go语言教程(全网最全,持续更新补全)
1、环境部署
https://studygolang.com/dl
选择对应的版本
1.1 Linux环境
1、下载安装包wget https://studygolang.com/dl/golang/go1.24.0.linux-amd64.tar.gz2、解压tar -C /usr/local -xvzf go1.24.0.linux-amd64.tar.gz3、配置环境变量vim /etc/profile.d/go.shexport GOROOT=/usr/local/goexport GOPATH=$HOME/goexport PATH=$PATH:$GOROOT/bin:$GOPATH/binsource /etc/profile.d/go.sh###GOROOT:Go 安装目录。这里我们假设 Go 已安装在 /usr/local/go。GOPATH:Go 的工作目录。通常可以设置为用户的 ~/go,这将存放 Go 的第三方包、项目等。PATH:更新系统路径,以便所有用户都可以在命令行中使用 Go###4、验证环境go version1.2 Windows:
双击 .msi 文件,按照提示安装(默认安装路径:C:\\Program Files\\Go)。
安装完成后,打开终端(cmd 或 PowerShell),运行 go version,验证安装成功。
1.3 macOS:
双击 .pkg 文件,按照提示安装。
打开终端,运行 go version,验证安装成功。
2、基础命令使用
下面会用一个简单的例子,教会大家使用这些基础命令
go mod init :初始化模块
go mod tidy: 下载依赖
go run: 运行文件
go build: 编译打包
mkidr /opt/learn_gocd /opt/learn_go# 初始化模块# 会生成go.mod,主要用来记录所用到的依赖go mod init learn_go# 打印helloworldcat >main.go <<EOFpackage mainimport \"fmt\"func main() { fmt.Println(\"Hello, World!\")}EOF#设置国内镜像源(可选)go env -w GO111MODULE=ongo env -w GOPROXY=https://goproxy.cn,direct#下载依赖go mod tidy#执行go run main.go#编译打包成二进制文件go build -o myapp#执行二进制文件./myapp3、基本语法
3.1 变量和常量
变量:
- 声明变量使用 var 或短变量声明(:=)。
- Go 支持类型推导,编译器根据初始值自动推断类型。
示例:
package mainimport \"fmt\"func main() { // 显式声明 var x int = 10 var name string = \"Golang\" // 类型推导 var y = 3.14 // float64 // 短变量声明(仅在函数内使用) z := true fmt.Println(x, name, y, z)}常量:
- 使用 const 定义,值不可更改。
- 通常用于固定值,如数学常数。
示例:
package mainimport \"fmt\"func main() { const Pi = 3.14159 const AppName = \"MyApp\" fmt.Println(Pi, AppName)}注意事项:
变量未初始化时,默认值为类型的零值(int 为 0,string 为 “”,bool 为 false)。
短变量声明(:=)只能用于函数内部。
3.2 基本数据类型
Go 的基本数据类型包括:
int:整数(如 1, -100)。
float64:双精度浮点数(如 3.14)。
string:字符串(如 “hello”)。
bool:布尔值(true/false)。
示例:
package mainimport \"fmt\"func main() {//数字类型 age := 25 // int price := 19.99 // float64fmt.Printf(\"age: %T %v \\n\", age, age)fmt.Printf(\"age: %T %v \\n\", price, price)// 控制小数点后显示的位数,这里是2位 fmt.Printf(\"Price with 2 decimal places: %.2f\\n\", price)//字符串 message := \"Hello\" // string //多行字符串 message2 :=` Hello Hello Hello ` isActive := true // bool fmt.Printf(\"Age: %d, Price: %.2f, Message: %s, Active: %t\\n\", age, price, message, isActive)}字符串类型详解
字符串底层是一个byte数组,所以可以和[]byte类型相互转换
uint8类型,或者byte 型:代表了ASCII码的一个字符。
rune类型:代表一个 UTF-8字符
package mainimport \"fmt\"func main() {s := \"你好李四\"s_rune := []rune(s)fmt.Println( \"再见\" + string(s_rune[2:])) // 再见李四}字符串常见操作
package mainimport (\"fmt\"\"strings\")func main() {//字符串长度len()var str = \"this is str\"fmt.Println(len(str)) //11//字符串拼接var str1 = \"`好\"var str2 = \"golang\"fmt.Println(str1 + \", \" + str2) fmt.Println(fmt.Sprintf(\"%s, %s\", str1, str2))//字符串分割strings.Split()var s = \"123-456-789\"var arr = strings.Split(s, \"-\") //返回一个字符串类型的切片[]stringfmt.Println(arr) //[123 456 789]//遍历字符串str := \"Hello, 世界\"// 方法1:使用 for range 遍历(推荐,可以正确处理 Unicode 字符)for index, char := range str {fmt.Printf(\"位置 %d: 字符 %c, Unicode码点 %U\\n\", index, char, char)}// 方法2:使用 for 循环遍历字节for i := 0; i < len(str); i++ {fmt.Printf(\"位置 %d: 字节 %d, 字符 %c\\n\", i, str[i], str[i])}// 方法3:将字符串转换为 rune 切片后遍历runes := []rune(str)for i, r := range runes {fmt.Printf(\"位置 %d: 字符 %c\\n\", i, r)}}3.3 复合数据类型
3.3.1 数组
数组是指 同一类型数据的集合
Go语言中数组的核心特点:
- 固定长度 - 数组长度在声明时确定,不可更改
- 值类型 - 赋值或传参时会复制整个数组
- 长度是类型的一部分 - [5]int和[10]int是不同类型
- 零值初始化 - 未赋值的元素自动设为零值
- 内存连续存储 - 元素在内存中连续排列
在实际开发中,Go程序员通常更倾向于使用切片(slice),因为它提供了动态长度和引用特性,更加灵活。
示例:
package mainimport \"fmt\"func main() {//定义、使用数组 var numbers [3]int = [3]int{1, 2, 3} fmt.Println(numbers) // [1 2 3] fmt.Println(numbers[1]) // 2//数组在进行数据传递时,是值传递,而非引用传递var arr = [3]int{1,2,3} arr2 := arr arr2[0] = 3 fmt.Println(arr,arr2) //[1 2 3] [3 2 3]//遍历数组 scores := [5]int{95, 85, 75, 90, 88} // 1. 使用传统的for循环 for i := 0; i < len(scores); i++ { fmt.Printf(\"学生%d的成绩: %d\\n\", i+1, scores[i]) } // 2. 使用for-range获取索引和值 for index, score := range scores { fmt.Printf(\"学生%d的成绩: %d\\n\", index+1, score) }}3.3.2 切片(slice)
切片(slice)是Go语言中比数组更灵活的数据结构
切片的核心特点:
- 动态长度 - 可以根据需要增长或缩小
- 引用类型 - 传递切片时只复制切片结构,不复制底层数据
- 底层结构 - 包含三部分:指向底层数组的指针、长度(len)和容量(cap)
- 零值是nil - 未初始化的切片值为nil,长度和容量都为0
- 可以使用append()函数 - 向切片添加元素,必要时会自动扩容
示例:
package mainimport \"fmt\"func main() { // 声明切片 var a []string //声明一个字符串切片, b==nil,无法直接使用 var f = make([]string,4) var b = []int{} //声明一个整型切片并初始化,b != nil var c = []int{1, 2, 3, 4} //声明一个整型切片并初始化,并赋值 // 添加元素 c = append(c, 5) fmt.Println(c) // [1 2 3 4 5] // 切片操作 //slice[low:high] low: 起始索引(包含该元素) high: 结束索引(不包含该元素) d = c[1:3] fmt.Println(d) // [2 3] fmt.Println(\"长度:%d 容量:%d\",len(d),cap(d) // 5}3.3.3 映射(map)
Map是Go语言中的内置关联数据结构,它提供了键值对的存储方式,类似于其他语言中的哈希表、字典或关联数组。
Map的核心特点:
- 键值对存储 - 每个值都与一个唯一的键关联
- 无序集合 - Map中的元素没有固定顺序
- 引用类型 - 传递Map时只复制引用,不复制数据
- 动态大小 - 会根据需要自动扩容
- 零值是nil - 未初始化的Map值为nil,不能直接使用
- 键类型限制 - 键必须是可比较的类型(如数字、字符串、布尔等)
- 值类型无限制 - 值可以是任何类型
示例:
package mainimport \"fmt\"func main() {// 1. 创建Map的不同方式studentScores1:= map[string]int{}studentScores2:= make(map[string]int)studentScores := map[string]int{\"张三\": 85,\"李四\": 92,\"王五\": 78,}fmt.Println(\"学生成绩:\", studentScores)// 2. 添加和修改元素studentScores[\"张三\"] = 90studentScores[\"刘六\"] = 60fmt.Println(\"学生成绩:\", studentScores)// 3. 获取元素zhangScore := studentScores[\"张三\"]fmt.Println(\"张三的成绩:\", zhangScore)// 4. 检查键是否存在score, ok := studentScores[\"赵六\"]if ok {fmt.Println(\"赵六的成绩:\", score)} else {fmt.Println(\"赵六不在成绩单中\")}// 6. 删除元素delete(studentScores, \"王五\")fmt.Println(\"删除王五后:\", studentScores)// 7. 遍历Mapfor name, score := range studentScores {fmt.Printf(\"%s: 成绩=%d\\n\", name, score)}//8. 只获取keyfor k := range studentScores {fmt.Printf(\"%s\\n\", k)}// 8. 获取Map长度fmt.Println(\"学生人数:\", len(studentScores)) }3.4 控制结构
if-else:
支持初始化语句,作用域限于 if 块。
示例:
package mainimport \"fmt\"func main() { score := 85 if score >= 90 { fmt.Println(\"A\") } else if score >= 60 { fmt.Println(\"Pass\") } else { fmt.Println(\"Fail\") }}for 循环:
Go 只有 for 循环,无 while。
示例:
package mainimport \"fmt\"func main() { // 标准 for 循环 for i := 0; i < 3; i++ { fmt.Println(i) } // 类似 while 的循环 sum := 0 for sum < 5 { sum++ fmt.Println(sum) } // 遍历切片 numbers := []int{1, 2, 3} for index, value := range numbers { fmt.Printf(\"Index: %d, Value: %d\\n\", index, value) }}switch-case:
自动 break,支持表达式。
示例:
package mainimport \"fmt\"func main() { day := 3 switch day { case 1: fmt.Println(\"Monday\") case 2: fmt.Println(\"Tuesday\") case 3: fmt.Println(\"Wednesday\") default: fmt.Println(\"Other\") }}3.5 函数
使用方法
使用 func 关键字,指定参数和返回值类型。
示例:
package mainimport \"fmt\"//函数使用func add(a int, b int) int {return a + b}func main() {result := add(2, 3)fmt.Println(result) // 5//匿名函数addfunc := func(a int, b int) int {return a + b}result2 := addfunc(1,2)fmt.Println(result2)}Init函数和main函数
main函数
Go语言程序的默认入口函数
init函数
go语言中 init函数用于包 (package)的初始化,该函数是go语言的一个重要特性。
有下面的特征:
- init函数是用于程序执行前做包的初始化的函数,比如初始化包里的变量等
- 每个包可以拥有多个init函数
- 同一个包中多个init函数的执行顺序go语言没有明确的定义(说明)
- 不同包的init函数按照包导入的依赖关系决定该初始化函数的执行顺序
- init函数不能被其他函数调用,而是在main函数执行之前,自动被调用
init函数函数和和main函数函数的的异同异同
相同点:
- 两个函数在定义时不能有任何的参数和返回值,且Go程序自动调用。
不同点:
- init可以应用于任意包中,且可以重复定义多个。
- main函数只能用于main包中,且只能定义一个。
- 两个函数的执行顺序:
对同一个go文件的 init() 调用顺序是从上到下的。
对同一个package中不同文件是按文件名字符串比较“从小到大”顺序调用各文件中的 init() 函数。
对于不同的 package ,如果不相互依赖的话,按照main包中\"先 import 的后调用\"的顺序调用其包中的init()
如果 package 存在依赖,则先调用最早被依赖的 package 中的 init() ,最后调用 main 函数。
在这里插入代码片闭包
闭包是一个函数能够记住并访问其创建时的环境变量,简单来说,就像一个函数随身带着一个小背包,里面装着它需要的变量。
案例1: 工厂函数
func makeMultiplier(factor int) func(int) int { return func(x int) int { return x * factor }}func main() { double := makeMultiplier(2) triple := makeMultiplier(3) fmt.Println(double(5)) // 输出:10 fmt.Println(triple(5)) // 输出:15}说明:makeMultiplier是一个工厂函数,它返回一个根据特定因子进行乘法的函数。返回的函数\"记住\"了创建时传入的factor值。案例2: 装饰器
func logExecutionTime(f func(string) string) func(string) string { return func(input string) string { start := time.Now() result := f(input) fmt.Printf(\"执行时间: %v\\n\", time.Since(start)) return result }}func processString(s string) string { time.Sleep(100 * time.Millisecond) return strings.ToUpper(s)}func main() { decoratedFunc := logExecutionTime(processString) result := decoratedFunc(\"hello\") fmt.Println(result) // 输出执行时间和\"HELLO\"}说明:这个例子实现了装饰器模式,logExecutionTime函数返回一个新函数,它在执行原始函数前后添加了额外的逻辑(计时功能)。返回的函数形成闭包,它捕获了原始函数f
3.6 错误处理
error处理
大部分的内置包或者外部包,都有自己的报错处理机制。因此我们使用的任何函数可能报错,这些报错都不应该被忽略,
而是在调用函数的地方,优雅地处理报错
示例:
package mainimport (\"fmt\"\"net/http\")func main() {resp, err := http.Get(\"http://example.com/\")if err != nil {fmt.Println(err)return}fmt.Println(resp)}panic/recover:
用于处理严重错误(如程序崩溃),不推荐频繁使用。
示例:
package mainimport (\"fmt\")// 案例: 空指针引用func demoNilPointer() {fmt.Println(\"\\n------ 空指针引用案例 ------\")defer func() {if r := recover(); r != nil {fmt.Println(\"捕获到panic:\", r)}}()var p *int = nilfmt.Println(\"尝试解引用空指针\")fmt.Println(*p) // 这里会引发panic}func main() {demoNilPointer()fmt.Printf(\"hello world\")}这段代码由几个关键部分组成:
-
defer 关键字:defer会将后面的函数调用推迟到当前函数返回之前执行。无论当前函数是正常返回还是因为panic而中断,defer都会确保这个函数被调用。
-
匿名函数:func() { … }()是一个立即定义并执行的匿名函数。括号()表示立即调用这个函数。
-
recover() 函数:这是Go语言内置函数,用于捕获当前goroutine中的panic。如果当前goroutine没有panic,recover()返回nil;如果有panic,recover()会捕获panic的值并返回,同时停止panic传播。
-
判断逻辑:if r := recover(); r != nil { … }会先调用recover()并将结果赋值给变量r,然后检查r是否为nil。如果不是nil,说明捕获到了panic。
工作流程:
1、当函数开始执行时,先注册这个defer函数(但暂不执行)
2、如果函数正常执行完毕,defer函数会在返回前执行,recover()返回nil,不做特殊处理
3、如果函数中发生了panic:
- 函数立即停止正常执行
- Go运行时开始回溯调用栈,执行每一层的defer函数
- 当执行到这个defer函数时,recover()捕获panic值
- panic传播被阻止,程序恢复正常执行流程
- 打印捕获到的panic信息
这种模式是Go语言处理异常情况的惯用法,它允许你在发生严重错误时优雅地恢复程序执行,而不是让整个程序崩溃。
简单来说,这段代码的意思是:“如果这个函数中发生了panic,请捕获它并打印出来,然后让程序继续运行,而不是崩溃”。
4、go核心特性
4.1 指针(Pointer)
指针是一个变量,其值为另一个变量的内存地址。在 Go 中:
使用 *T 表示指向类型 T 的指针类型
使用 & 运算符获取变量的内存地址
使用 * 运算符解引用指针(获取指针指向的值)
作用:
指针是存储变量内存地址的数据类型,主要作用是允许函数修改外部变量、避免复制大型数据结构
指针使用说明
核心概念:(a是一个变量)
- 指针地址:\" &a \"
- 指针取值: \" *&a \"
- 指针类型: \" *T \" , eg: *int
原理如图所示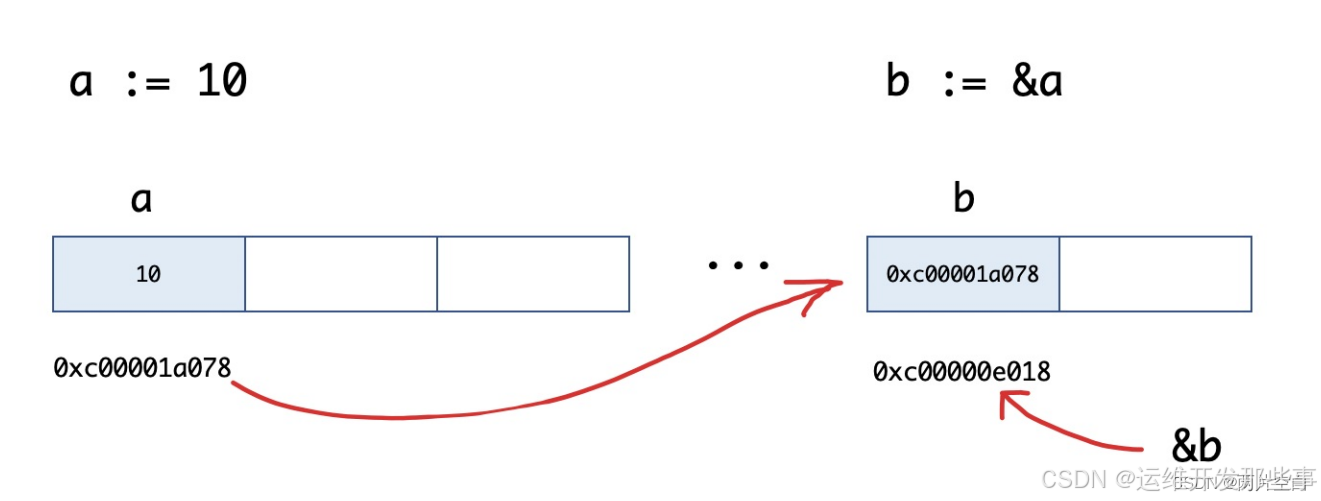
代码示例
package mainimport (\"fmt\")func main() {//指针地址&a、指针取值*aa := 10b := &ac := *&afmt.Println(a, b, c) //10 0xc0000a4010 10 10fmt.Printf(\"a的类型是%T,b的类型是%T,c的类型是%T\\n\", a, b, c) //a的类型是int,b的类型是*int,c的类型是int}new和make用法
在 Go 语言中对于引用类型的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则则我们的值就没办法存储
eg:
package mainfunc main() {var studentscore map[string]intstudentscore[\"lisi\"] = 80println(studentscore)}执行会报错:panic: assignment to entry in nil map
Go 语言中 new 和 make 是内建的两个函数,主要用来分配内存
make和new的主要区别
-
适用类型不同
make: 仅用于创建切片(slice)、映射(map)和通道(channel)
new: 可用于任何类型 -
返回值不同
make: 返回初始化后的引用类型的值(返回已初始化的实例本身,可以直接使用)
new: 返回指向零值的指针 -
初始化行为不同
make: 分配内存并初始化底层数据结构,使其可用
new: 只分配内存并设为零值,不做初始化
package mainimport \"fmt\"func main() {// 使用make创建切片、map和channelslice := make([]int, 3) // 创建长度为3的切片m := make(map[string]int) // 创建mapch := make(chan int, 2) // 创建带缓冲的channelfmt.Println(slice, m, ch)// 使用new创建各种类型ptr := new(int) // 创建指向int零值的指针fmt.Println(*ptr) // 输出0// 对比make和new创建切片的区别s1 := make([]int, 3) // 创建初始化的切片,可直接使用s2 := new([]int) // 创建指向nil切片的指针,*s2是空切片fmt.Println(s1, *s2) // 输出[0 0 0] []// *s2需要先append才能使用*s2 = append(*s2, 1, 2, 3)fmt.Println(*s2) // 输出[1 2 3]}4.2 结构体
结构体使用
结构体(struct)是一种自定义的数据类型
核心概念:
- 结构体
- 结构体方法
- 结构体指针方法
区别总结
结构体方法:接收者是结构体值,方法内修改字段不会影响原始结构体。
结构体指针方法:接收者是结构体指针,方法内修改字段会影响原始结构体。
package mainimport \"fmt\"// 结构体type Person struct {Name stringAge int}// 结构体方法func (p Person) SayHello() {fmt.Println(\"Hello, my name is\", p.Name)}// 结构体指针方法func (p *Person) SetAge1(age int) {p.Age = age}func (p Person) SetAge2(age int) {p.Age = age}// main 函数演示了Go语言中结构体的四种初始化方式:// 1. 直接初始化结构体// 2. 先声明后赋值// 3. 使用new关键字创建指针// 4. 使用取地址符&初始化指针// 同时展示了结构体方法和指针方法的调用区别,// 以及Go语言按值传递的特性。func main() {// 创建一个Person实例,方式1person := Person{Name: \"John\", Age: 30}// 创建一个Person实例,方式2var person2 Personperson2.Name = \"Amy\"person2.Age = 25fmt.Printf(\"person2: %T\\n\", person2) //person2: main.Person// 创建一个Person实例,方式3// person3返回的是结构体指针 person3.Name = \"xiaoming\" 底层 (*person3).name = \"xiaoming\"person3 := new(Person)person3.Name = \"xiaoming\"person3.Age = 30fmt.Printf(\"person3: %T\\n\", person3) //person3: *main.Person// 创建一个Person实例,方式4person4 := &Person{Name: \"liuqiang\", Age: 30}fmt.Printf(\"person4: %T\\n\", person4) //person4: *main.Person// 调用构体方法person.SayHello()// 调用结构体指针方法//指针接收者:当结构体方法使用指针接收者(即方法接收者为 *StructType 形式)定义时,该方法会接收一个指向结构体的指针。这意味着方法内部操作的是原始结构体的内存地址,而不是其副本。因此,对结构体字段的任何修改都会直接反映到原始结构体上person4.SetAge1(40) //40fmt.Println(person4.Age)//在Go语言中,函数参数的传递方式是按值传递。这意味着当你将一个变量传递给函数时,实际上是传递了这个变量的副本。因此,如果在函数内部修改了这个副本,原始变量不会受到影响。person.SetAge2(40)fmt.Println(person.Age) //30}继承
package mainimport (\"fmt\")type Person struct {Name stringAge int}// 继承type Student struct {Person *PersonSchool string}// 继承type Teacher struct {Person PersonSchool string}//注意:继承的时候指定结构体指针和结构体的区别。继承结构体指针,在赋值操作的时候,可以修改原来的值,而继承结构体的时候,赋值会把结构体对象复制一份func main() {stu := Student{Person: &Person{Name: \"John\", Age: 20},School: \"MIT\",}fmt.Println(stu)stu.Person.Age = 21fmt.Println(stu.Person.Age)tea := Teacher{Person: Person{Name: \"Amy\", Age: 30},School: \"Harvard\",}fmt.Println(tea)tea.Person.Age = 31fmt.Println(tea.Person.Age)//赋值的时候,两者区别,指针类型可以修改原来的值,结构体类型会复制一份新的值tea1 := teatea1.Person.Age = 32fmt.Println(tea1.Person.Age) //32fmt.Println(tea.Person.Age) //31stu1 := stustu1.Person.Age = 22fmt.Println(stu1.Person.Age) //22fmt.Println(stu.Person.Age) //22}encoding-json包
encoding-json包可以实现 结构体和json之间的相互转换
package mainimport (\"encoding/json\"\"fmt\")type Person struct {Name stringAge int}// 指定序列化后的字段type Person2 struct {Name string `json:\"name\"`Age int `json:\"age\"`}func main() {// 序列化,对象转jsonperson := Person{Name: \"John\", Age: 30}jsonData, err := json.Marshal(person) //返回的是一个字节切片[]uint8if err != nil {fmt.Println(\"Error marshalling to JSON:\", err)return}fmt.Printf(\"jsonData: %T\\n\", jsonData) //jsonData: []uint8//string() 将字节切片转换为字符串fmt.Println(string(jsonData)) //{\"Name\":\"John\",\"Age\":30}// 反序列化,json转对象//反引号(`)包围的字符串是 原始字符串字面量,与普通的双引号字符串(\" \")不同,它不会对字符串内容中的特殊字符(如换行符、制表符等)进行转义处理,也不需要使用反斜杠(\\)来转义json_str := `{\"Name\":\"John\",\"Age\":30}`var person2 Person//json_str 是字符串类型,需要转换为字节切片err = json.Unmarshal([]byte(json_str), &person2)if err != nil {fmt.Println(\"Error unmarshalling from JSON:\", err)return}fmt.Println(person2)// 序列化,对象转json,指定序列化后的字段person3 := Person2{Name: \"Amy\", Age: 30}jsonData, err = json.Marshal(person3)if err != nil {fmt.Println(\"Error marshalling to JSON:\", err)return}fmt.Println(string(jsonData)) //{\"name\":\"John\",\"age\":30}// 反序列化,json转对象,指定序列化后的字段json_str = `{\"name\":\"Amy\",\"age\":30}`var person4 Person2err = json.Unmarshal([]byte(json_str), &person4)if err != nil {fmt.Println(\"Error unmarshalling from JSON:\", err)return}fmt.Println(person4) //{John 30}}4.3 接口
如何使用
Go 语言中的接口定义是非常简单的,接口定义了一组方法,但是不包含方法的具体实现。实现接口的类型需要提供该接口所定义的所有方法
接口的作用
- 多态性:通过接口,可以让不同的类型实现相同的行为,代码可以对不同类型的对象进行相同的操作。
- 解耦:接口使得代码中的模块和功能解耦,减少了对具体类型的依赖,增强了灵活性和可扩展性。
package mainimport (\"fmt\")// 定义一个接口 Animal,包含一个 Speak 方法type Animal interface {Speak() string}// 定义一个函数,传入一个 Animal 类型的参数,并调用其 Speak 方法func Speak(a Animal) {fmt.Println(a.Speak())}// 定义一个 Dog 结构体,包含一个 Name 字段type Dog struct {Name string}// 实现 Animal 接口的 Speak 方法func (d Dog) Speak() string {return \"Woof!\"}// 定义一个 Cat 结构体,包含一个 Name 字段type Cat struct {Name string}// 实现 Animal 接口的 Speak 方法func (c Cat) Speak() string {return \"Meow!\"}func main() {dog := Dog{Name: \"Rex\"}cat := Cat{Name: \"Whiskers\"}// Speak函数接收Amimal接口,不管哪个结构体,只要实现了 Animal 接口的 Speak 方法,就可以调用Speak(dog) //输出:Woof!Speak(cat) //输出:Meow!}空接口
Golang中空接口也可以直接当做类型来使用,可以表示任意类型 (泛型概念)
package mainimport (\"fmt\")// 定义一个函数接收空接口func print(a interface{}) {fmt.Println(a)}func main() {print(1)print(\"hello\")print(true)// 定义一个空接口类型的切片a := []interface{}{\"nihao\", 2, true}print(a)// 定义一个map,key为string,value为空接口b := map[string]interface{}{\"name\": \"张三\", \"age\": 20, \"gender\": \"男\"}print(b)// 定义一个结构体,包含一个字段,类型为空接口c := struct {Name interface{}}{Name: \"张三\"}print(c)}类型断言
是用来检查接口类型的动态类型
语法:
value, ok := x.(T)
- x 是一个接口类型的变量。
- T 是我们希望断言的目标类型。
- value 是断言成功后的值,如果 x 是 T 类型,value 将包含 x 的值。
- ok 是一个布尔值,如果断言成功,ok 为 true,否则为 false。
如果没有使用 ok 变量,断言失败会导致程序 panic。通过 ok 方式,可以避免这种情况并优雅地处理类型断言失败的情况。
package mainimport \"fmt\"func main() { var x interface{} = \"Hello, Go!\" // x 是一个空接口,可以接受任何类型 // 类型断言,检查 x 是否是一个 string 类型 value, ok := x.(string) if ok { fmt.Println(\"x is a string:\", value) // 输出:x is a string: Hello, Go! } else { fmt.Println(\"x is not a string\") } // 类型断言,检查 x 是否是一个 int 类型 value2, ok2 := x.(int) if ok2 { fmt.Println(\"x is an int:\", value2) } else { fmt.Println(\"x is not an int\") // 输出:x is not an int }}5、并发编程
5.1 并发和并行
并发是指多个任务在同一时间段内交替进行,而并行是指多个任务在同一时刻同时进行
5.2 进程、线程、协程
1、进程是操作系统分配资源的最小单位,每个进程有自己的内存空间和资源,进程间相互独立。
2、线程是进程中的执行单位,同一个进程中的线程共享内存和资源,因此线程间的通信和协作更高效。
3、协程是用户级的轻量级线程,协程通过协作式调度,不需要操作系统干预,能够实现高效的并发执行,且开销远低于线程
协程被称为用户级的轻量级线程,是因为:
-
用户级调度:协程的调度由用户程序控制,而不是由操作系统内核控制。操作系统只知道线程的调度,而协程的切换完全是在用户代码中通过程序实现,避免了内核的上下文切换开销。
-
栈空间小:与线程相比,协程占用的内存栈空间非常小。线程需要为每个任务分配独立的内存空间,通常需要几百KB甚至更多,而协程的栈空间可以控制得非常小,通常只需要几KB。
上下文切换低成本:线程的上下文切换需要保存和恢复大量的寄存器状态及内核栈,耗费较多的系统资源。而协程的切换只需要保存和恢复一些基本的状态信息(如栈指针、程序计数器等),这一过程由用户空间的库进行管理,因此切换速度更快、开销更低。
- 无需内核干预:线程的调度由操作系统内核完成,涉及内核态和用户态之间的切换,涉及上下文切换和系统调用,这些都需要消耗较多的时间和资源。而协程完全在用户空间调度,避免了内核干预,减少了上下文切换的成本。
5.2 goroutine
- 多线程编程的缺点
- 在 java/c 中我们要实现并发编程的时候,我们通常需要自己维护一个线程池
- 并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换
- goroutine
- Goroutine 是 Go 语言中的一种轻量级线程,但 goroutine是由Go的运行时(runtime)调度和管理的。
- Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经 内置了 调度和上下文切换的机制 。
- 在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能–goroutine
当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个goroutine去执行这个函数就可
以了,就是这么简单粗暴。
5.3 协程使用
WaitGroup
用于等待一组 goroutines 完成
主要方法:
- Add (int): 增加等待的 goroutine 数量,`` 通常是一个正数,表示将增加多少个 goroutine。
- Done(): 在一个 goroutine 完成时调用,表示这个 goroutine 已经结束,WaitGroup 的计数器减少 1。
- Wait(): 阻塞当前 goroutine,直到 WaitGroup 中的计数器减少到 0,即所有的 goroutines 都完成。
package mainimport (\"fmt\"\"sync\"\"time\")func task(i int, waitGroup *sync.WaitGroup) {// 在函数结束时,调用 Done 方法,减少 WaitGroup 的计数器defer waitGroup.Done()fmt.Printf(\"任务%d开始执行\\n\", i)// 模拟任务执行时间 1stime.Sleep(time.Second * 1)fmt.Printf(\"任务%d执行完成\\n\", i)}func main() {var waitGroup sync.WaitGroupfor i := 1; i <= 5; i++ {waitGroup.Add(1)go task(i, &waitGroup)}// 等待协程执行完成waitGroup.Wait()// 所有 goroutines 完成后,输出fmt.Println(\"All tasks finished\")}此处跑出一个关于值传递的问题,如果task方法接受的是结构体,go task()传入的也是sync.WaitGroup结构体,会发生什么?
答: waitGroup.Wait()这行会报错 fatal error: all goroutines are asleep - deadlock!
1、sync.WaitGroup 是一个结构体,当按值传递时,会创建一个副本;
2、在副本上调用 Done() 方法不会影响原始的 WaitGroup,所以waitGroup.Wait()永远都没办法结束
3、通过使用指针,我们确保所有协程都在操作同一个 WaitGroup 实例
5.4 channel
channel 是一种用于在 goroutine 之间传递数据的机制
主要作用:
- 通信:通过 channel,可以让多个 goroutines 之间交换数据。
- 同步:使用 channel 可以使得某个 goroutine 在完成特定操作后通知其他 goroutine,或者等待其他 goroutine 完成任务。
- 阻塞行为:发送和接收数据时会自动阻塞,直到操作可以继续。
用法
package mainimport (\"fmt\")// 创建一个channelfunc main() {// 创建一个channelch := make(chan int)fmt.Printf(\"channel: %v ,Type: %T\\n\", ch, ch)// 启动一个协程,向channel中写入数据go func() {// 向channel中写入数据ch <- 1}()// 从channel中读取数据result := <-chfmt.Println(result)}案例:生产者消费者
package mainimport (\"fmt\"\"time\")// 生产者func producer(ch chan int) {for i := 1; i <= 10; i++ {println(\"生产者生产数据\", i)ch <- i}// 关闭channel,无法写入,但是还可以读取//写完记得要关闭,否则消费者会一直阻塞等待,for读取的时候会报错死锁close(ch)}// 消费者func consumer(ch chan int, exitChan chan bool) {// 从channel中读取数据,阻塞等待,直到有数据写入channel,如果channel关闭,则退出循环for i := range ch {fmt.Println(\"消费者消费数据\", i)// 休眠1秒time.Sleep(time.Second * 1)}// 发送完成信号exitChan <- trueclose(exitChan)}// 创建一个channelfunc main() {// 创建一个channelch := make(chan int)exitChan := make(chan bool)// 启动生产者go producer(ch)// 启动消费者go consumer(ch, exitChan)for {if _, ok := <-exitChan; !ok {fmt.Println(\"所有任务完成\")break}}}5.5 select多路复用
select 语句用于实现多路复用,可以在多个通道(channels)之间进行选择,并且在某个通道准备好进行操作时执行相应的操作。它类似于操作系统中的 I/O 多路复用,使得程序能够同时处理多个事件或任务。
作用:
- 多通道监听:select 可以在多个通道上等待,这样程序能够同时处理多个数据流。
- 阻塞与非阻塞:select 会阻塞等待直到某个通道可以进行操作。如果有多个通道可以操作,Go会随机选择一个进行处理。
- 超时处理 - 结合 time.After 可以实现超时机制
- 优雅退出 - 可以设置退出信号,实现程序的优雅退出
select { case <- chan1: // 如果chan1成功读到数据,则进行该case处理语句 case <- chan2: // 如果chan2成功读到数据,则进行该case处理语句 default: // 如果上面都没有成功,则进入default处理流程案例: 结合多通道监听、超时处理、优雅退出
package mainimport (\"context\"\"fmt\"\"os\"\"os/signal\"\"time\")// 模拟两个工作协程,分别发送消息到不同的通道func worker1(ch chan string) {for i := 1; i <= 3; i++ {ch <- fmt.Sprintf(\"Worker1: Message %d\", i)time.Sleep(1 * time.Second) // 模拟工作}}func worker2(ch chan string) {for i := 1; i <= 3; i++ {ch <- fmt.Sprintf(\"Worker2: Message %d\", i)time.Sleep(2 * time.Second) // 模拟工作}}func main() {// 创建两个通道ch1 := make(chan string)ch2 := make(chan string)// 创建上下文,用于优雅退出ctx, cancel := context.WithCancel(context.Background())defer cancel()// 启动两个工作协程go worker1(ch1)go worker2(ch2)// 捕获系统退出信号(如 Ctrl+C)sigCh := make(chan os.Signal, 1)signal.Notify(sigCh, os.Interrupt)// 设置超时时间为 10 秒timeout := time.After(10 * time.Second)fmt.Println(\"开始监听消息...\")for {select {case msg := <-ch1: // 监听 worker1 的消息fmt.Println(\"收到:\", msg)case msg := <-ch2: // 监听 worker2 的消息fmt.Println(\"收到:\", msg)case <-timeout: // 超时退出fmt.Println(\"超时,程序退出\")returncase <-sigCh: // 捕获退出信号fmt.Println(\"收到退出信号,优雅退出\")cancel() // 通知上下文取消returncase <-ctx.Done(): // 上下文取消fmt.Println(\"上下文取消,程序退出\")return}}}上下文作用:
上下文(context) 是一个用于控制协程生命周期和传递取消信号的工具
-
上下文(context.Context)通过 ctx.Done() 提供了一个通道,当上下文被取消时(比如调用 cancel()),Done() 通道会关闭,通知所有监听它的协程停止工作。
-
在案例代码中,ctx, cancel := context.WithCancel(context.Background()) 创建了一个可取消的上下文。当收到退出信号(如 Ctrl+C)或超时触发时,调用 cancel(),程序通过 select 监听到 <-ctx.Done() 后退出,也就是说当 cancel() 被调用,<-ctx.Done() 会触发
-
由于 ctx.Done() 是一个 <-chan struct{} 类型的通道,返回值是 struct{} 的零值,即一个空的 struct{}
5.6 互斥锁
互斥锁(Mutex,Mutual Exclusion Lock)用于保护共享资源,防止多个 goroutine 同时访问或修改共享数据,从而避免数据竞争(data race)问题。Go 的标准库 sync 包提供了 sync.Mutex 类型来实现互斥锁
案例:一万个1相加
package mainimport (\"fmt\"\"sync\")func main() {var waitGroup sync.WaitGroupvar lock sync.Mutexnum := 0for i := 1; i <= 10000; i++ {waitGroup.Add(1)go func() {lock.Lock()num += 1lock.Unlock()waitGroup.Done()}()}waitGroup.Wait()fmt.Println(num) //10000}6、常见库的使用
6.1 fmt
- Println(常用):一次输入多个值的时候 Println 中间有空格,Println 会自动换行
- Print:一次输入多个值的时候 Print 没有 中间有空格,不会自动换行
- Printf(常用):是格式化输出,在很多场景下比 Println 更方便
- Sprintf(常用):是格式化输出,返回字符串,不打印,常用于变量的拼接以及赋值
package mainimport \"fmt\"func main() {fmt.Print(\"zhangsan\",\"lisi\",\"wangwu\") //zhangsanlisiwangwufmt.Println(\"zhangsan\",\"lisi\",\"wangwu\") //zhangsan lisi wangwuname := \"zhangsan\"age := 20fmt.Printf(\"%s 今年 %d 岁\", name, age) //zhangsan 今年 20 岁info := fmt.Sprintf(\"姓名:%s, 性别: %d\", name, 20)fmt.Println(info)}- 格式化符号
%v: 默认格式值。
%T: 变量类型。
%d: 整数。
%f: 浮点数。
%t: 布尔值。
%s: 字符串。
%x, %X: 十六进制表示
6.2 reflect
reflect.TypeOf查看数据类型
package mainimport (\"fmt\"\"reflect\")func main() {c := 10fmt.Println( reflect.TypeOf(c) ) // int}6.3 time
package mainimport (\"fmt\"\"time\")func main() {//获取当前时间now := time.Now()fmt.Println(now)//获取年月日小时分钟秒fmt.Println(now.Year(), now.Month(), now.Day(), now.Hour(), now.Minute(), now.Second())//格式化当前时间fmt.Println(now.Format(\"2006-01-02 15:04:05\"))//获取当前时间戳timestamp := time.Now().Unix()fmt.Println(timestamp)}
