【视频生成模型】通义万相Wan2.1模型本地部署和LoRA微调
目录
- 1 简介
- 2 本地部署
-
- 2.1 配置环境
- 2.2 下载模型
- 3 文生视频
-
- 3.1 运行命令
- 3.2 生成结果
- 4 图生视频
-
- 4.1 运行命令
- 4.2 生成结果
- 5 首尾帧生成视频
-
- 5.1 运行命令
- 5.2 生成结果
- 6 提示词扩展
- 7 LoRA微调
1 简介
通义万相 2.1 在 2025 年 1 月推出,2 月 25 日阿里巴巴宣布全面开源该模型。此次开源意义重大,让全球开发者都能参与到模型的应用与优化中。它提供了 14B 专业版和 1.3B 轻量版两种规格,满足不同场景需求。在权威评测 VBench 中,14B 版本以 86.22% 总分超越 Sora、Luma 等国内外模型,在运动质量、视觉质量等 14 个主要维度评测中斩获 5 项第一。1.3B 轻量版则主打高效率,在 RTX 4090 显卡上仅需 8.2GB 显存即可生成 480P 视频,4 分钟内完成 5 秒视频生成,兼容主流消费级 GPU。
本文来实测一下。
2 本地部署
2.1 配置环境
将Wan2.1工程克隆到本地:
git clone https://github.com/Wan-Video/Wan2.1.gitcd Wan2.1安装依赖库:
# Ensure torch >= 2.4.0pip install -r requirements.txt如果安装flash_attn较慢,可以直接下载flash-attn安装包,离线安装,下载地址:https://github.com/Dao-AILab/flash-attention/releases
2.2 下载模型
到modelscope上下载模型:
pip install modelscopemodelscope download Wan-AI/Wan2.1-T2V-14B --local_dir ./Wan2.1-T2V-14B3 文生视频
3.1 运行命令
Single-GPU:
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt \"Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage.\"如果显存较小,遇到OOM(内存不足)问题,可以使用–offload_model True和–t5_cpu选项来减少GPU内存使用。例如,在RTX 4090 GPU上:
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt \"Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage.\"Multi-GPU:
pip install \"xfuser>=0.4.1\"torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt \"Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage.\"3.2 生成结果
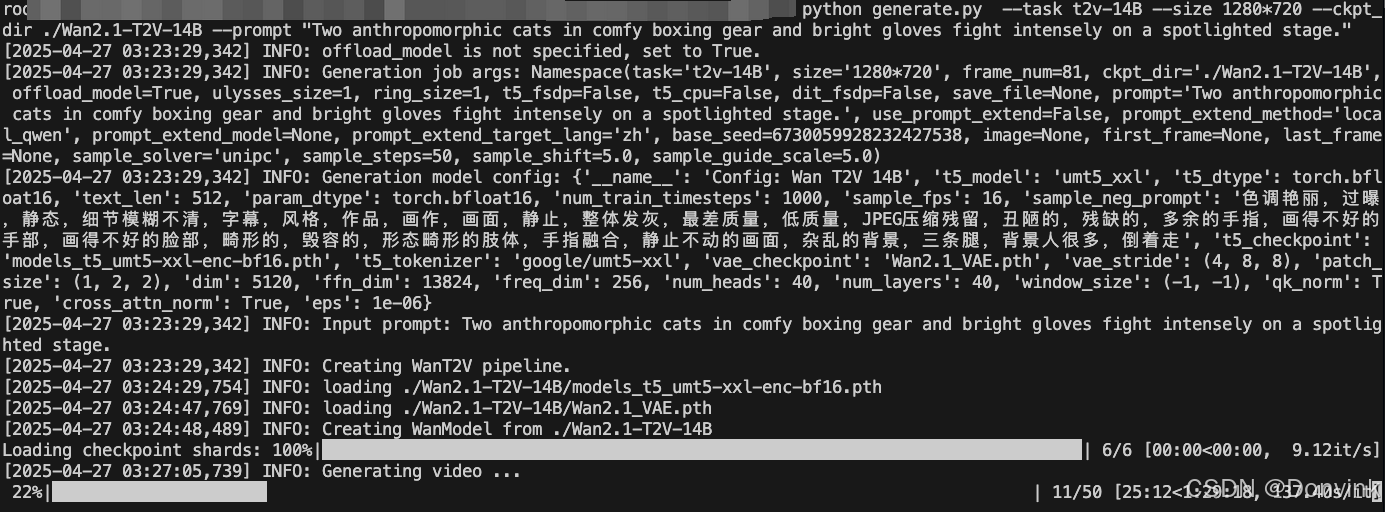
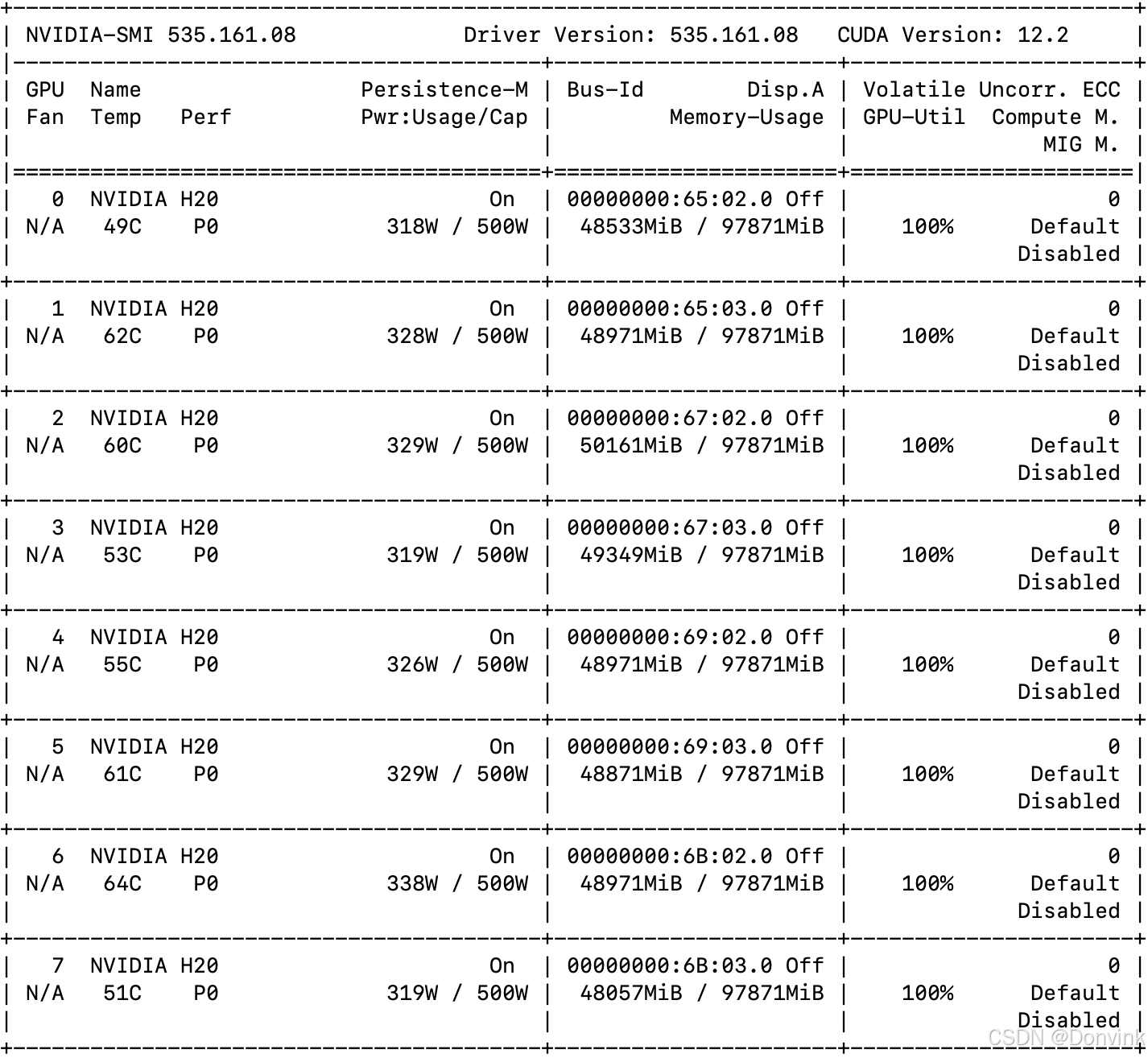
使用Wan2.1-T2V-14B模型,迭代50步:
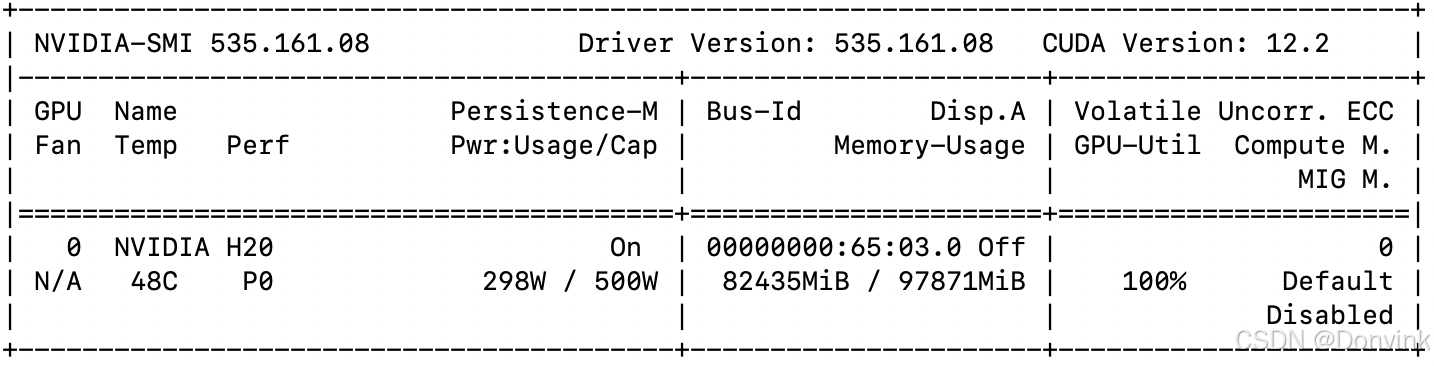
单卡耗时约2小时,显存占用80多GB。
(和官方说的5秒视频需要10分钟不太相符,是什么原因?)
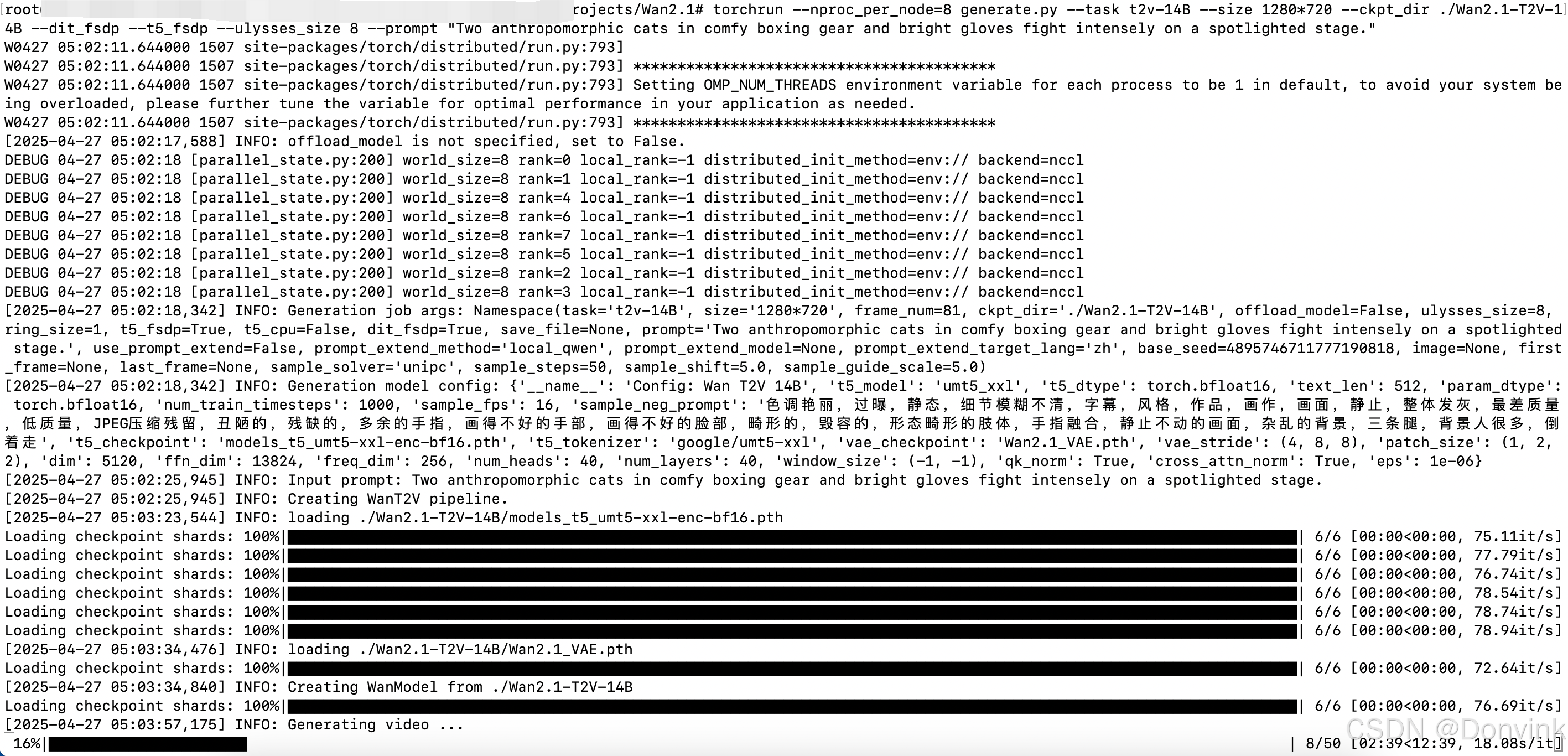
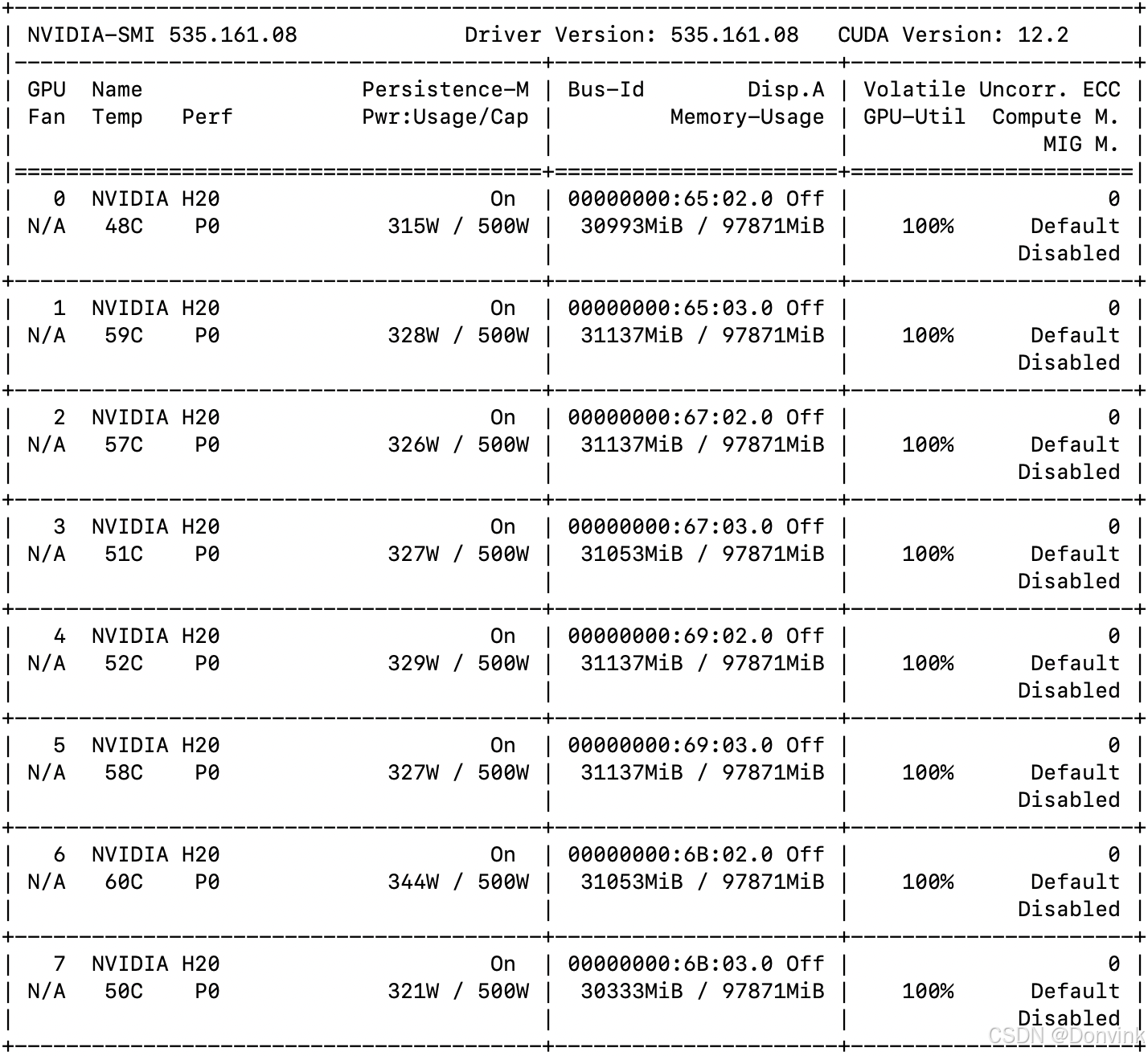
8卡耗时约15分钟,每张卡占用显存30多GB。
生成结果:
bilibili

4 图生视频
4.1 运行命令
Single-GPU:
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --prompt \"Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline\'s intricate details and the refreshing atmosphere of the seaside.\"Multi-GPU:
torchrun --nproc_per_node=8 generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt \"Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline\'s intricate details and the refreshing atmosphere of the seaside.\"4.2 生成结果
8卡耗时12分钟左右,每张卡显存占用约48GB。
输入图片:

生成结果:bilibili
5 首尾帧生成视频
5.1 运行命令
Single-GPU:
python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --prompt \"CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective.\"Multi-GPU:
torchrun --nproc_per_node=8 generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt \"CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective.\"5.2 生成结果
8卡耗时30分钟左右,每张卡显存占用约48GB。
输入首帧:

输入尾帧:

生成结果:bilibili
6 提示词扩展
此外,我们还可以使用本地模型进行提示词扩展(Prompt Extension)。
对于文本到视频的任务,您可以使用Qwen/Qwen2.5-14B-Instruct、Qwen/Qwen2.5-7B-Instruct 和Qwen/Qwen2.5-3B-Instruct等模型。
对于图像到视频或最后一帧到视频的任务,您可以使用Qwen/Qwen2.5-VL-7B-Instruct和Qwen/Qwen2.5-VL-3B-Instruct等模型。
较大的模型通常提供更好的扩展结果,但需要更多的GPU内存。
可以使用参数–prompt_extension_model修改用于扩展的模型,例如:
- 文生视频:
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt \"Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage\" --use_prompt_extend --prompt_extend_method \'local_qwen\' --prompt_extend_target_lang \'zh\'- 图生视频:
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct --prompt \"Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline\'s intricate details and the refreshing atmosphere of the seaside.\"- 首尾帧生成视频:
python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --use_prompt_extend --prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct --prompt \"CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective.\"7 LoRA微调
请参考:LoRA微调Wan2.1教程
git clone https://github.com/modelscope/DiffSynth-Studio.gitcd DiffSynth-Studiopip install -e .Step 1: Install additional packages
pip install peft lightning pandasStep 2: Prepare your dataset
You need to manage the training videos as follows:
data/example_dataset/├── metadata.csv└── train ├── video_00001.mp4 └── image_00002.jpgmetadata.csv:
file_name,textvideo_00001.mp4,\"video description\"image_00002.jpg,\"video description\"We support both images and videos. An image is treated as a single frame of video.
Step 3: Data process
CUDA_VISIBLE_DEVICES=\"0\" python examples/wanvideo/train_wan_t2v.py \\ --task data_process \\ --dataset_path data/example_dataset \\ --output_path ./models \\ --text_encoder_path \"models/Wan-AI/Wan2.1-T2V-1.3B/models_t5_umt5-xxl-enc-bf16.pth\" \\ --vae_path \"models/Wan-AI/Wan2.1-T2V-1.3B/Wan2.1_VAE.pth\" \\ --tiled \\ --num_frames 81 \\ --height 480 \\ --width 832After that, some cached files will be stored in the dataset folder.
data/example_dataset/├── metadata.csv└── train ├── video_00001.mp4 ├── video_00001.mp4.tensors.pth ├── video_00002.mp4 └── video_00002.mp4.tensors.pthStep 4: Train
LoRA training:
CUDA_VISIBLE_DEVICES=\"0\" python examples/wanvideo/train_wan_t2v.py \\ --task train \\ --train_architecture lora \\ --dataset_path data/example_dataset \\ --output_path ./models \\ --dit_path \"models/Wan-AI/Wan2.1-T2V-1.3B/diffusion_pytorch_model.safetensors\" \\ --steps_per_epoch 500 \\ --max_epochs 10 \\ --learning_rate 1e-4 \\ --lora_rank 16 \\ --lora_alpha 16 \\ --lora_target_modules \"q,k,v,o,ffn.0,ffn.2\" \\ --accumulate_grad_batches 1 \\ --use_gradient_checkpointingFull training:
CUDA_VISIBLE_DEVICES=\"0\" python examples/wanvideo/train_wan_t2v.py \\ --task train \\ --train_architecture full \\ --dataset_path data/example_dataset \\ --output_path ./models \\ --dit_path \"models/Wan-AI/Wan2.1-T2V-1.3B/diffusion_pytorch_model.safetensors\" \\ --steps_per_epoch 500 \\ --max_epochs 10 \\ --learning_rate 1e-4 \\ --accumulate_grad_batches 1 \\ --use_gradient_checkpointingIf you wish to train the 14B model, please separate the safetensor files with a comma. For example: models/Wan-AI/Wan2.1-T2V-14B/diffusion_pytorch_model-00001-of-00006.safetensors,models/Wan-AI/Wan2.1-T2V-14B/diffusion_pytorch_model-00002-of-00006.safetensors,models/Wan-AI/Wan2.1-T2V-14B/diffusion_pytorch_model-00003-of-00006.safetensors,models/Wan-AI/Wan2.1-T2V-14B/diffusion_pytorch_model-00004-of-00006.safetensors,models/Wan-AI/Wan2.1-T2V-14B/diffusion_pytorch_model-00005-of-00006.safetensors,models/Wan-AI/Wan2.1-T2V-14B/diffusion_pytorch_model-00006-of-00006.safetensors.
If you wish to train the image-to-video model, please add an extra parameter --image_encoder_path \"models/Wan-AI/Wan2.1-I2V-14B-480P/models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth\".
For LoRA training, the Wan-1.3B-T2V model requires 16G of VRAM for processing 81 frames at 480P, while the Wan-14B-T2V model requires 60G of VRAM for the same configuration. To further reduce VRAM requirements by 20%-30%, you can include the parameter --use_gradient_checkpointing_offload.
Step 5: Test
Test LoRA:
import torchfrom diffsynth import ModelManager, WanVideoPipeline, save_video, VideoDatamodel_manager = ModelManager(torch_dtype=torch.bfloat16, device=\"cpu\")model_manager.load_models([ \"models/Wan-AI/Wan2.1-T2V-1.3B/diffusion_pytorch_model.safetensors\", \"models/Wan-AI/Wan2.1-T2V-1.3B/models_t5_umt5-xxl-enc-bf16.pth\", \"models/Wan-AI/Wan2.1-T2V-1.3B/Wan2.1_VAE.pth\",])model_manager.load_lora(\"models/lightning_logs/version_1/checkpoints/epoch=0-step=500.ckpt\", lora_alpha=1.0)pipe = WanVideoPipeline.from_model_manager(model_manager, device=\"cuda\")pipe.enable_vram_management(num_persistent_param_in_dit=None)video = pipe( prompt=\"...\", negative_prompt=\"...\", num_inference_steps=50, seed=0, tiled=True)save_video(video, \"video.mp4\", fps=30, quality=5)Test fine-tuned base model:
import torchfrom diffsynth import ModelManager, WanVideoPipeline, save_video, VideoDatamodel_manager = ModelManager(torch_dtype=torch.bfloat16, device=\"cpu\")model_manager.load_models([ \"models/lightning_logs/version_1/checkpoints/epoch=0-step=500.ckpt\", \"models/Wan-AI/Wan2.1-T2V-1.3B/models_t5_umt5-xxl-enc-bf16.pth\", \"models/Wan-AI/Wan2.1-T2V-1.3B/Wan2.1_VAE.pth\",])pipe = WanVideoPipeline.from_model_manager(model_manager, device=\"cuda\")pipe.enable_vram_management(num_persistent_param_in_dit=None)video = pipe( prompt=\"...\", negative_prompt=\"...\", num_inference_steps=50, seed=0, tiled=True)save_video(video, \"video.mp4\", fps=30, quality=5)
