追忆经典,燃烧小宇宙!识别出最强的黄金圣斗士!
文章目录
- 摘要
- 选择主题
- 制作数据集
-
- 视频截取
- 通过搜索
- 统一名字和格式
-
- 统一名字
- 统一图片格式
- 制作测试集
- 总结
摘要
以前写文章用数据集是从一个公开的数据集里面抽取了部分数据做成的数据集,有人反映说不知道test的真值,那怎么办呢?
那我们就一起制作一个吧!
这篇文章会详细描述图像分类数据集的制作过程。欢迎大家一起学习!
选择主题
为了大家不觉得枯燥增加一些趣味性,我选用动漫人物做数据集,一个让80、90后无法拒绝的动漫《圣斗士星矢》!!!

本来想选5小强,不过5小强的辨识度太高了,没有难度,所以选黄金圣斗士!不知道大家是否还记着他们,在开始前,我们一起先熟悉一下他们。
- 白羊座 穆

- 金牛座 阿鲁迪巴

- 处女座 沙加

- 巨蟹座 迪斯马斯克

- 双子座 撒加

- 水瓶座 卡妙

- 山羊座 修罗

- 射手座 艾俄洛斯

- 狮子座 艾奥里亚

- 天秤座 童虎

- 天蝎座 米罗

- 双鱼座 阿布罗狄

黄精圣斗士们,集合!!

制作数据集
这章,我们一起来获取图片,获取图片的方法有两种:一种是将视频切成图片,再选取和截取目标。
一种是在搜索里面搜素材然后下载到本地。
视频截取
选用的视频有:《圣斗士星矢——黄金十二宫》、《圣斗士星矢 冥王哈迪斯冥界篇 后章》、《圣斗士星矢 黄金魂 -soul of gold-》。
网盘地址:https://pan.baidu.com/s/1wCRaX1Eo3xXcvDKRYxnufQ?pwd=hyoc 提取码:hyoc
用到的工具:ffmpeg,安装方法见:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/117842049
将ffmpeg 安装完成后,我们就可以开始将视频切成图片了。执行命令:
ffmpeg -i 1.MP4 -f image2 -vf fps=1/2 -qscale:v 2 image2/img1%04d.jpg-i: 视频路径
-f: 图片格式
fps=1/2: 每2s取1帧
image2/img1%04d.jpg: 生成的图片命名格式
截取的图片:


通过搜索
搜索,我选用的必应,执行代码:
import osimport sysimport timeimport urllibimport requestsimport refrom bs4 import BeautifulSoupimport timeheader = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'}url = "https://cn.bing.com/images/async?q={0}&first={1}&count={2}&scenario=ImageBasicHover&datsrc=N_I&layout=ColumnBased&mmasync=1&dgState=c*9_y*2226s2180s2072s2043s2292s2295s2079s2203s2094_i*71_w*198&IG=0D6AD6CBAF43430EA716510A4754C951&SFX={3}&iid=images.5599"def getImage(url, count): '''从原图url中将原图保存到本地''' try: time.sleep(0.5) urllib.request.urlretrieve(url, './imgs/穆_' + str(count + 1) + '.jpg') except Exception as e: time.sleep(1) print("本张图片获取异常,跳过...") else: print("图片+1,成功保存 " + str(count + 1) + " 张图")def findImgUrlFromHtml(html, rule, url, key, first, loadNum, sfx, count): '''从缩略图列表页中找到原图的url,并返回这一页的图片数量''' soup = BeautifulSoup(html, "lxml") link_list = soup.find_all("a", class_="iusc") url = [] for link in link_list: result = re.search(rule, str(link)) # 将字符串"amp;"删除 url = result.group(0) # 组装完整url url = url[8:len(url)] # 打开高清图片网址 getImage(url, count) count += 1 # 完成一页,继续加载下一页 return countdef getStartHtml(url, key, first, loadNum, sfx): '''获取缩略图列表页''' page = urllib.request.Request(url.format(key, first, loadNum, sfx), headers=header) html = urllib.request.urlopen(page) return htmlif __name__ == '__main__': name = "白羊座穆" # 图片关键词 path = './imgs/' # 图片保存路径 countNum = 500 # 爬取数量 key = urllib.parse.quote(name) first = 1 loadNum = 35 sfx = 1 count = 0 rule = re.compile(r"\"murl\"\:\"http\S[^\"]+") if not os.path.exists(path): os.makedirs(path) while count < countNum: html = getStartHtml(url, key, first, loadNum, sfx) count = findImgUrlFromHtml(html, rule, url, key, first, loadNum, sfx,count) first = count + 1 sfx += 1修改name字段即可,然后过滤一下下载的图片。
经过上面的操作,我们已经得到了大量的图片,将图片整理到各自的文件夹中,如下图:

到这里一个比较粗糙的数据集就制作完成了,由于我们采用了多种方式获取的图片,存在格式上和名字上不统一,接下来我将这些图片的格式和名字统一处理。
统一名字和格式
统一名字
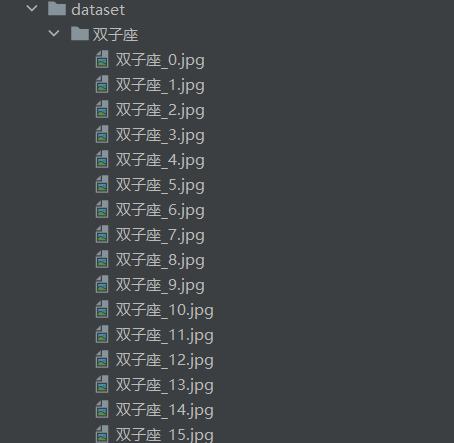
将图片的名字统一成“类别_num”的格式。执行代码:
import oslist_dir=os.listdir('dataset')for dir_name in list_dir: image_list=os.listdir("dataset/"+dir_name) for i in range(len(image_list)): print(i) img_path=("dataset\\"+dir_name+"\\"+image_list[i]) image_name_new=dir_name+"_"+str(i)+"."+image_list[i].split('.')[-1] image_name_new_path="dataset/"+dir_name+"/"+image_name_new print(image_name_new_path) os.rename(img_path, image_name_new_path)运行结果:

运行之后,名字统一了,但是图片的格式尚未统一,接下来统一图片的格式。
统一图片格式
将图片统一成“jpg”的格式,这是数据集常用的格式。执行代码:
import osimport globfrom PIL import Imageimage_list = glob.glob('dataset/*/*.*')for image_name in image_list: imag_suffix = image_name.split('.')[-1] if imag_suffix != 'jpg': im = Image.open(image_name) im = im.convert('RGB') image_name_new = image_name.split('.')[-2] + ".jpg" print(image_name_new) im.save(image_name_new, quality=95) os.remove(image_name)运行结果:
在统一格式和名字后,接下来我们抽取一些图片做测试集
制作测试集
测试集是从我们上面制作的数据集中随机抽取一部分,请记住:随机。执行代码:
import shutilimport globimage_list = glob.glob('dataset/*/*.*')from sklearn.model_selection import train_test_splitimport osos.makedirs("test",exist_ok=True)trainval_files, test_files = train_test_split(image_list, test_size=0.05, random_state=42)for file in test_files: file=file.replace("\\","/") file_name=file.split("/")[-1] print(file_name) file_new_path="test/"+file_name shutil.move(file,file_new_path)运行结果:

到这里我们完成了数据集的制作。
总结
这篇文章讲述了如何制作图像分类数据集,欢迎大家点赞,收藏和转发。如果有不对的地方,还请大家指出!


