pythonA股实时数据分析(进阶版)_pyalgotrade akshare
声明:
本篇文章仅针对公开数据进行合法爬取,不违规使用与传播
章节:
这是python项目专栏--第二期(pythonA股实时数据分析(进阶版))
前言:
本章针对A股数据分析进阶读者,以获取A股数据、茅台历史股价数据为例进行全流程数据分析,建议阅读python项目专栏--第一期(pythonA股实时数据分析)后(获取东方财富网A股数据、哪吒2背后公司光线传媒股票数据为例进行数据分析),对股票数据获取和分析有一个基础了解后,可以加深读者对python项目专栏--第二期(pythonA股实时数据分析(进阶版))的理解。
官网:https://www.akshare.xyz/ 比较全
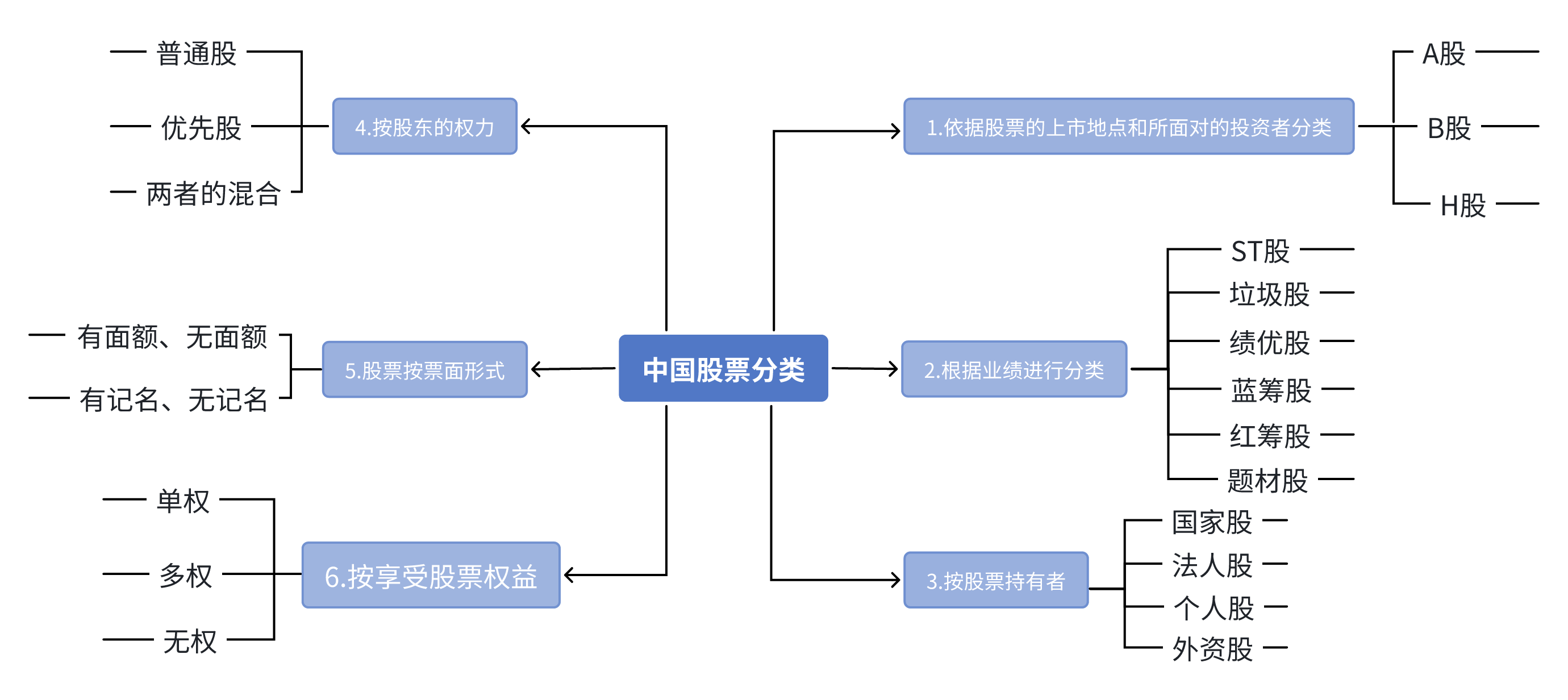
A股 ,即 人民币普通股 (https://baike.baidu.com/item/%E4%BA%BA%E6%B0%B4%E5%B8%81%E6%99%AE%E9%80%9A%E8%82%A1%E7%A5%A8/59251447?fromModule=lemma_inlink),是由中国境内注册公司发行,在境内上市,以人民币标明面值,供境内机构、组织或个人(2013年4月1日起,境内港澳台居民可开立A股账户)以人民币认购和交易的 普通股股票 (https://baike.baidu.com/item/%E6%99%AE%E9%80%9A%E8%82%A1%E8%82%A1%E7%A5%A8/2123577?fromModule=lemma_inlink)。
B股的正式名称是人民币特种股票。它是以人民币标明面值,以外币认购和买卖,在境内(上海、深圳)证券交易所上市交易的股票。
H股又称境外上市外资股,是境内上市公司在境外发行上市的股份。
一、python相关库的安装
官网:[https://www.akshare.xyz/](https://www.akshare.xyz/) 比较全
1. 要安装的模块
1.1 通用安装
pip install akshare --upgrade(切记要及时更新akshare库,否则后面通过接口获取不到数据,会报错误,如下)

注意:程序运行时,文件名、文件夹名不能是:akshare
1.2 国内安装-Python
pip install akshare -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com --upgrade
二、股票数据的获取
2.1使用历史东财行情数据
接口: stock_zh_a_hist()
目标地址:
[https://quote.eastmoney.com/concept/sh603777.html?from=classic](https://quote.eastmoney.com/concept/sh603777.html?from=classic)(示例)
描述: 东方财富-沪深京 A 股日频率数据;历史数据按日频率更新,当日收盘价请在收盘后获取
限量: 单次返回指定沪深京 A 股上市公司、指定周期和指定日期间的历史行情日频率数据
输入参数
名称
类型
描述
symbol
str
symbol=\'603777\'; 股票代码可以在 ak.stock\\_zh\\_a\\_spot\\_em() 中获取
period
str
period=\'daily\'; choice of {\'daily\', \'weekly\', \'monthly\'}
start\\_date
str
start\\_date=\'202110301\'; 开始查询的日期
end\\_date
str
end\\_date=\'20211016\'; 结束查询的日期
adjust
str
默认返回不复权的数据;qfq: 返回前复权后的数据;hfq: 返回后复权
股票数据复权
1. 为何要复权:由于股票存在配股、分拆、合并和发放股息等事件,会导致股价出现较大的缺口。若使用不复权的价格处理数据、计算各种指标,将会导致它们失去连续性,且使用不复权价格计算收益也会出现错误。为了保证数据连贯性,常通过前复权和后复权对价格序列进行调整。
2. 前复权:保持当前价格不变,将历史价格进行增减,从而使股价连续。前复权用来看盘非常方便,能一眼看出股价的历史走势,叠加各种技术指标也比较顺畅,是各种行情软件默认的复权方式。这种方法虽然很常见,但也有两个缺陷需要注意。
2.1为了保证当前价格不变,每次股票权除息,均需要重新调整历史价格,因此其历史价格是时变的。这会导致在不同时点看到的历史前复权价可能出现差异。
2.2 对于有持续分红的公司来说,前复权价可能出现负值。
3. 后复权:保证历史价格不变,在每次股票权益事件发生后,调整当前的股票价格。后复权价格和真实股票价格可能差别较大,不适合用来看盘。其优点在于,可以被看作投资者的长期财富增长曲线,反映投资者的真实收益率情况。
4.在量化投资研究中普遍采用后复权数据。
名称
类型
描述
日期
object
交易日
开盘
float64
开盘价
收盘
float64
收盘价
最高
float64
最高价
最低
float64
最低价
成交量
int64
注意单位:手
成交额
float64
注意单位:元
振幅
float64
注意单位:%
涨跌幅
float64
注意单位:%
涨跌额
float64
注意单位:元
换手率
float64
注意单位:%
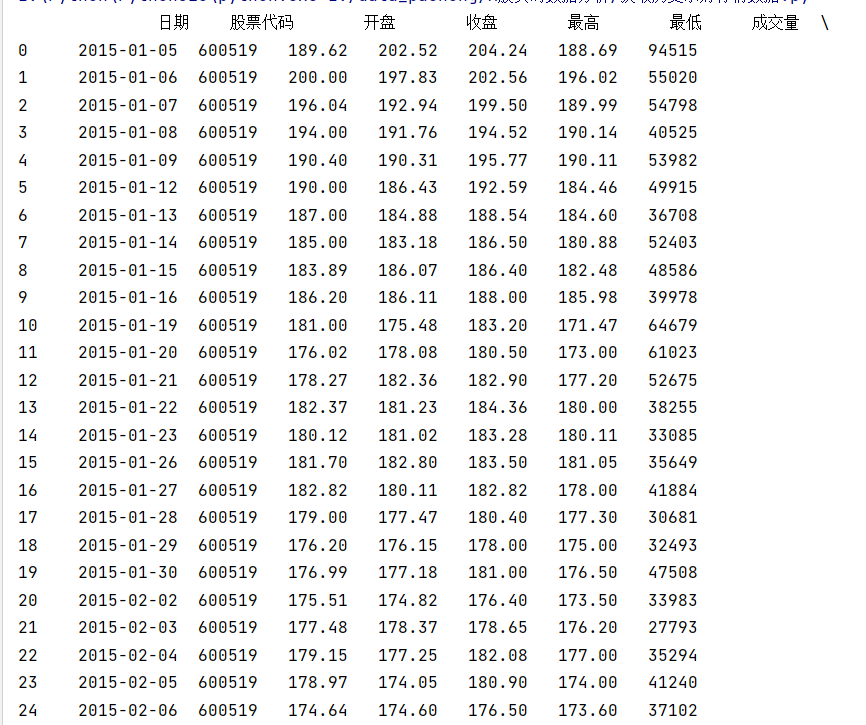
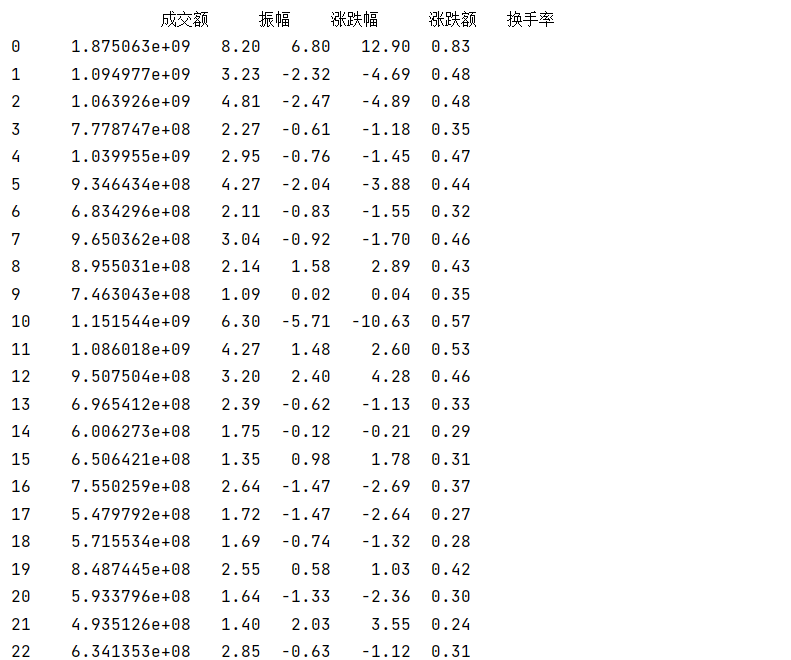
import akshare as akimport pandas as pd# 设置value的显示长度为200,默认为50pd.set_option(\'max_colwidth\', 200)# 显示所有列,把行显示设置成最大pd.set_option(\'display.max_columns\', None)# 显示所有行,把列显示设置成最大pd.set_option(\'display.max_rows\', None)# 用股票茅台股票代码貌似输出没有那么列,实际显示在最下面df = ak.stock_zh_a_hist(symbol=\"600519\", period=\"daily\", start_date=\"20150101\", end_date=\'20230425\', adjust=\"\")print(df)# 保存到本地,方便取用,而不是重新抓取# index=False保存时不要默认索引df.to_csv(\'./data.csv\', index=False) # index=False保存时不要默认索引所有列字段(全是中文显示),看上去没显示,实际在下面,往下拉:
日期 股票代码 开盘 收盘 最高 最低 成交量 成交额 振幅 涨跌幅 涨跌额换手率
pandas表格显示设置
代码
解释
pd.get_option(“display.max_rows”)
获取最大显示行数
pd.get_option(“display.max_columns”)
获取最大显示列数
pd.get_option(“display.expand_frame_repr”)
获取输出数据宽度超过设置宽度时,表示是否对其要折叠,False不折叠,True要折叠。
pd.get_option(“display.max_colwidth”)
获取单列数据宽度,以字符个数计算,超过时用省略号表示。
pd.get_option(“display.precision”)
获取设置输出数据的小数点位数。
pd.get_option(“display.width”)
获取数据显示区域的宽度,以总字符数计算。
pd.get_option(“display.show_dimensions”)
获取当数据量大需要以truncate(带引号的省略方式)显示时,该参数表示是否在最后显示数据的维数,默认 True 显示,False 不显示。
2.2 使用新浪历史行情数据
接口: stock_zh_a_daily() ---- 字段输出全是英文
P.S. 建议切换为 stock_zh_a_hist 接口使用(该接口数据质量高,访问无限制)
目标地址: [https://finance.sina.com.cn/realstock/company/sh600006/nc.shtml](https://finance.sina.com.cn/realstock/company/sh600006/nc.shtml)(示例)
描述: 新浪财经 - 沪深京 A 股的数据,历史数据按日频率更新;注意其中的 sh689009 为 CDR,请通过 ak.stock_zh_a_cdr_daily 接口获取
限量: 单次返回指定沪深京 A 股上市公司指定日期间的历史行情日频率数据,多次获取容易封禁 IP输入参数
名称
类型
描述
symbol
str
symbol=\'sh600000\'; 股票代码可以在 ak.stock_zh_a_spot 中获取
start_date
str
start_date=\'20201103\'; 开始查询的日期
end_date
str
end_date=\'20201116\'; 结束查询的日期
adjust
str
默认返回不复权的数据;qfq: 返回前复权后的数据;hfq: 返回后复权后的数据;hfq-factor: 返回后复权因子;qfq-factor: 返回前复权因子
import akshare as akimport pandas as pd# 设置value的显示长度为200,默认为50pd.set_option(\'max_colwidth\', 200)# 显示所有列,把行显示设置成最大pd.set_option(\'display.max_columns\', None)# 显示所有行,把列显示设置成最大pd.set_option(\'display.max_rows\', None)# 如果代码相同,加了市场 如这里 sz000002stock_zh_a_daily_qfq_df = ak.stock_zh_a_daily(symbol=\"sz000002\", start_date=\"20201103\", end_date=\"20221116\", adjust=\"qfq\")print(stock_zh_a_daily_qfq_df)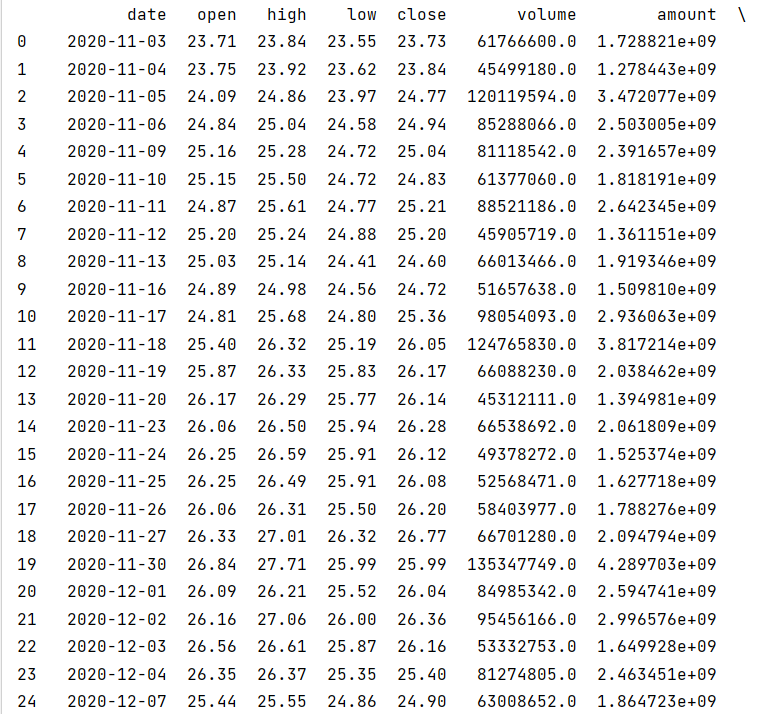

接口实例-前复权因子
import akshare as akimport pandas as pd# 设置value的显示长度为200,默认为50pd.set_option(\'max_colwidth\', 200)# 显示所有列,把行显示设置成最大pd.set_option(\'display.max_columns\', None)# 显示所有行,把列显示设置成最大pd.set_option(\'display.max_rows\', None)# 如果代码相同,加了市场 如这里 sz000002stock_zh_a_daily_qfq_df = ak.stock_zh_a_daily(symbol=\"sz000002\", start_date=\"20201103\", end_date=\"20221116\", adjust=\"qfq\")# print(stock_zh_a_daily_qfq_df)# 接口示例-复权因子qfq_factor_df = ak.stock_zh_a_daily(symbol=\"sz000002\", adjust=\"qfq-factor\") # qfq 前复权print(qfq_factor_df)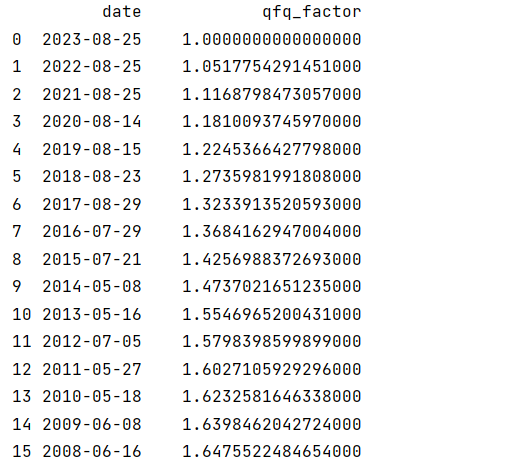
2.3 所有股票实时行情数据
实时行情数据 - 东财
沪深京 A 股
接口:stock_zh_a_spot_em
目标地址:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
没有输入参数
import akshare as akimport pandas as pd# 设置value的显示长度为200,默认为50pd.set_option(\'max_colwidth\', 200)# 显示所有列,把行显示设置成最大pd.set_option(\'display.max_columns\', None)# 显示所有行,把列显示设置成最大pd.set_option(\'display.max_rows\', None)stock_zh_a_spot_em_df = ak.stock_zh_a_spot_em()print(stock_zh_a_spot_em_df)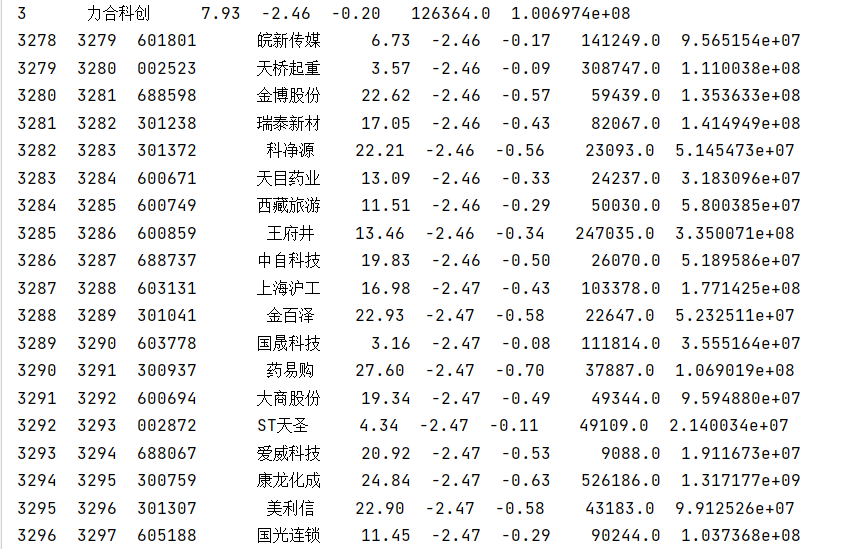
三、数据归一化
方法一:手动归一化
import pandas as pd# 设置value的显示长度为200,默认为50pd.set_option(\'max_colwidth\', 200)# 显示所有列,把行显示设置成最大pd.set_option(\'display.max_columns\', None)# 显示所有行,把列显示设置成最大pd.set_option(\'display.max_rows\', None)# 1. 读取文件# index_col=0 设置为索引列 parse_dates=True 没有指定列时,表示将尝试解析 index 为日期格式# parse_dates=[0,1,2,3,4] :尝试解析 0,1,2,3,4 列为时间格式;# parse_dates=[[‘考试日期’,‘考试时间’]] :传入多列名,尝试将其解析并且拼接起来,parse_dates[[0,1,2]] 也有同样的效果df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 2. 归一化# 归一化前必须把日期列设置为索引列,不然取数时,日期列的数据就丢失了# 没有取日期列进行归一化,但设置为了索引,既做了不做归一化又不丢失数据df = df[[\'开盘\',\'收盘\',\'最高\',\'最低\',\'成交额\']]# 数据归一化df_min_max = (df - df.min()) / (df.max() - df.min())print(df_min_max)# 打印头部df.head()print(df.head())方法二:用模块进行归一化
import pandas as pdfrom sklearn.preprocessing import MinMaxScaler# 设置显示选项pd.set_option(\'max_colwidth\', 200)pd.set_option(\'display.max_columns\', None)pd.set_option(\'display.max_rows\', None)# 1. 读取文件并设置索引df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 2. 选择需要的数值列numeric_cols = [\'开盘\', \'收盘\', \'最高\', \'最低\', \'成交额\']df = df[numeric_cols]# 3. 使用MinMaxScaler进行归一化scaler = MinMaxScaler(feature_range=(0, 1))# 创建归一化后的DataFrame(保留原始索引)normalized_data = scaler.fit_transform(df)df_normalized = pd.DataFrame(normalized_data, columns=df.columns, index=df.index) # 关键:保留日期索引# 4. 查看结果print(\"归一化后的数据:\")print(df_normalized.head())# 5. 验证数据类型print(\"\\n索引类型:\", type(df_normalized.index))print(\"前五行索引值:\", df_normalized.index[:5])四、基本可视化
4.1时间序列小分析
收盘价平均移动可视化分析----归一化前绘制,因为我们要看真实股价
import plotly.graph_objects as goimport pandas as pdfrom plotly.offline import plotimport plotly.io as piopio.renderers.default = \'browser\' # 强制在浏览器中打开# 设置显示选项pd.set_option(\'max_colwidth\', 200)pd.set_option(\'display.max_columns\', None)pd.set_option(\'display.max_rows\', None)# 1. 读取文件并设置索引df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 2. 选择需要的数值列df = df[[\'开盘\',\'收盘\',\'最高\',\'最低\',\'成交额\']]# 3. 准备数据x_index = df.index.tolist()# 计算移动平均线close_5roll = df[\'收盘\'].rolling(window=5).mean()close_10roll = df[\'收盘\'].rolling(window=10).mean()close_20roll = df[\'收盘\'].rolling(window=20).mean()close_30roll = df[\'收盘\'].rolling(window=30).mean()# 4. 创建图表fig = go.Figure()# 添加收盘价线fig.add_trace(go.Scatter(x=x_index, y=df[\'收盘\'], mode=\'lines\', name=\'收盘价\', line=dict(color=\'black\', width=1.5)))# 添加均线fig.add_trace(go.Scatter(x=x_index, y=close_5roll, mode=\'lines\', name=\'5日均线\', line=dict(color=\'blue\', width=1.5)))fig.add_trace(go.Scatter(x=x_index, y=close_10roll, mode=\'lines\', name=\'10日均线\', line=dict(color=\'green\', width=1.5)))fig.add_trace(go.Scatter(x=x_index, y=close_20roll, mode=\'lines\', name=\'20日均线\', line=dict(color=\'orange\', width=1.5)))fig.add_trace(go.Scatter(x=x_index, y=close_30roll, mode=\'lines\', name=\'30日均线\', line=dict(color=\'red\', width=1.5)))# 5. 设置图表布局fig.update_layout( title=\'收盘价移动平均值\', xaxis_title=\'日期\', yaxis_title=\'价格\', hovermode=\'x unified\', legend=dict( orientation=\'h\', yanchor=\'bottom\', y=1.02, xanchor=\'right\', x=1 ), template=\'plotly_white\', height=800 # 增加高度)# 6. 添加网格线和交互功能fig.update_xaxes( showgrid=True, gridwidth=1, gridcolor=\'LightGrey\', rangeslider_visible=True)fig.update_yaxes( showgrid=True, gridwidth=1, gridcolor=\'LightGrey\')# 7. 保存并在浏览器中打开plot(fig, filename=\'stock_chart.html\', auto_open=True)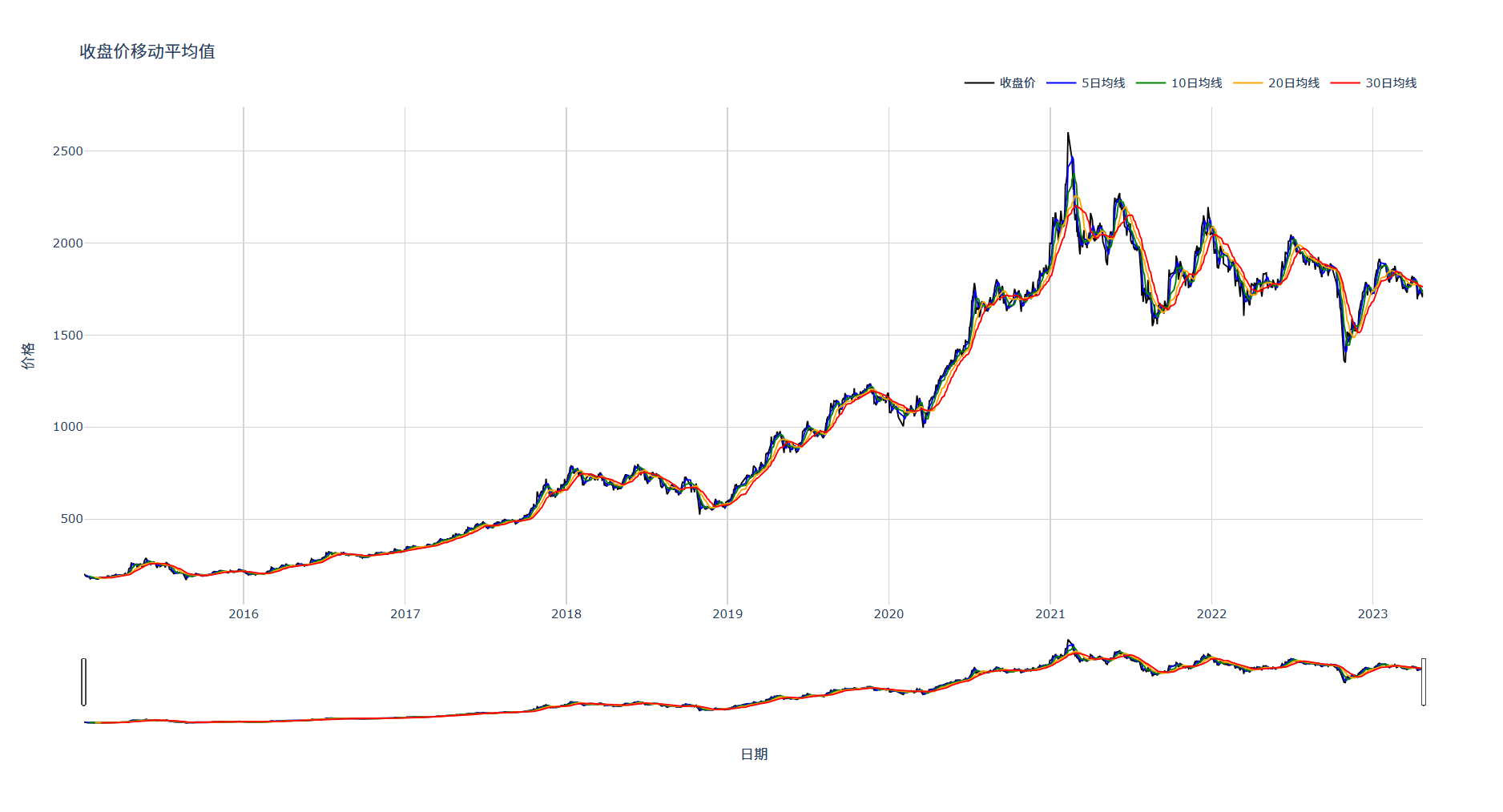
4.2绘制所有4个价格价格走势图
# 在导入 matplotlib 之前设置正确的后端import matplotlibmatplotlib.use(\'TkAgg\') # 使用 Tkinter 后端,这是最常用的桌面后端import matplotlib.pyplot as pltplt.rcParams[\'font.size\'] = 15plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 设置中文字体import pandas as pd# 设置显示选项pd.set_option(\'max_colwidth\', 200)pd.set_option(\'display.max_columns\', None)pd.set_option(\'display.max_rows\', None)# 1. 读取文件df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 2. 选择需要的数值列df = df[[\'开盘\',\'收盘\',\'最高\',\'最低\',\'成交额\']]# 3. 创建图表plt.figure(figsize=(15, 8))# 绘制四条价格线plt.plot(df.index, df[\'开盘\'], label=\'开盘价\', linewidth=2)plt.plot(df.index, df[\'收盘\'], label=\'收盘价\', linewidth=2)plt.plot(df.index, df[\'最高\'], label=\'最高价\', linewidth=2)plt.plot(df.index, df[\'最低\'], label=\'最低价\', linewidth=2)# 添加标题和标签plt.title(\'股价走势图\', fontsize=18)plt.xlabel(\'日期\', fontsize=15)plt.ylabel(\'价格\', fontsize=15)# 添加图例plt.legend(loc=\'best\', fontsize=12)# 添加网格plt.grid(True, linestyle=\'--\', alpha=0.7)# 自动调整日期格式plt.gcf().autofmt_xdate()# 显示图形plt.tight_layout()plt.show()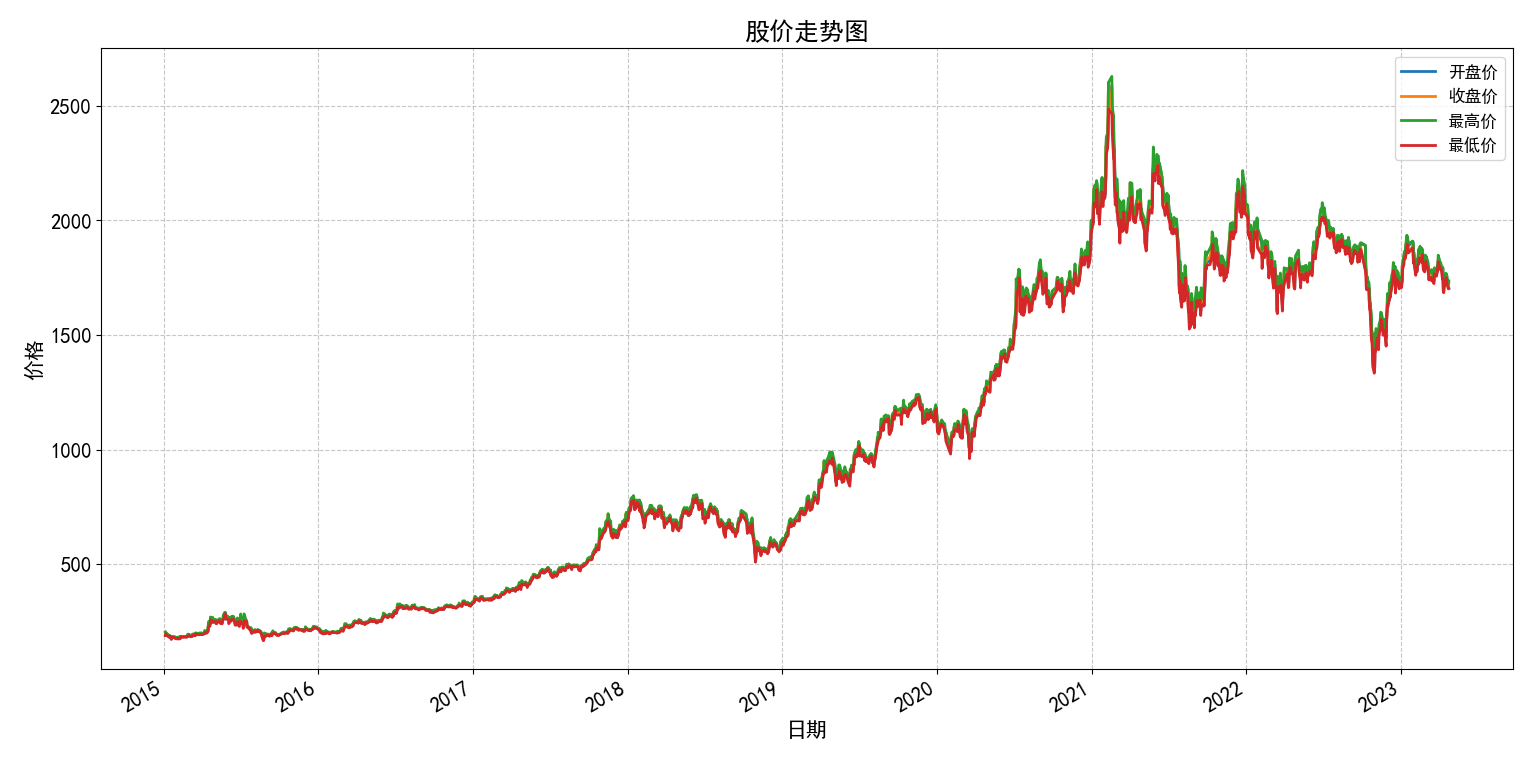
如果希望把成交额也绘制上去,则需要使用归一化后的数据,因为成交额和股票价格不在一个量级上
import pandas as pdimport matplotlibmatplotlib.use(\'TkAgg\') # 使用 Tkinter 后端,这是最常用的桌面后端import matplotlib.pyplot as plt# 设置中文显示plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 使用黑体显示中文plt.rcParams[\'axes.unicode_minus\'] = False # 正确显示负号# 设置显示选项pd.set_option(\'max_colwidth\', 200)pd.set_option(\'display.max_columns\', None)pd.set_option(\'display.max_rows\', None)# 1. 读取文件(请替换为实际文件路径)file_path = r\'E:\\data_pachong\\A股实时数据分析\\data.csv\'df = pd.read_csv(file_path, index_col=0, parse_dates=True)# 2. 选择需要的数值列df = df[[\'开盘\', \'收盘\', \'最高\', \'最低\', \'成交额\']]# 3. 数据归一化(将各列缩放到0-1范围)df_min_max = (df - df.min()) / (df.max() - df.min())# 4. 创建图表plt.figure(figsize=(15, 8))# 绘制五条归一化后的数据线plt.plot(df_min_max.index, df_min_max[\'开盘\'], label=\'开盘价\', linewidth=2)plt.plot(df_min_max.index, df_min_max[\'收盘\'], label=\'收盘价\', linewidth=2)plt.plot(df_min_max.index, df_min_max[\'最高\'], label=\'最高价\', linewidth=2)plt.plot(df_min_max.index, df_min_max[\'最低\'], label=\'最低价\', linewidth=2)plt.plot(df_min_max.index, df_min_max[\'成交额\'], label=\'成交额(归一化)\', linewidth=2, linestyle=\'--\')# 添加标题和标签plt.title(\'股票价格与成交额走势图(归一化)\', fontsize=18)plt.xlabel(\'日期\', fontsize=15)plt.ylabel(\'归一化值\', fontsize=15)# 添加图例plt.legend(loc=\'best\', fontsize=12)# 设置Y轴范围plt.ylim(-0.05, 1.05)# 添加网格plt.grid(True, linestyle=\'--\', alpha=0.7)# 自动调整日期格式plt.gcf().autofmt_xdate()# 显示图形plt.tight_layout()plt.show()# 可选:保存图片# plt.savefig(\'stock_price_volume.png\', dpi=300, bbox_inches=\'tight\')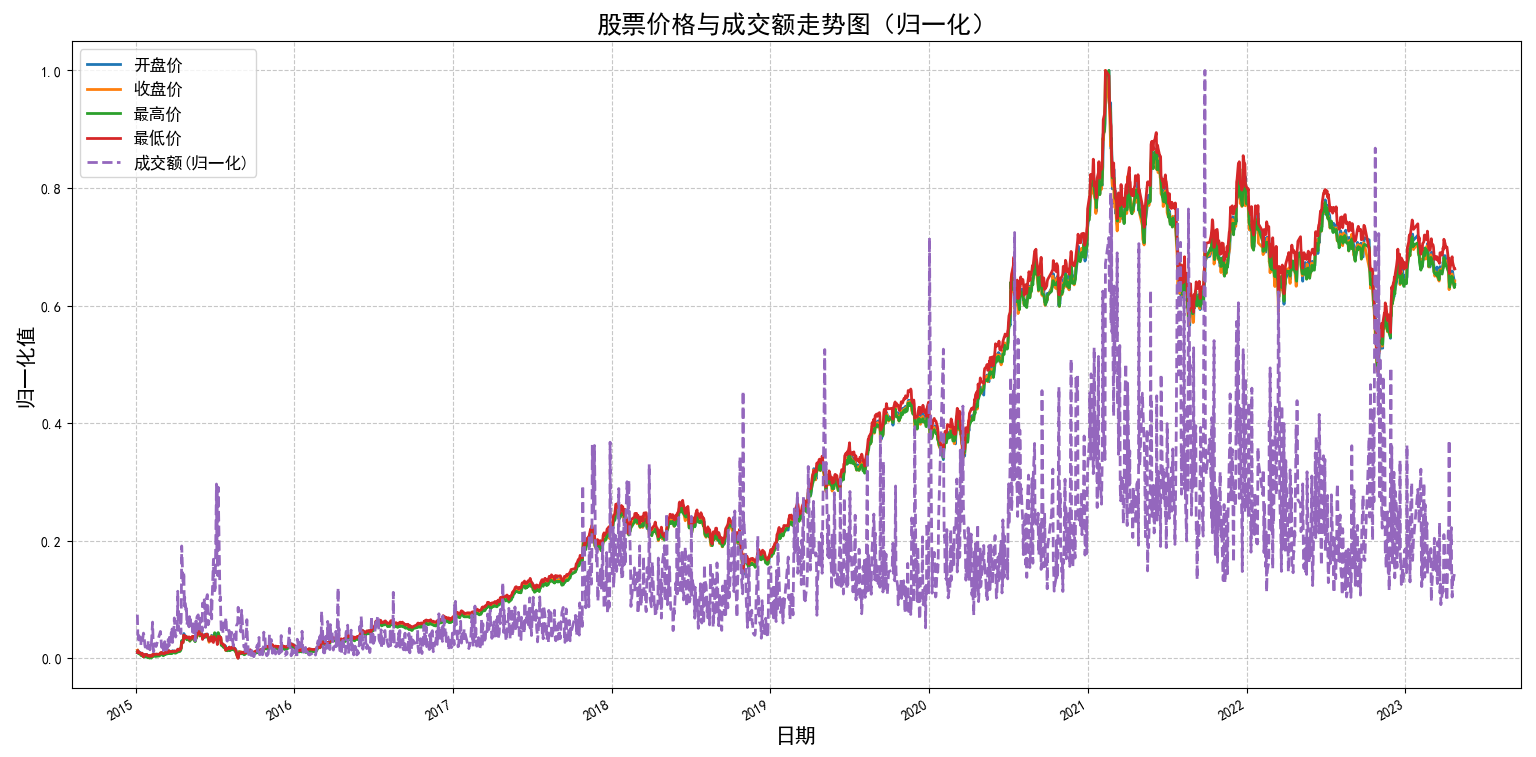
4.3股票收盘价格走势
股票收盘价走势图,加上最高点和最低点标注。有点麻烦,主要是把日期转
主要是`argmin(close)`获取到是位置索引,而匹配不出标签索引,但我们画图是用标签索引即日期作为横轴来绘制图形的;解决办法就是再通过位置索引取值,`df[\'收盘\'].index`获取标签索引列表,再索引取值。
import numpy as npimport pandas as pdimport matplotlibmatplotlib.use(\'TkAgg\') # 使用 Tkinter 后端,这是最常用的桌面后端import matplotlib.pyplot as plt# 设置value的显示长度为200,默认为50pd.set_option(\'max_colwidth\', 200)# 显示所有列,把行显示设置成最大pd.set_option(\'display.max_columns\', None)# 显示所有行,把列显示设置成最大pd.set_option(\'display.max_rows\', None)# 1. 读取文件# index_col=0 设置为索引列 parse_dates=True 没有指定列时,表示将尝试解析 index 为日期格式# parse_dates=[0,1,2,3,4] :尝试解析 0,1,2,3,4 列为时间格式;# parse_dates=[[‘考试日期’,‘考试时间’]] :传入多列名,尝试将其解析并且拼接起来,parse_dates[[0,1,2]] 也有同样的效果df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 设置画布大小plt.subplots(figsize = (9,4))# 设置图表风格plt.style.use(\'fivethirtyeight\')close = df[\'收盘\']# 获取收盘价最小值对应的索引# close_min = np.argmin(close)# 因为返回的是位置索引,绘制图形时横轴用的日期,为标签索引,所以在获取位置索引,还要通过索引找到对应日期close_min = df.index[np.argmin(close)] # 通过最大值的索引,取对应最大值的日期索引# 获取收盘价最大值对应的索引# close_max = np.argmax(close)close_max = df.index[np.argmax(close)]# 设置标注的内容信息show_min = \'[\'+str(close_min)+\' \'+str(close[close_min])+\']\'show_max = \'[\'+str(close_max)+\' \'+str(close[close_max])+\']\'# 绘制股票收盘价格走势图plt.plot(df[\'收盘\'])# 标注最低点plt.annotate(show_min,xy=(close_min,close.loc[close_min]),xytext=(close_min,close.loc[close_min]),arrowprops=dict(facecolor=\'green\'))# 标注最高点plt.annotate(show_max,xy=(close_max,close.loc[close_max]),xytext=(close_max,close.loc[close_max]),arrowprops=dict(facecolor=\'red\'))# 显示图表plt.show()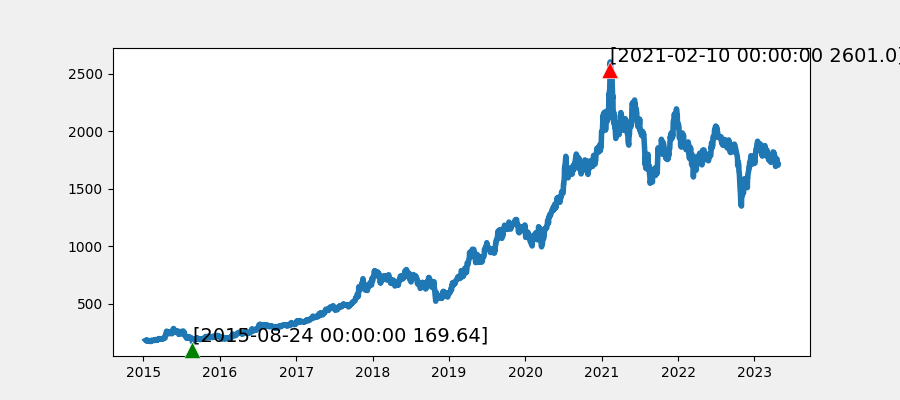
# close_min = close_min.strftime(\"%Y-%m-%d\")
# close_max = close_max.strftime(\"%Y-%m-%d\")
这能转成这样,去掉日期后面的 00 会报错
但上面进行修改优化,返回最大值的索引改用`idmax()`更方便,并在显示信息里`show_max`、`show_min`的日期转成了只有年月日的日期,其他不变。
import numpy as npimport pandas as pdimport matplotlibmatplotlib.use(\'TkAgg\')import matplotlib.pyplot as plt# 设置显示选项pd.set_option(\'max_colwidth\', 200)pd.set_option(\'display.max_columns\', None)pd.set_option(\'display.max_rows\', None)# 1. 读取文件df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 设置画布大小plt.figure(figsize=(9, 4))# 设置图表风格plt.style.use(\'fivethirtyeight\')# 获取收盘价数据close = df[\'收盘\']# 使用 idxmin() 和 idxmax() 获取极值点日期close_min_date = close.idxmin() # 最低点日期close_max_date = close.idxmax() # 最高点日期# 获取对应的收盘价close_min_value = close.loc[close_min_date]close_max_value = close.loc[close_max_date]# 格式化日期(去掉时间部分)min_date_str = close_min_date.strftime(\"%Y-%m-%d\")max_date_str = close_max_date.strftime(\"%Y-%m-%d\")# 设置标注文本show_min = f\'最低点 [{min_date_str}]\\n{close_min_value:.2f}\'show_max = f\'最高点 [{max_date_str}]\\n{close_max_value:.2f}\'# 绘制股票收盘价格走势图plt.plot(close, label=\'收盘价\', linewidth=1.5)# 标注最低点 - 绿色箭头plt.annotate(show_min, xy=(close_min_date, close_min_value), xytext=(close_min_date, close_min_value - (close.max() - close.min()) * 0.1), arrowprops=dict(facecolor=\'green\', shrink=0.05, width=1.5, headwidth=8), ha=\'center\', va=\'top\', bbox=dict(boxstyle=\"round,pad=0.3\", fc=\"white\", ec=\"green\", alpha=0.8))# 标注最高点 - 红色箭头plt.annotate(show_max, xy=(close_max_date, close_max_value), xytext=(close_max_date, close_max_value + (close.max() - close.min()) * 0.1), arrowprops=dict(facecolor=\'red\', shrink=0.05, width=1.5, headwidth=8), ha=\'center\', va=\'bottom\', bbox=dict(boxstyle=\"round,pad=0.3\", fc=\"white\", ec=\"red\", alpha=0.8))# 添加标题和标签plt.title(\'股票收盘价走势图\', fontsize=14, fontweight=\'bold\')plt.xlabel(\'日期\', fontsize=10)plt.ylabel(\'收盘价\', fontsize=10)# 添加网格plt.grid(True, linestyle=\'--\', alpha=0.7)# 自动调整日期格式plt.gcf().autofmt_xdate()# 显示图例plt.legend(loc=\'best\', fontsize=9)# 显示图表plt.tight_layout()plt.show()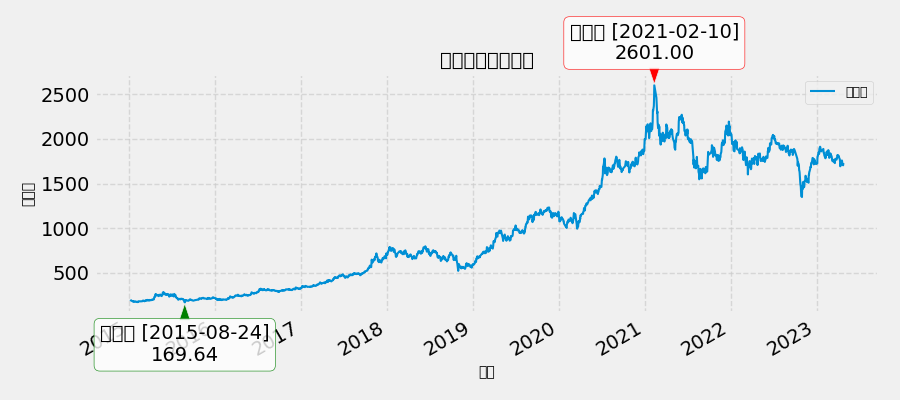
4.4股票涨跌分析图
股票涨跌情况分析主要分析收盘价,收盘价的分析常常是基于股票收益率的。股票收益率又可以分为简单收益率和对数收益率。
简单收益率:是指相邻两个价格之间的变化率;
对数收益率:是指所有价格取对数后两两之间的差值;
使用直接从表读取的数据 df
# 股票涨跌分析import numpy as npimport pandas as pdimport matplotlibmatplotlib.use(\'TkAgg\')import matplotlib.pyplot as pltplt.rcParams[\'font.family\'] = [\'SimHei\'] # 设置中文字体plt.rcParams[\'axes.unicode_minus\'] = False # 解决负号显示问题# 根据索引切片,抽取指定日期范围内的收盘价数据df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)mydata = df[\'2022-01-01\':\'2022-12-31\']mydata_close = mydata[\'收盘\']# 对数收益率 = 当日收盘价取对数 - 昨日收盘价取对数# shift(1) 向下移动一个单位,按索引trade_date对应位置进行相减log_change = np.log(mydata_close) - np.log(mydata_close.shift(1))# 绘图plt.figure(figsize=(10, 4))plt.plot(log_change)# 绘制水平分割线,标记股票收盘价相对于y=0的偏离程度plt.axhline(y=0, color=\'purple\', linestyle=\'--\', alpha=0.5, linewidth=2)plt.ylabel(\'对数收益率\')plt.show()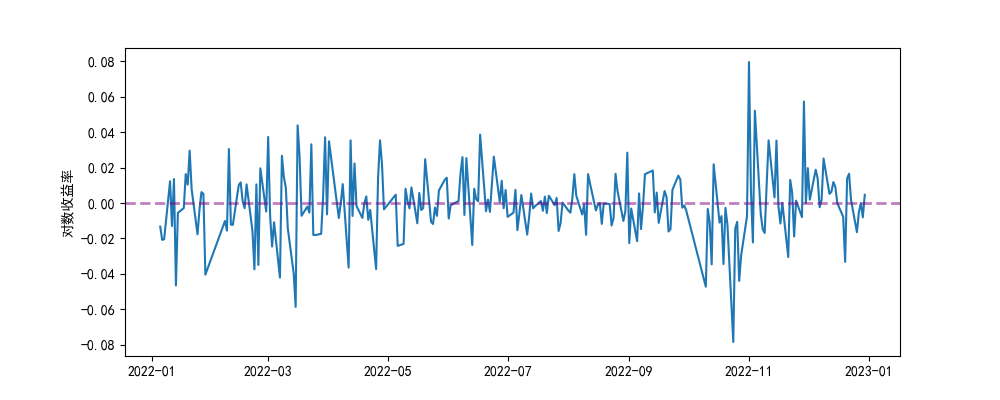
以水平分割线为基准,值在上面表示今天相对于昨天股票涨了,值在下面表示今天相对于昨天股票跌了。
4.5股票K线走势图
在 Python 中,主要使用 mplfinance 模块绘制 k 线图,具体步骤如下:
1. 抽取 “最高价”“收盘价”“开盘价”“最低价” 和 “成交量” 数据;
2. 抽取指定日期范围内的数据;
3. 自定义颜色和图表样式;
4. 绘制 k 线图。
import mplfinance as mpfimport numpy as npimport pandas as pdimport matplotlibmatplotlib.use(\'TkAgg\')import matplotlib.pyplot as pltplt.rcParams[\'font.family\'] = [\'SimHei\'] # 设置中文字体plt.rcParams[\'axes.unicode_minus\'] = False # 解决负号显示问题# 根据索引切片,抽取指定日期范围内的收盘价数据df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)mydata = df[\'2022-01-01\':\'2022-12-31\']# 把成交量列\'vol\'改为\'volume\',因为后面绘图默认的是volume名;因为是中文,全部改为英文mydata.rename(columns={\'成交量\':\'volume\',\'开盘\':\'open\',\'收盘\':\'close\',\'最高\':\'high\',\'最低\':\'low\'}, inplace=True)# 绘制K线图# 自定义颜色mc = mpf.make_marketcolors( up=\'red\', # 上涨K线柱子的颜色为“红色” down=\'green\',# 下跌K线柱子的颜色为“绿色” edge=\'i\', # K线图柱子边缘的颜色(i代表继承自up和down的颜色),下同 volume=\'i\', # 成交量直方图的颜色 wick=\'i\' # 上下影线的颜色)# 调用make_mpf_style()函数,自定义k线图样式mystrle = mpf.make_mpf_style(base_mpl_style=\'ggplot\', marketcolors=mc)# 自定义样式mystrle# 显示成交量# 添加移动平均线mav(5、10、20日的平均线)# tight_layout=True 紧密布局# update_width_config 蜡烛宽度设置# figratio 设置图片大小参数,用plt.figure()无效mpf.plot( mydata, type=\'candle\', style=mystrle, volume=True, mav=(5, 10, 20), tight_layout=True, update_width_config=dict(candle_linewidth=1.75, line_width=0.7), figratio=(20, 10))plt.show()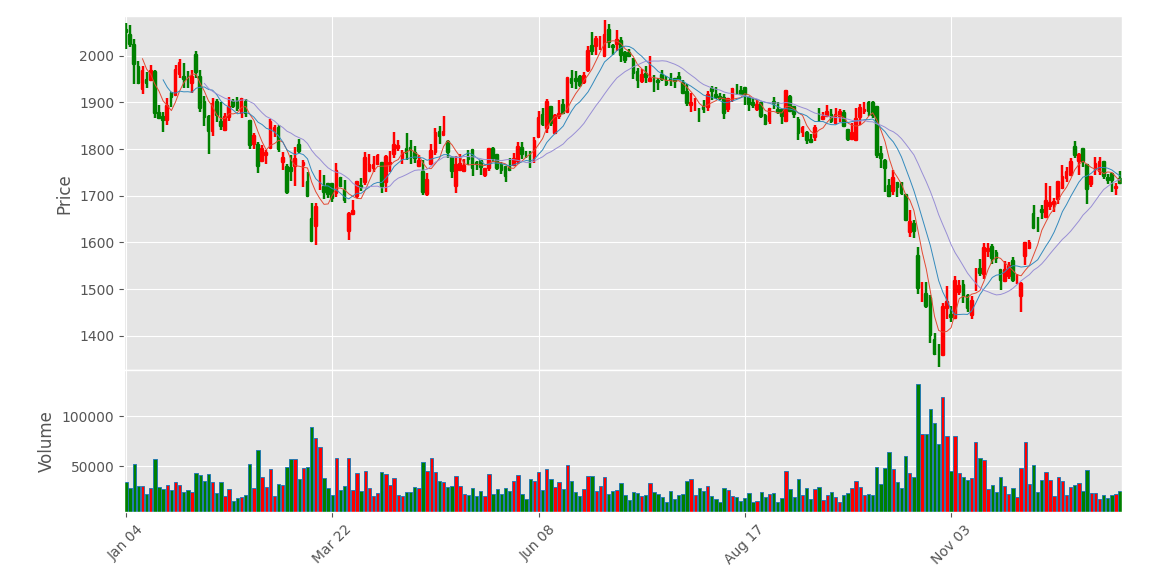
参数详细说明:
mpf.plot(data, type, title, ylabel, style, volume, ylabel_lower, show_nontrading, figratio, mav)`
其中:
data 为一个 DataFrame 对象,要保证其有 Open、High、Low、Close 四个列。且行索引的名称必须是 \'Date\',此外还有一列是 \'Volume\',这一列不是必须的(如果要同时绘制成量柱状图,则还需要该列名为 Volume 的列。)
type为绘制图线的类型,可以的选择有 \'ohlc\'、\'candle\'(蜡烛图)、\'line\'(直线,仅绘制收盘价时序图时用)、\'renko\'、\'pnf\'。
title即图片标题
ylabel:纵轴的标签
风格(style):这是我认为最赞的两个参数之一(另一个是 mav,直接绘出均线,下边有介绍)。`mplfinance` 提供了很多内置样式,如下:
`binance`,
`blueskies`,
`brasil`,
`charles`,
`checkers`,
`classic`,
`default`,
`mike`,
`nightclouds`,
`sas`,
`starsandstripes`,
`yahoo`
可以逐个尝试,从而找出自己喜欢的风格,这里不再一一列举。当然也可以自己定义风格样式。
例如:
例如:python
mpf.plot(mydate, type=\'candle\', style=\'yahoo\')
volume:True 表示添加成交量,默认 False。
ylabel_lower:成交量的 Y 轴标签。
show_nontrading:True 显示非交易日,默认 False。(这个一般不常用。)
figratio:控制图表大小的元组,用于调整图表大小;
例如:mpf.plot(mydate, type=\'candle\', style=mystyle, volume=True, figratio=(3, 2))
mav:整数或包含整数的元组,是否在图表中添加移动平均线。例如 mav=(5, 10) 表示添加 5 日均线和 10 日均线。
savefig:如果要保存生成的图片,则加入 savefig`参数,参数值为要保存的路径 + 文件名。
股票数据太多,显示问题,可以用 resample() 重采样。在上面代码最终绘制前进行数据重采样。
import mplfinance as mpfimport numpy as npimport pandas as pdimport matplotlibmatplotlib.use(\'TkAgg\')import matplotlib.pyplot as pltplt.rcParams[\'font.family\'] = [\'SimHei\'] # 设置中文字体plt.rcParams[\'axes.unicode_minus\'] = False # 解决负号显示问题# 根据索引切片,抽取指定日期范围内的收盘价数据df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)mydata = df[\'2022-01-01\':\'2022-12-31\']# 把成交量列\'vol\'改为\'volume\',因为后面绘图默认的是volume名;因为是中文,全部改为英文mydata.rename(columns={\'成交量\':\'volume\',\'开盘\':\'open\',\'收盘\':\'close\',\'最高\':\'high\',\'最低\':\'low\'}, inplace=True)# 绘制K线图# 自定义颜色mc = mpf.make_marketcolors( up=\'red\', # 上涨K线柱子的颜色为“红色” down=\'green\',# 下跌K线柱子的颜色为“绿色” edge=\'i\', # K线图柱子边缘的颜色(i代表继承自up和down的颜色),下同 volume=\'i\', # 成交量直方图的颜色 wick=\'i\' # 上下影线的颜色)# 调用make_mpf_style()函数,自定义k线图样式mystrle = mpf.make_mpf_style(base_mpl_style=\'ggplot\', marketcolors=mc)# 数据量太多了,选5天取一次样本,5天选最后一天结果作为值mydata2 = mydata.resample(rule=\'5D\').last()# mydata2mpf.plot( mydata2, type=\'candle\', style=mystrle, volume=True, mav=(5, 10, 20), tight_layout=True, update_width_config=dict(candle_linewidth=1.75, line_width=0.7), figratio=(20, 10))plt.show()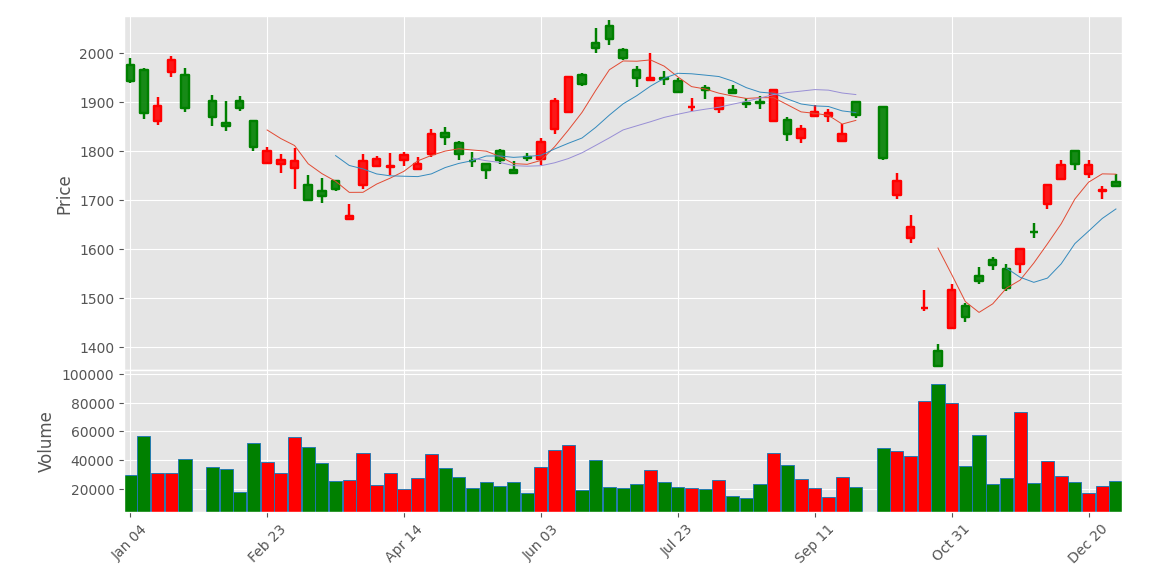
五、股票分析预测
5.股票分析预测
此处不做重点讲。
基本上,股票市场分析分为两部分:基本面分析和技术分析。
(1)基本面分析涉及根据当前的商业环境和财务业绩分析公司未来的盈利能力。
(2)另一方面,技术分析包括阅读图标和使用统计数据来确定股票市场的趋势。我们的重点将放在技术分析部分。
参考代码:https://zhuanlan.zhihu.com/p/100625956
安装 keras
先安装深度学习库 tensorflow
pip install tensorflow -i https://mirrors.aliyun.com/pypi/simple/
再安装 Keras 是深度学习里神经网络框架
pip install keras -i https://mirrors.aliyun.com/pypi/simple/
Keras 神经网络框架便是其中之一,它是一个高级神经网络 API,用 Python 编写,能够在 TensorFlow、CNTK 或 Theano 之上运行。它的开发重点是实现快速实验。能够以最小的延迟从理念到结果是进行良好研究的关键。接下来我们要讲的神经网络原理与梯度求解,Keras 都已经对它们有了很好的封装,在后续的学习中,大家只要学会怎么去构建网络结构就没有什么问题了,其余的问题都由神经网络框架替我们去解决。
长短期记忆(LSTM)
1.介绍
LSTM(Long Short Term Memory,LSTM)泛用于序列预测问题,并且已被证明是非常有效的。它们工作得很好是因为 LSTM 能够存储过去重要的信息,并忘记不重要的信息。LSTM 有三个门:
输入门:输入门将信息添加到单元状态
遗忘门:它删除模型不再需要的信息
输出门:LSTM 的输出门选择要显示为输出的信息
现在,让我们将 LSTM 实现为黑盒子,并检查它在我们的特定数据上的性能。
2.实现
# 导入所需的库from sklearn.preprocessing import MinMaxScalerfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, LSTMimport pandas as pdimport numpy as npimport pandas as pd# 设置value的显示长度为200,默认为50pd.set_option(\'max_colwidth\', 200)# 显示所有列,把行显示设置成最大pd.set_option(\'display.max_columns\', None)# 显示所有行,把列显示设置成最大pd.set_option(\'display.max_rows\', None)# 1. 读取文件# index_col=0 设置为索引列 parse_dates=True 没有指定列时,表示将尝试解析 index 为日期格式# parse_dates=[0,1,2,3,4] :尝试解析 0,1,2,3,4 列为时间格式;# parse_dates=[[‘考试日期’,‘考试时间’]] :传入多列名,尝试将其解析并且拼接起来,parse_dates[[0,1,2]] 也有同样的效果df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 创建数据框data = df.sort_index(ascending=True, axis=0)# 因为日期列已经做为了索引列new_data = df[[\'收盘\']]print(new_data)# 创建训练集和验证集dataset = new_data.values# 这里我们不能打乱数据,因为在时间序列中必须是顺序的train = dataset[0:1652,:] # 数据集总共2202条,取0.75valid = dataset[1652:,:] # 验证集# 数据归一化scaler = MinMaxScaler(feature_range=(0, 1))scaled_data = scaler.fit_transform(dataset)# 将数据集转换为x_train和y_train# 这里设置的60,表示是预测下一个目标值时将在过去查看的步骤数# 当i=60时xtrain添加的数据scaled_data[i-60:i,0]scaled为_data[0:60,0] 这里只有收盘价,取0列; y_train作为目标值,只有一个值, scaled_data[60,0]x_train, y_train = [], []for i in range(60, len(train)): x_train.append(scaled_data[i-60:i,0]) y_train.append(scaled_data[i,0])x_train, y_train = np.array(x_train), np.array(y_train)# 重塑为3维数组x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))# 创建和拟合LSTM网络model = Sequential()model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1)))model.add(LSTM(units=50))model.add(Dense(1))# optimizer: 优化器,用于控制梯度裁剪 adam# Adam优化器是目前应用最多的优化器。让学习率随着训练过程自动修改,以便加快训练,提高模型性能。model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')# batch_size 整数每次梯度更新的样本数。# epochs整数,训练模型迭代次数# verbose 日志展示,整数 0:为不在标准输出流输出日志信息 1:显示进度条2 :每个epoch输出一行记录model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=2)# 使用过去值来预测# 输入为没有归一化前的训练集(除去了预留的60组数据)inputs = new_data[len(new_data) - len(valid) - 60:].valuesinputs = inputs.reshape(-1,1)inputs = scaler.transform(inputs)# 测试集X_test = []for i in range(60, inputs.shape[0]): X_test.append(inputs[i-60:i,0])X_test = np.array(X_test)X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))# 预测closing_price = model.predict(X_test)# inverse_transform()将标准化后的数据转换为原始数据closing_price = scaler.inverse_transform(closing_price)3.结果
# RMSErms = np.sqrt(np.mean(np.power((valid - closing_price), 2)))print(rms)#61.575817193567865 误差不算很小评价指标
描述信息
MSE(均方误差)
预测值与真实值偏差的平方和的平均值。
RMSE(均方根误差)
MSE的平方根。数量级与真实值相同。比如RMSE=10,可以认为回归效果相比真实值平均相差10。
MAE(平均绝对误差)
预测值与真实值偏差的绝对值的平均值。
MAPE(平均绝对百分比误差)
预测值与真实值偏差占真实值的比例的平均值。MAPE不仅考虑了预测值与真实值的误差,还考虑了误差与真实值之间的比例。在某些场景下,比如真实值是50到1000万,100W预测成50W和1000W预测成950W的差距是相当大的。MAPE可以用较小的数值概括风险。
四个标准的范围都是 [0, +∞),当预测值与真实值完全吻合时等于 0,即完美模型;误差越大,这些值越大,模型越不好。
用于绘图
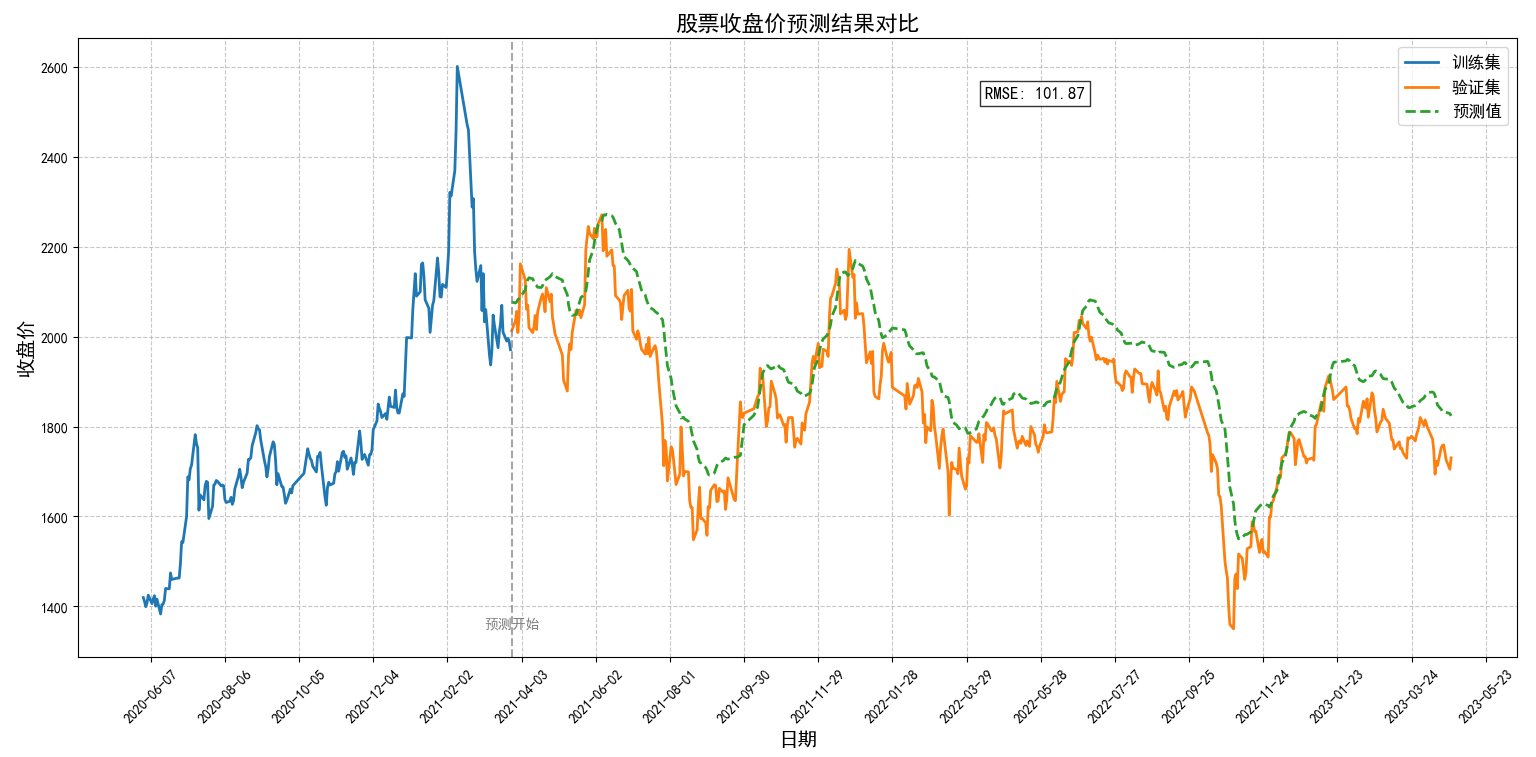
# 用于绘图import matplotlib.pyplot as pltplt.rcParams[\'font.family\'] = \'SimHei\'plt.figure(figsize=(15, 8))train = new_data[1600:1652] # 把训练集减去了大部分,方便看验证效果valid = new_data[1652:]# 把预测结果作为新列添加到验证集valid[\'Predictions\'] = closing_price# 设置均匀地取刻度(在0-500之间均匀地取100个日期标签)plt.xticks(np.linspace(0, 500, 100), rotation=90)plt.plot(train[\'收盘\'], label=\'训练集\')plt.plot(valid[[\'收盘\', \'Predictions\']], label=[\'验证集\', \'预测值\'])plt.legend()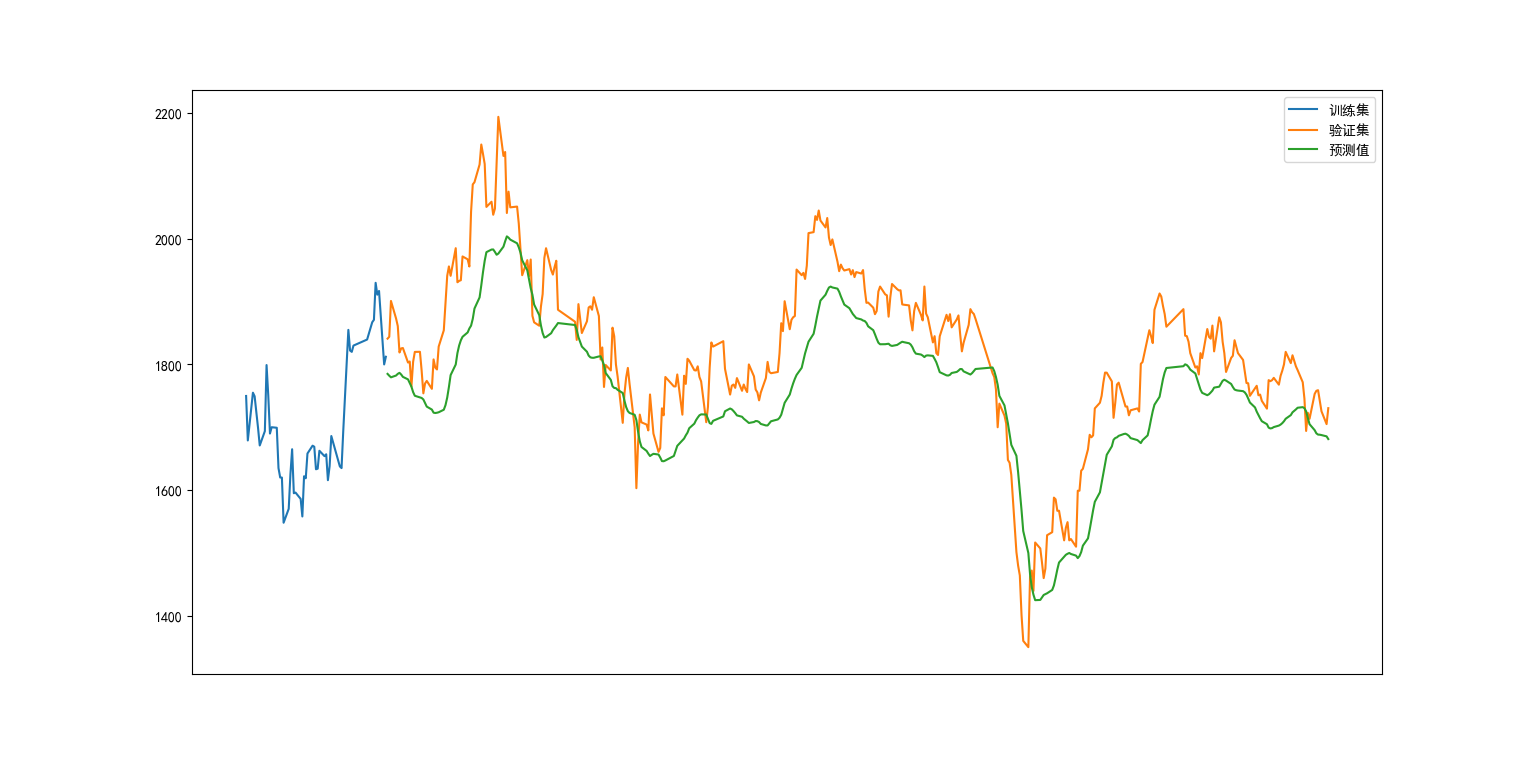
刻度显示不出来,把训练集的数据减去一些,主要看后面预测的结果和实际的结果是否一致,模型是否预测准
# 导入所需的库from sklearn.preprocessing import MinMaxScalerfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, LSTMimport pandas as pdimport numpy as npimport matplotlibmatplotlib.use(\'TkAgg\')import matplotlib.pyplot as pltplt.rcParams[\'font.family\'] = [\'SimHei\'] # 设置中文字体plt.rcParams[\'axes.unicode_minus\'] = False # 解决负号显示问题# 设置显示选项pd.set_option(\'max_colwidth\', 200)pd.set_option(\'display.max_columns\', None)pd.set_option(\'display.max_rows\', None)# 1. 读取文件df = pd.read_csv(r\'E:\\data_pachong\\A股实时数据分析\\data.csv\', index_col=0, parse_dates=True)# 创建数据框data = df.sort_index(ascending=True, axis=0)new_data = df[[\'收盘\']]print(new_data)# 创建训练集和验证集dataset = new_data.valuestotal_size = len(dataset)train_size = int(total_size * 0.75) # 75%用于训练valid_size = total_size - train_size # 25%用于验证train = dataset[0:train_size, :]valid = dataset[train_size:, :]# 数据归一化scaler = MinMaxScaler(feature_range=(0, 1))scaled_data = scaler.fit_transform(dataset)# 将数据集转换为x_train和y_trainx_train, y_train = [], []for i in range(60, len(train)): x_train.append(scaled_data[i - 60:i, 0]) y_train.append(scaled_data[i, 0])x_train, y_train = np.array(x_train), np.array(y_train)x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))# 创建和拟合LSTM网络model = Sequential()model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1)))model.add(LSTM(units=50))model.add(Dense(1))model.compile(loss=\'mean_squared_error\', optimizer=\'adam\')model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=2)# 使用过去值来预测inputs = new_data[len(new_data) - len(valid) - 60:].valuesinputs = inputs.reshape(-1, 1)inputs = scaler.transform(inputs)# 准备测试集X_test = []for i in range(60, inputs.shape[0]): X_test.append(inputs[i - 60:i, 0])X_test = np.array(X_test)X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))# 预测closing_price = model.predict(X_test)closing_price = scaler.inverse_transform(closing_price)# 计算RMSErms = np.sqrt(np.mean(np.power((valid - closing_price), 2)))print(f\"均方根误差(RMSE): {rms}\")# 优化图表显示plt.figure(figsize=(15, 8))# 1. 减少训练集显示范围 - 只显示最后200个训练点train_start = max(0, train_size - 200) # 确保起始位置有效train_plot = new_data[train_start:train_size]# 2. 准备验证集和预测值valid_plot = new_data[train_size:]valid_plot[\'Predictions\'] = closing_price# 3. 绘制图表plt.plot(train_plot.index, train_plot[\'收盘\'], label=\'训练集\', linewidth=2)plt.plot(valid_plot.index, valid_plot[\'收盘\'], label=\'验证集\', linewidth=2)plt.plot(valid_plot.index, valid_plot[\'Predictions\'], label=\'预测值\', linestyle=\'--\', linewidth=2)# 4. 优化刻度显示# 自动选择合适数量的刻度plt.gca().xaxis.set_major_locator(plt.MaxNLocator(20))plt.xticks(rotation=45) # 旋转45度避免重叠# 5. 添加图表元素plt.title(\'股票收盘价预测结果对比\', fontsize=16)plt.xlabel(\'日期\', fontsize=14)plt.ylabel(\'收盘价\', fontsize=14)plt.legend(loc=\'best\', fontsize=12)plt.grid(True, linestyle=\'--\', alpha=0.7)# 6. 高亮显示预测区域plt.axvline(x=valid_plot.index[0], color=\'gray\', linestyle=\'--\', alpha=0.7)plt.text(valid_plot.index[0], plt.ylim()[0] * 1.05, \'预测开始\', fontsize=10, color=\'gray\', ha=\'center\')# 7. 添加RMSE值plt.text(valid_plot.index[int(len(valid_plot) / 2)], plt.ylim()[1] * 0.95, f\'RMSE: {rms:.2f}\', fontsize=12, bbox=dict(facecolor=\'white\', alpha=0.8))plt.tight_layout()plt.show()