OSPF 路由协议多区域
一、课程目标
本课程旨在帮助学习者掌握 OSPF 多区域的核心知识,具体包括:掌握 OSPF 各种 LSA 的内容和传递过程、了解普通区域与特殊区域的特点、掌握 OSPF 多区域的配置。
二、OSPF 多区域划分的必要性
-
单区域存在的问题
单区域 OSPF 网络中,存在三大问题:一是链路状态数据库(LSDB)庞大,占用大量内存,SPF 算法计算开销大;二是 LSA(链路状态通告)洪泛范围广,拓扑变化的影响范围大;三是路由无法汇总,导致路由表庞大,查找路由开销高。
举例:一个大型园区如果只用一个区域,所有路由器都要存储整个园区的拓扑细节,一旦某个角落的网络变化,所有路由器都要重新计算路径,效率极低。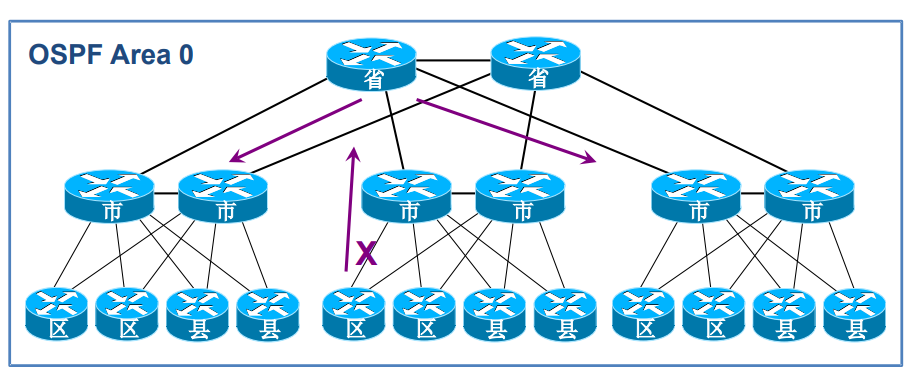
-
多区域的优势
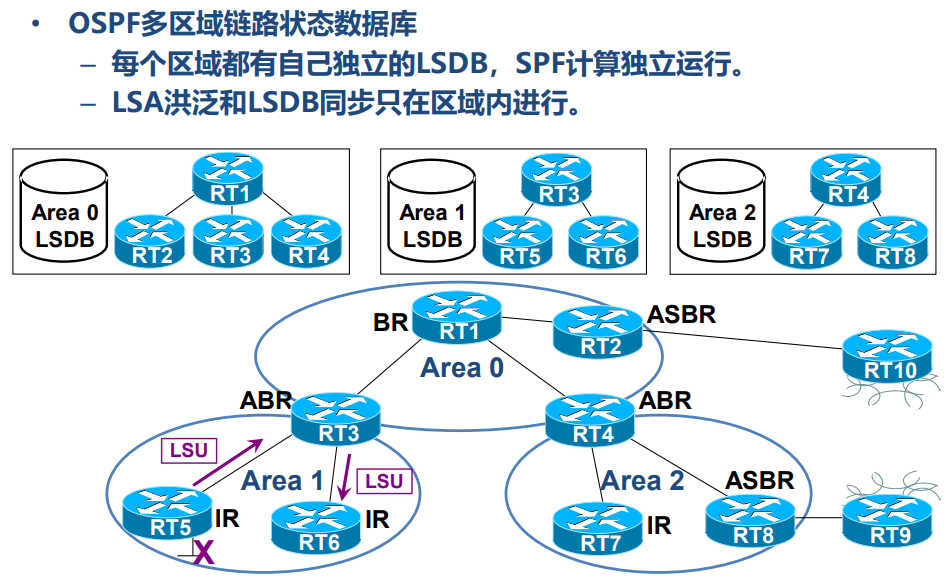
划分区域后,每个区域拥有独立的 LSDB,LSA 洪泛被限制在区域内,减少了拓扑变化的影响范围;同时,区域边界可以对路由进行汇总,减小路由表规模。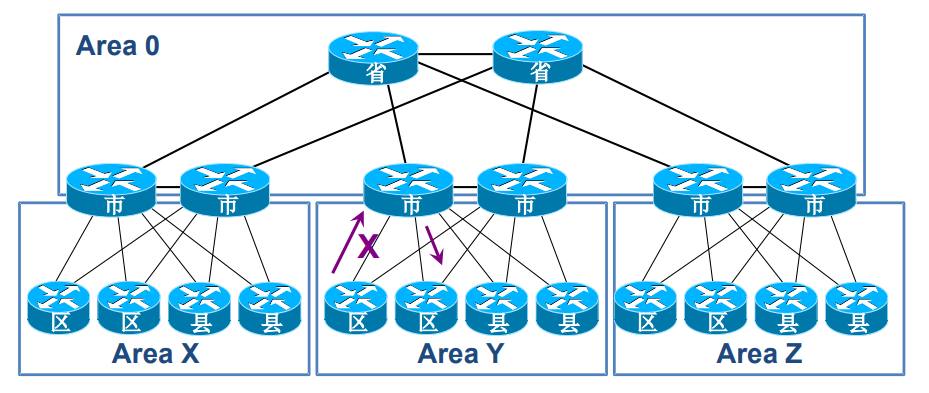
三、OSPF 多区域基本概念
-
区域分类
- 骨干区域(Area 0):必须连续,不能被分割,是所有区域交换路由信息的核心。
- 非骨干区域:必须直接与 Area 0 相连,非骨干区域之间不能直接交换路由,需通过 Area 0 中转。
- 特殊区域:具有特殊性质,如 Stub、NSSA 等,用于简化路由管理。
举例:骨干区域类似城市主干道,非骨干区域类似支路,支路必须连接主干道才能与其他支路互通。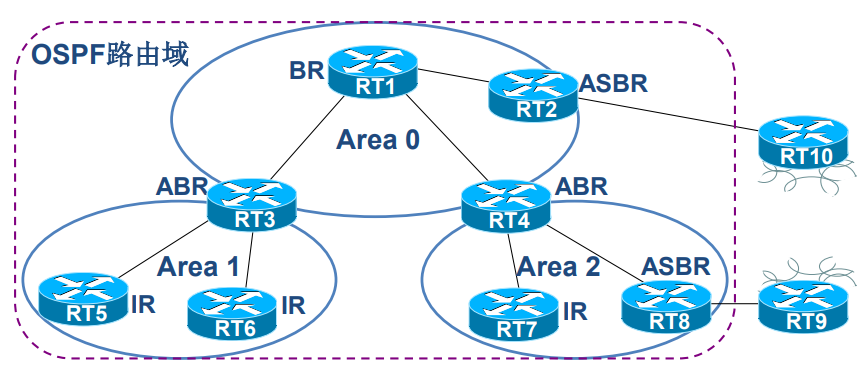
-
关键设备
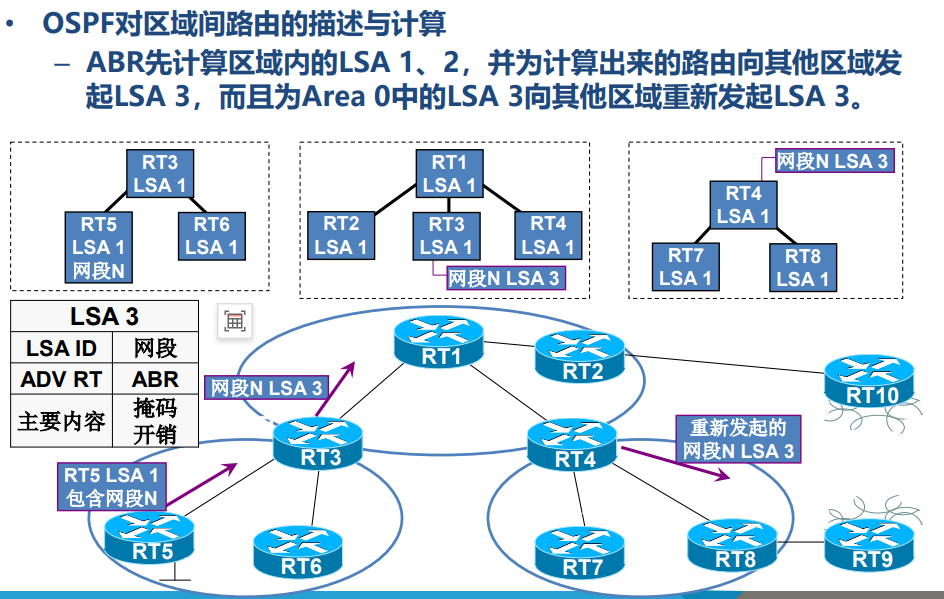
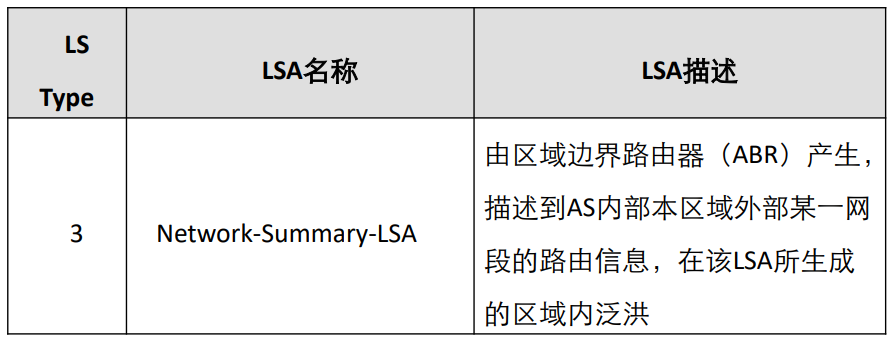
- ABR(区域边界路由器):连接多个区域(至少包含 Area 0),负责在区域间传递路由信息,会生成汇总 LSA(LSA 3)描述区域间路由。
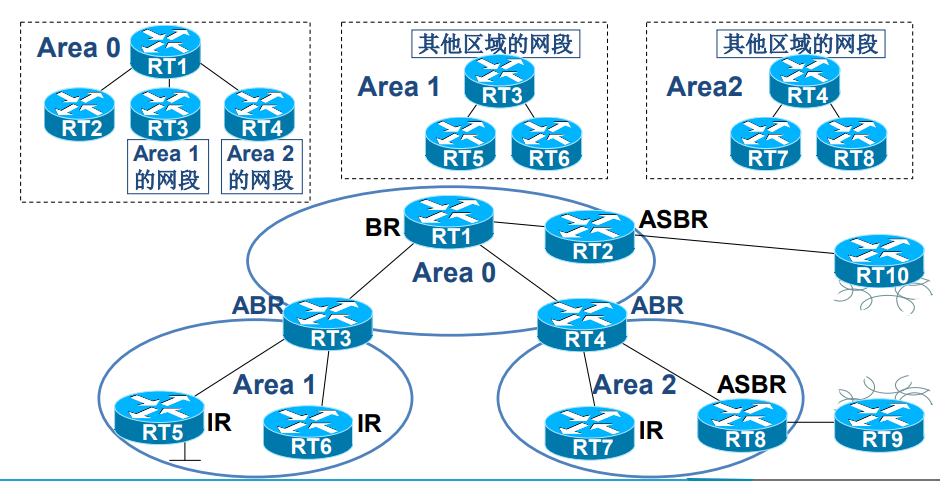
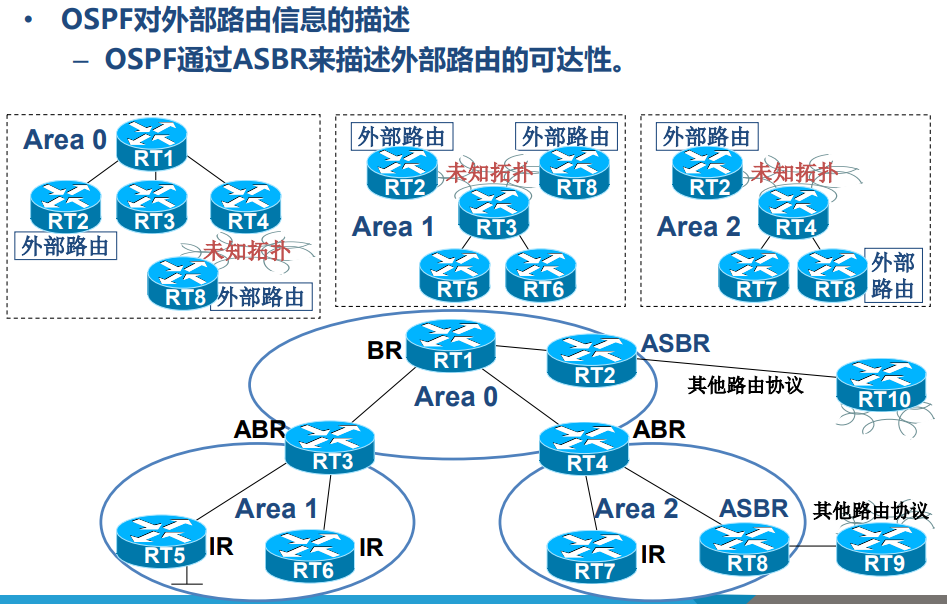
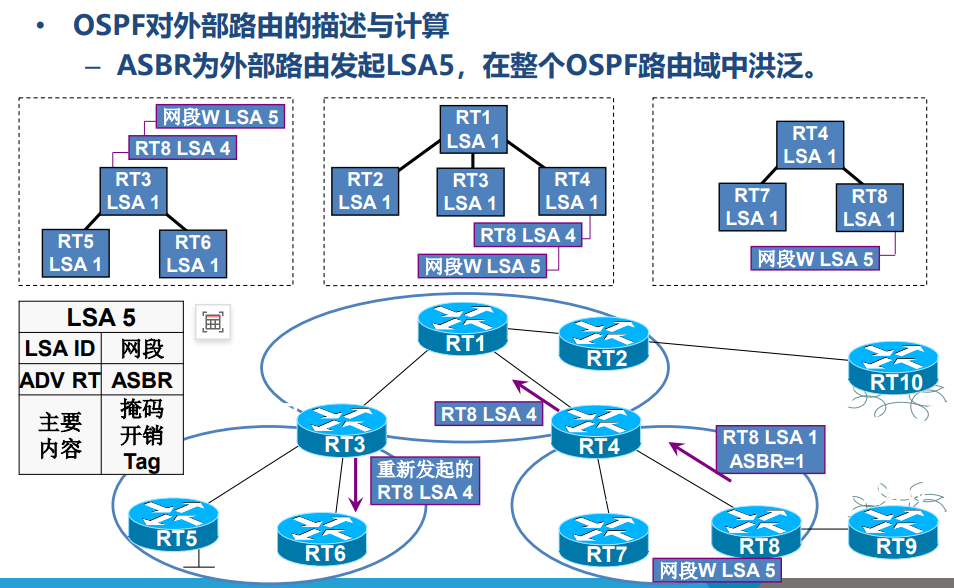
- ASBR(自治系统边界路由器):连接 OSPF 域与其他路由协议(如 RIP),负责引入外部路由,会生成外部 LSA(LSA 5 或 LSA 7)描述外部路由。
- ABR(区域边界路由器):连接多个区域(至少包含 Area 0),负责在区域间传递路由信息,会生成汇总 LSA(LSA 3)描述区域间路由。
LSDB(链路状态数据库)
四、OSPF 的 LSA 分类与传播
-
LSA 类型及特点
OSPF 的 LSA 分为 7 种主要类型,核心区别在于发起者、洪泛范围和作用:LSA 类型 名称 发起者 洪泛范围 作用 1 路由器 LSA 所有 OSPF 路由器 本区域内 描述路由器直连的拓扑信息(如接口、邻居) 2 网络 LSA DR(指定路由器) 本区域内 描述广播型 / NBMA 网络中连接的路由器列表 3 汇总 LSA ABR 单个区域内 描述区域间的路由信息(如其他区域的网段) 4 ASBR 汇总 LSA ABR 单个区域内 描述 ASBR 的位置(帮助其他区域找到外部路由的入口) 5 外部 LSA ASBR 整个 OSPF 域(除特殊区域) 描述 OSPF 外部的路由(如从 RIP 引入的路由) 7 NSSA 外部 LSA NSSA 区域的 ASBR 本 NSSA 区域内 描述 NSSA 区域的外部路由,会被 ABR 转换为 LSA 5 转发到其他区域 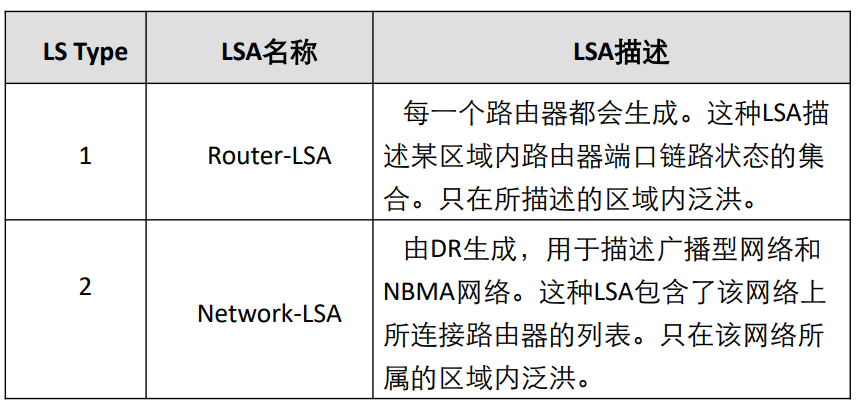
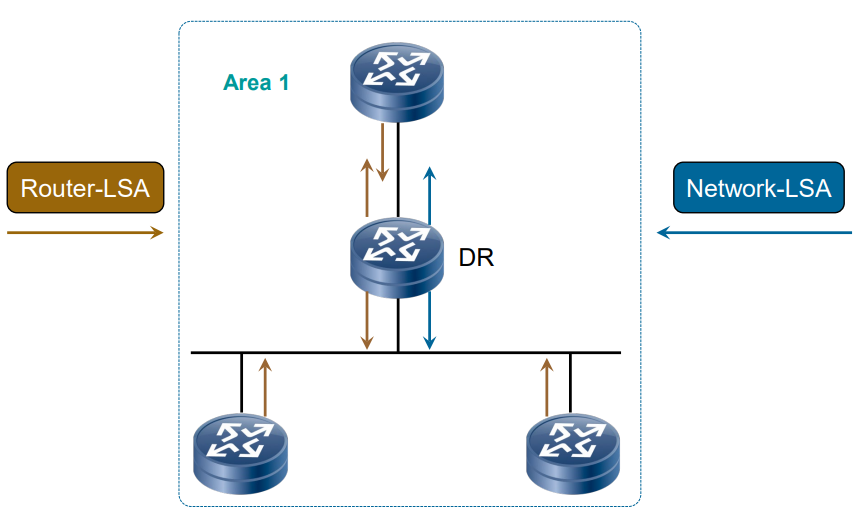
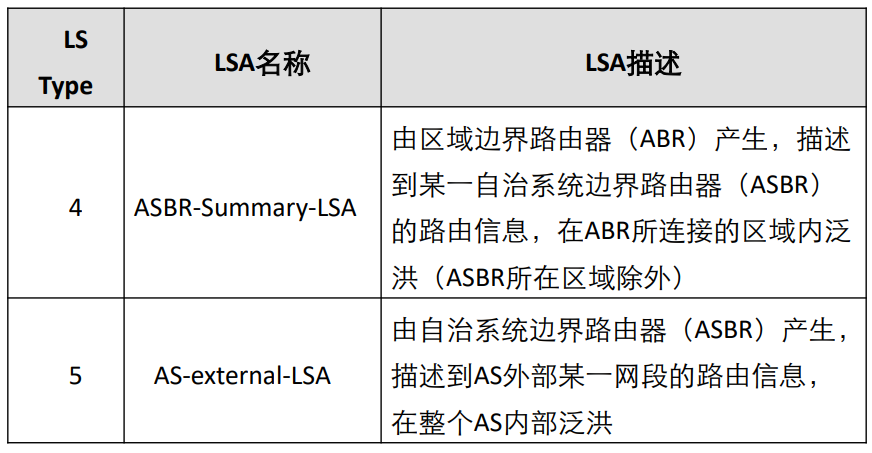
举例:LSA 1 类似 “个人名片”,每个路由器在自己区域内分享自己的位置和连接;LSA 3 类似 “区域名片”,ABR 汇总其他区域的信息发给本区域;LSA 5 类似 “外部邀请函”,ASBR 告诉整个 OSPF 域 “外部有新路由可用”。


-
LSA 传播过程
- 区域内路由传播:以网段 10.1.3.0/24 为例,RT3(Area 1 内的路由器)生成 LSA 1,在 Area 1 内洪泛;区域内所有路由器通过 LSA 1 和 LSA 2 计算本地拓扑。
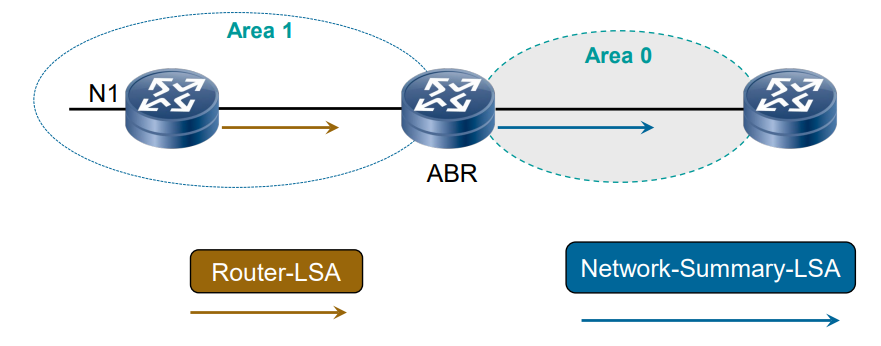
- 区域间路由传播:ABR(如 RT1)收到 Area 1 的 LSA 1 后,生成 LSA 3(描述 10.1.3.0/24)并在 Area 0 洪泛;其他区域的 ABR(如 RT6)收到后,再生成新的 LSA 3 转发到自己所在的区域(如 Area 2)。
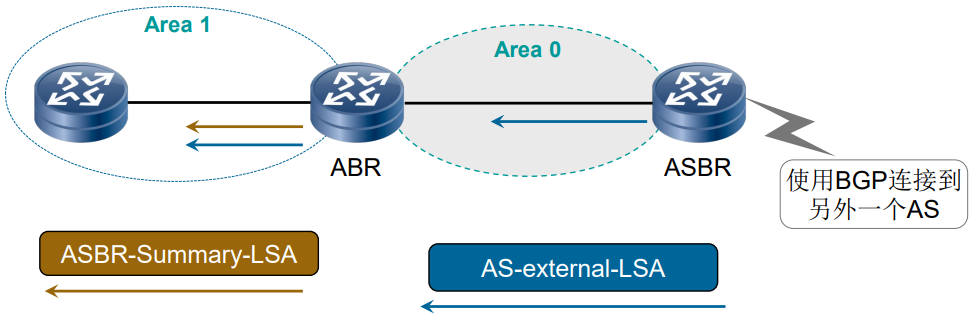
- 外部路由传播:以外部路由 172.16.4.0/24 为例,ASBR(如 RT2)生成 LSA 5 在整个 OSPF 域洪泛;同时,ABR(如 RT6)生成 LSA 4(描述 RT2 的位置),帮助其他区域的路由器找到 ASBR,从而访问外部路由。

五、OSPF 特殊区域
特殊区域通过限制 LSA 类型简化路由管理,常见类型及特点如下:
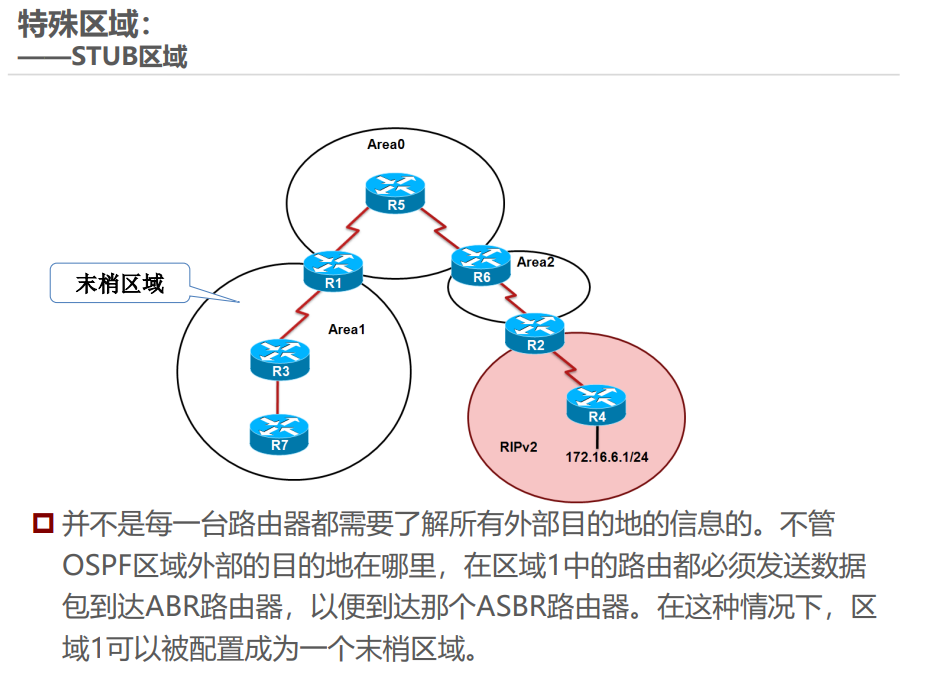
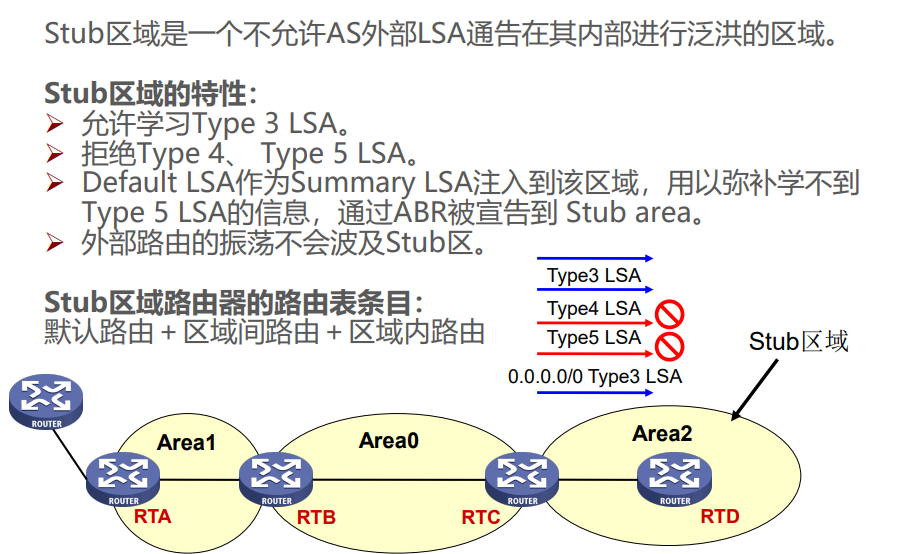
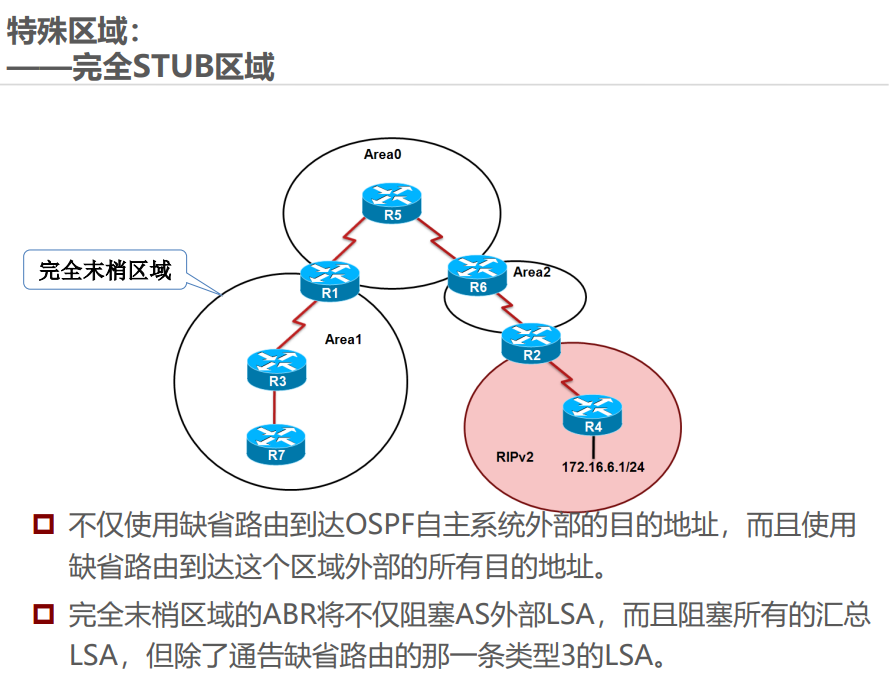
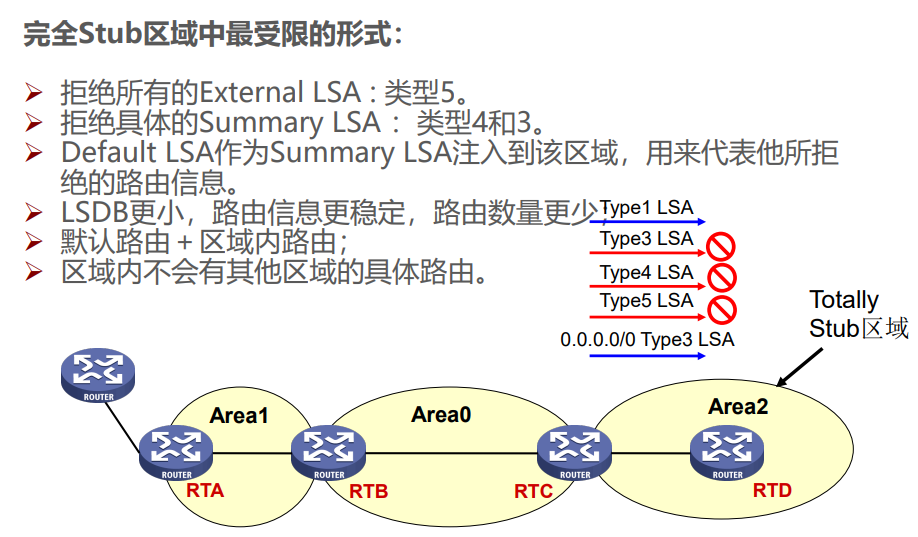
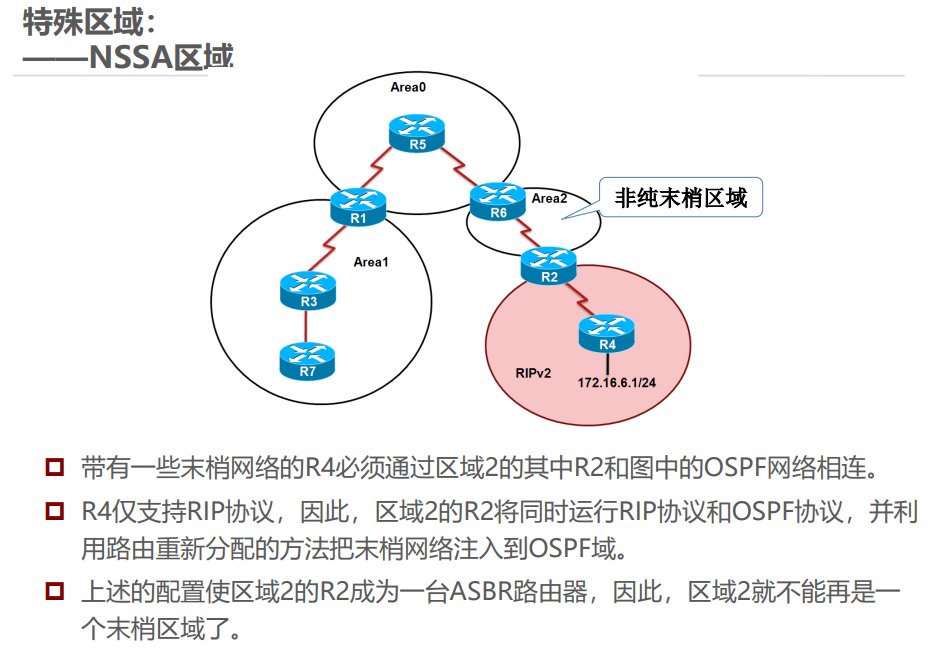
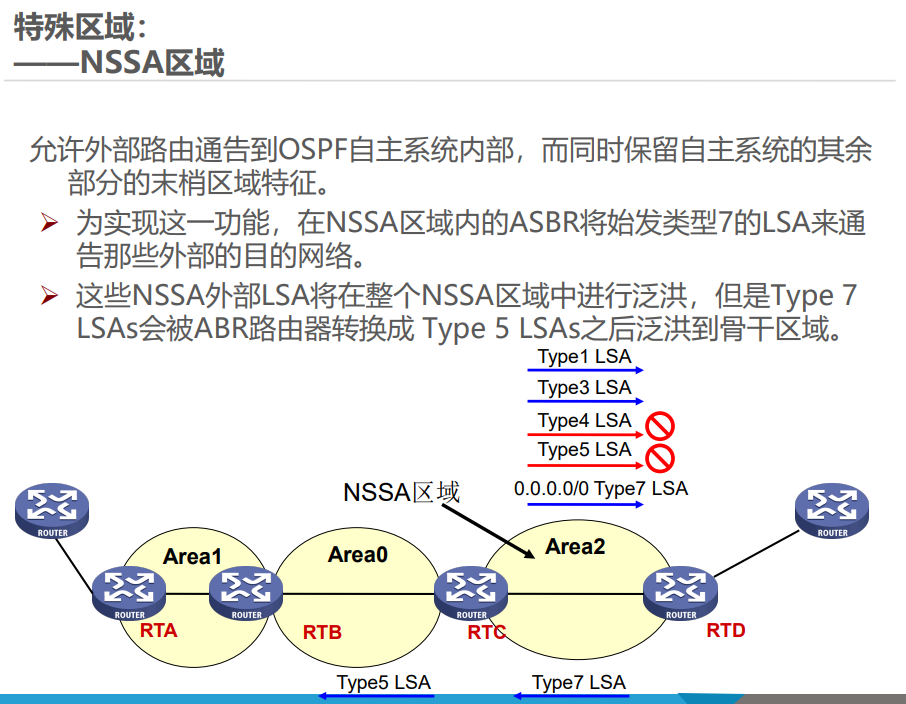
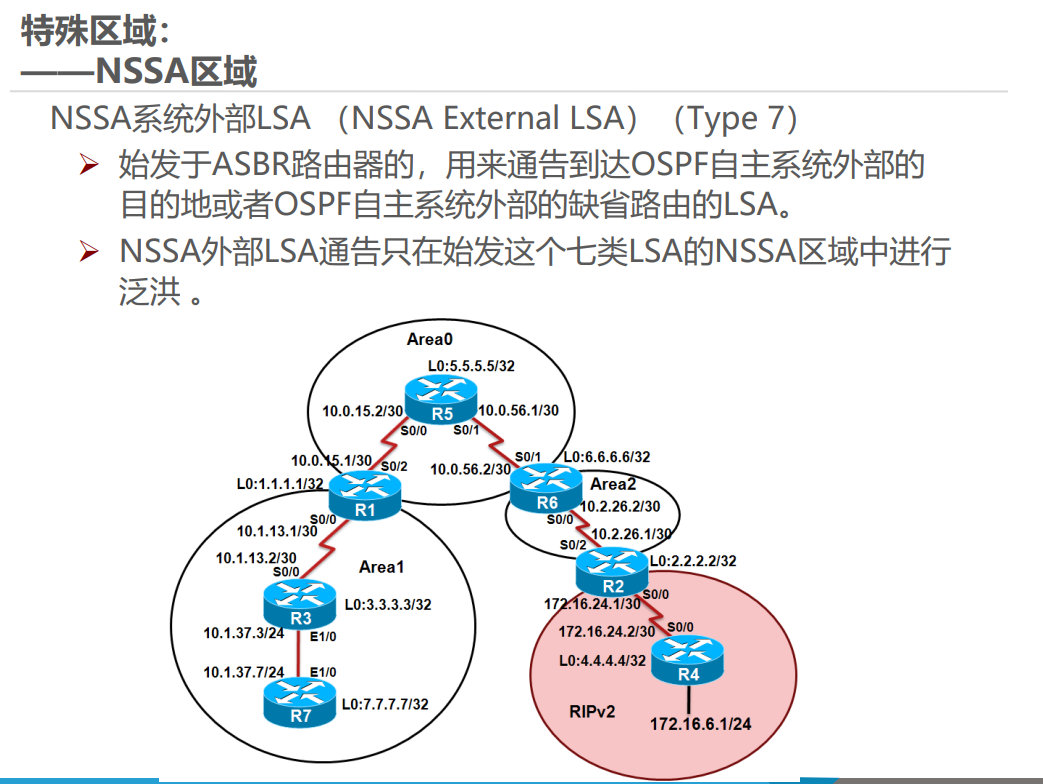
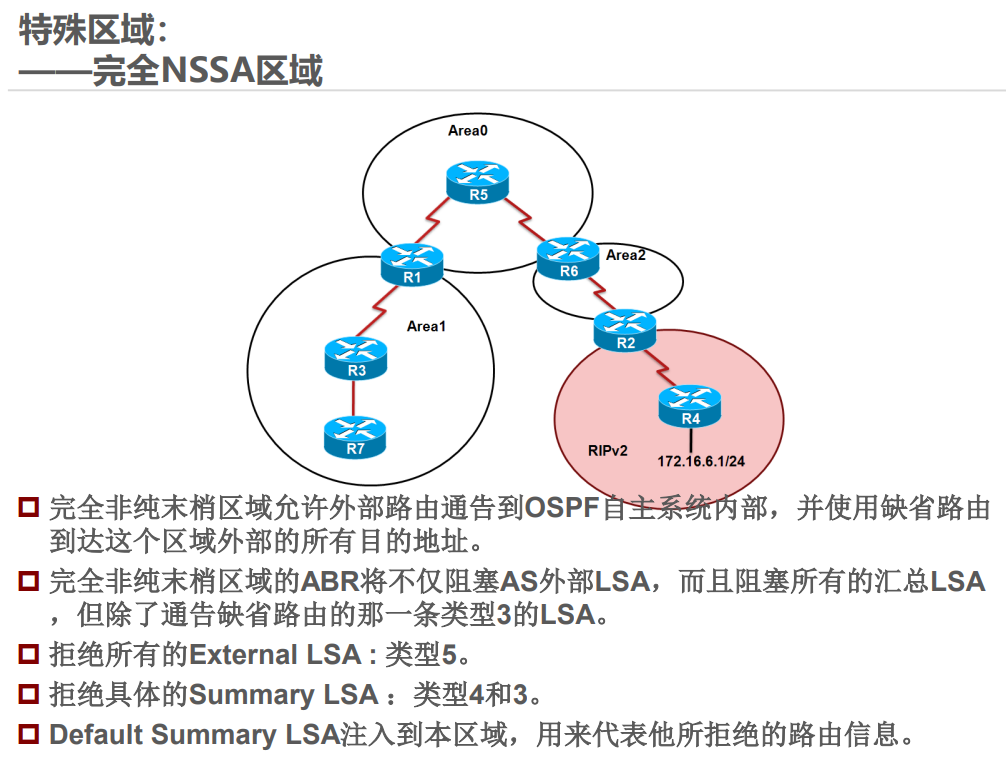
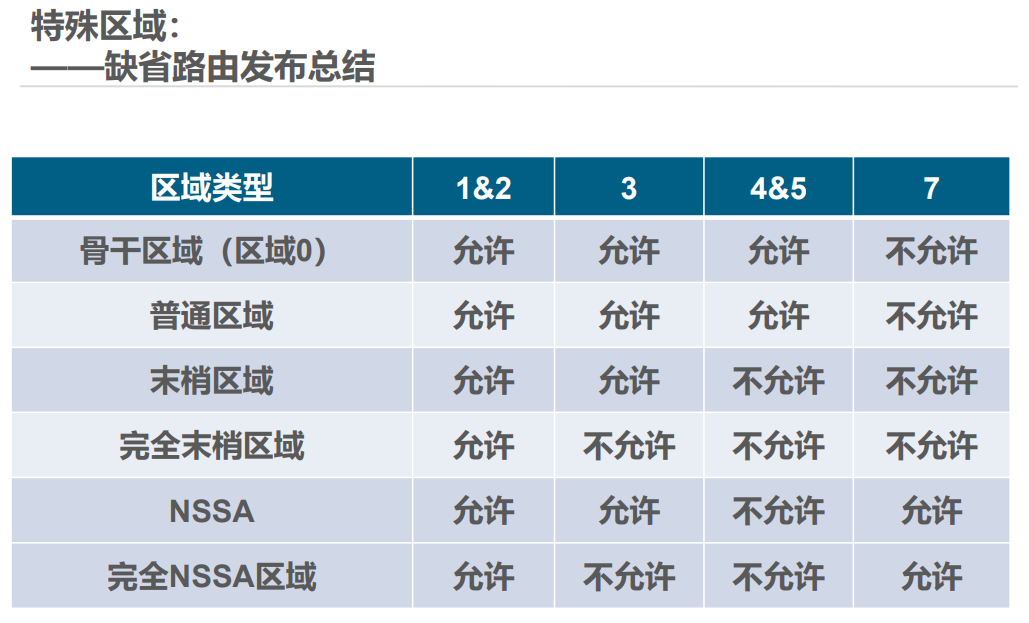
举例:Stub 区域类似 “封闭小区”,只知道小区内的路和到主干道的默认路,不知道外部城市的详细路;NSSA 区域类似 “半开放小区”,可以自己引入外部小路(LSA 7),再通过小区门口(ABR)转换为大路(LSA 5)告诉其他区域。
六、路由汇总与外部路由开销
-
路由汇总
为减少路由条目,ABR 和 ASBR 可对路由进行汇总:- 区域间汇总(ABR):通过
area N range 目标网段 子网掩码命令,将 Area N 内的细化路由汇总为一条路由,以 LSA 3 发布到其他区域。 - 外部路由汇总(ASBR):通过
summary-address 目标网段 子网掩码命令,将引入的外部细化路由汇总为一条路由,以 LSA 5 发布。
举例:将 172.18.0.0/24、172.18.1.0/24 等 4 个网段汇总为 172.18.0.0/22,路由表中只需保留一条汇总路由,简化管理。
- 区域间汇总(ABR):通过
-
外部路由开销类型
OSPF 外部路由的开销计算有两种类型:- 类型 1:总开销 = LSA 携带的外部开销 + 本地到 ASBR 的开销(与 OSPF 内部开销统一)。
- 类型 2:总开销 = LSA 携带的外部开销(忽略本地到 ASBR 的开销,默认类型)。
优先级:类型 1 优于类型 2(类型 2 相当于外部开销 “无穷大”)。例如,访问外部网段时,类型 1 会计算 “本地到入口(ASBR)的路费 + 外部路费”,类型 1 更精准;类型 2 只算 “外部路费”,适合外部路由开销远大于内部的场景。
七、OSPF 多区域配置案例
以一个多区域 OSPF 网络为例,核心配置包括:
- 区域划分:将网络分为 Area 0(骨干)、Area 1、Area 2(NSSA 区域)。
- 路由汇总:ABR(如 SWA、SWB)对 Area 1 的 172.18.0.0/24 等网段汇总为 172.18.0.0/22。
- NSSA 配置:Area 2 配置为 NSSA 区域,ASBR(如 SWD)引入外部路由并汇总为 192.168.0.0/22。
- 默认路由注入:核心交换机(SWA、SWB)向 OSPF 域注入默认路由,确保所有区域能访问外部网络。

