一文读懂机器学习分类全流程

目录
前言
提出问题
一、介绍
1.分类简介
2.imblearn的安装
二、数据加载及预处理
1.加载并查看数据
①导入Python第三方库
②调用并查看数据
2.查看数据分布
①各国样本分布直方图
②各国样本划分
3.各国最受欢迎食材可视化
4.平衡数据集
①样本插值采样
三、分类器选择
四、逻辑回归模型构建
1.数据导入及查看
2.可训练特征与预测标签选择及数据集划分
3.构建逻辑回归模型及精度评价
4.模型测试
五、更多分类模型
1.第三方库导入
2.测试不同分类器
①线性SVC分类器
②K-近邻分类器
③SVM分类器
④集成分类器
六、模型发布为Web应用
1.模型打包
2.配置Flask应用
②app.py
3.应用运行及测试
结论
前言
在本文中,你将学到:
0 复习数据预处理及可视化
1 了解分类的基本概念
2 使用多种分类器来对比模型精度
3 掌握使用分类器列表的方式来批处理不同模型
4 将机器学习分类模型部署为Web应用
提出问题
本文我们所用的数据集是亚洲美食数据集,其包括了亚洲5个国家的美食食谱与所属的国家。我们构建模型的目的是解决:
如何根据美食所用食材判断其所属国家
即以美食食材为可训练特征,所属国家为预测标签构建机器学习分类模型。
一、介绍
1.分类简介
分类是经典机器学习的基本重点,也是监督学习的一种形式,与回归技术有很多共同之处。其通常分为两类:二元分类和多元分类。本文中,我将使用亚洲美食数据集贯穿本次学习。
还记得我在之前文章中提到的:
0 线性回归可帮助我们预测变量之间的关系,并准确预测新数据点相对于该线的位置。因此,例如,预测南瓜在9月与12月的价格。
1 Logistic回归帮助我们发现“二元类别”:在这个价格点上,这是橙子还是非橙子?
分类也是机器学习人员和数据科学家的基本工作之一。从二分类(判断邮件是否是垃圾邮件),到使用计算机视觉的复杂分类和分割,其在很多领域都有着很大的作用。
以更科学的方式陈述该过程:
我们所使用的分类方法创建了一个预测模型,这个模型使我们能够将输入变量之间的关系映射到输出变量。
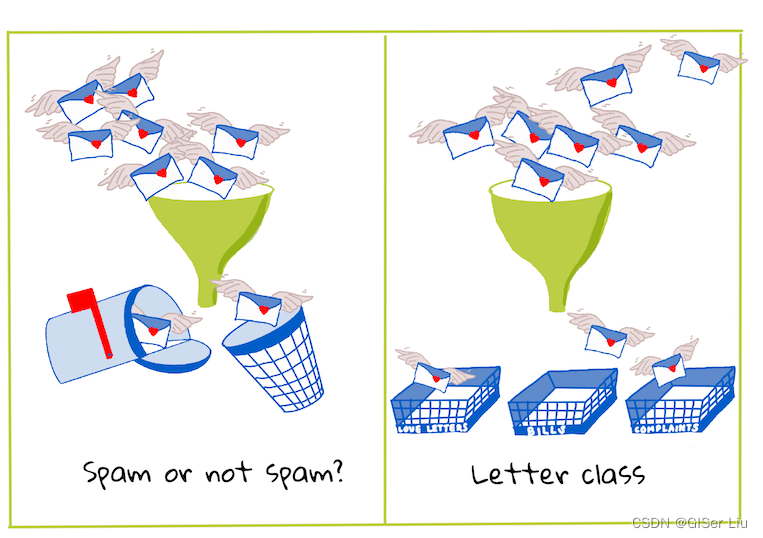
分类使用各种算法来确定数据点的标签或类别。我们以亚洲美食数据集为例,看看通过输入一组特征样本,我们是否可以确定其菜肴所属的国家。
以下是经典机器学习常用的分类方法。
0 逻辑回归
1 决策树分类(ID3、C4.5、CART)
2 基于规则分类
3 K-近邻算法(K-NN)
4 贝叶斯分类
5 支持向量机(SVM)
6 随机森林(Random Forest)
2.imblearn的安装
在开始本文学习之前,我们第一个任务是清理和调整数据集以获得更好的分析结果。我们需要安装的是imblearn库。这是一个基于Python的Scikit-learn软件包,它可以让我们更好地平衡数据。
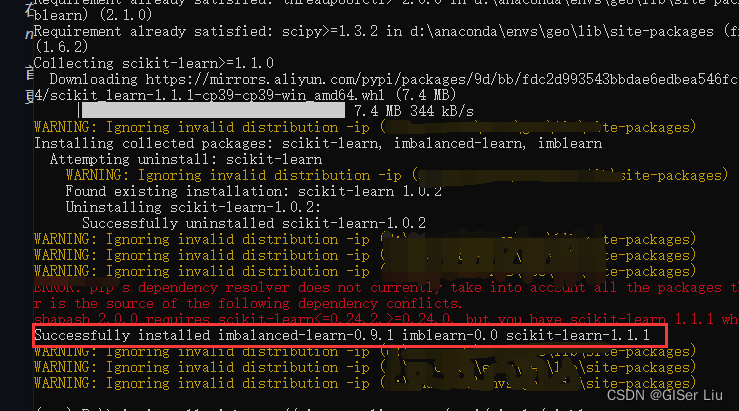
在命令行中输入以下代码,使用阿里的镜像来安装 imblearn :
pip install -i https://mirrors.aliyun.com/pypi/simple/ imblearn看到如下图所示代表安装成功。
二、数据加载及预处理
1.加载并查看数据
①导入Python第三方库
import pandas as pdimport matplotlib.pyplot as pltimport matplotlib as mplimport numpy as npfrom imblearn.over_sampling import SMOTE②调用并查看数据
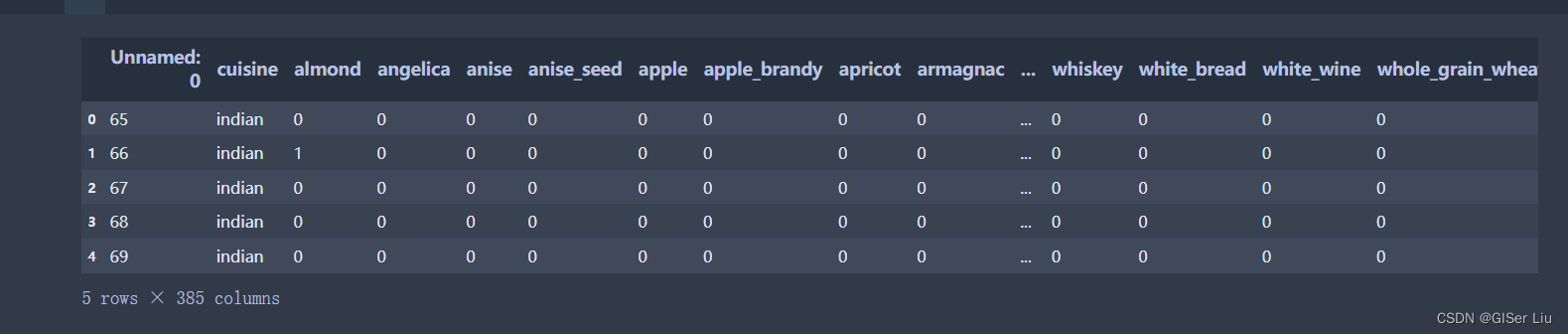
df = pd.read_csv('cuisines.csv')df.head()前5行数据如下图所示:
查看数据结构:
df.info()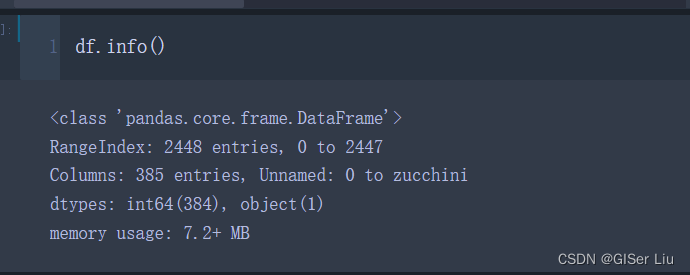
通过查看数据与其组织结构,我们可以发现数据有2448行,385列,其中有大量的无效数据。
2.查看数据分布
我们可以对数据进行可视化来发现数据集中的数据分布。
①各国样本分布直方图
通过调用barh()函数将数据绘制为柱状图。
df.cuisine.value_counts().plot.barh() #根据不同国家对数据集进行划分结果如下:
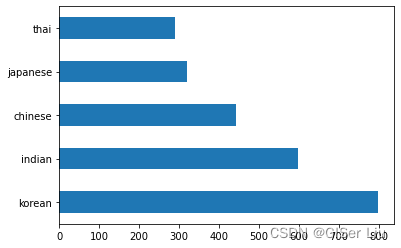
我们可以看到,数据集中以韩国料理样本最多,泰国样本最少。美食的数量有限,但数据的分布是不均匀的。我们可以解决这个问题!在此之前,请进一步探索。
②各国样本划分
了解各国美食有多少可用数据并将其打印输出。输入以下代码,从结果中我们可以看到不同国家美食的可用数据:
thai_df = df[(df.cuisine == "thai")]#提取泰国美食japanese_df = df[(df.cuisine == "japanese")]#提取日本美食chinese_df = df[(df.cuisine == "chinese")]#提取中国美食indian_df = df[(df.cuisine == "indian")]#提取印度美食korean_df = df[(df.cuisine == "korean")]#提取韩国美食print(f'thai df: {thai_df.shape}')#输出数据结构print(f'japanese df: {japanese_df.shape}')#输出数据结构print(f'chinese df: {chinese_df.shape}')#输出数据结构print(f'indian df: {indian_df.shape}')#输出数据结构print(f'korean df: {korean_df.shape}')#输出数据结构
3.各国最受欢迎食材可视化
现在,我们可以更深入的挖掘数据,并了解每种菜肴的成分。在此之前,我们应该对数据进行预处理,删去重复值。
在python中创建一个函数来删除无用的列,然后按成分数量进行排序。
def create_ingredient_df(df): ingredient_df = df.T.drop(['cuisine','Unnamed: 0']).sum(axis=1).to_frame('value')#从原始数据中删除无效列并统计axis=1的总和赋值给value列 ingredient_df = ingredient_df[(ingredient_df.T != 0).any()]#提取所有非0值的样本 ingredient_df = ingredient_df.sort_values(by='value', ascending=False, inplace=False)#按照数值的大小进行排序 return ingredient_df#返回处理并排序后的结果现在,我们调用create_ingredient_df()函数来了解泰国美食中,最受欢迎的十大食材。输入以下代码:
thai_ingredient_df = create_ingredient_df(thai_df)thai_ingredient_df.head(10).plot.barh()查看泰国美食中十大最受欢迎的食材:
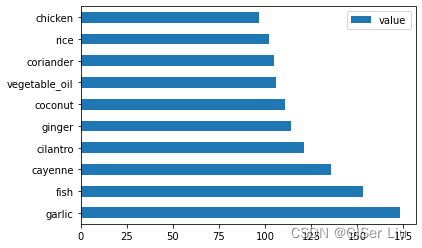
我们可以看到,第一名的食材是garlic(大蒜),第十名则是chicken(鸡肉)。
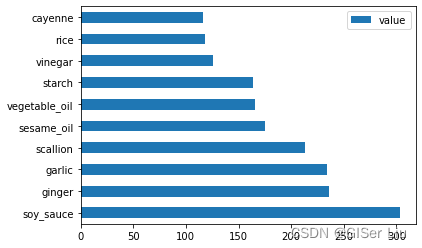
对中国数据执行同样的操作:
chinese_ingredient_df = create_ingredient_df(chinese_df)chinese_ingredient_df.head(10).plot.barh()结果如下,中国美食食材中,最受欢迎的是soy_sauce(酱油),第十名是cayenne(红辣椒):
同理,我们也可以输出其他国家的美食食材,这里就不水文了。大家可自行尝试。
现在,我们需要使用drop()函数删除不同美食间造成混淆的最常见成分以突出各国食材的特色,每个国家的人都喜欢米饭、大蒜和生姜。(可自行可视化查看),我们输入以下代码将其删去。
feature_df= df.drop(['cuisine','Unnamed: 0','rice','garlic','ginger'], axis=1)#删去最常见的这几列以平衡不同国家之间的混淆labels_df = df.cuisine 4.平衡数据集
现在我们已经清理了数据,因为不同国家的样本数量差异较大,我们需要使用SMOTE(“合成少数过度采样技术”)来平衡它。
SMOTE介绍
①样本插值采样
调用SMOTE对象的 fit_resample() 函数来插值重采样生成新样本。输入以下代码:
oversample = SMOTE()transformed_feature_df, transformed_label_df = oversample.fit_resample(feature_df, labels_df)print(f'new label count: {transformed_label_df.value_counts()}')print(f'old label count: {df.cuisine.value_counts()}')查看新样本与旧样本的数据量差异:
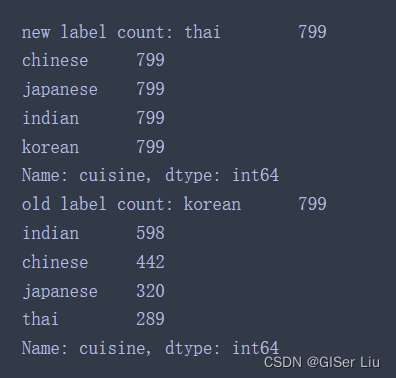
我们可以看到,新样本不同类别标签下的样本数量都在799,它是以旧样本中最大样本量标签为基础构建的,而旧样本则参差不齐,分布不均匀。
数据质量很好,干净、平衡!🧸🧸
数据预处理的最后一步是将预处理后的数据导出以后直接调用。输入以下代码:
transformed_df.to_csv("cleaned_cuisines.csv")#保存至新文件方便下一次直接调用三、分类器选择
现在,数据已经经过预处理,我们可以构建分类模型了!
但是选择什么模型好呢?
Scikit-learn中的分类算法在监督学习下,在该类别中,我们将找到许多分类方法。这种多样性一见钟情就相当令人眼花缭乱。以下方法都包含分类技术:
线性模型
支持向量机
随机梯度下降
最近邻
高斯过程
决策树
集成学习(随机森林)
多类和多输出算法(多类和多标签分类、多类-多输出分类)
使用什么分类器?
通常,同时运行几个分类模型,最终找到精度最高的方法很常用。Scikit-learn提供了对所创建数据集的并列比较,比较了下面模型的结果。
KNeighbors,SVC,GaussianProcessClassifier,DecisionTreeClassifier,RandomForestClassifier,MLPClassifier,AdaBoostClassifier,GaussianNB和QuadraticDiscrinationAnalysis
下图显示了这些模型可视化的结果:
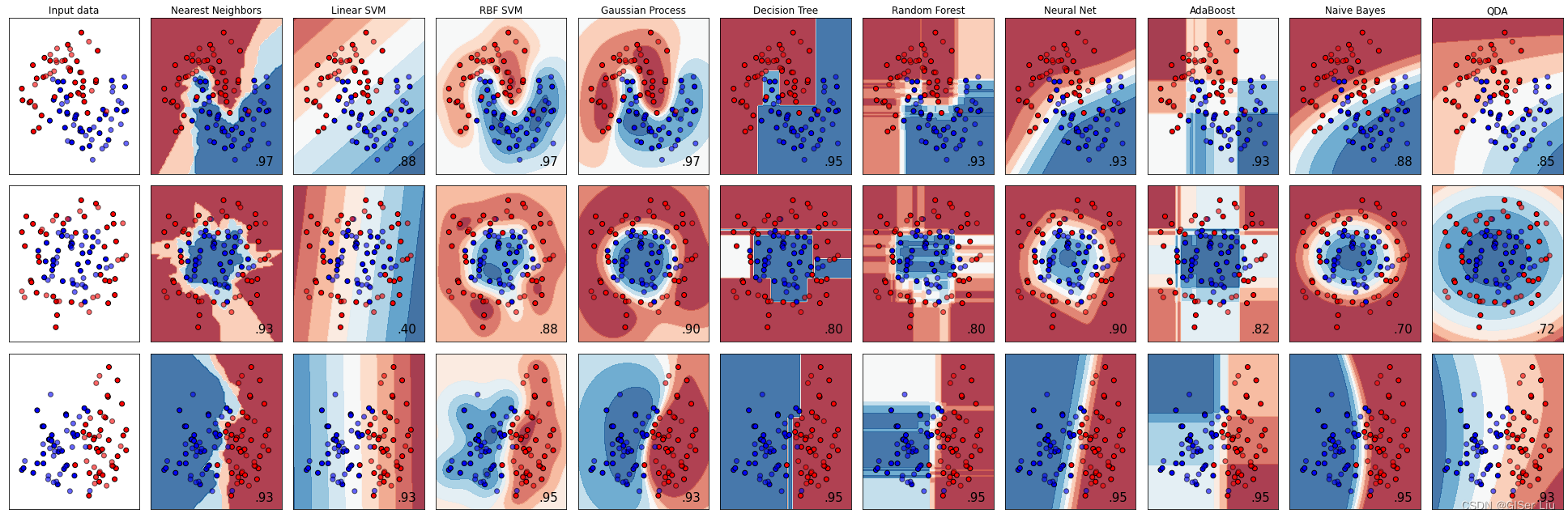
这种方法在数据集样本较少时可以使用,但随着样本数量的增多,这对计算的负担将会越来越大。我们先不考虑这种方法。请继续向下看😀。
四、逻辑回归模型构建
在前文中,我们已经对数据进行了预处理,方便起见,我们在后续文章中直接调用经过预处理的 cleaned_cuisines.csv 文件。
我们在之前的逻辑回归文章中,有学到逻辑回归的基本原理与构建流程,这里我们可以尝试使用逻辑回归来解决问题。
1.数据导入及查看
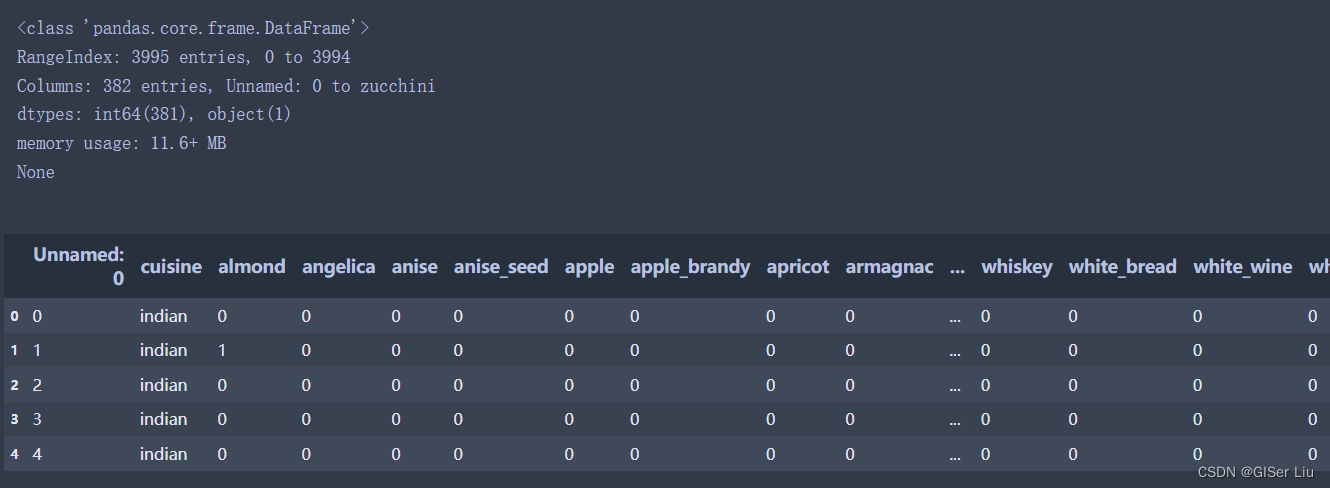
导入第三方库并加载经过预处理的数据cleaned_cuisines.csv。输入以下代码:
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curvefrom sklearn.svm import SVCimport numpy as npimport pandas as pdcuisines_df = pd.read_csv("cleaned_cuisines.csv")print(cuisines_df.info())cuisines_df.head()数据如下图所示:
2.可训练特征与预测标签选择及数据集划分
以美食数据集的所属国家列为预测标签Y,食材为可训练特征构建数据集。并以7:3的比例划分训练集与测试集。输入以下代码:
cuisines_label_df = cuisines_df['cuisine'] #以cuisine列为预测标签cuisines_feature_df = cuisines_df.drop(['Unnamed: 0', 'cuisine'], axis=1) #删去无用的列,取食材列为可训练特征X_train, X_test, Y_train, Y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)#以7:3比例划分训练集与测试集3.构建逻辑回归模型及精度评价
使用划分好的数据集进行逻辑回归模型构建,打印出模型的精度评价表;测试模型的预测效果。输入以下代码:
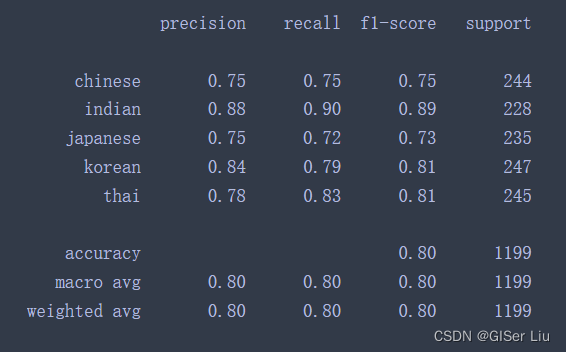
lr = LogisticRegression(multi_class='ovr',solver='liblinear')model = lr.fit(X_train, np.ravel(Y_train))accuracy = model.score(X_test, Y_test)print ("Accuracy is {}".format(accuracy))Y_pred = model.predict(X_test)print(classification_report(Y_test,Y_pred))输出结果为ACC系数为:79.1%
通过打印出该模型的精度评价表我们可以获得更多的模型信息:
4.模型测试
测试模型并查看模型在测试集上将样本分类为不同类别的概率:
print(f'ingredients: {X_test.iloc[50][X_test.iloc[50]!=0].keys()}')print(f'cuisine: {Y_test.iloc[50]}')test= X_test.iloc[50].values.reshape(-1, 1).Tproba = model.predict_proba(test)classes = model.classes_resultdf = pd.DataFrame(data=proba, columns=classes)topPrediction = resultdf.T.sort_values(by=[0], ascending = [False])topPrediction.head()输出结果为:

可以看到对于测试集上的某个样本,其预测为日本菜的概率为91%。
五、更多分类模型
在前文中,我们已经构建了逻辑回归模型,那么可以使用其他模型吗,怎么选择呢?
在开始选择分类器之前,我要向各位读者推荐一个机器学习神器----分类地图。
Scikit-learn提供了一个机器学习分类器选择的地图,它可以进一步帮助使用者缩小分类器的选择范围,如下图:
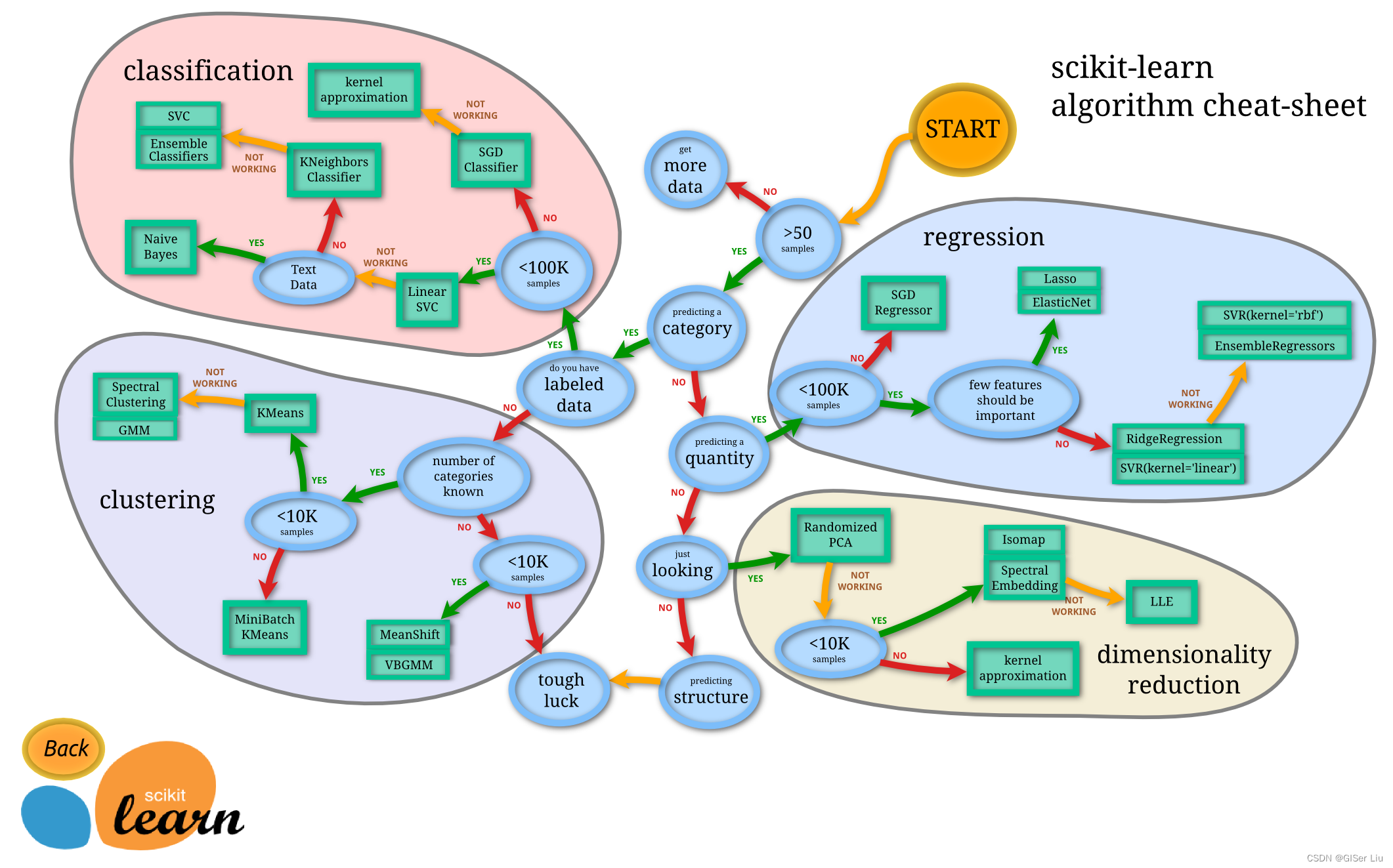
一旦我们对数据有了一定的了解,此地图将极大的节省我们的试错成本,因为我们可以沿着其路径“行走”来选择需要的模型(看着图走):
0 我们有大于50个样本
1 我们想要预测一个类别
2 我们标记了数据
3 我们的样本少于100K
4 我们可以选择线性SVC
5 如果这不起作用,因为我们有数字数据
6 我们可以尝试 KNeighbors Classifier
7 如果这不起作用,请尝试 SVC 和 集成分类器(诸如随机森林)
这是一条非常有用的工具,对机器学习初学者很友好。
1.第三方库导入
按照这条路径,我们首先需要导入多分类器需要的第三方库:
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.svm import SVCfrom sklearn.ensemble import RandomForestClassifier, AdaBoostClassifierfrom sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curveimport numpy as np数据和训练样本我们继续使用之前划分好的数据集。
2.测试不同分类器
①线性SVC分类器
支持向量聚类 (SVC) 是支持向量机机器学习技术系列的子集。在此方法中,你可以选择一个“核函数”来决定如何对标签进行聚类。“C”参数是指“正则化”,它调节参数的影响。内核有多个选择;在这里,我们将其设置为“线性”核函数。概率默认为“假”;在这里,我们将其设置为“true”以收集概率估计值。我们将随机状态设置为“0”,以随机排列数据以获得概率。
首先我们需要创建一个分类器列表,用于存储之后新增的机器学习分类器。先放入一个线性SVC分类器。
C = 10 #正则化参数设置为10# Create different classifiers.classifiers = { 'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0)}#创建分类器列表使用线性SVC训练模型并打印精度报告:
n_classifiers = len(classifiers)for index, (name, classifier) in enumerate(classifiers.items()): classifier.fit(X_train, np.ravel(y_train)) y_pred = classifier.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100)) print(classification_report(y_test,y_pred))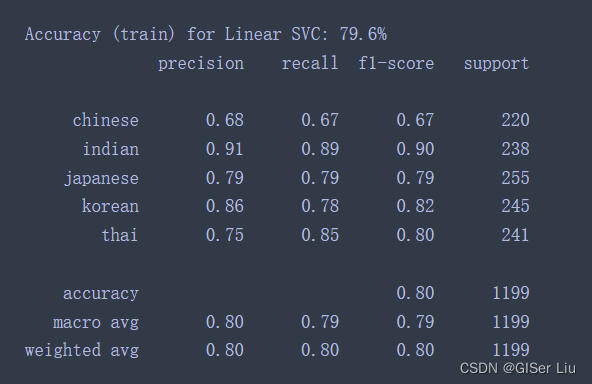
查看线性SVC的精度报告,效果还不错,准确率达到了78.6%。
②K-近邻分类器
K-Neighbors是机器学习常用的方法,可用于监督学习与无监督学习。在此方法中,需要预先创建部分点数,并在这些点周围收集数据,以预测数据的广义标签。
我们在之前创建的分类器列表中加入KNN分类器代码。运行以后再次查看精度:
'KNN classifier': KNeighborsClassifier(C),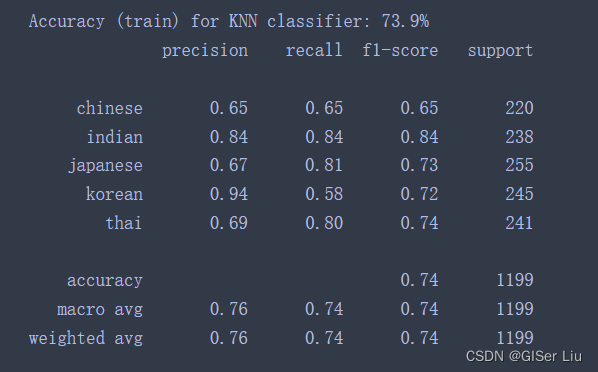
🤨精度有所下降。。
③SVM分类器
SVM分类器是用于分类和回归任务的支持向量机机器学习方法系列的子集。SVM“将训练样本点映射到高维空间中”,最大化两个类别之间的距离。后续的预测数据被映射到此空间中,来预测其类别。
我们在K-近邻算法后加入支持向量分类器:
'SVC': SVC(),再次运行,查看SVM支持向量模型结果。
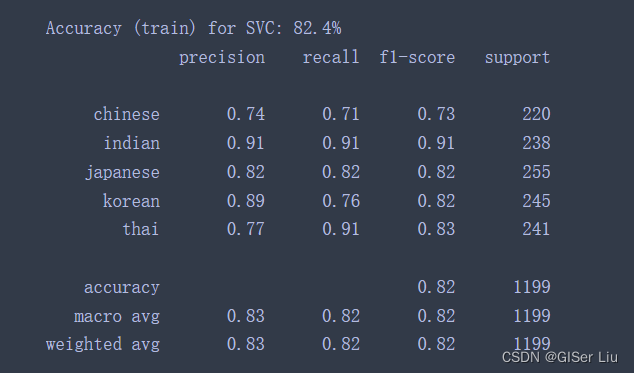
🥇fantastic!精度上升到了82.4%。
继续测试其他模型...
④集成分类器
之前的测试精度相当不错。让我们尝试使用集成学习模型,特别是Random Forest和AdaBoost吗,在模型中列表加入下面代码后运行:
'RFST': RandomForestClassifier(n_estimators=100), 'ADA': AdaBoostClassifier(n_estimators=100)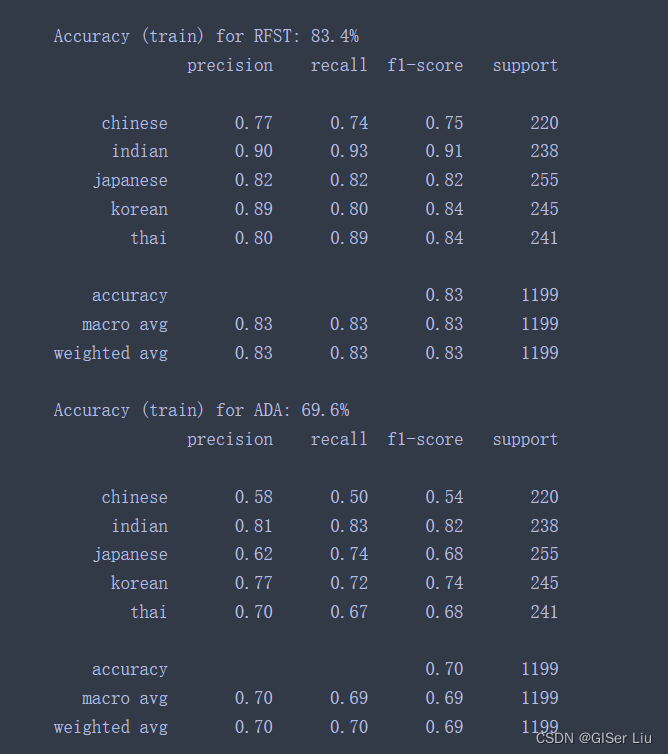
很不戳!🎈🎈RFST随机森林的精度达到了83.4%,AdaBoost似乎不太好,不过这不重要。
集成学习方法结合了几个基本分类器的预测,以提高模型的质量。在我们的示例中,我们使用了 Random Trees 和 AdaBoost。
0 随机森林是一种平均方法,它构建了一个由“决策树”组成的“森林”,注入了随机性,以避免过度拟合。n_estimators参数设置为树的数量。
1 AdaBoost 将分类器拟合到数据集,然后将该分类器的副本拟合到同一数据集。它侧重于错误分类项目的权重,并调整下一个分类器要更正的拟合度。
这些技术中的每一种都有大量超参数可以调整。读者可以自行研究每个参数的默认参数,并尝试调整这些参数观察其对模型质量的影响。
六、模型发布为Web应用
我在模型部署的文章中有讲解使用Flask框架和pickle库打包模型及应用构建的全流程,虽然之前按用的时回归模型。但回归模型与分类模型部署的流程一样:
训练模型>模型打包>应用配置>模型部署>运行测试
1.模型打包
方便起见,我们我们使用刚刚训练好的逻辑回归分类模型,将其使用Pickle库将其打包为 美食预测.pkl文件,以便后续的使用。输入以下代码:
import picklemodel_filename = 'cuisines.pkl'pickle.dump(model, open(model_filename,'wb'))model = pickle.load(open('cuisines.pkl','rb'))print(model.predict([range(1,381)]))输出的结果为 Indian🤣,(这里参数其实有错,因为输入特征有380个,不可能一个一个输入...我自己就编了点,还是三哥吃的杂。项目实践中我们对大量样本常常使用批处理,只有小样本才这样直接输入)。
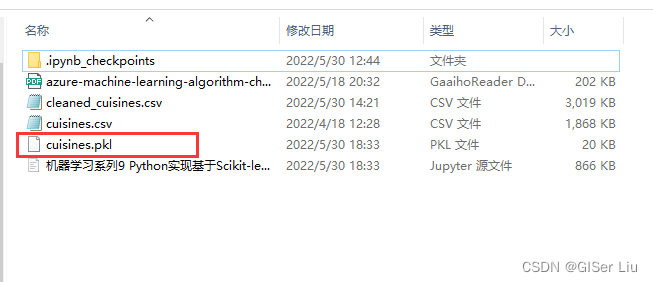
可以看到文件夹下已经生成了打包好的模型。😊
2.配置Flask应用
详细配置请看:机器学习系列8 基于Python构建Web应用以使用机器学习模型
我们这里只配置关键文件index.html和app.py,其他文件配置请看此文。
①index.html
🍕亚洲美食预测器🍖 根据拥有的食材来预测UFO出现的国家!
包含的食材填1,不包含的填0
{{ prediction_text }}
②app.py
import numpy as npfrom flask import Flask, request, render_templateimport pickleapp = Flask(__name__)#初始化APPmodel = pickle.load(open("cuisines.pkl", "rb"))#加载模型@app.route("/")#装饰器def home(): return render_template("index.html")#先引入index.html,同时根据后面传入的参数,对html进行修改渲染。@app.route("/predict", methods=["POST"])def predict(): int_features = [int(x) for x in request.form.values()]#存储用户输入的参数 int_features = int_features+list(range(1,372)) #凑数 final_features = [np.array(int_features)]#将用户输入的值转化为一个数组 prediction = model.predict(final_features)#输入模型进行预测 output = prediction[0]#将预测值传入output return render_template( "index.html", prediction_text="Likely country: {}".format(output)#将预测值返回到Web界面,使我们看到 )if __name__ == "__main__": app.run(debug=True)#调试模式下运行文件,实时反应结果。仅限测试使用,生产模式下不要使用软件结构如下图:
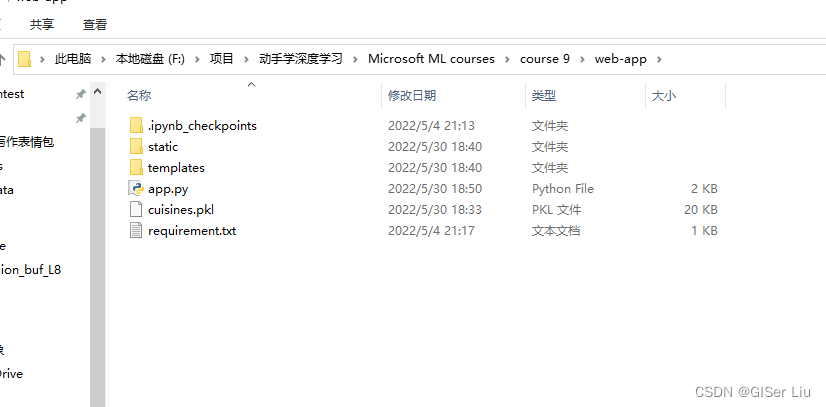
3.应用运行及测试
在命令行cd切换路径至当前目录下,输入以下代码,将出现的链接复制到浏览器打开:
python app.py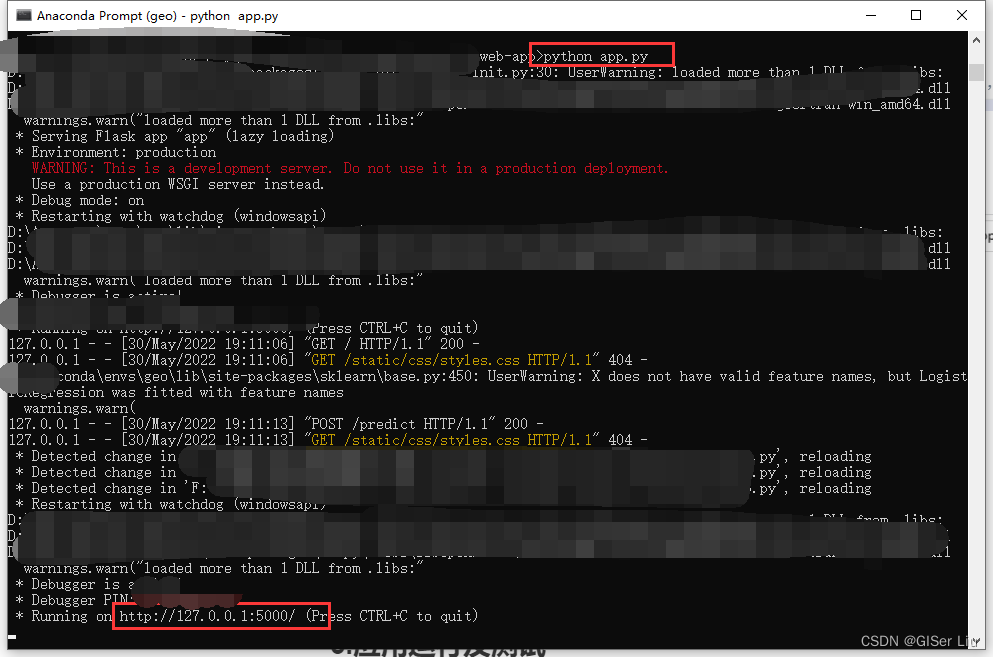
按要求输入特征,代码运行成功,输出印度:

至此,本文内容结束!
结论
在本文中,作者对机器学习分类的概念进行了简单的介绍,详细的讲解了数据预处理,分类器选择、模型训练及精度评价,还有最后的Web应用发布。在今后的文章中,我将创作更多的机器学习文章,以文督学,感谢观看!

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!
“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”
系列文章
机器学习系列0 机器学习思想_GISer Liu的博客-CSDN博客
机器学习系列1 机器学习历史_GISer Liu的博客-CSDN博客
机器学习系列2 机器学习的公平性_GISer Liu的博客-CSDN博客_公平机器学习
机器学习系列3 机器学习的流程_GISer Liu的博客-CSDN博客
机器学习系列4 使用Python创建Scikit-Learn回归模型_GISer Liu的博客-CSDN博客
机器学习系列5 利用Scikit-learn构建回归模型:准备和可视化数据(保姆级教程)_GISer Liu的博客-CSDN博客
机器学习系列6 使用Scikit-learn构建回归模型:简单线性回归、多项式回归与多元线性回归_GISer Liu的博客-CSDN博客_多元多项式回归机器学习系列7 基于Python的Scikit-learn库构建逻辑回归模型_GISer Liu的博客-CSDN博客机器学习系列8 基于Python构建Web应用以使用机器学习模型_GISer Liu的博客-CSDN博客

