基于大数据的房价数据可视化分析预测系统
1. 项目背景
房地产是促进我国经济持续增长的基础性、主导性产业,二手房市场是我国房地产市场不可或缺的组成部分。由于二手房的特殊性,目前市场上实时监测二手房市场房价涨幅的情况较少,影响二手房价的因素错综复杂,价格并非呈传统的线性变化。
本项目利用Python实现某一城市二手房相关信息的爬取,并对爬取的原始数据进行数据清洗,存储到数据库中,通过 flask 搭建后台,分析影响二手房房价的各类因素,并构建递归决策树模型,实现房价预测建模。
2. 二手房数据
二手房信息爬C流程为,先获取该市所有在售楼盘,以保定市为例,其中,p1 表示分页的页码,因此可以构造循环,抓取所有分页下的楼盘数据。
base_url = 'https://baoding.anjuke.com/community/p{}/'all_xqlb_links = set()for page in range(1, 51): url = base_url.format(page) # 获取 html 页码,并进行dom解析 # ...通过分析 html 页面的 Dom 结构,利用 Bootstrap 进行解析,获取楼盘的详细字段信息。
同理,获取楼盘下所有在售房源信息:
def get_house_info(house_link): """获取房屋的信息""" headers = { 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8', 'cookie': 'aQQ_ajkguid=7C0DF728-2DD3-AEF7-5AE1-AAC7E82D8A60; id58=CocHKmGeUbtvnzYfKtAIAg==; _ga=GA1.2.440545268.1637765564; 58tj_uuid=77fb0a86-cfab-4a4f-aa63-e2e4a69731fa; als=0; cmctid=772; sessid=A3E31958-F652-4014-B26C-87EE93EFE667; ctid=14; fzq_h=a9b2d7c26e6521ef071ae84068ac5aa0_1637996216214_75db448315884028ab128221dd4077c8_47901717218226362245370512298064674903; twe=2; new_uv=2; _gid=GA1.2.1381332738.1637996382; wmda_uuid=d437ad68fb26624a80f2670595ea2c0d; wmda_session_id_6289197098934=1637996411733-36806473-f8b4-a246; wmda_visited_projects=%3B6289197098934; new_session=0; utm_source=; spm=; fzq_js_anjuke_xiaoqu_pc=ac0887cb147cd4ba84155189391aa497_1637996809340_24; init_refer=https%253A%252F%252Fbeijing.anjuke.com%252Fcommunity%252Fprops%252Fsale%252F51651%252Fp5%252F; _gat=1; obtain_by=2; fzq_js_anjuke_ershoufang_pc=138af2c9eed465b9859e227d331d33ea_1637997414151_25; xxzl_cid=eb195336df074605b844f558d2dac96b; xzuid=9e6e0d0a-9d5d-4401-99f3-f7c206e85d52', 'referer': house_link, 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36' } response = requests.get(house_link, headers=headers) response.encoding = 'utf8' soup = BeautifulSoup(response.text, 'lxml') house_info = { '链接': house_link, '产权性质': '未知', '房屋类型': '未知', '产权年限': '未知', '房本年限': '未知', '唯一住房': '未知', '参考首付': '未知', '发布时间': '未知', '总价': '', '单价': '', '房屋户型': '未知', '所在楼层': '未知', '建筑面积': '', '装修程度': '未知', '房屋朝向': '未知', '建造年代': '未知', '配套电梯': '无', '所属小区': '未知', '所在位置': '未知' } tbody = soup.select('tbody.houseInfo-main')[0] tds = tbody.select('td') for td in tds: datas = td.text.split(' ') if '产权性质' in datas[0]: house_info['产权性质'] = datas[0].replace('产权性质', '') if '产权年限' in datas[0]: house_info['产权年限'] = datas[0].replace('产权年限', '') if '发布时间' in datas[0]: house_info['发布时间'] = datas[0].replace('发布时间', '') if '唯一住房' in datas[0]: house_info['唯一住房'] = datas[0].replace('唯一住房', '') if '房屋类型' in datas[0]: house_info['房屋类型'] = datas[0].replace('房屋类型', '') if '房本年限' in datas[0]: house_info['房本年限'] = datas[0].replace('房本年限', '') if '参考预算' in datas[0]: yusuan = datas[0].replace('参考预算', '') house_info['参考首付'] = yusuan[2:].split(',')[0] total_price = soup.select('span.maininfo-price-num')[0] total_price = total_price.text.strip() house_info['总价'] = total_price avgprice = soup.select('div.maininfo-avgprice-price')[0] avgprice = avgprice.text.strip() house_info['单价'] = avgprice huxing = soup.select('div.maininfo-model-item.maininfo-model-item-1')[0] huxing = huxing.text.strip() house_info['房屋户型'] = huxing.split(' ')[0] house_info['所在楼层'] = huxing.split(' ')[1] daxiao = soup.select('div.maininfo-model-item.maininfo-model-item-2')[0] daxiao = daxiao.text.strip() house_info['建筑面积'] = daxiao.split(' ')[0] house_info['装修程度'] = daxiao.split(' ')[1] chaoxiang = soup.select('div.maininfo-model-item.maininfo-model-item-3')[0] chaoxiang = chaoxiang.text.strip() house_info['房屋朝向'] = chaoxiang.split(' ')[0] house_info['建造年代'] = chaoxiang.split(' ')[1].split('/')[0][:-2] bar = soup.select('div.crumbs.crumbs-middle')[0] xiaoqu = bar.select('a.anchor.anchor-weak')[-1] house_info['所属小区'] = xiaoqu.text.strip() tags = soup.select('div.maininfo-tags')[0].text if '电梯' in tags: house_info['配套电梯'] = '有' # 所属区域 for line in soup.select('div.maininfo-community-item'): text = line.text.strip() if '所属区域' in text: house_info['所在位置'] = text.split(' ')[1].split('\xa0')[0] return house_info3. 二手房数据清洗与存储
抓取的原始数据可能存在数据异常、缺失等情况,需要进行数据清洗和数据类型转换等预处理操作。清洗后的数据存储到 mysql 或 sqlite 等关系型数据库中。
for house_info in all_house_infos: for key in all_keys: if key not in house_info: house_info[key] = '暂无' if isinstance(house_info['单价'], float): continue house_info['单价'] = float(house_info['单价'][:-3].strip()) house_info['总价'] = float(house_info['总价'].strip()) house_info['建筑面积'] = float(house_info['建筑面积'][:-1].strip()) house_info['参考首付'] = float(house_info['参考首付'][:-1].strip()) tmp = list(map(int, re.findall(r'(\d+)', house_info['房屋户型']))) house_info['房屋户型_室数'] = tmp[0] house_info['房屋户型_厅数'] = tmp[1] house_info['房屋户型_卫数'] = tmp[2] del house_info['房屋户型'] if '(' not in house_info['所在楼层']: house_info['所在楼层'] = '底层({})'.format(house_info['所在楼层']) house_info['总楼层'] = list(map(int, re.findall(r'(\d+)', house_info['所在楼层'])))[0] house_info['所在楼层'] = house_info['所在楼层'][:2] 4. 二手房价可视化分析预测系统
系统采用 flask 搭建 web 后台,利用 pandas 等工具包实现对当前城市二手房现状、二手房价格影响因素等进行统计分析,并利用 bootstrap + echarts 进行前端渲染可视化。系统通过构建机器学习模型(决策树、随机森林、神经网络等模型),对二手房价格进行预测。
4.1 系统首页/注册登录
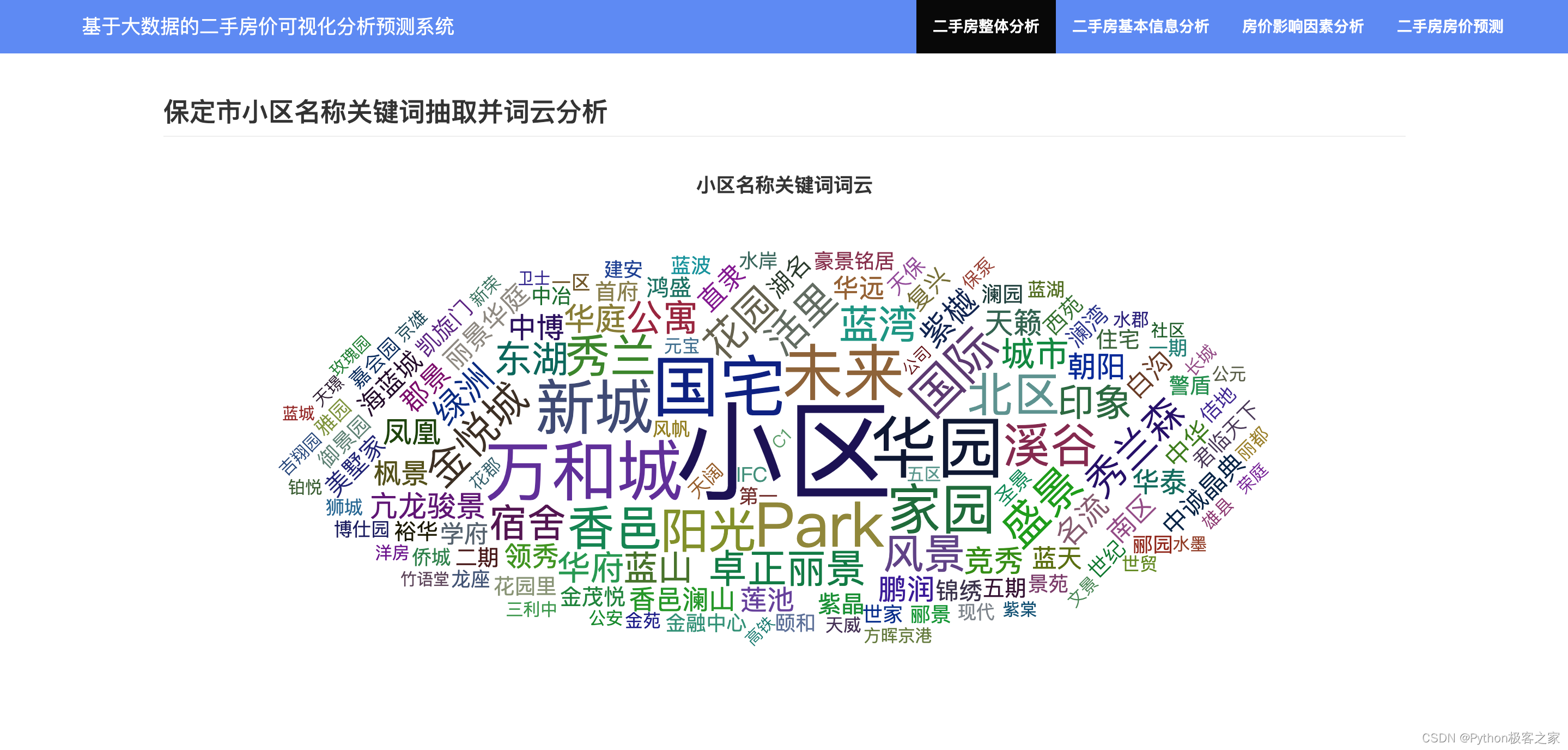
4.2 小区楼盘名称关键词抽取与词云展示
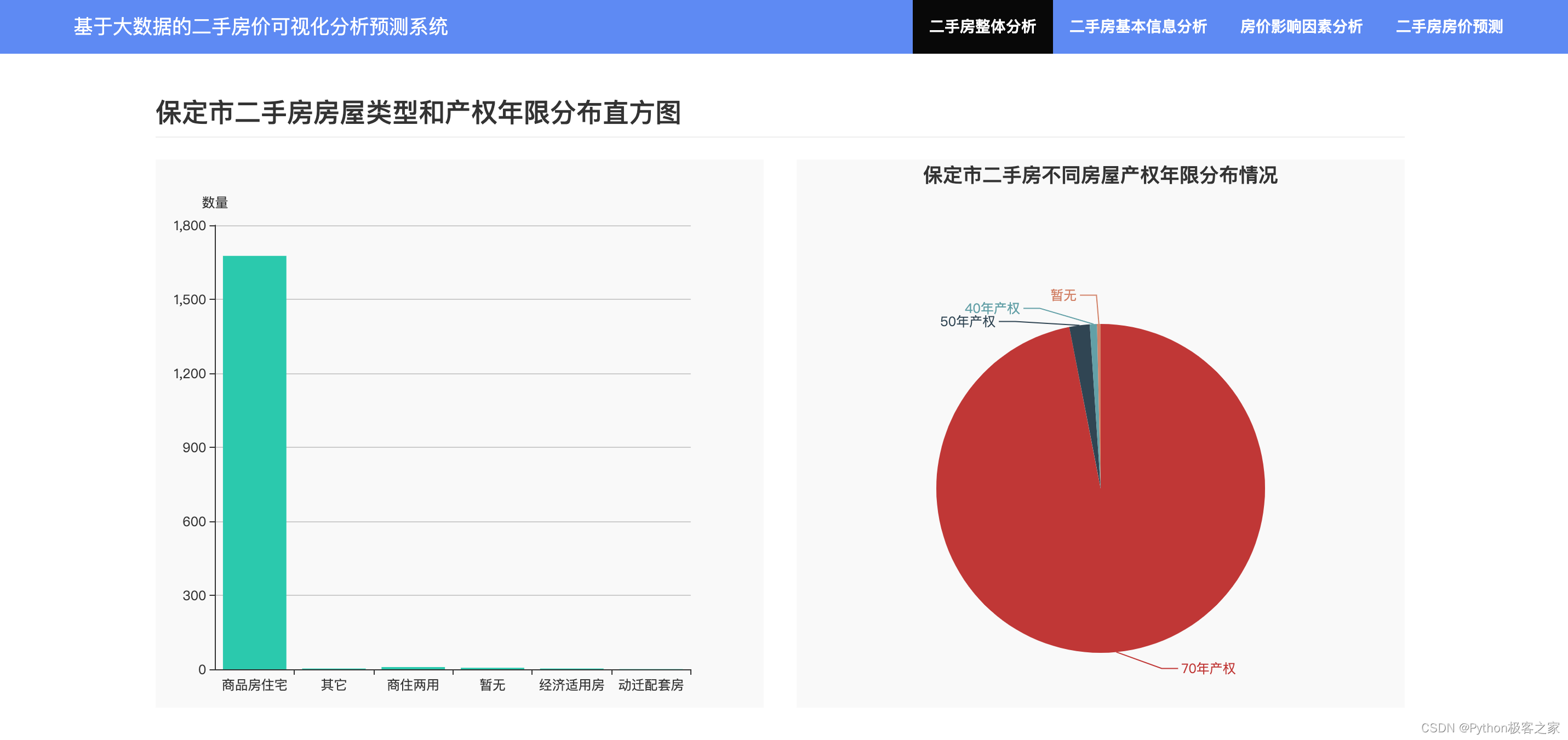
4.3 二手房房屋类型与产权年限分布
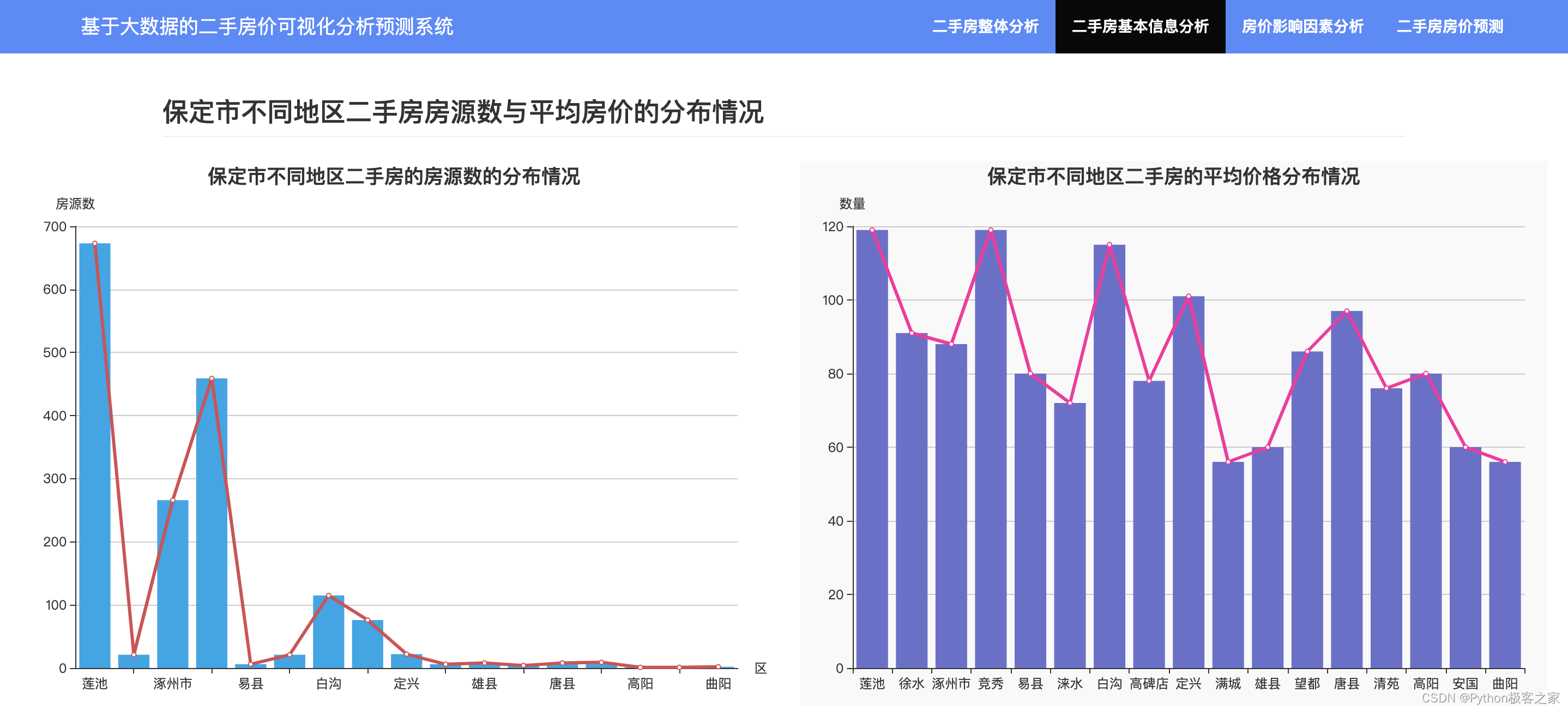
4.4 不同区域在售二手房房源数量与均价对比
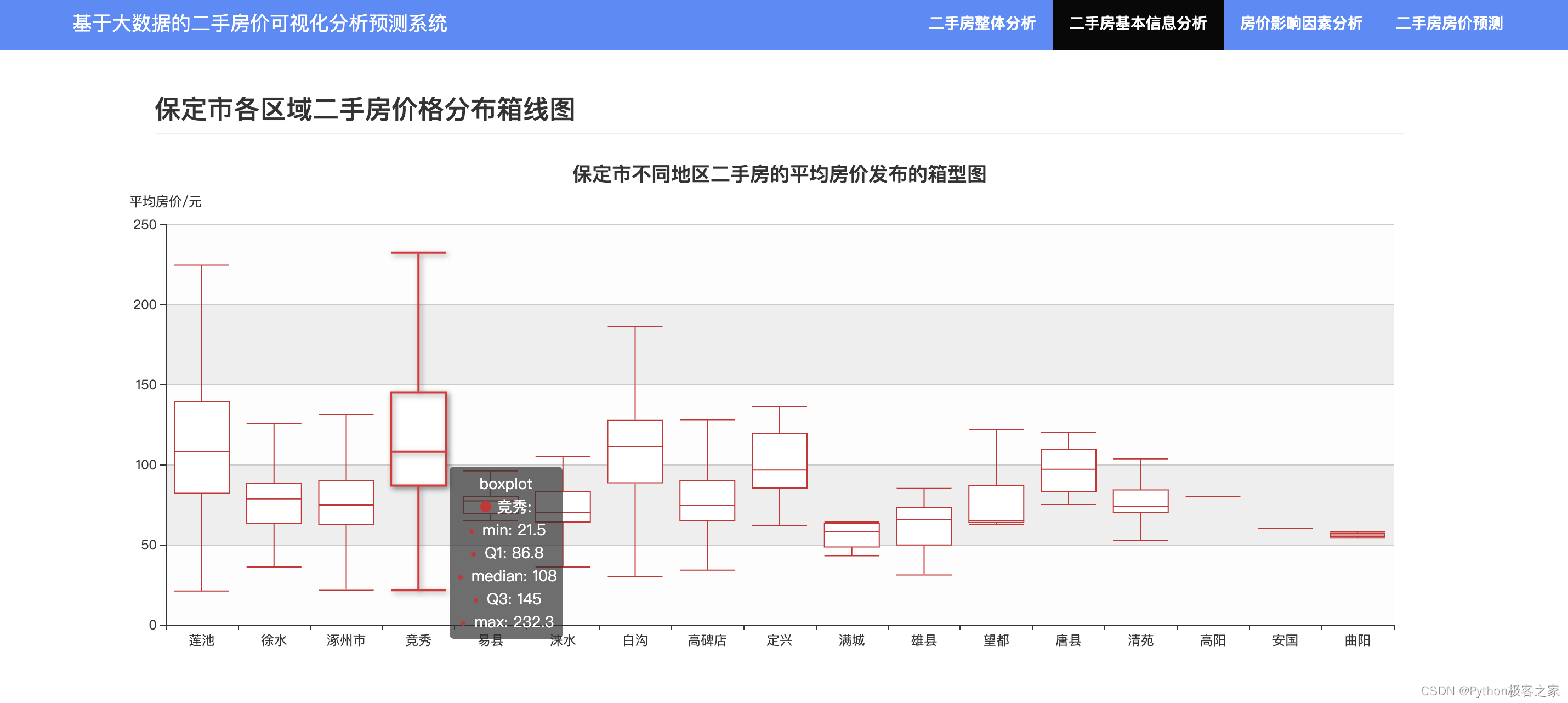
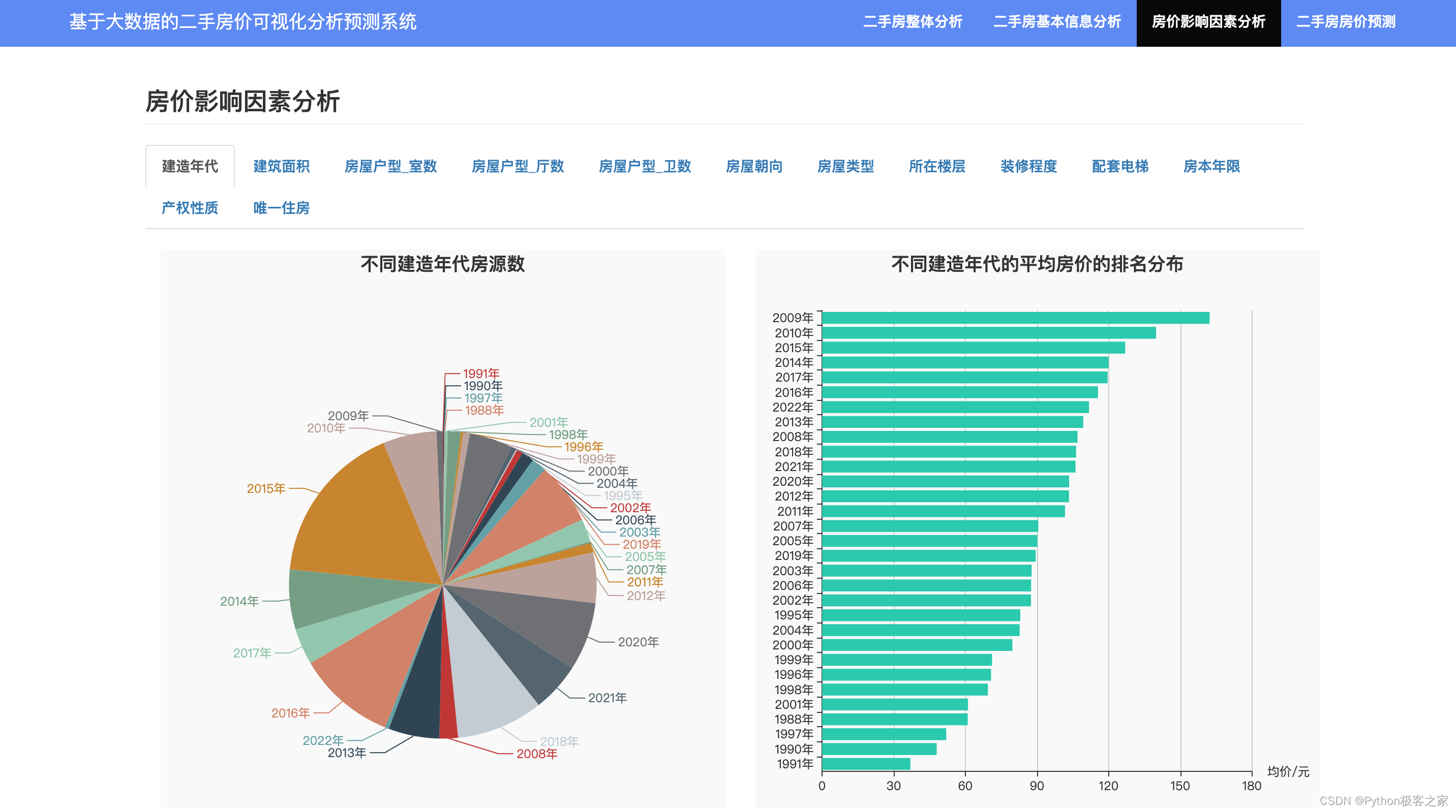
4.5 房价影响因素分析
房价影响因素包括:建造年代、建筑面积、房屋户型、朝向、房屋类型、楼层、装修程度、配套电梯、房本年限、产权性质、唯一住房、所在区域、周边设施等等诸多因素。我们对每类因素的影响情况分别进行可视化展示:
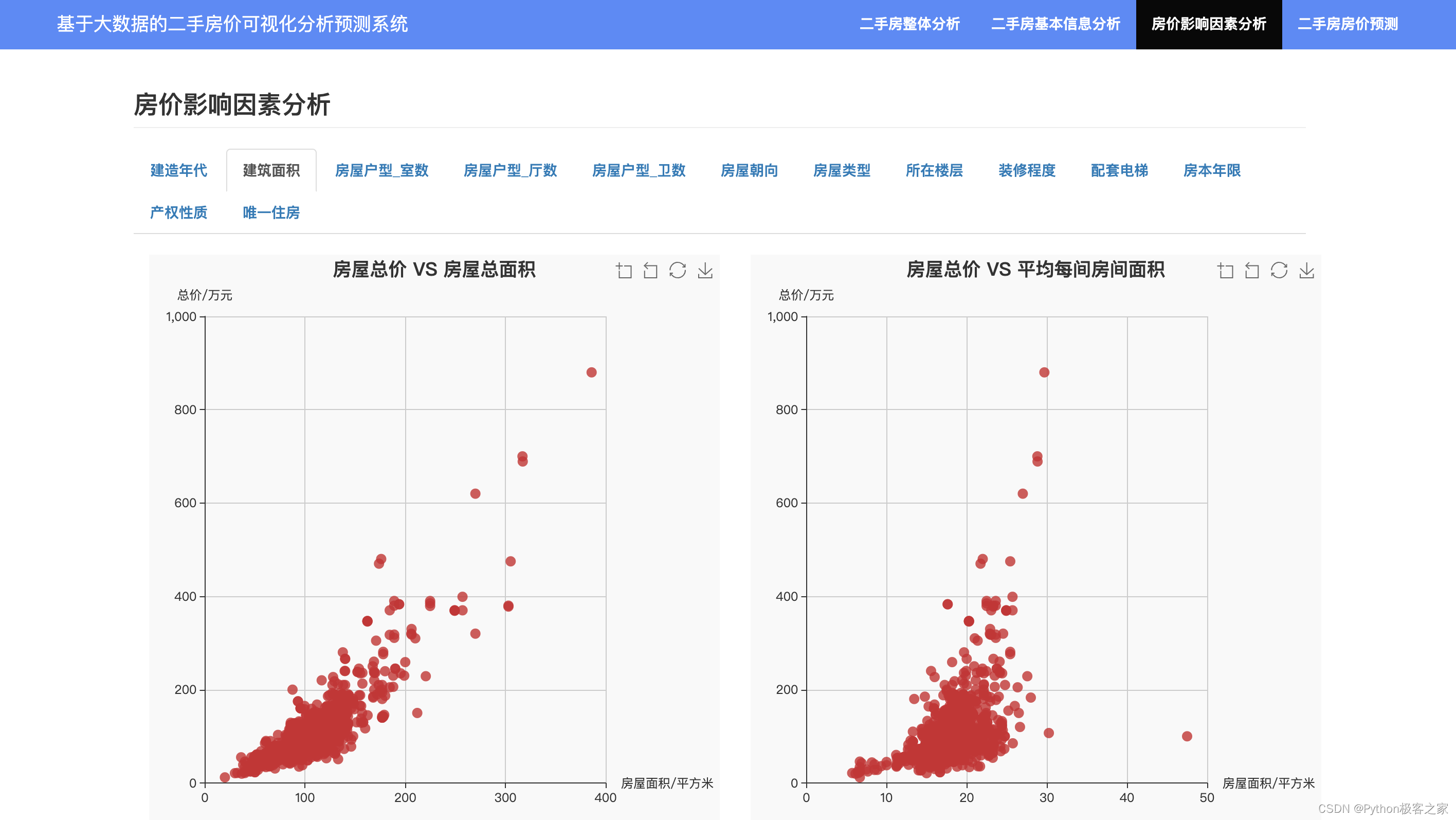
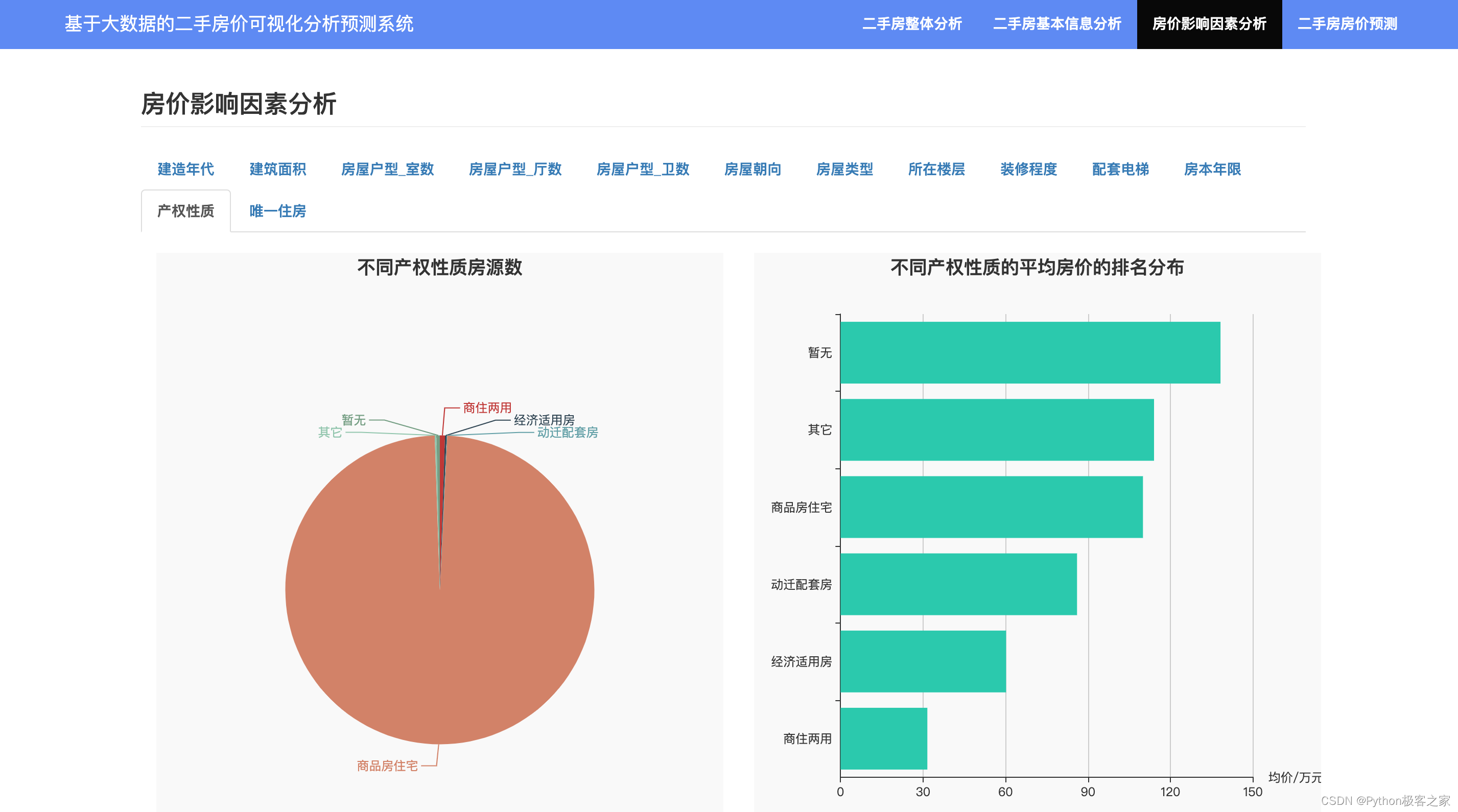
4.6 基于机器学习模型的二手房价格预测
通过一些列的特征工程、数据标准化、训练集验证集构造、决策树模型构建等操作,完成决策树模型的交叉验证训练和模型评估:
print('---> cv train to choose best_num_boost_round')dtrain = xgb.DMatrix(train_X, label=train_Y, feature_names=df_columns)xgb_params = { 'learning_rate': 0.005, 'n_estimators': 4000, 'max_depth': 3, 'min_child_weight': 1.5, 'eval_metric': 'rmse', 'objective': 'reg:linear', 'nthread': -1, 'silent': 1, 'booster': 'gbtree'}cv_result = xgb.cv(dict(xgb_params), dtrain, num_boost_round=4000, early_stopping_rounds=100, verbose_eval=400, show_stdv=False, )best_num_boost_rounds = len(cv_result)mean_train_logloss = cv_result.loc[best_num_boost_rounds-11 : best_num_boost_rounds-1, 'train-rmse-mean'].mean()mean_test_logloss = cv_result.loc[best_num_boost_rounds-11 : best_num_boost_rounds-1, 'test-rmse-mean'].mean()print('best_num_boost_rounds = {}'.format(best_num_boost_rounds))print('mean_train_rmse = {:.7f} , mean_valid_rmse = {:.7f}\n'.format(mean_train_logloss, mean_test_logloss))模型训练结果:
---> cv train to choose best_num_boost_round[0]train-rmse:4.10205test-rmse:4.10205[400]train-rmse:0.59919test-rmse:0.605451[800]train-rmse:0.20857test-rmse:0.230669[1200]train-rmse:0.185981test-rmse:0.21354[1600]train-rmse:0.181188test-rmse:0.211841[2000]train-rmse:0.177933test-rmse:0.211291[2400]train-rmse:0.174346test-rmse:0.210886best_num_boost_rounds = 2512mean_train_rmse = 0.1733781 , mean_valid_rmse = 0.2108875测试集预测结果与真实值分布情况:
print('决策树模型在验证集上的均方误差 RMSE 为:', rmse(valid_Y, predict_valid))>> 决策树模型在验证集上的均方误差 RMSE 为: 0.19991482173207226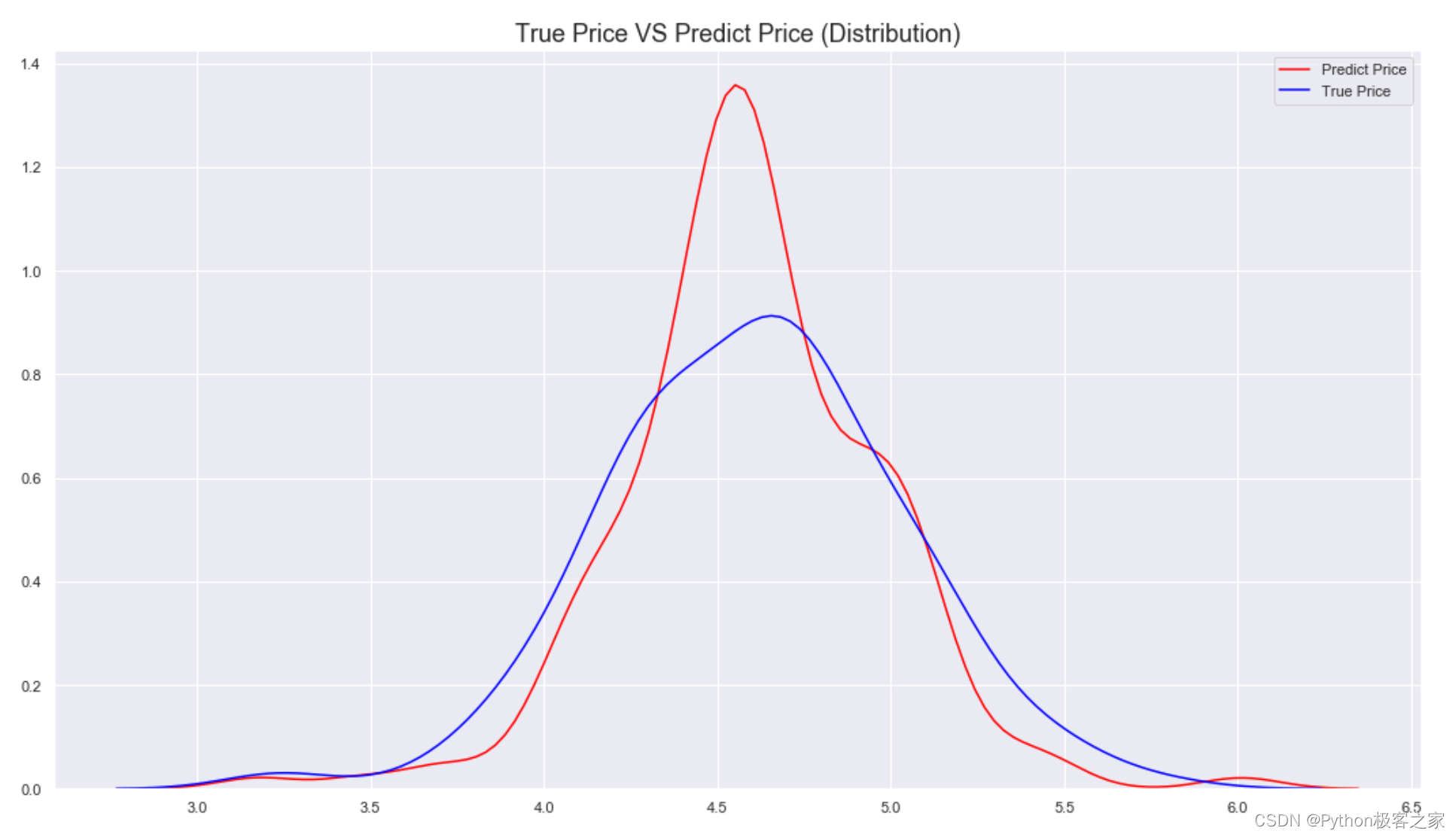
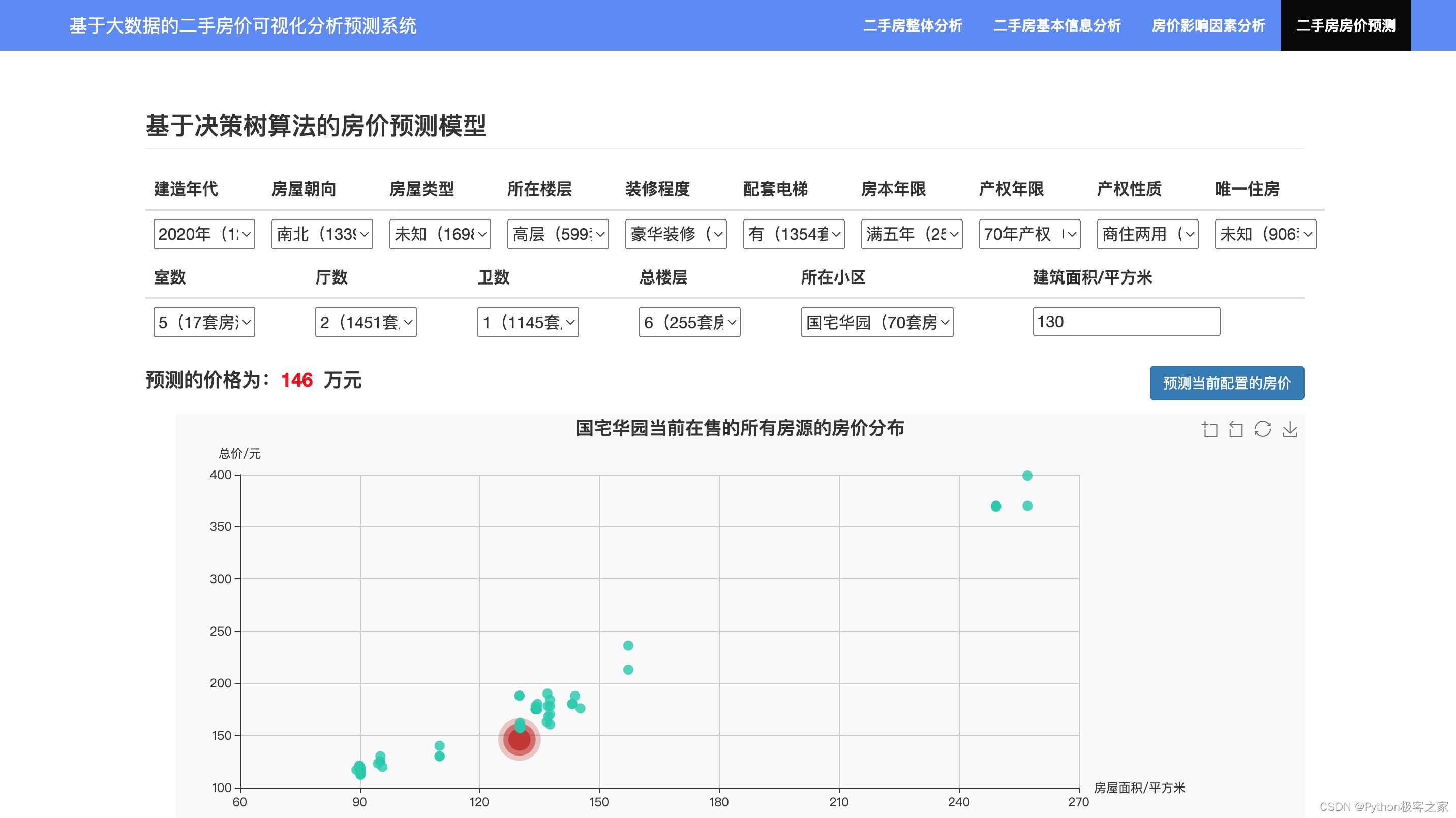
二手房价格预测模型交互式页面:
扫描下方作者 QQ 名片 


