1分钟极速生成简历表单,AI与Flash Table实战让你领先一步
前言
过去,开发和业务人员在制作复杂表单时,常常遇到流程繁琐、效率低下等问题。传统开发方式不仅耗时,还容易出现数据整合和交互设计的难题。现在有一个热门了低代码平台Flash Table,它简化了表单开发流程,让用户可以更快地创建和管理复杂表单,提高了整体效率。现在,开发者处理数据和交互问题变得更加轻松,工作也更加灵活高效。
一、表单开发的现实困境
1.1 传统开发的痛点
说到表单开发,作为一名开发者和业务人员,我真是深有体会。刚入行那会儿,写表单总觉得是个“体力活”,每次业务方一改需求,前端、后端、数据库全都得跟着动,改完还得反复测试,真是让人头大。表单一多,后期维护更是噩梦,哪怕只是加个小字段,都要全链路改一遍,真心累。
1.2 Flash Table的创新与优势
针对这些问题,Flash Table做了不少改进。它保留了低代码平台的高效和易用,同时在灵活性、性能和集成能力上做了优化。
比如,支持可视化拖拽和智能生成表单,开发效率提升不少;数据整合能力也很强,能方便地对接多系统,解决数据孤岛问题;复杂交互和个性化需求也有丰富的自定义选项,性能接近手写代码。对开发和业务来说,门槛低了不少,维护起来也更省心
下面,我们就一起来看看Flash Table的安装流程,帮助你快速上手体验这款高效工具!!!
二、Flash Table安装教程
Flash Table的安装过程其实非常友好,无论你是有经验的开发者,还是刚入门的业务同学,都能顺利完成部署。这里我结合自己的实际体验,给大家详细梳理一下安装流程,并分享一些小建议,帮助大家少踩坑、快上手。

2.1 选择合适的部署方式
- 推荐Docker部署:如果你有一台Linux服务器,强烈建议用Docker方式部署。Docker环境一致性好,安装和升级都很方便,适合生产环境和团队协作。
- 本地体验可用Jar包:如果只是本地体验或者小团队试用,直接用Jar包也很方便,配置简单,启动快,适合个人或小型项目。
个人建议:如果你对Linux和Docker不熟悉,可以先用Jar包本地体验,等熟悉后再迁移到服务器上用Docker部署。
2.2 环境准备
- 硬件要求:建议8GB以上内存,50GB以上硬盘空间,x86_64架构服务器。
- 操作系统:推荐CentOS、Ubuntu、OpenEuler、OpenKylin等主流Linux发行版。
- Docker环境:Docker版本需大于等于25.0.0。可用
docker version命令检查。 - 依赖服务:MySQL、MongoDB、Redis、MinIO(如用Jar包部署,需提前准备好这些服务)。
小贴士:如果是第一次接触Docker,建议先在本地虚拟机上练习一下基本命令,后续运维会轻松很多。
2.3 上传并解压安装包
-
下载离线安装包
注册并登录Flash Table官网,下载最新的离线安装包(如flashtable-20250605.tar.gz)。 -
上传到服务器
使用scp命令或WinSCP等工具,将安装包上传到服务器指定目录(如/opt/)。scp flashtable-20250605.tar.gz root@服务器IP:/opt/ -
解压安装包
在服务器上解压安装包到目标文件夹:mkdir /opt/flashtabletar -xzvf flashtable-20250605.tar.gz -C /opt/flashtablecd /opt/flashtable
2.4 一键部署(Docker方式)
Flash Table安装包内自带一键部署脚本1key_deploy.sh,极大简化了安装流程。
-
运行一键部署脚本
bash 1key_deploy.sh -
按提示选择安装项
- 先选择
1. deploy bases(部署基础服务) - 再选择
2. deploy services(部署核心服务)
脚本会自动拉取镜像、创建容器、初始化配置,整个过程无需手动干预。
- 先选择
-
检查服务状态
安装完成后,可用如下命令实时查看服务运行情况:
watch -n 5 -d \"docker service ls|grep cxist\"状态为
1/1即表示服务启动成功。 -
记录初始账号密码
安装脚本会在屏幕和
README.md中输出各程序的初始账号密码,建议及时保存。
个人感受:一键部署真的很省心,基本不用担心环境兼容和依赖问题,几分钟就能搞定。
2.5 Jar包部署(适合本地体验)
如果没有Docker环境,也可以用Jar包方式部署:
-
准备依赖服务
本地需提前安装好JDK11、MySQL、MongoDB、Redis、MinIO等服务,并保证能正常连接。 -
解压并配置
解压安装包,修改external.yml配置文件,填写数据库、存储等信息。 -
初始化数据库
用MySQL Workbench等工具,导入db_init目录下的SQL文件,完成数据库初始化。 -
启动服务
运行startup.bat(Windows)或startup.sh(Linux),等待服务启动。 -
访问系统
浏览器输入http://localhost:9005/(端口可自定义),即可进入系统主界面。
小建议:本地体验时,建议所有依赖服务都用默认端口,避免端口冲突和配置错误。
2.6 访问Web界面
- Docker部署默认端口:
http://服务器IP:11000 - Jar包部署默认端口:
http://localhost:9005/
三、Flash Table功能讲解
Flash Table不仅仅是一个表单生成工具,更是一个集成了AI、数据整合、交互设计等多项能力的低代码平台。下面我结合官方演示视频和自己的实际体验,详细介绍一下Flash Table的核心功能。
3.1 用Flash Table重构复杂表单开发
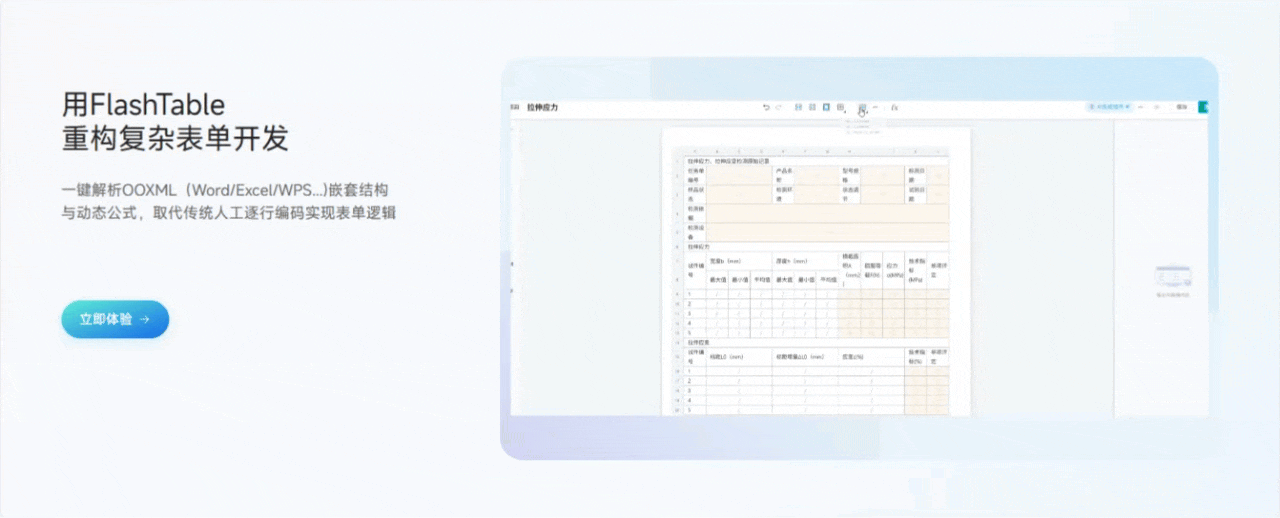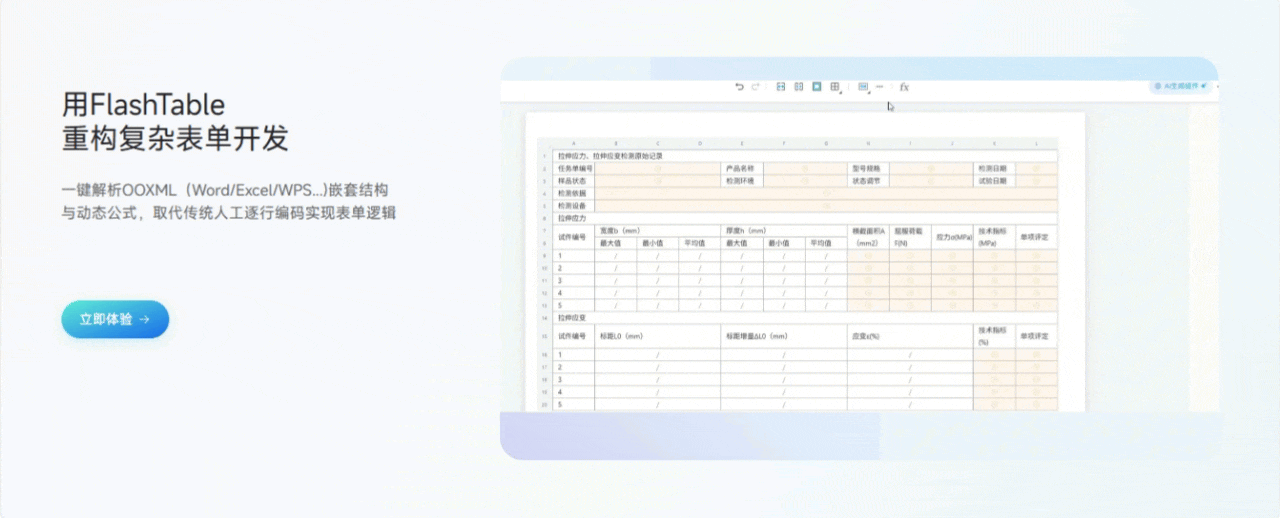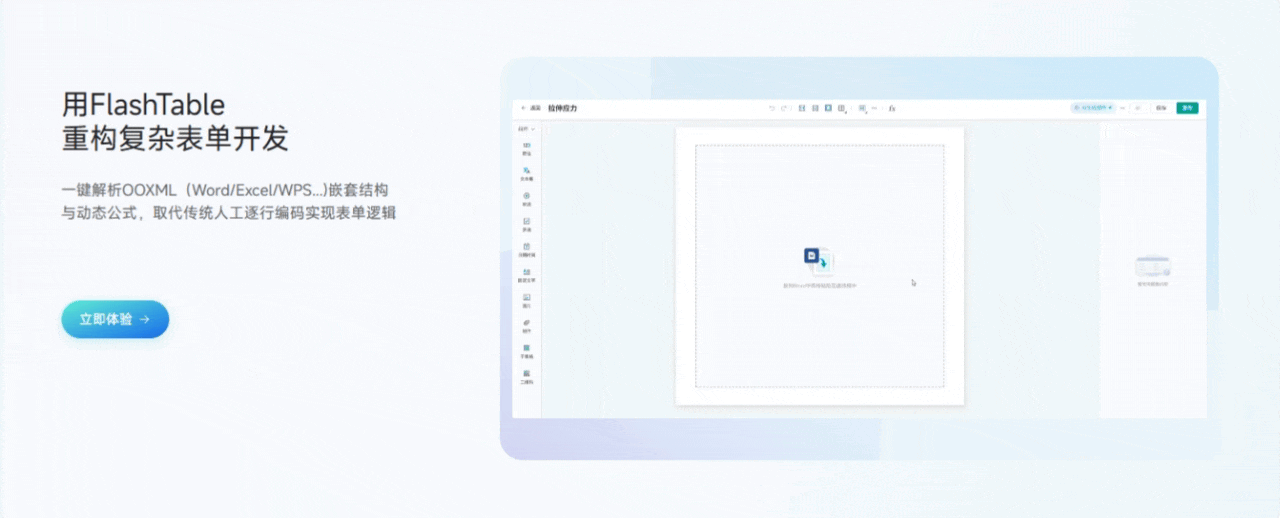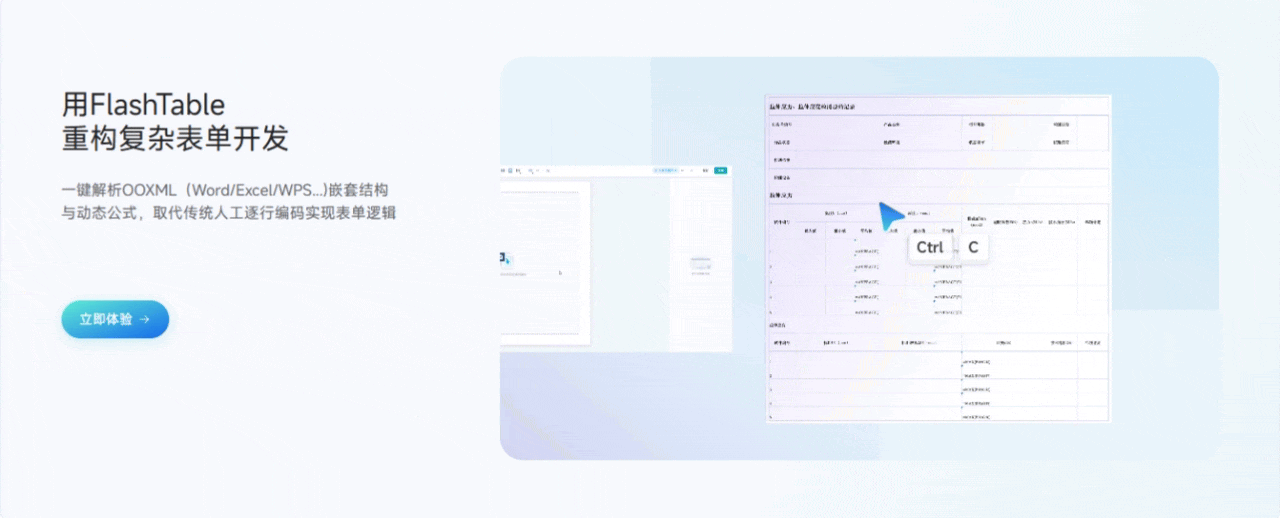
功能亮点说明:
- 一键导入文档,自动生成表单结构
只需将Word、Excel等文档内容复制粘贴到平台,Flash Table会自动识别表格、字段、标题等信息,智能生成表单初稿,极大减少了手动搭建的工作量。 - 可视化拖拽编辑
表单字段、布局、分组、校验等都可以通过拖拽和点击完成,所见即所得,极大降低了开发门槛。 - 支持复杂嵌套和分组
无论是多级表单、子表单还是分组字段,都能轻松实现,满足复杂业务场景。 - 实时预览与调试
编辑过程中可以随时预览表单效果,及时发现和修正问题。
个人体验:以前做复杂表单,前后端要反复沟通、改代码,现在用Flash Table,基本上业务同学自己就能搞定80%的需求,开发效率提升非常明显。
3.2 用Flash Table搭建高保真交互表单
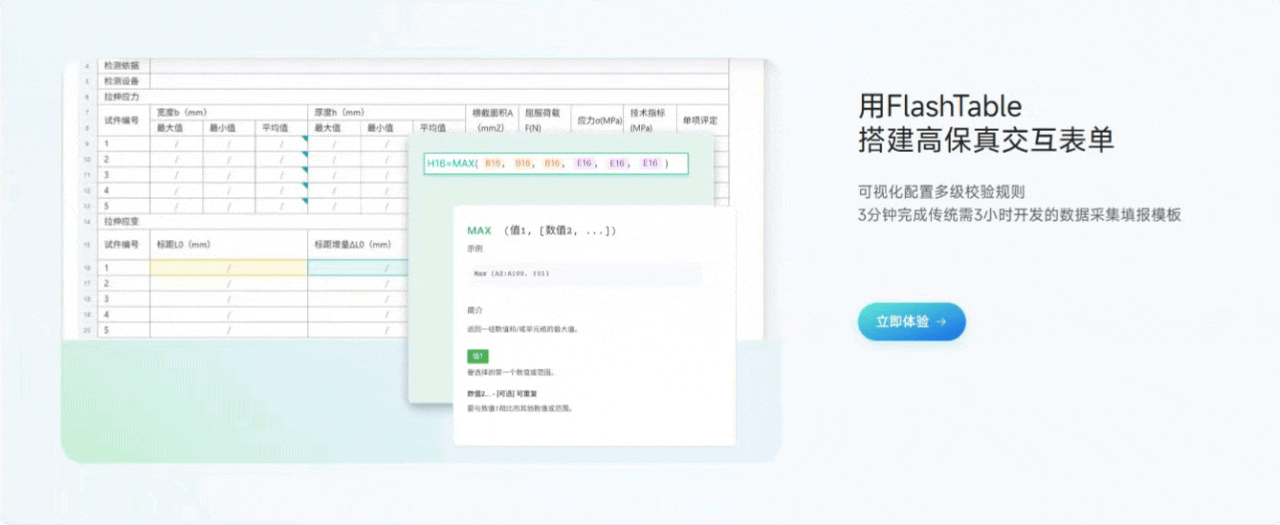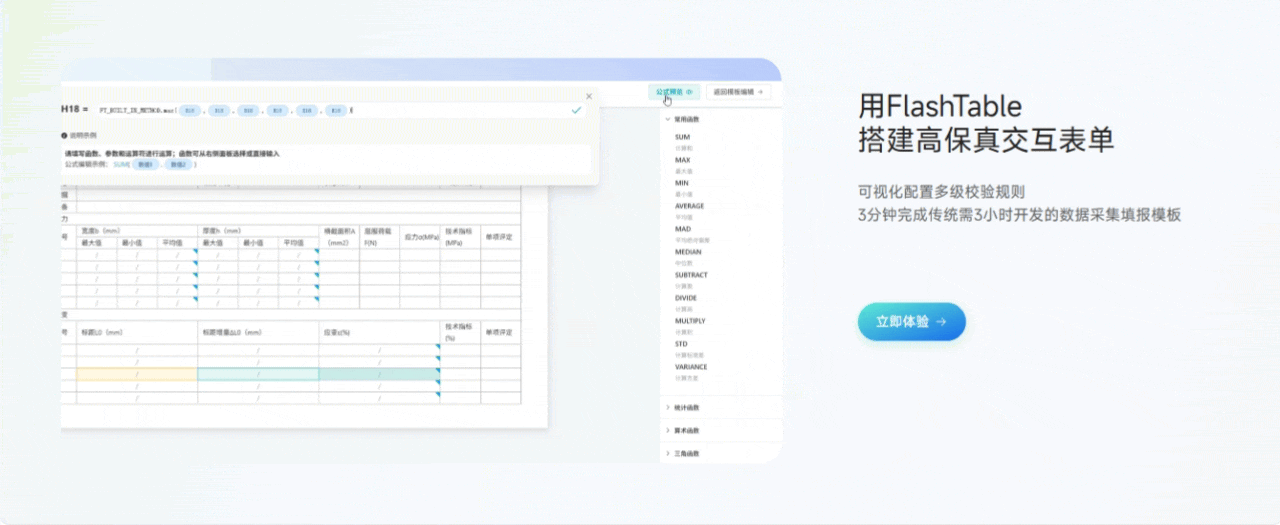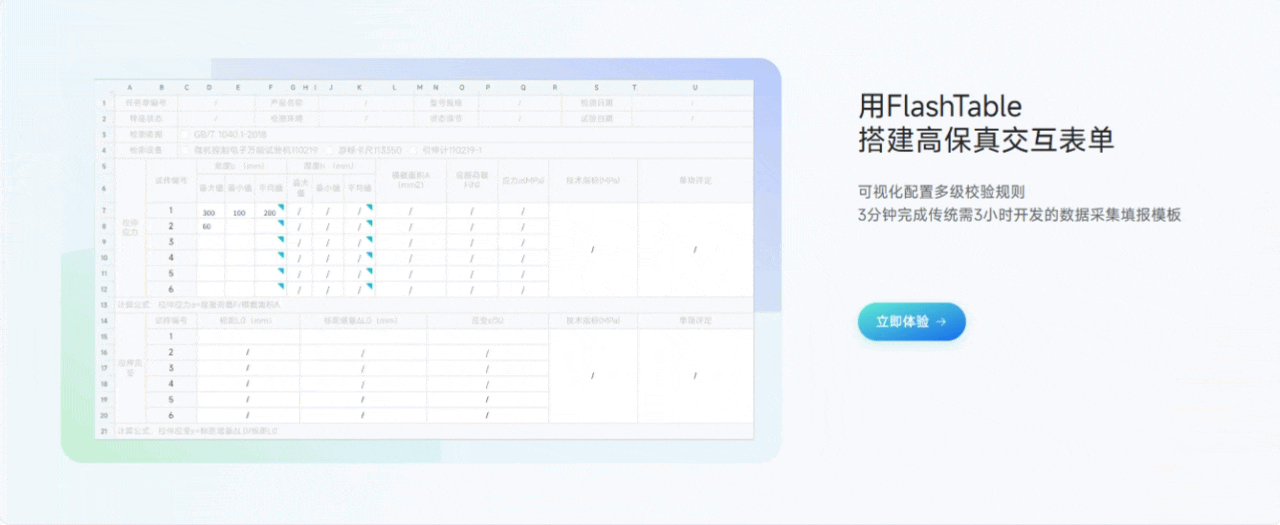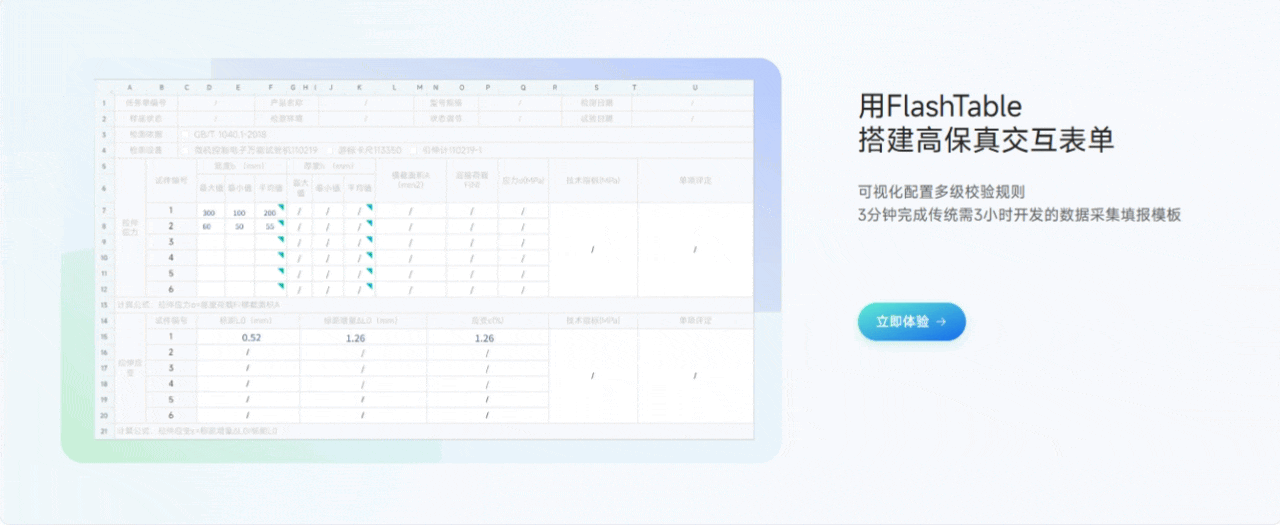
功能亮点说明:
- 条件渲染与字段联动
可以设置字段的显示/隐藏、必填/非必填、只读/可编辑等条件,支持多字段联动,满足各种动态交互需求。 - 动态校验与自定义校验规则
支持常见的格式校验、范围校验,也可以自定义校验逻辑,保证数据质量。 - 自定义脚本扩展
对于更复杂的交互,可以编写自定义脚本,实现如自动计算、批量赋值等高级功能。 - 高保真预览
表单交互效果可以实时预览,确保上线即用。
个人体验:很多低代码平台的交互能力比较弱,Flash Table在这方面做得很强,复杂的业务逻辑也能通过配置和脚本轻松实现,极大提升了表单的可用性和用户体验。
3.3 用Flash Table打通系统数据孤岛
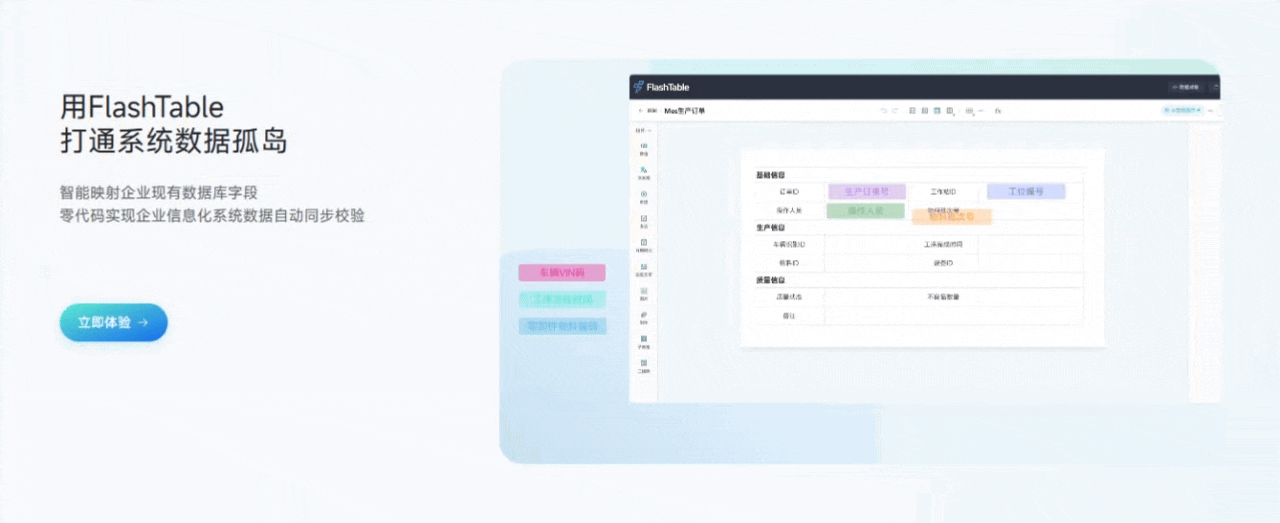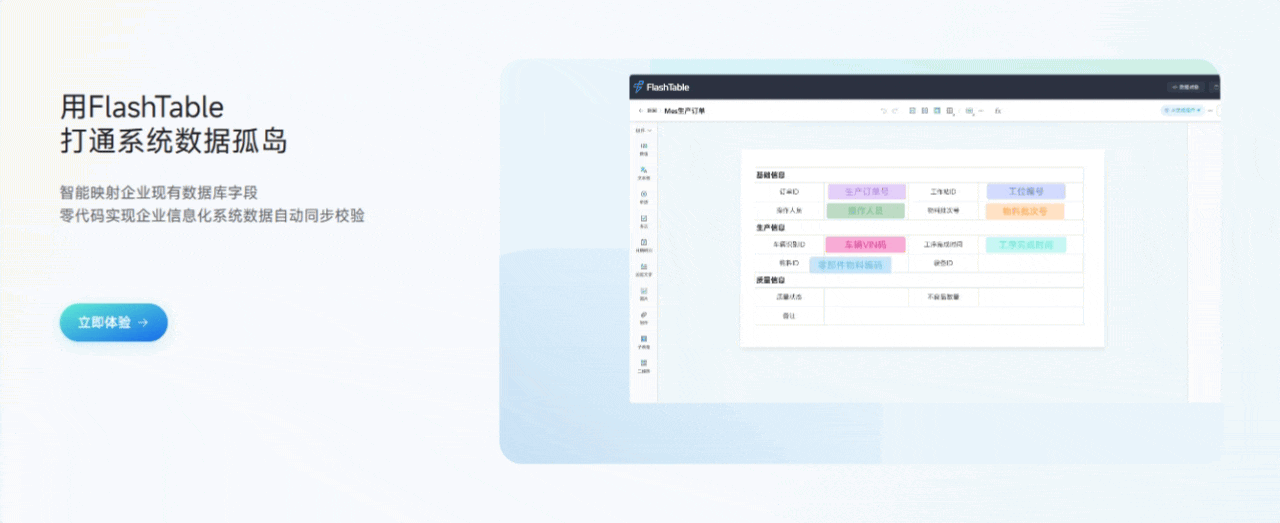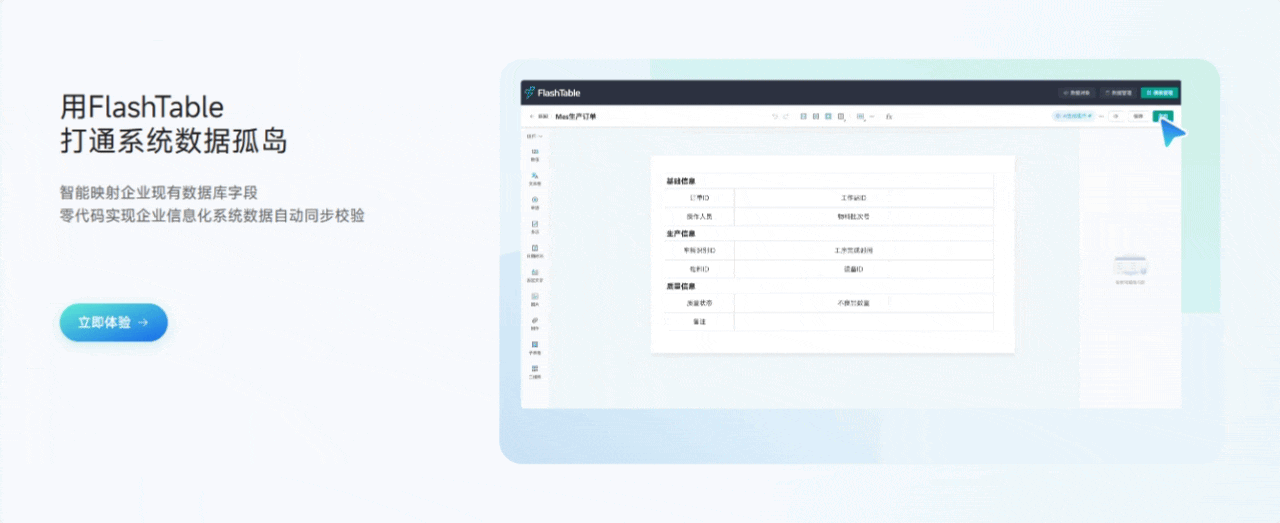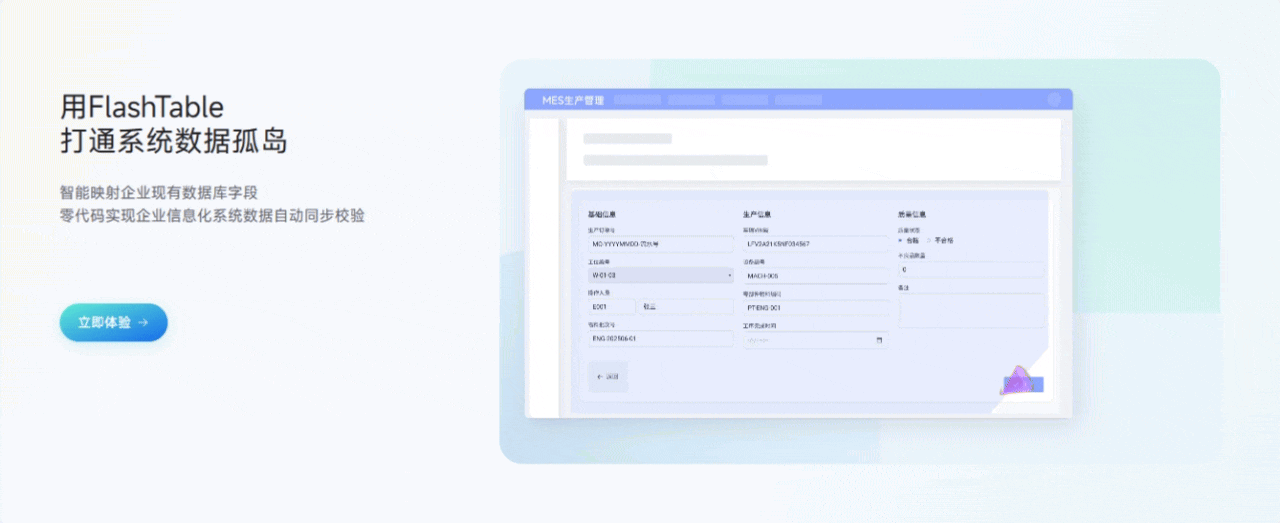
功能亮点说明:
- 多数据源集成
支持MySQL、MongoDB、Redis、MinIO等主流数据源,表单数据可以灵活存储和读取。 - 数据映射与同步
可视化配置数据映射规则,实现表单与业务系统的数据互通,彻底消除“数据孤岛”。 - 数据权限与分级管理
支持多角色、多级权限配置,保障数据安全和合规。 - 数据实时同步与回填
支持数据的实时同步、回填和导出,方便后续数据分析和业务流转。
个人体验:以前做数据集成要写很多接口和同步脚本,现在用Flash Table,配置一下就能搞定,极大降低了系统集成的难度。
3.4 AI + Flash Table = 解放双手
功能亮点说明:
- AI一键解析文档
只需上传或粘贴文档内容,AI会自动识别字段、类型、校验规则等,生成完整的表单结构。 - 智能推荐组件与交互逻辑
AI会根据内容智能推荐合适的表单组件和交互逻辑,减少人工配置。 - 支持主流大模型接入
可接入如字节豆包、通义千问等主流大模型,体验前沿AI能力。 - 极大提升开发效率
复杂表单几分钟就能生成,真正实现“解放双手”。
个人体验:AI生成表单真的很香,尤其是面对大批量、结构复杂的表单需求时,效率提升非常明显,几乎不用再手动搭建,省时省力。
四、实战:一分钟完成简历模板开发
本章节将以“简历模板开发”为例,带你体验Flash Table的极速表单搭建能力。整个过程分为环境准备、表单开发、效果展示三大步骤,帮助你快速上手。
4.1 环境准备
4.1.1 选择部署方式
- 推荐本地体验可用Jar包部署,适合个人或小团队快速试用。
- 若有服务器资源,建议使用Docker部署,便于后续扩展和运维。
本节我们采用Jar包进行部署,我们首先下载Jar包到本地,之后新建一个文件夹,文件示例如下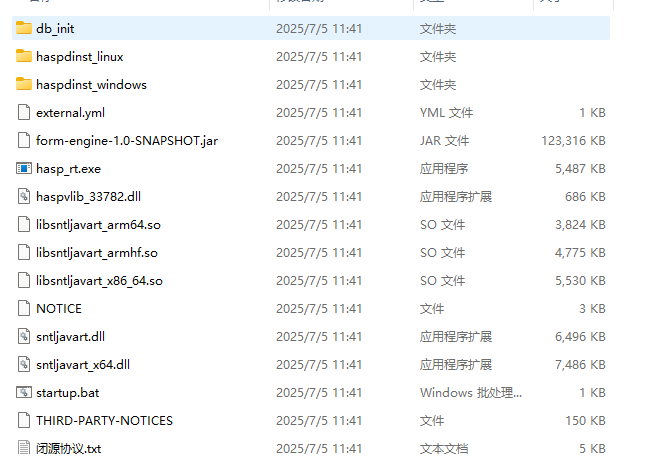
4.1.2 安装依赖服务
- 本地需提前安装好JDK11、MySQL、MongoDB、Redis、MinIO等服务,并确保能正常连接。
- Windows用户:进入
haspdinst_windows目录,双击install.bat安装依赖。 - Linux用户:进入
haspdinst_linux目录,按readme.txt说明操作。
jdk下载截图如下
下载jdk11版本

- Mysql数据库服务开启如下

- MongoDB数据库 服务开启如下

- Redis数据库服务开启如下

MinIO文件存储,配置截图如下
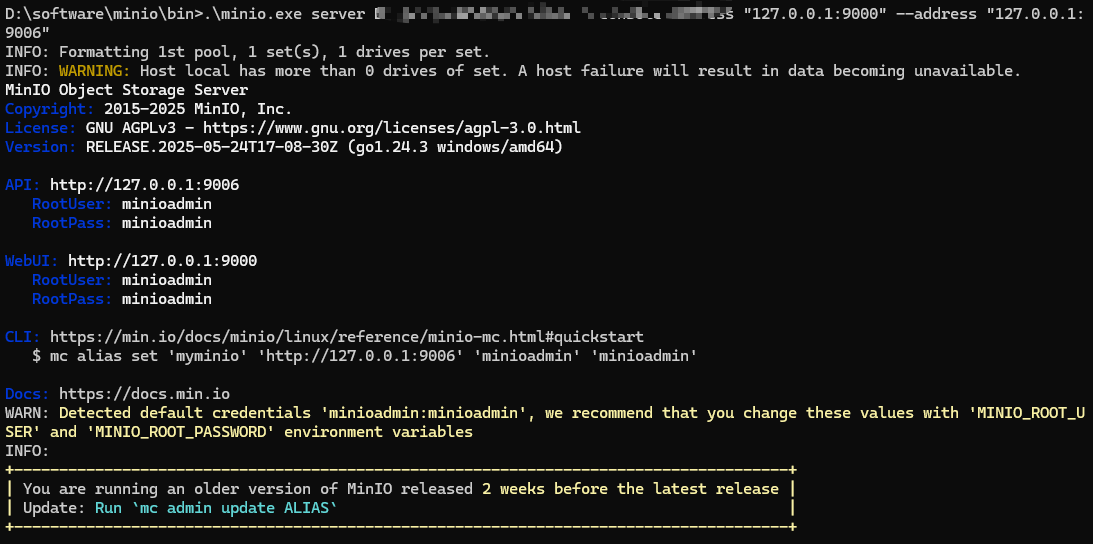
创建一个test1用作存储

4.1.3 解压与配置
-
- 解压Flash Table安装包到指定目录。
- 修改
external.yml配置文件,填写数据库、存储等信息。
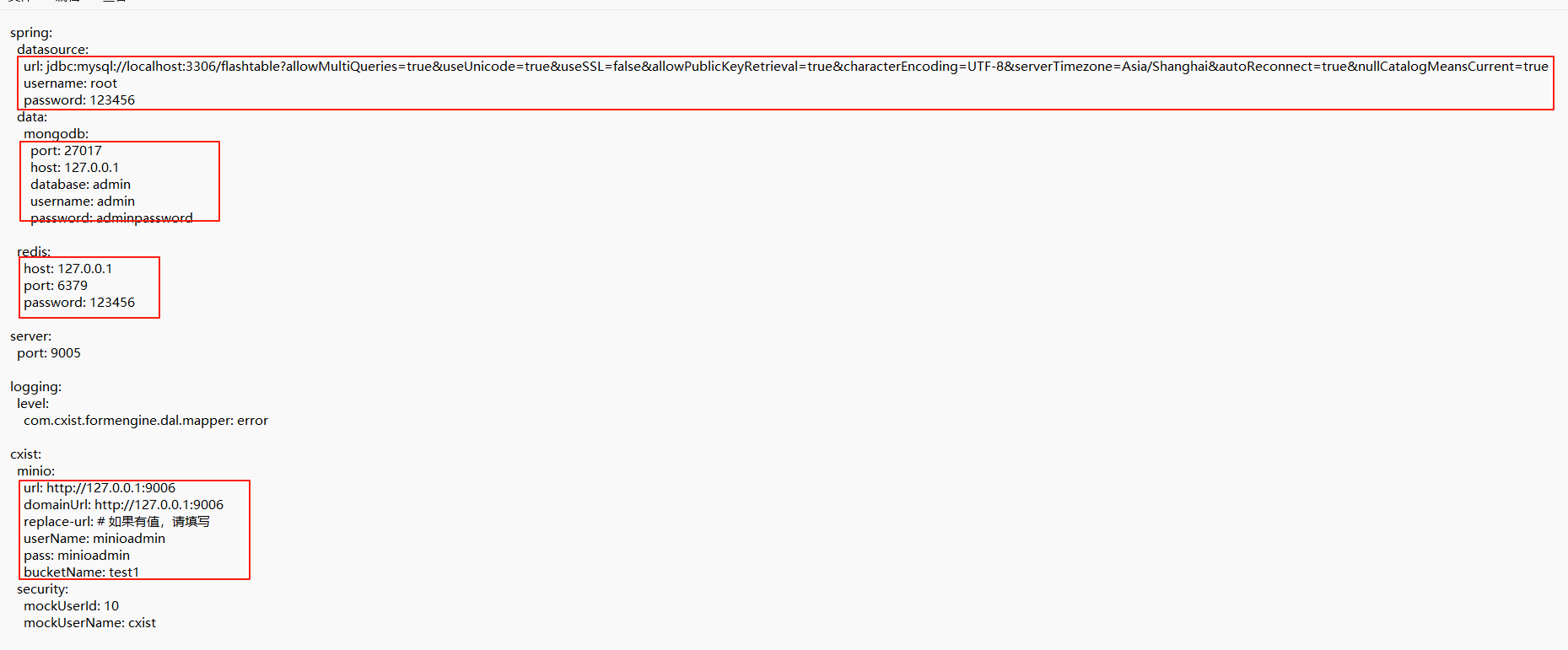
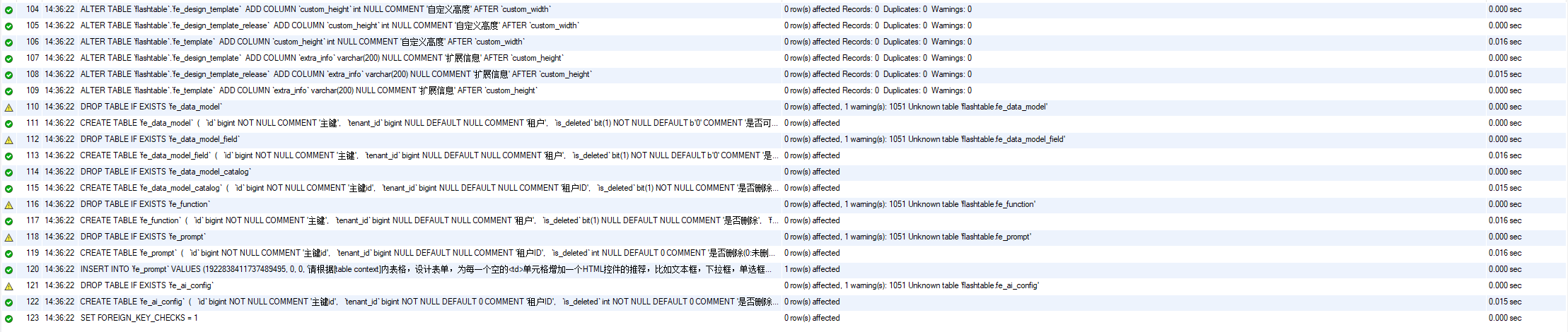
4.1.4 初始化数据库
- 使用MySQL Workbench等工具,导入
db_init目录下的SQL文件,完成数据库初始化。
下图为执行后的结果
4.1.5 启动服务
- Windows:双击
startup.bat启动服务。 - Linux:运行
startup.sh启动服务。
4.1.6 访问系统
- 浏览器输入
http://localhost:9005/(或服务器IP+端口),进入Flash Table主界面。
4.2 表单开发全流程
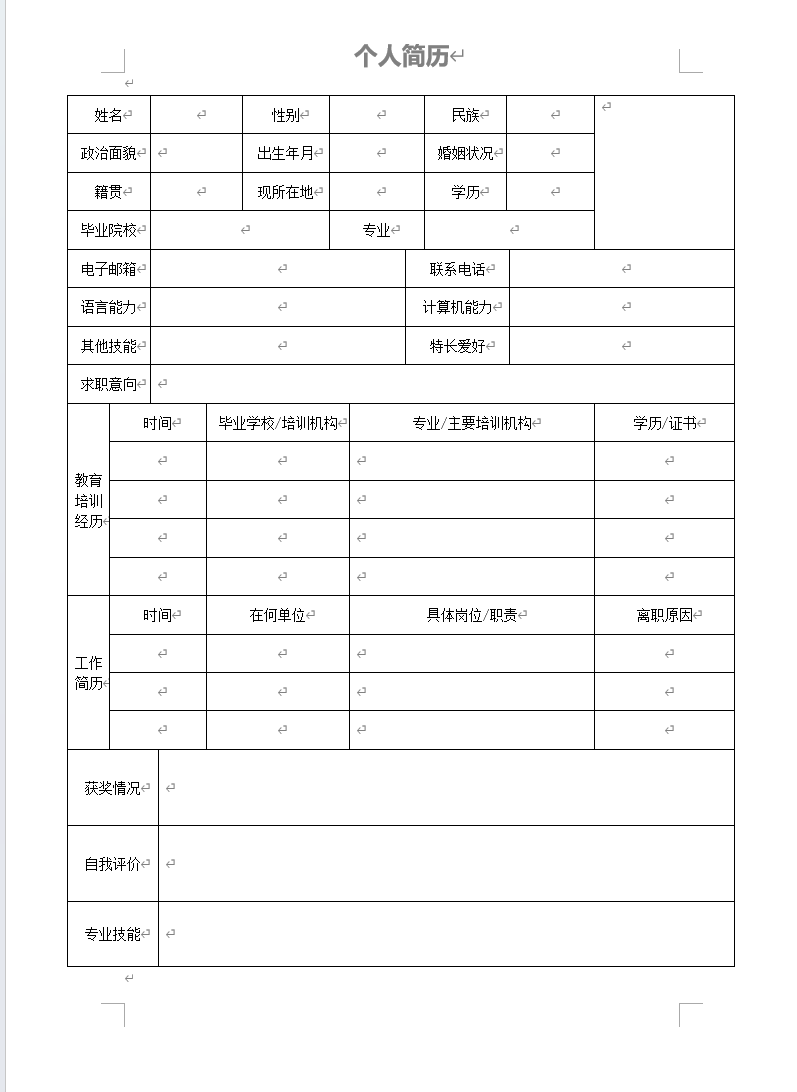
4.2.1 准备简历模板
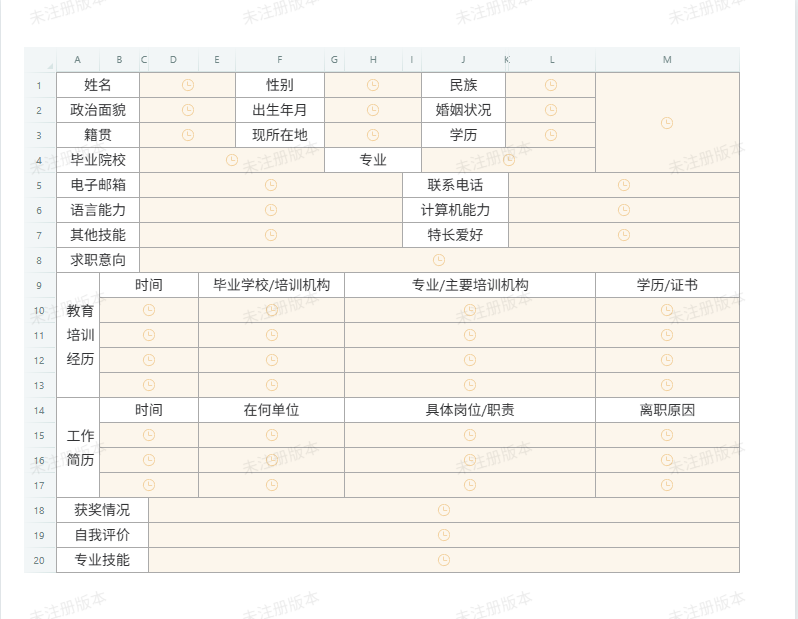
- 下载一份Word格式的简历模板。
- 使用
Ctrl+A全选内容,Ctrl+C复制。
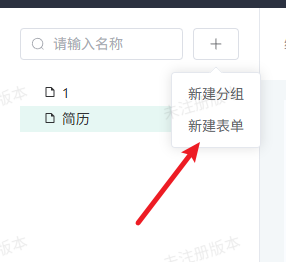
4.2.2 新建表单项目
- 在Flash Table主界面,点击左上角“+”按钮,选择“新建表单”。
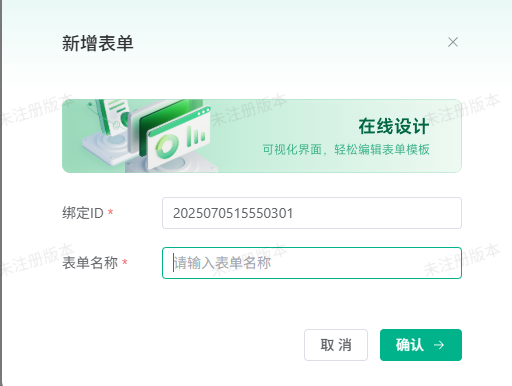
- 输入表单名称(如“简历模板”),点击确定。
4.2.3 粘贴模板内容
- 在表单编辑区,将刚才复制的Word内容粘贴进去。
- 此时页面还未自动生成表单组件。
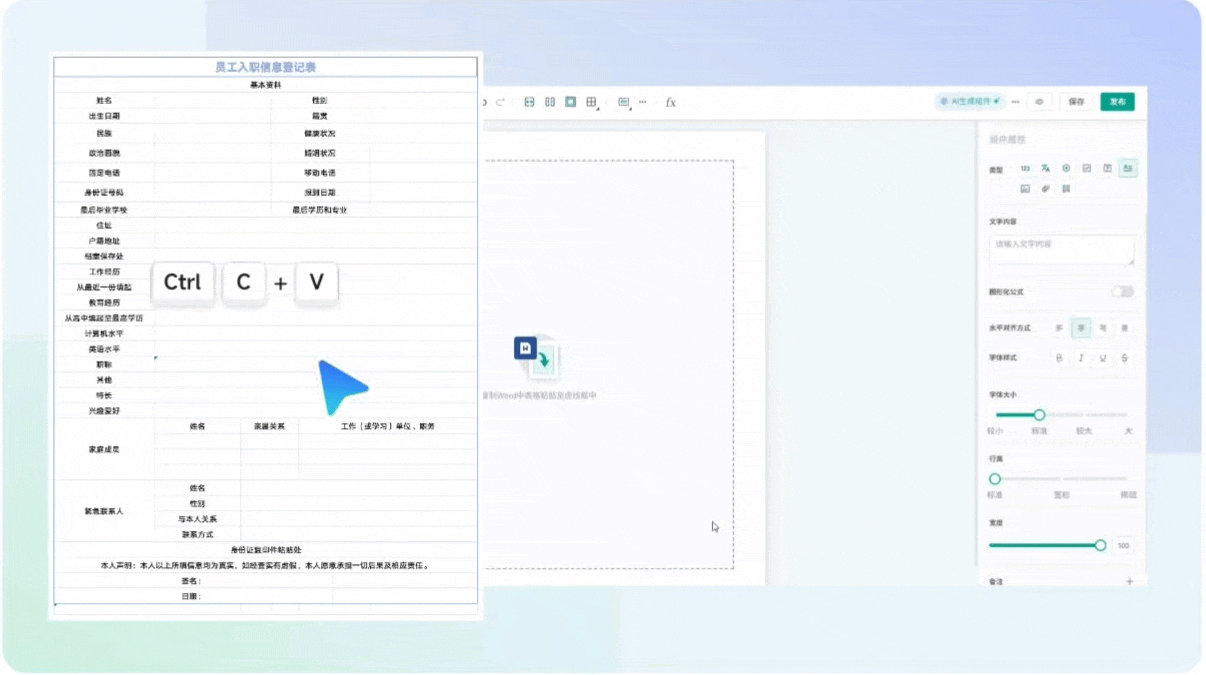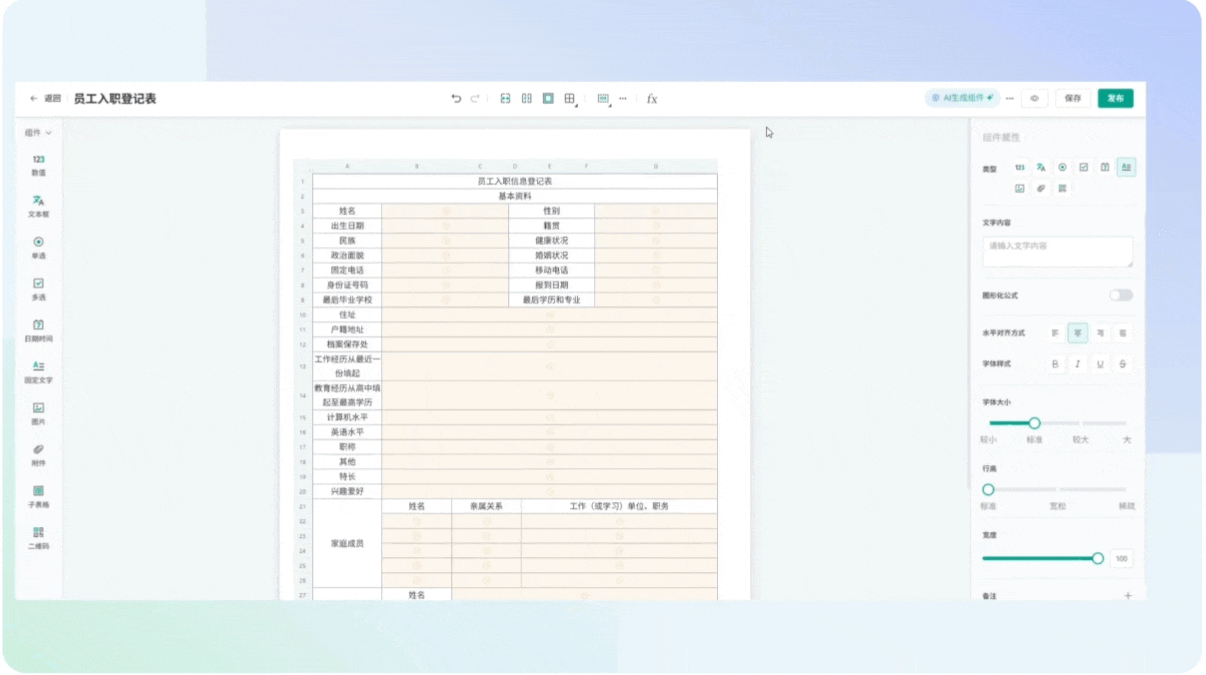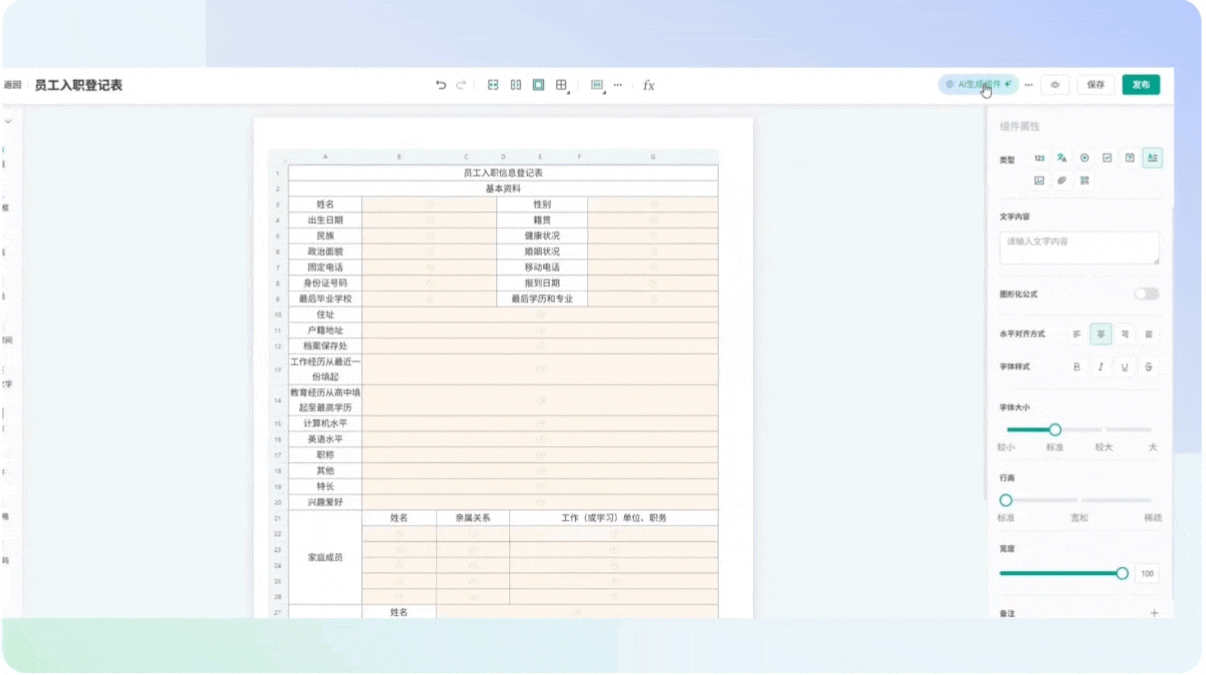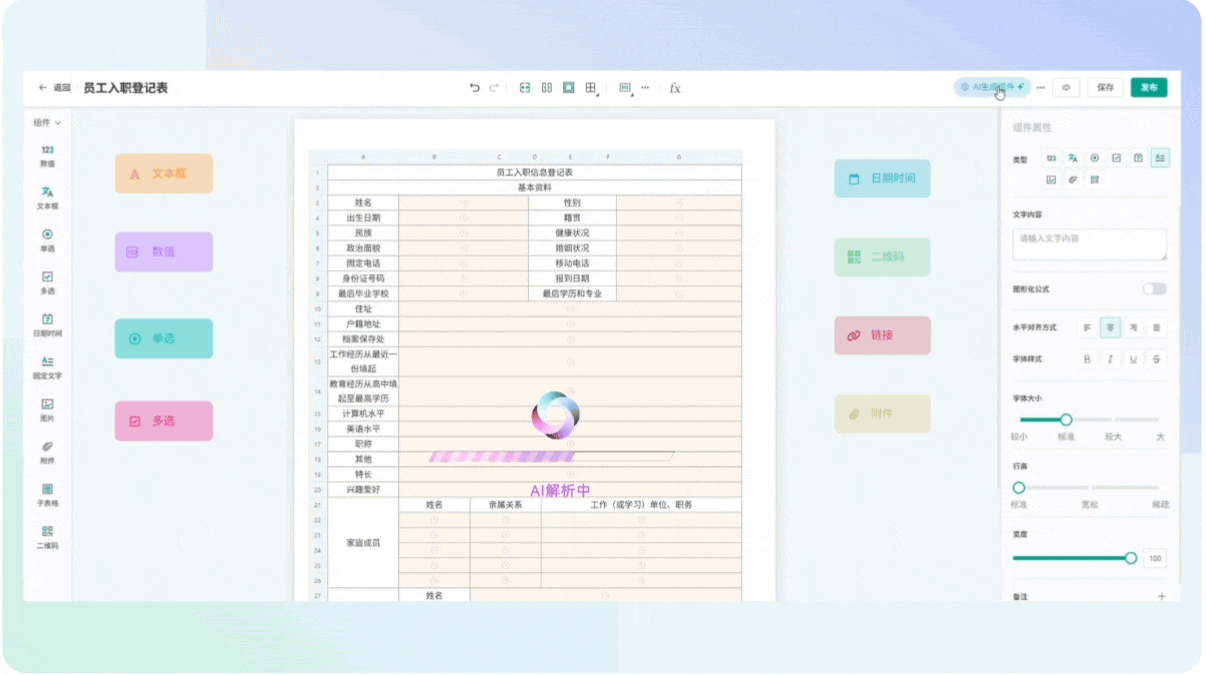
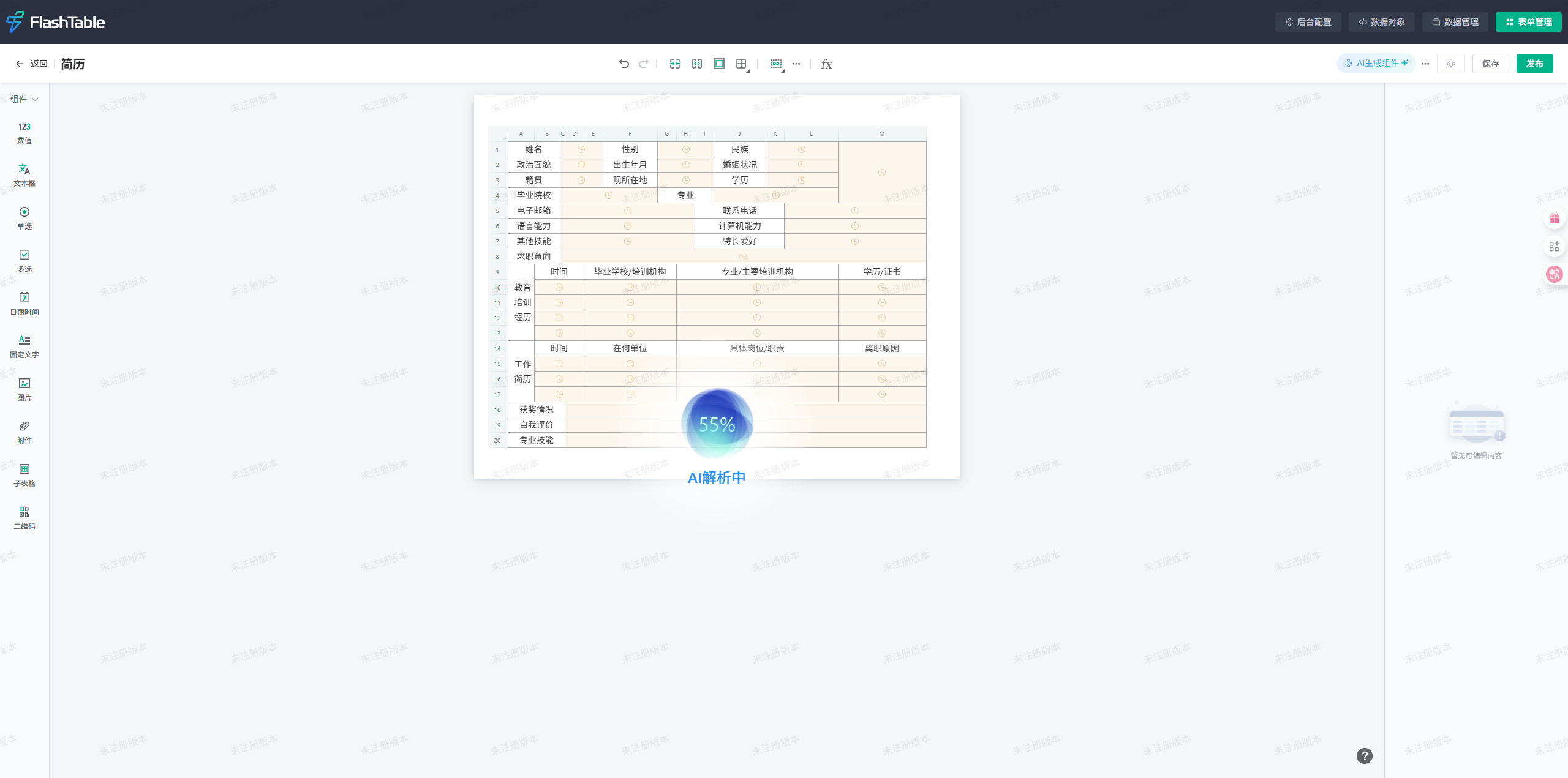
4.2.4 AI智能生成组件
- 点击“后台配置”,选择AI模型(如字节豆包doubao-1-5-pro-32k-250115)。

- 配置完成后,点击“AI生成组件”按钮,等待AI自动识别并生成表单字段。
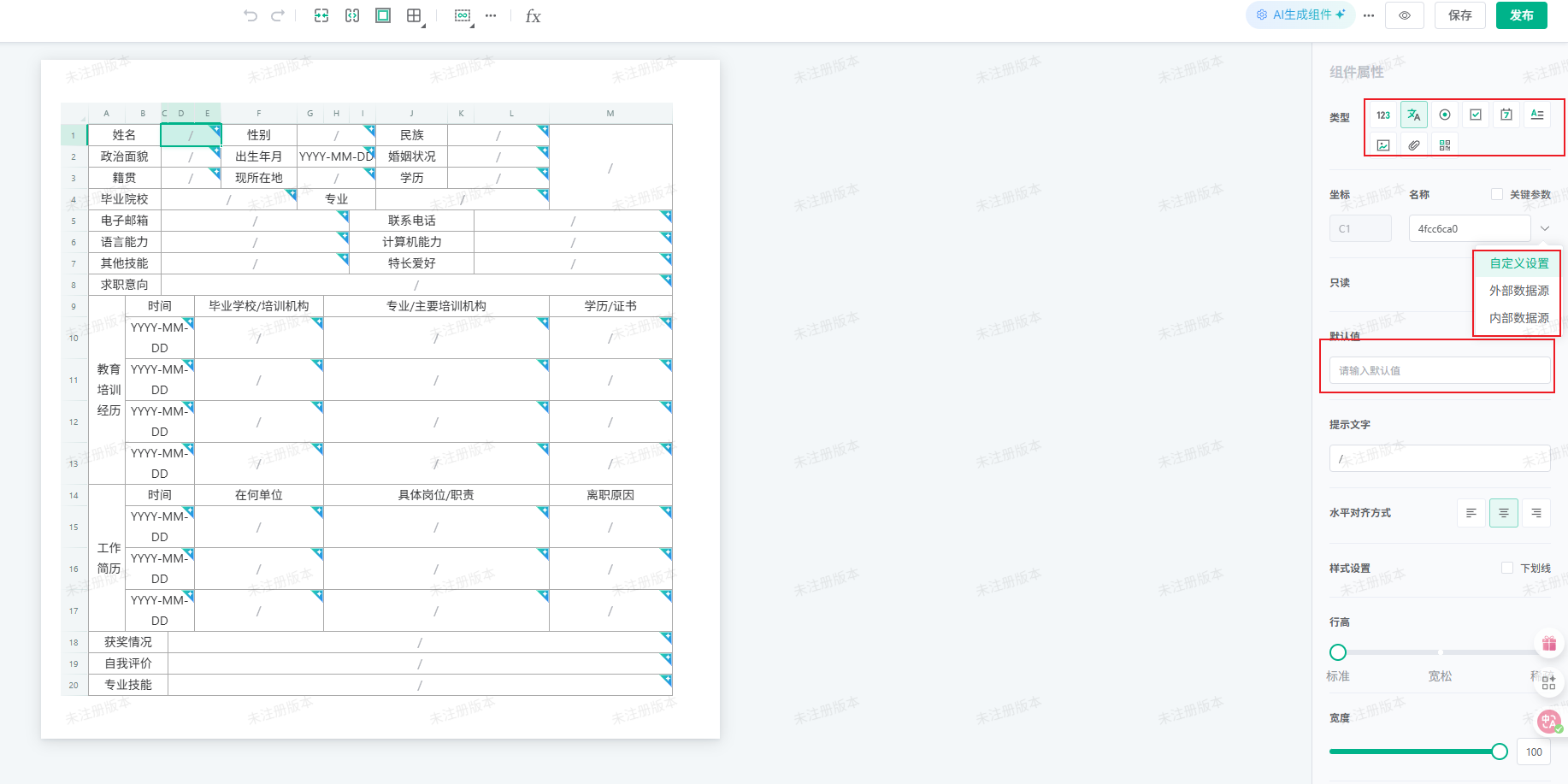
4.2.5 个性化调整
- 根据实际需求,调整字段类型、数据源、默认值等。
- 可添加校验规则、设置字段联动、配置交互逻辑等。
4.2.6 发布表单
- 配置完成后,点击右上角“发布”按钮,表单即可上线使用。
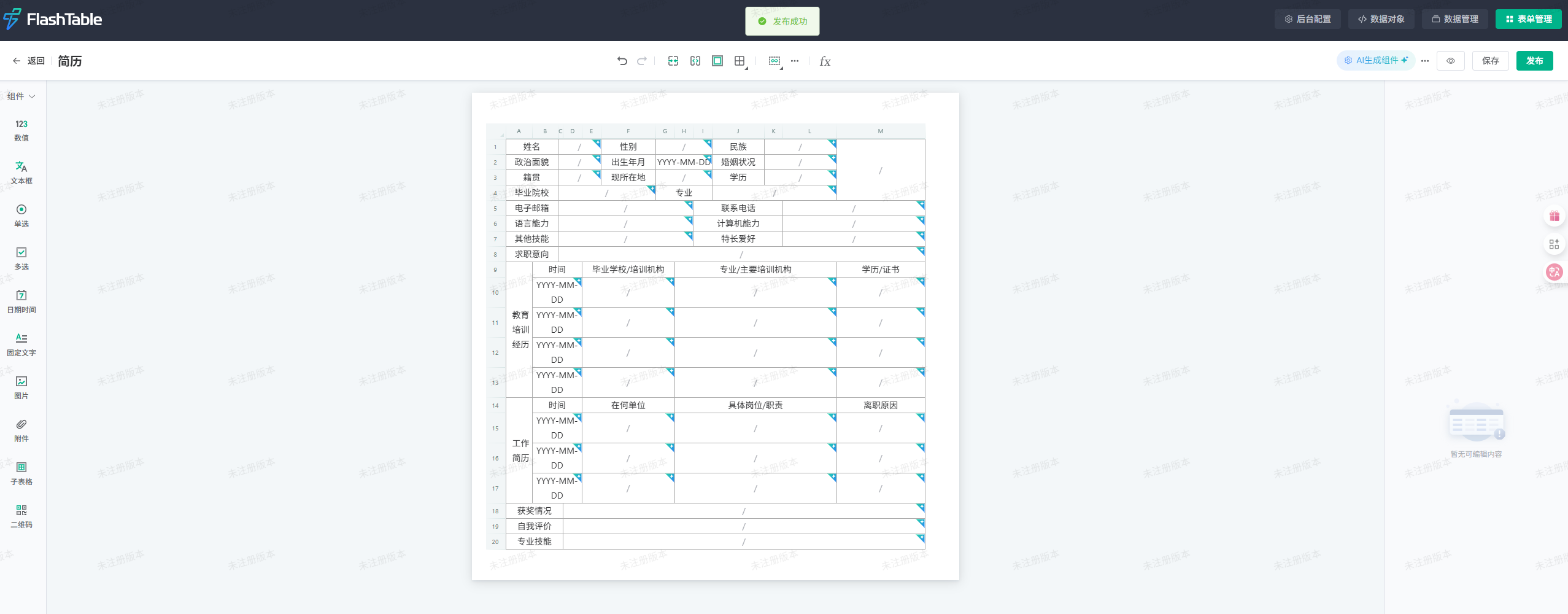
4.3 效果展示
- 自动生成的表单结构清晰,字段齐全,基本还原了Word模板的内容。
- 支持自定义设置,如必填项、下拉选项、日期选择等,满足个性化需求。
- 表单发布后可直接收集和管理数据,支持数据导出、权限分配等功能。

五、Flash Table使用点评
本章将Flash Table与传统开发方式、主流低代码平台(如简道云)进行对比,帮助大家更直观地了解其优势
5.1 测试环境
- 硬件环境:16G内存
- 软件环境:Win11、JDK 11、MySQL 8.0、MongoDB 4.4、Redis 6.0、MinIO
- 对比平台:Flash Table、传统SpringBoot+Vue开发、简道云
5.2 传统开发 VS 简道云 VS Flash Table
传统开发方式(如SpringBoot+Vue)最大的特点是灵活性高,几乎可以实现任何复杂或个性化的业务需求,适合对系统有特殊要求的场景,但开发周期长、技术门槛高、维护成本大。
简道云等主流低代码平台则以“快速、易用”为主要优势,面向业务人员,支持可视化拖拽和配置,适合标准化、流程化的业务应用,开发效率高、上手快,但在复杂交互和深度定制方面存在一定局限。
Flash Table则兼具两者优点,不仅支持AI智能生成表单、自动化搭建,极大提升开发效率,还原生支持多数据源集成和复杂交互逻辑,具备较强的定制能力和企业级运维支持,适合对效率、集成和定制化有较高要求的企业级场景。
结语
Flash Table让表单开发变得简单多了,不管是技术人员还是业务人员,都能轻松上手,把更多精力放在业务创新上。不管公司规模大小,都能用它快速实现业务流程的数字化升级。随着AI技术发展,Flash Table会越来越智能,成为企业数字化转型的好帮手。
现在,终于可以告别那些麻烦的表单开发,工作效率直接翻倍!
体验直达链接:https://flashtable.cn/


