如何通过阿里云服务器部署hexo博客(超详细)_阿里云部署hexo

👏大家好!我是和风coding,希望我的文章能给你带来帮助!
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
📝点击 我的主页 还可以看到和风的其他内容噢,更多内容等你来探索!
📕欢迎参观我的个人网站:Gentlewind

文章目录
前置知识:
- linux基础
- git基础
- nginx基础
- money(需要购买阿里云服务器和域名)
引言:
Hexo是一款基于Node.js的静态博客框架,依赖少易于安装使用,是搭建博客的首选框架。本篇教程记述了作者用阿里云轻量应用服务器部署Hexo的详细过程,步骤完整,操作性强,一起来看看吧~
步骤一:本地电脑部署
1、安装nodeJS
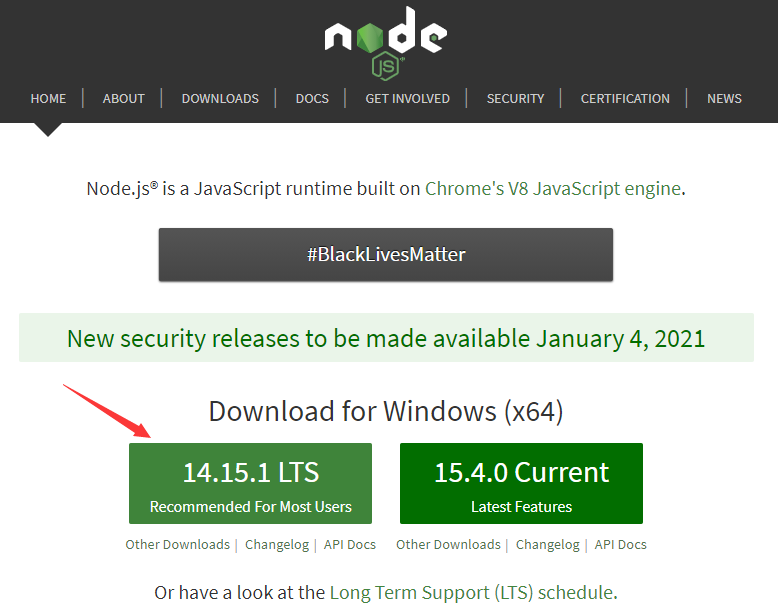
浏览器进入NodeJS 官网,安装 LTS(Long Term Support)版本。
验证nodeJS是否安装成功:
按住win+R,输入cmd,进入 cmd 命令行工具,输入node -v查看 node 版本,若出现版本信息(如下图示),则说明 node 安装成功。

2.、安装Hexo
i. 安装Hexo
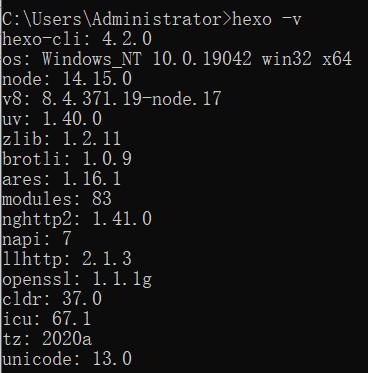
在 cmd 命令行中输入npm install hexo-cli -g,安装 hexo。完成后输入hexo -v查看版本信息,确认安装成功。
ii. 初始化根目录
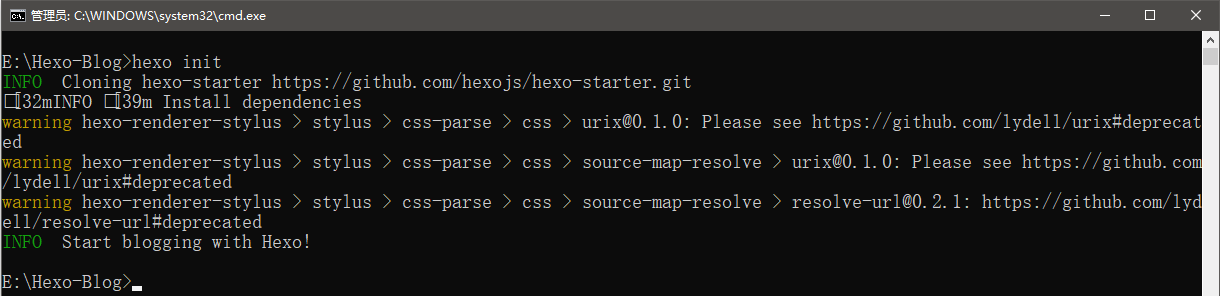
创建文件夹Hexo-Blog,在 cmd 命令行中进入该目录,输入hexo init初始化根目录。
iii. 本地查看
输入hexo g&&hexo s(生成静态文件,并开启本地服务器)
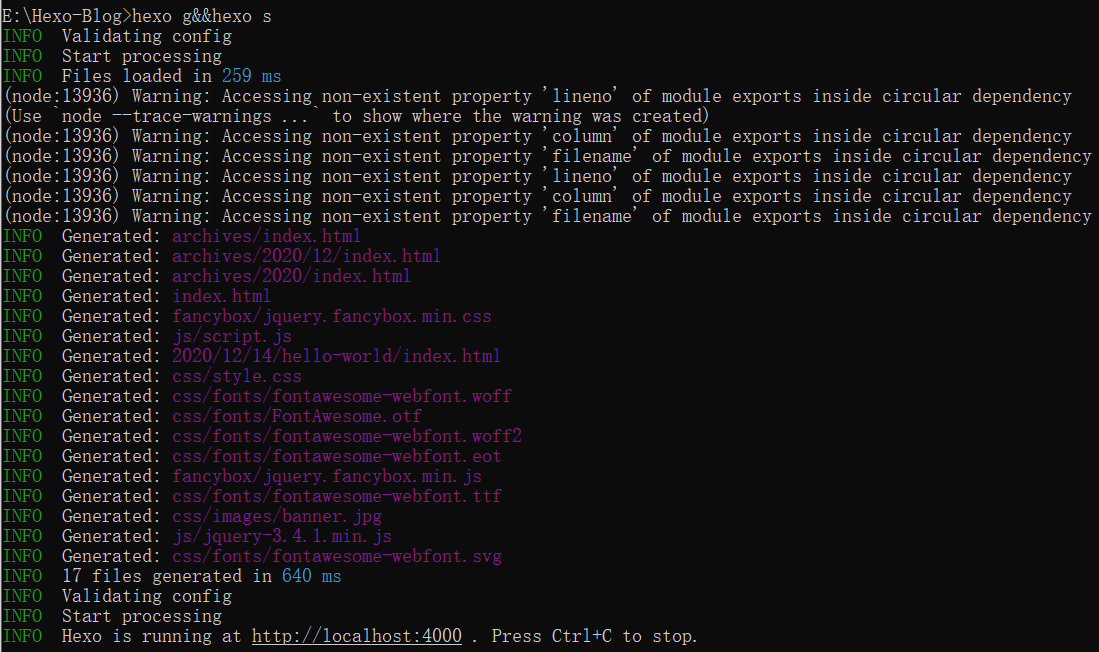
根据提示,在浏览器中打开http://localhost:4000,即可看到初始的博客页面。
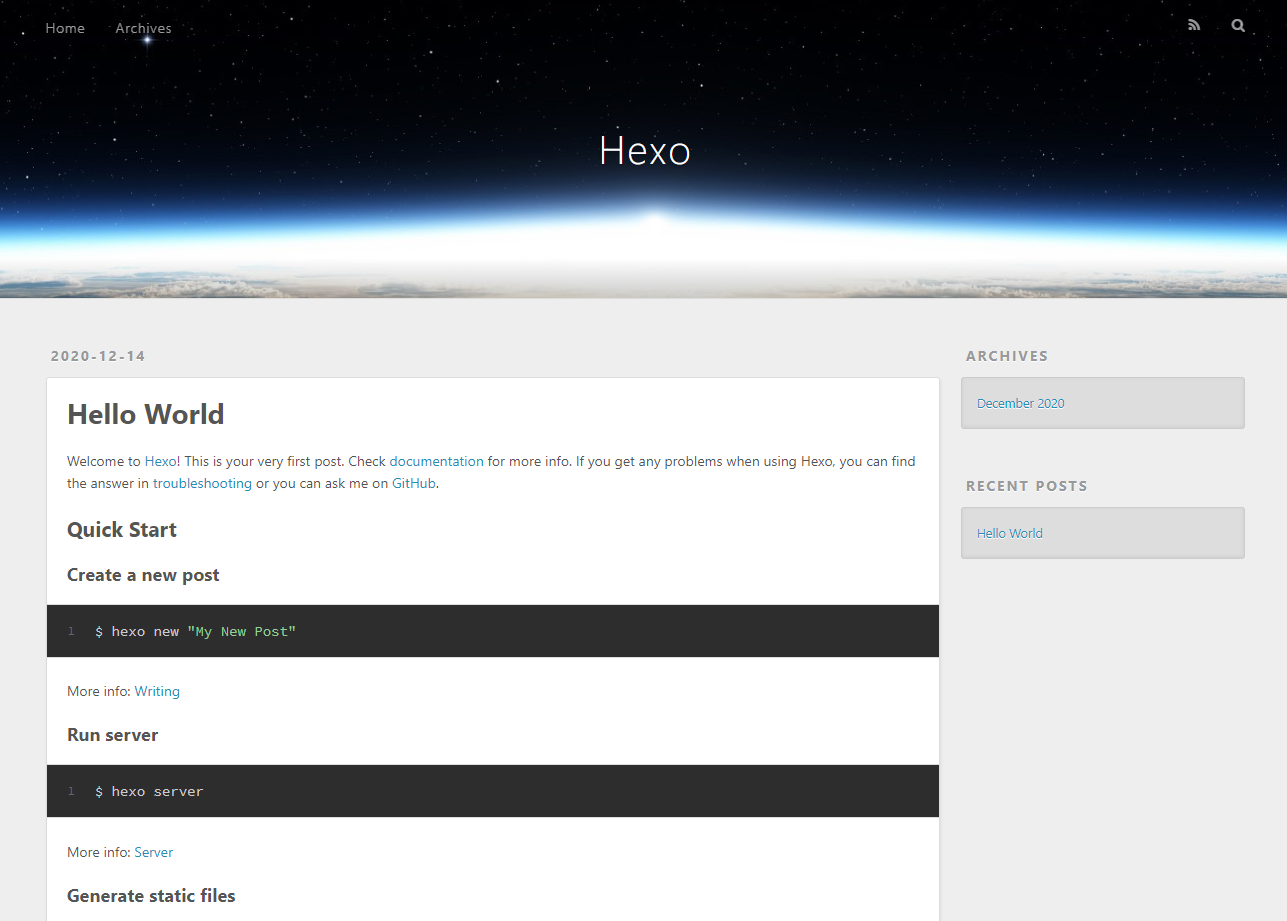
iv. 美化博客
对自己的博客进行更改样式、美化、增删功能、发布文章等操作,就不展开介绍了。
步骤二:购买域名
本教程后续涉及域名处,以test.top为例进行演示;读者在自己学习部署时,应将此域名替换为自己网站的域名。
详细了解可以参考这篇博客:购买域名后如何使用 | Gentle Wind
1、购买域名
在阿里云上可以购买域名,.com/.cn/.top/.xyz/.store等域名一应俱全,部分域名只需要1块钱。
2、域名备案
域名绑定国内的服务器,必须要进行备案操作,否则将无法访问。从提交备案信息,到管局审核通过,大概15天左右(看运气)

有不懂的可以看这篇博客:
https://zhuanlan.zhihu.com/p/422965705
3、域名解析
域名解析是把域名指向网站空间 IP,

