首次贡献Flink源码,竟贡献了3600+行?记录首次PR经历!_多易 flink 源码
接触Flink快两年了,一年前开始局部地阅读源码,为的是解决工作上遇到的问题,虽然最后基本上都没有什么收获。但是阅读源码的习惯还是保持了下来,半年前的一天,在看FlinkSql相关源码时看到了这样个todo:
先介绍一下背景:
大部分依赖calcite解析sql的计算引擎如hive、spark解析sql的过程:
sql->sqlnode(AST)->relnode->logic planner->physic planner->task
而flink在此之间多封装了一层,会将sqlnode,转换成operation之后再生成relnode,目的是统一SQL api和table api.
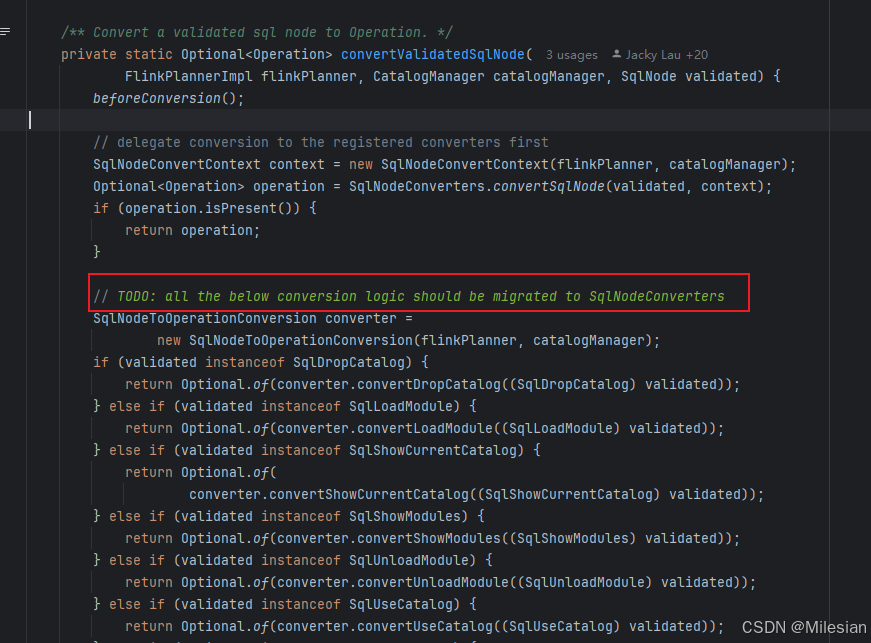
这一个类SqlNodeToOperationConversion的功能就是将解析好的sqlnode进行validate,之后根据sqlnode的类型(比如create table、drop database)转换为对应的operation.
转换逻辑的代码一开始是这样设计的:if else 判断sqlnode类型,然后根据不同的类型调不同的转换方法,方法就直接放在了上述类中。
后来flink的开发者们认为这种硬编码的方式有缺陷,于是打算重构这部分逻辑,设计了一个新的类叫SqlNodeConverters:
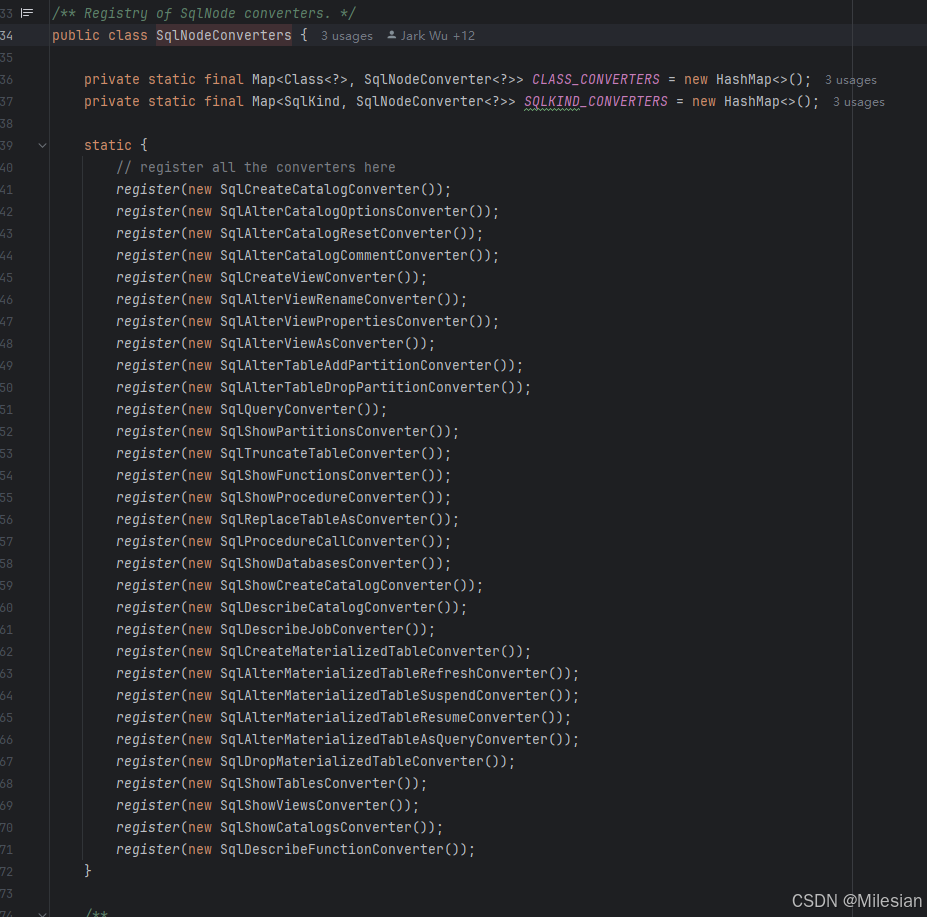
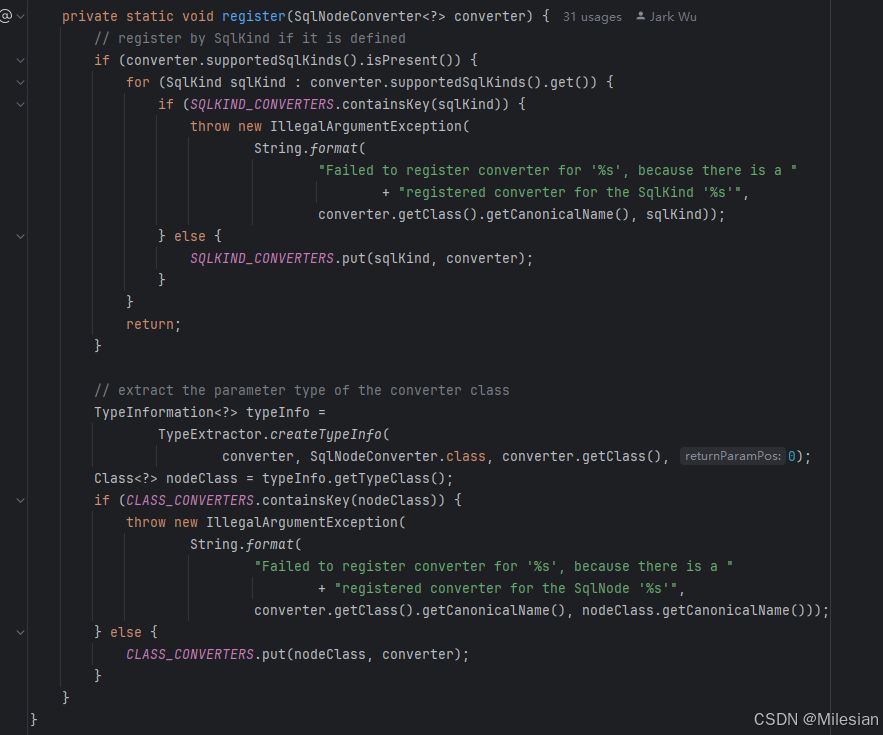
简单来说就是维护两张表来记录注册过的class和sqlkind,每种转化逻辑都写一个新的类,在这里注册class和sqlkind,注册的同时调用转换逻辑。
以下是deepseek的分析:
迁移这部分转换逻辑到
SqlNodeConverters的主要目的是为了提升代码的可维护性、扩展性和架构清晰度。以下是具体原因:
1. 模块化与代码组织
问题:原有的
SqlNodeToOperationConversion类承担了所有SQL节点到Operation的转换逻辑,导致类臃肿、职责不清晰。改进:通过迁移到
SqlNodeConverters,将不同SQL节点的转换逻辑拆分到独立的转换器中,每个转换器专注于特定类型的SQL节点(如CREATE TABLE、ALTER TABLE),符合单一职责原则。
2. 统一接口与扩展性
问题:旧代码使用
if-else分支处理不同类型的SQL节点,新增支持需要修改核心类,违反开闭原则。改进:
SqlNodeConverters提供插件化机制,允许通过注册新转换器轻松支持新SQL语法,无需修改核心代码,显著提升扩展性。
3. 技术债务清理
问题:代码中的
TODO注释明确表明原有实现是临时方案,技术债务需偿还。改进:迁移到
SqlNodeConverters是代码优化的既定步骤,旨在减少技术债务,避免未来维护成本增加。
4. 解耦上下文依赖
问题:原有逻辑直接依赖
FlinkPlanner和CatalogManager,耦合度高。改进:
SqlNodeConverters通过SqlNodeConvertContext封装上下文(如 Planner 和 Catalog),解耦转换逻辑与外部依赖,提升可测试性和复用性。
5. 支持动态SQL处理
问题:硬编码的
if-else分支难以适应动态SQL扩展(如自定义DDL)。改进:
SqlNodeConverters的注册机制支持动态加载转换器,为Flink未来支持更多SQL标准或自定义语法奠定基础。
6. 代码可读性与维护性
问题:集中式处理导致代码冗长,新增逻辑需在庞大类中定位。
改进:每个
Converter独立实现,代码结构更清晰,开发者能快速定位特定语法处理逻辑,降低维护难度。
迁移的实际影响
风险控制:迁移过程中需确保兼容性,通过单元测试和集成测试覆盖原有场景,防止功能回归。
性能考量:转换器链可能引入轻微性能开销,但通过合理设计(如懒加载、缓存)可忽略不计。
渐进式迁移:代码中保留旧逻辑作为回退(
TODO部分尚未完成),确保平滑过渡。
总结
迁移转换逻辑到
SqlNodeConverters是Flink优化SQL处理框架的关键步骤,旨在构建更模块化、可扩展且易于维护的架构,为后续支持复杂SQL语法和用户自定义扩展提供坚实基础。
半年前初看到这个todo,当时就有点跃跃欲试,不过一个是还没有捋顺这部分转换逻辑,另一个是没有大块的时间来做这个事情,总之就搁置了。年后上班这段时间比较闲,先是提交了一个文档的bug修复(之前的文章提到的python ES7 连接器的demo写错了),差不多已经可以混到contributor的头衔了,但是感觉没啥含金量,于是想到了把这个todo给他干了。
迁移细节没兴趣可以跳过:
迁移的工作的其实并不难,可以说大部分的converter都是白给,直接新建个类,实现一个SqlNodeConverter接口,重写个convertSqlNode方法,方法直接从原类下面复制过来就完事了,最后在SqlNodeConverters里注册一下新的converter.
但是也有部分复杂的,比如CreateTableConverter,在原类里本身就是特殊处理的:
原本就有一个SqlCreateTableConverter类,里面实现了普通的create table、create table as 、create table like等转换逻辑。
SqlNodeToOperationConversion 类中专门为create table维护了一个成员变量,构造方法里new出来一个sqlCreateTableConverter来调用转换方法。但是按照新的设计思路,注册converter是一段静态代码块,显然不可能在注册的时候传参,我所写的新的SqlCreateTableConverter类只能接收SqlNodeToOperationConversion 中传过来的上下文context,原本的上下文只有flink planner 和catalog mannager,所以还得改造上下文的设计。
另外一点,我只注册了CreateTable,但是CreateTableAs类型的sqlnode虽然是CreateTable的子类,但是在表中是查不到的,我的设计和原有设计一致,create table as是在SqlCreateTableConverter中实现,而不是新注册一个SqlCreateTableAsConverter,所以从注册表中查class类型如果查不到,还得循环遍历sqlnode所有的父类(后来的alter table底下甚至有三四层继承结构)。
最后一共新建42个converter类,删除1个原有的类,修改7个类,耗时一个星期,终于提了PR.
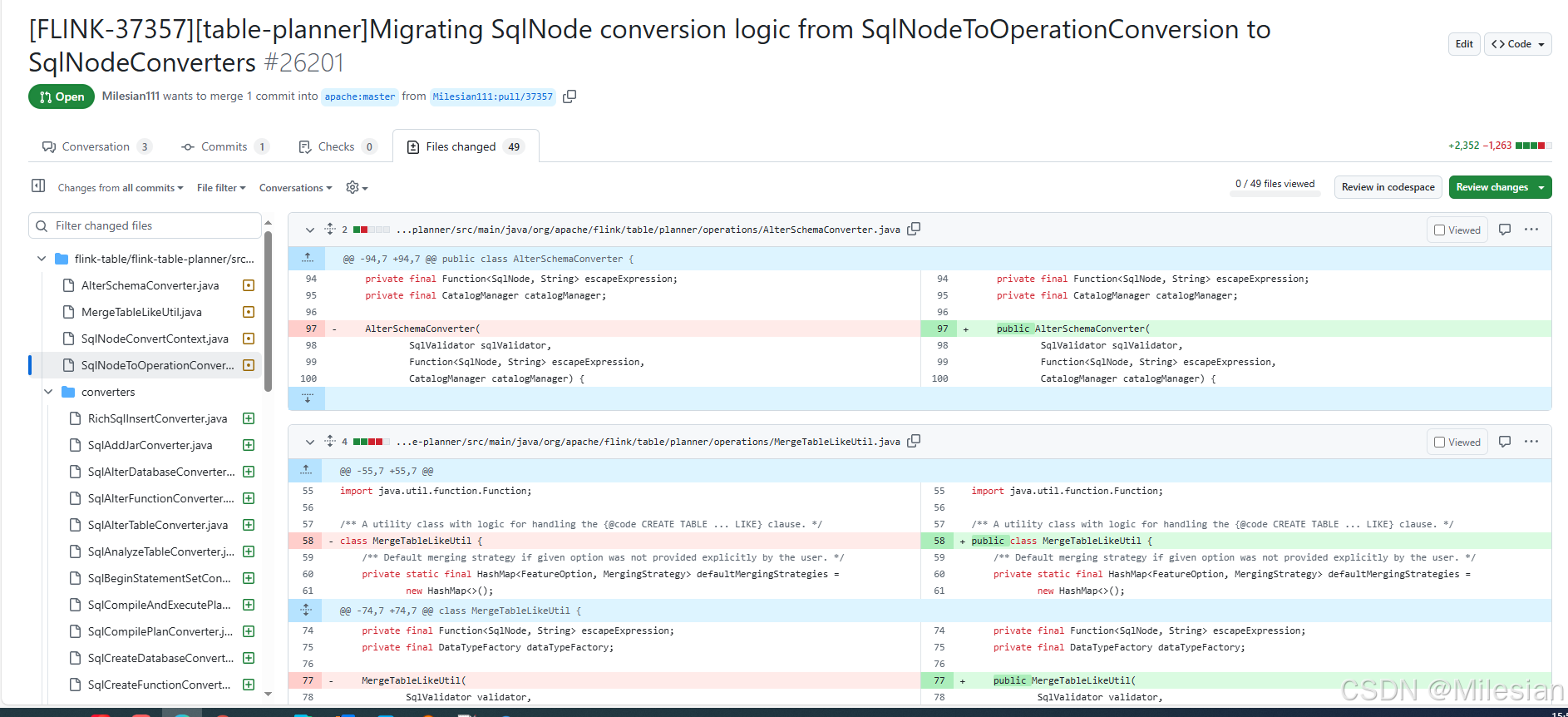
贡献行数达到了3600行,还是有点小小的成就感,坐等review咯。
提交贡献的流程在这篇文章里写的比较详细了:
码住!Flink Contributor 速成指南-CSDN博客
有趣的是,我修改的这段代码的原作者伍翀(云邪)正好是这篇攻略的作者。
另外在这推荐一下多易涛哥的flink源码视频课程,一年来遇到读源码很吃力的部分,我都会看看涛哥有没有精讲这段,对我帮助非常大,有兴趣可以先去B站看看涛哥的flink二次开发试听课,绝对牛逼,当时光看两节试听课我就感觉醍醐灌顶。
下一阶段可能尝试写点新的feature了,比如neo4j的connector,java和python实现。
给自己加油!也祝大家早日成为Contributor哈哈。

