一、25. K 个一组翻转链表
1.1、206. 反转链表
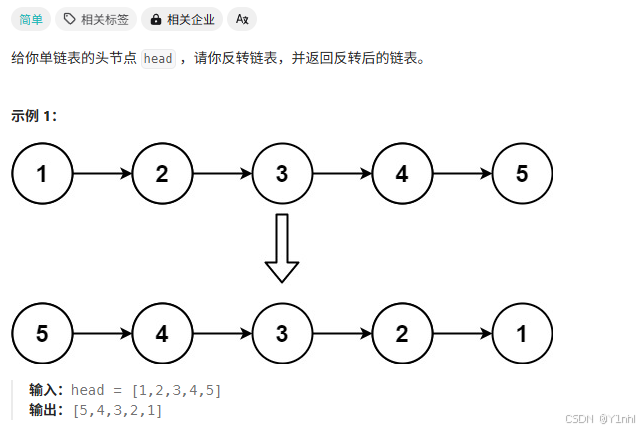
class ListNode:def __init__(self, val=0, next= node):self.val = valself.next = nextclass Solution:def reverseList(self, head):pre = Nonecur = headwhile cur:next = cur.nextcur.next = prepre = curcur = nextreturn pre
1.2、92. 反转链表 II
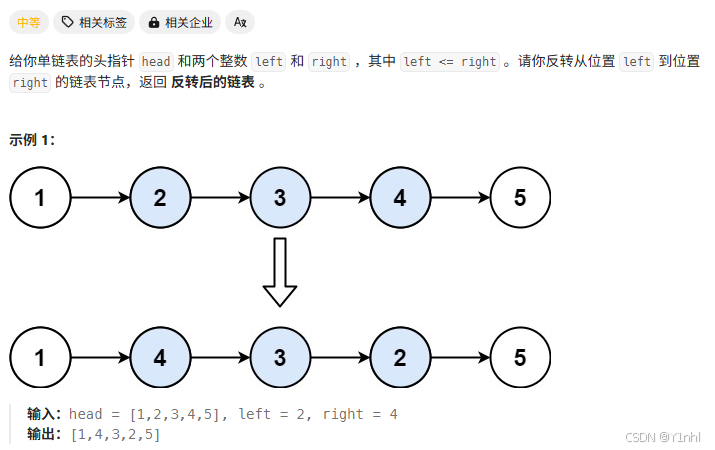
- 思路:
整体来看,1是反转前的第left个节点(p0.next),pre(4)是反转的后的头节点,cur是当前遍历到的节点下一个(5)。
class Solution:def reverseBetween(self, head, left, right):p0 = dummy = ListNode(next = head) for _ in range(left-1):p0 = p0.next pre = Nonecur = p0.next for _ in range(right-left+1)nxt = cur.nextcur.nxt = prepre = curcur = nxtp0.next.next = curp0.next = prereturn dummy.next
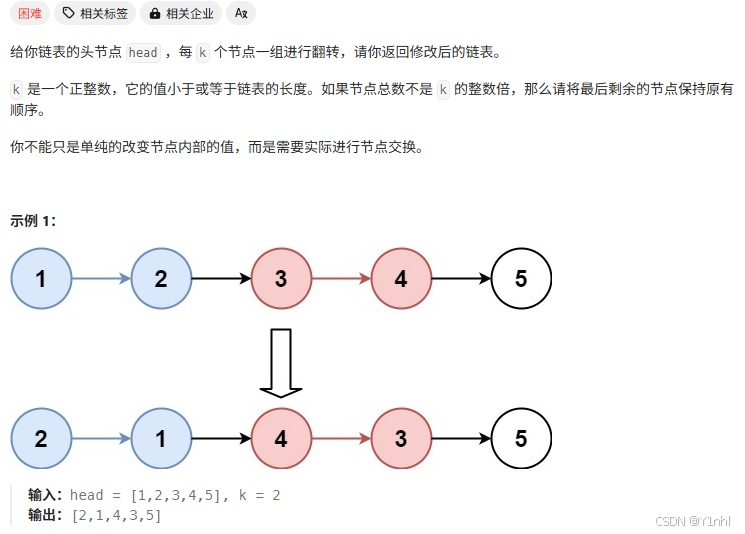
class Solution:def reverseKGroup(self, head, k):n = 0cur = headwhile cur:n += 1cur = cur.nextp0 = dummy = ListNode(next = head)pre = Nonecur = headwhile n >= k:n -= kfor _ in range(k):nxt = cur.nextcur.next = prepre = curcur = nxtnxt = p0.nextnxt.next = curp0.next = prep0 = nxt
二、148. 排序链表
2.1、876. 链表的中间结点
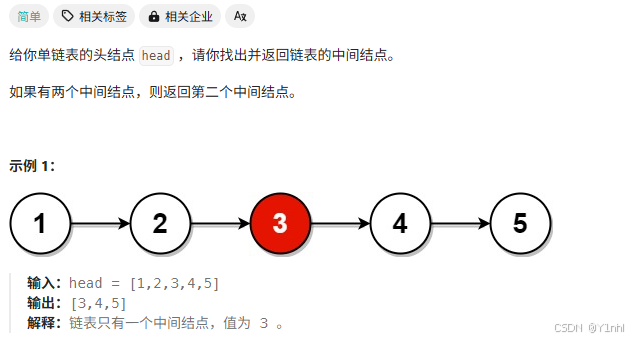
class Solution: def middleNode(self, head: Optional[ListNode]) -> Optional[ListNode]: t1 = t2 = head while t2 and t2.next: t1 = t1.next t2 = t2.next.next return t1
2.2、21. 合并两个有序链表
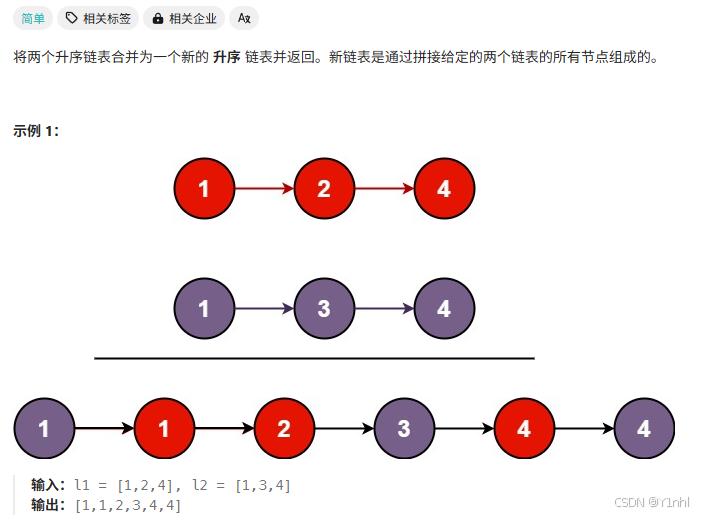
class Solution: def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]: dummy = ListNode() cur = dummy while list1 and list2: if list1.val <= list2.val: cur.next = list1 cur = cur.next list1 = list1.next else: cur.next = list2 cur = cur.next list2 = list2.next if list1: cur.next = list1 else: cur.next = list2 return dummy.next
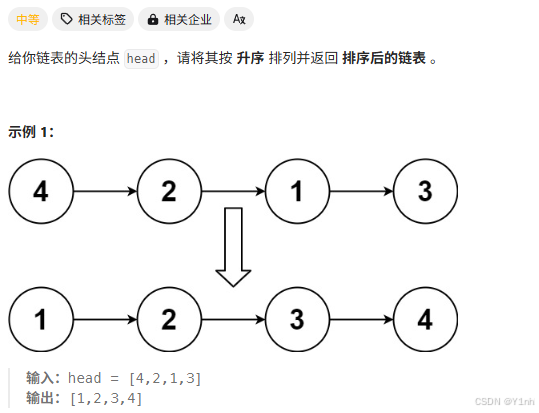
- 思路1:归并排序
找到链表的中间节点,断开为前后两端,分别排序前后两端,排序后,再合并两个有序链表。
- 代码1:
class Solution: def middleNode(self, head: Optional[ListNode]) -> Optional[ListNode]: slow = fast = head while fast and fast.next: pre = slow slow = slow.next fast = fast.next.next pre.next = None return slow def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]: cur = dummy = ListNode() while list1 and list2: if list1.val < list2.val: cur.next = list1 list1 = list1.next else: cur.next = list2 list2 = list2.next cur = cur.next cur.next = list1 if list1 else list2 return dummy.next def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]: if head is None or head.next is None: return head head2 = self.middleNode(head) head = self.sortList(head) head2 = self.sortList(head2) return self.mergeTwoLists(head, head2)

