MYSQL查询执行过程
MySQL逻辑架构
首先我们先来了解一下MySQL各组件之间如何协同工作的,直接看下图:
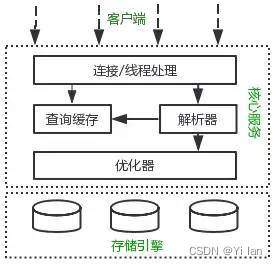
MySQL逻辑架构整体分为三层,分别是客户端层,核心服务层,存储引擎层:
客户端层:客户端层是最上层,主要处理连接处理、授权认证、安全等功能,并非MYSQL特有
核心服务层:核心服务层主要处理查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)、存储过程、触发器、视图等
存储引擎层:负责MySQL中的数据存储和提取。核心服务层通过API与其通信。
MySQL查询过程
查询执行的流程,如下图:
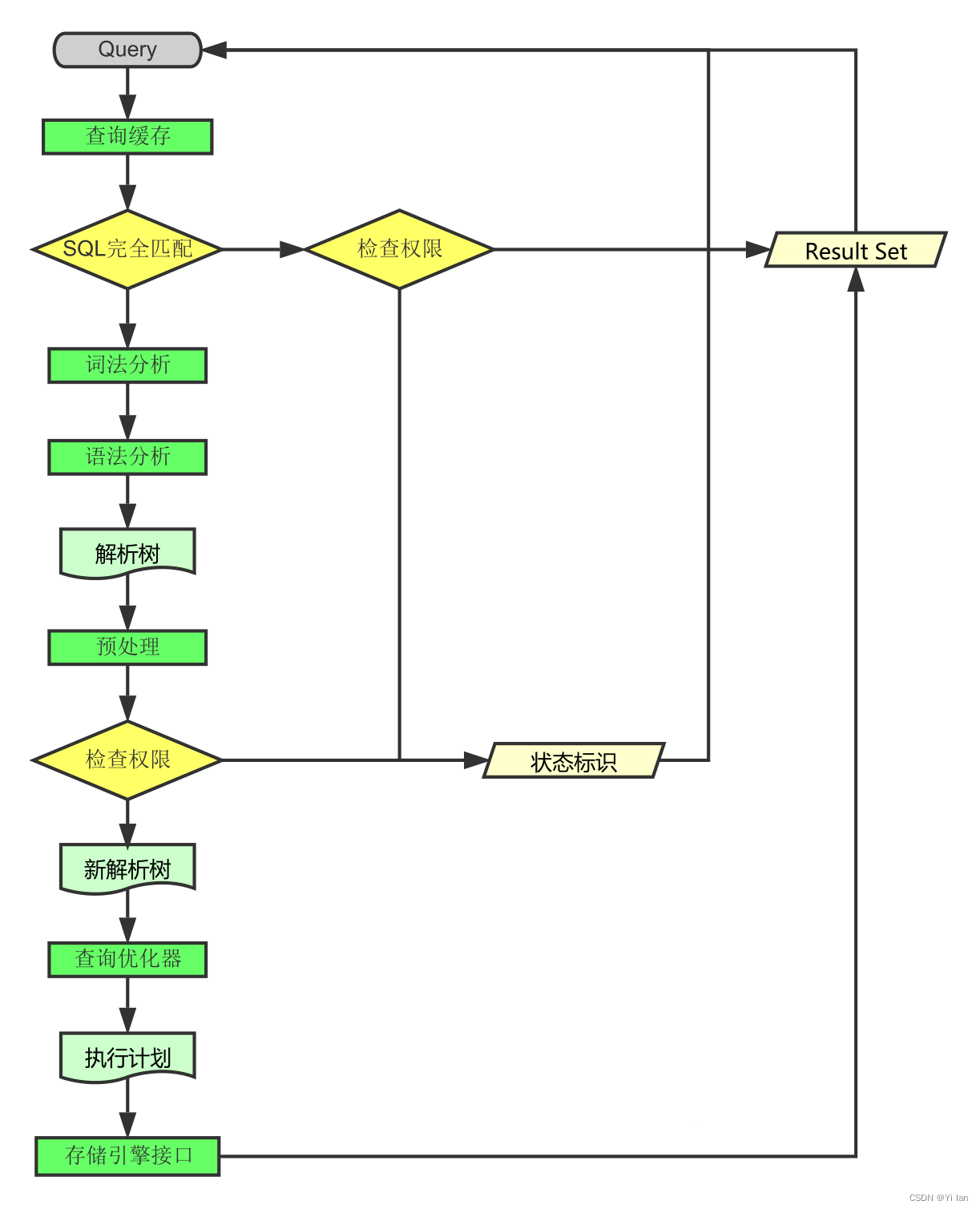
查询过程:
1. 先查询缓存,检查Query语句是否完全匹配,接着再检查是否具有权限,都成功则直接取数据返回
2. 上一步有失败则转交给‘命令解析器’,经过词法分析,语法分析后生成解析树
3. 接下来是预处理阶段,处理解析器无法解决的语义,检查权限等,生成新的解析树
4. 再转交给对应的模块处理
5. 如果是SELECT查询还会经由‘查询优化器’做大量的优化,生成执行计划
6. 模块收到请求后,通过‘访问控制模块’检查所连接的用户是否有访问目标表和目标字段的权限
7. 有则调用‘表管理模块’,先是查看table cache中是否存在,有则直接对应的表和获取锁,否则重新打开表文件
8. 根据表的meta数据,获取表的存储引擎类型等信息,通过接口调用对应的存储引擎处理
9. 上述过程中产生数据变化的时候,若打开日志功能,则会记录到相应二进制日志文件中
总结起来就是:
客户端向MySQL服务器发送一条查询请求
服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
服务器进行SQL解析、预处理、再由优化器生成对应的执行计划
MySQL根据执行计划,调用存储引擎的API来执行查询
将结果返回给客户端,同时缓存查询结果
但是,这中间会有一些参数对其进行控制,比如当查询语句很长的时候,需要设置max_allowed_packet参数;query_cache_type参数来控制是否使用缓存等。
SQL解析
SQL解析执行顺序:
FROM
ON
JOIN
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
ORDER BY
LIMIT
left join、right join、join和inner join的区别
连接查询join经常使用,但是一直没有完全搞明白各种用法的区别,left join、right join、join和inner join等等各种join,到底有什么区别? 官网给出的总结性质的图:
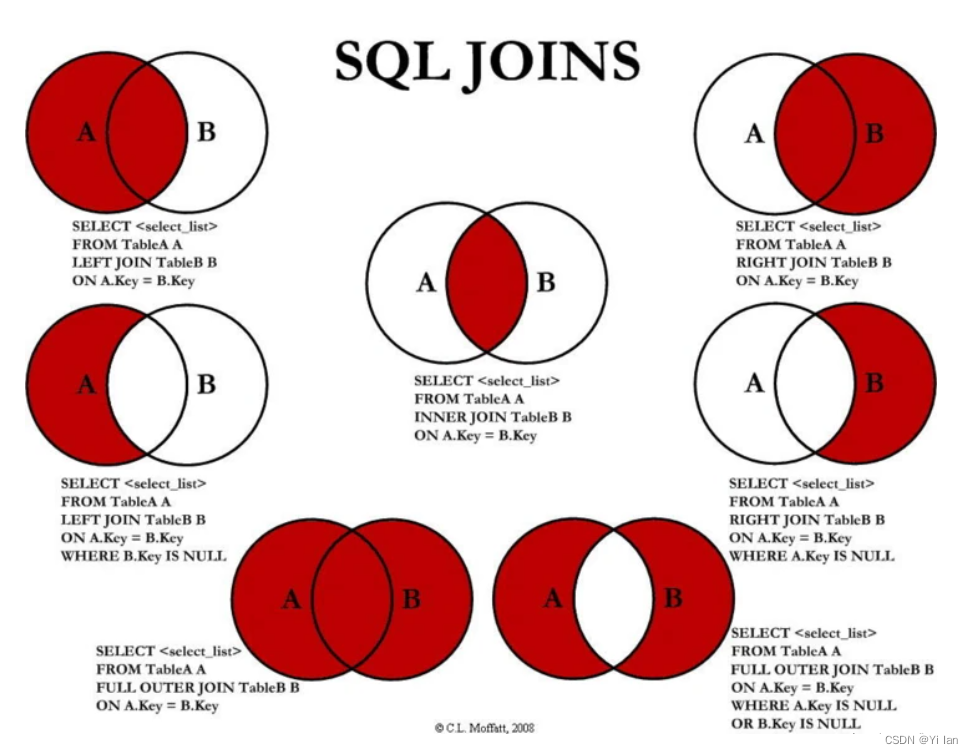
这张图总结了所有join的区别,如果只是看的话,那么还是看不懂,必须自己动手试试。
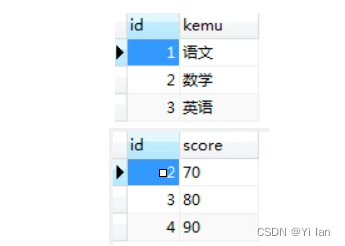
建立两张表来进行连接查询,第一张表命名为kemu,第二张表命名为score:
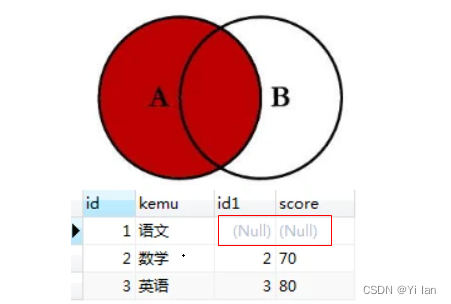
left join
顾名思义,就是“左连接”,表1左连接表2,以左为主,表示以表1为主,关联上表2的数据,查出来的结果显示左边的所有数据,然后右边显示的是和左边有交集部分的数据。如下:
select *from kemu left join score on kemu.id = score.id
结果:
right join
“右连接”,表1右连接表2,以右为主,表示以表2为主,关联查询表1的数据,查出表2所有数据以及表1和表2有交集的数据,如下:
select * from kemu right join score on kemu.id = score.id
结果:

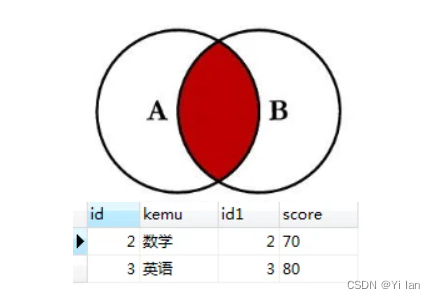
join
join,其实就是“inner join”,为了简写才写成join,两个是表示一个的,内连接,表示以两个表的交集为主,查出来是两个表有交集的部分,其余没有关联就不额外显示出来,这个用的情况也是挺多的,如下
select * from kemu join score on kemu.id = score.id
结果:
在Mysql中using()用于两张表的join查询,而且在using()中指定的列在两个表中均存在,并且作为join的条件。
比如:
select a.*, b.* from a left join b on a.id = b.id
等价于:
select a.*, b.* from a left join b using(id);

