(2025|NVIDIA,NAS,蒸馏,持续预训练,SFT,RLHF,聊天与推理)Llama-Nemotron:高效推理模型
Llama-Nemotron: Efficient Reasoning Models
目录
1. 引言
2. 推理优化模型的构建
2.1 部署约束与效率目标
2.2. NAS后训练:知识蒸馏与持续预训练
3. 合成数据
3.1 推理开启(Reasoning On)
3.2 推理关闭(Reasoning Off)
3.2.1 通用域开放式任务的生成时扩展
4. 监督微调(SFT)
4.1 通用策略
4.2 各模型微调细节
5. 推理强化学习
5.1 训练过程
5.2 基础设施
5.3 内存与推理优化
6. 偏好优化强化学习
6.1 指令跟随
6.2 RLHF
7. 推理与聊天基准评估
7.1 Benchmarks
7.2 LN-Nano(8B)
7.3 LN-Super(49B)
7.4 LN-Ultra(253B)
8. 评估判断能力(LLM-as-a-Judge)
9. 总结
1. 引言
Llama-Nemotron 是开源异构推理模型系列,主打高推理能力与高推理效率,且支持商业用途。
该系列包含三种尺寸:LN-Nano(8B)、LN-Super(49B)、LN-Ultra(253B)。所有模型具备 “推理开关(reasoning toggle)” 机制(通过 system prompt:\"detailed thinking on/off\" 控制),支持在聊天与推理模式间切换。
该模型系列基于 Llama 3 系列,通过神经架构搜索(neural architecture search,NAS)、知识蒸馏、持续预训练、监督微调与强化学习五阶段完成训练。
LN-Ultra 具备最强性能,推理能力优于 DeepSeek-R1,且在 8×H100 节点上实现高效部署。LN 系列在多个推理与非推理任务中表现优异,具有良好的可控性、推理精度与吞吐量。
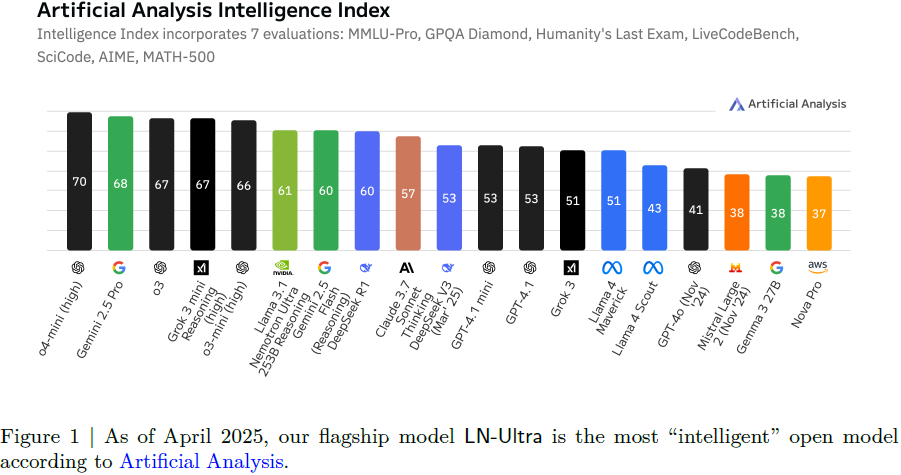
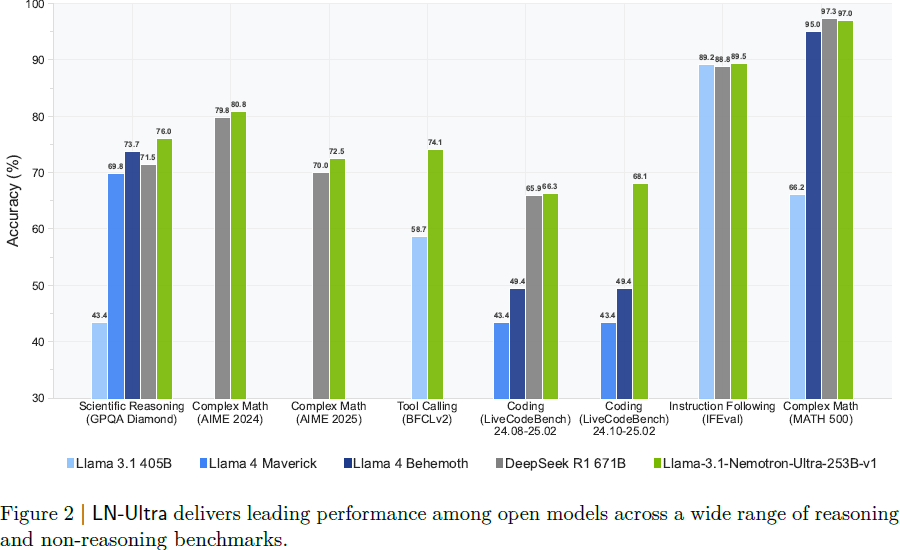
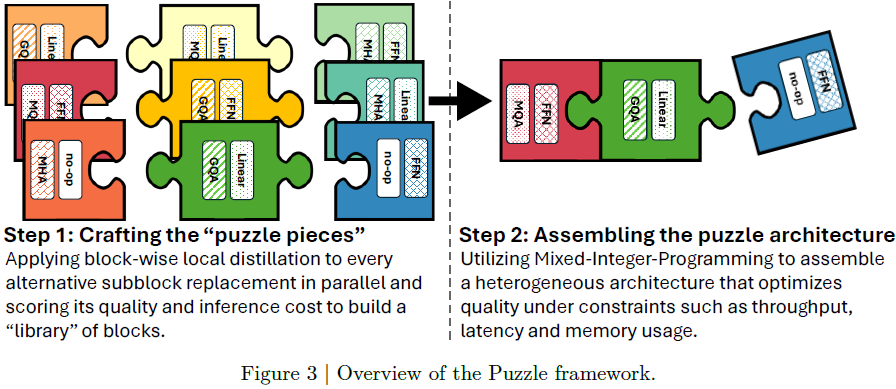
2. 推理优化模型的构建
LN-Super 和 LN-Ultra 模型通过 Puzzle 框架进行优化,提升在真实部署场景中的推理效率。Puzzle 是一种神经架构搜索(Neural Architecture Search, NAS)框架,能够在硬件约束下生成高效架构。
Puzzle 的优化流程包括两步:
1)构建模块库(Crafting Puzzle Pieces)
从 Llama 3 指令模型(LN-Super 基于 Llama 3.3-70B,LN-Ultra 基于 Llama 3.1-405B)出发。
对每一层 transformer block 进行局部蒸馏,训练多个替代子模块,这些模块在保留性能的同时更高效。
替代块包括:
-
移除 Attention
-
变更 FFN 维度:例如压缩到原始隐藏层的 87%、75%、50% 甚至 10%。
-
其他操作:如 Grouped-Query Attention(GQA)、Linear Attention、no-op 结构。
2)组合拼图架构(Assembling the Puzzle)
使用混合整数规划(mixed-integer programming,MIP)方法,从模块库中为每一层选择最优结构。
优化目标涵盖推理吞吐量、延迟、内存使用等部署约束。
支持构建多种在准确率与效率间权衡的结构,实现不同场景下的个性化部署。
FFN 融合。为 LN-Ultra 设计的额外压缩手段,用于进一步减少推理延迟:
-
Puzzle 移除部分 attention 层后,模型中会出现连续的 FFN 层。
-
FFN Fusion 将这些连续 FFN 融合为更宽但更少的 FFN 层,可并行执行,降低序列深度。
-
提升在多 GPU 系统上的计算利用率,降低通信开销。
2.1 部署约束与效率目标
LN-Super:
-
针对单张 NVIDIA H100 GPU 优化(tensor parallelism,TP1)。
-
相比 Llama 3.3-70B-Instruct 在 TP4 设置下,LN-Super 在 TP1 下仍实现 ≥2.17 倍吞吐量提升。
-
在 FP8 精度下支持约 300K 缓存 token。
LN-Ultra:
-
优化目标为完整的 8×H100 节点。
-
在架构搜索阶段约束其推理延迟必须比 Llama 3.1-405B-Instruct 低至少 1.5 倍,最终实现 1.71 倍延迟减少。
-
FP8 精度下支持 300 万 token,BF16 精度下为 60 万 token。
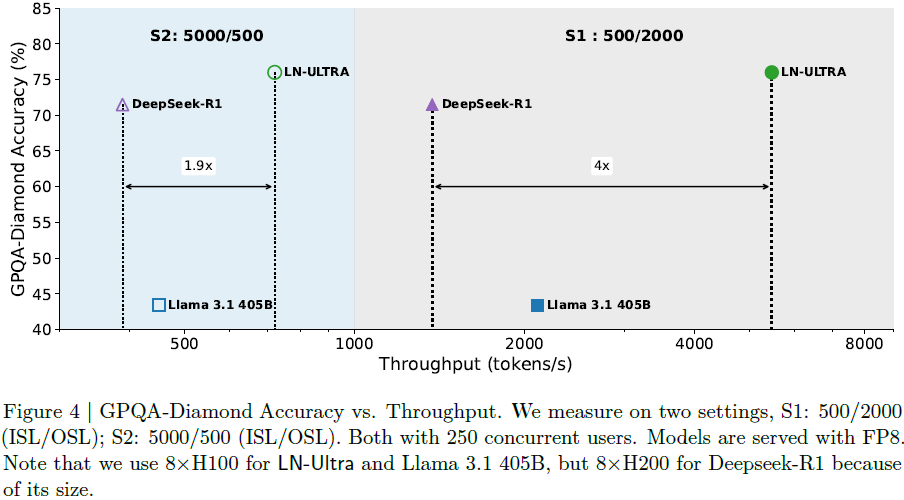
图 4 展示了在不同设置下(S1 与 S2),LN-Ultra 在 GPQA-Diamond 准确率与推理吞吐量方面均优于 DeepSeek-R1 与 Llama-3.1-405B。
2.2. NAS后训练:知识蒸馏与持续预训练
在完成 NAS 阶段后,LN-Super 和 LN-Ultra 模型还需要进一步训练,以提升各个模块之间的兼容性,并弥补逐层替换过程中带来的质量损失。
-
LN-Super 使用知识蒸馏目标,在 Distillation Mix 数据集上训练了 40B token。
-
LN-Ultra 首先在相同的蒸馏数据集上进行了 65B token 的知识蒸馏训练,然后又使用 Nemotron-H 第 4 阶段预训练数据集进行了 88B token 的持续预训练。
(2025|NVIDIA,压缩,FP8,VLM)Nemotron-H:精确高效的混合 Mamba-Transformer 家族
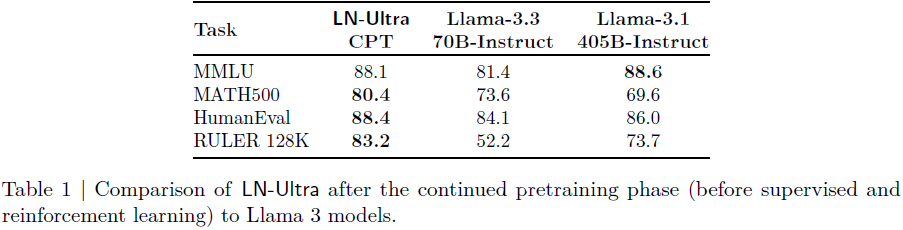
这一最终的预训练步骤使 LN-Ultra 不仅能够追平,而且在关键基准测试中超越参考模型 Llama 3.1-405B-Instruct,展示出即使在激进的结构优化之后,仍然可以通过短期的蒸馏与预训练实现出色的模型性能(表1)。
3. 合成数据
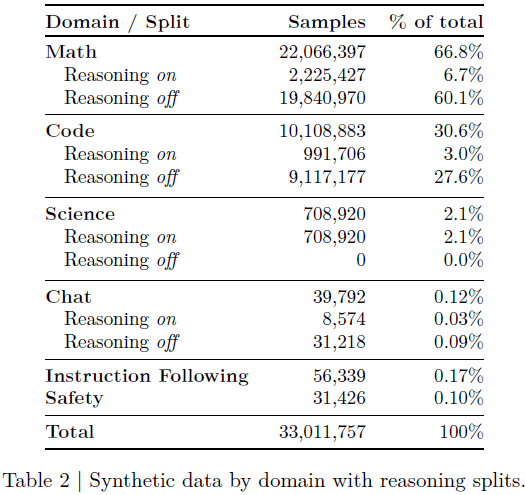
Llama-Nemotron 使用大规模合成数据训练,分为推理开启(Reasoning on)与关闭(Reasoning off)两类,通过系统指令(detailed thinking on / off)控制模型推理行为。
3.1 推理开启(Reasoning On)
数学:从 Art of Problem Solving (AoPS) 提取难题,使用 Qwen 和 DeepSeek-R1 生成解答,确保答案正确并去重。
代码:收集近 29K 题,生成并筛选带 标签的 Python 解答,最终保留 488K 条。
科学:由 LLM 生成或从 StackOverflow 获取选择题,覆盖物理、生物等学科。
通用任务:涵盖问答、摘要、头脑风暴等,使用奖励模型筛选高质量回复。
3.2 推理关闭(Reasoning Off)
为了训练模型正确响应“关闭推理”的指令,构建了成对样本:
-
使用与 3.1 相同的 prompt,生成对应的非推理回答;
-
标记系统指令为“detailed thinking off”;
-
使用不同版本的 Llama 3.1/3.3-Instruct 模型生成非推理回答;
-
回答根据答案正确性或奖励模型进行筛选。
还使用公开数据集扩展函数调用与安全任务样本。
3.2.1 通用域开放式任务的生成时扩展
为生成高质量的通用开放式响应,Llama-Nemotron 采用了一种新的 “反馈-编辑” 生成时扩展系统(Feedback-Edit Inference-Time-Scaling),流程如下:
1)数据来源:选取 2 万条首轮对话 prompt,来自 ShareGPT 与 WildChat-1M。
2)初始生成:使用 Llama-3.1-Nemotron-70B-Instruct 生成多个初始回答。
3)三阶段优化:
- 反馈模型:识别回答中待改进部分;
- 编辑模型:据反馈修改文本;
- 选择模型:从多个版本中挑选最佳回答。
最终构建出一个包含 20K 高质量开放式对话数据的训练集,用于增强模型在通用任务上的表现。
4. 监督微调(SFT)
监督微调阶段旨在将推理能力从强教师模型(如 DeepSeek-R1)迁移至 LN 系列模型,并训练模型根据指令控制推理行为(\"detailed thinking on/off\")。
4.1 通用策略
使用 token-level 交叉熵损失训练;
混合使用推理开启与关闭的数据;
推理数据因序列更长,需更高学习率和多轮训练;
所有模型采用 Adam 优化器,学习率使用线性预热 + 余弦退火策略。
4.2 各模型微调细节
LN-Nano(8B)
三阶段训练流程:
-
仅用数学/代码/科学领域推理数据;
-
引入非推理数据训练 “推理控制”;
-
融合聊天、指令、工具调用任务微调;
全程使用 32k token 序列打包(sequence packing),batch size = 256。
LN-Super(49B)
-
使用全量数据训练 1 个 epoch;
-
学习率 5e-6,序列长度 16k,batch size = 256;
-
小规模实验表明更多 epoch 更优,但受限于资源。
LN-Ultra(253B)
-
使用 24k token 序列打包(sequence packing),batch size = 256;
-
初始尝试高学习率会导致不稳定(梯度爆炸),最终采用:
-
warmup 到 1e-5,之后余弦衰减至 1e-6;
-
-
训练中途多次重启并重新初始化优化器才成功收敛。
5. 推理强化学习
监督微调虽然能复制教师模型的推理能力,但无法超越。为使 LN-Ultra 超越 DeepSeek-R1,对其进行大规模强化学习,仅用于 LN-Ultra。
5.1 训练过程
算法:采用 GRPO(Group Relative Policy Optimization)。
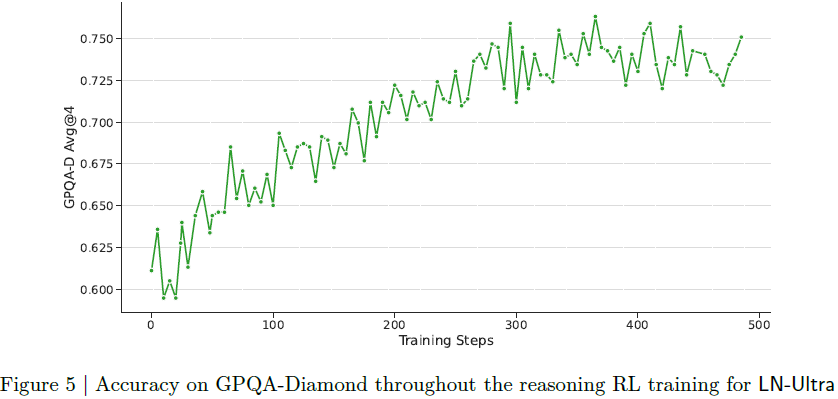
训练数据:精选高难度问题,剔除 “通过率高” 的样本,提升挑战性。
训练策略:
-
每个 prompt 生成 16 个样本;
-
使用准确率奖励(与标准答案匹配)与格式奖励(推理内容需包裹在
标签中); -
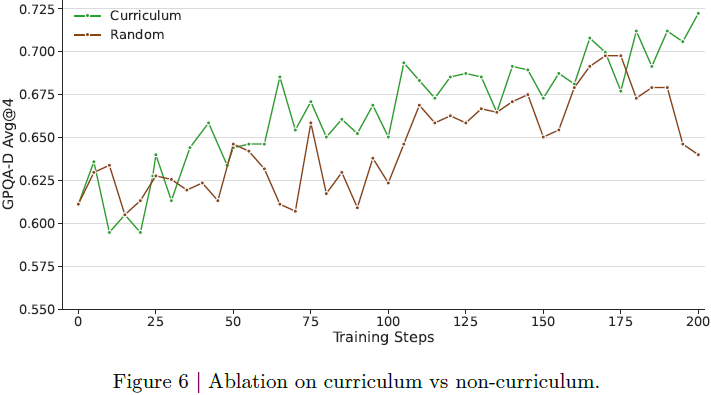
引入 curriculum 学习策略(逐步提升训练样本难度),训练更稳定且收敛效果更好。
5.2 基础设施
使用 NeMo-Aligner 和 Megatron-LM 实现训练与生成在相同 GPU 的共置(co-located);
GPU 集群规模:72 个节点 × 8×H100 GPU;
并行策略包括:
训练模型:
-
Tensor 并行(序列并行):8;
-
Pipeline 并行:18;
-
Context 并行:2;
-
数据并行:2。
生成模型:
-
Tensor 并行(序列并行):8;
-
数据并行:72
5.3 内存与推理优化
精细管理权重共享、激活缓存,以避免 GPU/CPU OOM(out of memory),
启用 FP8 生成推理:
-
使用动态权重缩放与 token 缩放;
-
推理速度提升 1.8 倍;
-
是目前最大规模推理训练中最高吞吐记录(32 token/s/GPU/prompt)。
6. 偏好优化强化学习
为提升 Llama-Nemotron 模型的指令跟随能力、对话自然性和综合表现,对 LN-Nano、LN-Super、LN-Ultra 分别应用了不同的 RLHF 策略。
6.1 指令跟随
目标:增强模型处理多步复杂指令的能力;
方法:使用指令验证器做奖励函数,采用 RLOO 算法;
过程:短期训练(<120步),使用指令跟验证器作为奖励
6.2 RLHF
LN-Super(49B)
-
算法:两轮 online RPO;
-
奖励模型:Llama-3.1-Nemotron-70B-Reward;
-
数据:HelpSteer2;
-
结果:Arena-Hard 分数从 69.1 提升至 88.3,超过 GPT-4o 和 Claude 3.5 Sonnet,以及 Llama-3.1-405b-instruct 和 Mistral-large-2407
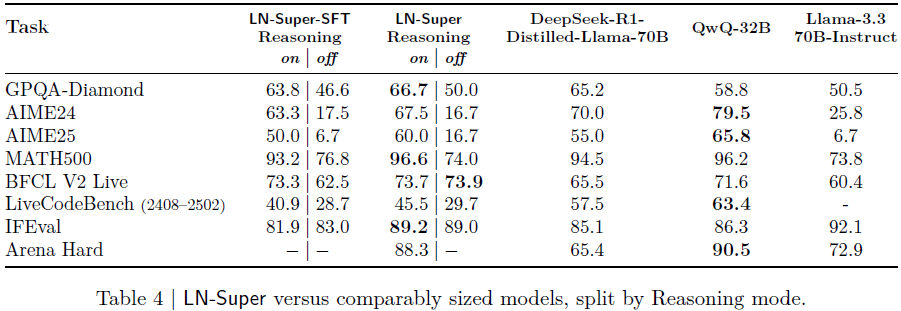
LN-Ultra(253B)
-
算法:GRPO;
-
设置:每 prompt 采样 8 个响应,batch size 288,训练 30 步;
-
结果:在不牺牲推理能力的同时,提升对话自然度和指令跟随能力。
LN-Nano(8B)
-
算法:两轮 offline RPO;
-
第一轮增强推理控制;
-
第二轮增强指令跟随;
-
-
每轮训练最多 400 步,使用较大 batch 和较高 KL 惩罚(β=0.03)以确保稳定。
7. 推理与聊天基准评估
Llama-Nemotron 系列在多个标准基准上评估其推理和非推理(聊天、指令)能力。模型支持 “Reasoning On/Off” 模式,统一使用 32K 上下文长度 进行评估,进一步提升推理表现。
7.1 Benchmarks
推理类任务:
-
GPQA-Diamond(科学推理)
-
AIME24/25(奥数题)
-
MATH500(复杂数学)
-
LiveCodeBench(代码生成,两个时间区间)
非推理任务:
-
IFEval(指令跟随能力)
-
BFCL V2(函数调用)
-
Arena-Hard(人类聊天偏好评估)
7.2 LN-Nano(8B)
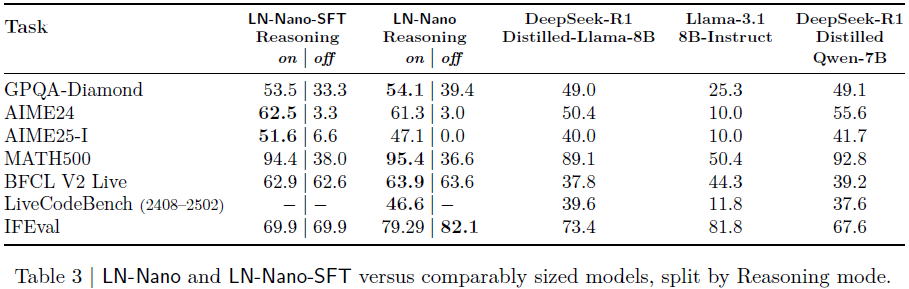
在 MATH500 达到 95.4%;
AIME25-I 表现远超同尺寸模型;
展现出极强的紧凑模型推理能力;
通过推理控制微调与 RPO,平衡了 IFEval 与推理表现。
7.3 LN-Super(49B)
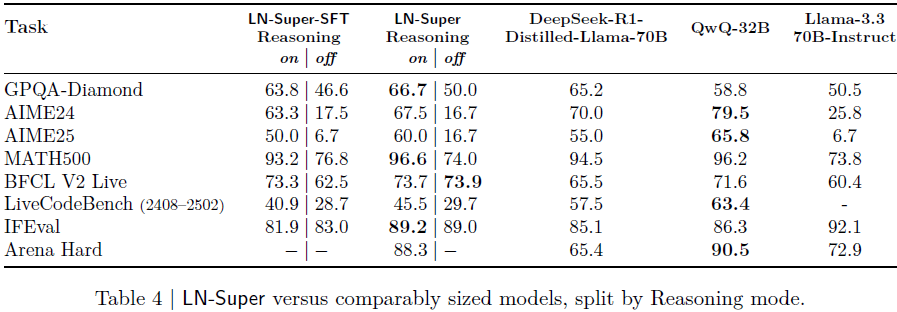
在 Reasoning On 模式下普遍优于 Llama-3.3-70B;
IFEval:89.2 分,Arena-Hard:88.3 分,性能均衡;
LiveCodeBench 稍弱(因使用旧版数据集);
通过模型合并尝试在指令跟随与对话自然性之间取平衡。
7.4 LN-Ultra(253B)
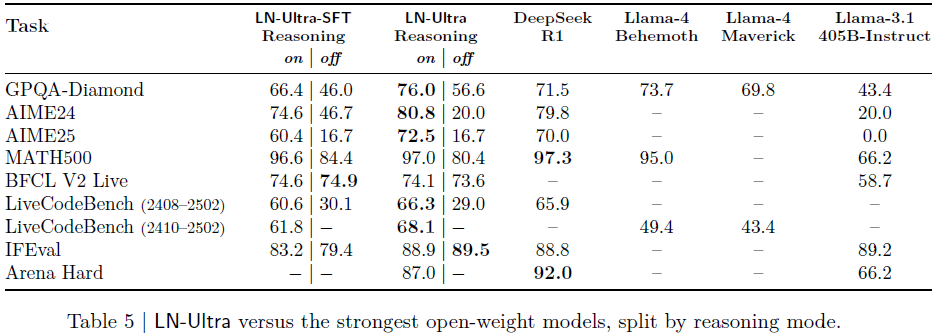
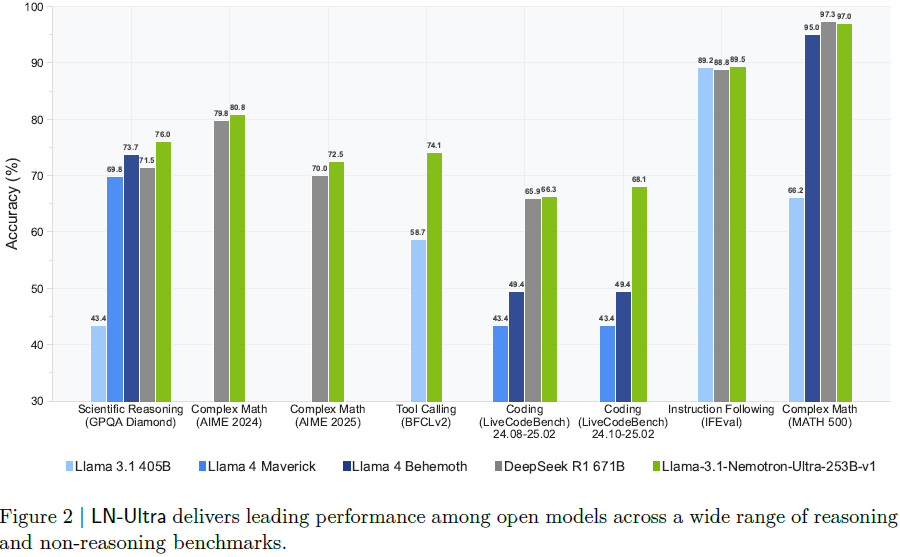
全面超越 DeepSeek-R1,为当前最强开源推理模型;
GPQA-Diamond 达 76.0%,AIME25 达 72.5%;
LiveCodeBench 和 MATH500 表现突出;
IFEval 达到 89.5,Arena-Hard 为 87.0;
RL 是突破 SFT 上限、取得领先表现的关键。
8. 评估判断能力(LLM-as-a-Judge)
为测试模型在非训练目标任务上的泛化能力,在 JudgeBench 数据集上评估各模型的 “判别优劣回答” 能力(LLM as a Judge)。
任务说明:
-
模型需判断两个回答中哪个质量更高;
-
涉及知识、推理、数学、代码等多个维度;
-
属于 “出分能力以外” 的泛化测试。
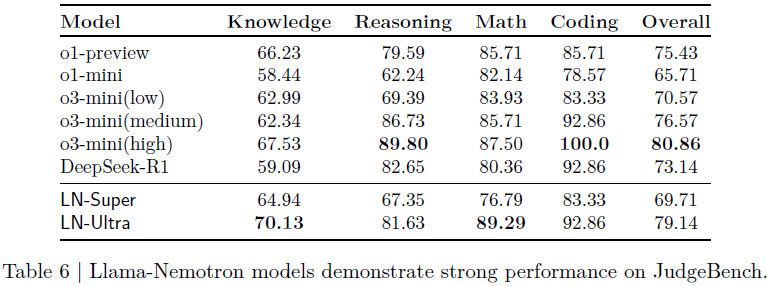
结论:
-
LN-Ultra 为目前最强开源评判模型,仅次于专有的 o3-mini-high;
-
LN-Super 同样超越了 o1-mini 等多个闭源小模型;
-
Llama-Nemotron 展现出优秀的 任务外泛化与判断能力。
9. 总结
本文发布了 Llama-Nemotron 模型系列。该系列模型在宽松许可协议下开源,提供了模型权重、训练数据和完整代码。
Llama-Nemotron 模型在多个推理任务中表现与当前最先进的模型相当,同时具备较低的内存需求与高效的推理能力。
观察到,在拥有强大推理能力教师模型的前提下,基于其生成的高质量合成数据进行监督微调,能有效赋予较小模型出色的推理能力。
但若希望模型在推理能力上超越教师模型的水平,则必须进行大规模、课程式的强化学习训练,并结合可验证的奖励机制。
此外,还发现,要构建一个在广泛基准上都表现优异的通用型大模型,需要在训练后阶段设计多个细致的训练阶段,形成完整的微调流程。
论文地址:https://arxiv.org/abs/2505.00949
Huggingface:
https://huggingface.co/collections/nvidia/llama-nemotron-67d92346030a2691293f200b
Github:
NeMo:https://github.com/NVIDIA/NeMo
NeMo-Aligner:https://github.com/NVIDIA/NeMo-Aligner/tree/llama-nemotron-dev
Megatron-LM:https://github.com/NVIDIA/Megatron-LM
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

