计算机视觉:Transformer的轻量化与加速策略_transformer加速


计算机视觉:Transformer的轻量化与加速策略
- 一、前言
- 二、Transformer 基础概念回顾
-
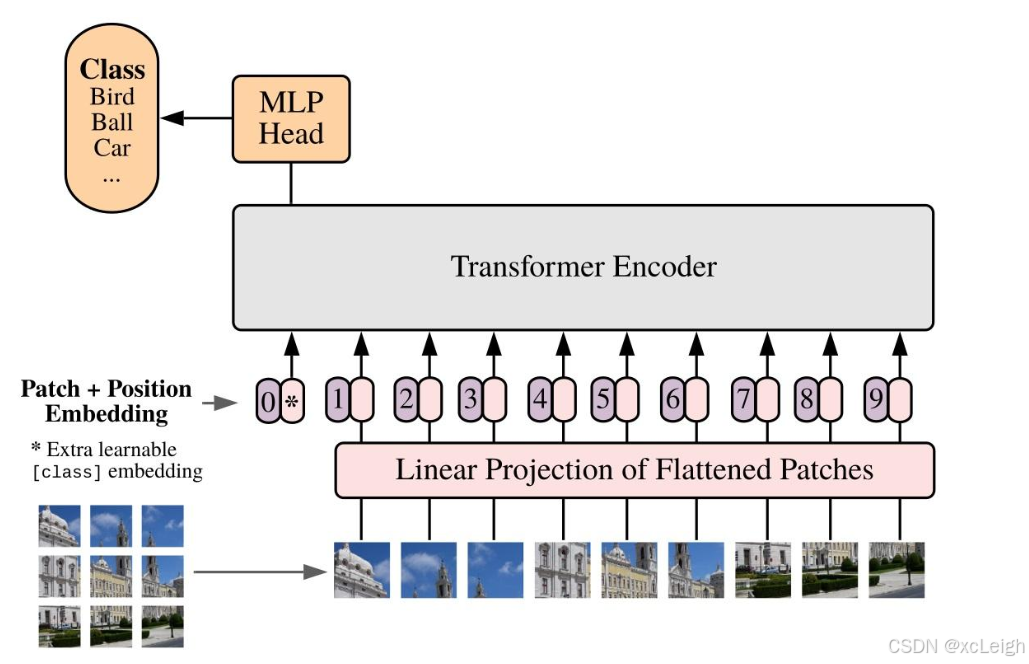
- 2.1 Transformer 架构概述
- 2.2 自注意力机制原理
- 三、Transformer 轻量化策略
-
- 3.1 模型结构优化
-
- 3.1.1 减少层数和头数
- 3.1.2 优化 Patch 大小
- 3.2 参数共享与剪枝
-
- 3.2.1 参数共享
- 3.2.2 剪枝
- 3.3 知识蒸馏
- 四、Transformer 加速策略
-
- 4.1 模型量化
-
- 4.2.2 TPU 加速
- 4.3 算法优化
-
- 4.3.1 稀疏注意力机制
- 4.3.2 快速注意力算法
- 5.1 评估指标
- 5.2 实验结果
- 六、总结与展望
- 致读者一封信
计算机视觉:Transformer的轻量化与加速策略,人工智能,计算机视觉,大模型,AI,在计算机视觉领域,Transformer 自被引入后,凭借其强大的特征建模能力,在图像分类、目标检测、语义分割等众多任务中取得了优异的成绩。然而,原始的 Transformer 模型结构复杂,参数量巨大,计算资源消耗高,导致模型训练和推理速度慢,难以部署在资源受限的设备(如移动设备、嵌入式设备)上。因此,研究 Transformer 的轻量化与加速策略成为推动其广泛应用的关键。本文将深入探讨各种轻量化与加速技术,并结合代码示例进行详细说明。
一、前言
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行


