limits = c(7.5,10.2),name = "log($)") + coord_fixed() + ggtitle("1970") + xlab("x (m)") + ylab("y (m)") print(g1)
2.2时间序列图 Time-Series Plots
接下来,我们看一下 NOAA 数据集中与最高温度数据相关的时间序列。可以绘制所有 139 个气象站的时间序列(推荐这样做);在这里,我们查看随机选择的一组站点的时间序列。我们首先获得唯一的台站标识符集,从中随机选择10个,从数据集中提取与这10个台站相关的数据。
UIDs = unique(Tmax$id) # 提取 IDs UIDs_sub = sample(UIDs, 10) # 选取10个ID样本 Tmax_sub <- filter(Tmax, id %in% UIDs_sub) # 选取对应ID的数据子集为了可视化这些站点的时间序列,我们使用了 facet函数。当给定一个长数据框时,可以首先将数据框细分为组并为每组生成一个图。以下代码显示每个站点的时间序列。我们使用的命令是 facet_wrap,它会自动调整显示分面的行数和列数。如果指定,则命令 facet_grid 将列用于一个分组变量,而行用于第二个分组变量。
TmaxTS <- ggplot(Tmax_sub) + geom_line(aes(x = t, y = z)) + facet_wrap(~id, ncol = 5) + xlab("Day number (days)") + ylab("Tmax (degF)") + theme(panel.spacing = unit(0.1, "lines")) # 分面间距print(TmaxTS)
提供给 facet_wrap 的参数 ~id 是 R 中的一个公式。在这种情况下,该公式用于表示我们正在分面的组。语法 x~y 可用于对两个变量进行分面。
2.3 Hovmoller Plot
Hovmöller 图是二维时空可视化,其中空间被折叠(投影或平均)到一维上;第二个维度则表示时间。如果数据位于时空网格上,则可以相对容易地生成 Hovmöller 图。
考虑纬度 Hovmöller 图。第一步是使用函数 expand.grid 生成一个由 25 个空间点和 100 个时间点组成的规则网格,并将限制设置为数据集中可用的纬度和时间限制。
lim_lat = range(Tmax$lat) # 纬度范围lim_t = range(Tmax$t) #时间范围lat_axis = seq(lim_lat[1], lim_lat[2], length = 25) # 维度轴t_axis = seq(lim_t[1], lim_t[2], length = 100) #时间轴lat_t_grid <- expand.grid(lat = lat_axis, t = t_axis)接下来,我们需要将每个站点的纬度坐标与网格上最近的纬度坐标相关联。这可以通过找到从站的纬度坐标到网格每个点的距离,找到最接近的网格点,并将其分配给它来完成。我们将网格数据存储在 Tmax_grid 中。
Tmax_grid <- Tmaxdists <- abs(outer(Tmax$lat, lat_axis, "-")) Tmax_grid$lat <- lat_axis[apply(dists, 1, which.min)]现在我们已经将每个站点与一个纬度坐标相关联,剩下的就是按纬度和时间分组,然后我们对落在纬度-时间段内的所有站点值求平均值。
Tmax_lat_Hov <- group_by(Tmax_grid, lat, t) %>% summarise(z = mean(z))head(Tmax_lat_Hov)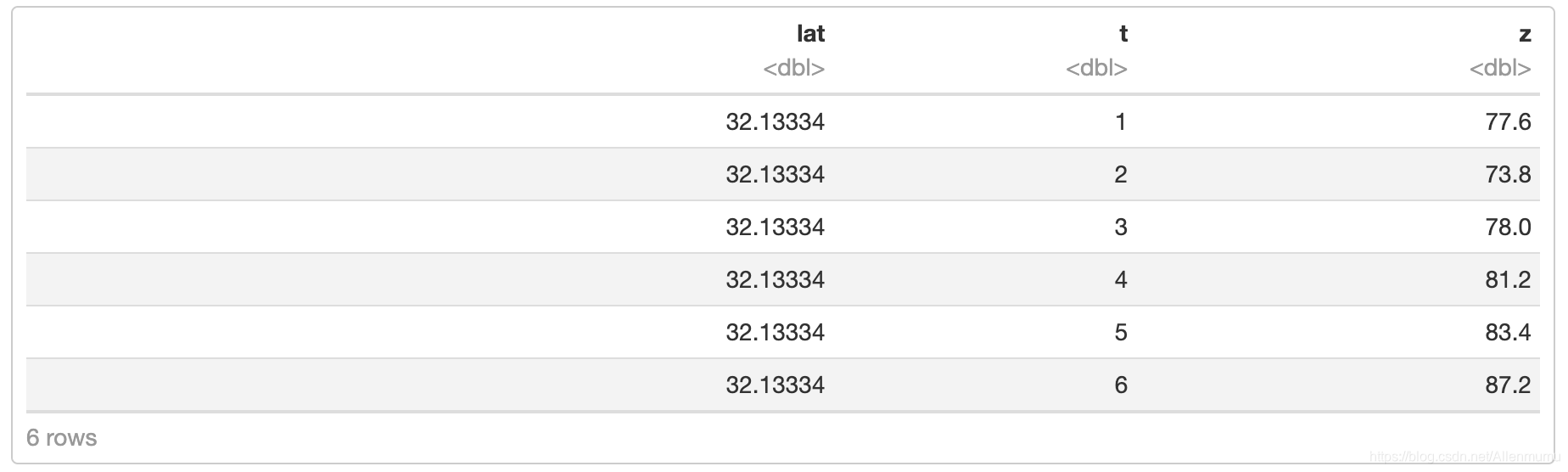
在这种情况下,每个纬度-时间带至少包含一个数据点,因此 Hovmöller 图在已建立的网格上不包含缺失点。情况可能并非总是如此,简单的插值方法(例如 akima 包中的 interp)可用于填充没有数据的网格单元。
使用 ggplot2 函数 geom_tile 有助于绘制网格数据。函数 geom_tile 与 geom_point 类似,不同之处在于它假设有规律地间隔数据并自动在图中使用矩形块。由于矩形块是“填充的”,我们使用 STRbook 函数 fill_scale 而不是 col_scale。
Hovmoller_lat <- ggplot(Tmax_lat_Hov) + # take data geom_tile(aes(x = lat, y = t, fill = z)) + # plot fill_scale(name = "degF") + scale_y_reverse() + # 反转y轴 ylab("Day number (days)") + xlab("Latitude (degrees)") print(Hovmoller_lat)
函数 scale_y_reverse 确保时间从上到下增加,这在 Hovmöller 图中是默认的做法的。。

