【Hive入门】Hive行级安全:基于Apache Ranger的细粒度访问控制深度解析_hive ranger
引言
在大数据时代,数据安全与隐私保护已成为企业不可忽视的核心需求。传统表级权限控制已无法满足\"同一张表不同用户看到不同数据\"的业务场景,行级安全(Row-Level Security)成为数据仓库系统的必备能力。
1 行级安全概述
1.1 什么是行级安全?
行级安全(Row-Level Security, RLS)是一种数据访问控制机制,它允许管理员定义过滤规则,控制用户能够访问表中的哪些行数据。与传统的表级权限相比,RLS提供了更细粒度的访问控制。关键特性:
- 透明过滤:自动应用策略,用户无需修改查询
- 动态过滤:基于用户属性或环境上下文决定可见数据
- 集中管理:策略统一存储和管理
1.2 行级安全应用场景
场景
需求描述
解决方案
多租户数据隔离
不同租户只能看到自己的数据
按租户ID过滤
数据权限分级
高管看全部数据,经理看部门数据
按职位级别过滤
合规要求
GDPR要求隐藏某些敏感数据
按数据分类过滤
2 Apache Ranger架构与集成
2.1 Apache Ranger核心组件
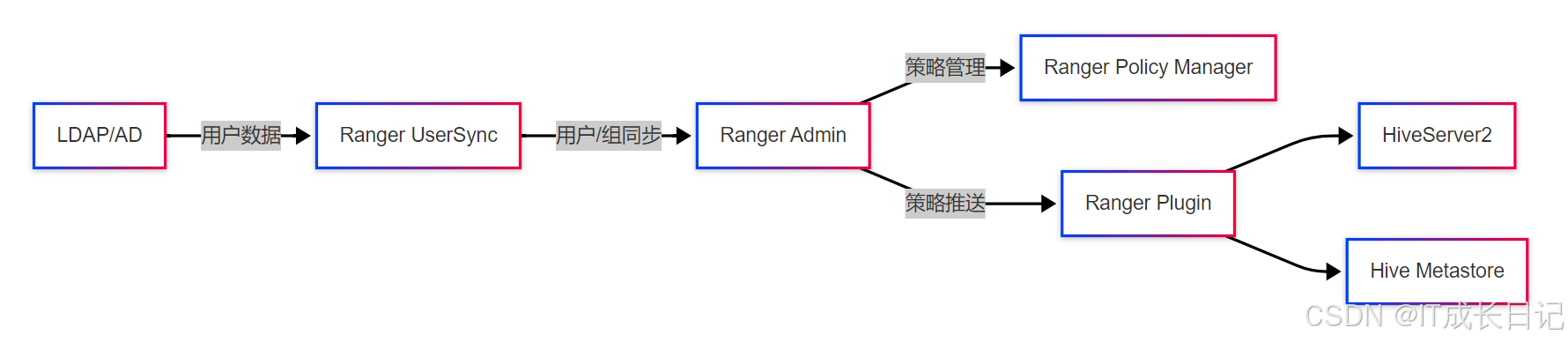
组件说明:
- Ranger Admin:策略管理和UI界面
- Ranger UserSync:从LDAP/AD同步用户和组信息
- Ranger Plugin:嵌入Hive服务的策略执行引擎
3 行级安全策略配置实战
3.1 策略配置界面解析
Ranger管理界面提供直观的策略配置:
- Resources:指定策略应用的表/列
- Conditions:定义行过滤条件
- Permissions:设置允许的操作(select/update等)

3.2 典型策略配置示例
3.2.1 部门数据隔离
- 场景:各部门只能查看本部门数据
-- 策略条件 department_id = ${USER.department}配置参数:
- 策略名:department_filter
- 资源:sales.employee_data
- 条件:department_id = ${USER.department}
- 用户组:finance_group, hr_group
3.2.2 时间敏感数据控制
- 场景:销售代表只能查看当前季度的数据
-- 策略条件 quarter = CURRENT_QUARTER()- 自定义函数:
// 注册UDFpublic class CurrentQuarterUDF extends UDF { public String evaluate() { // 实现季度计算逻辑 }}3.3 策略优先级与冲突解决
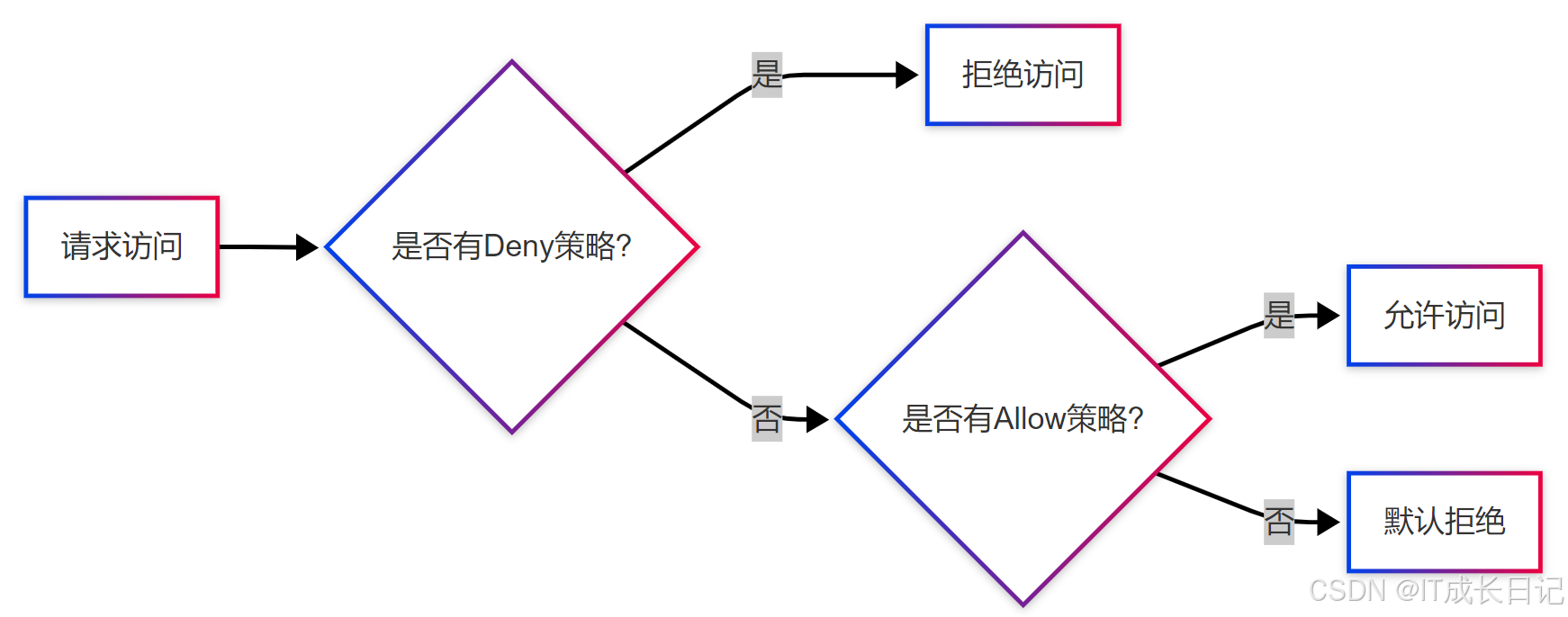
Ranger采用拒绝优先原则,策略评估顺序为:
- 显式拒绝(Deny)策略
- 显式允许(Allow)策略
- 默认拒绝(如果没有匹配策略)
4 高级行级安全特性
4.1 动态掩码(Dynamic Masking)
- 对敏感列数据根据用户权限显示不同内容:
-- 策略示例:隐藏薪资最后两位CASE WHEN user_role = \'HR\' THEN salary ELSE CONCAT(SUBSTR(salary, 1, LENGTH(salary)-2), \'\')END4.2 基于标签的访问控制(TBAC)
- 创建分类标签:
ranger-admin create-tag --name PII --desc \"Personally Identifiable Information\"- 标记资源:
ALTER TABLE customers SET TAGS (\'PII\');- 标签策略:
{ \"conditions\": \"user.department = \'compliance\'\", \"accessTypes\": [\"select\"]}4.3 审计与合规报告
Ranger提供完整的审计功能:
- 审计日志存储:Solr或RDBMS
- 关键审计字段:
- 访问时间
- 操作用户
- 访问资源
- 策略决策
- 示例:
SELECT * FROM ranger_audits WHERE resource = \'sales.employee_data\' AND access_type = \'SELECT\'ORDER BY event_time DESC LIMIT 100;5 性能优化
5.1 行级过滤性能影响
影响因素:
- 策略复杂度
- 数据量大小
- 并发查询数
优化方案:
- 谓词下推:确保过滤条件尽早执行
EXPLAIN SELECT * FROM employee WHERE department_id = \'IT\';- 分区剪枝:结合分区表设计
ALTER TABLE sales ADD PARTITION (region=\'east\');- 策略缓存:调整Ranger缓存设置
# ranger-hive-plugin/install.propertiespolicy_cache_interval=3006 总结
Apache Ranger为Hive提供了企业级的行级安全解决方案,通过灵活的策略配置可实现:
- 基于属性的数据过滤
- 动态数据掩码
- 细粒度访问审计
实施行级安全时需注意:
- 合理设计策略避免性能瓶颈
- 建立策略审查机制
- 结合数据分类和标签管理
随着数据合规要求日益严格,行级安全将成为大数据平台的标配功能,Apache Ranger作为成熟解决方案值得企业深入研究和应用。
附录:常见问题解答
Q1:行级过滤是否影响Hive查询性能?
- 避免过于复杂的条件
- 结合分区表设计
- 定期审查策略有效性
Q2:如何实现跨多表的关联查询过滤?
-- orders表策略customer_id = ${USER.managed_customers}-- customers表策略id IN (${USER.managed_customers})Q3:策略变更后多久生效?
curl -X POST http://hiveserver:port/refresh/policies
