Windows下模型微调+量化+对话三部曲之模型微调(llamafactory+llamacpp+ollama)_在windows llama-factory微调
由于教程步骤过多比较详细,所以以三部曲的形式分为了三篇,该教程是三部曲的第一篇,该篇主要是皆在利用llamafactory进行模型微调,同时给出一些相关注意事项。本教程的目标是微调出一个能够成功对自我认知进行转换的模型,然后将其量化并且部署在本地。
博主电脑配置信息如下:
NVIDIA GeForce RTX 3060 Ti
注意:最好安装anaconda或者miniconda创建虚拟环境用来运行llamacpp和llamafactory,所以该教程假设您已经安装了anaconda。
llamafactory安装+微调
1、按住键盘“win+s”键打开搜索,输入anaconda prompt点击进入命令行窗口
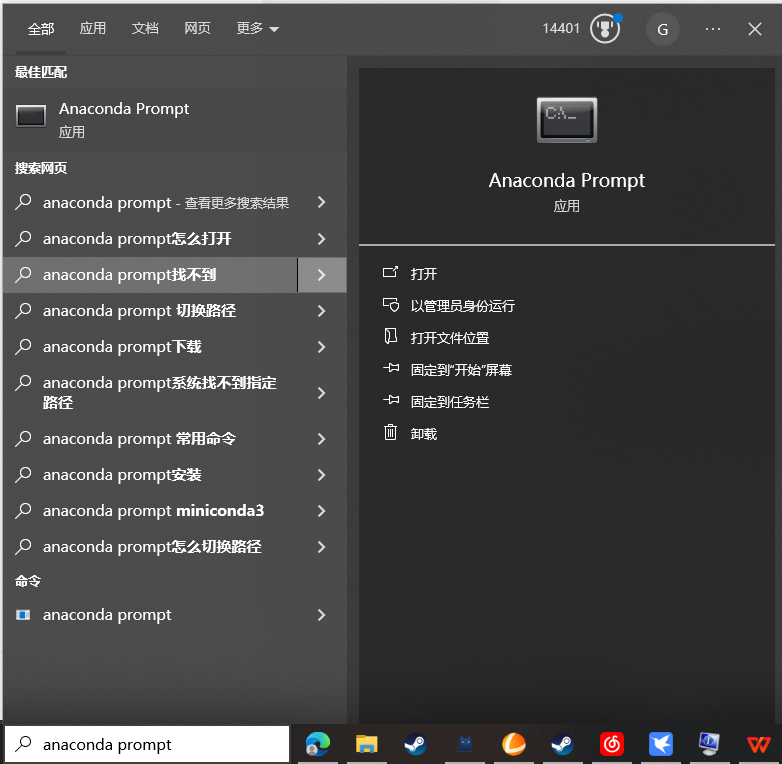
2、输入创建虚拟环境命令:
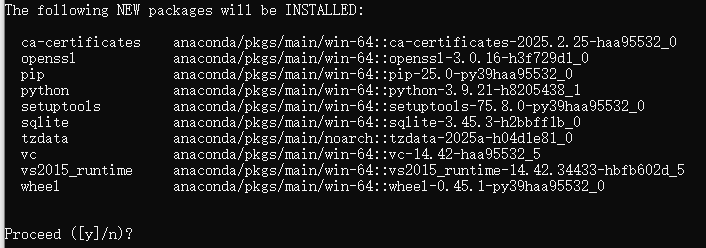
conda create --name llamafactory python=3.9当弹出如下窗口时直接回车即可
3、创建好虚拟环境后不要关闭这个窗口,点击下面的LLamafactory的压缩包下载链接进行下载,如果下载不了,可以选择进入gitee中进行下载。
github:https://github.com/hiyouga/LLaMA-Factory/archive/refs/tags/v0.9.2.zip
gitee:Gitee Search - 开源软件搜索
4、下载完后,将其解压到你想要存放的路径,比如我将其解压到了G盘存放,记住存放路径后面我们需要用到。
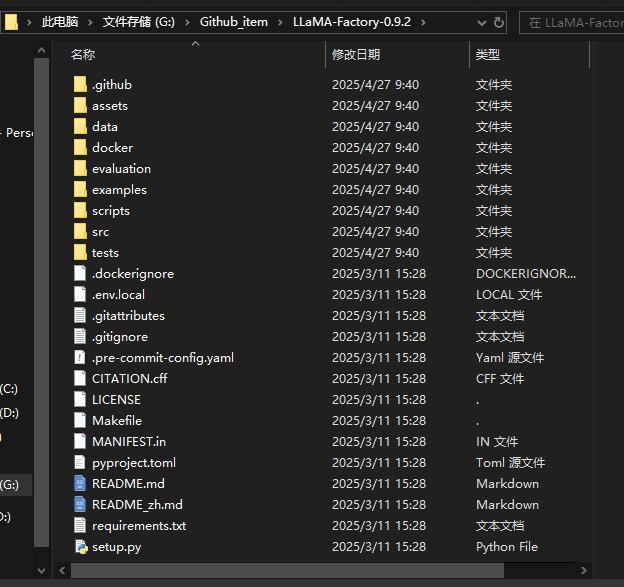
5、解压完毕后,我们回到anaconda的命令行窗口,命令行窗口进入到LLamafactory的目录下,以我为例
6、当命令行窗口进入到该目录下时,我们执行以下pip安装命令
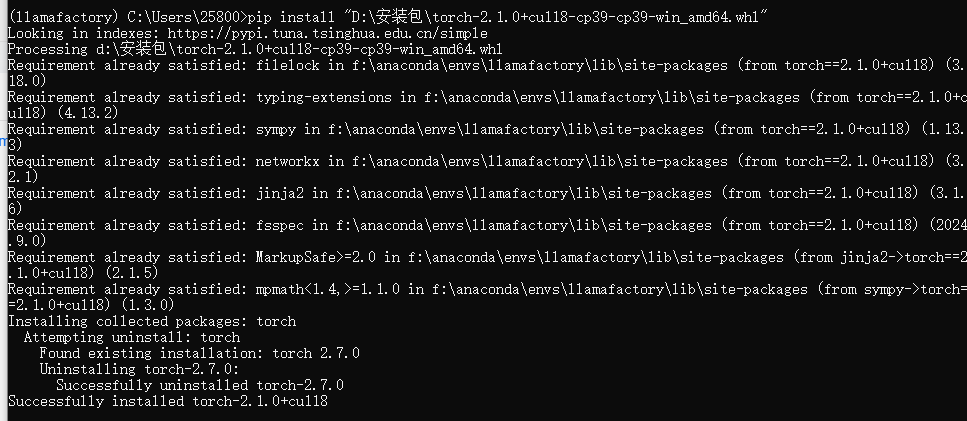
pip install -e \".[torch,metrics]\"### 如果环境出现冲突请使用如下安装命令pip install --no-deps -e .6.1 下载完后不要急,这个pip命令中下载的是cpu的torch版本,我们需要利用之前下载好的torch的gpu版本进行覆盖(如果你还没下可以查看这个教程:如何快速安装pytorch gpu版本,避免用官方命令下载导致速度过慢-CSDN博客),我的命令如下
pip install \"D:\\安装包\\torch-2.1.0+cu118-cp39-cp39-win_amd64.whl\"安装结果如图下所示:
测试是否安装成功如图所示:

7、输入命令llamafactory-cli version来测试是否安装成功
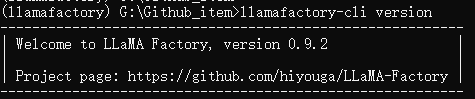
8、测试成功后,我们需要获取一个公开的大语言模型进行微调,这里我推荐使用modelscope下载模型,我们先在该虚拟环境下安装modelscope库
pip install modelscope下载完成后如下图所示
9、安装成功后,我们进入到“魔塔社区”主页,首页 · 魔搭社区
获取对应模型下载命令如下图所示
9.1 在搜索框输入你想要微调的模型,这里以Qwen2.5举例(这里我用的是7.5B的模型,如果你的设备显存和内存不够,可以考虑选择1.5B)
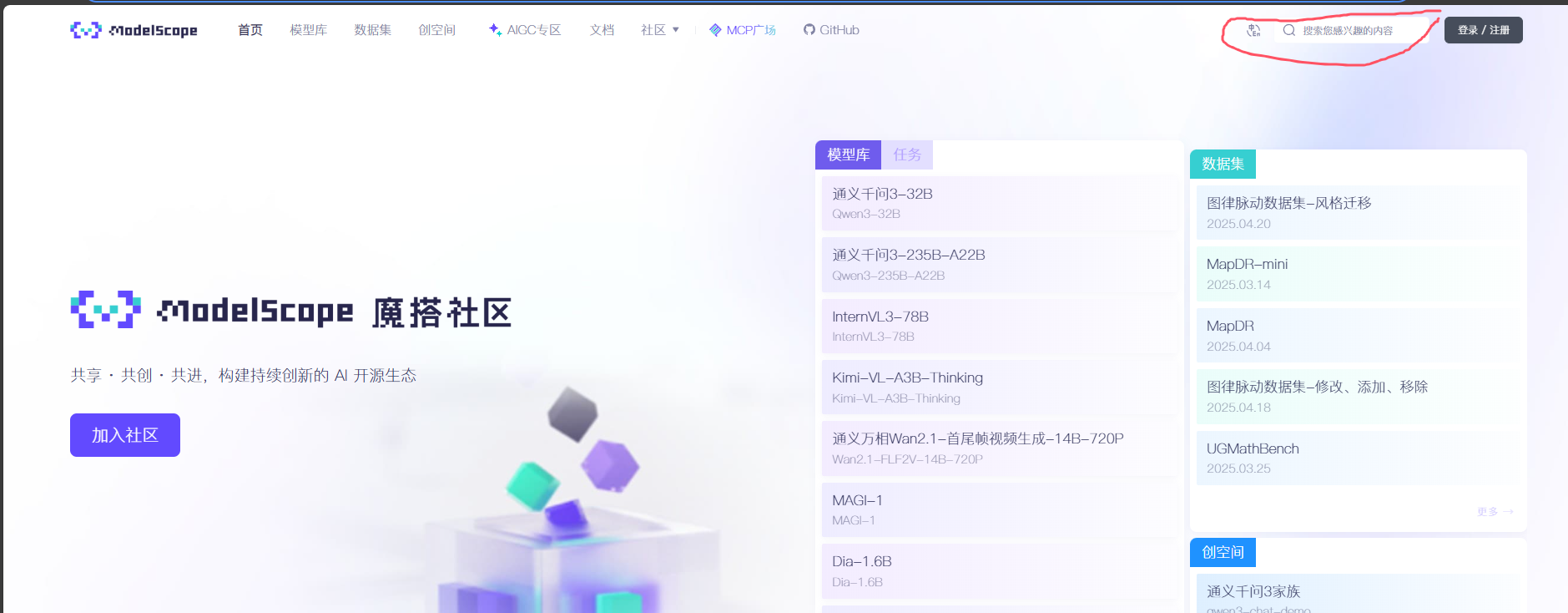
9.2 点击进入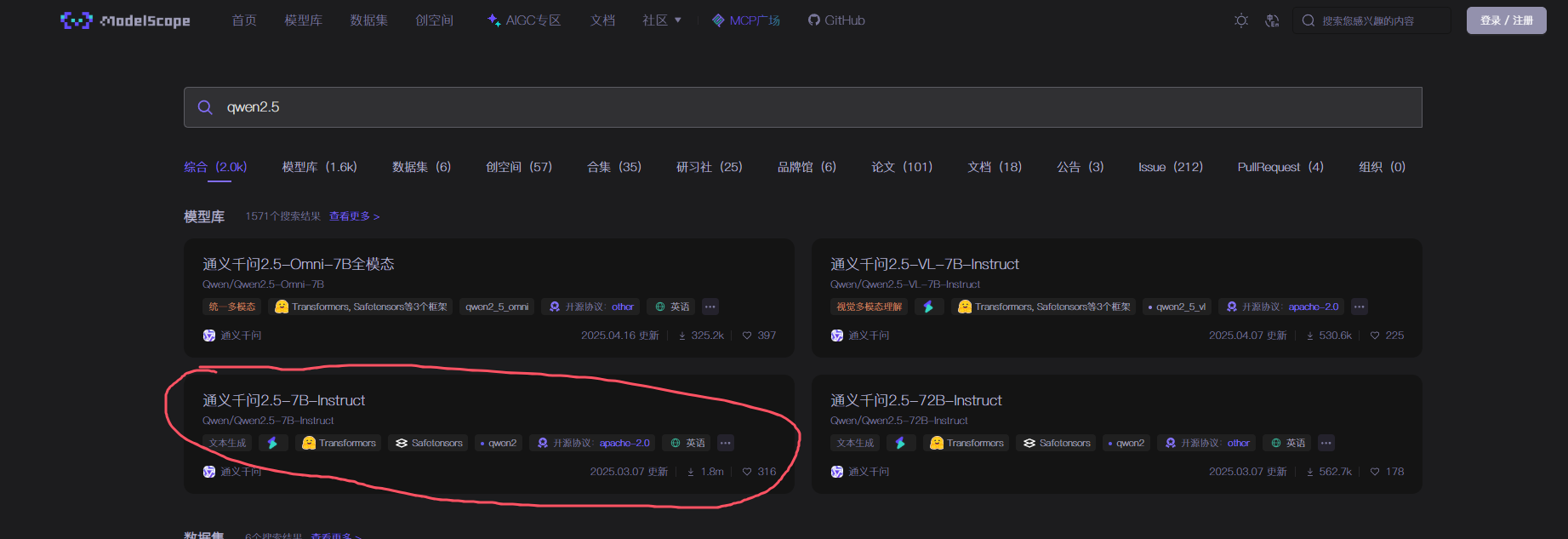
9.3 进入后点击“模型文件”
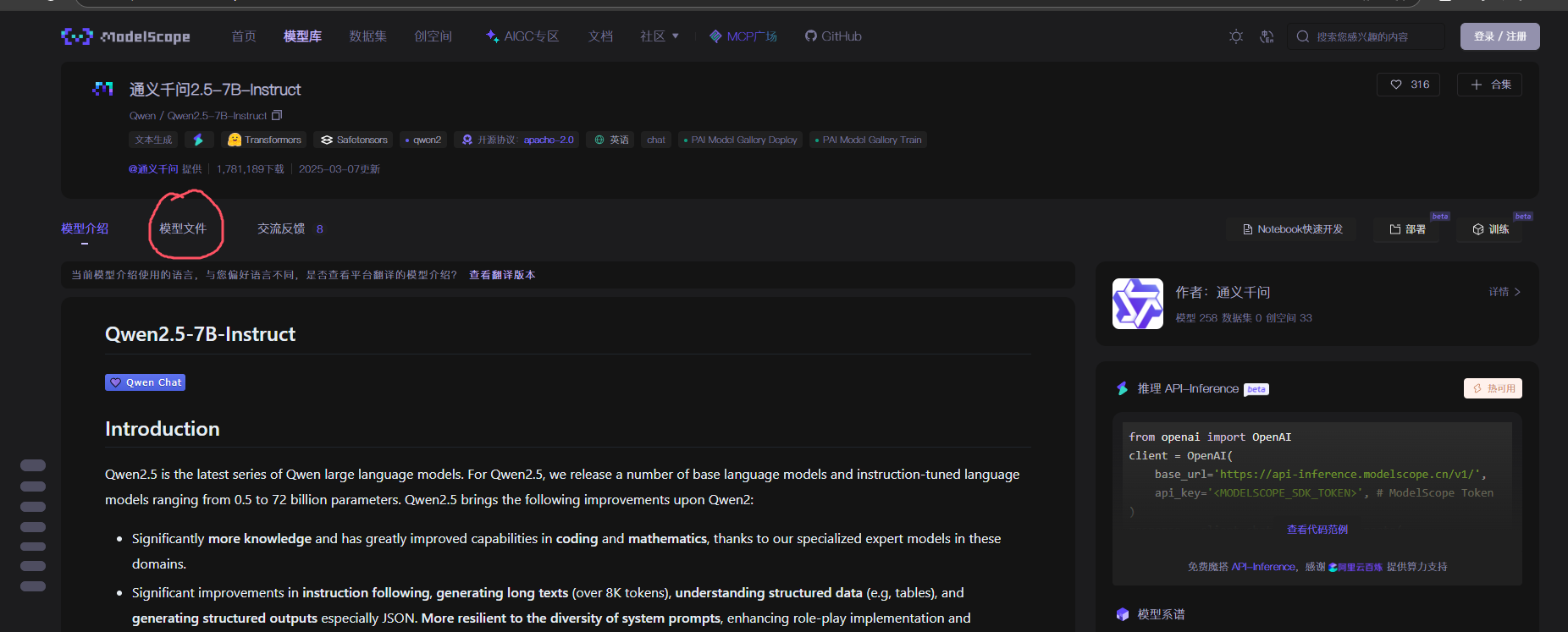
9.4 点击下载模型
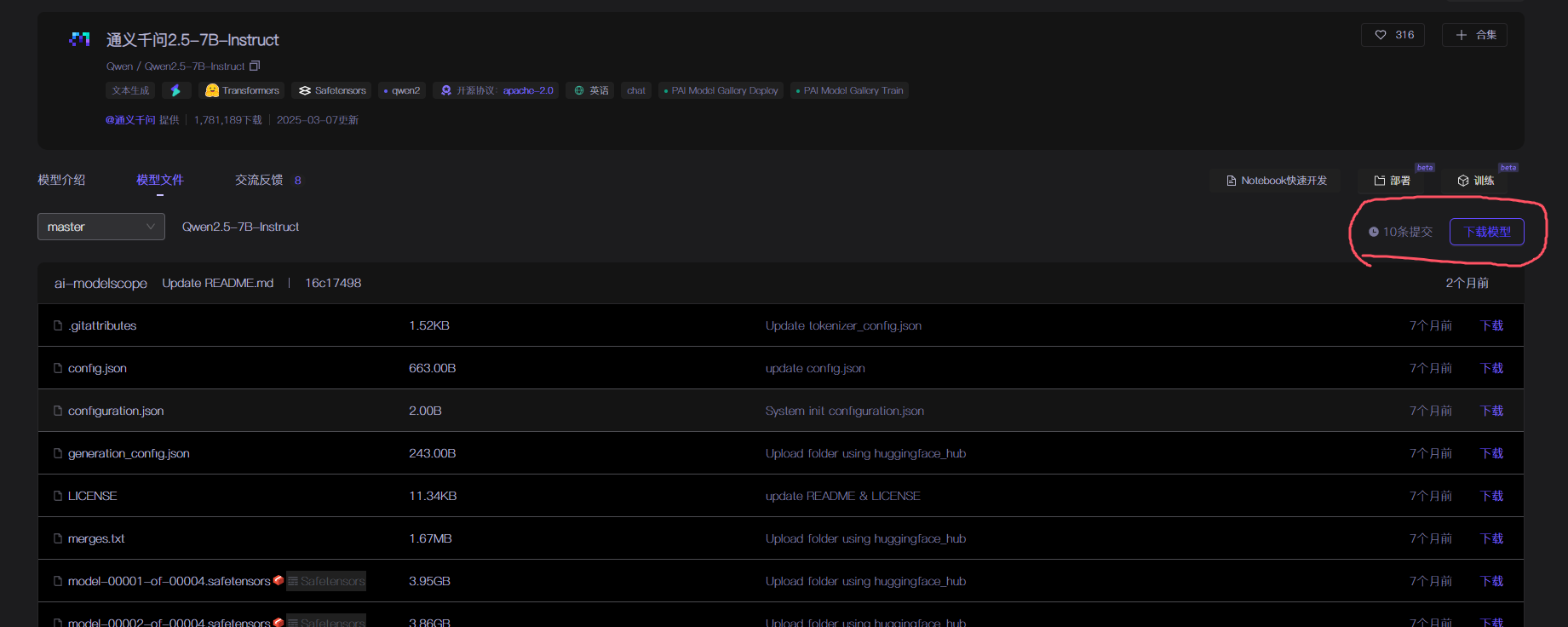
9.5 获取模型下载命令
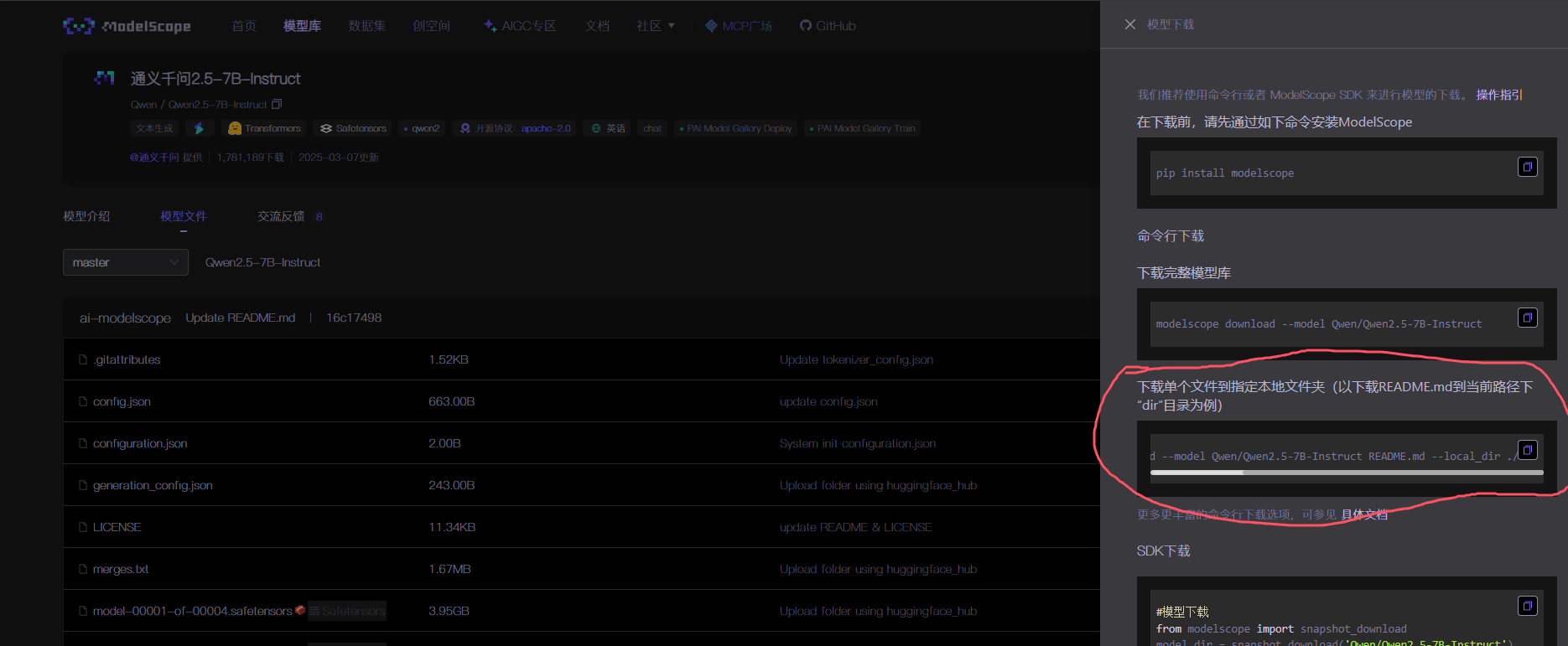
这是我的下载命令,可以直接复制粘贴使用,这里我的存放路径为E:\\Models\\Qwen
modelscope download --model Qwen/Qwen2.5-7B-Instruct --local_dir E:\\Models\\Qwen模型文件较大等待下载完即可。
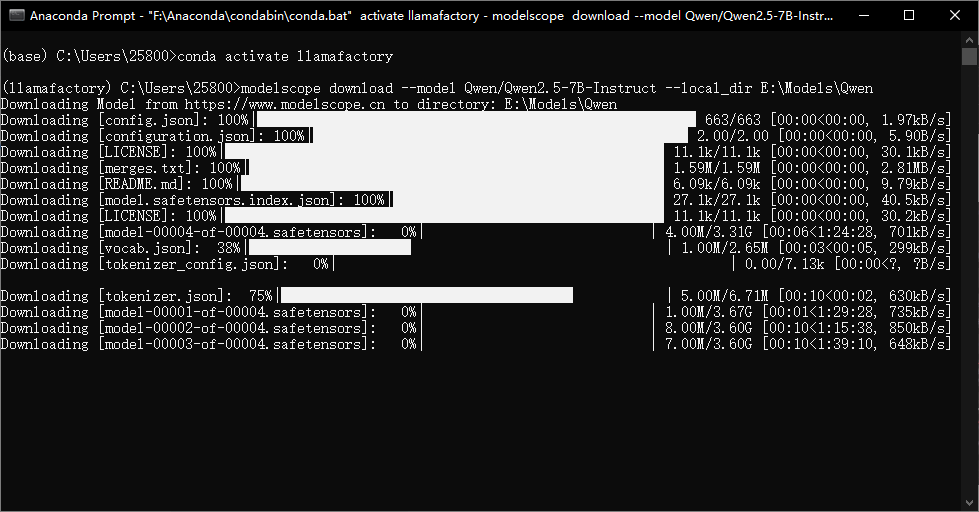
10、下载完模型后,微调模型数据集是必不可少的,LLamafactory提供了一个身份认知数据集identity.json,相关路径如下
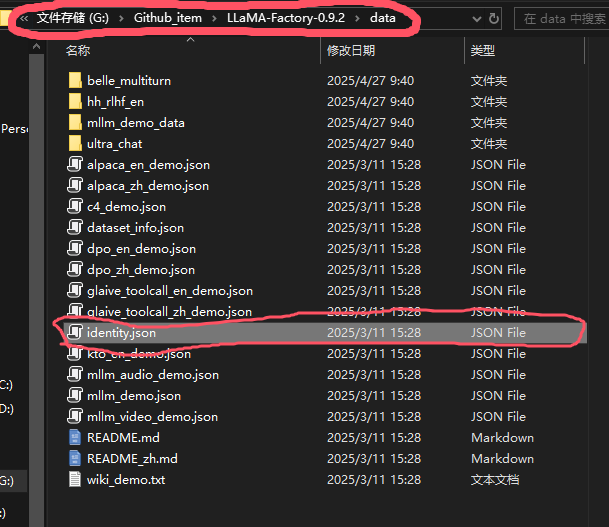
11、对该数据集提前做好备份后,使用记事本打开identity.json,该数据集identity.json遵循alpaca格式,利用ctrl+H组合键,将{{name}}替换为你给这个模型取的名字,{{author}} 替换为你自己想用的作者名字。
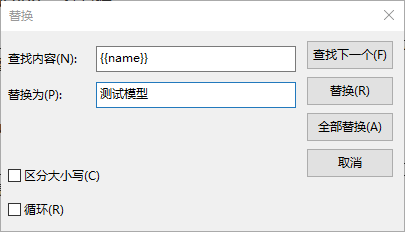
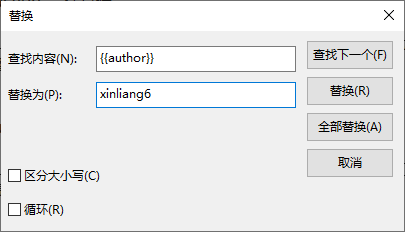
修改前数据集:

修改后数据集:

注意:你想使用自己的数据集进行微调时,一定要将数据集转换为对应格式,具体格式可以查看下面网址。
数据处理 - LLaMA Factory
12、在数据集准备好之后,我们可以选择两种方法微调,一种是LLamafactory提供的ui界面进行训练,另一种则是使用cmd命令 + yaml配置文件进行训练,这里我们选择后者,后者在Linux上也可以使用,注意需要创建一个空白yaml格式的文件。配置文件参数可以参考:SFT 训练 - LLaMA Factory
以下是我的配置文件参数,同时注意将“model_name_or_path”和“output_dir”改为你自己的路径,如果你用的不是Qwen作为基底模型,那么template需要对应的进行修改,由于我们需要改变模型自我身份的认知,所以dataset那一栏一定要选择identity的数据集,同时训练集较少所以logging_steps和save_steps较小
### modelmodel_name_or_path: E:\\graduation_design\\Qwen2.5_7B_instruct### methodstage: sftdo_train: truefinetuning_type: loralora_target: all### datasetdataset: identitytemplate: qwencutoff_len: 1024max_samples: 1000 overwrite_cache: truepreprocessing_num_workers: 16### outputoutput_dir: E:\\graduation_design\\test\\modellogging_steps: 5save_steps: 20plot_loss: trueoverwrite_output_dir: true### trainper_device_train_batch_size: 2 gradient_accumulation_steps: 2learning_rate: 2.0e-4 num_train_epochs: 2 lr_scheduler_type: cosinewarmup_ratio: 0.1 weight_decay: 0.05lora_dropout: 0.05bf16: trueddp_timeout: 180000000### validationval_size: 0.1per_device_eval_batch_size: 1eval_strategy: stepseval_steps: 500 13、在配置文件准备好后,我们开始使用命令进行训练,有两个注意的点。
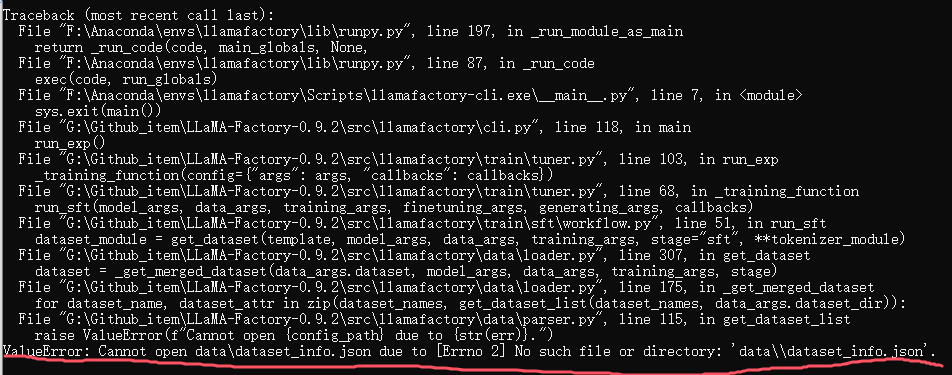
第一个:你的命令行的执行路径必须在LLamafactory目录下,因为它会寻找你当前路径下的data文件中的dataset_info.json,如图:
第二个:当你改变了命令行的执行路径后,在你使用llamafactory-cli train example.yaml ,这个example.yaml一定要使用绝对路径或者相对路径,比如我的配置文件在E:\\graduation_design\\test,那么命令就要使用:
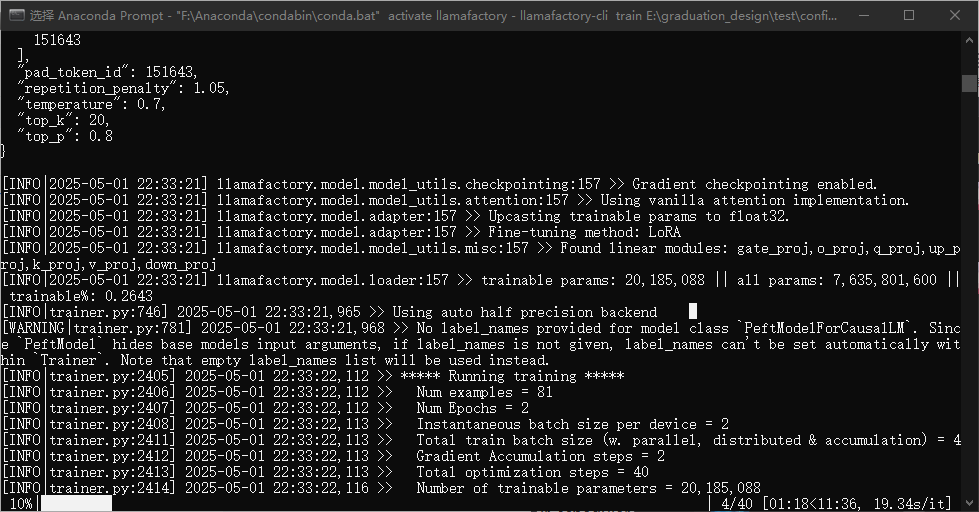
llamafactory-cli train E:\\graduation_design\\test\\config.yaml在确定路径没有问题后,训练截图如下:
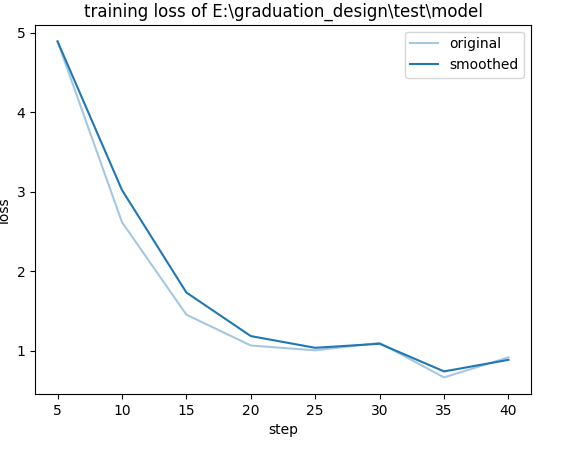
训练损失如下:
15、在模型训练完后,LLamafactory会在你的输出路径下存放adapter(适配器),adapter需要将其与模型合并后才能完成真正你想要实现的功能,模型合并我将会在量化章节中讲到现在还不需要用到,训练完成后模型文件结构如下:
16、我们可以使用LLamafactory提供的模型对话测试功能,可以不用先对模型合并,先来看看效果怎么样,这里的对话测试一样我们使用配置文件先设置参数,配置文件参数如下:
model_name_or_path: E:\\graduation_design\\Qwen2.5_7B_instructadapter_name_or_path: E:\\graduation_design\\test\\model\\checkpoint-40template: qwenfinetuning_type: lorainfer_backend: huggingface注意上面的参数中infer_backend如果你想使用vllm,只能在Linux系统中运行
17、如果在当前命令行的路径下没有该配置文件,则需要在命令中指定,LLamafactory中的所有命令都是如此,对话测试命令(使用绝对路径):
llamafactory-cli chat E:\\graduation_design\\test\\inference_config.yaml对话结果:
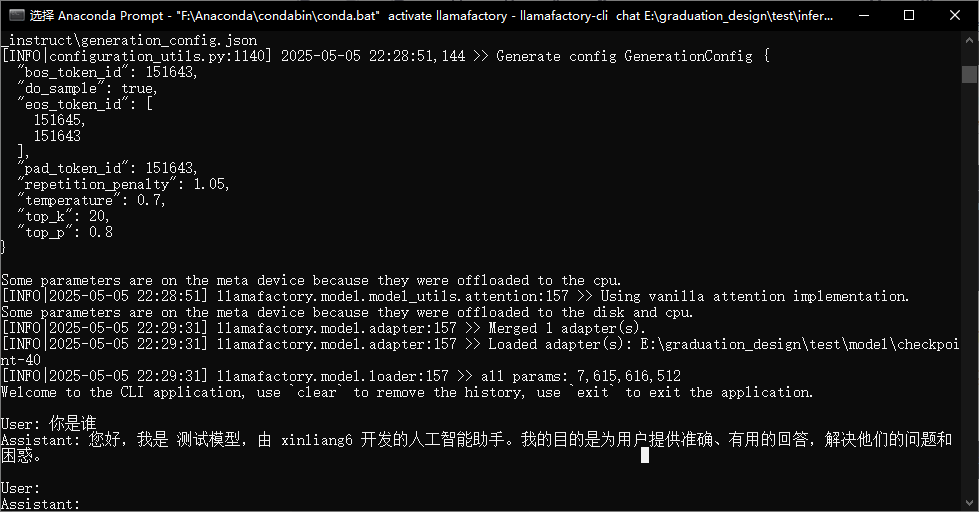
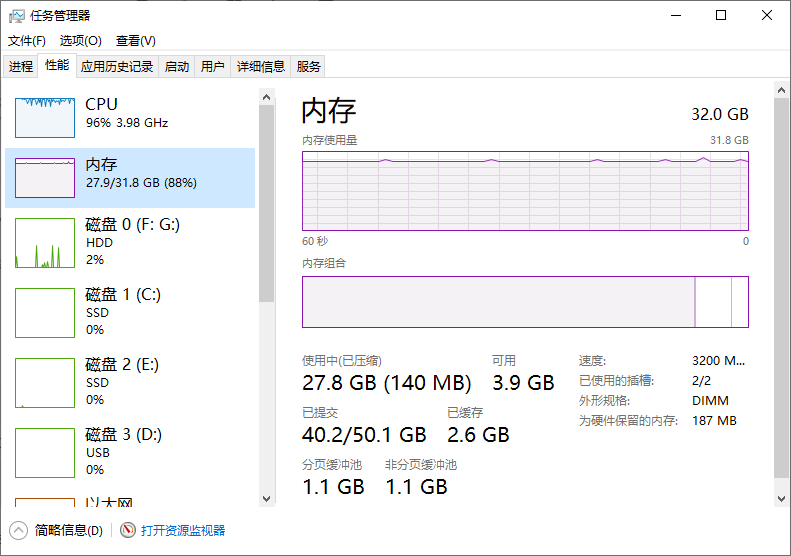
在完成上述对话测试后,我们已经完成大概60%的工作,剩下的40%为模型量化和部署。
同时最后,由于仅仅是LLamafactory提供的对话测试,所以作者没有进行硬件优化,比如利用cpu+gpu进行混合推理,可以看到下图中我们仅仅是通过内存和cpu进行推理,显卡没有发挥作用,上图推理出的一段话大概需要5-7分钟左右,量化模型后模型体积减小推理更快,同时利用ollama实现混合推理,这也就是为什么需要用到llamacpp和ollama。