Pandas的应用---DataFrame
目录
Pandas的数据帧DataFrame
DataFrame的功能特点
DataFrame与Series的区别与联系
创建DataFrame对象
通过各种形式数据创建DataFrame对象
读取其他文件创建DataFrame对象
DataFrame属性和方法
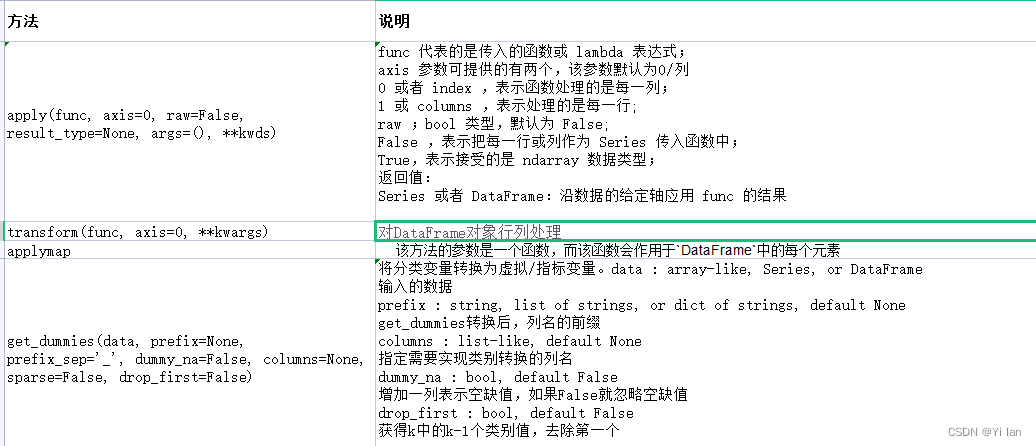
DataFrame常用方法
获取数据
索引和切片
重塑数据
concat函数
merge函数
数据处理
数据清洗
数据分析
数据可视化
总结
Pandas的数据帧DataFrame
DataFrame的功能特点
列可以有不同的类型
大小可变
标记轴(行和列)
可以对行和列执行算术运算
DataFrame与Series的区别与联系
区别:
series,只是一个一维结构,它由index和value组成
dataframe,是一个二维结构,除了拥有index和value之外,还拥有column
联系:dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series
创建DataFrame对象
1. 通过各种形式数据创建
DataFrame对象,比如ndarray,series,map,lists,dict,constant和另一个DataFrame2. 读取其他文件创建
DataFrame对象,比如CSV,JSON,HTML,SQL等
下面对这几种创建方式函数进行分析:
通过各种形式数据创建DataFrame对象
函数原型:
DataFrame( data, index, columns, dtype, copy)
参数说明:

代码如下:
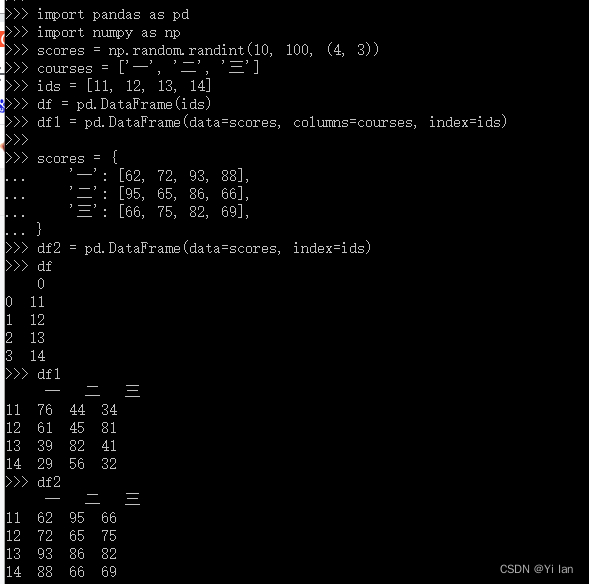
import pandas as pdimport numpy as npscores = np.random.randint(10, 100, (4, 3))courses = ['一', '二', '三']ids = [11, 12, 13, 14]df = pd.DataFrame(ids)df1 = pd.DataFrame(data=scores, columns=courses, index=ids)scores = { '一': [62, 72, 93, 88], '二': [95, 65, 86, 66], '三': [66, 75, 82, 69],}df2 = pd.DataFrame(data=scores, index=ids)dfdf1df2运行结果:
读取其他文件创建DataFrame对象
文件格式对应的读写操作如下:
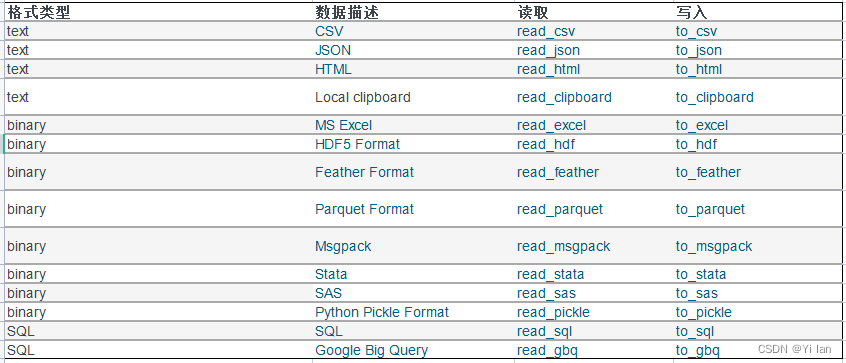
下面简单介绍几个常用的函数:
read_csv函数:读取CSV文件,read_csv函数的参数非常多,重要的参数如下:
● filepath_or_buffer:用来指定数据的路径的
● sep: 用来指定数据中列之间的分隔符的,接收一个str对象。默认分隔符为逗号
● delimiter:也是用来指定分隔符的,和参数sep功能相同,但默认值为None
● delim_whitespace:也是用来设置数据中的分隔符的。接收一个布尔值,表示是否将空白字符作为分隔符
● header: 如果数据中包含表头,或者说列名,这个参数用来指定表头在数据中的行号。接收一个int对象或者由int构成的列表对象。默认值是infer。infer的行为如下:如果没有指定● names参数,infer就等价于header=0;如果指定了names参数,此时的infer等价于header=None。
● names:用来指定列名的
● index_col:如果我们希望把数据中的某一列数据作为index,就可以使用这个参数。默认值为None
● usecols:一个文件中的数据可能有很多列,有时候我们只需要部分列,这时候可以使用usecols参数
● squeeze:如果我们希望读取的数据只有一列,默认返回的是DataFrame,如果我们希望返回Series,可以使用这个参数。参数接收的是布尔值,默认为False,表示返回DataFrame,如果是True,则返回Series
● prefix:prefix这个参数可以指定一个前缀,这样列的序号会和这个前缀拼接到一块构成列名
● mangle_dupe_cols:这个参数接收一个布尔值,如果是True,若数据中存在同名列,如有两个name列,则第一个列名保持不变,第二个name列将被重命名为name.1。如果是FALSE会抛出ValueError异常。
● skiprows:来指定在读取数据时,我们想跳过哪些行
● skipfooter:表示不读取数据的最后n行
● nrows:指定pandas一次性从文件中读取多少行数据,这在读取海量数据中很有用
● na_filter:控制pandas在读取数据时是否自动检测数据中的缺失值。这个参数就是用来控制这个行为的。默认为True表示检测缺失值,如果设置为False,表示不检测缺失值
● skip_blank_lines:判断是否跳过空行。如果指定为True,表示跳过空行。指定为False,不跳过空行,空行数据正常读取但被全部转换为缺失值nan。默认值为True
● encoding:指定读取文件时使用的编码,通常是utf-8,可以根据自己文件的实际编码进行设置
import pandas as pd# 如果导出的文件为gbk编码方式,导入数据的时候用gbkdf = pd.read_csv(r'test.csv',,encoding="gbk",nrows =2) #导入前两行dfpandas read_sql 和 to_sql 读写Mysql的参数详解
excel文件的函数请看:read_excel 和 to_excel 读写Excel的参数详解这篇文章
DataFrame属性和方法
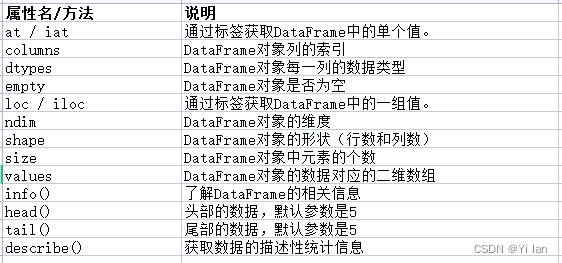
DataFrame常用方法
获取数据
索引和切片
`DataFrame`对象可以看做多个`Series`对象组成,所以它的“索引和切片”和`Series`对象是一样的。我们对`DataFrame`对象取某一行得到的就是一个`Series`对象。常用的索引和切片如下:
1. 使用整数索引
2.使用自定义的标签索引
3.切片操作
4.花式索引
5.布尔索引
重塑数据
所谓重塑数据就是数据合并,即把多分不在一起数据合并在一起。这样方便我们做统计分析。
concat函数
pd.concat(object,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verify_integrity=False)
参数说明
object:series,dataframe或则是panel构成的序列list
axis:需要合并连接的轴,0是行,1是列
join:连接的方式inner,或者outer;如果是 inner 得到的是两表的交集,如果是outer,得到的是两表的并集
join_axes:如果是join_axes的参数传入,可以指定根据那个轴来对齐数据
append:append是series和dataframe的方法,使用他就是默认沿着行(axis=0,列对齐)
ignore_index:使用ignore_index参数,为true时,合并的两个表就根据列字段对齐,然后合并,最后真理新的index
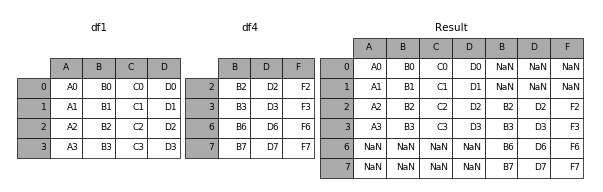
import pandas as pdids1 = [0, 1, 2, 3]scores1 = { 'A': ["A0", "A1", "A2", "A3"], 'B': ["B0", "B1", "B2", "B3"], 'C': ["C0", "C1", "C2", "C3"], 'D': ["D0", "D1", "D2", "D3"],}df1 = pd.DataFrame(data=scores1, index=ids1)ids4 = [2, 3, 6, 7]scores4 = { 'B': ["B2", "B3", "B6", "B7"], 'D': ["D2", "D3", "D6", "D7"], 'F': ["F2", "F3", "F6", "F7"],}df4 = pd.DataFrame(data=scores4, index=ids4)result=pd.concat([df1,df4],axis=1)result运行结果如下:
merge函数
merge( left, right, how="inner", on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=("_x", "_y"), copy=True, indicator=False, validate=None)
参数说明:
left 左表
right 右表
how 连接方式,inner、left、right、outer,默认为inner
on 用于连接的列名称
left_on 左表用于连接的列名
right_on 右表用于连接的列名
left_index 是否使用左表的行索引作为连接键,默认False
right_index 是否使用右表的行索引作为连接键,默认False
sort 默认为False,将合并的数据进行排序
copy 默认为True,总是将数据复制到数据结构中,设置为False可以提高性能
suffixes 存在相同列名时在列名后面添加的后缀,默认为(’_x’, ‘_y’)
indicator 显示合并数据中数据来自哪个表
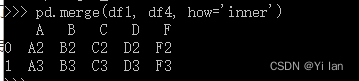
import pandas as pdids1 = [0, 1, 2, 3]scores1 = { 'A': ["A0", "A1", "A2", "A3"], 'B': ["B0", "B1", "B2", "B3"], 'C': ["C0", "C1", "C2", "C3"], 'D': ["D0", "D1", "D2", "D3"],}df1 = pd.DataFrame(data=scores1, index=ids1)ids4 = [2, 3, 6, 7]scores4 = { 'B': ["B2", "B3", "B6", "B7"], 'D': ["D2", "D3", "D6", "D7"], 'F': ["F2", "F3", "F6", "F7"],}df4 = pd.DataFrame(data=scores4, index=ids4)result = pd.merge(df1, df4, how='inner')result运行结果如下:
有时候我们合并完数据之后,我们也希望能重置索引,并使用默认索引,那么我们可以使用‘reset_index’函数或者‘set_index’函数,如下:
set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数说明:
append添加新索引,drop为False,inplace为True时,索引将会还原为列
reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')参数说明:
level:可以是int, str, tuple, or list, default None等类型。作用是只从索引中删除给定级别。默认情况下删除所有级别。
drop:bool, default False。不要尝试在数据帧列中插入索引。这会将索引重置为默认的整数索引。
inplace:bool, default False。修改数据帧(不要创建新对象)。
col_level:int or str, default=0。如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一层。
col_fill:object, default。如果列有多个级别,则确定其他级别的命名方式。如果没有,则复制索引名称。
返回:
DataFrame or None。具有新索引的数据帧,如果inplace=True,则无索引
数据处理
数据清洗
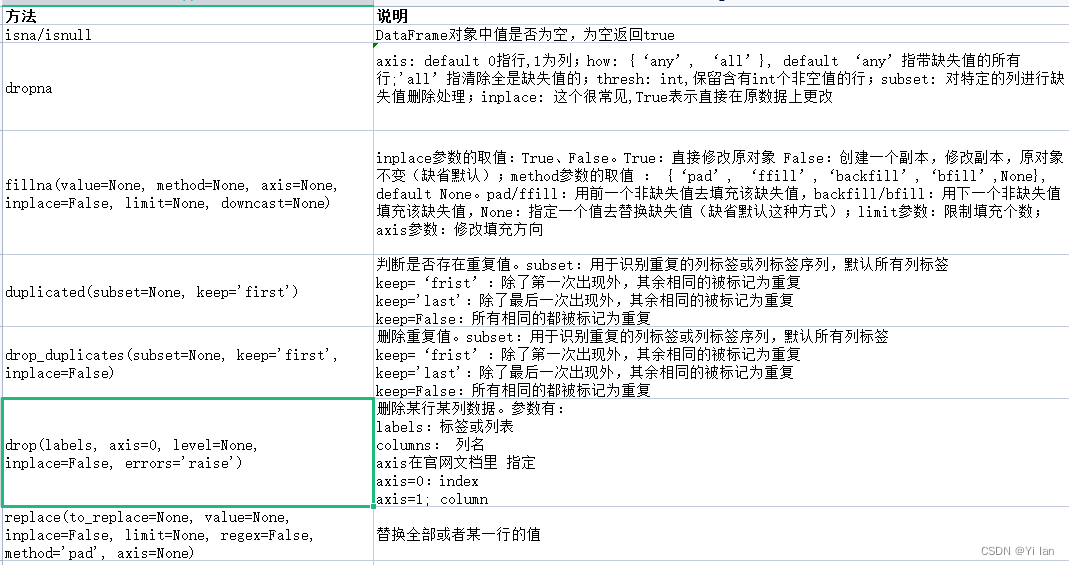
不管我们从哪里拿到数据,其实我们获取的数据都不会非常完美的。这些数据会有一些重复值或异常值,甚至还会有一些缺失值。那么我们要对数据进行处理分析的时候,就很希望这数据完美一些,所以我们在对数据处理分析之前,会清洗一下,经常使用的函数如下:
例子:
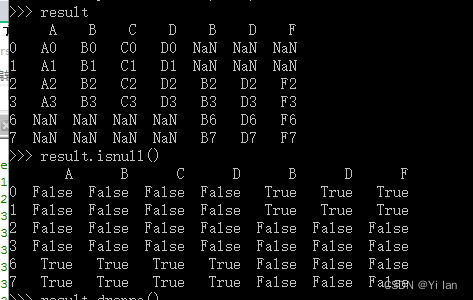
import pandas as pdids1 = [0, 1, 2, 3]scores1 = { 'A': ["A0", "A1", "A2", "A3"], 'B': ["B0", "B1", "B2", "B3"], 'C': ["C0", "C1", "C2", "C3"], 'D': ["D0", "D1", "D2", "D3"],}df1 = pd.DataFrame(data=scores1, index=ids1)ids4 = [2, 3, 6, 7]scores4 = { 'B': ["B2", "B3", "B6", "B7"], 'D': ["D2", "D3", "D6", "D7"], 'F': ["F2", "F3", "F6", "F7"],}df4 = pd.DataFrame(data=scores4, index=ids4)result=pd.concat([df1,df4],axis=1)result.isnull()运行结果如下:
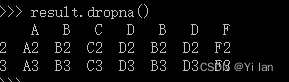
删除这些缺失值,如下:
对空值进行填充,如下:
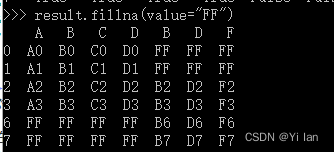
重复值的判断:
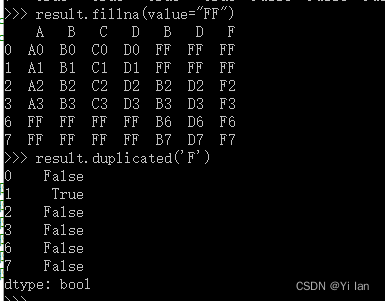
数据转换
代码如下:
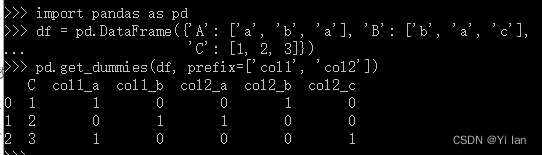
import pandas as pddf = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'], 'C': [1, 2, 3]})pd.get_dummies(df, prefix=['col1', 'col2'])运行结果如下:
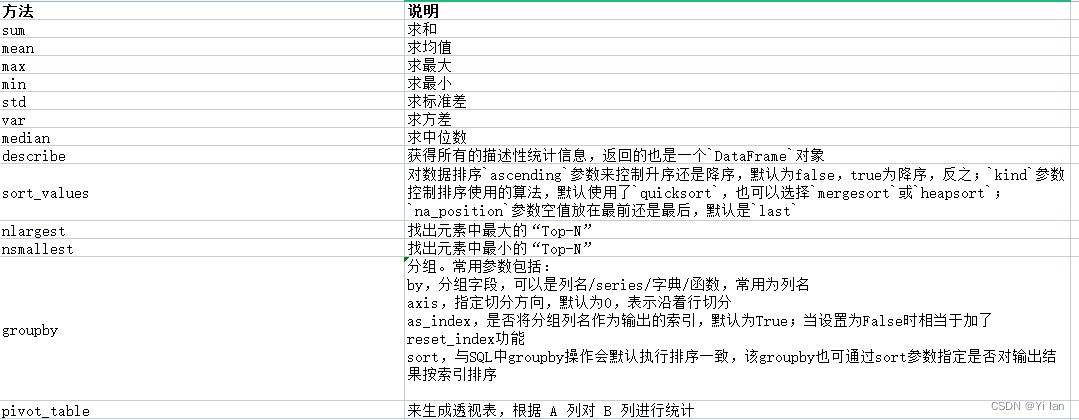
数据分析
我们拿到数据最重要的就是分析数据,从数据中迅速的解读出有价值的信息,然后解决我们当中的问题,那么有哪些统计和分析数据相关的方法呢?如下:
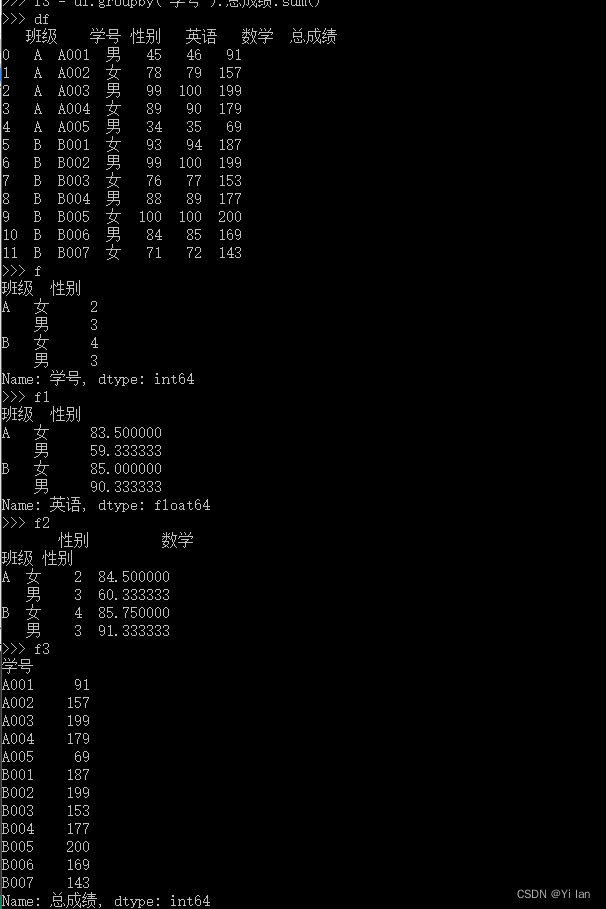
我们使用一个实际的例子说明吧,如下:
import pandas as pdimport matplotlib.pyplot as pltdf=pd.read_excel(r"test.xlsx",sheet_name=0)f=df.groupby(["班级","性别"])["学号"].count()f1=df.groupby(["班级","性别"])["英语"].mean()f2=df.groupby(["班级","性别"]).aggregate({"性别":"count","数学":"mean"})df['总成绩'] = df['数学'] + df['英语']f3 = df.groupby('学号').总成绩.sum()f4 = pd.pivot_table(df, index='学号', values='总成绩', aggfunc='sum')f4.plot(figsize=(8, 4), kind='bar')plt.xticks(rotation=0)plt.show()运行分析结果如下:
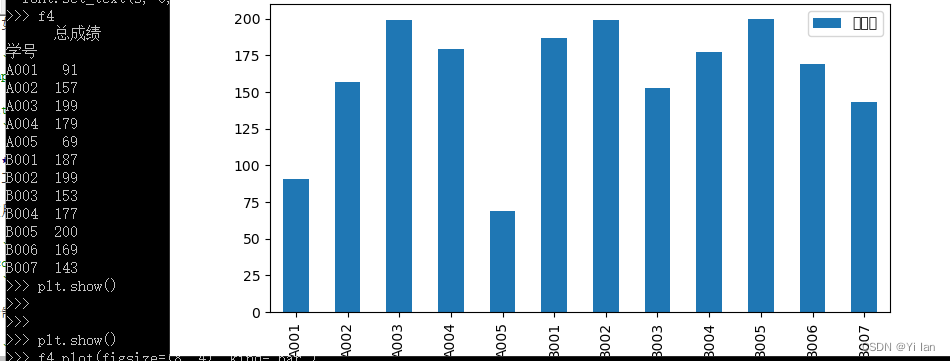
数据可视化
一图胜千言,我们对数据进行透视的结果,最终要通过图表的方式呈现出来,因为图表具有极强的表现力,能够让我们迅速的解读数据中隐藏的价值。`DataFrame`对象提供了`plot`方法来支持绘图,底层仍然是通过`matplotlib`库实现图表的渲染。呈现结果如“数据分析”篇章运行结果所示。
总结
我们主要介绍了pandas当中‘DataFrame’对象的经常使用的一些知识点和方法,熟练掌握对于我们搞定数据分析非常有帮助。如果大家想学习更多pandas相关方法,请看pandas官网 。。希望该文章对你有所帮助,哈哈哈哈哈哈~ 感谢阅读!觉得能帮助到您,可以点个赞,关注一下哈~谢谢~

