MediaPipe模型解读 | MoveNet-SinglePose:自底向上做单人姿态估计
MoveNet是Google在2021年5月推出的一款轻量化姿态估计模型,集成在MediaPipe当中,出来至今已经一年多了,但是似乎相关的技术解读比较少,最近正好调研到仔细研究了一下感觉挺有意思的,所以更新一期解读。
0. 前言

说起业务落地级别的姿态估计算法方案,大家基本上的共识都是top-down范式,也就是det+pose的形式,先由一个轻量级的姿态估计模型提供bbox,再依次送入pose模型进行单人姿态估计,利用一些工程上的优化能抵消掉det模型的开销,基本上做到一整套流程的平均推理延迟约等于单个姿态估计模型推理的延迟。
而MoveNet则比较与众不同,它是一个bottom-up的模型,这种范式一般用在多人姿态估计中,而更特别的是,MoveNet是一个bottom-up的单人姿态估计模型。从MoveNet的技术博客分享中,我感受到Google在这方面的工程能力确实值得我们学习,它在两种范式之间取得了优秀的平衡,既避免了单独训练一个det模型,又尽量保留了单人姿态估计的精度优势。
由于这是一个商业落地模型,因此MoveNet并没有论文放出,但根据TensorFlow Blog给出的信息和一些网友的复现还是能看出个大概了,因此我们直接进入模型的部分。
1. 模型
Backbone
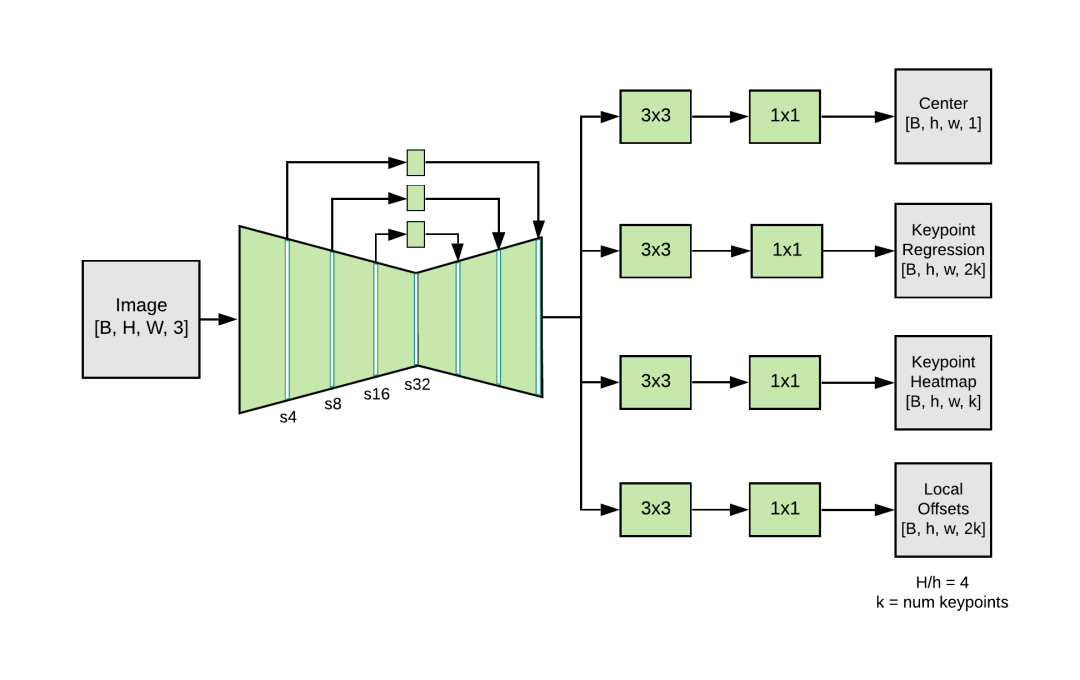
MoveNet整体的结构如上所示,Backbone部分是比较经典的带三层deconv的MobileNetv2,并且使用了残差连接来获取浅层特征,这个结构我已经在各种工程和学术论文中都见到了,比如Google自家业务上的BlazePose、BlazePalm,MIT的论文LitePose等,感觉这种结构在轻量化部署上基本是从各个角度得到了大家的认可。
从我个人的角度,我尝试总结一个优秀的轻量化姿态估计Backbone具有以下特点:
快速下采样:尽量快地压缩图片尺寸,降低整体的计算量
残差结构:获取浅层特征和梯度,一定程度上弥补快速下采样造成的一些问题(下采样太快信息损失太严重,模型来不及学出一些高级的有意义的语义特征),强化特征中的空间信息
参数集中在主干:在残差分支上的参数和计算量尽量少,把本来就比较可怜的算力全用在主干分支上
Neck
MoveNet比较特殊的设计主要在Neck和Head部分。
Neck部分使用了目标检测中常见的FPN,这主要因为MoveNet是一个Bottom-up模型。
对于Top-down模型而言,因为人为限定了画面中只有一个对象,因此该对象的各关键点不会出现太严重的尺度差异,基本上用同一个尺度下的特征图就能完成所有关键点的检测。
而对于Bottom-up模型而言,画面中有多个对象存在,难免有远近高低,因此不能只用一个尺度学到全部对象的可靠特征,因此需要用到FPN来做不同尺度的特征学习和融合。
Head
Head部分是最有意思的地方,它有四个预测头,分别是:
Center Heatmap[B, 1, H, W]:预测每个人的几何中心,主要用于存在性检测,用Heatmap上一个锚点来代替目标检测的bbox
Keypoint Regression[B, 2K, H, W]:基于中心点来回归17个关节点坐标值
Keypoint Heatmap[B, K, H, W]:每种类型的关键点使用一张Heatmap进行检测,这意味着多人场景下这张Heatmap中会出现多个高斯核
Offset Regression[B, 2K, H, W]:回归Keypoint Heatmap中各高斯核中心跟真实坐标的偏移值,用于消除Heatmap方法的量化误差,这在UDP中也有用到
第一时间看到这部分是不是有点蒙?没关系,接下来我会深入展开讲一下Head部分的处理。
2. 后处理
乍一看之下其实会觉得Head部分预测的信息是存在冗余的,比如Keypoint Regression和Keypoint Heatmap都是在预测每个关键点位置,最后我们该用哪个。我觉得这也是Google的这个工作有意思的地方。

对于四个头部预测的结果,会按照以下流程进行处理:
Step 1
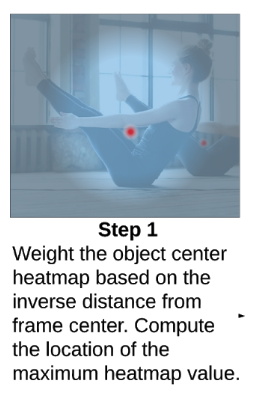
首先我们看到Center Heatmap,它的形状为[B, 1, H, W],预测的是每个人的几何中心。
说白了这个头部的作用是做目标检测,因为我们是一个人体姿态估计模型,我们所需要检测的目标类别是固定的,并且也不关心BBox这种东西,所以完全可以通过一个点来定位人。
这种做法在CenterNet等模型中就提出来了,通过为每个人渲染一个Gaussian Center来作为目标。
那么当画面中有多个人的时候,我们应该选用哪一个人呢?别忘了,我一开始就提高了MoveNet是一个单人姿态估计模型。
答案很简单,选距离画面中心最近的那个人。
但这里还有个小问题,当画面中有多个人的时候,预测的Center Heatmap也会有多个响应区域,我们如何才能拿到距离画面中心最近的那个高斯核的最大值点?
MoveNet的做法是通过反距离加权。
简单来说,对于画面中的每一个像素,我们都可以预先计算好一张权重Mask,每一个像素上的权重等于这个像素到画面中心的集合距离的倒数(严格来说是负幂),写成公式会是:
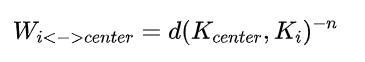
当n=1的时候权重就是倒数。
这张权重Mask是可以一开始计算好存起来的,并且不会发生变化,它的作用是对远离画面中心的像素进行抑制,用它对Center Heatmap加权,我们就可以把画面中其他人的响应值压低,从而使得离画面最近的人的最大值点可以通过Argmax拿到。
Step 2
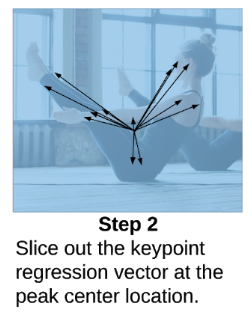
有了目标的几何中心后,接下来就要获取他的各个关键点了,直接在这个点位置上我们可以拿到Keypoint Regression的结果,它直接就是一个人的所有关键点的坐标。
Step 3
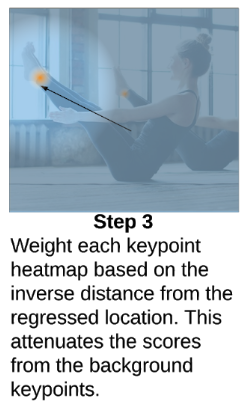
但这里有一个新的问题:画面中的人假如比较密集,我们的目标周围会有一些别的人的关键点被检测到,举个例子,可能在Center附近有三个鼻子,我们如何知道哪个鼻子是属于我们的目标呢?
做法其实跟第一步类似,同样是依靠加权,而权重Mask的生成则依赖于Keypoint Regression的结果。
根据经验我们知道,使用Keypoint Regression直接预测出来的关键点是比较不准的,如果用来作为预测结果肯定是不理想的,但是它可以作为一个粗略的结果,用来帮助我们确定哪些关键点是属于我们的目标的。
简单来说就是,我们假设距离Regression位置最近的那个高斯核是我们想要的。
用跟第一步一样的方法,我们可以通过Regression的坐标和全图的像素计算出一个权重Mask,用它来对Keypoint Heatmap加权,从而抑制掉其他距离较远的高斯核响应值,这样一来我们又可以通过Argmax拿到我们想要的那个Keypoint了。
Step 4
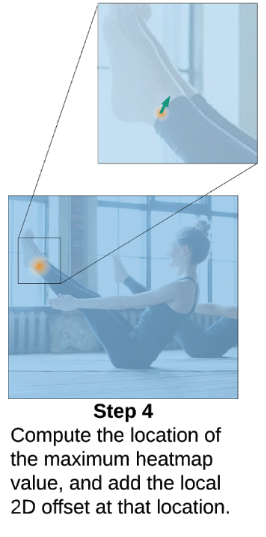
有了Keypoint后事情还没有结束,因为模型预测的Heatmap是比输入图片小的,存在量化误差,一般来说Heatmap的尺寸是输入图片的1/4,因此Heatmap上的像素对应到输入图片上的点是稀疏的,假如GT落在这些稀疏的点之间,我们是永远都预测不出来的。
所以,我们可以通过一个Offset Regression分支来预测Heatmap到GT点的偏移,从而消除量化误差。
这种方法在UDP种也进行了详细的介绍,感兴趣的小伙伴可以看我之前的文章:《姿态估计经典论文 | 无偏数据处理UDP:魔鬼藏在细节里》
https://zhuanlan.zhihu.com/p/541744841
经过这一整套流程后,MoveNet的Head预测的所有信息就都用上了,而且并没有任何的冗余。
3. 训练与优化
训练部分值得讲的东西就很少了,这里简单介绍一下。
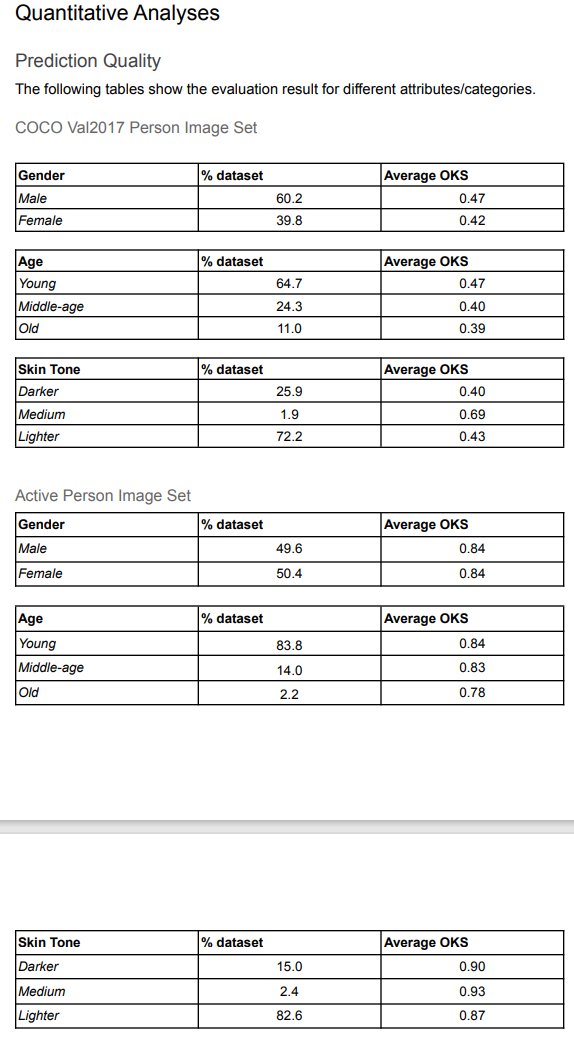
由于是一个商业模型,因此训练使用了Google的内部数据集,主要是针对一些比如瑜伽、运动健身的不常见姿态,当然也用到了开源数据集COCO,最后汇报的模型精度如下:
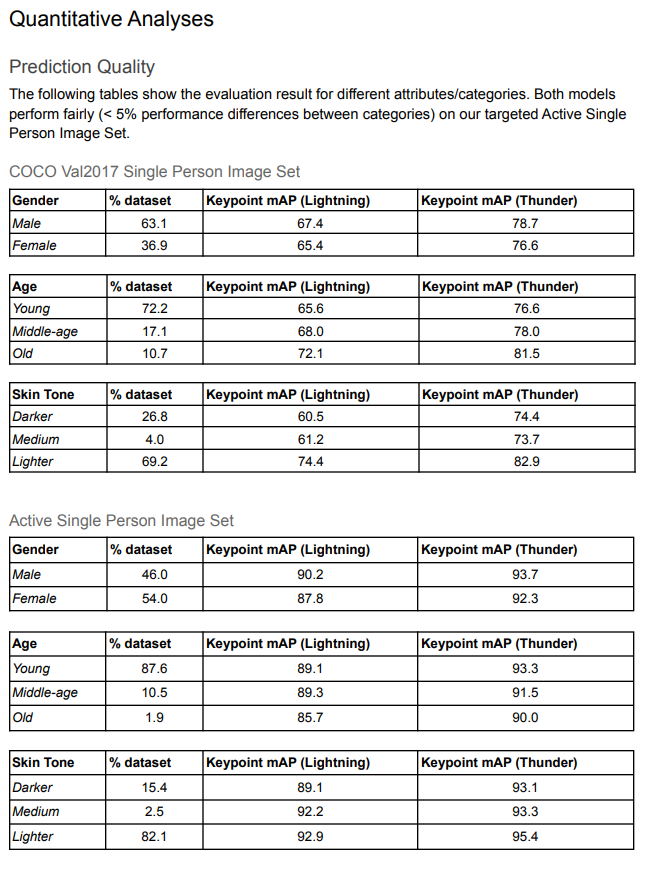
从结果来看Google对COCO中的数据进行了进一步清洗,因此这个精度应该没办法跟其他模型在COCO上汇报的结果直接比较,不过直观上还是可以看到整体结果是不错的,两个模型在男女上的精度加权平均值为AP 66.662(小模型192x192)和77.9251(中模型256x256),能跟Top-down模型掰掰手腕。
而在工程优化方面也做了很多常见的操作,比如调整MobileNetv2不同层的通道数,FPN上的结果也是直接Argmax简单粗暴而不是取Top_k,这些都能加速模型推理。
作为小模型,预测结果的抖动也是不可避免的,所以MediaPipe中使用了非线性滤波器来进行平滑。
4. 结语
以上就是MoveNet-SinglePose的全部内容了,后续Google也推出了多人姿态估计版本的MoveNet-MultiPose,但我看了之后感觉跟这一版的变动很大,而且没有太多新鲜的东西,精度上也不够理想,这里贴出来给大家仅供参考: