自动化打造信息影响力:用 Web Unlocker 和 n8n 打造你的自动化资讯系统_n8n webhook
一、研究背景
在信息爆炸的时代,及时获取高质量行业资讯成为内容创作者、运营者以及研究者的刚需。无论是IT、AI领域的技术动态,还是招聘、人才市场的趋势新闻,第一时间掌握热点、总结观点并进行内容输出,正逐渐成为提升影响力与构建个人/组织品牌的关键手段。
为实现“日更内容”目标,很多人开始探索自动化的路径——使用爬虫工具定期抓取目标网站内容,借助 AI 模型自动生成摘要,再将结果推送至社群平台。这一流程的核心,是稳定、高效地获取网页数据,在实际操作中,却出现了很多问题:
- 首先是出现了验证码,阻断自动化流程;
- 紧接着是请求返回403 Forbidden,提示IP被封;
- 最终是目标网站直接对我们常用IP段进行了临时封禁,哪怕切换机器或重启网络都无济于事。
按照检查方法,当处于非爬虫操作时,我们在F12控制台输入window.navigator.webdriver时,显示的是false,输入进去出现了刺眼的红色报错,而且显示也出现了True, “Failed to load resource: the server responded with a status of 400”,对这个报错就是非常典型的爬虫被反爬,检测出是selenium,报400,无法进入网站。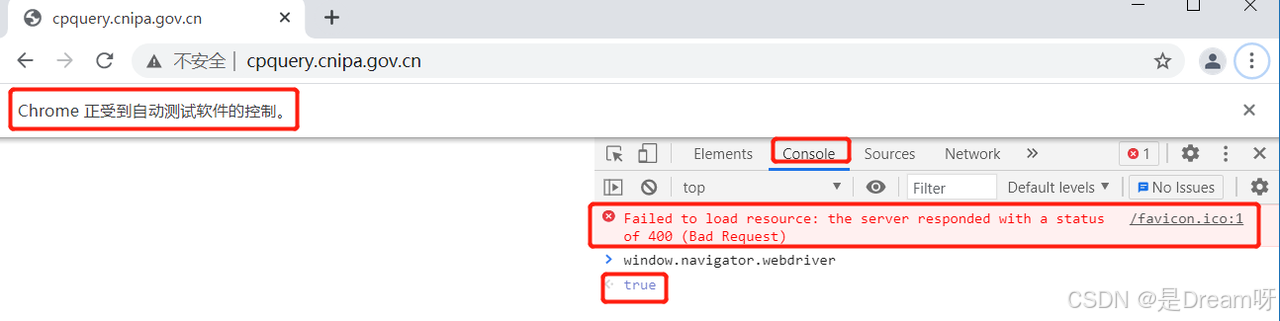
对于很多爬虫新手来说,当出现这样的情况时,常常会一头雾水,不知道是代码出错了还是服务器出了问题。实际上,这种情况多数是因为网站运行了自己的JavaScript检测代码,针对selenium等工具的特性进行了检查。一旦被识别为自动化请求,网站便会触发“防盗系统”,阻止访问请求,从而使爬虫停止工作。这些问题背后,本质上是网站为了保护内容、防止大规模抓取所布设的反爬机制。在我们看来是获取研究素材的技术手段,在网站看来却是“异常访问”。
二、反爬机制与IP黑名单的困境
起初,我们尝试采用常规手段应对:更换User-Agent、动态调整请求频率、引入Selenium渲染页面、通过Tesseract-OCR识别验证码、使用开源代理池轮换IP……可以说把互联网上关于“反反爬虫”的技巧都试了一遍。
但结果并不理想:
- 验证码识别成功率低;
- 免费代理IP可用率低,频繁失效;
- 自建IP池成本高、维护复杂;
- 有的网站反爬机制智能程度极高,行为模式识别异常即封。
这些问题严重影响数据采集的稳定性。内容抓取流程一旦中断,不仅自动摘要与推送环节失效,还会直接影响整体的内容更新节奏和对社群的维护力,进而削弱了打造专业影响力的关键窗口。
三、Web Unlocker API 功能亮点
在一次开发者讨论会上,有成员提到近期一些公司在使用亮数据(Bright Data)的服务进行网页内容采集,尤其是其中的 Web Unlocker API 被称为“反爬终结者”。抱着试一试的心态,我开始查阅它的官方文档与用户案例。相比传统代理,它不只是换了个IP那么简单,而是提供了一个集代理、反检测、验证码处理、重试机制于一体的全流程解决方案。
下面,我们从科研实际应用的角度,拆解它的几大核心亮点:
1、自动解锁复杂网页,免手动维护浏览器逻辑
许多科研网页并非简单静态HTML,而是依赖 JavaScript 渲染、前端交互加载、多级跳转甚至动态token验证机制。以往处理这种页面需使用浏览器内核(如Selenium),不仅速度慢,还极易触发封锁。
Web Unlocker API 通过自动执行JavaScript代码、处理cookie与headers关系、识别并绕过跳转,直接返回“渲染完成”的页面源码,真正实现了请求一次、获取完整内容的目标。
2、智能身份伪装 + 错误处理机制,提升数据获取成功率
许多目标网站会检测请求来源是否真实用户行为,例如是否使用自动化脚本、IP是否频繁访问、请求间隔是否异常等。一旦触发风控机制,就会出现验证码、跳转、403等问题,严重影响数据完整性。
Web Unlocker 的优势在于自动处理验证码(图形、滑动、Google reCAPTCHA)、模拟真实浏览行为(动态UA、鼠标轨迹等)、内置失败重试与自动换IP机制。开发者无需自己处理这些细节,系统会根据响应状态智能切换策略,最大限度提升成功率。
3、全球住宅/移动IP资源,支持多语言集成,科研集成便捷
Web Unlocker API 的底层服务依托亮数据的全球IP资源池,涵盖住宅、移动、数据中心IP,并支持灵活的地理位置选择(如按国家、城市、运营商筛选),非常适合做跨地区数据对比或访问受限资源。
同时,接口以 RESTful 形式提供,官方支持 Python、Node.js、Java、C# 等多种语言SDK,并提供详细文档与日志追踪系统,方便科研人员快速集成至已有数据管道或定时调度系统中。
四、Web Unlocker API 实战
下面将介绍我如何利用 Bright Data + n8n + ChatGPT API,构建一个完全自动化的新闻摘要推送系统,实现从新闻采集、摘要生成、到社群发布的全链路自动化。
1.配置网页解锁器
使用 Web Unlocker 的第一步,是在亮数据(Bright Data)官网后台完成基础配置。在功能面板中,依次点击进入“代理 & 抓取基础设施”板块,这里汇集了亮数据所有面向网页数据提取的核心服务。在众多工具中,选择“网页解锁器”(Web Unlocker),这是专为破解复杂网站反爬机制而设计的一体化解决方案。
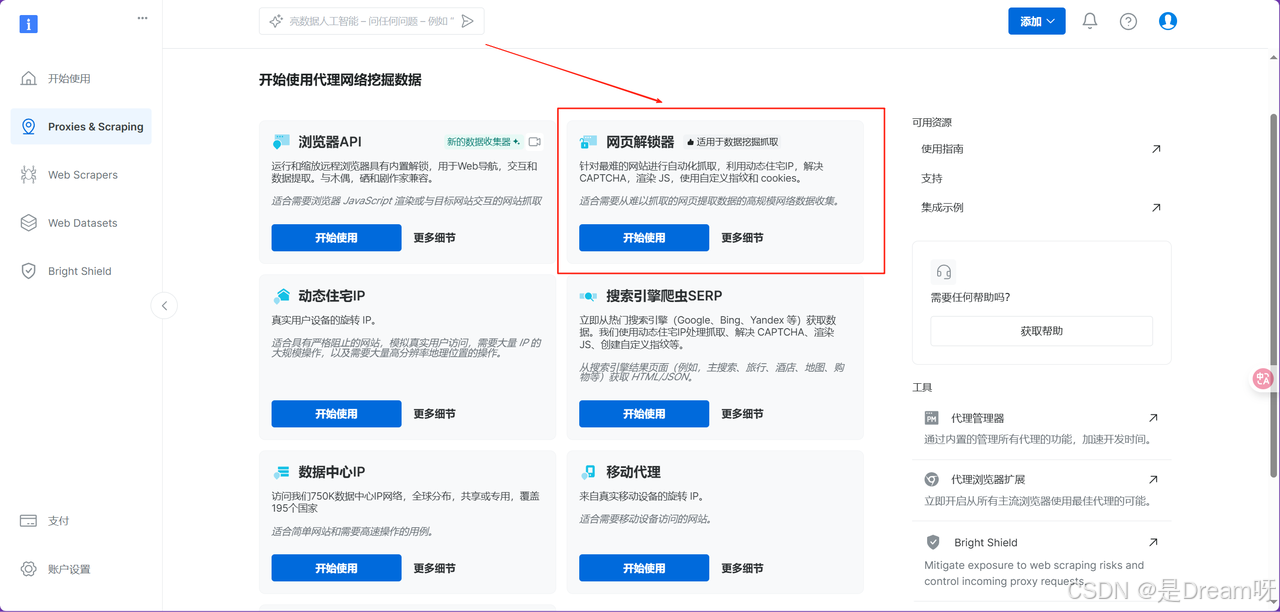
进入网页解锁器配置界面后,接下来的操作就是填写一些基础设置内容。首先,我们需要为当前的解锁通道添加一个清晰的通道描述。虽然这个字段在技术上不是必填项,但强烈建议为每个通道设定有意义的名称,这样也有利于后续任务的开发和回顾: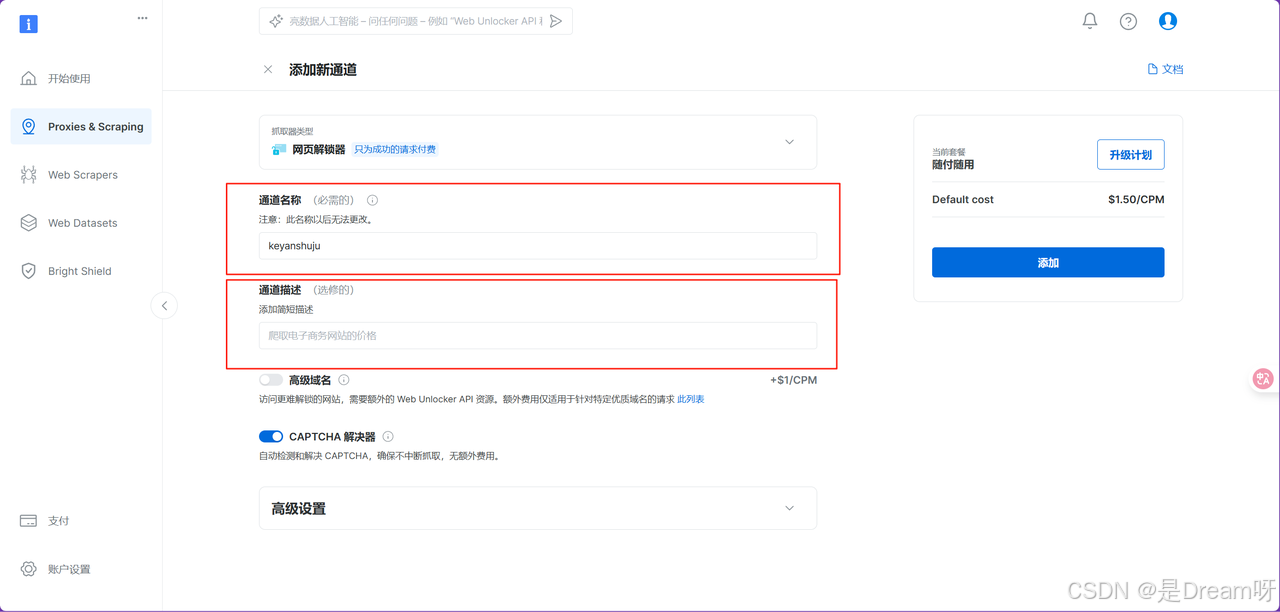
完成基础设置并保存后,系统将自动生成一个我们自己命名的通道,并跳转至该通道的详细信息页。在此页面中,可以查看与该通道相关的完整配置信息: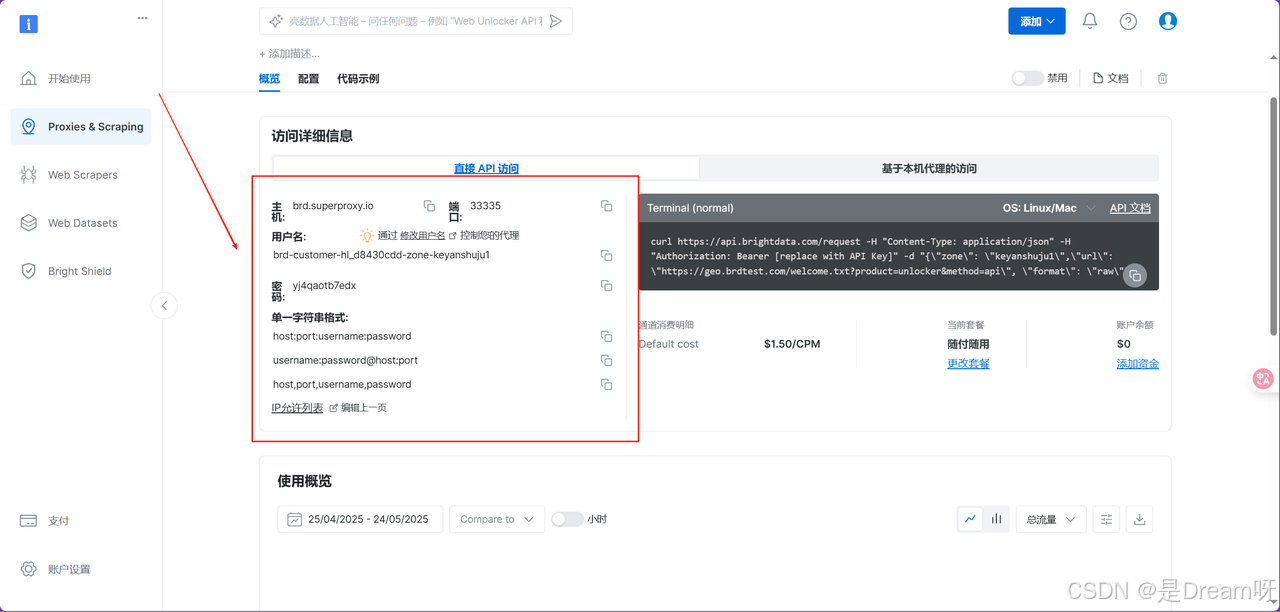
选择“配置”,选中“网页解锁器”进行使用:

2.爬取相关数据
首先导入了一些必要的 Python 模块。requests 用于发送 HTTP 请求,BeautifulSoup 负责解析返回的 HTML 内容,warnings 则用来处理可能出现的警告信息。接下来是代理配置部分。由于目标网站有一定的反爬机制,我使用了 Bright Data(亮数据)提供的代理服务来绕过限制。通过填写 customer_id、zone_name 和 zone_password 这三个参数,确认了自己的用户身份。然后根据这些信息构建了一个代理 URL,并将其分别绑定到 HTTP 和 HTTPS 协议上,存入 proxies 字典中。这样一来,在后续使用 requests 发起请求时,就可以自动通过代理服务器进行访问,提升稳定性和成功率。
# 忽略SSL警告warnings.filterwarnings(\'ignore\', message=\'Unverified HTTPS request\')# 您的Bright Data凭证(根据配置页面更新)proxy_host = \"brd.superproxy.io\"proxy_port = \"33335\"username = \"brd-customer-hl_d8430cdd-zone-keyanshuju1\"password = \"yj4qaotb7edx\"# 代理设置 - 支持多种格式proxy_url = f\"{proxy_host}:{proxy_port}\"proxy_auth = f\"{username}:{password}\"# 主要代理配置proxies = { \"http\": f\"http://{proxy_auth}@{proxy_url}\", \"https\": f\"http://{proxy_auth}@{proxy_url}\"}接下来,我通过 Bright Data(亮数据)代理服务向目标网站发送 HTTP 请求,获取新闻页面的内容。拿到 HTML 响应后,使用 BeautifulSoup 对页面进行解析,并提取新闻标题和链接信息。为了提高抓取的鲁棒性,我设计了一个多选择器尝试机制,以应对网页结构可能存在的变化或不一致性。
def parse_36kr_news(html_content, url): \"\"\"解析36氪新闻内容\"\"\" soup = BeautifulSoup(html_content, \'html.parser\') articles = [] # 多种可能的新闻项选择器 selectors = [ \'a.article-item-title\', \'.article-item-title\', \'a[class*=\"title\"]\', \'.news-item a\', \'.article-title a\', \'h3 a\', \'h2 a\', \'.item-title a\', \'a[href*=\"/p/\"]\', \'a[href*=\"36kr.com\"]\' ] print(f\"正在解析页面: {url}\") for selector in selectors: try: elements = soup.select(selector) if elements: print(f\"使用选择器 \'{selector}\' 找到 {len(elements)} 个元素\") for element in elements: title = element.get_text(strip=True) link = element.get(\"href\") if title and len(title) > 5: # 过滤掉太短的标题 # 处理相对链接 if link: if link.startswith(\"/\"): full_link = f\"https://36kr.com{link}\" elif not link.startswith(\"http\"): full_link = f\"https://36kr.com/{link}\" else: full_link = link else: full_link = \"链接不可用\" articles.append({ \'title\': title, \'link\': full_link, \'source\': url }) if articles: break except Exception as e: print(f\"选择器 \'{selector}\' 解析失败: {e}\")得到爬取到的结果如下:

3.流程自动化平台n8n
n8n(“node, no-code”) 是一款开源、可扩展的流程自动化工具,功能类似 Zapier,但更灵活、更适合开发者使用。在本项目中,n8n 承担“调度器”和“执行器”的角色,负责从新闻网站抓取数据、调用摘要生成、格式化输出并推送至群聊。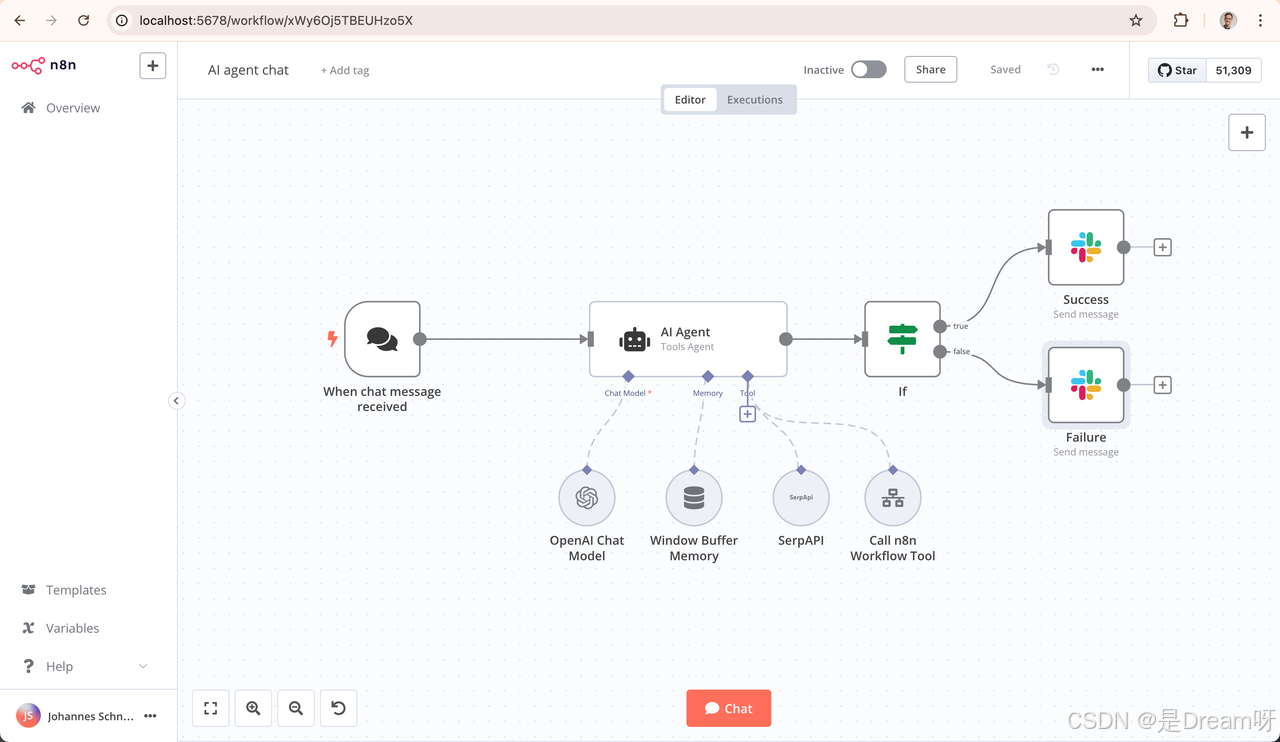
首先,我们使用 n8n 的定时器(Cron 节点)设定每日定时执行任务,如早 9 点和晚 6 点自动启动流程。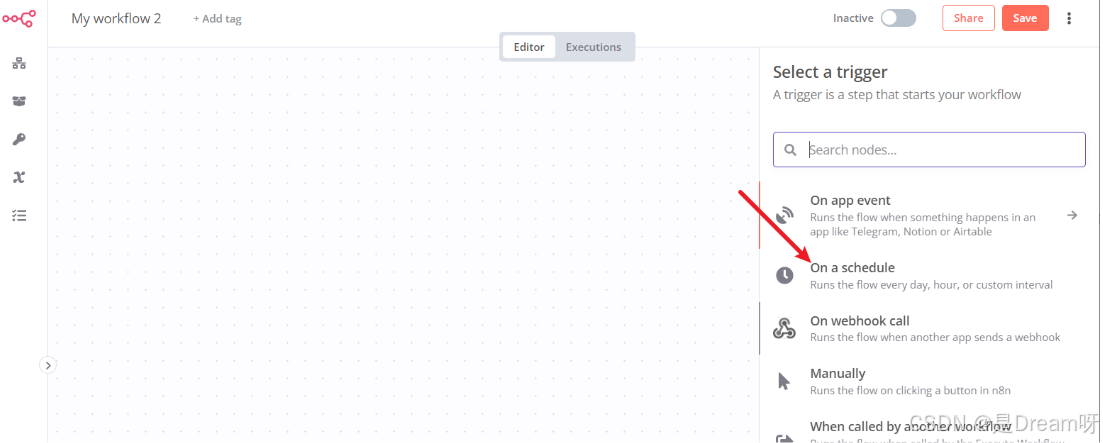 然后自动访问目标新闻网站(如 36氪、虎嗅)首页,获取 HTML 内容:
然后自动访问目标新闻网站(如 36氪、虎嗅)首页,获取 HTML 内容: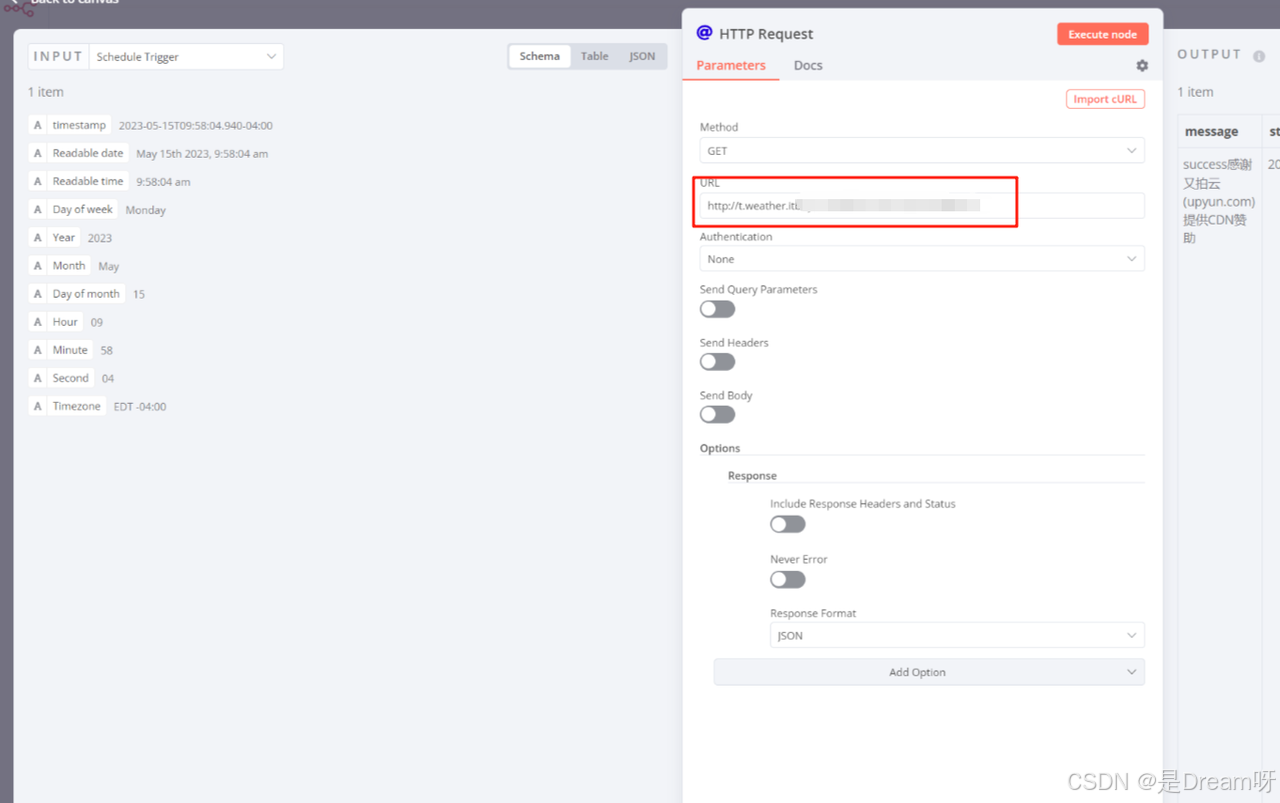
利用节点提取每篇文章的标题与链接,结构化输出为 JSON 数据格式:
然后调用 GPT-4 API,为每条新闻生成 50-100 字的摘要内容。
4.AI 摘要生成模块(基于 ChatGPT API)
在本系统中,我们使用 OpenAI 的 ChatGPT(GPT-4)API 对抓取到的新闻内容进行摘要生成。相比传统关键词提取工具,GPT-4 能更准确理解文章意图,生成具备“新闻编辑感”的摘要内容。
接口地址:https://api.openai.com/v1/chat/completions
为了确保摘要高质量,系统内置了“提示词模板”:
{ \"role\": \"system\", \"content\": \"你是一名资深 IT 行业媒体编辑,请对以下新闻生成简洁明了的摘要,要求语言客观、中立、不重复标题,字数控制在150字以内。\"}每条新闻由 title 和 url 组成,通过用户 prompt 传入:{ \"role\": \"user\", \"content\": \"标题:小鹏“瘦身”,蔚来学得会吗? 链接:https://36kr.com/p/3305015892810496\"}得到的结果如下:
{ \"choices\": [ { \"message\": { \"role\": \"assistant\", \"content\": \"依靠爆款策略、成本控制和管理重构,小鹏蹚出一条路,朝着盈利更进一步,但还不能“半场开香槟”。同样亟需扭亏的蔚来,试图复制小鹏“逆袭”,战略大方向没有错,但在具体战术上仍有众多待解难题。\" } } ]}5.自动发送新闻摘要到微信群聊
因为n8n并不直接支持推送数据到微信上,但是企业微信支持自定义机器人,通过Webhook地址即可实现自动发送消息到指定群聊,安全且易用。
同时我们可以使用一些第三方的微信API接口来实现这个数据的推送比如将数据推送到某一个公众号的服务器上面,由其再发到自己微信客户端的聊天窗口上。这里依然使用HTTP Request节点来执行这个动作,具体是通过向WxPusher发送GET请求,之后再发送给用户的聊天窗口。
WxPusher (微信推送服务) 是一个使用微信公众号作为通道的,实时信息推送平台,可以通过调用API的方式,把信息推送到微信上,无需安装额外的软件,即可做到信息实时通知。在摘要生成后,新增 HTTP Request 节点,调用URL,发送摘要文本,同时消息内容格式支持 Markdown,可以展示标题+摘要+链接,方便阅读。
我们已经在前面节点中用OpenAI或其它方式生成了摘要文本,存储在{{json[\"summary\"]}},新闻标题在{{json[\"title\"]}},新闻链接在{{json[\"url\"]}}。在 n8n 里配置HTTP Request节点,Method选POST,Headers 设置 Content-Type: application/json。Body(Raw JSON):
{ \"msgtype\": \"markdown\", \"markdown\": { \"content\": \"【{{$json[\\\"title\\\"]}}】\\n> {{$json[\\\"summary\\\"]}}\\n\\n[阅读全文]({{$json[\"url\"]}})\" }}按照上上面的配置,就会显示创建发送任务成功,手机端就可以接收到每天自动的新闻推送了:
同时我们也可以使用Python进行消息推送,代码参考如下:
def wxPusher_send_messaget_post(message): import requests import json app_token = \'xxx\' UID = \'xxx\' data = { \"appToken\": app_token, \"content\": message, \"summary\": message, \"contentType\": 1, \"topicIds\": [ 123 ], \"uids\": [ UID ], \"url\": \"https://wxpusher.zjiecode.com\", \"verifyPay\": False } json_data = json.dumps(data) url= \"https://wxpusher.zjiecode.com/api/send/message\" headers = { \'Content-Type\': \"application/json\", } request = requests.post(url,data=json_data,headers=headers) print(\"request:\", request) return requestwxPusher_send_messaget_post(\'好的\')通过这一闭环自动化设计,我们不仅解决了反爬痛点,还极大提升了信息处理与分发的效率。借助 n8n 自动化流程编排与 ChatGPT 文本生成模型,我们进一步将整个内容流程自动化成一个可复用、低门槛的工作流,极大节省了人工整理与发布成本。
五、总结
本文围绕从反爬机制的实战分析出发,我们引入了 Bright Data 提供的 Web Unlocker API,它以一种“即插即用”的方式,极大地简化了复杂网页的采集过程,真正做到了你只管提 URL,其他我来搞定!
最关键的是,这一切只需要注册 Bright Data 并启用 Web Unlocker 的试用额度即可开启。Bright Data 提供的新用户试用配额足以支撑你搭建一个日更级别的资讯采集系统,零门槛、免运维、快速见效,如果你也想提升专业影响力,实现内容日更自动化,快来试试吧!
点击注册免费试用 https://get.brightdata.com/wbunlocker


