基于Kylin的数据统计分析平台架构设计与实现
目录
1 前言
2 关键模块
2.1 数据仓库的搭建
2.2 ETL
2.3 Kylin数据分析系统
2.4 数据可视化系统
2.5 报表模块
3 最终成果
4 遇到问题
1 前言
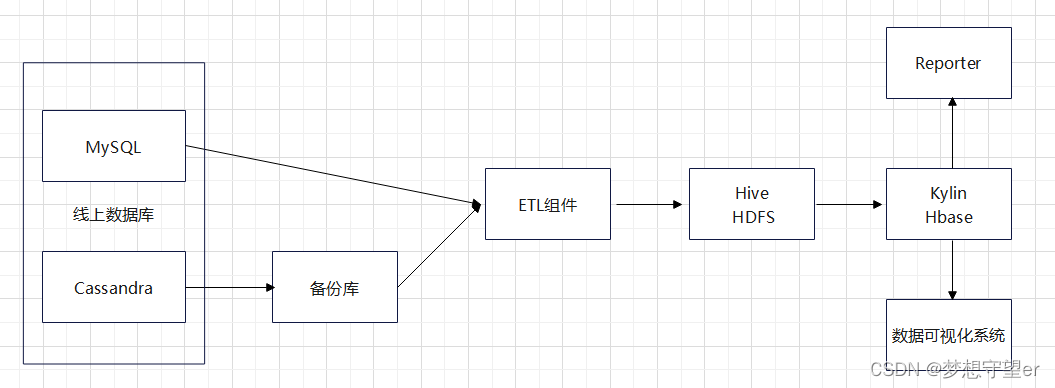
此项目是我在TP-LINK公司云平台部门做的一个项目,总体包括云上数据自动化统计流程的设计和组件的开发。目的是为了对云平台上的设备和用户数据做多维度的统计和分析,以及便于观察设备数据的历史趋势,让业务部门更好地做业务决策。整体的架构与数据流向如下图所示,采用Hive做数据仓库,使用Spark实现一个ETL组件,完成数据的抽取、转换和加载,引入kylin做数据预计算,另外开发报表模块和数据可视化系统,对接kylin获取统计数据。每天Hive的新增数据量20多个G,kylin预计算之后的数据压缩比为5%左右。
2 关键模块
2.1 数据仓库的搭建
数据仓库选择Hive,存储主要分为三类数据,包括设备、用户和生产数据。表的设计采用星型模型,维度表有model表,事实表有设备首次连接时间、设备在线状态表等。每天全量拉取线上数据库的数据,数据仓库保留最近两天的数据。对于个别大数据量的表采用冷热数据分离的方式,设置冷热数据分割时间线,每次只拉取热数据,更新被update的冷数据,再将冷热数据合并。定时任务脚本定时清理过期分区的数据。
2.2 ETL
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程。ETL组件使用Spark框架,从线上数据库和备份库抽取数据到内存中做计算和转换,然后加载到数据仓库Hive。ETL一方面做数据清洗,过滤掉不合法的值,一方面做数据粒度的转换,例如时间字段转换成粒度小的衍生字段。由于整体线上数据库数据量不是特别大,所以选择全量抽取。
2.3 Kylin数据分析系统
原先我们采用的是使用spark内存计算技术对数据做各种维度组合做聚合计算,将统计值存于mysql中,用户从mysql中做二次聚合查询结果耗时过长,所以调研一种OLAP引擎旨在提高查询效率。kylin是国内开发的一款开源的OLAP引擎,支持对数据做多维度的预计算,利用以空间换时间的思想,根据用户建立的用户模型做聚合计算,生成对应的多个数据集合cubeid,提供sql的方式查询,提高数据查询效率。数据模型主要包括设备数据、用户数据和设备生产数据。维度众多情况下预计算后的数据量庞大,需要对cube构建做优化,主要通过两方面优化。一是使用聚合组,聚合组是通过分组的方式划分维度,同一组中的维度才能被聚合计算,减少维度组合的情况,从而减少cubeid。二是使用cubeplanner进行优化,该方式需要开启dashboard对历史统计请求监控统计,根据统计数据包括cubei命中频率以及采用贪心算法,经过多轮计算,因为有些cubeid可以根据其他cubeid计算,每一轮计算效益比最大的cubeid,最终到达膨胀率阈值后停止。
2.4 数据可视化系统
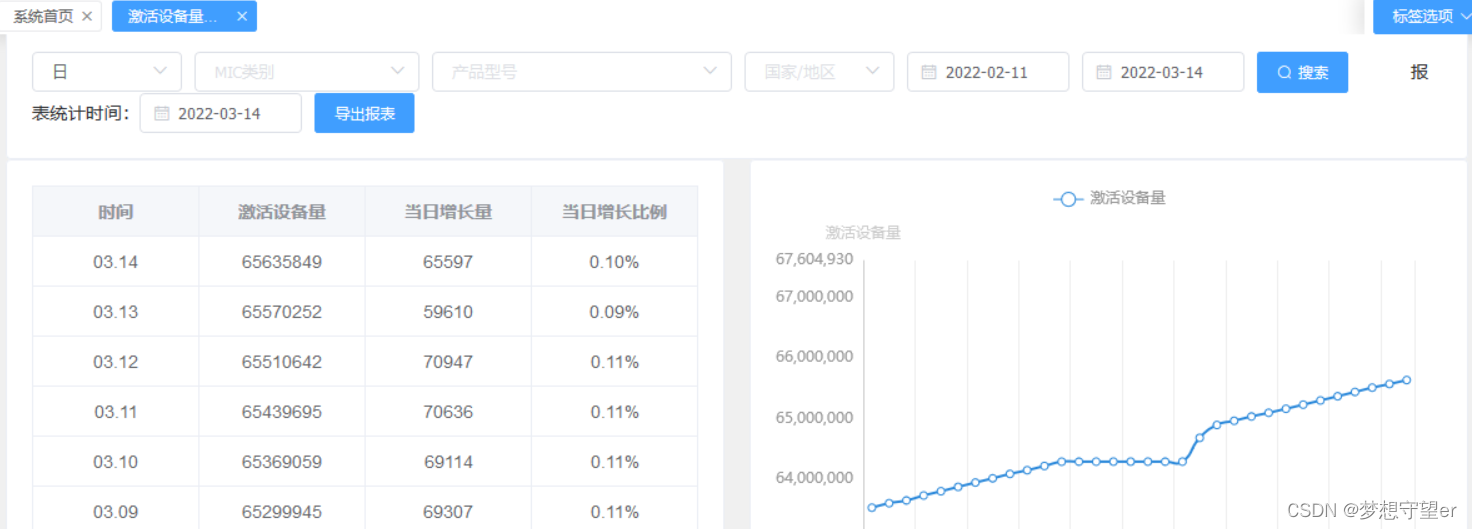
数据可视化系统用python(Django)构建,前端使用vue,前端接受用户选择的查询维度,以表格和折线图的形式展示结果数据。
2.5 报表模块
报表模块是一个python模块,根据定义好的数据度量,获取kylin统计数据,生成Excel。度量数据主要设备和用户数据在多维度下的各个场景下的聚合值,如设备24小时内活跃数量、绑定账号数量等。生成的Excel表格包含了全部报表数据,每日邮件定时发出。另外还有定制报表,这一部分是业务部门根据自己的特定需求提出,不包含在上面的常规报表模块,需要定制化开发。
3 最终成果
最终实现了千万设备数量每日自动化地统计分析,支持数据可视化系统查询多维度数据,数据查询效率相比于原来的mysql查询提高10倍左右。
4 遇到问题
- 因系统重启并且误用tmp临时目录作为hdfs的存储目录,导致hdfs和kylin的所有元数据和业务数据都丢失,解决方案为重新创建kylin model和cube等信息,hdfs重新建立数据仓库表,已生成的统计数据丢失了,可视化系统改为从旧数据统计系统获取数据。
- 数据分析任务失败没能及时发现,需要人工检查,有时候需要外部门反馈才发现,恢复数据困难。解决方案为增加任务执行失败告警,监控各个任务的执行时间和结果,建立超时和失败等告警,及时发现问题,及时恢复数据。
 超强干货来袭
超强干货来袭  云风专访:近40年码龄,通宵达旦的技术人生
云风专访:近40年码龄,通宵达旦的技术人生

