机器学习系列8 基于Python构建Web应用以使用机器学习模型
课前测验

本文所用数据及源码免费下载
目录
一、内容介绍
二、应用构建
1.构建机器学习Web应用的思考
①思考问题
②几种构建机器学习模型 Web 应用的方法。
2.工具安装
3.数据预处理
①数据加载及查看
②数据处理及特征选择
4.机器学习模型构建
①数据集划分
②调用逻辑回归模型训练多分类模型
5.“腌制”你的模型
6.配置Flask应用
①创建应用文件夹
②构建网页样式style.css文件
③构建Web界面内容index.html文件
④构建Python后端app.py文件
7.运行Flask应用
三、内容总结
🚀挑战
课后测验
一、内容介绍
在本文中,我将使用上世纪UFO目击事件数据集👽👽👽训练机器学习模型,并将其部署为Web应用。
你将学到:
0 如何“腌制”训练有素的模型
1 如何在 Flask 应用中使用该机器学习模型
我们继续使用Jupyter notebook来清理数据和训练我们的模型,当然你也可以使用已训练好的模型来直接进入Web模型部署阶段。
在模型部署中,我们需要使用 Flask框架构建一个 Web 应用程序。
二、应用构建
1.构建机器学习Web应用的思考
假如你正在一家企业中工作,其中数据科学部门训练了一个机器模型,他们希望你在应用中使用该模型,你该怎么做?
①思考问题
知道问题后,你该如何思考?思考什么?
0 它是Web应用程序还是移动应用程序?如果你正在构建移动应用程序或需要在物联网中使用模型,则可以使用TensorFlow Lite并在Android或iOS应用程序中使用该模型。
1 模型部署平台是什么?在云中还是在本地?
2 脱机支持。应用是否必须脱机工作?
3 使用什么技术来训练模型?所选技术可能会影响您需要使用的工具。
②几种构建机器学习模型 Web 应用的方法。
我们该用什么方法去构建机器学习Web应用呢?
0 使用 TensorFlow。其框架生态系统提供了使用 TensorFlow 转换用于Web 应用程序的 TensorFlow 模型的功能.js。
1 使用 PyTorch。此库可以选择将模型导出为 ONNX(开放神经网络交换)格式,以便在可以使用 Onnx Runtime的 JavaScript Web应用程序中使用。
2 使用 Lobe.ai 或 Azure 自定义视觉。如果使用 ML SaaS(软件即服务)系统(如 Lobe.ai 或Azure 自定义视觉)来训练模型,则此类软件提供了为许多平台导出模型的方法,包括生成要由联机应用程序在云中查询的定制 API。
对于初学者,我们可以使用Flask框架构建一个完整的 Flask Web 应用程序,该应用程序能够在 Web 浏览器中训练模型。当然这一步也可以在JavaScript环境中使用TensorFlow.js来完成。
由于我们的学习一直基于 Python 的Jupyter notebook,因此我将基于Jupyter notebook逐步讲解构建机器学习Web应用的全流程。

2.工具安装
对于此次任务,我们需要安装两个工具:Flask和Pickle,前者是Python的第三方库,后者是标准库。
0 Flask是一个用python语言基于Werkzeug工具箱编写的轻量级web开发框架,它主要面向需求简单,项目周期短的小应用。它提供了使用Python和模板引擎构建网页的Web框架的基本功能。
1 pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。即我们可以将训练好的模型封装到文件中,直接拿来预测使用。
输入以下代码安装flask框架:
pip3 install -i https://mirrors.aliyun.com/pypi/simple/ flask pickle模块是内置库,无需安装。
3.数据预处理
本文中我们使用 NUFORC(国家 UFO 报告中心)收集的 80000 次 UFO 目击事件的数据。这些数据对UFO目击事件有一些有趣的描述,例如:
“一名男子从夜间照射在草地上的一束光中出现,
他跑向德州仪器停车场” “灯光追赶着我们”
数据和配套的ipynb文件我已经上传到资源中,点击链接即可免费下载。
接下来我们对数据进行预处理。
①数据加载及查看
导入第三方库,加载并查看数据内容及数据结构:
import pandas as pd #导入pandas库并重命名为pdimport numpy as np #导入numpy库并重命名为npufos = pd.read_csv('./data/ufos.csv') #使用pandas库的read_csv函数加载数据ufos.head()#查看数据的前五行内容
我们可以看到数据中具有UFO目击的时间,经纬度坐标,国家以及时长等。
继续查看数据组织结构:
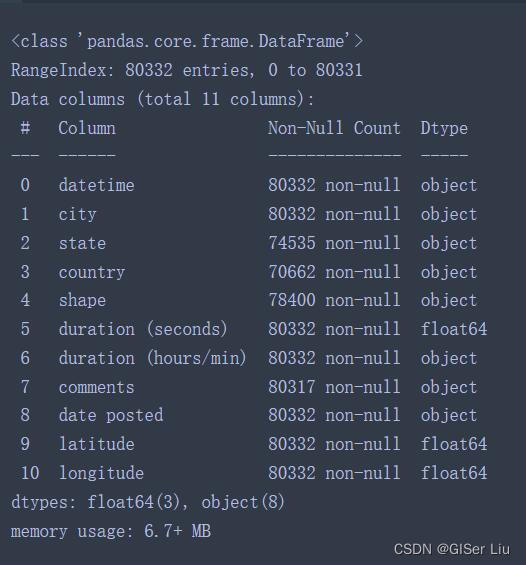
我们可以看到我们的数据中共有80332行,其中部分列有缺失值。
②数据处理及特征选择
方便起见,我们将需要的数据提取至新表,并删去存在缺失值的列。
输入以下代码:
ufos = pd.DataFrame({'Seconds': ufos['duration (seconds)'], 'Country': ufos['country'],'Latitude': ufos['latitude'],'Longitude': ufos['longitude']})ufos.dropna(inplace=True) #删除缺失值ufos.Country.unique() #查看国家数据包含的类别现在,我们通过筛选1-60 秒之间的目击事件来减少我们需要处理的数据量,输入以下代码:
ufos = ufos[(ufos['Seconds'] >= 1) & (ufos['Seconds'] <= 60)]导入Scikit-learn的库,使用LabelEncoder标签编码器按字母顺序对数据进行编码将国家/地区的文本值转换为数字,这一步与我们上一文中逻辑回归的原理一样,不过本文是多分类问题。输入以下代码:
from sklearn.preprocessing import LabelEncoderufos['Country'] = LabelEncoder().fit_transform(ufos['Country'])ufos.head()输出结果为:
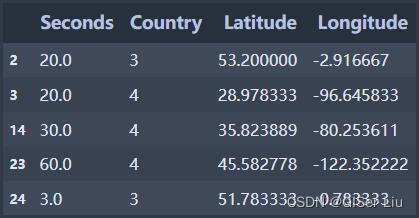
查看经过预处理的数据,我们看到,数据中只存在四列,其中:
0 Seconds、Latitude、Loongitude作为输入特征
1 Country 作为预测标签

4.机器学习模型构建
现在,数据已经处理完成,我们可以进行模型训练了。
①数据集划分
利用Scikit-learn库的train_test_split函数将数据集以8:2的比例进行划分。
输入以下代码:
from sklearn.model_selection import train_test_split#导入数据集划分函数Selected_features = ['Seconds','Latitude','Longitude']#设定特征变量值X = ufos[Selected_features]#设定输入特征数据Y = ufos['Country']#设定预测标签X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)#以8:2的比例划分训练集与测试集②调用逻辑回归模型训练多分类模型
数据集划分好以后,调用逻辑回归模型函数训练模型。
输入以下代码:
from sklearn.metrics import accuracy_score, classification_report#调用ACC系数,和分类指标函数from sklearn.linear_model import LogisticRegression#调用逻辑回归模型model = LogisticRegression()#实例化逻辑回归模型model.fit(X_train, Y_train)#输入训练集,训练逻辑回归模型predictions = model.predict(X_test)#在测试集上进行预测print(classification_report(Y_test, predictions))#输出精度指标表print('Predicted labels: ', predictions)#输出预测结果print('Accuracy: ', accuracy_score(Y_test, predictions))#输出ACC系数值输出结果为:
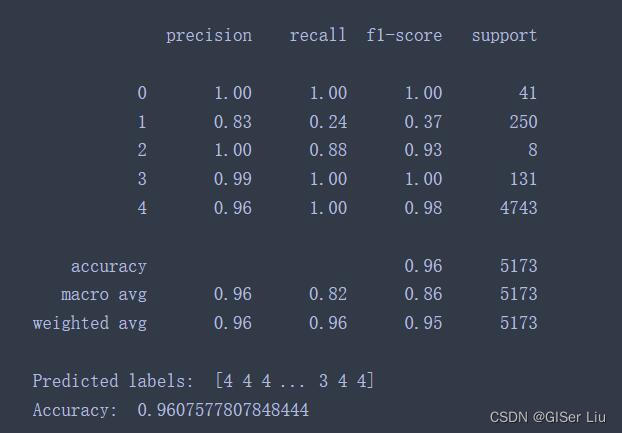
准确率96%!还不错。这说明特征变量高度相关。
事实上经纬度坐标与国家位置本来就高度相关,不过这也算是精度验证了。
5.“腌制”你的模型
模型我们已经训练完成,准确率也不赖,现在我们可以将其“腌制”,即封装打包。“腌制”完成后,加载模型,根据时间,经纬度;我们就可以对其进行测试了!
输入以下代码:
import pickle #调用“腌制”库model_filename = 'ufo-model.pkl'#设定文件名pickle.dump(model, open(model_filename,'wb'))#对模型进行“腌制”model = pickle.load(open('ufo-model.pkl','rb'))#加载“腌制”好的模型print(model.predict([[50,44,-12]]))#测试模型,其中参数分别是出现的秒数、纬度、经度 不出所料,会输出"1",这代表着该UFO出现的位置是Canada。
6.配置Flask应用
本节内容很重要!!!
现在我们可以构建一个Flask Web应用来使用我们的模型了!
①创建应用文件夹
首先,新建一个名为web-app的文件夹;这里,“web-app”是应用的名称,你也可以按自己的喜好设置,记得运行文件中也要同样的名称。
再根据以下文件结构组建文件夹:
web-app/ static/ css/ style.css templates/ index.html app.py requirement.txt ufo-model.pkl0 static文件夹中的css文件夹用以存储css网页样式文件
1 templates文件夹用以存储html网页内容文件
2 app.py文件是模型加载及运行文件,它在这里起到后端脚本的作用,类似于PHP
3 ufo-model.pkl是我们“腌制”好的模型文件
requirement.txt文件中存储本模型需要调用的python第三方库名。
scikit-learn
pandas
numpy
flask

②构建网页样式style.css文件
打开style.css文件,输入以下CSS代码并保存:
body {width: 100%;height: 100%;font-family: 'Helvetica';background: black;color: #fff;text-align: center;letter-spacing: 1.4px;font-size: 30px;}input {min-width: 150px;}.grid {width: 300px;border: 1px solid #2d2d2d;display: grid;justify-content: center;margin: 20px auto;}.box {color: #fff;background: #2d2d2d;padding: 12px;display: inline-block;} 若你对前端有所涉猎,也可以自行修改代码,调整样式。
③构建Web界面内容index.html文件
打开index.html文件,输入以下HTML代码创建文本框和按钮并保存:
🛸 UFO 目击预测器! 👽 根据UFO目击秒数及经纬度来预测UFO出现的国家!
{{ prediction_text }}
④构建Python后端app.py文件
打开app.py文件,输入以下代码并保存:
import numpy as npfrom flask import Flask, request, render_templateimport pickleapp = Flask(__name__)#初始化APPmodel = pickle.load(open("ufo-model.pkl", "rb"))#加载模型@app.route("/")#装饰器def home(): return render_template("index.html")#先引入index.html,同时根据后面传入的参数,对html进行修改渲染。@app.route("/predict", methods=["POST"])def predict(): int_features = [int(x) for x in request.form.values()]#存储用户输入的参数 final_features = [np.array(int_features)]#将用户输入的值转化为一个数组 prediction = model.predict(final_features)#输入模型进行预测 output = prediction[0]#将预测值传入output countries = ["Australia", "Canada", "Germany", "UK", "US"]#根据预测值判断国家 return render_template( "index.html", prediction_text="Likely country: {}".format(countries[output])#将预测值返回到Web界面,使我们看到 ) if __name__ == "__main__": app.run(debug=True)#调试模式下运行文件,实时反应结果。仅限测试使用,生产模式下不要使用在运行应用之前,请查看一下app.py文件,它可以分解为以下步骤:
0 首先,加载依赖项并启动应用。
1 然后,导入模型。
2 然后,在主路由上呈现index.html。
3 表单变量被收集并转换为 numpy数组。然后将它们发送到模型并返回预测值。
4 根据预测值与国家/地区的对应关系将该国家发送回 index.html以在Web模板中呈现。
7.运行Flask应用
Win+R输入cmd打开命令行,cd文件路径至web-app,输入以下代码:
cd [文件夹所在路径] #如:cd F:\web-app\输入以下代码运行程序:
python app.py稍等片刻,将出现的本地服务器地址复制到浏览器中打开便可以在默认浏览器中加载出Web应用。
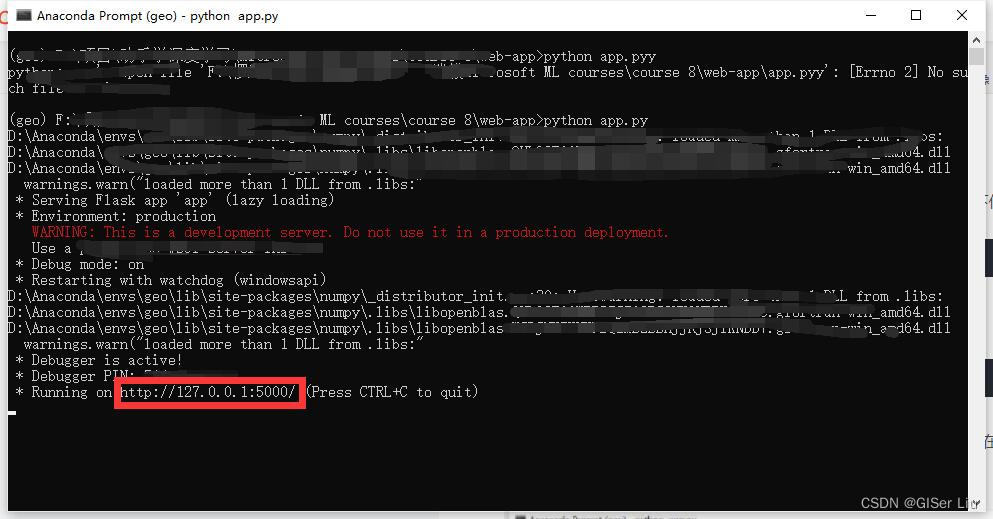
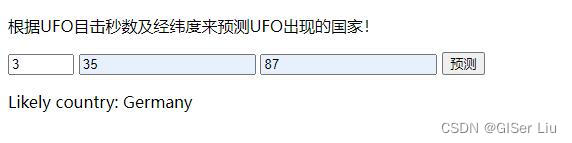
输入参数预测结果。对模型进行测试,测试成功!。
恭喜!你已成功实现了Web APP!🏆
使用Flask和pickle构建Web 应用相对简单。其中最重要的是了解发送到模型和预测的数据格式和数据结构。这完全取决于模型的训练方式。
在生产环境中,模型训练者与用户之间需要良好的沟通。了解用户需求迭代Web应用是很必要的!
三、内容总结
在本文中,我们使用Python的Flask框架与Pickle模块构建了Web应用程序,在UFO目击数据集上构建了逻辑回归多分类模型,并将其集成在Web程序中。实现了机器学习模型的Web应用构建。
🚀挑战
1.无需在Jupyter notebook中训练模型并将其导入 Flask 应用程序,你可以直接在 Flask 应用程序中尝试训练模型!尝试一下,看看这种方法有什么利弊?
2.构建 Web 应用以使用 ML 模型的方法有很多种。列出您可以使用 JavaScript 或 Python 构建 Web 应用以利用机器学习的方法。
课后测验

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!
“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”

