基于 Python 的招聘信息可视化分析系统
温馨提示:文末可扫描作者 QQ 名片
1. 项目简介
本项目利用 Python 从某招聘网站抓取海量招聘数据,进行数据清洗和格式化后存储到关系型数据库中(如mysql、sqlite等),利用 Flask + Bootstrap + Echarts 搭建招聘信息可视化分析系统,实现不同岗位的学历要求、工作经验、技能要求、薪资待遇等维度的可视化分析,并根据岗位所在地进行不同地域(华东、华北、华中、华南、西南、西北和东北)维度的细粒度分析。同时依据用户需求实现热门岗位的推荐,并利用决策树算法实现岗位薪资的预测。
2. 招聘信息
分析某招聘网站的网页结构和接口可以看出,招聘数据可直接通过接口返回的 json 格式数据直接得到,因此采集相对比较简单了,直接模拟接口请求,对返回的数据进行解析即可。
base_url = 'https://search.xxxxx.com/list/000000,000000,0000,00,9,99,%25E5%25BC%2580%25E5%258F%2591,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='datas = []for page in range(1, total_page + 1): print('--> 第 {} 页'.format(page)) url = base_url.format(page) headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36', 'accept-language': 'zh-CN,zh;q=0.9', 'cache-control': 'max-age=0', 'Cookie': 'Your Cookie', 'Host': 'search.51job.com', } response = requests.get(url, headers=headers) items = response.json()['engine_jds'] for item in items: try: job_name = item['job_name'] hangye = item['companyind_text'] company = item['company_name'] salary = item['providesalary_text'] location = item['attribute_text'][0] location = location.split('-')[0] location = location.split('_')[0] jingyan = item['attribute_text'][1] xueli = item['attribute_text'][2] zhaopin_counts = 1#item['attribute_text'][3] pub_time = item['issuedate'] datas.append((job_name, hangye, company, location, salary, jingyan, xueli, zhaopin_counts, pub_time)) except: pass print('爬取了 {} 条就业数据'.format(len(datas)))3. 招聘信息可视化分析系统
3.1 系统注册登录
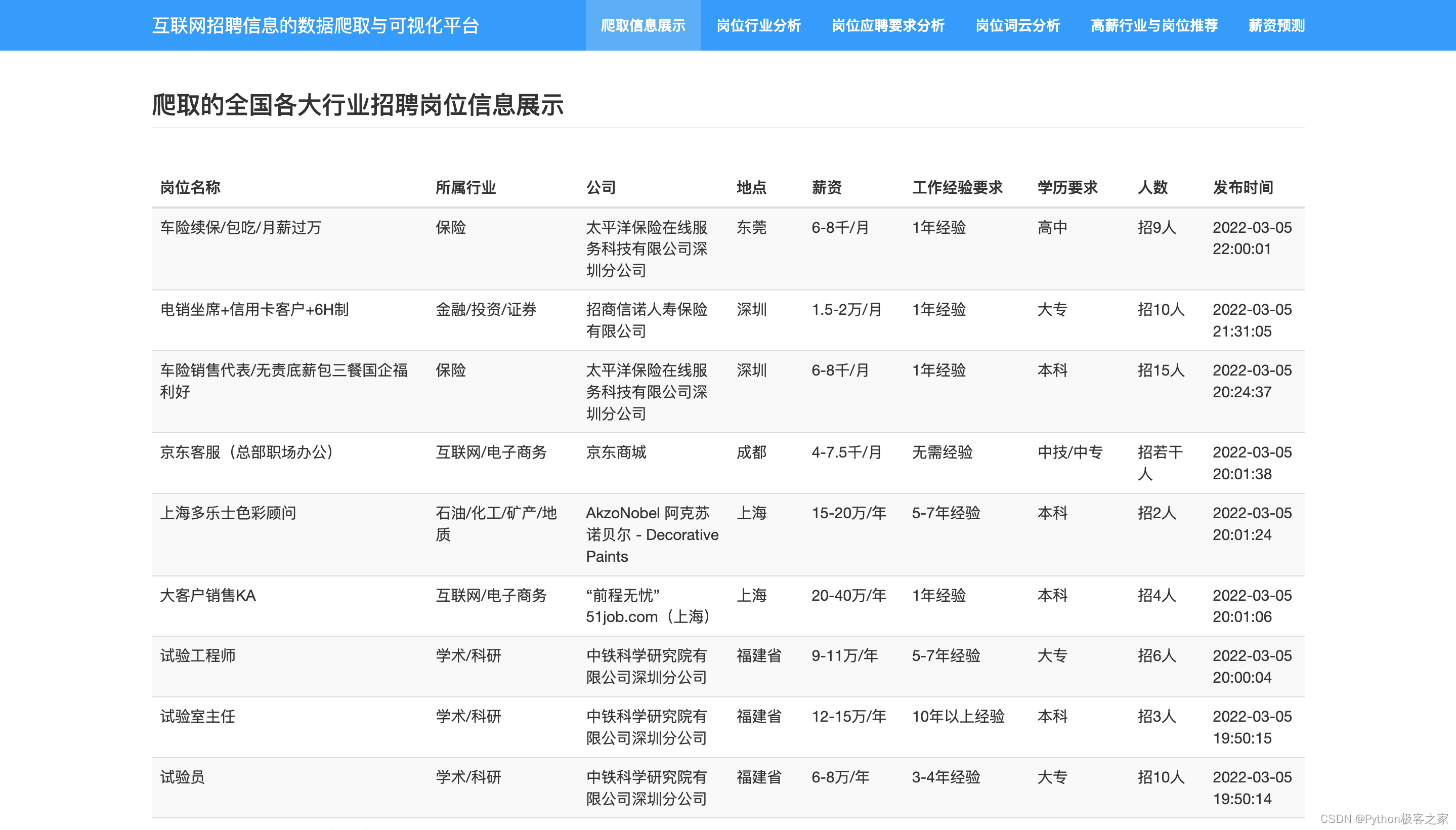
3.2 招聘数据展示
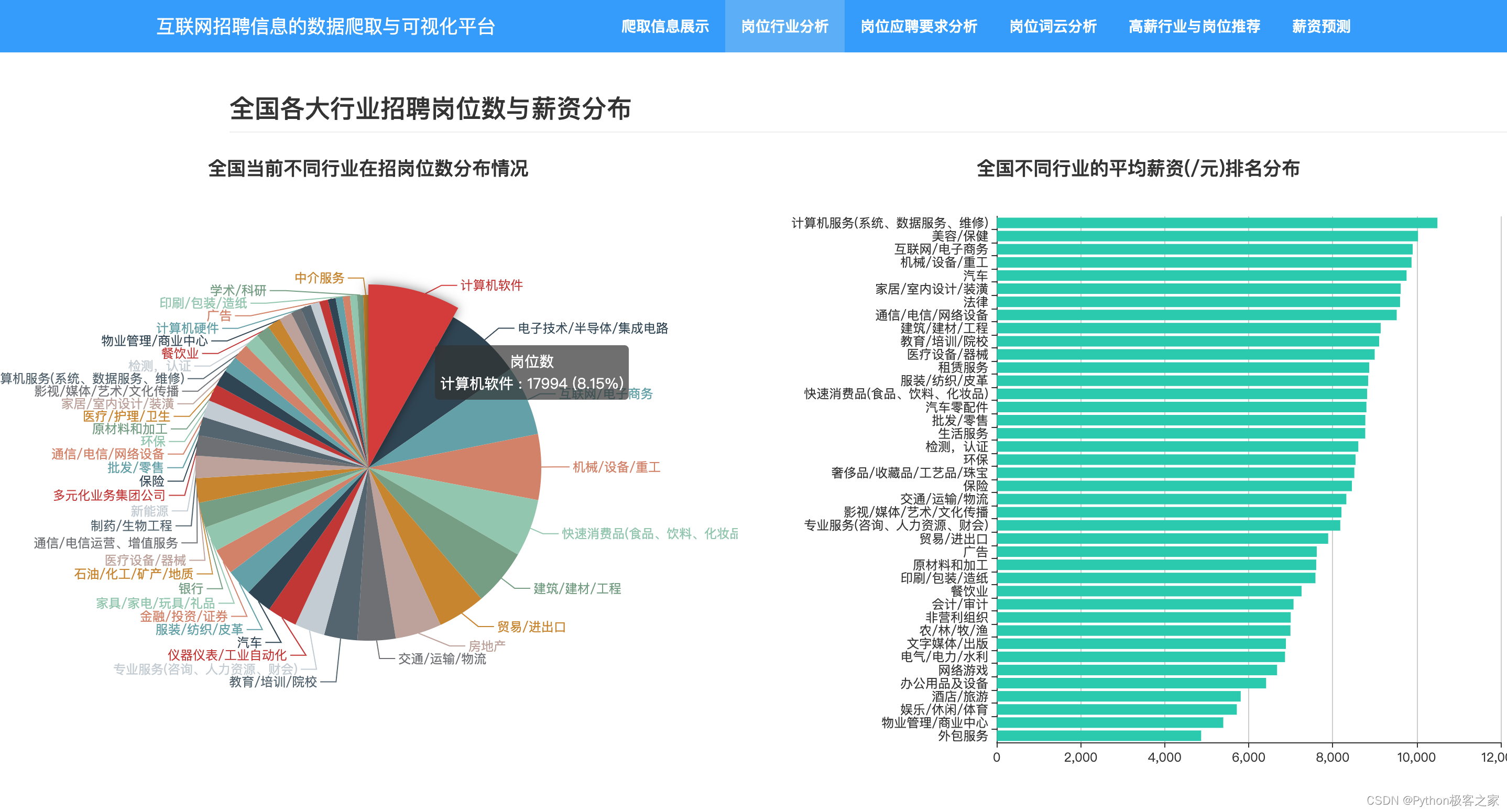
3.3 各行业招聘岗位数与薪资分布
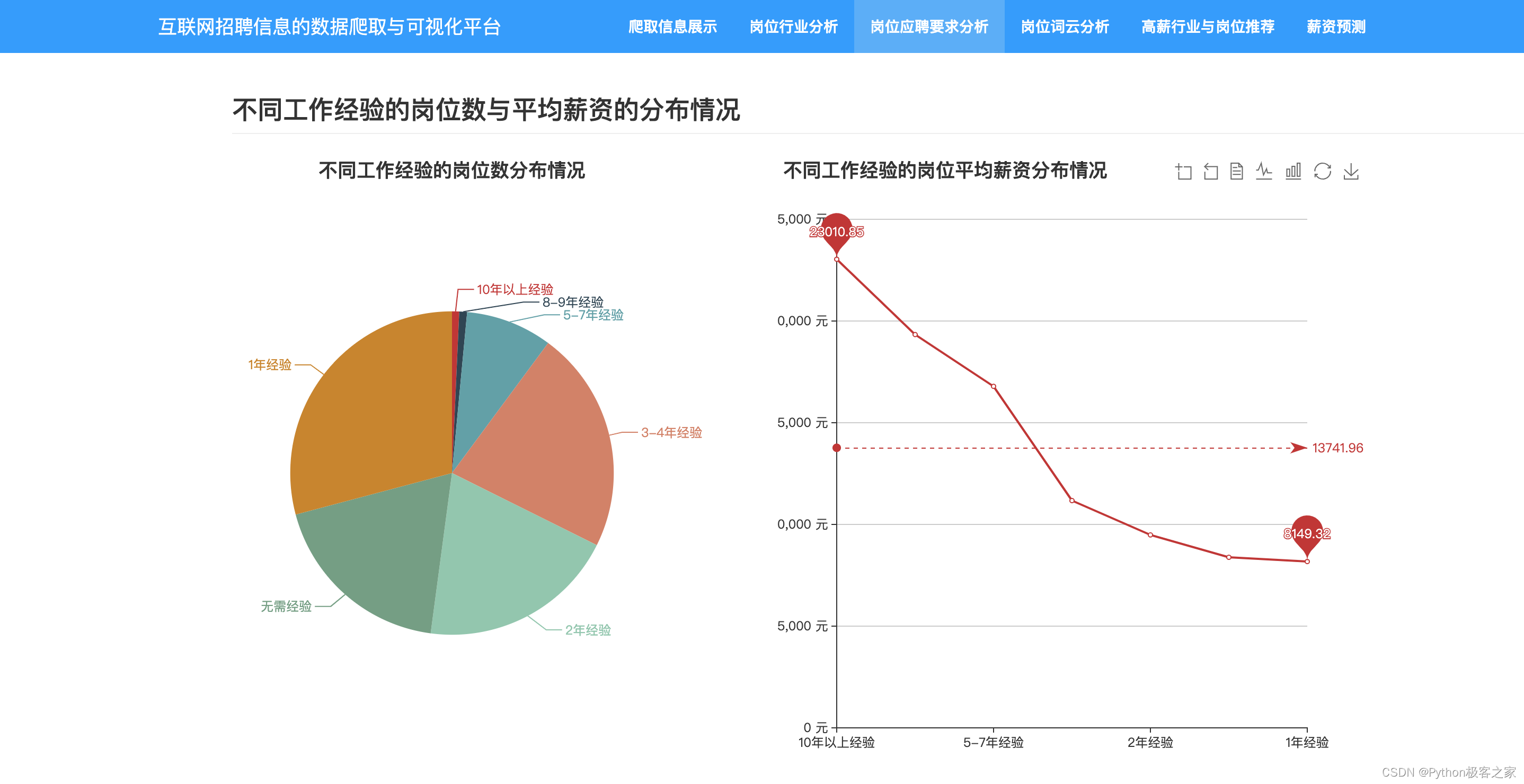
3.4 不同工作经验的岗位数与平均薪资的分布情况
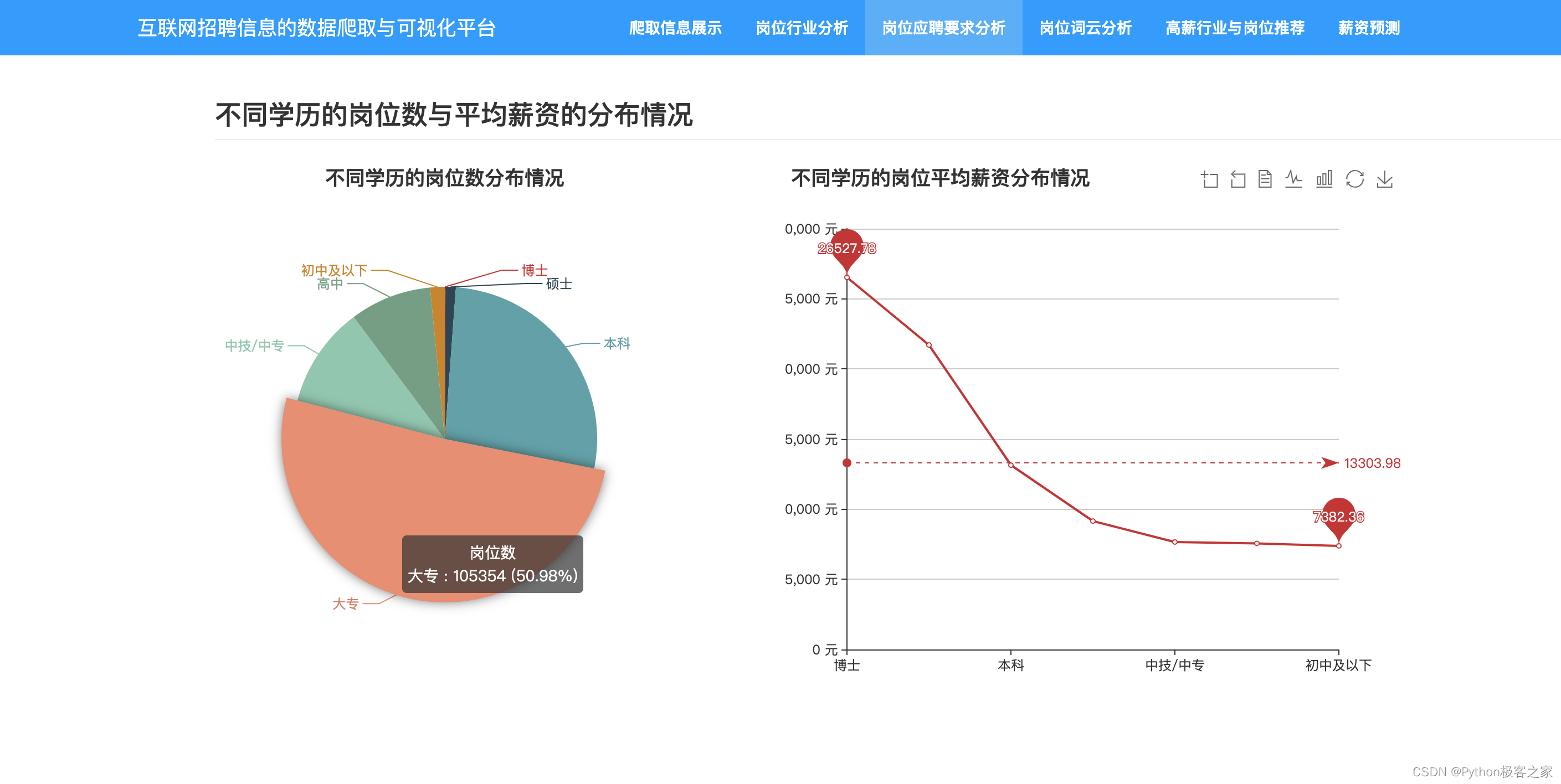
3.5 不同学历的岗位数与平均薪资的分布情况
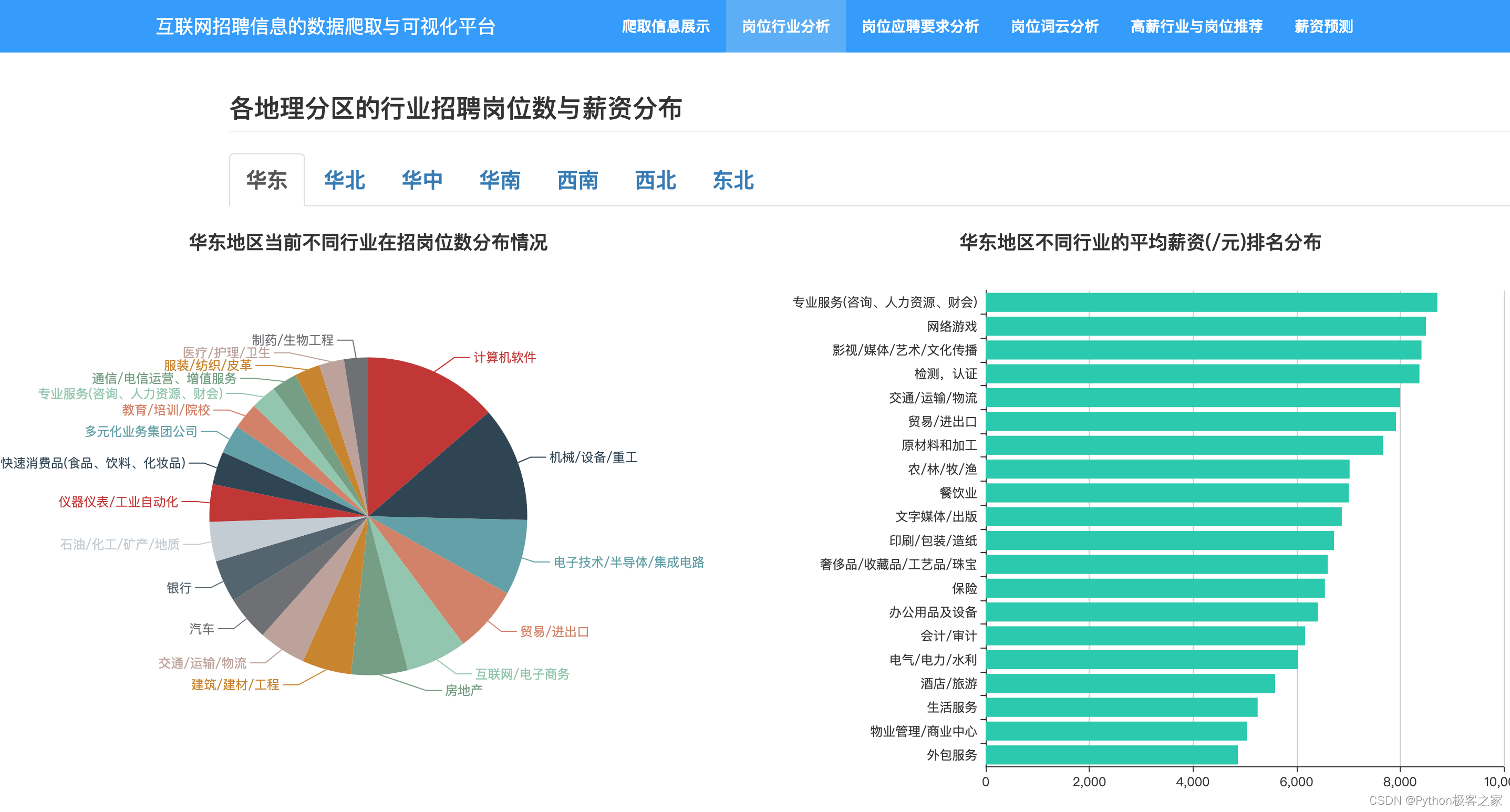
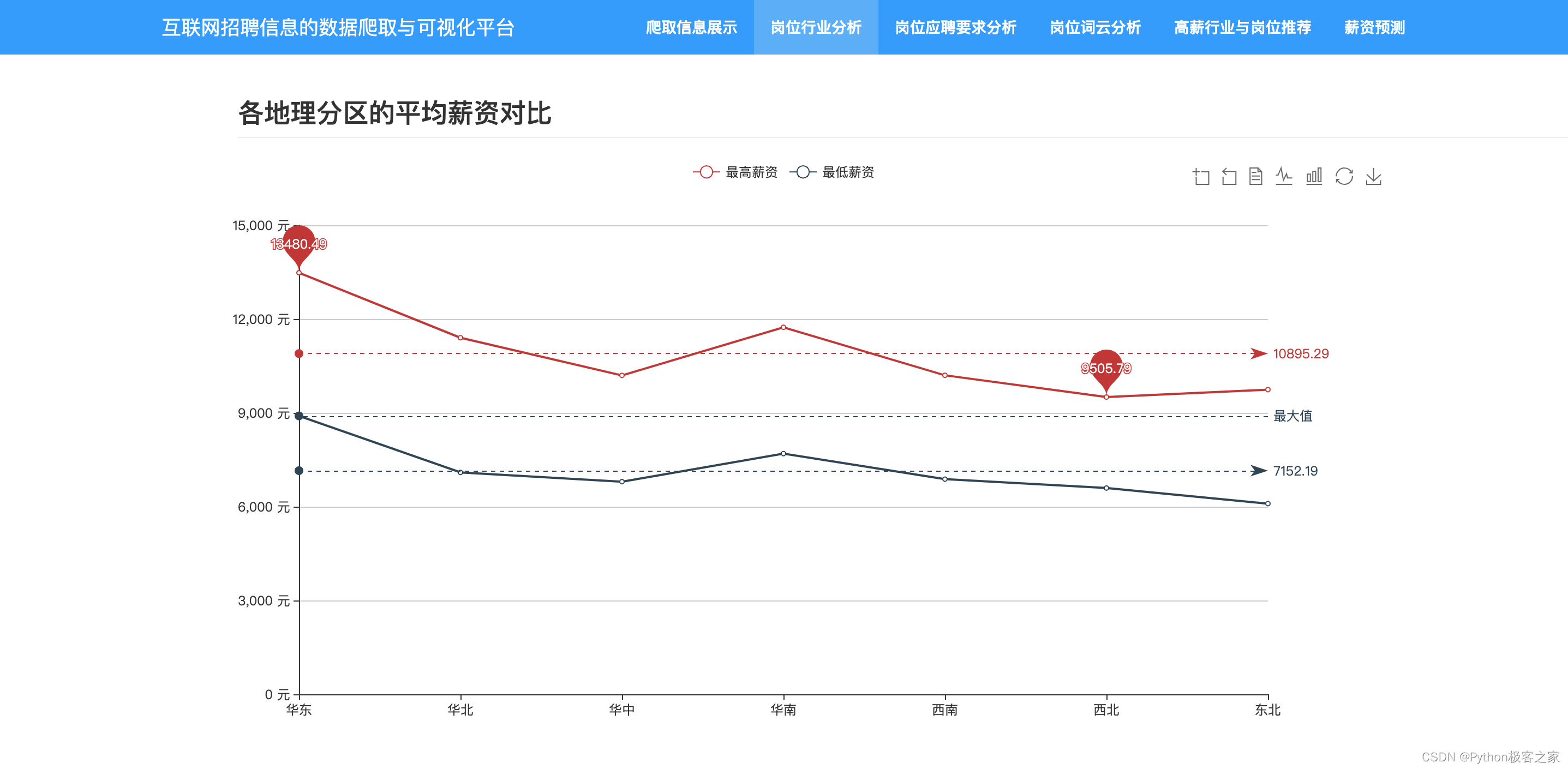
3.6 不同区域热招岗位及其薪资分布情况

3.7 热门岗位推荐

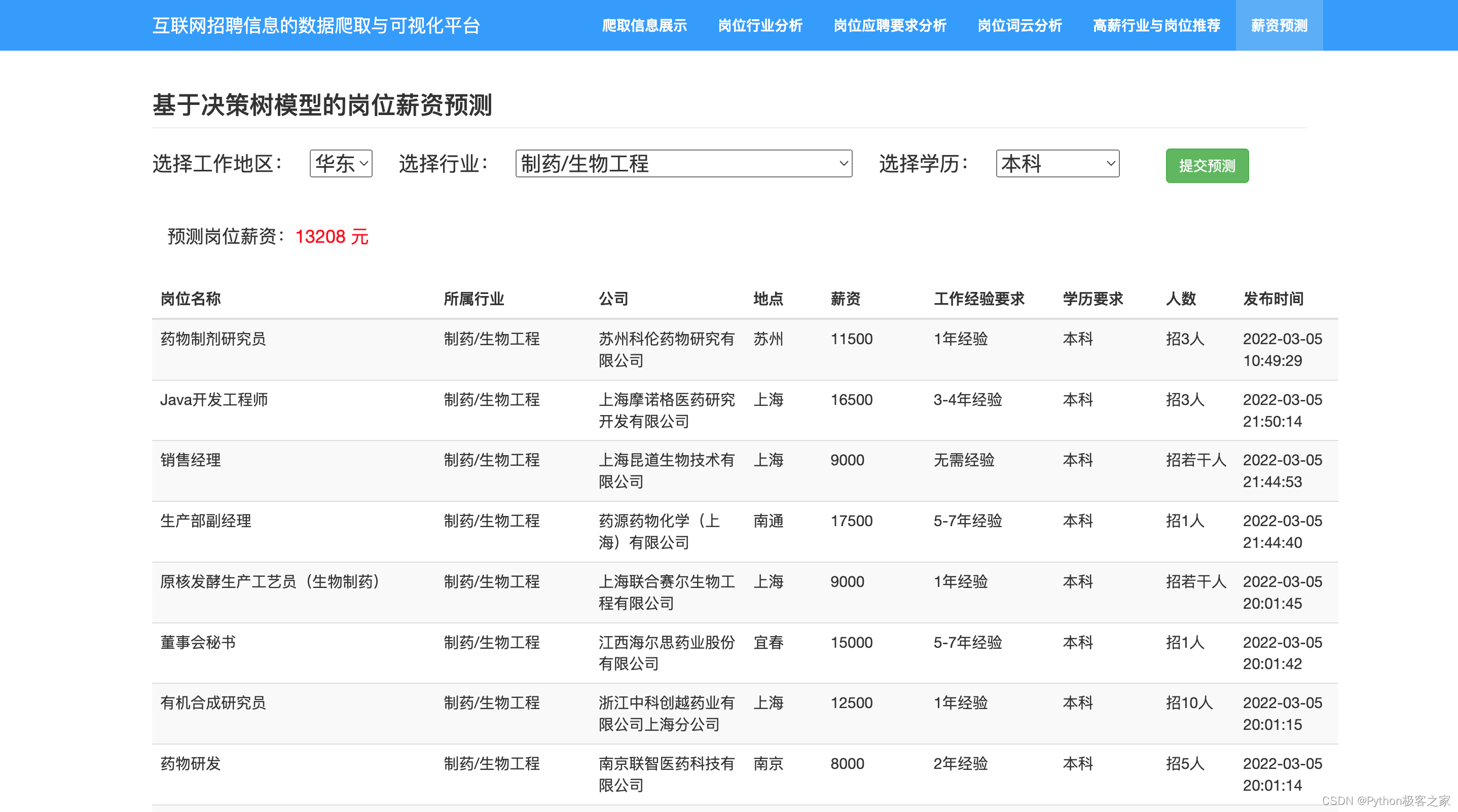
3.8 基于决策树模型的岗位薪资价格预测
扫描下方作者 QQ 名片 


