【论文复现】在线健康社区重大慢病患者负面评论倾向的关键影响因素分析

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.项目介绍
2.1文献来源
2.2数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3情感分析
4.4BERTopic主题建模
4.5结果可视化
源代码

1.项目背景
近年来由于我国互联网医疗规范化水平持续提升,互联网医疗领域相关监管政策框架日益完善,据中国互联网络信 息中心(CNNIC)在京发布第 51 次《中国互联网络发展状况 统计报告》显示,互联网医疗成为2022年用户规模增长最快 的应用。截至 2022 年 12 月,我国互联网医疗用户规模达 3.63 亿 ,较 2021 年 12 月 增 长 6466 万 ,占 网 民 整 体 的 34.0% 。我国在线健康社区众多,平台与平台之间、医生与 医生之间的服务质量差距较大,用户对医生和平台的服务评价褒贬不一,患者与医生、平台间的矛盾日益凸显。在医疗行业中,正面临着成本上升和患者需求增加这两个重要挑战。其中,提高医疗质量和控制费用是该行业主要面临的难题 。换句话说,患者对医疗质量的要求不断提高,对医疗效果也有着更高的期望 。重大慢病特指国家指明的心脑血管疾病、癌症、慢性呼吸系统疾病、糖尿病四类。重大慢病患者由于病程时间长、治愈率低且有研究表明,随着慢病病程延长,患者的抑郁概率呈现上升趋势 ,所以当重大慢病患者对医疗服务质量不满意时,气愤、沮丧等消极情绪会进一步使病情恶化,最终以负面评论的形式展现出来,因而提升医疗服务质量对于重大慢病患者的身心健康具有重要意义。
2.项目介绍
2.1文献来源
[1]王辉,王晓玉,李卫东,等.在线健康社区重大慢病患者负面评论倾向的关键影响因素分析[J].情报科学,2024,42(06):12-20+28.
本次论文技术复现只是做了部分复现,如爬虫、情感分析和BERTopic模型分析。复现的内容并不完整。如需源码或数据集请关注公主号【派森小木屋】
2.2数据集介绍
本实验数据集来源于好大夫在线医疗平台,使用Python爬虫采集高血压、糖尿病和冠心病的问诊数据,包括患者性别、年龄、问诊内容、交流次数、医生、科室等,共计爬取17w+条数据,其中高血压67728条,糖尿病54917条,冠心病50523条。


部分爬虫代码如下:(完整版请关注文末公主号后进q群领取)
import requestsfrom lxml import etreeimport csvimport timeimport randomdef main(page): cookies = { \'acw_tc\': \'ddcc42ac17264803542016009e2feafef31e19332b0823318854f787b4\', \'g\': \'46152_1726480354852\', \'Hm_lvt_dfa5478034171cc641b1639b2a5b717d\': \'1726480356\', \'HMACCOUNT\': \'CE22B48046061130\', \'g\': \'HDF.84.66e60d45f038e\', \'Hm_lpvt_dfa5478034171cc641b1639b2a5b717d\': \'1726480587\', } headers = { \'accept\': \'*/*\', \'accept-language\': \'zh-CN,zh;q=0.9,en;q=0.8\', \'cache-control\': \'no-cache\', \'content-type\': \'application/x-www-form-urlencoded; charset=UTF-8\', # \'cookie\': \'acw_tc=ddcc42ac17264803542016009e2feafef31e19332b0823318854f787b4; g=46152_1726480354852; Hm_lvt_dfa5478034171cc641b1639b2a5b717d=1726480356; HMACCOUNT=CE22B48046061130; g=HDF.84.66e60d45f038e; Hm_lpvt_dfa5478034171cc641b1639b2a5b717d=1726480587\', \'origin\': \'https://www.haodf.com\', \'pragma\': \'no-cache\', \'priority\': \'u=1, i\', \'referer\': \'https://www.haodf.com/citiao/jibing-zibizheng/bingcheng.html?p=4\', \'sec-ch-ua\': \'\"Chromium\";v=\"128\", \"Not;A=Brand\";v=\"24\", \"Google Chrome\";v=\"128\"\', \'sec-ch-ua-mobile\': \'?0\', \'sec-ch-ua-platform\': \'\"Windows\"\', \'sec-fetch-dest\': \'empty\', \'sec-fetch-mode\': \'cors\', \'sec-fetch-site\': \'same-origin\', \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36\', \'x-requested-with\': \'XMLHttpRequest\', } data = { \'nowPage\': page, \'pageSize\': pageSize, \'diseaseId\': diseaseId, } response = requests.post(\'https://www.haodf.com/ndisease/ajaxLoadMoreWenzhen\', cookies=cookies, headers=headers, data=data) html_text = response.json()[\'data\'][\'list\'] html_text = f\'{html_text}
\' tree = etree.HTML(html_text) li_list = tree.xpath(\'//ul/li\') if li_list: for li in li_list: try: info1 = li.xpath(\'./a/div/span[1]/text()\')[0] sex = info1.split(\' \')[0].split(\':\')[1] age = info1.split(\' \')[1] time_ = li.xpath(\'./a/div/span[3]/text()\')[0].split(\'时间\')[-1] if len(time_) == 5: time_ = \'2025.\'+time_ text = li.xpath(\'./a/h3/text()\')[0].replace(\'\\n\',\'\') talk_num = li.xpath(\'./div/div[1]/span[1]/span[1]/text()\')[0] doctor = li.xpath(\'./div/div[2]/a[1]/text()\')[0] hospital = li.xpath(\'./div/div[2]/a[2]/text()\')[0] department = li.xpath(\'./div/div[2]/a[3]/text()\')[0] print(sex,age,time_,text,talk_num,doctor,hospital,department) csvwriter.writerow((sex,age,time_,text,talk_num,doctor,hospital,department)) f.flush() except: pass else: raise3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
导入第三方库并加载三个数据集
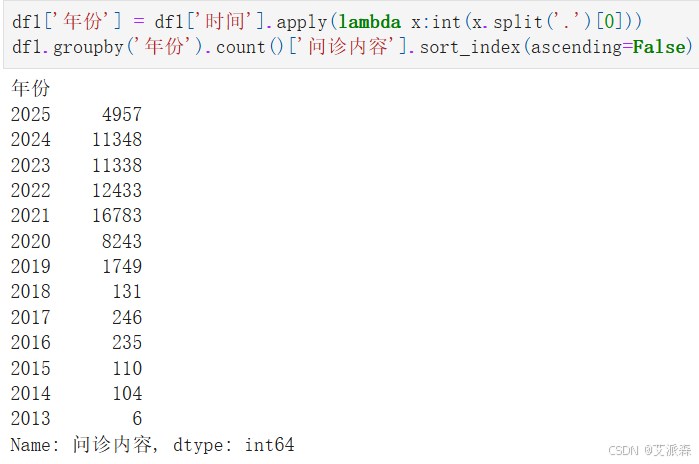
查看第一个高血压数据集按年份分布的问诊内容数量
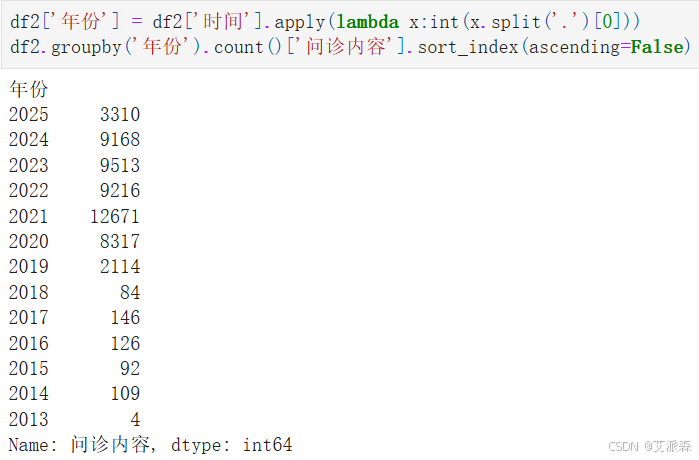
查看第二个糖尿病数据集按年份分布的问诊内容数量
查看第三个冠心病数据集按年份分布的问诊内容数量
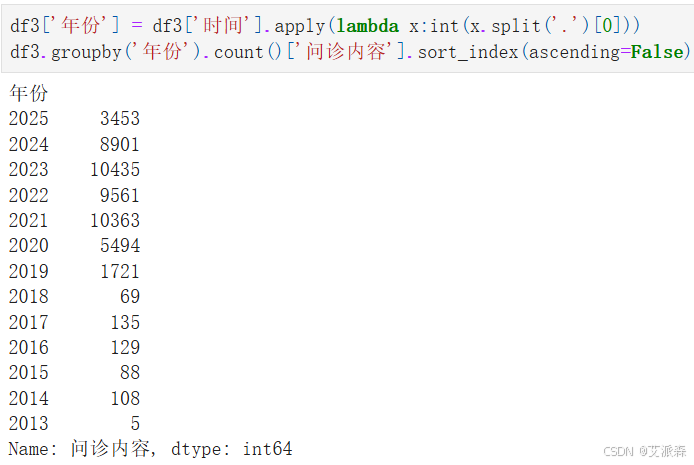
这里我选取2024年的问诊内容进行分析,合并三个2024年的数据集
new_df = pd.concat([df1[df1[\'年份\']==2024],df2[df2[\'年份\']==2024],df3[df3[\'年份\']==2024]],axis=0)new_df.head()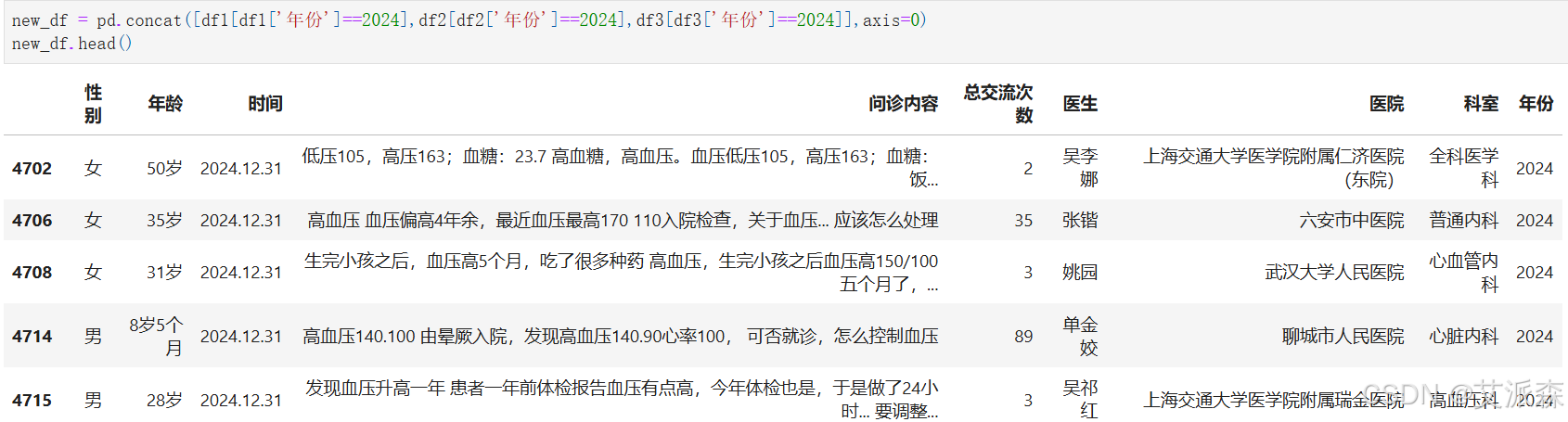
查看新数据集的大小,共计29417条
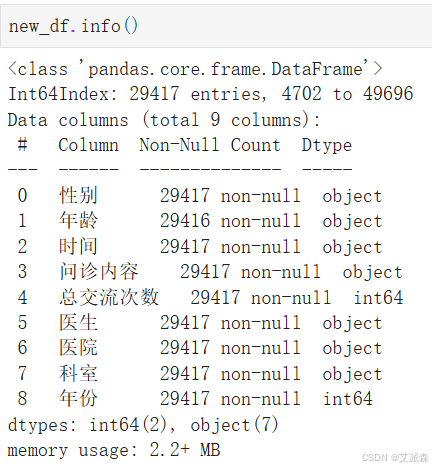
查看数据基本信息
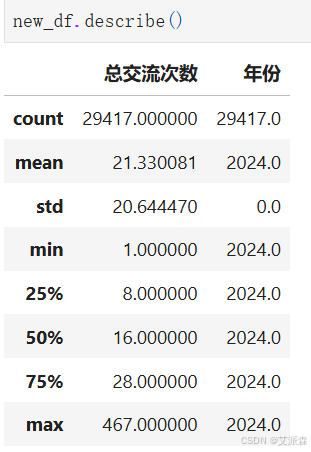
查看数值型变量的描述性统计
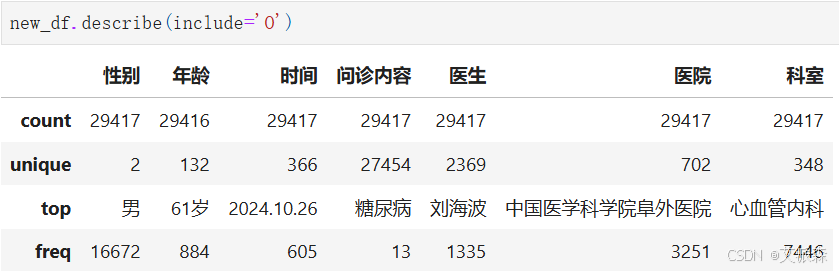
查看非数值型变量的描述性统计
4.2数据预处理
统计缺失值
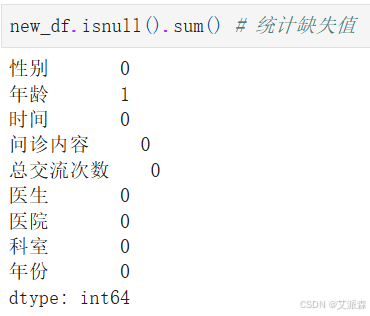
发现年龄变量中存在一个缺失值
统计重复值

发现存在一个重复数据
删除缺失数据和重复数据

4.3情感分析
这里我使用SnowNLP库进行情感分析,关于SnowNLP库的使用,可参考之前的博文:
SnowNLP使用自定义语料进行模型训练(情感分析)
基于snownlp模型的MatePad11产品用户评论情感分析
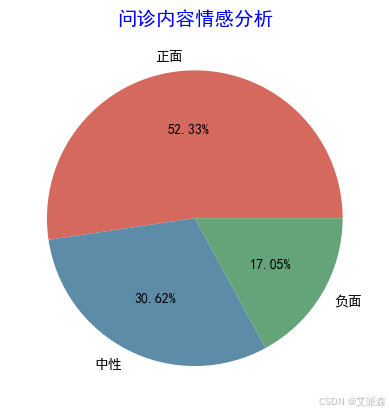
SnowNLP会得出每一条评论的情感分值,再讲情感分值进行分类(正面、中性、负面)
注意:要想SnowNLP情感分类精准,必须要使用自定义预料进行模型训练,具体参考上面第一篇博文,比如要做医学领域的情感分析,就要用医学领域的语料库去模型训练才能调高分类准确率,这里我没有做模型训练,使用自带的语料库。
# 加载情感分析模块from snownlp import SnowNLP# 遍历每条评论进行预测values=[SnowNLP(i).sentiments for i in new_df[\'问诊内容\']]# 输出情感分值# myval保存预测值myval=[]good=0mid=0bad=0for i in values: if (i>=0.6): myval.append(\"正面\") good=good+1 elif 0.4<i<0.6: myval.append(\"中性\") mid+=1 else: myval.append(\"负面\") bad=bad+1new_df[\'预测值\']=valuesnew_df[\'评价类别\']=myvalnew_df.head()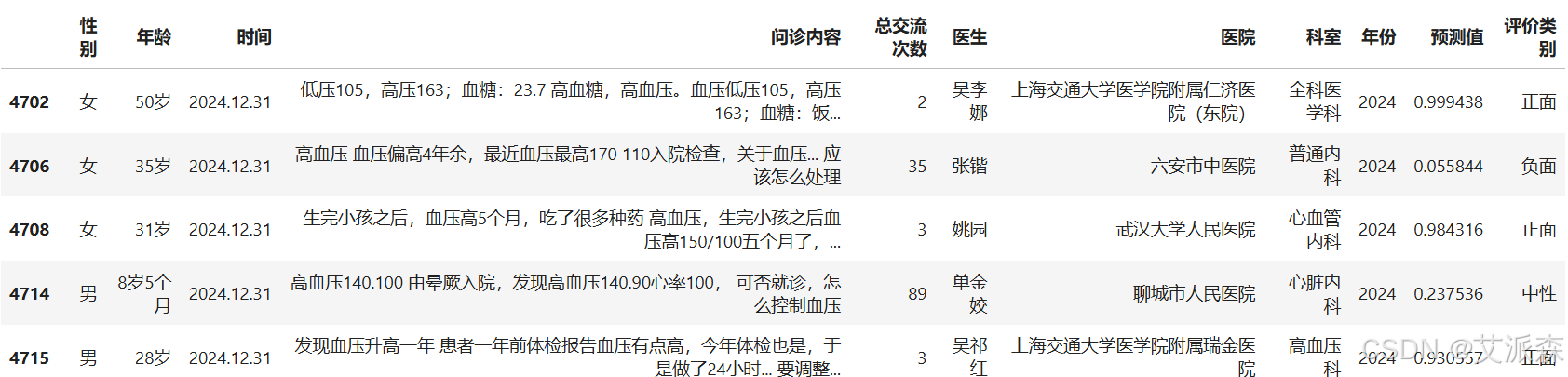
情感分析结果可视化

4.4BERTopic主题建模
首先提取出负面评论
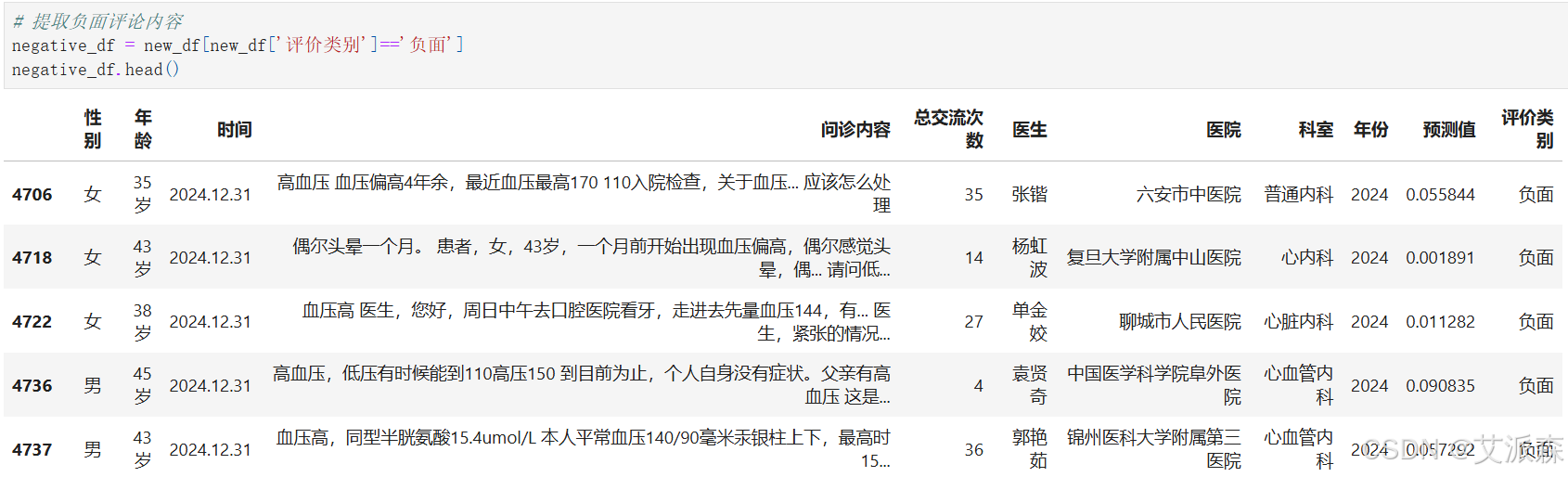
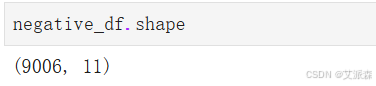
共计9006条数据
自定义中文分词函数并对负面评论进行分词、去停用词、降噪处理

对评论内容进行词向量化

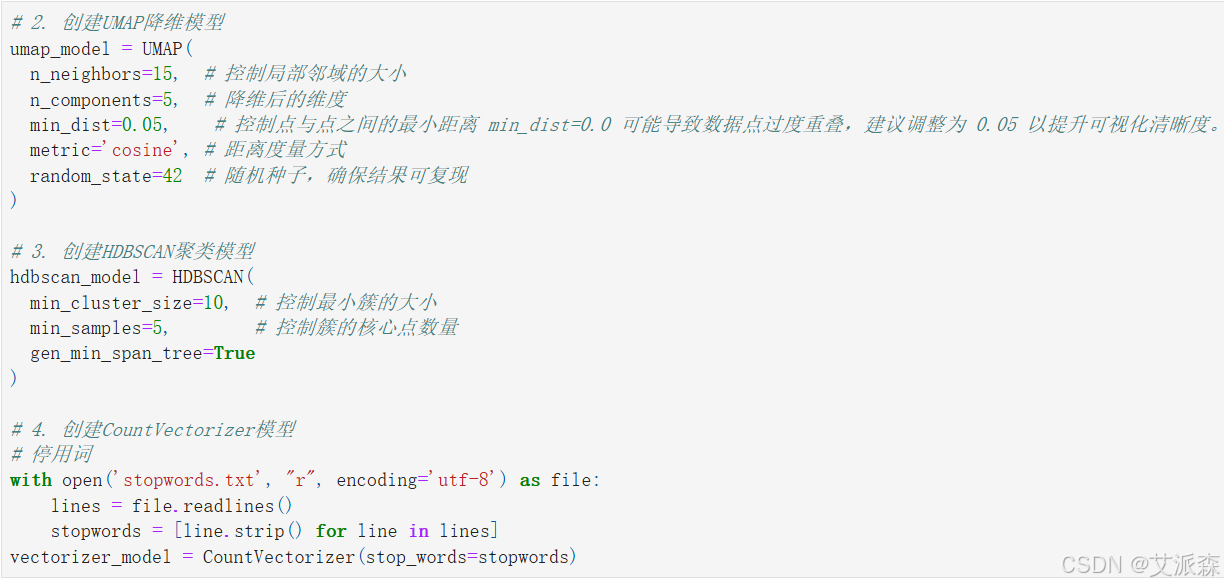
创建UMAP降维模型、创建HDBSCAN聚类模型、创建CountVectorizer模型
接着导入BERTopic模型并进行训练
# 主题优化# 该模型会将冗余的词进行替换,生成更具有多样性的主题词。from bertopic.representation import MaximalMarginalRelevance # 导入representation_model = MaximalMarginalRelevance() # 创建mmr模型topic_model = BERTopic( embedding_model=embedding_model, vectorizer_model=vectorizer_model, umap_model=umap_model, hdbscan_model=hdbscan_model, representation_model=representation_model # 传入模型)# 6.查看主题topics, probs = topic_model.fit_transform(docs, embeddings=embeddings) #传入训练好的词向量topic_info = topic_model.get_topic_info()topic_info
4.5结果可视化

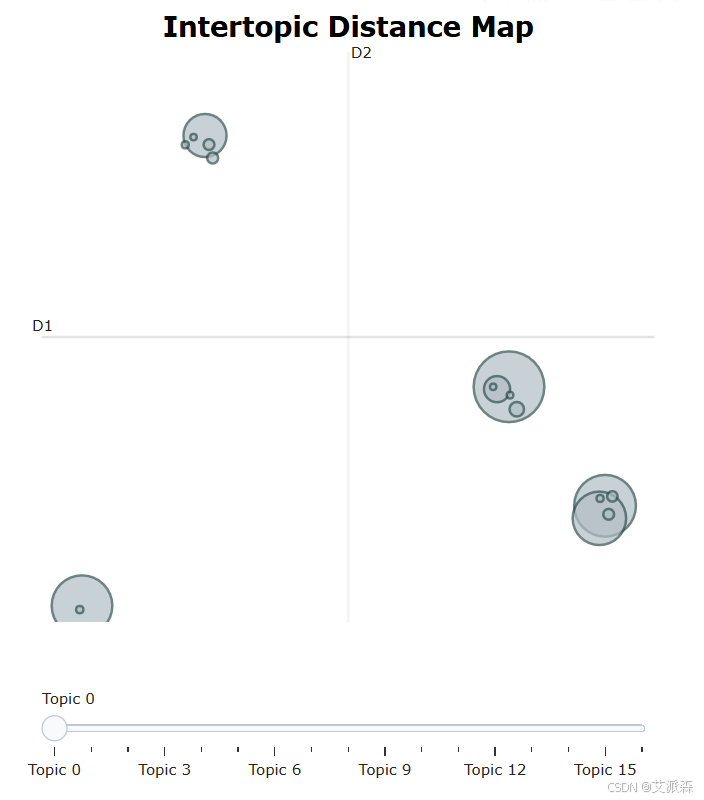

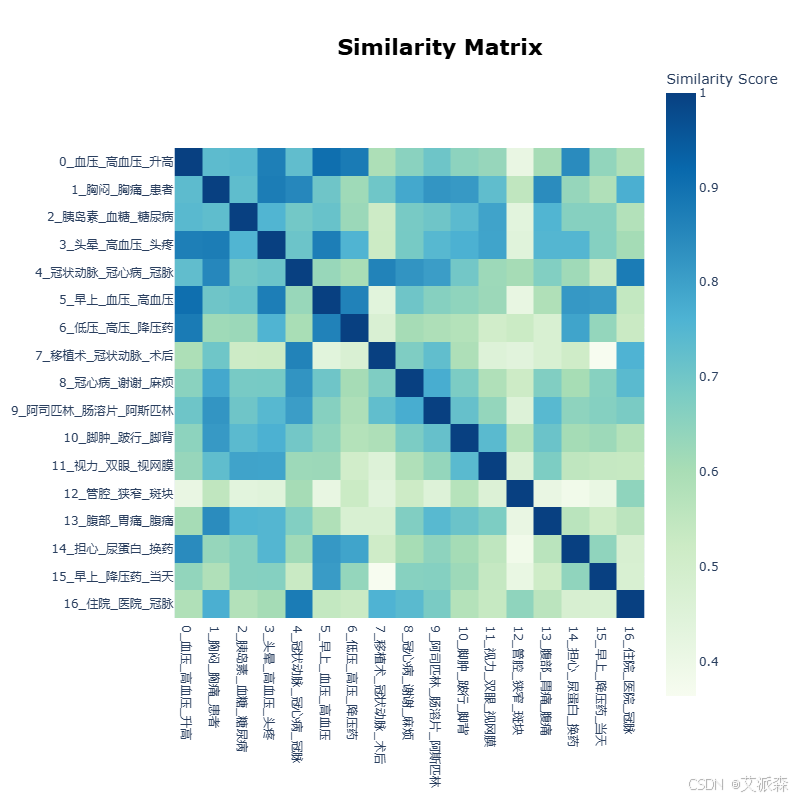

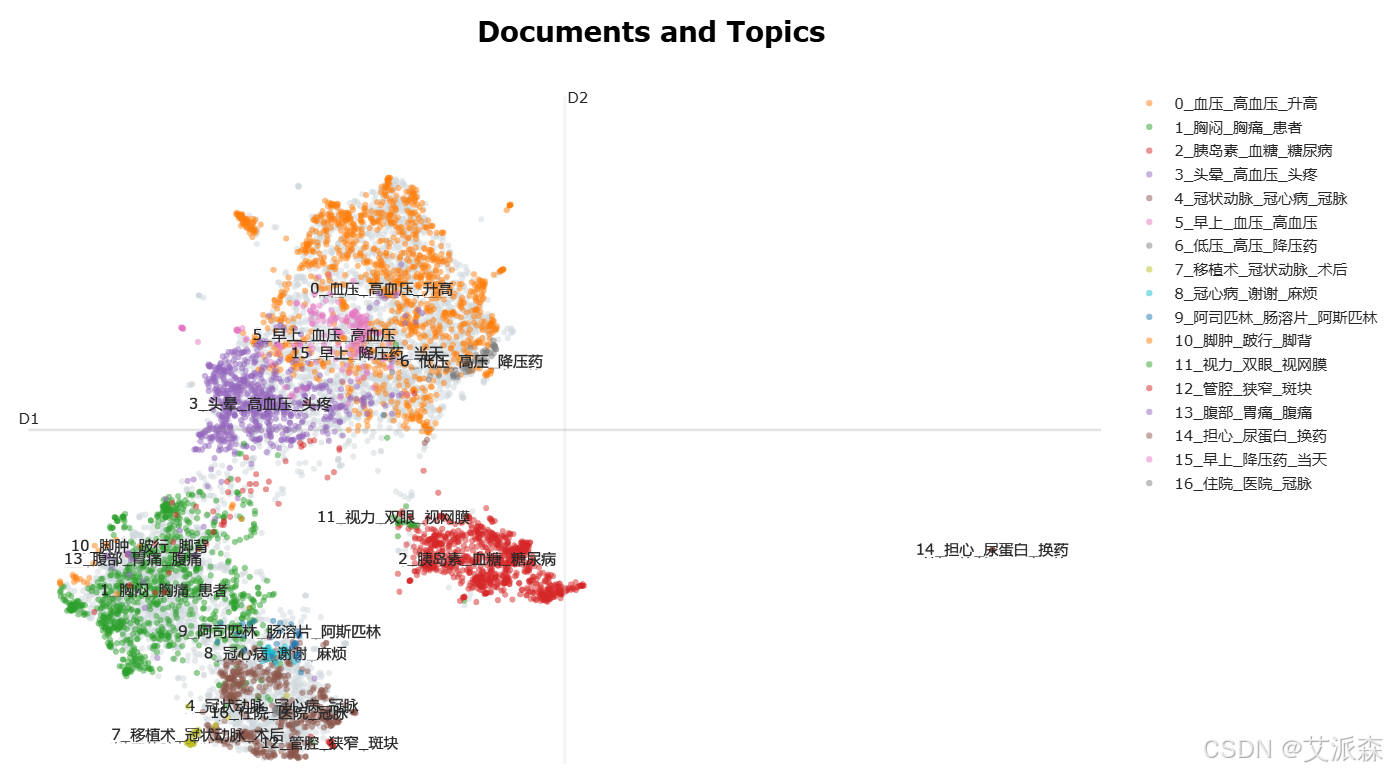

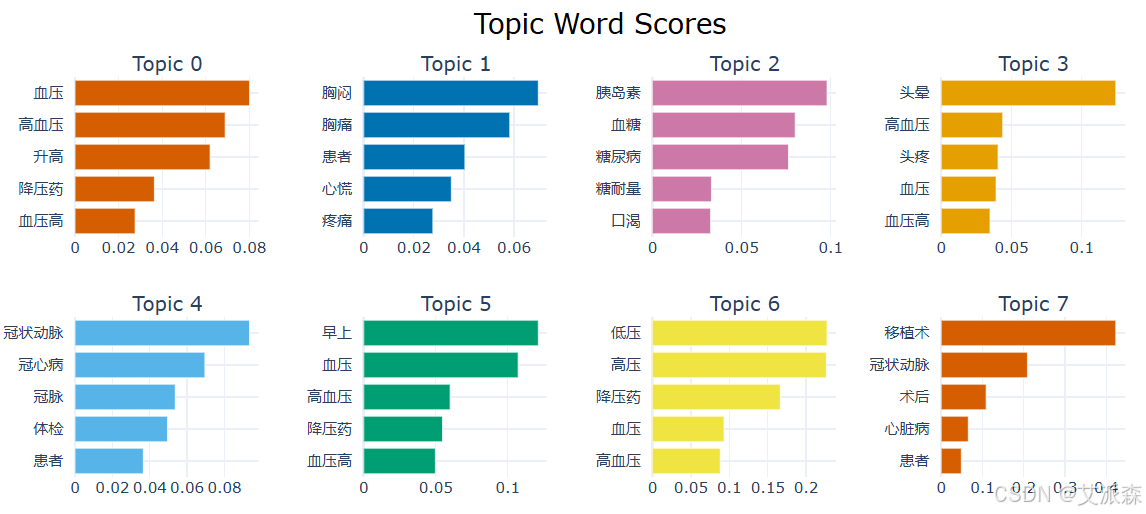

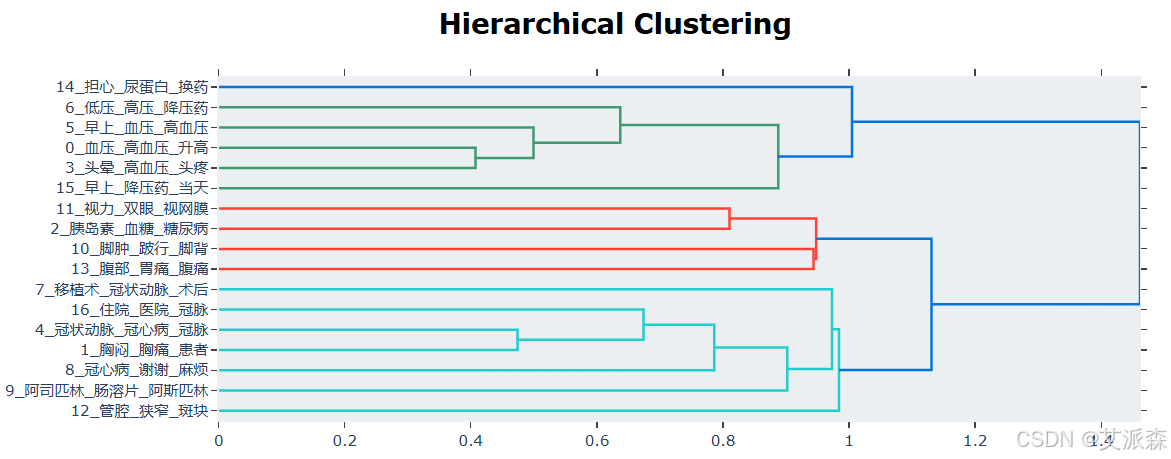
文献中只使用了后面四张图进行结果分析
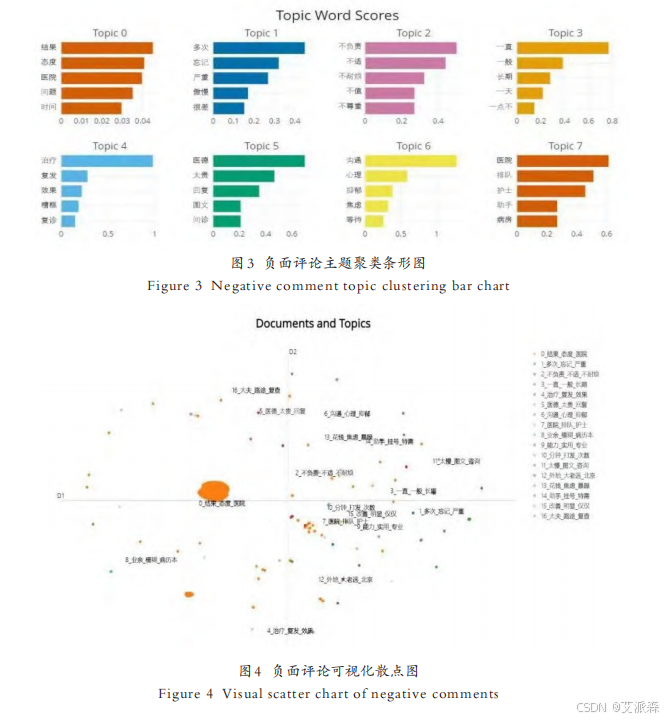
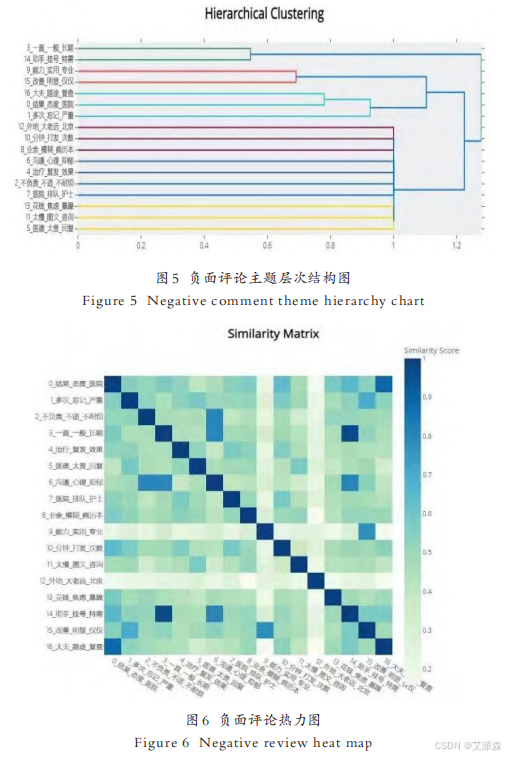
本次论文技术复现到这里结束!复现的内容并不是很完整!如需源码或数据集请关注公主号【派森小木屋】!
源代码
# 导入工具包import numpy as npfrom bertopic import BERTopicfrom sentence_transformers import SentenceTransformerfrom umap import UMAPfrom hdbscan import HDBSCANfrom sklearn.feature_extraction.text import CountVectorizerimport reimport jiebaimport pandas as pdimport warningswarnings.filterwarnings(\'ignore\')df1 = pd.read_csv(\'hypertension_inquiry_data.csv\')df2 = pd.read_csv(\'diabetes_inquiry_data.csv\')df3 = pd.read_csv(\'coronary_heart_disease_inquiry_data.csv\')df1.head()df1[\'年份\'] = df1[\'时间\'].apply(lambda x:int(x.split(\'.\')[0]))df1.groupby(\'年份\').count()[\'问诊内容\'].sort_index(ascending=False)df2[\'年份\'] = df2[\'时间\'].apply(lambda x:int(x.split(\'.\')[0]))df2.groupby(\'年份\').count()[\'问诊内容\'].sort_index(ascending=False)df3[\'年份\'] = df3[\'时间\'].apply(lambda x:int(x.split(\'.\')[0]))df3.groupby(\'年份\').count()[\'问诊内容\'].sort_index(ascending=False)new_df = pd.concat([df1[df1[\'年份\']==2024],df2[df2[\'年份\']==2024],df3[df3[\'年份\']==2024]],axis=0)new_df.head()new_df.shapenew_df.info()new_df.describe()new_df.describe(include=\'O\')new_df.isnull().sum() # 统计缺失值new_df.duplicated().sum() # 统计重复数据new_df.dropna(inplace=True) # 删除缺失值new_df.drop_duplicates(inplace=True) # 删除重复值# 加载情感分析模块from snownlp import SnowNLP# 遍历每条评论进行预测values=[SnowNLP(i).sentiments for i in new_df[\'问诊内容\']]# 输出情感分值# myval保存预测值myval=[]good=0mid=0bad=0for i in values: if (i>=0.6): myval.append(\"正面\") good=good+1 elif 0.4<i 1: result_list.append(word) return \' \'.join(result_list)# 调用分词函数docs = negative_df[\'问诊内容\'].apply(chinese_word_cut).tolist()print(\'文本条数: \', len(docs))# 1. 词向量模型,同时加载本地训练好的词向量model_path = \"./paraphrase-multilingual-MiniLM-L12-v2\"embedding_model = SentenceTransformer(model_path)embeddings = embedding_model.encode(docs) # 生成嵌入向量print(\'向量shape:\', embeddings.shape)# 2. 创建UMAP降维模型umap_model = UMAP( n_neighbors=15, # 控制局部邻域的大小 n_components=5, # 降维后的维度 min_dist=0.05, # 控制点与点之间的最小距离 min_dist=0.0 可能导致数据点过度重叠,建议调整为 0.05 以提升可视化清晰度。 metric=\'cosine\', # 距离度量方式 random_state=42 # 随机种子,确保结果可复现) # 3. 创建HDBSCAN聚类模型hdbscan_model = HDBSCAN( min_cluster_size=10, # 控制最小簇的大小 min_samples=5, # 控制簇的核心点数量 gen_min_span_tree=True)# 4. 创建CountVectorizer模型# 停用词with open(\'stopwords.txt\', \"r\", encoding=\'utf-8\') as file: lines = file.readlines() stopwords = [line.strip() for line in lines]vectorizer_model = CountVectorizer(stop_words=stopwords)# 主题优化# 该模型会将冗余的词进行替换,生成更具有多样性的主题词。from bertopic.representation import MaximalMarginalRelevance # 导入representation_model = MaximalMarginalRelevance() # 创建mmr模型topic_model = BERTopic( embedding_model=embedding_model, vectorizer_model=vectorizer_model, umap_model=umap_model, hdbscan_model=hdbscan_model, representation_model=representation_model # 传入模型)# 6.查看主题topics, probs = topic_model.fit_transform(docs, embeddings=embeddings) #传入训练好的词向量topic_info = topic_model.get_topic_info()topic_info# 结果可视化#6.1 主题分布可视化fig1 = topic_model.visualize_topics()fig1.write_html(\"1.topics.html\")#6.2 主题相似度可视化fig2 =topic_model.visualize_heatmap()fig2.write_html(\"2.simi_heatmap.html\")# 6.3 文档散点图可视化reduced_embeddings = UMAP().fit_transform(embeddings)fig3 = topic_model.visualize_documents(docs, reduced_embeddings=reduced_embeddings)fig3.write_html(\"3.docsvisual.html\")#6.4 主题关键词可视化fig4 = topic_model.visualize_barchart()fig4.write_html(\"4.keywords.html\")#6.5 层级可视化fig5= topic_model.visualize_hierarchy()fig5.write_html(\"5.Hierarchical.html\")y资料获取,更多粉丝福利,关注下方公众号获取


