【小白量化智能体】应用6:根据通达信指标等生成机器学习Python程序
【小白量化智能体】应用6:根据通达信指标等生成机器学习Python程序
【小白量化智能体】是指能够自主或半自主地通过与环境的交互来实现目标或任务的计算实体。智能体技术是一个百科全书,又融合了人工智能、计算机科学、心理学和经济学等多个领域的知识,能够在复杂环境中自主决策和行动的实体。能够实现量化投资的各方面应用,例如自动设计指标,自动编写Python自动交易策略等等。
【小白量化智能体】能够通过中文描述,转化为指标公式和Python程序,以及生成机器学习程序。
如果自己不会写Python策略,去定做一个指标公式是需要3位数,定做一个策略需要花费4位数。花钱是次要的,你能保证你的技术公式和策略是100%准确吗?
大家知道,失败是成功之母,我相信你的努力尝试100次失败后,最终会做出成功的策略。问题是你有100个4位数的开发资金吗?
【小白量化智能体】能够1分钟内写出交易指标公式,1秒钟生成各种Python策略。每天可以生成无数个策略,开发成本就是电费。
我们下面给大家介绍根据通达信公式并生成机器学习Python程序的过程。
一、通达信指标公式生成机器学习Python程序
打开小白量化智能体,点按钮【机器学习】:
在弹出窗口中选择一个机器学习算法。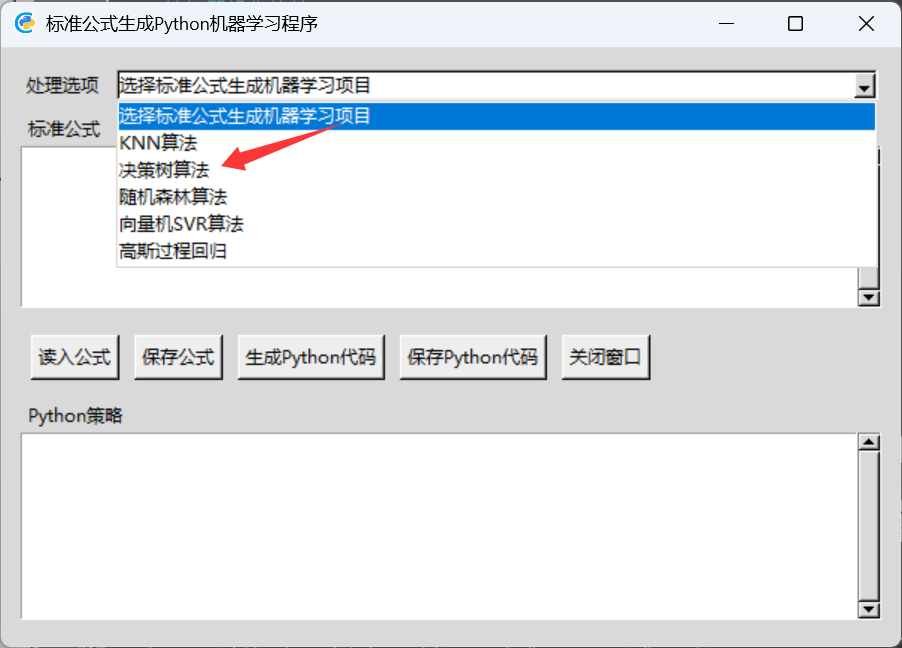
然后输入一个指标公式,点【生成Python代码】。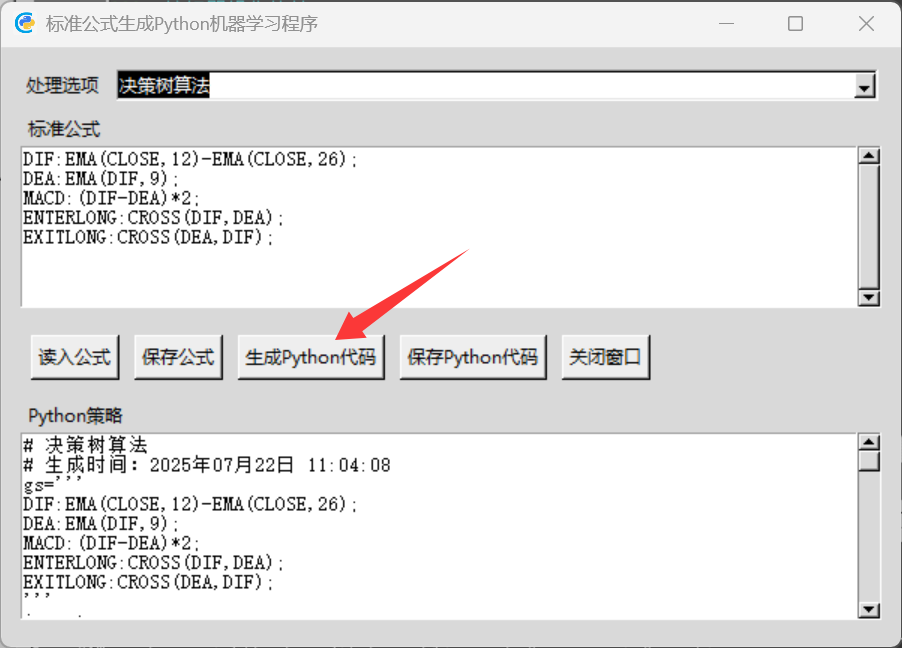
自动把指标公式作为分析因子生成一个机器学习Python代码。
# 决策树算法# 生成时间:2025年07月22日 11:04:08gs=\'\'\'DIF:EMA(CLOSE,12)-EMA(CLOSE,26);DEA:EMA(DIF,9);MACD:(DIF-DEA)*2;ENTERLONG:CROSS(DIF,DEA);EXITLONG:CROSS(DEA,DIF);\'\'\'import os,syssys.path.append(os.path.abspath(\'.\'))sys.path.append(os.path.abspath(\'..\'))import math,joblibimport datetime,timeimport pandas as pd import numpy as npimport matplotlib.pyplot as pltfrom HP_formula import * #小白量化仿通达信公式函数库import HP_tdx as htdx#小白通达信行情库 import HP_formula as hgs #小白通达信公式库from sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_errorplt.rcParams[\'font.sans-serif\']=[\'SimHei\'] #用来正常显示中文标签plt.rcParams[\'axes.unicode_minus\']=False #用来正常显示负号tdxapi=htdx.TdxInit(ip=\'183.60.224.178\',port=7709)#(nCategory, nMarket, sStockCode, nStart, nCount) #获取市场内指定范围的证券K 线, #指定开始位置和指定K 线数量,指定数量最大值为800。 #参数: #nCategory -> K 线种类 #0 5 分钟K 线 #1 15 分钟K 线 #2 30 分钟K 线 #3 1 小时K 线 #4 日K 线 #5 周K 线 #6 月K 线 #7 1 分钟 #8 1 分钟K 线 #9 日K 线 #10 季K 线 #11 年K 线 #nMarket -> 市场代码0:深圳,1:上海 #sStockCode -> 证券代码; #nStart -> 指定的范围开始位置; #nCount -> 用户要请求的K 线数目,最大值为800。m=0code=\'000002\'today=time.strftime(\'%Y-%m-%d\',time.localtime(time.time()))df=htdx.get_bars(nCategory=4,nMarket =m,code=code,start=\'1991-01-01\',end=today)#小白数据规格化mydf=initmydf(df) ##初始化mydf表mydf=mydf.reset_index(level=None,drop=True,col_level=0,col_fill=\'\')C=CLOSE=mydf[\'close\']L=LOW=mydf[\'low\']H=HIGH=mydf[\'high\']O=OPEN=mydf[\'open\']V=VOL=mydf[\'volume\']from HP_formula import * #小白股票指标公式函数库tgs1=hgs.Tdxgs()tgs1.loaddf(mydf)mydf=tgs1.rungs(gs)mydf[\'ZF\']=(C-REF(C,1))/(REF(C,1)+0.000000001) #涨幅mydf[\'label\']=REF(mydf[\'ZF\'],-1) #明日涨幅## 数据整理mydf.dropna(inplace=True) ##删除无效数据mydf=mydf.reset_index(level=None,drop=True,col_level=0,col_fill=\'\')print(mydf)#mydf.to_csv(\'ls.csv\' , encoding= \'gbk\')# 将日期时间列转换为数值类型for col in [\'datetime\', \'date\', \'date2\']: mydf[col] = pd.to_datetime(mydf[col]).astype(\'int64\')# 提取特征和目标变量X = mydf.drop([ \'label\'], axis=1)y = mydf[\'label\']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42)##################################################from sklearn.tree import DecisionTreeRegressor#构建决策树回归器clf = DecisionTreeRegressor()# 在训练集上训练模型clf.fit(X_train, y_train)# 在测试集上进行预测y_pred = clf.predict(X_test)# 计算模型的均方误差mse = mean_squared_error(y_test, y_pred)print(f\'模型的均方误差:{mse}\')#print(list(y_test)[-5:],\'\\n\', list(y_pred)[-5:])## 保存模型## 模型和数据文件路径MODEL_PATH = \'model.pkl\'joblib.dump(clf, MODEL_PATH)print(f\'模型已保存到: {MODEL_PATH}\')二、在《小白量化智能体》软件中运行程序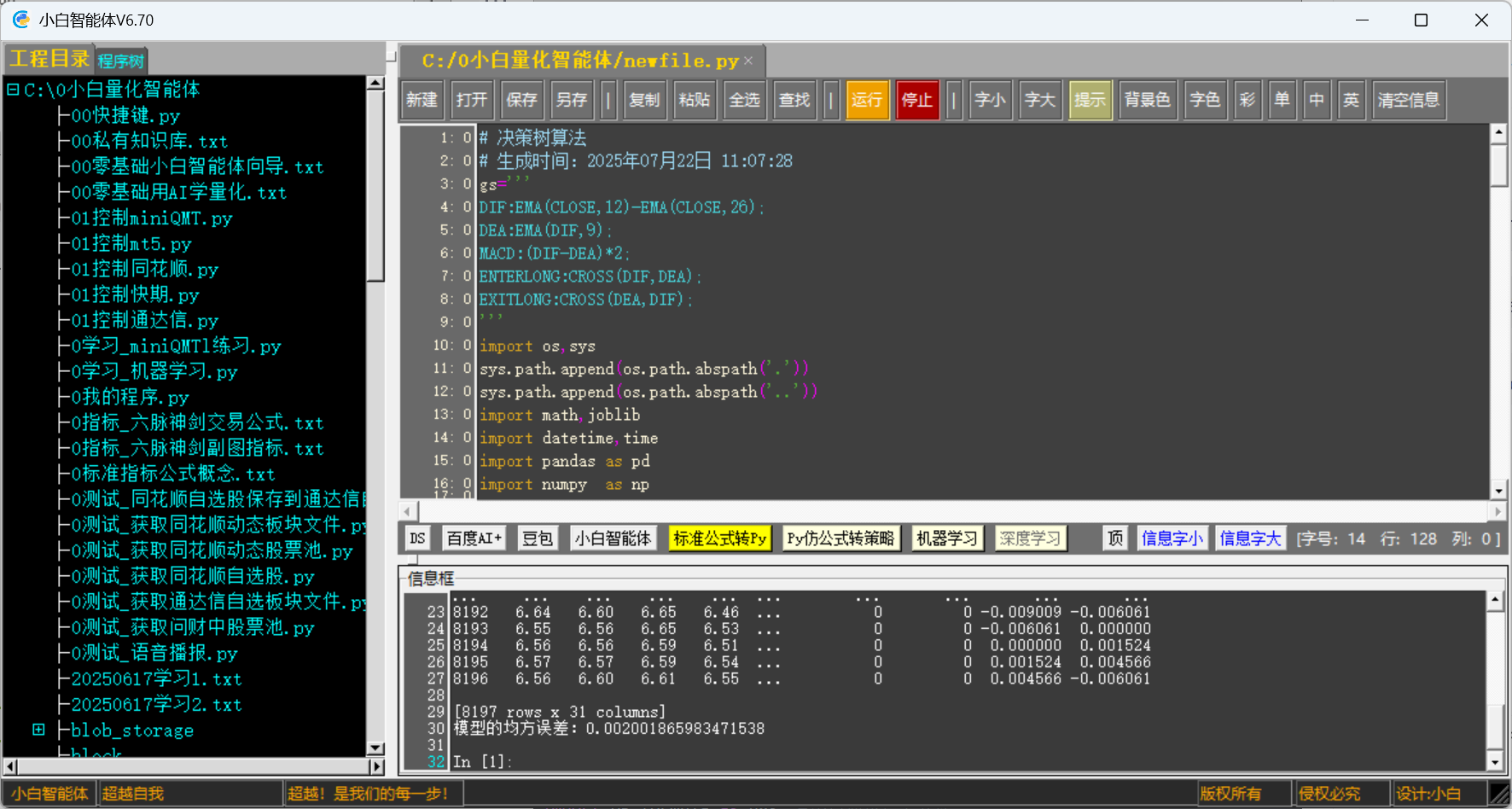
机器学习的模型及结果保存到文件 \'model.pkl’中。
三、在用策略中使用机器学习模型
如果机器学习预测有效,可以在策略中直接使用训练好的机器模型数据,不用重新进行机器学习。下面是使用训练好的机器模型数据的代码。
## 加载模型clf2 = joblib.load(MODEL_PATH)print(f\'模型已从 {MODEL_PATH} 加载\')# 在训练集上训练模型clf2.fit(X_train, y_train)# 在测试集上进行预测y_pred = clf2.predict(X_test)# 计算模型的均方误差mse = mean_squared_error(y_test, y_pred)print(f\'模型的均方误差:{mse}\')上面给出了自动生成机器学习Python程序的示例。
我们可以尝试使用更多的因子,更多的数据进行训练。
也可以选择不同的机器学习模型,实现自己的目的。
《小白量化智能体》相当一位计算机本科生免费帮你写指标公式,免费写策略,辅助你做机器学习、深度学习量化研究。
本身是支持中文Python语法和西文Python语法的集成开发工具,适合7岁-70岁人都适合学习中文Python编程。
今天的文章先写到这里,欢迎继续关注我的博客。后面我还介绍更多的【小白量化智能体】开发Python策略的知识。
超越自己是我的每一步!我的进步就是你的进步!

