requests库爬虫实例
本次爬虫试图获得各个城市2015年-2021年每个月的房价均价情况
考虑到不同城市等级的城市房价可能存在明显差距,我们参考城市等级排名2022给所有城市划分等级
本次爬虫主要爬取一线、新一线、二线这三个级别城市的房价
本次爬虫主要使用requests库和BeautifulSoup库
结果展示:
目录
1、引入需要的库
2、搭建爬虫模块
2.1 获取网页的源代码
2.2 获取网页集合
2.3 解析获取的网页
2.4 衔接函数和处理爬虫报错
2.5 构建主函数,将数据写入csv文件
3、爬虫实际操作
1、引入需要的库
from bs4 import BeautifulSoup import requests import reimport csv本次爬虫主要使用requests库获取网站的源代码,再通过BeautifulSoup库解析成文本,通过re库获取关键数据。
2、搭建爬虫模块
2.1 获取网页的源代码
def getHtml(url): #定义获取网页信息的函数,输出为网页信息 #伪装成浏览器 headers = {'User-Agent': 'MMozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0)Gecko/20100101 Firefox/31.0'} r = requests.get(url,headers=headers) r.encoding= r.apparent_encoding return r.text 说明:这个函数的作用非常简单,就是获取网址源代码,然后打印下来
2.2 获取网页集合
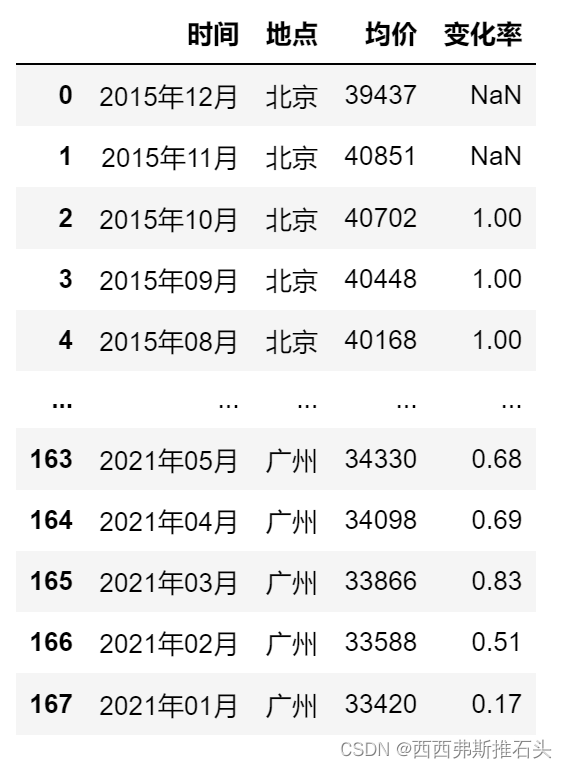
def urllist(x): #获取url列表的函数 url="https://www.anjuke.com/fangjia/{}{}/" urllist=[url.format(m,n) for m in x for n in range(2015,2022)] return urllist说明:为什么写这个函数呢?因为我们爬取的数据不在一个网页,我们需要爬取很多的网页才能获得这些数据,而这些网页的构成是有规律的,因此我们需要仔细观察之后写出来!!!
因此,我们只需要给urllist函数一个城市代号列表,这个函数就可以直接生成众多的url供我们使用!!!
效果如下:
2.3 解析获取的网页
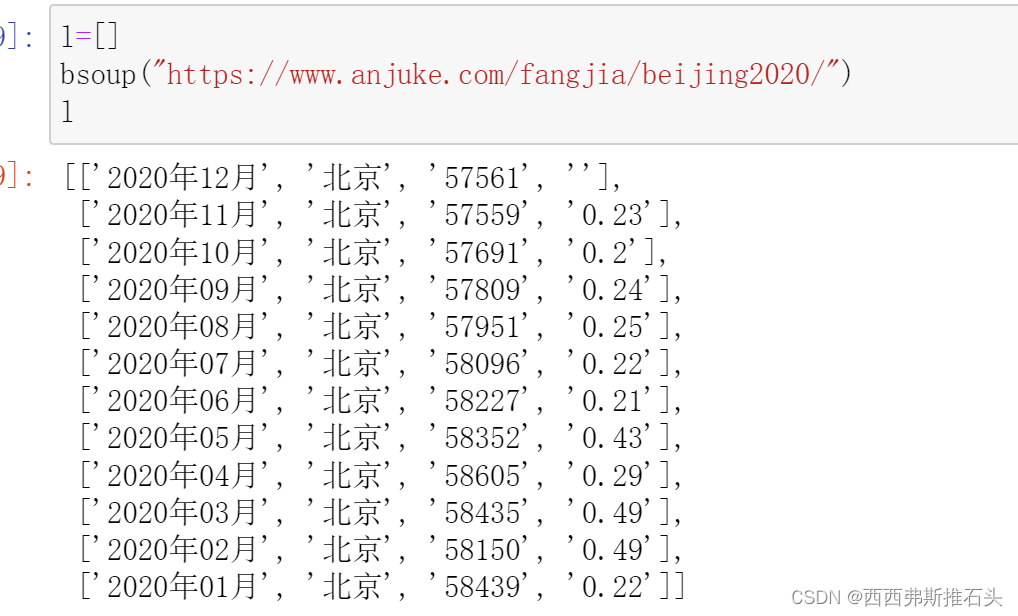
def bsoup(url): #煲汤解析得到的源代码 soup = BeautifulSoup( getHtml(url), 'lxml') a=soup.find_all(name="a", attrs = {'class':'nostyle'})#观察源代码,发现所要得到的数据格式 b=soup.select('div[class="fjlist-box boxstyle2"]>h3') #发现a中没有城市名,查找源代码,发现城市名所在的部分 cs=re.findall("年([\u4e00-\u9fa5]+)房价均价",b[0].text)#使用正则表达式获得城市名 for i in range(len(a)):#发现a中是一年12个月的数据,使用循环获得一个月的数据 b=a[i].text.strip().split("\n")#去除不需要的符号 b.append(cs[0])#加上城市名 #调整一下各个部分的顺序, didian=b[-1] shijian=b[0][0:-2] junjia=b[1][0:-3] bianhualv=b[2][0:-2] b[0]=shijian b[1]=didian b[2]=junjia b[3]=bianhualv #加入到l列表中,l列表成为了一个二元数组 l.append(b)说明:这段代码的功能主要是获取我们想要的内容,通过BeautifulSoup库解析源代码,通过三种方式最终获得我们需要的数据。通过for循环保存到列表中。
下面展示部分数据存在的源代码!
以北京市2020年12月房价均价为例,用F12查看网页源代码,找到网站中房价对应的代码,发现规律。
下面找到城市名称对应的源代码部分!
这里我使用的是正则表达式获得城市名称!
下面展示结果
2.4 衔接函数和处理爬虫报错
def li(x):#定义一个函数,将煲汤模块和获取url列表模块粘在一起 for url in urllist(x): #发现后面的程序可能报错,从而使该部分函数无法执行,采取try-except函数予以报错处理 try: bsoup(url) except: continue#使用continue函数跳过报错的语句,继续对下一条url进行处理说明:在实际操作时,我们发现这样一个问题:部分地区的某些时间的房价数据不存在,如果按照我们的代码直接执行,会使得函数发生错误而中断,为了克服这个问题带来的麻烦,我们使用try-except方法来处理报错,通过continue函数跳过报错的循环,直接执行下一次循环,完美解决了这个问题。
2.5 构建主函数,将数据写入csv文件
def main(x,name):#定义主函数,将获得的二维数组写入csv文件 li(x) f = open(name, 'w', encoding='utf-8', newline="") headers=["时间","地点","均价","变化率"]#给csv文件加表头 csv_write = csv.writer(f) csv_write.writerow(headers) for i in l: csv_write.writerow(i)#一行一行的写入 f.close()由此,爬虫框架构建完毕,下一步准备引入要爬虫的城市名列表,开始爬!!!
3、爬虫实际操作
这里我们根据城市等级进行分组爬虫,写入不同的csv文件!!!
#在百度上搜索城市等级排名2022,重点关注一线、新一线、二线#在尝试爬取之后发现报错,查看原网址,发现有些城市不存在,逐一删去#再次报错,发现有些城市使用首字母简写,有些使用全部拼音,逐一前往原网址核对#大功告成,分别建立一线、欣一线、二线列表yixian=["beijing","guangzhou"]xinyixian=["hangzhou","suzhou","nanjing","chongqing","wuhan","tianjin","cs",\ "xa","qd","zhengzhou","nb","foshan","dg","hf"]erxian=["wuxi","xm","fz","jinan","sy","dalian","km","heb","cc","quanzhou","wenzhou","sjz","gy","nanning","nc",\ "cz","zh","nantong","zh","yt","shaoxing","jx","huizhou","ty","tangshan","jinhua","weifang","taiz",\"zs","yangzhou","lanzhou"]#对一线房价进行爬虫l=[]main(yixian,name="yixian.csv")#对新一线房价进行爬虫l=[]main(xinyixian,name="xinyixian.csv")#对二线房价进行爬虫l=[]main(erxian,name="erxian.csv")值得一提的是,这里很多城市名用的是缩写,需要自己去查看网址确认,这一点比较麻烦,只能一个一个查找了!!!
感兴趣的同学可以自己引入三线、四线、五线城市继续爬取!!!
下一部分,我们将简单的进行可视化,本篇文章就到这里,谢谢各位看官!!!
 开发者涨薪指南
开发者涨薪指南  48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系

