第12期:Spark零基础学习路线
大家好,我是你们的老朋友老王随聊,今天和大家讨论的话题——Spark零基础应该怎么学?
通过这段时间和群里同学们交流,发现很多大学生甚至职场小白对Spark学习路线不是很清晰,所以我花了一些时间给大家整理了一张Spark零基础学习路线全景图,给喜欢Spark的小伙伴提供一个学习的方向。
欢迎加入老王的成长社区,我们一起进步
社区新上线两大专栏:【大学生成长计划】和【职场小白成长计划】,老王将携手多位业界技术大佬分享我们这些年的工作经验,希望对在校或在职的小伙伴能起到抛砖引玉的效果!
目录
1、踏实走好每一阶段
2、Spark零基础学习路线图
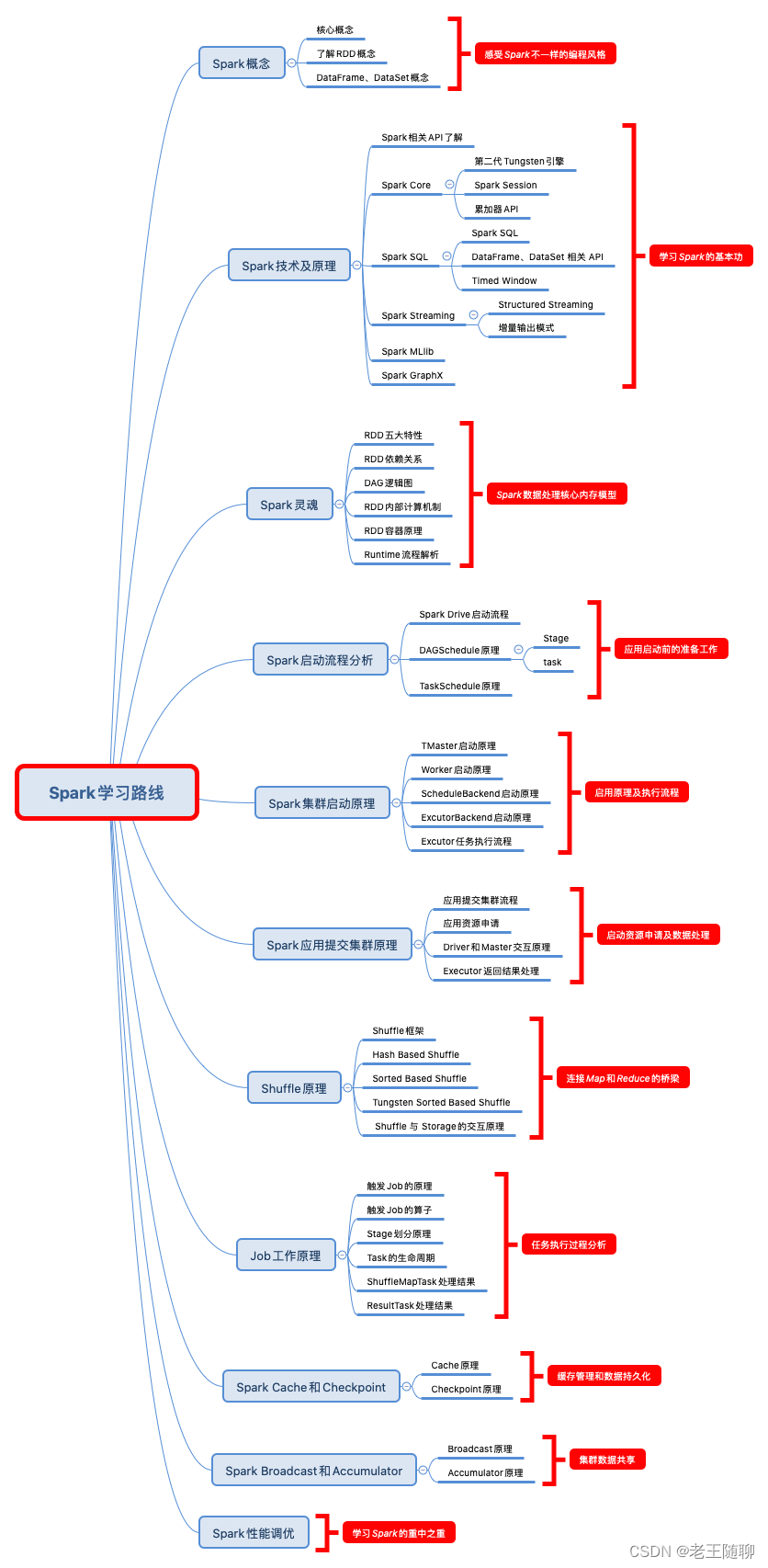
这里总共整理了11个学习阶段,并在文章末尾附有Spark零基础学习路线图。
Java零基础学习路线
Python零基础学习路线
Hadoop零基础学习路线
1、踏实走好每一阶段
1) 了解Spark基础部分,尤其是RDD弹性分布式数据集概念,这也是整个Spark数据处理的内存模型核心部分。
2)了解Spark技术,主要包括PySpark和Spark的常用API、Spark SQL及常用的窗口函数等。这部分属于Spark学习部分的基本功,对后面深入学习Spark内部原理有很大帮助。
3)Spark RDD可以数是整个Spark数据处理的灵魂。需要系统思考RDD的五大特性:分区、Task、依赖关系、类算子以及移动运算机制。
4)了解Spark启动流程,包含:Spark Drive启动流程、DAGSchedule原理和TaskSchedule原理。这部分将有助于后续调优分析使用。
5)了解集群启动原理,加深对Spark的TMaster、Worker和Excutor运转机制的了解,有助于理解应用执行过程中问题分析。
6)应用提交部分涵盖了应用提交集群流程、应用资源申请、Driver和Master交互原理和Executor返回结果处理的任务的整个执行生命周期。
7)Shuffle是连接Map和Reduce的桥梁。这个部分在日常调优中会常用到,比如我们常见的数据倾斜问题。
8)Job工作原理包含:触发Job的算子、Stage划分原理、Task的生命周期、ShuffleMapTask处理结果和ResultTask处理结果的更加细粒度的执行过程分析。
9)了解Spark Cache和Checkpoint机制,有助于深入认识spark内部缓存管理和数据持久化的流程。
10)了解Spark Broadcast和Accumulator 运行机制,有助于如何在整个应用执行过程中,如何更好的对数据进行共享,以此来提升数据加载效率。
11)Spark性能优化是真正考察前面内容是否学习扎实,比如算子调优、数据倾斜分析。
2、Spark零基础学习路线图
如果你有更好的学习方法和建议,可以在留言区交流讨论!

