【推荐系统】基于文本挖掘的推荐模型【含基于CNN的文本挖掘、python代码】
【推荐系统】基于文本挖掘的推荐模型【含基于CNN的文本挖掘】
- 一、实现的主要原理及思路
- 二、 结果与分析
-
- 1. 基于CNN的评论文本挖掘
- 2. 基于文本挖掘的推荐模型-评分预测
- 三、总结
基于文本挖掘的推荐模型 – 了解基于文本评论的推荐模型,实现评分预测
一、实现的主要原理及思路
1. 深度神经网络
关于神经网络更详细介绍可以看此篇【深度学习】含神经网络、CNN、RNN推理
1.1神经网络原理

1.2神经网络的表示

1.3示例
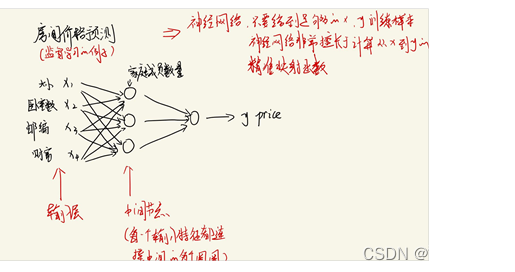
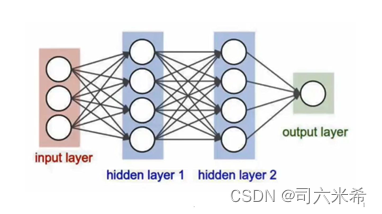
1.4深度神经网络(Deep Neural Networks,DNN)
DNN则是指包含多个隐层的神经网络
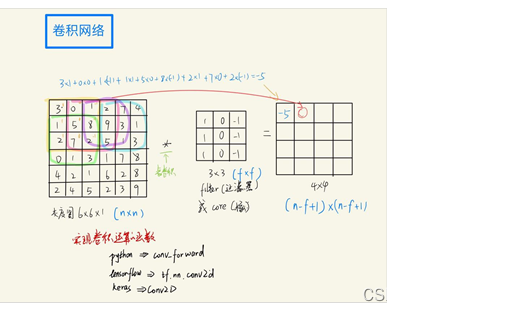
2. 卷积网络(Convolutional Neural Networks, CNN)处理文本评价的方式
2.1图像 应用 卷积网络
二维卷积网络是通过将卷积核在二维矩阵中,分别从width和height两个方向进行滑动窗口操作,且对应位置进行相乘求和。而图像则正是拥有二维特征像素图,所以图像应用卷积网络是二维卷积网络。
2.2文本挖掘 应用 卷积神经网络
当文本由一系列单词组成,eg:hello world, I like you.是一个一维的单词序列,卷不起来。所以此时应将卷积网络的思想运用到文本挖掘中,则需要考虑到单词的表征。如下图👇cat延申出是否是动词,是否是人类等等一系列表征,便变成二维进行卷积。但需要注意的是,将卷积核在二维矩阵中,只能从width和height两个方向进行滑动窗口操作(即卷积要包括一个单词的所有表征),且对应位置进行相乘求和。放在下图中也就是只能上下进行卷积。

3. 基于CNN的评论文本挖掘
3.1数据预处理
原始数据👇【由于原数据集2125056万条过大,为方便调试后续代码,实现整个过程,所以数据集仅选取其中一部分,训练集大小为425001*1】
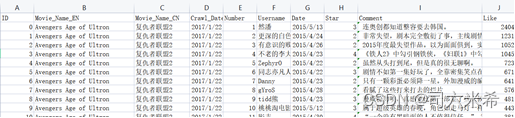
提取出我们所需要的评分以及评论文本,并将两者组成列表👇

利用jieba包,构建分词函数,从而得到分好词的评论。👇【下图为拿一个评论进行分词尝试,并存为列表】

有了词以后我们需要针对单词进行向量化,也就是上面 2.2文本挖掘 应用 卷积神经网络中的图的数据获取,而这里使用了包word2vec(word2vec是一种将单词转换为向量形式的工具。用于将文本的处理的问题简化为向量空间中的向量运算,通过计算向量空间上的距离来表示文本语义上的相似度),而word2vec实现原理是它将词表中所有的词进行统一编码,每个词在向量中占为1(让向量中只有一个维度为1),eg:“开心”=[0000001000000……],然后根据每个词的上下文进行训练,从而判断两个词之间的相似性👇
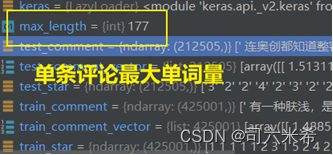
为了统一卷积的输入,计算每条评论的最长单词数,然后将所有评论单词数量进行扩充至最长单词数👇
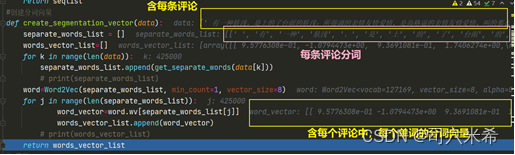
数据预处理部分函数👇
import pandas as pdimport numpy as npimport jiebaimport gensimimport tqdmfrom tensorflow import kerasfrom tensorflow.keras import layersfrom tensorflow.keras import modelsimport randomfrom gensim.models import Word2Vecdef data_processing(): array = pd.read_csv(" ", header=None) np_array = np.array(array) mid=round(len(np_array)/1000) print(mid) print(999 * (mid + 1)) test_star=np_array[1:mid,7] train_star=np_array[999*(mid+1):,7] train_star = keras.utils.to_categorical( train_star, num_classes=10) test_star = keras.utils.to_categorical( test_star, num_classes=10) test_comment=np_array[1:mid,8] train_comment=np_array[999*(mid+1):,8] return test_comment,test_star,train_comment,train_star#分词def get_separate_words(data): seqlist=jieba.cut(data,cut_all = False) seqlist=list(seqlist) seqlist= seqlist + [0] * (177 - len(seqlist)) # print(list(seqlist)) # print(','.join(seqlist)) return seqlist#创建分词向量def create_segmentation_vector(data): separate_words_list = [] words_vector_list=[] # max=0 for k in range(len(data)): separate_words_list.append(get_separate_words(data[k])) # if len(get_separate_words(data[k]))>max: # max=len(get_separate_words(data[k])) # print(separate_words_list) word=Word2Vec(separate_words_list, min_count=1, vector_size=8) for j in range(len(separate_words_list)): k=word.wv[separate_words_list[j]] op=[] for t1 in k: tem=[] for t2 in t1: tem.append(float(t2)) op.append((tem.copy())) word_vector=op words_vector_list.append([word_vector]) # print(words_vector_list) return words_vector_list,max3.2CNN
利用tensorflow的keras进行构建模型,模型细则👇
# 模型def cnn(X_train,Y_train,X_test,Y_test): X_train = np.array(X_train) X_train = X_train.reshape(X_train.shape[0], 177, 8, 1) Y_train = np.array(Y_train) Y_test= np.array(Y_test) X_test = np.array(X_test) X_test= X_test.reshape(X_test.shape[0], 177, 8, 1) print('开始卷积') # 定义模型Sequential 序贯模型。序贯模型是线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠 model = models.Sequential() # # 向模型中添加层 # 【Conv2D】 # 构建卷积层。用于从输入的高维数组中提取特征。卷积层的每个过滤器就是一个特征映射,用于提取某一个特征, # 过滤器的数量决定了卷积层输出特征个数,或者输出深度。 # 因此,图片等高维数据每经过一个卷积层,深度都会增加,并且等于过滤器的数量 model.add(layers.Conv2D(1, kernel_size=(8,8), # 添加卷积层,深度1,过滤器大小8*8activation='relu', # 使用relu激活函数input_shape=(177,8,1))) # 输入的尺寸 model.add(layers.MaxPooling2D(pool_size=(170, 1))) # 添加池化层,过滤器大小是170*1 model.add(layers.Conv2D(64, (1,1), activation='relu')) # 添加卷积层 model.add(layers.MaxPooling2D(pool_size=(1, 1))) # 添加池化层 model.add(layers.Flatten()) # 将池化层的输出拉直,然后作为全连接层的输入 model.add(layers.Dense(500, activation='relu')) # 添加有500个结点的全连接层,激活函数用relu model.add(layers.Dense(10, activation='softmax')) # 输出最终结果,有10个,激活函数用softmax # 定义损失函数、优化函数、评测方法 # model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准 # model.compile(optimizer = 优化器,loss = 损失函数,metrics = ["准确率”]) # 多分类损失函数categorical_crossentropy # 优化器采用SGD随机梯度下降算法 model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy']) # 自动完成模型的训练过程 # model.fit()方法用于执行训练过程 # model.fit( 训练集的输入特征,训练集的标签, # batch_size, #每一个batch的大小 # epochs, #迭代次数 # validation_data = (测试集的输入特征,测试集的标签), # validation_split = 从测试集中划分多少比例给训练集, # validation_freq = 测试的epoch间隔数) model.fit(X_train, Y_train, # 训练集batch_size=128, # batchsizeepochs=3, # 训练轮数validation_data=(X_test, Y_test)) # 验证集 score = model.evaluate(X_test, Y_test) print('Test loss:', score[0]) print('Test accuracy:', score[1]) customization_good = np.array(['这是一个非常好电影']) k=create_segmentation_vector(customization_good) k = np.array(k[0]) k = k.reshape(k.shape[0], 177, 8, 1) predict1 = model.predict(k) # print(predict1) print('评论:这是一个非常好电影\n评分为') print(np.argmax(predict1)) customization_bad=['这是差劲烂片'] k = create_segmentation_vector(customization_bad) k = np.array(k[0]) k = k.reshape(k.shape[0], 177, 8, 1) predict2 = model.predict(k) print('评论:这是差劲烂片\n评分为') print(np.argmax(predict2))损失函数采用多分类损失函数categorical_crossentropy
优化器采用SGD随机梯度下降算法
注意:为了符合上述模型数据类型要求,需要在数据预处理处进行严格的类型转换
关于CNN的其它实例练习可见此篇基于MNIST手写体数字识别–含可直接使用代码【Python+Tensorflow+CNN+Keras】
4.基于文本挖掘的推荐模型
将自定义单条评论进行单词分量,预测,取预测结果元素最大值所对应的索引即为预测评分
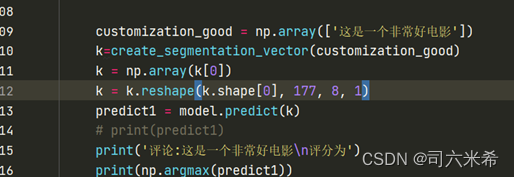
二、 结果与分析
1. 基于CNN的评论文本挖掘
结果👇
【20316份训练集,2125份测试集,训练迭代3次,测试loss约为2.246,测试准确率为0.08】

【21108份训练集,21251份测试集,训练迭代10次,测试loss约为1.96,测试准确率为0.108】👇
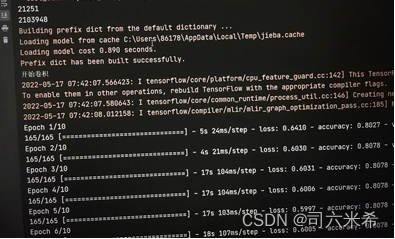
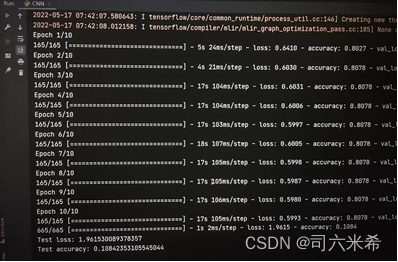
当我的测试集以及训练迭代次数增加时,测试的loss减少,准确率提高
【212466份训练集,42501份测试集,报错过大】
2. 基于文本挖掘的推荐模型-评分预测

三、总结
其实如果增大数据集训练量,准确率应该会更为理想,但是,当我尝试将训练集增到21万左右时,我的电脑跑了一晚上也没跑出来直接卡住。所以还是以学习整个流程,学会实现为主,不强求/(ㄒoㄒ)/~~柳暗花明又一村,不抛弃不放弃,它会跑起来的,要有坚定的信念感,去吧,皮卡丘

