计算机网络
目录
一、OSI 与 TCP/IP 各层的结构与功能
二、三次握手和四次挥手
1. 三次握手
2. 为什么要三次握手
3. 第二次握手回传了 ACK,为什么还要回传 SYN
4. 四次挥手
三、TCP 协议如何保证可靠传输
四、状态码
五、Cookie 和 Session
六、HTTP 1.0 和 HTTP 1.1
七、URI 和 URL
八、HTTP 和 HTTPS
一、OSI 与 TCP/IP 各层的结构与功能
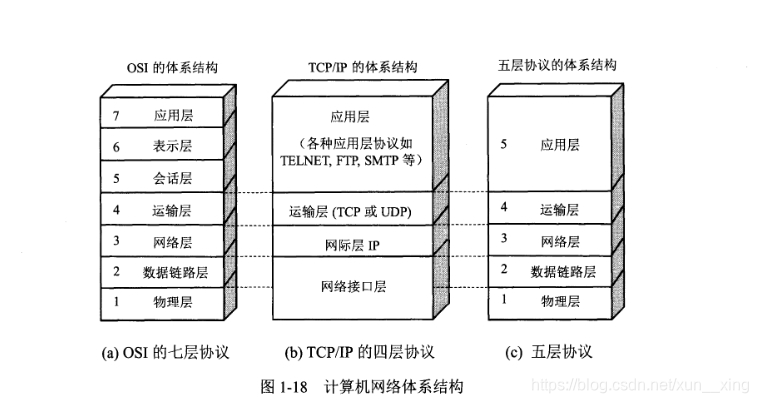
- 应用层
应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。 - 运输层
运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务。
运输层主要使用以下两种协议:
- 传输控制协议 TCP(Transmission Control Protocol):提供面向连接的,可靠的数据传输服务。
- 用户数据协议 UDP(User Datagram Protocol):提供无连接的,尽最大努力的数据传输服务(不保证数据传输的可靠性)。
- 网络层(网际层/IP 层)
在计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。 - 数据链路层
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。 数据链路层将网络层交下来的 IP 数据报组装成帧。 - 物理层
物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。
二、三次握手和四次挥手
1. 三次握手
- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
2. 为什么要三次握手
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
3. 第二次握手回传了 ACK,为什么还要回传 SYN
接收端传回发送端所发送的ACK是为了告诉客户端,我接收到的信息确实就是你所发送的信号了,这表明从客户端到服务端的通信是正常的。而回传SYN则是为了建立并确认从服务端到客户端的通信。
4. 四次挥手
- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
- 服务器-关闭与客户端的连接,发送一个 FIN 给客户端
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
三、TCP 协议如何保证可靠传输
1. 应用数据被分割成 TCP 认为最适合发送的数据块。
2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
3. 校验和: TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
4. TCP 的接收端会丢弃重复的数据。
5. 流量控制: TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
6. 拥塞控制: 当网络拥塞时,减少数据的发送。
7. ARQ协议: 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
8. 超时重传: 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
滑动窗口和流量控制
- TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。
- 拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。TCP的拥塞控制采用了四种算法,即慢开始、拥塞避免、快重传和快恢复。
四、状态码
1xx 信息状态码:表示接收的请求正在处理。
2xx 成功状态码:表示请求正常处理完毕。
- 200 OK:最常见状态码,请求成功。
- 204 No Content:请求成功,但服务器无数据返回。
- 206 Partial Content:客户端请求部分资源(如断点续传),服务器成功返回指定部分。
3xx 重定向状态码:需要后续操作才能完成这一请求。
- 301 Moved Permanently:资源永久迁移到新地址。
- 302 Found:资源临时迁移到新地址。
- 304 Not Modified:资源未修改,客户端可直接使用本地缓存。
4xx 客户端错误状态码:表示请求包含语法错误或无法完成。
- 400 Bad Request:请求格式错误。
- 401 Unauthorized:请求需要身份验证。
- 403 Forbidden:客户端已登录(身份验证通过),但无权限访问资源。
- 404 Not Found:最常见错误之一,服务器找不到请求的资源。
5xx 服务器错误状态码:服务器在处理请求的过程中发生了错误。
- 500 Internal Server Error:最常见的服务器错误,服务器遇到未知错误。
- 503 Service Unavailable:服务器暂时无法处理请求(如服务器维护、负载过高),通常会告知 “何时恢复”。
五、Cookie 和 Session
Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
Cookie 一般用来保存用户信息。Session 的主要作用就是通过服务端记录用户的状态。
Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
六、HTTP 1.0 和 HTTP 1.1
- 长连接:在HTTP/1.0中,默认使用的是短连接,HTTP 1.1起,默认使用长连接,HTTP/1.1的持续连接有非流水线方式和流水线方式 。
- 错误状态响应码:HTTP1.1中新增了24个错误状态响应码
- 缓存处理:在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
- 带宽优化及网络连接的使用:HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分。
七、URI 和 URL
- URI(Uniform Resource Identifier):是统一资源标志符,可以唯一标识一个资源。
- URL(Uniform Resource Location):是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
八、HTTP 和 HTTPS
-
端口:HTTP 默认80,HTTPS 默认443
-
安全性和资源消耗:HTTP协议运行在TCP之上,所有传输的内容都是明文;HTTPS是运行在SSL/TLS之上的HTTP协议,SSL/TLS 运行在TCP之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。

