SpringBoot 集成Mybatis Plus
一、为什么SpringBoot不推荐使用Mybatis
Spring Boot 不推荐使用 MyBatis,主要源于二者在设计理念、生态融合和开发风格上的差异。Spring Boot 强调“约定优于配置”,追求高效的开发体验和统一的框架风格。它通过自动配置和依赖注入,将复杂的基础设施工作隐藏在背后,让开发者可以专注于业务逻辑。而 MyBatis 更偏向于手动控制,强调 SQL 编写的灵活性与精确性,这种“显式配置”的风格在 Spring Boot 的体系中显得不够“Spring 化”。
在 Spring Boot 中,JPA(通常基于 Hibernate)得到了默认和深度的支持。它不仅提供了实体类到数据库表之间的自动映射能力,还能通过接口继承如 JpaRepository 来实现大部分常见的 CRUD 操作,几乎不需要写 SQL。这种面向对象的操作方式非常契合 Spring Boot 的开发理念。而 MyBatis 缺乏这样的统一接口标准,每一个查询都必须手动书写 Mapper 接口和 SQL 映射,导致代码重复多、维护成本高,不利于构建统一规范的架构。
此外,Spring Boot 的许多生态组件都是围绕 JPA 构建的。例如 Spring Data、Spring Data REST、Spring Security 等在与 JPA 协同工作时,可以自动识别实体类、权限注解和仓库接口,实现快速集成与配置。而 MyBatis 在这些方面往往需要额外的手工代码或第三方扩展来弥补功能差距,使得整个开发过程不够简洁和一致。
MyBatis 对复杂 SQL 的支持是它的优势,但也意味着它无法享受到像 JPA 那样的自动建表、字段同步、懒加载、级联操作等特性,这使得在开发初期或者需求频繁变化的项目中,使用 MyBatis 会显得繁琐与低效。同时,它的类型转换和对象关系映射能力相对较弱,复杂嵌套对象处理起来也需要手动配置,这与 Spring Boot 鼓励的自动化、低侵入、高复用的理念相悖。
因此,Spring Boot 并不是技术上无法使用 MyBatis,而是在它所倡导的开发模式中,MyBatis 显得不够“现代”,不够“自动”,也不够“统一”。在快速开发和规范统一的项目场景中,Spring Boot 更愿意推荐使用 JPA 或 Spring Data,只有在 SQL 控制要求高或性能调优需求明显的项目中,MyBatis 才是一个合适的选择。这也解释了为什么 Spring Boot 对 MyBatis 提供了官方 Starter,但始终没有像支持 JPA 那样将其设为默认或推荐选项。
二、Mybatis Plus 简介
MyBatis-Plus 是在 MyBatis 基础上进行增强的一个持久层框架,旨在简化 MyBatis 的开发过程,提高效率,降低重复代码。它并不改变 MyBatis 的核心理念,而是在其上层进行了封装,使开发者可以更方便地进行 CRUD 操作和复杂查询。MyBatis 本身需要手动编写 SQL 和 Mapper 接口,而 MyBatis-Plus 提供了丰富的自动化功能,如内置通用 Mapper、Service、分页插件、条件构造器等,从而大大减少了模板代码的数量。

通过集成 MyBatis-Plus,开发者可以仅通过继承 BaseMapper 接口,立即拥有一整套通用的数据库操作方法,如 selectById、insert、updateById、deleteById 等,避免了重复的 Mapper 方法定义。此外,它还支持强大的 Lambda 条件构造器,能用链式方式编写类型安全的查询条件,提升代码可读性和可维护性。MyBatis-Plus 还提供分页插件、乐观锁插件、逻辑删除、SQL 性能分析等实用功能,帮助开发者应对企业级应用中常见的持久层需求。
虽然 MyBatis-Plus 不属于 Spring Boot 官方推荐的技术栈,但它却很好地弥补了 MyBatis 开发繁琐、重复代码多的问题,使得 MyBatis 在与 Spring Boot 集成时更加现代化和高效。对于那些既想保留 SQL 控制力,又不想从零开始构建 CRUD 接口的团队来说,MyBatis-Plus 是一个非常实用且易于上手的选择。它在不改变原有 MyBatis 使用方式的前提下,通过增强功能提升了开发体验,越来越多的企业项目也因此倾向于在 Spring Boot 中选择 MyBatis-Plus 作为持久层方案。
三、SpringBoot 集成 Mybatis Plus
1、准备 SpringBoot 项目
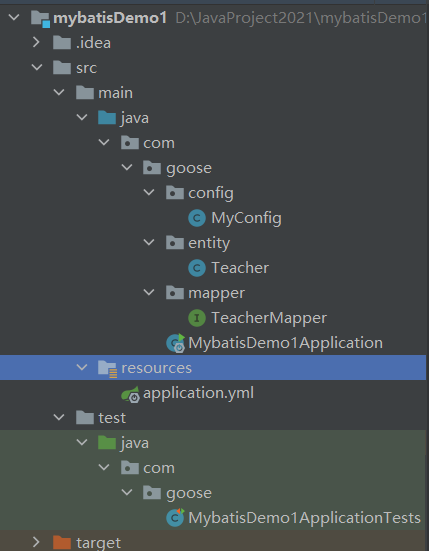
创建如上结构
2、导入依赖
org.mybatis.spring.boot mybatis-spring-boot-starter 2.3.1 com.mysql mysql-connector-j runtime org.springframework.boot spring-boot-starter-test test org.springframework.boot spring-boot-starter com.baomidou mybatis-plus-boot-starter 3.5.1 mysql mysql-connector-java runtime org.projectlombok lombok 3、创建实体类
package com.goose.entity;import lombok.*;import org.springframework.format.annotation.DateTimeFormat;import java.util.Date;@Data@AllArgsConstructor// @Getter// @Setter// @ToString@NoArgsConstructorpublic class Teacher { private Integer id; private String name; private String gender; private String subject; @DateTimeFormat(pattern = \"yyyy-MM-dd\") private Date hireDate;}4、创建好配置文件
application.yml
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver type: com.zaxxer.hikari.HikariDataSource url: jdbc:mysql://localhost:3306/springbootdemo username: root password: 123456# 配置MyBatis日志mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl5、创建配置类
package com.goose.config;import com.baomidou.mybatisplus.annotation.DbType;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class MyConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); return interceptor; }}这个配置类为 MyBatis-Plus 启用分页功能,在执行分页查询时自动处理 LIMIT 语句等逻辑,无需手写 SQL 来分页。
6、创建mapper 接口
package com.goose.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;import com.goose.entity.Teacher;import org.springframework.stereotype.Repository;@Repositorypublic interface TeacherMapper extends BaseMapper {}7、安装 lombok 插件
File——Settings——Plugins
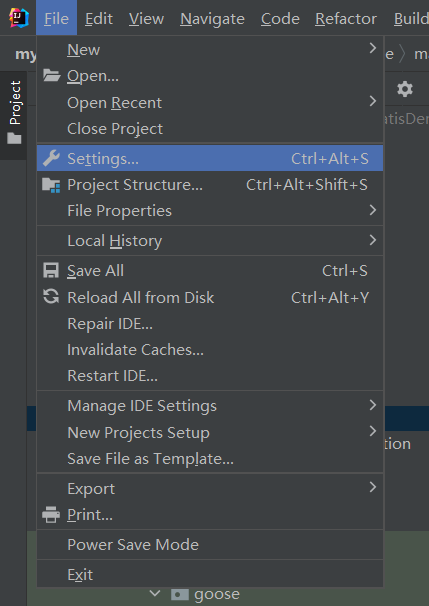
搜索找到 lombok 插件,下载安装后,重启 IDE
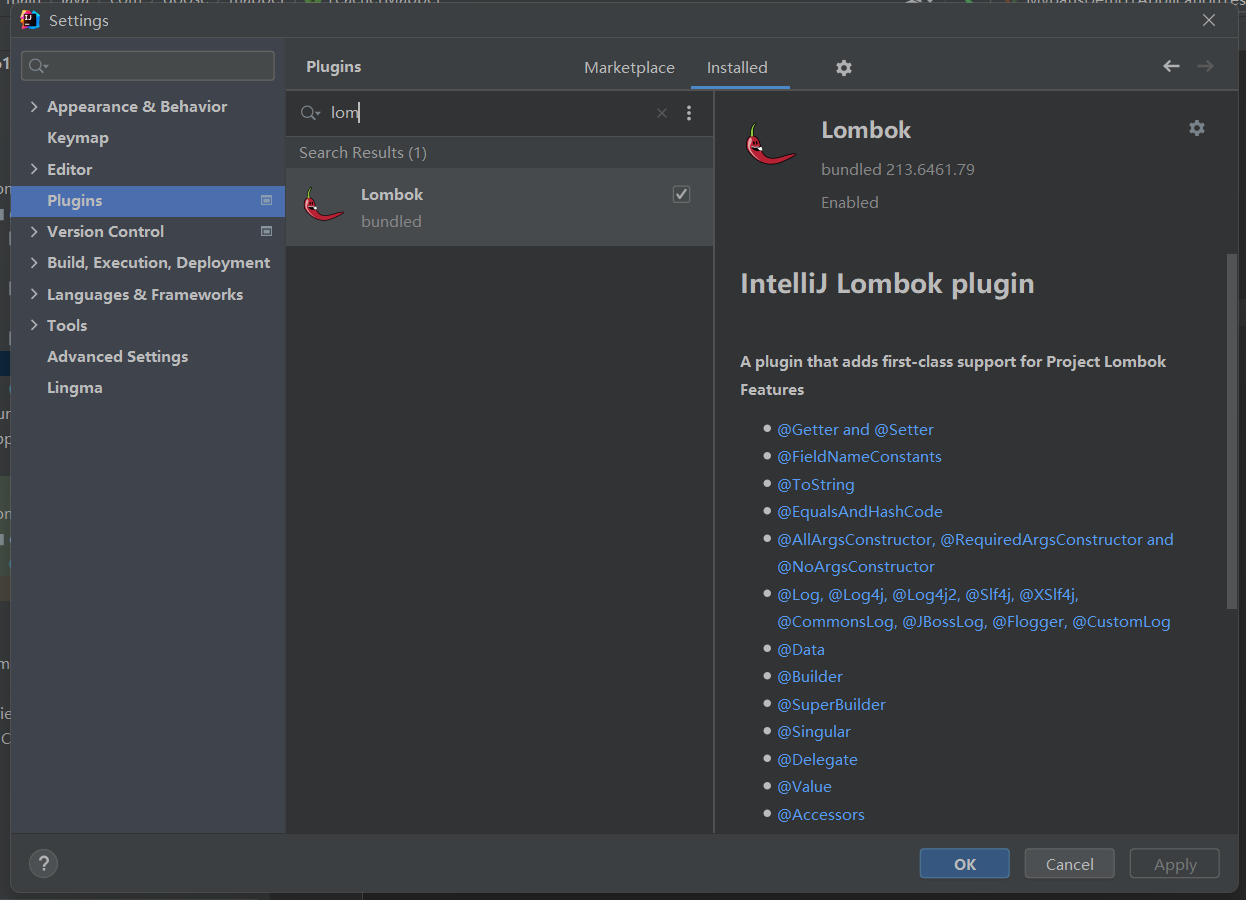
Lombok 是一个 Java 编译器级别的工具库,它的作用是通过注解的方式,自动为 Java 类生成常见的样板代码,如 getter、setter、构造函数、toString、equals、hashCode 等,从而大幅度简化代码、提升开发效率、减少冗余。
具体来说,Lombok 插件的主要作用如下:
- 简化 Getter/Setter 编写:使用 @Getter 和 @Setter 注解,可以自动为类的字段生成对应的 getter 和 setter 方法,无需手写。
- 自动生成构造函数:@NoArgsConstructor、@AllArgsConstructor、@RequiredArgsConstructor 可以自动生成无参、全参和指定字段的构造函数。
- 简化 toString/equals/hashCode 方法:使用 @ToString、@EqualsAndHashCode 注解后,不再需要手动重写这些方法。
- 简化 Builder 模式编写:@Builder 可以自动实现链式调用构建对象的方式,适用于构造参数多的类。
- 提供 Data 注解一站式生成常见方法:@Data 相当于同时加上 @Getter、@Setter、@ToString、@EqualsAndHashCode、@RequiredArgsConstructor,是实体类开发中非常常用的注解。
- 简化日志对象创建:@Slf4j、@Log4j 等注解可以自动为类生成对应类型的日志对象。
Lombok 插件的运行机制是在编译期通过注解处理器修改字节码,并不会在源码中直接生成方法,因此你看不到生成的 getter/setter,但它们确实存在于最终编译后的 class 文件中。Ctrl + F12 进行查看
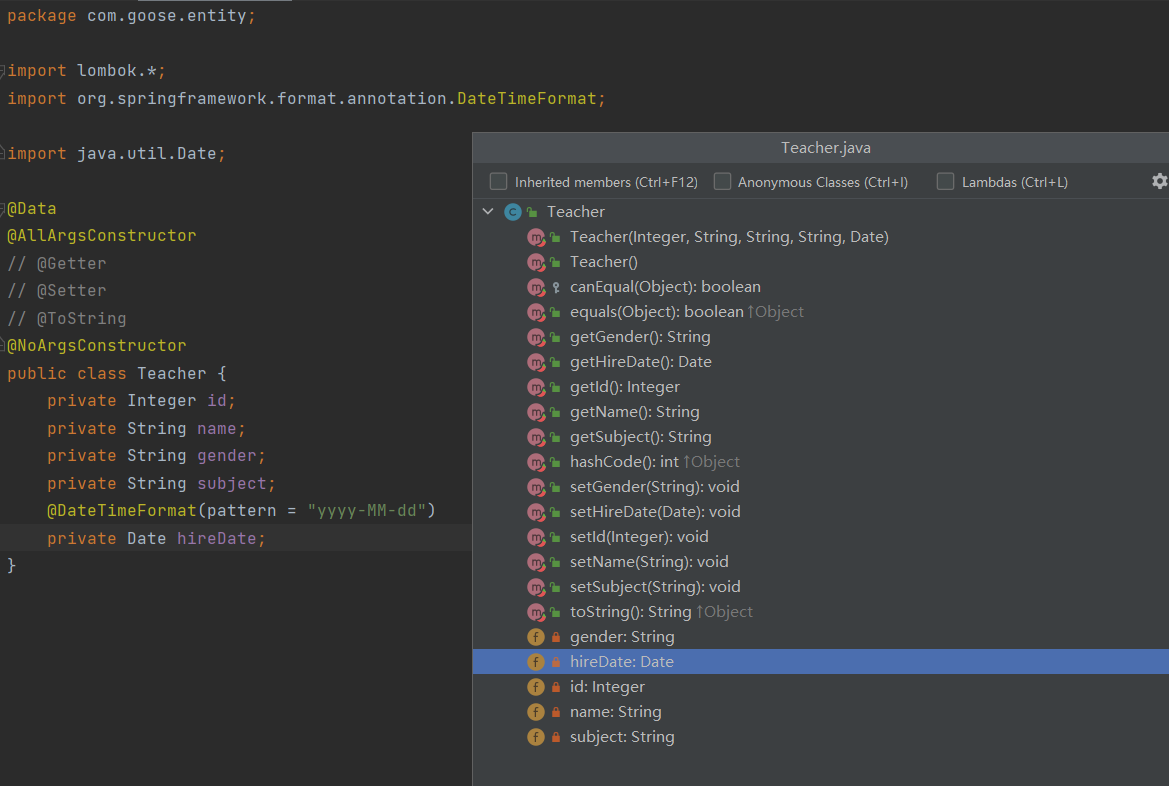
由于它改写的是编译行为,所以在 IDEA 中使用时,必须安装 Lombok 插件并开启注解处理器,否则会出现提示找不到方法的错误。
8、创建数据库表
生成测试数据
9、编写测试类
简单的CRUD操作可以不用再自己编写SQL,直接调用BaseMapper 中的方法即可。
这里直接使用持久层进行注入,不涉及到页面的使用
package com.goose;import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;import com.goose.entity.Teacher;import com.goose.mapper.TeacherMapper;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import java.text.SimpleDateFormat;import java.util.*;@SpringBootTestclass MybatisDemo1ApplicationTests { @Autowired public TeacherMapper teacherMapper; @Test public void findAll() { teacherMapper.selectList(null).forEach(System.out::println); } / * 插入实体对象 */ @Test public void insert() { Date now = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat(\"yyyy-MM-dd\"); simpleDateFormat.format(now); Teacher teacher = new Teacher(); teacher.setName(\"李华\"); teacher.setGender(\"male\"); teacher.setSubject(\"化学\"); teacher.setHireDate(now); teacherMapper.insert(teacher); } / * 根据主键id删除一条数据 */ @Test public void deleteById() { teacherMapper.deleteById(16); } / * 传入实体数据,根据实体中的数据进行删除 */ @Test public void deleteById_Entity() { Teacher teacher = new Teacher(); teacher.setId(18); teacherMapper.deleteById(teacher); } @Test public void deleteByMap() { // string放列名,Object放想要删除该列中满足某条件 Map map = new HashMap(); // 这里使用name作为条件 map.put(\"name\", \"Ivy Ma\"); map.put(\"gender\", \"female\"); // 删除所有name 为 Ivy Ma 的教师 // 可以多行删除,但是不会操作具有外键约束的内容 // DELETE FROM teacher WHERE gender = ? AND name = ? teacherMapper.deleteByMap(map); } @Test public void delete() { QueryWrapper teacherQueryWrapper = new QueryWrapper(); // eq应该是等于的,le应该是小于,ge应该是大于 // teacherQueryWrapper.eq(\"name\",\"Queena\"); // DELETE FROM teacher WHERE (name = ?) // teacherMapper.delete(teacherQueryWrapper); teacherQueryWrapper.eq(\"name\", \"Queena\"); teacherQueryWrapper.eq(\"subject\", \"Biology\"); // DELETE FROM teacher WHERE (name = ? AND subject = ?) teacherMapper.delete(teacherQueryWrapper); } @Test public void deleteBathIds() { List list = new ArrayList(); list.add(14); list.add(22); list.add(6); list.add(18); // ==> Preparing: DELETE FROM teacher WHERE id IN ( ? , ? , ? , ? ) // ==> Parameters: 14(Integer), 22(Integer), 6(Integer), 18(Integer) teacherMapper.deleteBatchIds(list); } @Test public void update() { Teacher teacher = new Teacher(); teacher.setId(21); teacher.setSubject(\"English\"); teacher.setGender(\"male\"); // 传入的对象需要主键 // ==> Preparing: UPDATE teacher SET gender=?, subject=? WHERE id=? // ==> Parameters: male(String), English(String), 21(Integer) teacherMapper.updateById(teacher); } @Test public void updateBy() { QueryWrapper teacherQueryWrapper = new QueryWrapper(); teacherQueryWrapper.eq(\"subject\", \"English\"); Teacher teacher = new Teacher(); teacher.setGender(\"female\"); // ==> Preparing: UPDATE teacher SET gender=? WHERE (subject = ?) // ==> Parameters: female(String), English(String) teacherMapper.update(teacher, teacherQueryWrapper); } @Test public void selectById() { Teacher teacher = teacherMapper.selectById(32); // ==> Preparing: SELECT id,name,gender,subject,hire_date FROM teacher WHERE id=? // ==> Parameters: 32(Integer) System.out.println(teacher); } @Test public void selectBatchIds() { List list = new ArrayList(); list.add(34); list.add(42); list.add(26); list.add(38); // ==> Preparing: SELECT id,name,gender,subject,hire_date FROM teacher WHERE id IN ( ? , ? , ? , ? ) // ==> Parameters: 34(Integer), 42(Integer), 26(Integer), 38(Integer) List teachers = teacherMapper.selectBatchIds(list); System.out.println(teachers); } @Test public void selectByMap(){ Map map = new HashMap(); map.put(\"gender\",\"male\"); map.put(\"subject\",\"Chemistry\"); // ==> Preparing: SELECT id,name,gender,subject,hire_date FROM teacher WHERE gender = ? AND subject = ? // ==> Parameters: male(String), Chemistry(String) List teachers = teacherMapper.selectByMap(map); System.out.println(teachers); } @Test public void selectOne(){ QueryWrapper teacherQueryWrapper = new QueryWrapper(); teacherQueryWrapper.eq(\"name\",\"Jason\"); // 只能查一条数据,数据多于一条,抛出错误,查询条件比较严格 Teacher teacher = teacherMapper.selectOne(teacherQueryWrapper); System.out.println(teacher); } @Test public void exist(){ QueryWrapper teacherQueryWrapper = new QueryWrapper(); teacherQueryWrapper.eq(\"subject\",\"Chemistry\"); // ==> Preparing: SELECT COUNT( * ) FROM teacher WHERE (subject = ?) boolean exists = teacherMapper.exists(teacherQueryWrapper); System.out.println(exists); } @Test public void selectCount(){ QueryWrapper teacherQueryWrapper = new QueryWrapper(); teacherQueryWrapper.eq(\"gender\",\"female\"); // ==> Preparing: SELECT COUNT( * ) FROM teacher WHERE (gender = ?) // ==> Parameters: female(String) Long aLong = teacherMapper.selectCount(teacherQueryWrapper); System.out.println(aLong); } @Test public void selectList(){ QueryWrapper teacherQueryWrapper = new QueryWrapper(); teacherQueryWrapper.eq(\"gender\",\"female\"); // ==> Preparing: SELECT id,name,gender,subject,hire_date FROM teacher WHERE (gender = ?) // ==> Parameters: female(String) List teachers = teacherMapper.selectList(teacherQueryWrapper); System.out.println(teachers); } @Test public void selectMaps(){ QueryWrapper teacherQueryWrapper = new QueryWrapper(); teacherQueryWrapper.eq(\"gender\",\"female\"); // ==> Preparing: SELECT id,name,gender,subject,hire_date FROM teacher WHERE (gender = ?) // ==> Parameters: female(String) List<Map> maps = teacherMapper.selectMaps(teacherQueryWrapper); // 把每个Teacher对象拆开了,拆成单独的map对象 System.out.println(maps); } @Test public void selectObjs(){ QueryWrapper teacherQueryWrapper = new QueryWrapper(); teacherQueryWrapper.eq(\"gender\",\"female\"); // ==> Preparing: SELECT id,name,gender,subject,hire_date FROM teacher WHERE (gender = ?) // ==> Parameters: female(String) List objects = teacherMapper.selectObjs(teacherQueryWrapper); // [1, 3, 4, 5, 7, 9, 11, 13, 15, 19, 20, 21, 23, 25, 27, 29, 31, 33, 35, 37, 38, 39, 41, 43, 45, 47, 49] // 只返回第一个字段的值 System.out.println(objects); } @Test public void testSelectPage() { // 创建分页对象:第1页,每页5条记录 Page page = new Page(1, 5); // 构造查询条件:只查 gender = \'female\' QueryWrapper wrapper = new QueryWrapper(); wrapper.eq(\"gender\", \"female\"); // 执行分页查询 Page resultPage = teacherMapper.selectPage(page, wrapper); // 打印分页结果 System.out.println(\"总记录数: \" + resultPage.getTotal()); System.out.println(\"总页数: \" + resultPage.getPages()); System.out.println(\"当前页数据:\"); resultPage.getRecords().forEach(System.out::println); } @Test public void testSelectMapsPage() { // 分页参数 Page<Map> page = new Page(1, 5); // 查询条件:查 subject = \'Math\' QueryWrapper wrapper = new QueryWrapper(); wrapper.eq(\"subject\", \"Math\"); // 分页查询返回 Map 列表 Page<Map> resultPage = teacherMapper.selectMapsPage(page, wrapper); // 打印结果 System.out.println(\"总记录数: \" + resultPage.getTotal()); System.out.println(\"总页数: \" + resultPage.getPages()); System.out.println(\"当前页 Map 数据:\"); resultPage.getRecords().forEach(System.out::println); }}
