【首款ARMv9开源芯片“星睿“O6测评】SVE2指令集介绍与测试
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
博客内容主要围绕:
5G/6G协议讲解
高级C语言讲解
Rust语言讲解
文章目录
- SVE2指令集介绍与测试
SVE2指令集介绍与测试

一、什么是SVE2
在Neon架构扩展(其指令集向量长度固定为128位)的基础上,Arm设计了可伸缩向量扩展(Scalable vector extension, SVE)。SVE是一种新的单指令多数据(SIMD)指令集,用于AArch64的扩展,支持灵活的向量长度实现。SVE提高了体系结构对需要大量数据处理的高性能计算(High Performance Computing, HPC)应用的适用性。
SVE2是SVE和Neon的超集。SVE2在数据级并行中允许更多的函数域。SVE2继承了SVE的概念、向量寄存器和工作原理。SVE和SVE2定义了32个可扩展向量寄存器。制作芯片时可以为硬件选择一个合适的矢量长度设计实现,在128位到2048位之间,以128位为增量。
SVE2和SVE的主要区别在于指令集的功能覆盖率。SVE是为高性能计算和机器学习应用而设计的。SVE2扩展了SVE指令集,除了HPC和ML还扩展了数据处理领域。SVE2指令集还可以加速以下应用程序中使用的常见算法:
- 计算机视觉;
- 多媒体;
- LTE基带处理;
- 基因组学;
- 内存数据库;
- Web服务;
- 通用软件;
为了帮助编译器更有效地对这些域进行矢量化,SVE2在大多数整数数字信号处理(DSP)和媒体处理功能中添加了矢量宽度无关的Neon指令版本。
SVE和SVE2都实现了大量数据的采集和处理函数。SVE和SVE2不是Neon指令集的扩展。相反,SVE和SVE2被重新设计,以获得比Neon更好的数据并行性。然而,SVE和SVE2的硬件逻辑覆盖在Neon硬件实现之上。当一个微架构支持SVE或SVE2时,它也支持Neon。
二、SVE2架构基础
与SVE一样,SVE2也是基于可扩展向量的。除了现有的Neon提供的寄存器组,SVE和SVE2添加了以下寄存器:
- 32个可扩展的向量寄存器,Z0~Z31;
- 16个可扩展的谓词寄存器,P0~P15;
- 一个故障谓词寄存器(FFR);
- 可扩展的向量系统控制寄存器 ZCR_Elx;
2.1 可扩展的向量寄存器 Z0~Z31
每个可伸缩向量寄存器Z0~Z31可以是128 ~ 2048位,增量为128位。底部的128位与固定128位长的NONE向量寄存器V0 ~ V31共享,如下图所示。
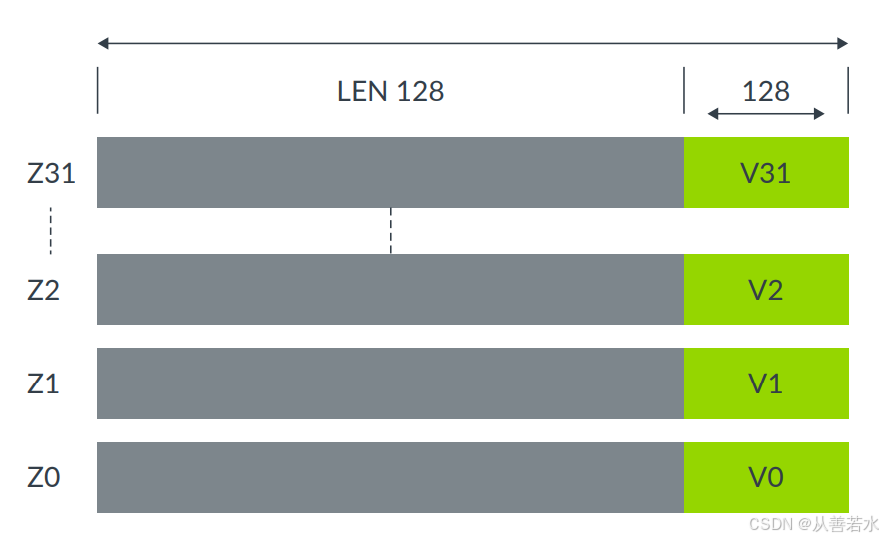
可扩展的向量可以:
- 保存64位、32位、16位和8位元素;
- 支持整数、双精度、单精度和半精度浮点元素;
- 在每个异常级别(EL)中配置向量长度;
2.2 可扩展的谓词寄存器 P0~P15
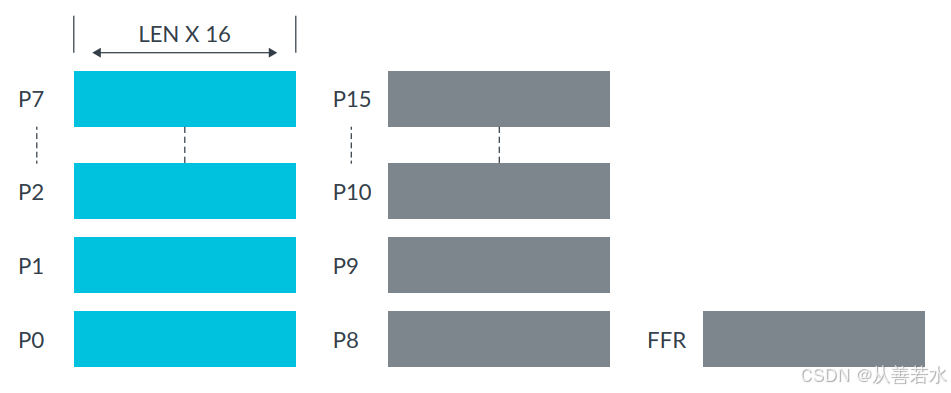
谓词寄存器通常用作数据操作的位掩码,其中:
- 每个谓词寄存器是 Zx 长度的1/8;
- P0-P7是用于加载、存储和算术的控制谓词;
- P8-P15是用于循环管理的额外谓词;
- FFR用于投机内存访问;
2.3 ZCR_Elx
可扩展的矢量系统控制寄存器指示SVE实现的特性:
- ZCR_Elx.LEN 字段用于当前和较低异常级别的向量长度;
- 目前大多数比特被保留以备将来使用。
三、查看“星睿“O6 CPU信息
输入下面的指令,查看“星睿“O6 CPU支持的指令集:
cat /proc/cpuinfo我们可以看到其支持SVE2和SVE等指令集。

四、在“星睿“O6上测试SVE2指令
要构建SVE或SVE2应用程序,必须选择支持SVE和SVE2特性的编译器。GNU tools 8.0+版本支持SVE。Arm Linux编译器18.0+版本支持SVE, 20.0+版本同时支持SVE和SVE2。GNU工具和Linux上的Arm编译器都支持优化C、C++ 、Fortran代码。LLVM(开源Clang)版本5及以上包括了对SVE的支持,版本9及以上包括了对SVE2的支持。
4.1 如何使用SVE2
有几种方法可以编写或生成SVE和SVE2代码:
编写汇编代码:可以使用SVE指令编写汇编文件,或者使用GNU风格的内联汇编;使用指令函数:可以直接调用高级语言中的指令函数,如C、C++或Fortran,它们与相应的SVE指令相匹配。这些指令函数有时被称为内联函数,在SVE的ACLE (Arm C语言扩展)中有详细介绍。内联函数是与相应指令匹配的函数,因此程序员可以直接在C、C++或Fortran等高级语言中调用它们。指令函数在编译后插入特定的指令。自动向量化:C、C++ 、Fortran编译器,例如Linux上的Arm编译器和Arm平台上的GNU编译器,可以从C、C++ 、Fortran循环生成SVE和SVE2代码。要生成SVE或SVE2代码,请为SVE或SVE2特性选择适当的编译器选项。例如,对于armclang,启用SVE2优化的一个选项是 -march=armv8-a+sve2 。如果你想使用sve版本的库,可以将 -march=armv8-a+sve2 和 -armpl=sve 结合使用;使用针对SVE和SVE2优化的库:已经有针对SVE进行了高度优化的库,例如Arm性能库和Arm计算库。Arm性能库包含BLAS、LAPACK、FFT、稀疏线性代数和libamath优化数学函数的高度优化实现。你必须安装Arm Allinea Studio并在代码中包含 armpl.h,才能链接ArmPL的任何函数。要使用Linux上的Arm编译器使用ArmPL构建应用程序,必须在命令行中指定 -armpl=。如果使用GNU工具,必须在命令行中包含ArmPL安装路径,并指定与Linux上的Arm编译器等价的GNU -armpl= 选项。
4.2 使用指令函数测试“星睿“O6 SVE2指令
#include #include #include #ifndef __ARM_FEATURE_SVE#warning \"Make sure to compile for SVE!\"#endif#define N 100int main() { // 获取SVE向量位长 uint64_t sve_bitwidth = svcntb() * 8; printf(\"SVE Vector Length: %lu bits\\n\", sve_bitwidth); // 初始化测试数据 uint32_t a[N], b[N], c[N]; for (int i = 0; i < N; i++) { a[i] = 1; b[i] = 2; c[i] = 0; } // SVE向量加法计算 uint64_t index = 0; // 当 index < N 时生成对应位宽的谓词掩码,用于向量循环的分批处理 svbool_t pg = svwhilelt_b32(index, (uint64_t)N); // 判断当前谓词掩码是否包含有效元素 while (svptest_any(svptrue_b32(), pg)) { // 加载数据 svuint32_t va = svld1(pg, &a[index]); svuint32_t vb = svld1(pg, &b[index]);// 计算加法 svuint32_t vc = svadd_z(pg, va, vb); // 存储结果 svst1(pg, &c[index], vc); // 更新index和pg index += svcntp_b32(svptrue_b32(), pg); pg = svwhilelt_b32(index, (uint64_t)N); } // 验证结果 int errors = 0; for (int i = 0; i < N; i++) { if (c[i] != 3) { printf(\"Error at index %d: got %d\\n\", i, c[i]); errors++; } } if (!errors) { printf(\"All calculations are correct!\\n\"); } return 0;}编译命令(需要支持SVE2的编译器):
gcc -march=armv9-a+sve2 -o sve_test sve_test.c功能说明:
- 使用
svcntb()获取向量寄存器字节长度,乘以8转换为位长度; - 创建两个输入数组并初始化(全1和全2);
- 使用SVE2指令进行向量加法:
svwhilelt_b32生成循环谓词;svld1加载向量数据;svadd_z执行向量加;svst1存储结果;
- 验证所有结果是否为3;
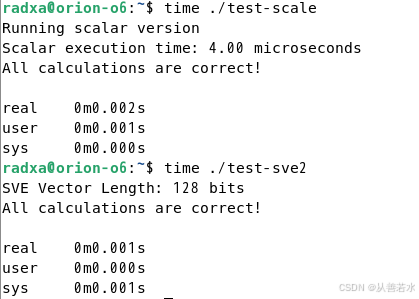
测试结果如下所示:

4.3 SVE与常规C代码的性能对比
#include #include #include #include #define N 100int main() { // 常规版本无向量长度概念 printf(\"Running scalar version\\n\"); // 初始化测试数据(与SVE版本一致) uint32_t a[N], b[N], c[N]; for (int i = 0; i < N; i++) { a[i] = 1; b[i] = 2; c[i] = 0; } // 标量加法计算 clock_t start = clock(); for (int i = 0; i < N; i++) { c[i] = a[i] + b[i]; } clock_t end = clock(); // 输出执行时间 double time_spent = (double)(end - start) / CLOCKS_PER_SEC * 1e6; printf(\"Scalar execution time: %.2f microseconds\\n\", time_spent); // 验证结果(与SVE版本一致) int errors = 0; for (int i = 0; i < N; i++) { if (c[i] != 3) { printf(\"Error at index %d: got %d\\n\", i, c[i]); errors++; } } if (!errors) { printf(\"All calculations are correct!\\n\"); } return 0;}编译命令(需要支持SVE2的编译器):
gcc -o scalar_test scalar_test.c对比测试结果如下所示:
五、总结
终于有一款开源的Armv9芯片了,想想之前为了能够学习和测试SVE指令,都是使用QEMU、Fast Models和Arm Instruction Emulator(ArmIE)模拟软件,现在终于可以甩开这些模拟软件在真实的硬件上学习测试了,真是一件激动人心的事情。


