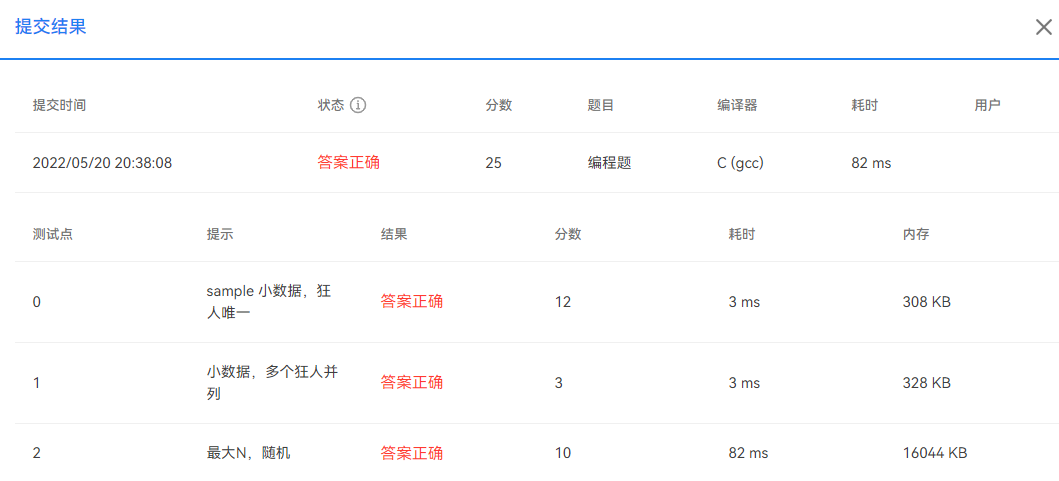
2.8 电话聊天狂人(散列,c)
电话聊天狂人
-
-
- 题意理解与解法分析
- 输入格式:
- 输出格式:
- 输入样例:
- 输出样例:
- 程序框架搭建
- 输出狂人
- 模板的引用与裁剪
-
- 查找
- 插入函数
- 代码
-
- 运行
-
原题直达:11-散列1 电话聊天狂人
题意理解与解法分析

给定大量手机用户通话记录,找出其中通话次数最多的聊天狂人。
输入格式:
输入首先给出正整数N(≤105),为通话记录条数。随后N行,每行给出一条通话记录。简单起见,这里只列出拨出方和接收方的11位数字构成的手机号码,其中以空格分隔。
输出格式:
在一行中给出聊天狂人的手机号码及其通话次数,其间以空格分隔。如果这样的人不唯一,则输出狂人中最小的号码及其通话次数,并且附加给出并列狂人的人数。
输入样例:
413005711862 1358862583213505711862 1308862583213588625832 1808792583215005713862 13588625832输出样例:
13588625832 3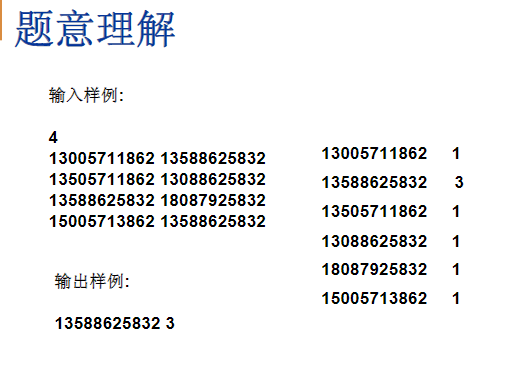
- 读入4,下面是4条通话记录
- 每个通话记录两个号码,一个播出的电话号码,一个是接电话的电话号码。
- 从这些号码里统计以下,哪个号码的人打电话或者接电话的总次数是最多的,那么这个人就叫做电话聊天狂人,那么就输入样例而言,我们可以有一个非常简单的做法,就是把电话号码一个一个读进来,当我遇到第一个号码的时候,这是一个新号码,那么他出现的次数是1,然后读到第二个号码的时候,他也是一个新号码,出现的次数是1,读到第三个号码发现也是新的,读到第四个也是新的,第五个看上去有点眼熟,他在这里出现过,如何知道他出现过呢,事实上在读每一条号码的时候,我好像都跑到前面去找了以下,而且这个是出现过的,那么次数就+1,然后下个号码又是新的,没有被180打头的,下一个又是新的,没有被150打头的,下一个又是出现过的,就说聊天狂人是这个号码,我们就输出这个号码以及他通话的次数3,要解决这个问题有好多方法,最简单直白的方法就是排序

- 通话最大条数N是10的5次方,那么在每一条记录里面,我们有两个电话号码,所以我们最多就是者么多个电话号码,然后每个号码存成一个长度为11的字符串,因为我们是11位的电话号码,接下来就是直接把这个字符串按照一个非递减的顺序来做一个排序,排好序以后重复出现过的电话号码,肯定都排在一起的,那我就从头到尾的去扫描这个有序的数组,如果是相同号码的话他一定是连续出现的,连续出现的号码就去统计一下他们出现的次数,当然我们还需要一个变量去记录那个最大的次数,碰到一个更大的,就去更新这个最大次数

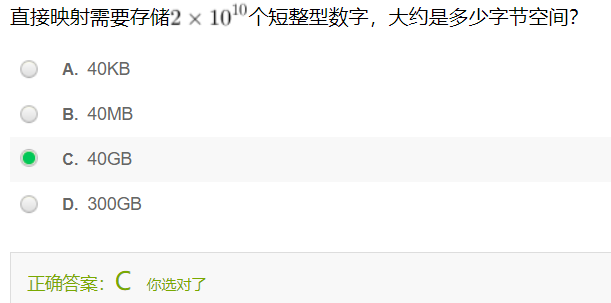
- 为每一个电话号码创建一个整数计数器,也就是说创建了一个有2x10的10次方个单元的整数数组,为什么是2乘以10的10次方个单元(乘2是因为一个记录有两组号码)?因为电话号码有11位,目前为止电话号码的第一位都是1,最大的好像是18几,所以取一个2x10的10次方,下标肯定是充分大了,那保证每个电话号码对应唯一的一个单元的下标,我们把这个数组初始化为0,那对读入的每一个电话号码,我们就可以去找以这个号码为下标的这个单元,把他这个计数器累计1次,当所有数据结束的时候,就顺序扫描这个数组,来找出计数器计数次数最多的单元,他对应的那个下标就是那个电话号码,
短整型即short型,一个占两个字节。
1KB = 1024B,1024KB = 1MB = 1048576B
2*2*10^10B ≈ 40 * 1024 * 1024 * 1024B = 40GB
选C。- 为了找2x10的5次方个号码,扫描2x10的10次方个单元,多花了10的5次方倍的时间,这个10的5次方倍就是另外一个NlogN
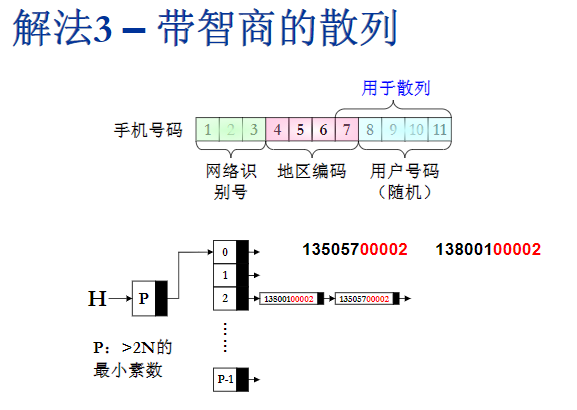
- 首先手机号码的前三位,一共就那么几种,不适合作为散列函数一部分来考虑,加入的话可能把大量数据映射到这几个区域里面,网洛识别号的后面四位,在最早的时候他是地区编码,比如杭州就是0571,现在他已经不完全是地区编码了,但仍有很大可能,所有的手机号都被映射到同一个地方,所以这一块也是不好的,随机性最好的是最后四位,是真正的用户号码,他是随机产生的,但在我们的问题里面,手机号码的数量级是10的5次方,那如果我们只用最后四位的话,扩散开来的那个效果可能还是不太好,所以一个比较合适的办法就是把手机号码的最后5位,用在这个散列函数里面
- 散列表如何设计?可以用数组,也可以用链表,在这里推荐用分离链接法,首先散列表的头存了散列表的长度,他的长度一般来说取一个素数P,那这个P应该是怎么取法呢?他应该是一个大于2n的一个最小素数,因为最多有2n个不同的电话号码,所以这个散列表的头节点的个数应该比2n略大一点
- 在建立好这些头节点之后,比如说第一个号码读进来,我们就去考虑他的后5位,就这个例子来说后5位是2,我们直接用除留余数法,不管去模哪个素数P,最后的余数肯定都是2了,所以这个电话号码会被映射到下标为2的这个链表里,因为当前这个链表是空,所以直接把他插到这个链表的表头里面,那下一个电话号码如果他的后5位也正好冲突了,也是2的话,那么他也被映射到同一个链表里,那我们就把新来的这个电话号码,插到这个链表的表头,那如果下一次又是这个电话号码出现的时候,会发生这个号码会再次的被映射到这个链表里,那我们首先会扫描这个链表,看看能不能找到这个号码,如果找到了这个号码,那我们就要在这个号码对应的这个结点计数器上面+1,如果找了一圈,发现链表上没有这个号码,那么这个新的号码就会被插到这个链表的表头里,我们希望的是冲突的次数不会太多,所以每一个链表的表长不对太长,所以整体的效率应该是线性的,就是O(N)这个数量级的
程序框架搭建

题目要求,不只有一个狂人的话,输出鲜花最小的狂人,所以当最大通话次数相等的情况下,要更新最小的号码
输出狂人

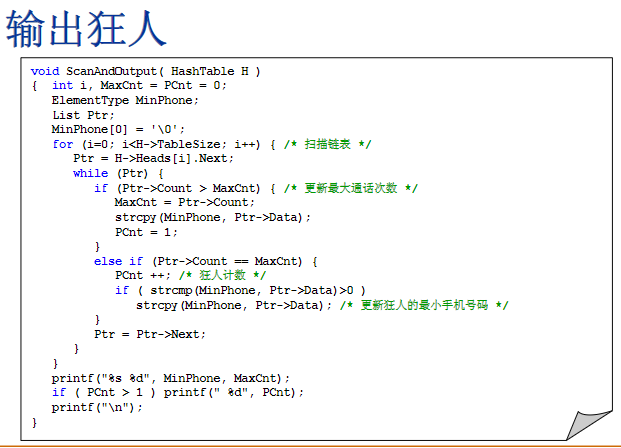
- 如果PCnt这个狂人的数大于1的话,最后还要我们把这个统计数据输出来,如果PCnt等于1的话,那就没必要了,因为只有一个狂人,只输出这两个数据就可以了
- 什么时候狂人不唯一呢?
指针指向当前节点的这个通话次数和现在的最大通话次数是相等的,也就是说我们又发现一个并列的狂人,当发现一个并列狂人的时候,这个PCnt++,这个狂人就统计在内,同时,当有很多狂人并列的时候,只能输出最小的电话号码,于是我们要做一个strcmp比较一下当前最小的电话号码和你现在的这个狂人的电话号码,如果strcmp返回来的数是大于0的,那就意味着后者是更小号码,就把更小的号码复制到这个最小号码的字符串里面去,也就是更新狂人的最小手机号码

模板的引用与裁剪
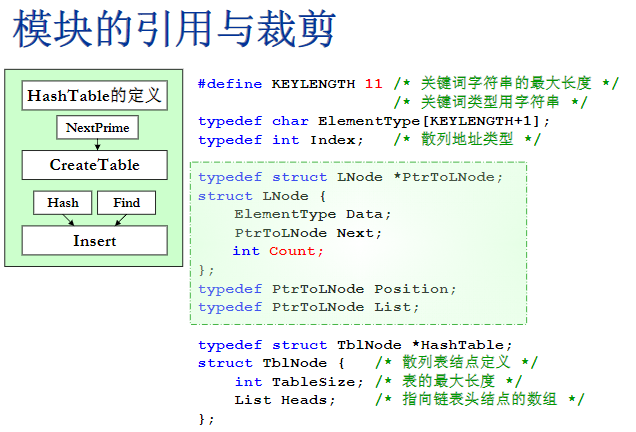
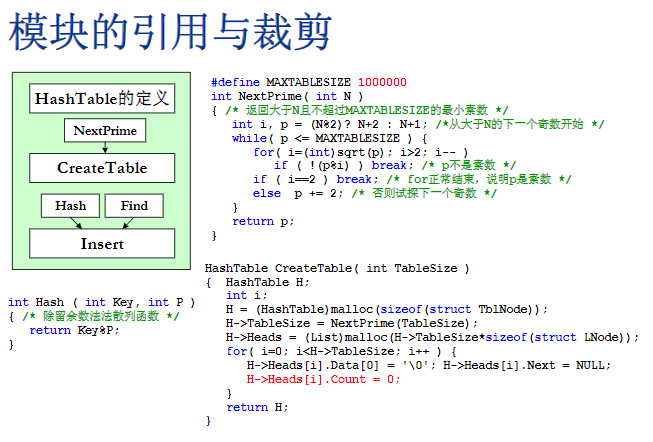
- 不写下面红色的一行也是没关系的,头节点反正是一个空结点,这个count本来就没有什么意义,但是写这一行代表一个好的习惯,就是说这个结点里的所有变量都要有一个初始化的值,不能有一个是空的,不知道是什么
- hash的参数key应该是一个整数,是截出来的后5位,不是直接把11位号码传进来
查找
- 修改前

我们传进去之前,要先把他的后5位截出来变成一个整数,如下图红色部分

- 修改后

多了一个宏定义
插入函数
- 修改前

- 修改后

把Key传进Hash之前,把它的后5位截出来变成一个整数,调用atoi函数,把一个字符串转换成一个整数,Key指向的是这个电话号码的第一位,再往右错位整个的11位,再从后往前数MAXD即5位,从那个地方开始,把后面的字符串传给atoi转换为一个整数,再把这个整数传给散列函数去计算
代码
#include #include #include #include #include #define KEYLENGTH 11 /*关键词字符串的最大长度*/#define MAXTABLESIZE 1000000#define MAXD 5 /*参与散列映射计算的字符个数*/typedef char ElementType[KEYLENGTH + 1]; /*关键词类型用字符串*/typedef int Index; //散列地址类型typedef struct LNode *PtrToLNode;struct LNode {ElementType Data;PtrToLNode Next;int Count;};typedef PtrToLNode Position;typedef PtrToLNode List;typedef struct TblNode *HashTable;struct TblNode { /*散列表结点定义*/int TableSize; /*表的最大长度*/List Heads; /*指向链表头结点的数组*/};void ScanAndOutput(HashTable H){int i, MaxCnt = 0;int PCnt = 0;ElementType MinPhone;List Ptr;MinPhone[0] = '\0';for (i = 0; i < H->TableSize; i++) /*扫描链表*/{Ptr = H->Heads[i].Next;while (Ptr){if (Ptr->Count > MaxCnt) { /*更新最大通话次数*/MaxCnt = Ptr->Count;strcpy(MinPhone, Ptr->Data);PCnt = 1;}else if (Ptr->Count == MaxCnt) {PCnt++; /*狂人计数*/if (strcmp(MinPhone, Ptr->Data) > 0) {strcpy(MinPhone, Ptr->Data);/*更新狂人的最小手机号码*/}}Ptr = Ptr->Next;}}printf("%s %d", MinPhone, MaxCnt);if (PCnt > 1) printf(" %d", PCnt);printf("\n");}int Hash(int Key, int P){ /*除留余数法散列函数*/return Key % P;}int NextPrime(int N){/*返回大于N且不超过MAXTABLESIZE的最小素数*/int i, p = (N % 2) ? N + 2 : N + 1; /*从大于N的下一个奇数开始*/while (p <= MAXTABLESIZE) {for (i = (int)sqrt(p); i > 2; i--){if (!(p%i)) break; /*p不是素数*/}if (i == 2) break; /*for正常结束,说明p是素数*/else p += 2; /*否则试探下一个奇数*/}return p;}HashTable CreateTable(int TableSize){HashTable H;int i;H = (HashTable)malloc(sizeof(struct TblNode));H->TableSize = NextPrime(TableSize);H->Heads = (List)malloc(H->TableSize * sizeof(struct LNode));for (i = 0; i < H->TableSize; i++) {H->Heads[i].Data[0] = '\0';H->Heads[i].Next = NULL;H->Heads[i].Count = 0;}return H;}Position Find(HashTable H, ElementType Key){Position P;Index Pos;/*初始散列位置*/Pos = Hash(atoi(Key + KEYLENGTH - MAXD), H->TableSize);P = H->Heads[Pos].Next;/*从该链表的第1个结点开始*//*当未到表尾,并且Key未找到时*/while (P && strcmp(P->Data, Key))P = P->Next;return P; /*此时p或者指向找到的结点,或者为NULL*/}bool Insert(HashTable H, ElementType Key){Position P, NewCell;Index Pos;P = Find(H, Key);if (!P) { /*关键词未找到,可以插入*/NewCell = (Position)malloc(sizeof(struct LNode));strcpy(NewCell->Data, Key);/*初始散列位置*/NewCell->Count = 1;Pos = Hash(atoi(Key + KEYLENGTH - MAXD), H->TableSize);/*将NewCell插入为H->Heads[Pos]链表的第1个结点*/NewCell->Next = H->Heads[Pos].Next;H->Heads[Pos].Next = NewCell;return true;}else {/*关键词已存在*/P->Count++;return false;}}void DestroyTable(HashTable H){int i;Position P, Tmp;/* 释放每个链表的结点 */for (i = 0; i < H->TableSize; i++) {P = H->Heads[i].Next;while (P) {Tmp = P->Next;free(P);P = Tmp;}}free(H->Heads); /* 释放头结点数组 */free(H); /* 释放散列表结点 */}int main(){int i, N;ElementType Key;HashTable H;scanf("%d", &N);H = CreateTable(N * 2); /*创建一个散列表*/for (i = 0; i < N; ++i){scanf("%s", Key); Insert(H, Key);scanf("%s", Key); Insert(H, Key);}ScanAndOutput(H);DestroyTable(H);return 0;}运行
413005711862 1358862583213505711862 1308862583213588625832 1808792583215005713862 1358862583213588625832 3