Hadoop入门学习(一)—— HDFS分布式文件系统
一、前言:大数据概述
大数据的核心工作其实就是:从海量的高增长、多类别、低信息密度的数据中挖掘出高质量的结果。
核心工作有三点:大数据存储、大数据计算、大数据传输
大数据软件生态:
存储:Hadoop-HDFS(是使用最为广泛的分布式存储技术)、HBase(使用最为广泛的NoSQL、KV型数据库,是基于HDFS之上构建的)
计算:Hadoop-MapReduce(大数据分布式计算引擎)、Hive(以SQL为开发语言的分布式计算框架、其底层使用了MapReduce)、Spark(基于内存计算的分布式计算系统)、Flink(主要用于实时计算)
传输:Kafka(分布式消息系统)、Flume(流式数据采集工具,可以从非常多的数据源中完成数据采集传输任务)、Sqoop(是一款ETL工具,可以协助大数据体系和关系数据库之间进行数据传输)
二、Hadoop 概述
Hadoop是一个Apache基金会所开发的分布式系统基础架构
主要解决:海量数据的存储和分析计算问题
Hadoop的优势:
(1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2)高扩展性:在集群间分配任务数据,可方便的扩展数以干计的节点。
(3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
(4)高容错性:能够自动将失败的任务重新分配。
Hadoop的功能主要有三个:分布式存储、计算和调度。分别对应三个功能组件:HDFS、MapReduce、YARN
2.1 分布式计算概述
分布式计算模式主要分为两类:分散-汇总模式和中心调度步骤执行模式
分散-汇总模式:将数据分片,多台服务器各自负责一部分数据处理;然后将各自的结果进行汇总处理;最终得到想要的计算结果。(MapReduce)
中心调度步骤执行模式:由一个节点作为中心调度管理者;将任务划分为几个具体步骤(包含数据处理、数据交换、数据汇总等过程);管理者安排每个机器执行任务;最终得到结果数据。(Spark、Flink)
三、Hadoop HDFS 分布式文件系统
3.1 HDFS的基础架构
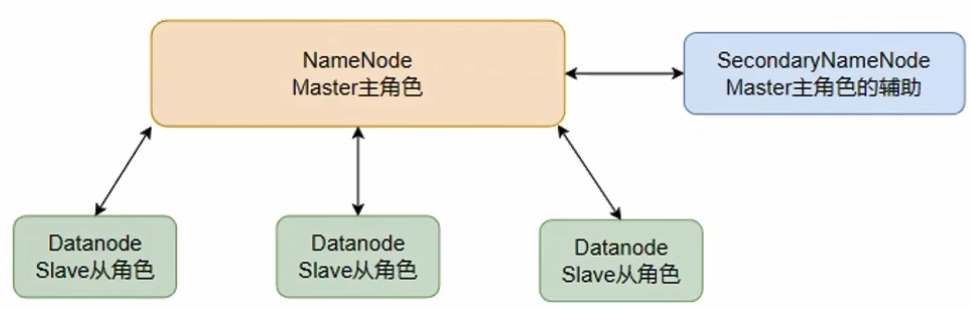
Hadoop HDFS 是一个典型的中心化模式(主从模式)技术架构。
HDFS有三个角色:
主角色:NameNode(负责管理HDFS整个文件系统,负责管理DataNode,是一个独立的进程)管理HDFS的的名称空间,配置副本策略,管理数据块的映射信息,处理客户端的读写请求,
从角色:DataNode(一个独立进程,主要负责数据的存储)存储实际的数据块,执行数据块的读写操作,
主角色的辅助角色:SecondaryNameNode(一个独立进程,主要帮助NameNode完成元数据整理工作)并非NameNode的热备,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。主要工作是辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits(后面会讲),并推送给NameNode。在紧急情况下,可辅助恢复NameNode。
Hadoop集群有三种运行模式:
(1)Local (Standalone) Mode 本地模式,单台服务器,数据存储在Linux本地
(2)Pseudo-Distributed Mode 伪分布式模式,单台服务器,数据存储在HDFS
(3)Fully-Distributed Mode 完全分布式模式,多台服务器,数据存储在HDFS
HDFS的缺点:

3.2 VMware虚拟机部署HDFS集群
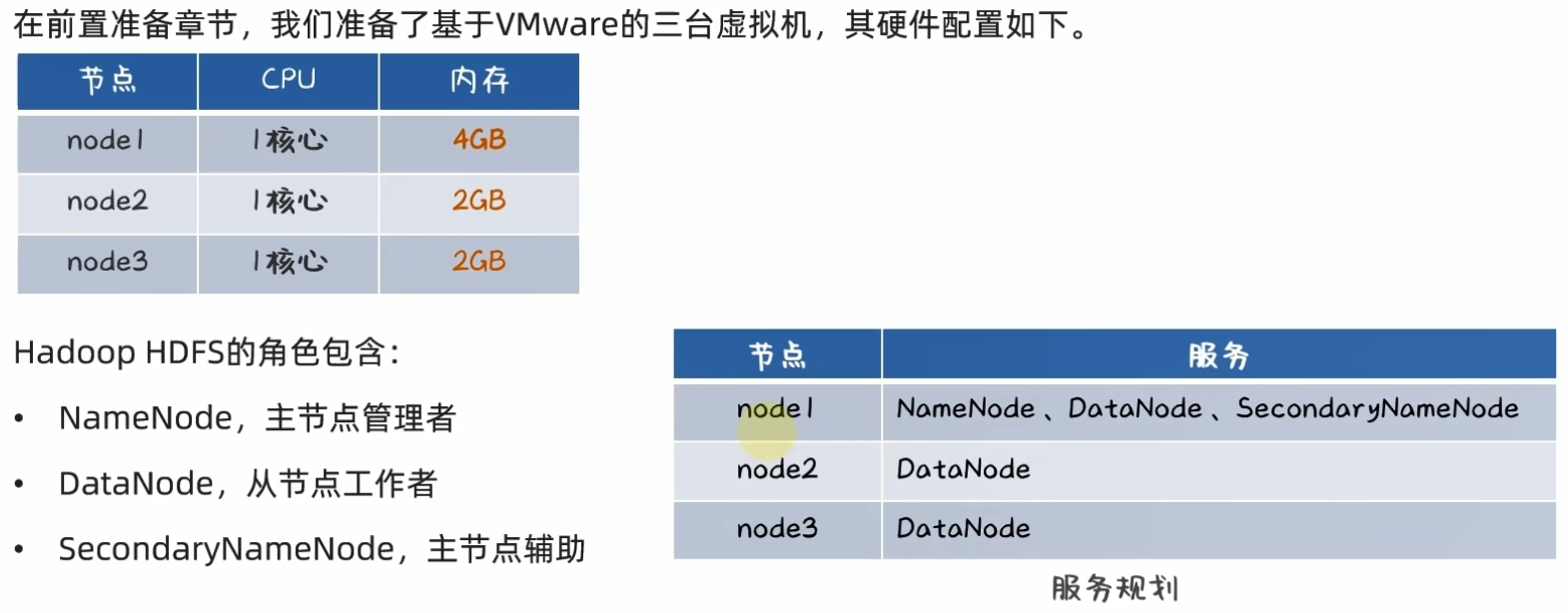
1、从Hadoop官网下载安装包
2、上传 & 解压 安装包
安装包目录结构

3、修改Hadoop的配置文件





4、准备数据目录

5、在集群中分发Hadoop文件夹

6、配置环境变量
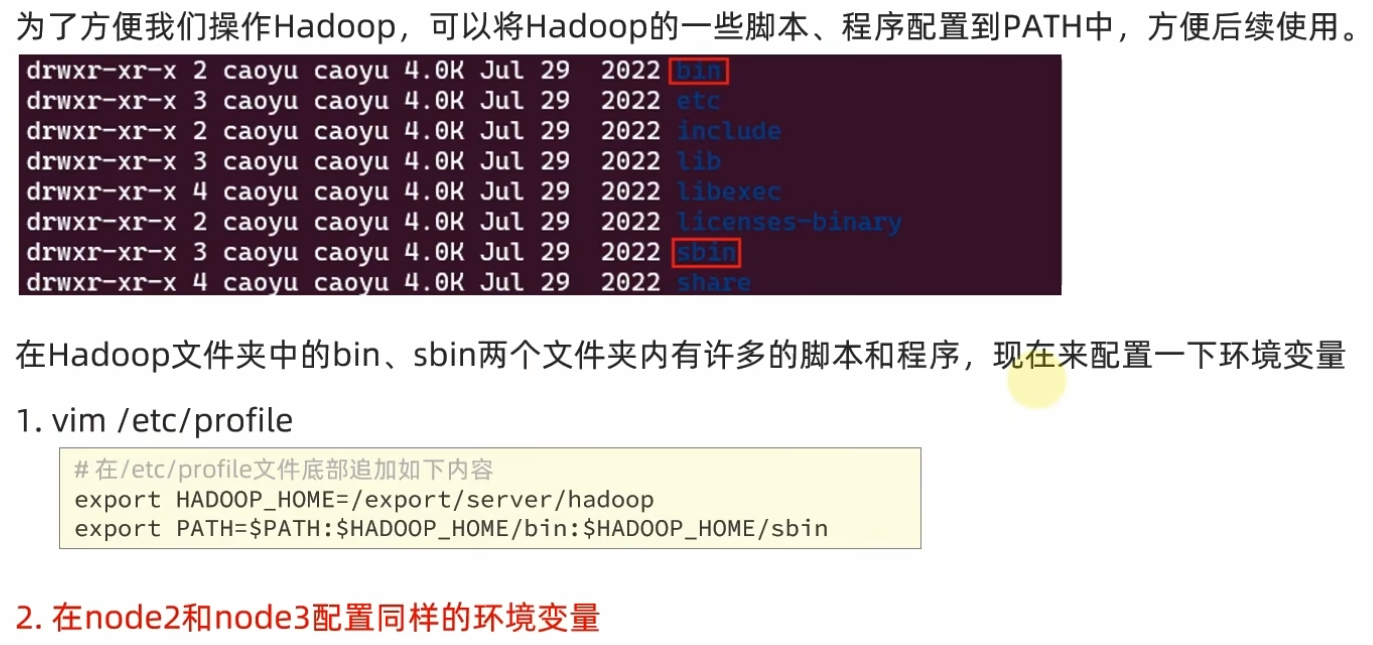
通过执行命令 source /etc/profile 使环境变量生效
7、格式化整个文件系统
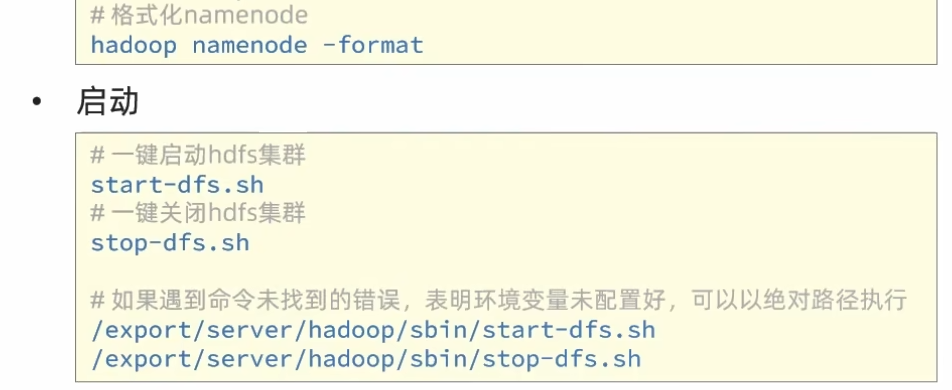
启动hdfs集群后,通过浏览器输入NameNode主机地址:9870,可以查看到hdfs文件系统的管理网页
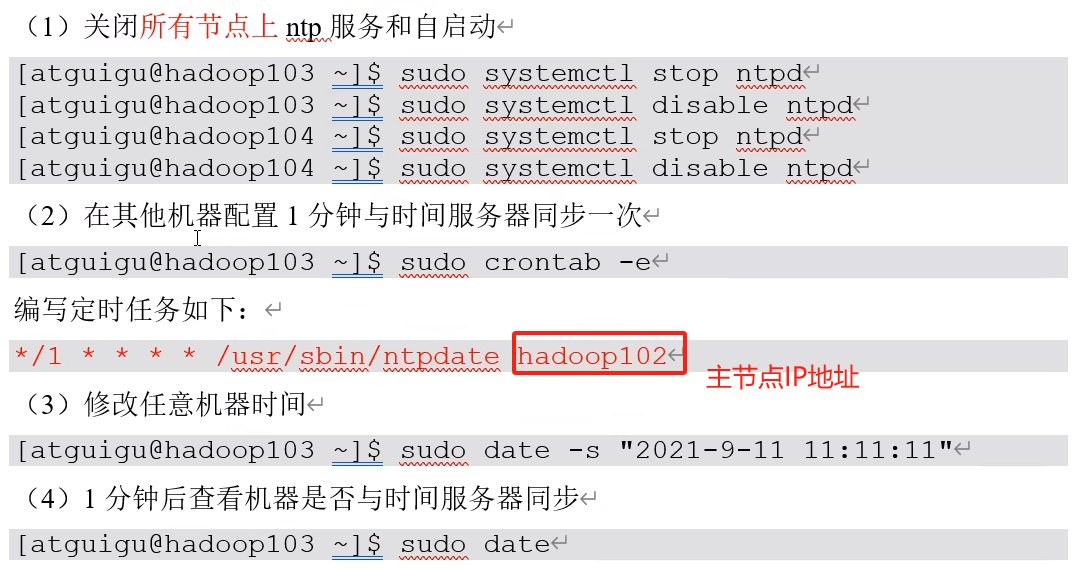
8、集群时间同步(如果生产环境中服务器不能连接外网,则需要对集群进行时间同步):
1)查看/设置所有节点ntpd服务状态和开机自启动状态
sudo systemctl status ntpdsudo systemctl start ntpdsudo systemctl is-enabled ntpd2)修改集群主节点的ntp.conf配置文件 sudo vim /etc/ntp.conf
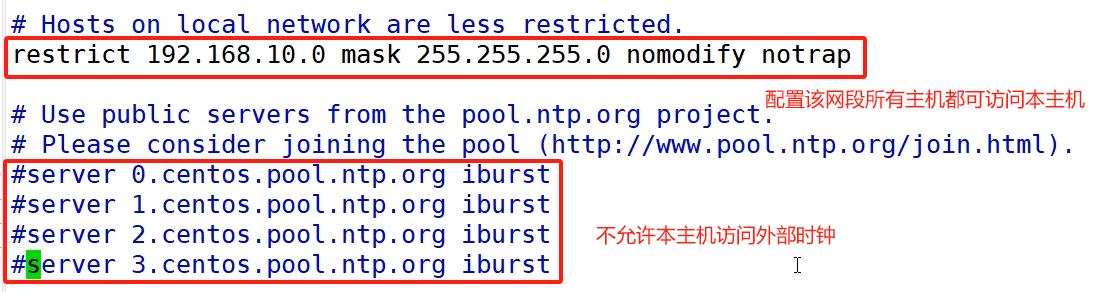

3)修改集群主节点的 etc/sysconfig/ntpd 文件

4)重新启动 ntpd 服务 sudo systemctl start ntpd
5)设置 ntpd 服务开机启动 sudo systemctl enabled ntpd
6)集群其他节点设置(必须使用root账户)
3.3 HDFS的 Shell 操作
3.3.1 进程启停管理
一键启停:

单进程启停:

3.3.2 HDFS文件系统基本信息
HDFS与Linux系统一样,均是以 / 作为根目录的组织形式。
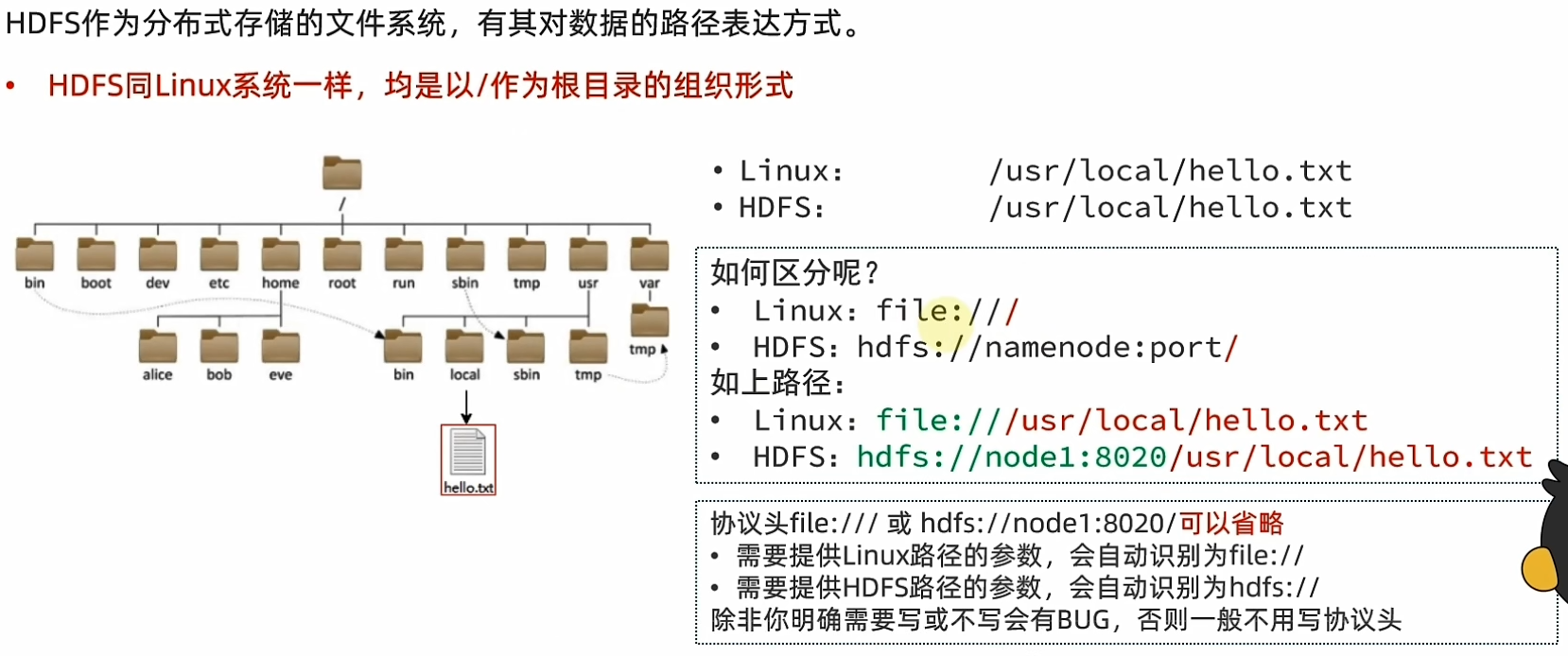
3.3.3 文件系统操作命令
Hadoop提供了两套命令体系:
Hadoop命令(老版用法),用法:hadoop fs [generic options]
hdfs命令(新版本用法),用法:hdfs dfs [generic options]
1、创建文件夹
hadoop fs -mkdir [-p]
hdfs dfs -mkdir [-p]
path 为待创建目录,-p选项会沿着路径创建父目录
2、查看指定目录下内容
hadoop fs -ls [-h] [-R] [...]
hdfs dfs -ls [-h] [-R] [...]
path 指定目录路径,-h显示文件size,-R递归查看指定目录及其子目录
3、上传文件到HDFS指定目录下(从本地Linux 上传到HDFS中)
hadoop fs -put [-f] [-p]
hdfs dfs -put [-f] [-p]
-f 覆盖目标文件(已存在),-p保留访问和修改时间,所有权和权限
本地文件系统(客户端所在机器),目标文件系统(HDFS)
4、查看HDFS文件内容
hadoop fs -cat ...
hdfs dfs -cat ...
读取大文件可以使用管道符配合more,进行翻页查看
hadoop fs -cat | more
hdfs dfs -cat | more
5、下载HDFS文件(下载文件到本地系统文件目录,必须是目录)
hadoop fs -get [-f] [-p]
hdfs dfs -get [-f] [-p]
-f 覆盖目标文件(已存在),-p保留访问和修改时间,所有权和权限
6、拷贝HDFS文件(-f 覆盖目标文件)
hadoop fs -cp [-f] ...
hdfs dfs -cp [-f] ...
7、追加数据到HDFS文件中(将所有给定本地文件的内容追加到给定dst文件;如果dst文件不存在,将创建该文件;如果为- ,则输入为从标准输入中读取)
整个HDFS文件系统的文件修改只支持删除和追加操作
hadoop fs -appendTofile ...
hdfs dfs -appendTofile ...
8、HDFS数据移动操作(移动文件到指定文件夹下,可以使用该命令重命名文件名称)
hadoop fs -mv ...
hdfs dfs -mv ...
9、HDFS数据删除操作(删除指定路径的文件或文件夹)
hadoop fs -rm -r [-skipTrash] URI [URI ...]
hdfs dfs -rm -r [-skipTrash] URI [URI ...]
-skipTrash 跳过回收站,直接删除;URI被删除路径;-r删除文件夹(不加-r删除文件)

官方命令指导文件:
https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
可以通过WEB界面操作
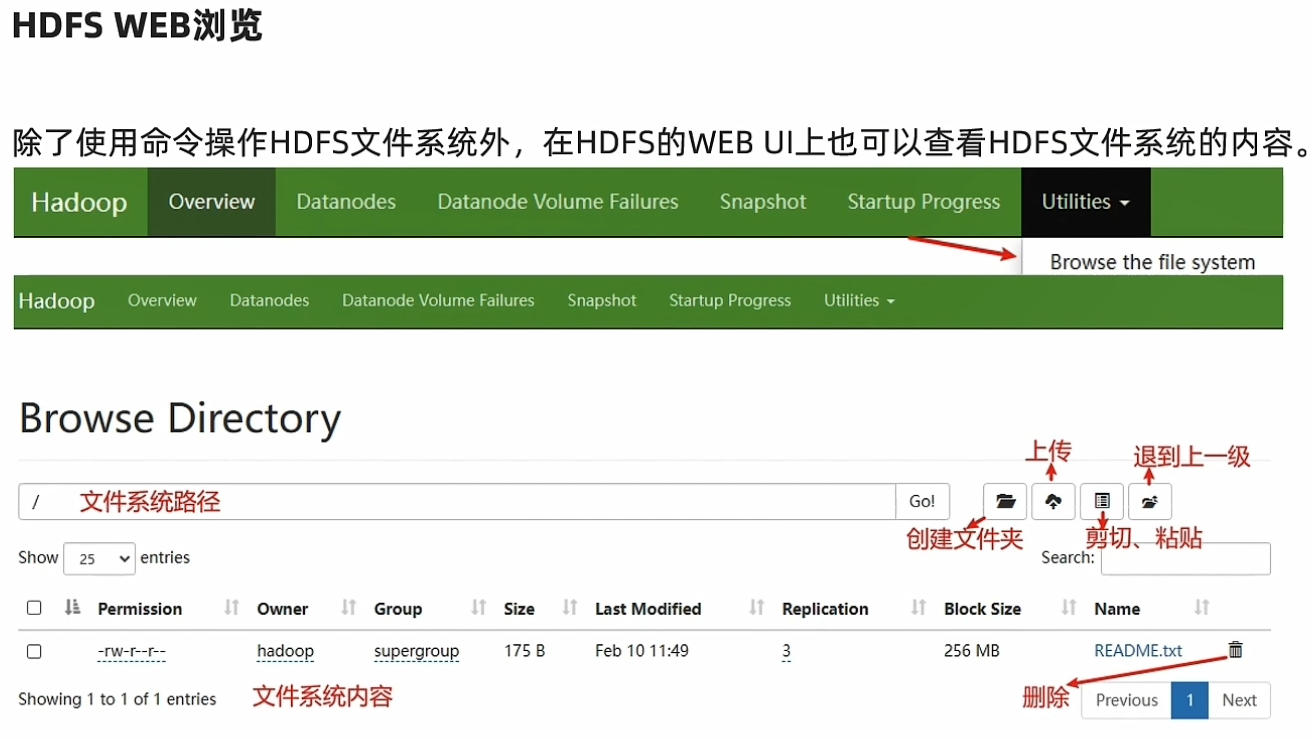

HDFS权限问题
![]()

3.3.4 HDFS客户端
Big Data Tools插件


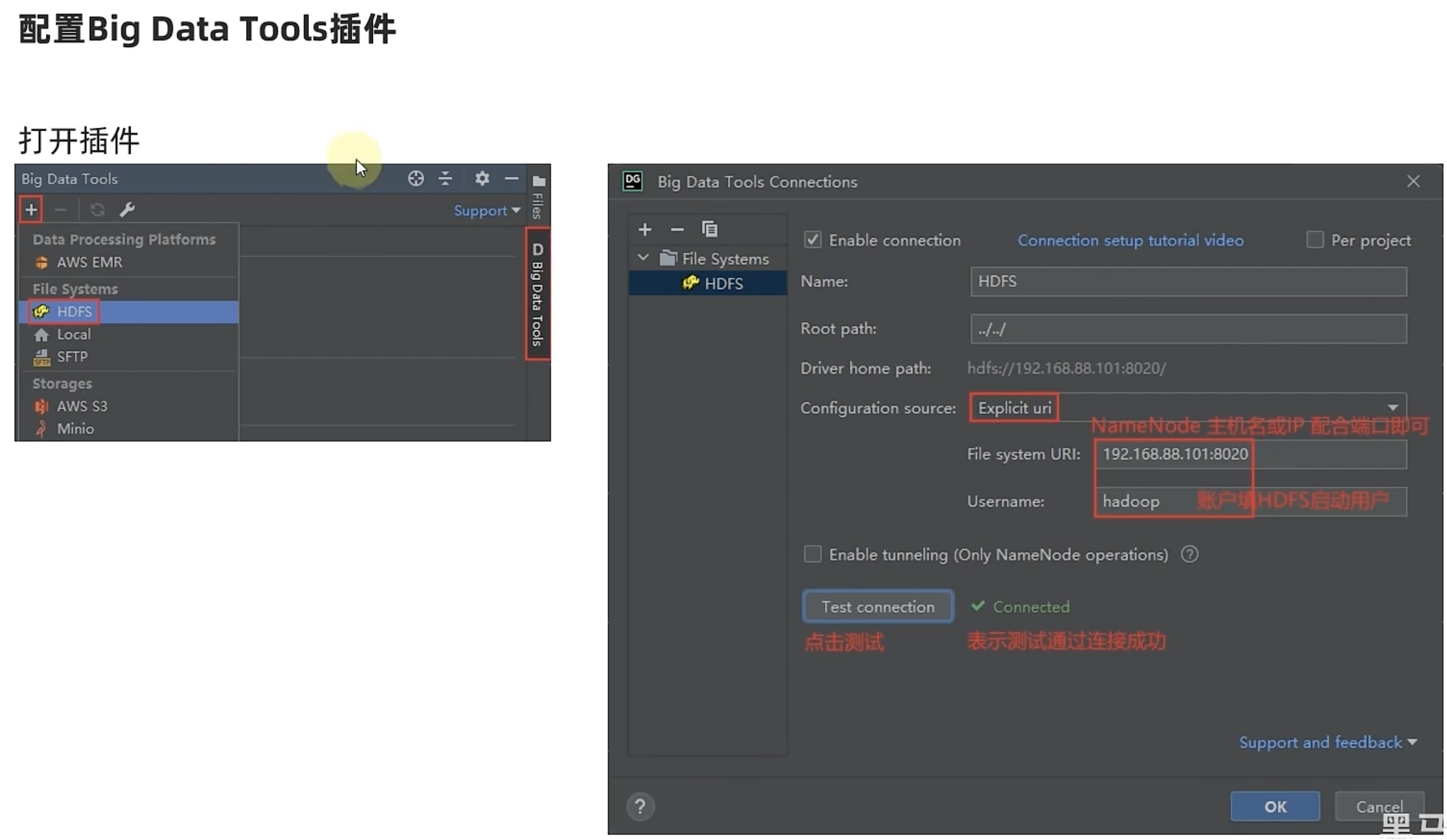
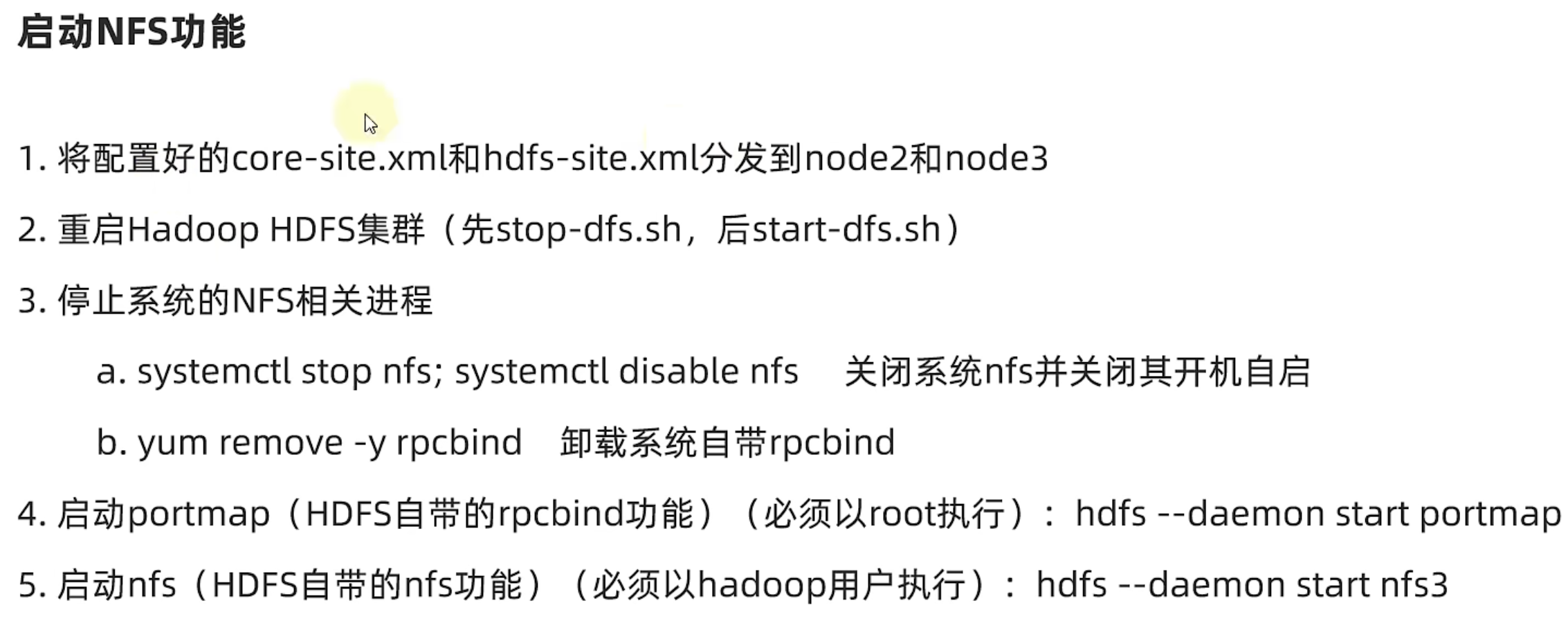
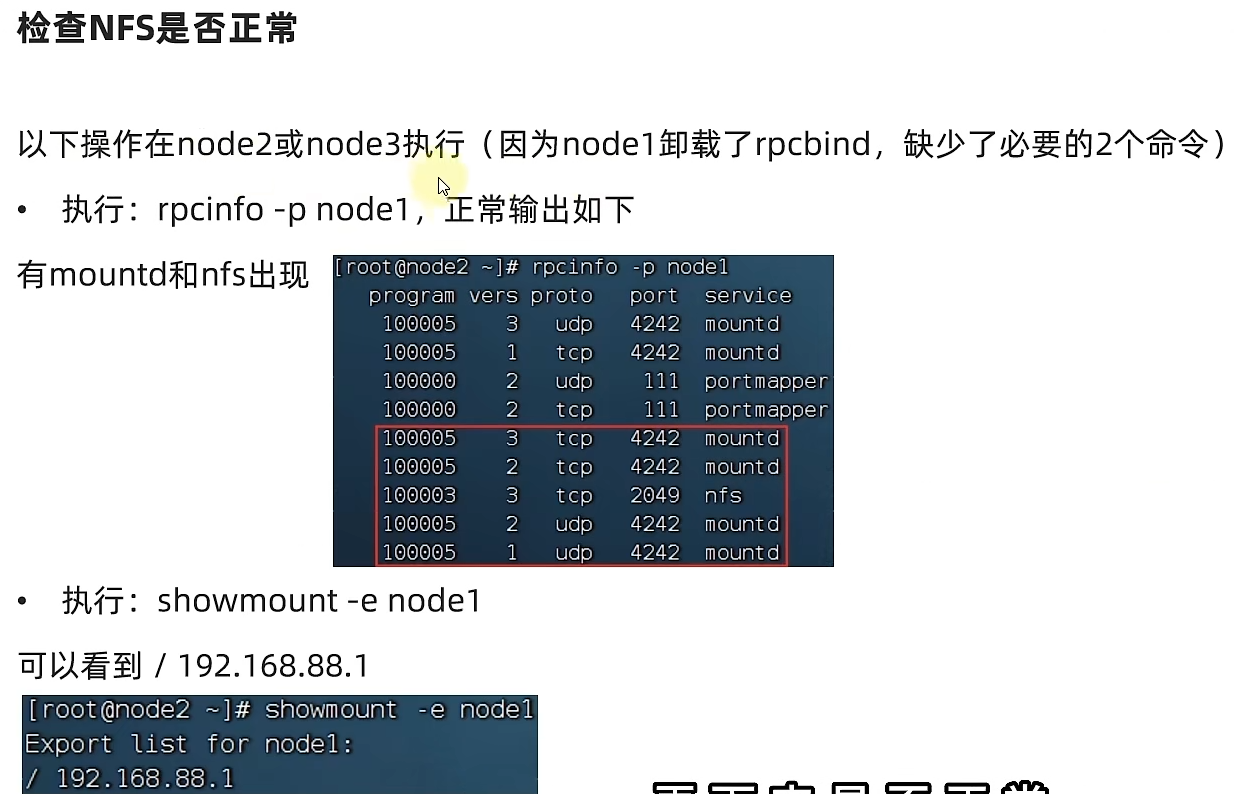
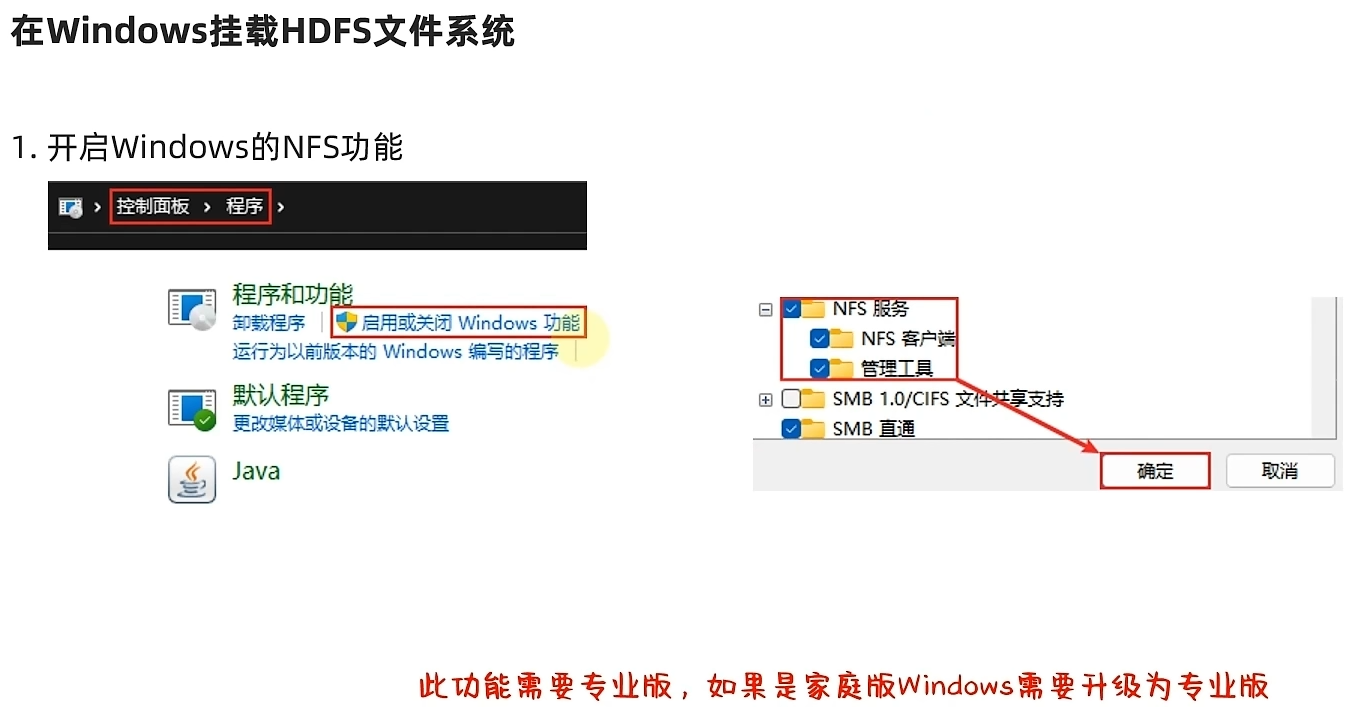
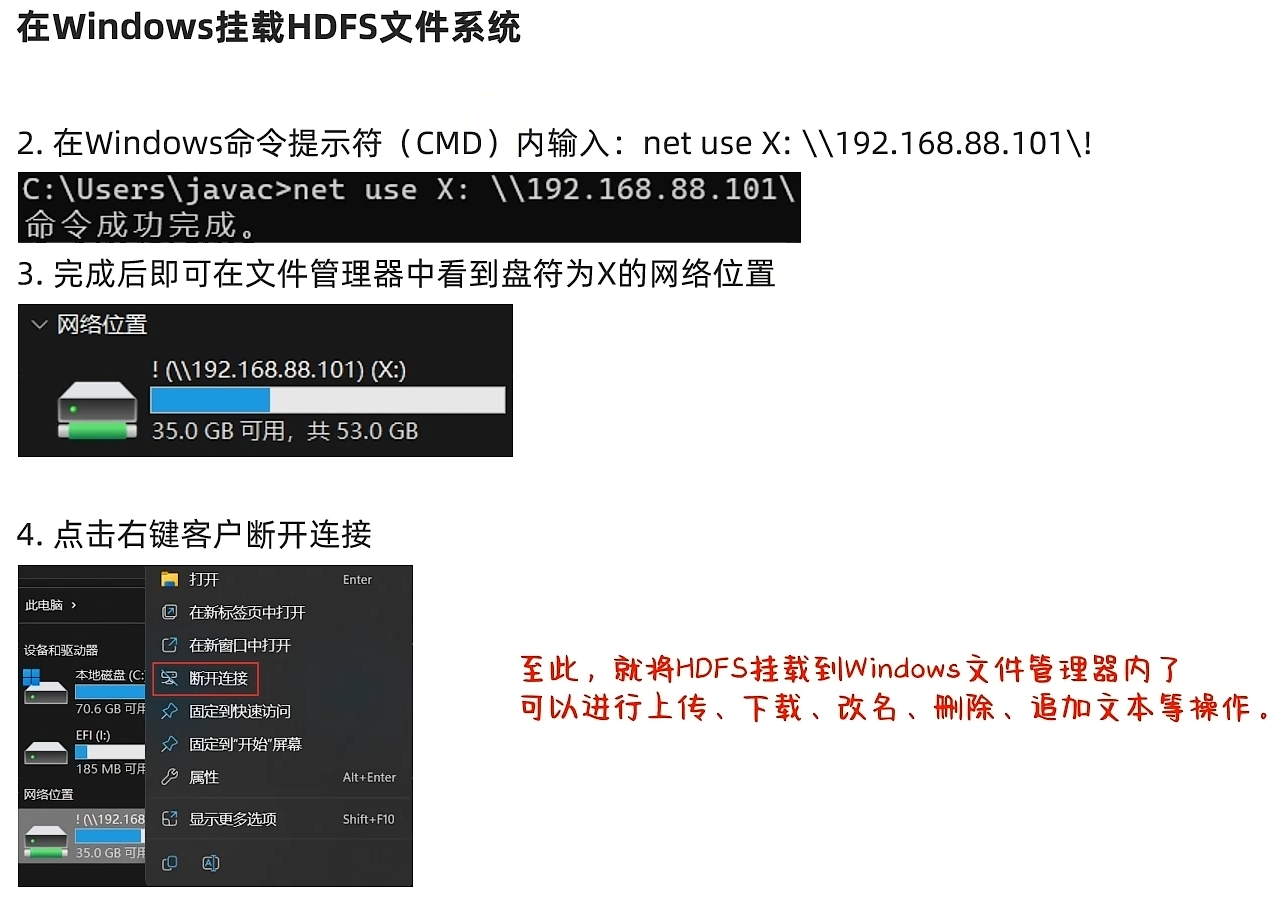
通过NFS网关将HDFS挂载到本地系统
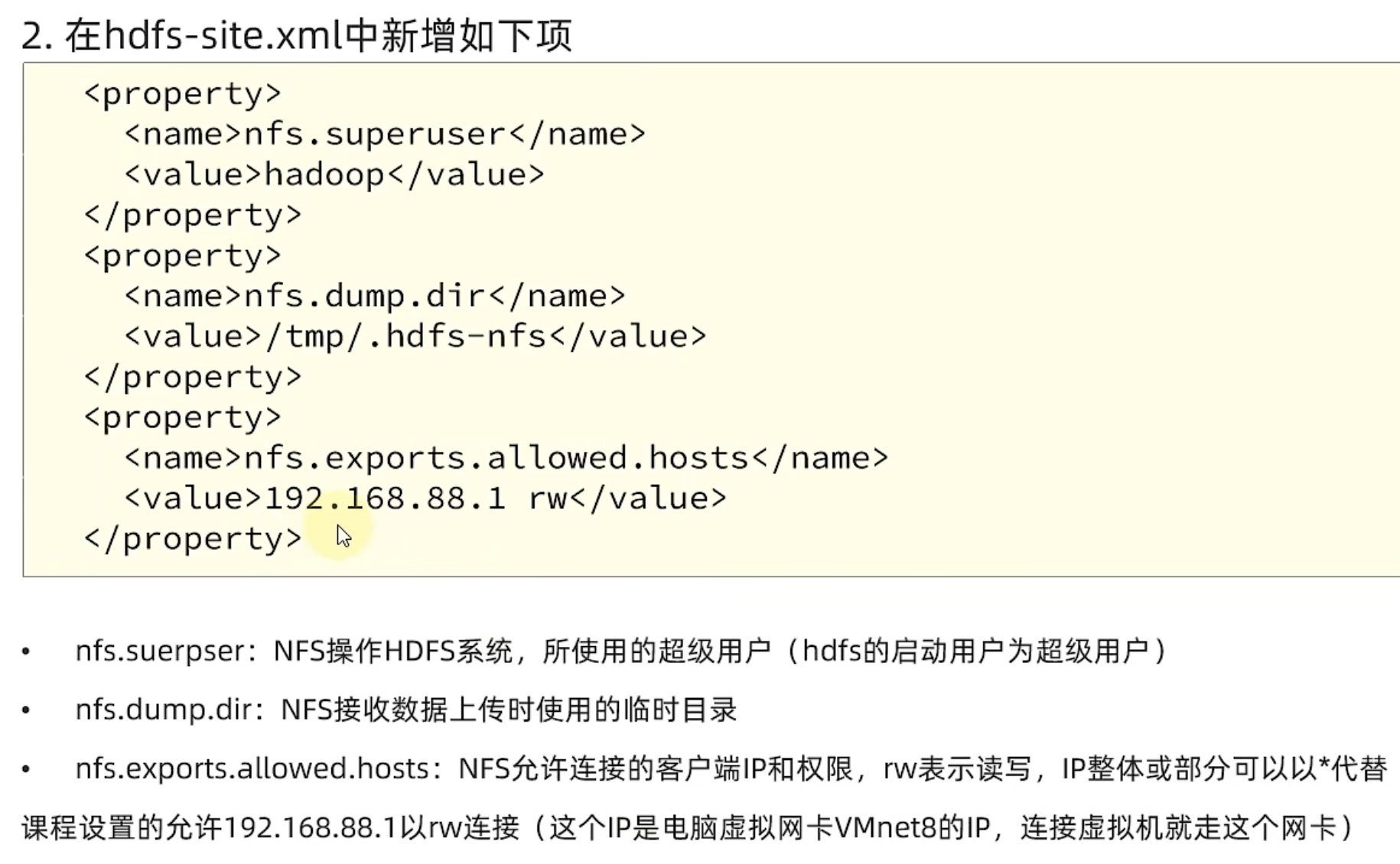
HDFS提供了基于NFS(Network File system)的插件,可以对外提供NFS网关,供其它系统挂载使用。
NFS 网关支持 NFSv3,并允许将 HDFS 作为客户机本地文件系统的一部分挂载,现在支持:上传、下载、删除、追加内容

3.4 HDFS的API操作(Java编程)
(1)环境准备,将下载的hadoop文件夹放置在开发主机(windows电脑)
(2)配置HADOOP_HOME及路径Path系统环境变量
(3)启动程序
(4)在 IDEA 中创建一个 Maven 工程 HdfsClientDemo,并导入相应的依赖坐标

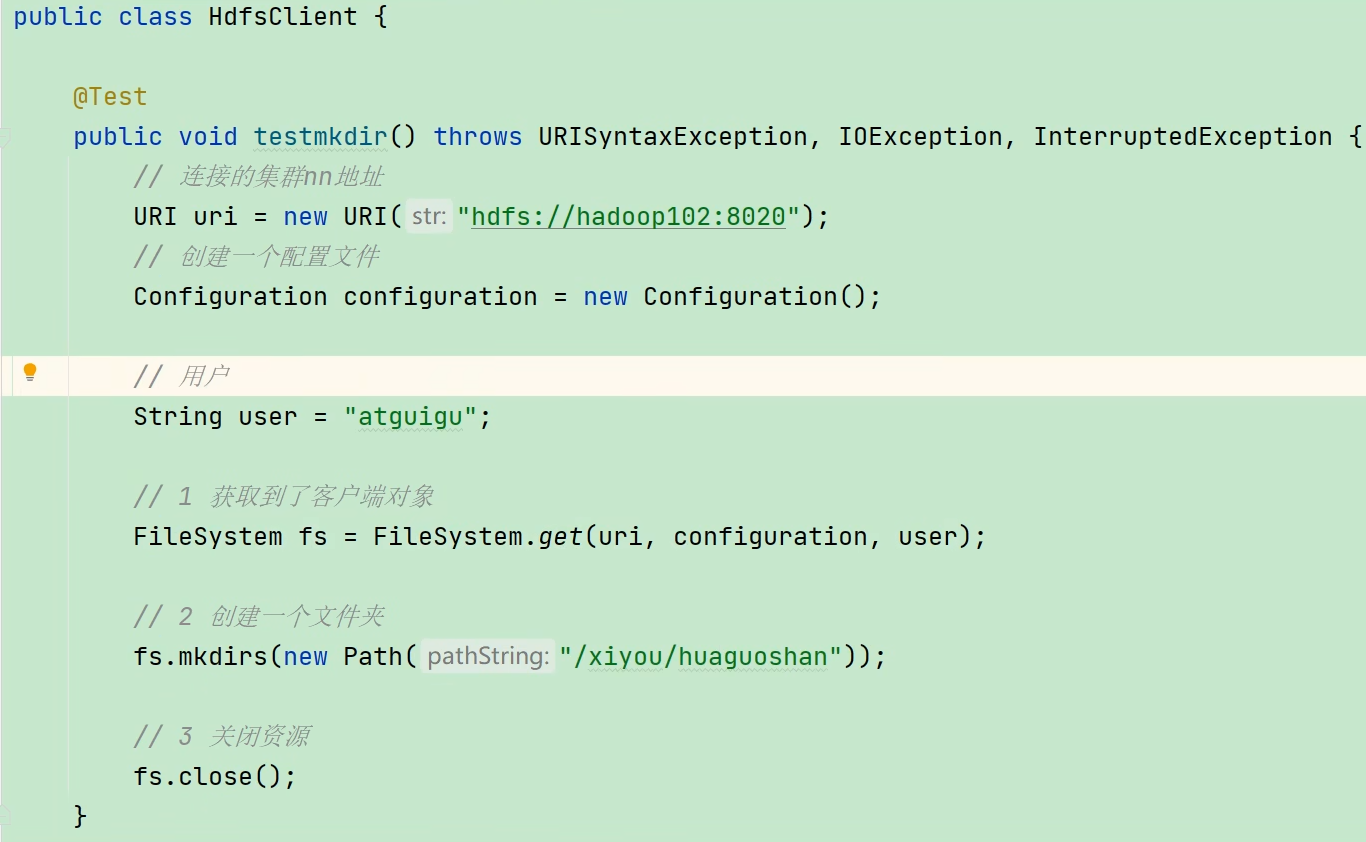
(5)创建 HdfsClient 类进行测试
3.4.1 API 参数的优先级
参数优先级排序:(1)客户端代码中设置的值 > (2)ClassPath 下的用户自定义配置文件 > (3)然后是服务器的自定义配置(xxx-site.xml) > (4)服务器的默认配置(xxx-default.xml)
3.5 HDFS的存储
3.5.1 HDFS的存储原理(文件块)
分布式存储:每个服务器(节点)存储文件的一部分
问题:文件大小不一,不利于统一管理
解决办法:设定同一的管理单位,block块(HDFS最小存储单位,256MB,可以修改)
问题:如果丢失或损坏了某个block块
解决:通过多个副本(备份)解决,HDFS默认每个block块有2个(可修改)备份,每个副本都存储到其他服务器。(每台主机最多存一份文件,如果副本数设置数大于集群主机数,则只存与集群数相等的副本,若再增加节点,则会再自动创建对应的副本)

这个设置表示总共有3 个block,也就是有两个副本备份



3.5.2 NameNode 元数据
问题:大文件被分成多个block块,hadoop是如何记录和整理文件和block块之间的关系?
这个问题由 NameNode 节点基于一批 edits 文件和一个 fsimage 文件负责整个文件系统的管理和维护。
edits文件:是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block。随着操作增加,为避免出现超大edits文件,会存在多个edits文件,保证检索性能。
fsimage 文件:对于同一文件的多次操作会进行合并,得到最终结果。将全部edits文件合并后即可得到一个FSImage文件。fsimage 文件记录的是某个时间点下整个文件系统的状态。

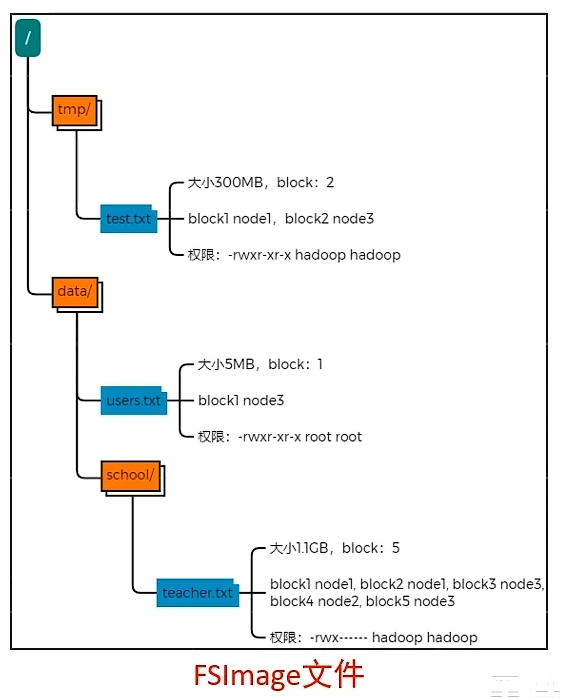


元数据的合并是由 SecondaryNameNode 做的,它通过http从NameNode拉取数据,合并完成后在发回NameNode。
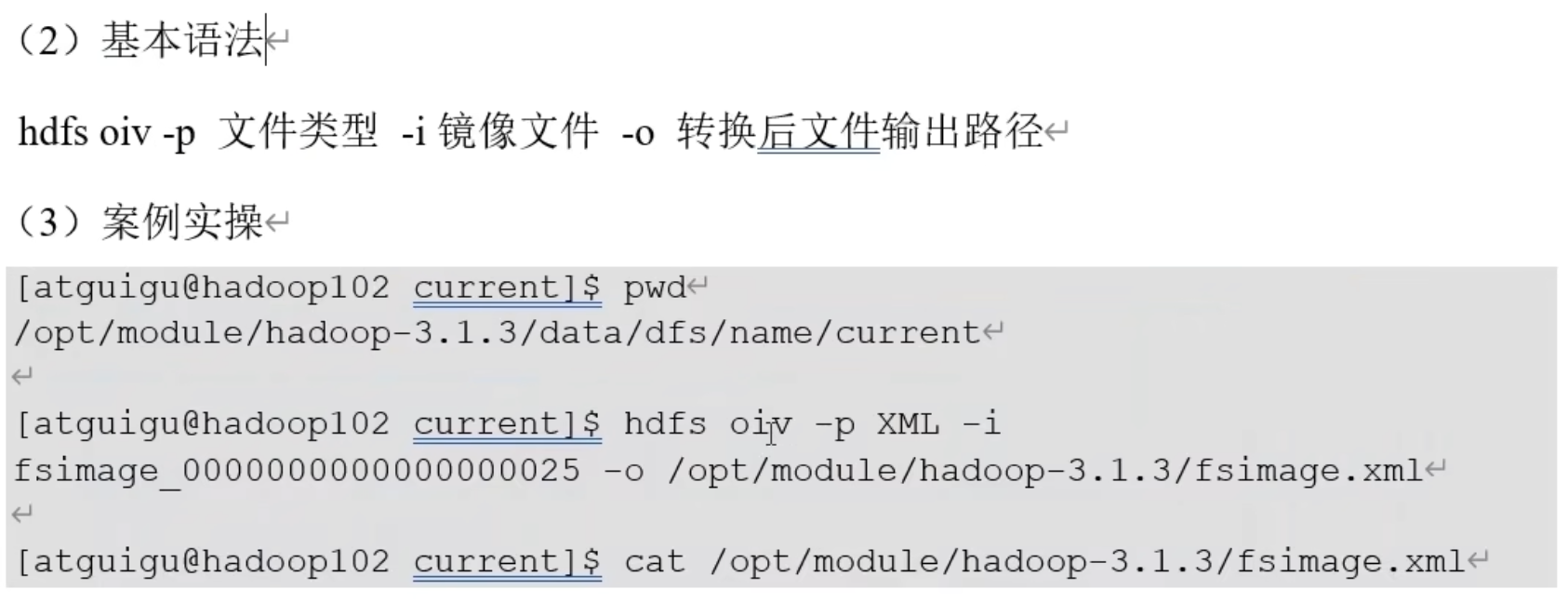
查看 fsimage 文件:
查看 edits 文件:

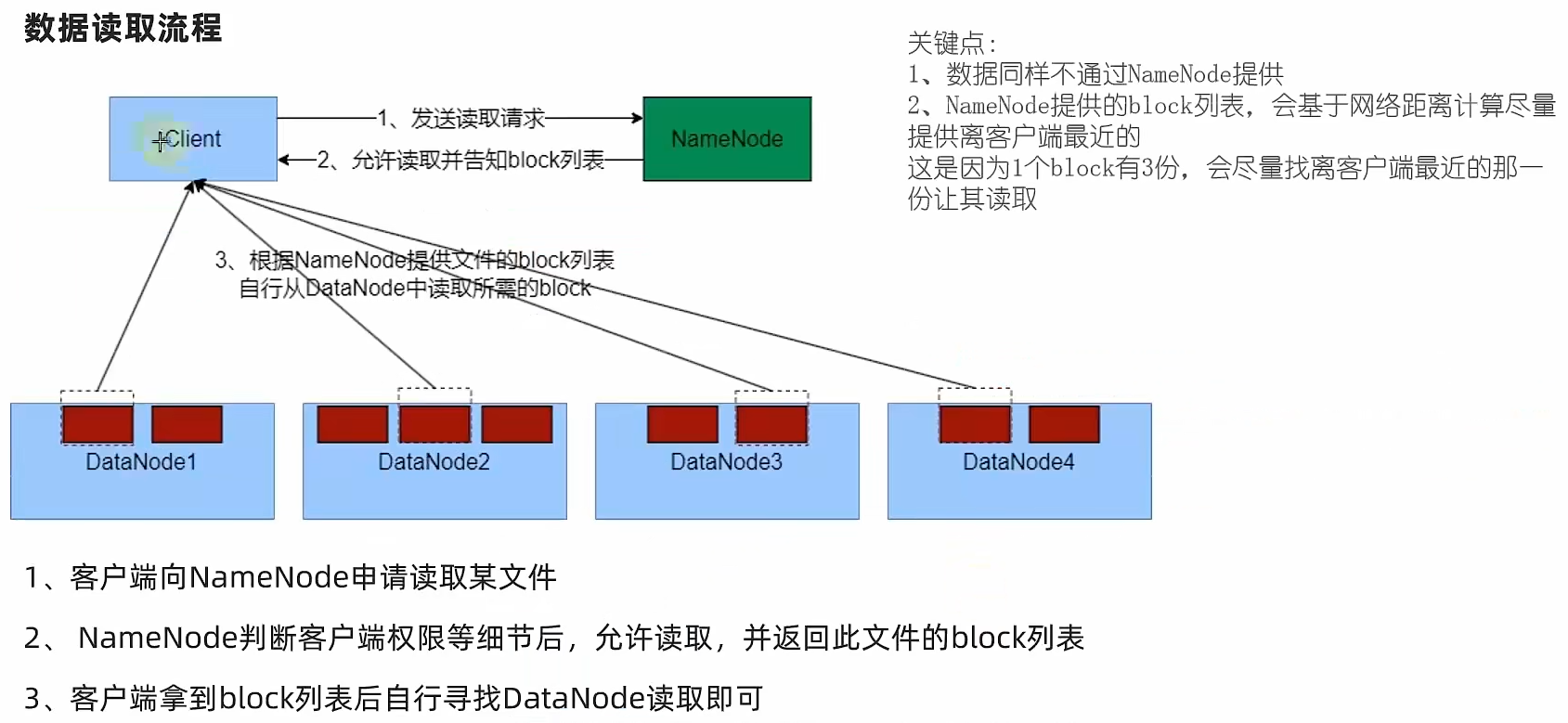
3.5.3 HDFS数据的读写流程
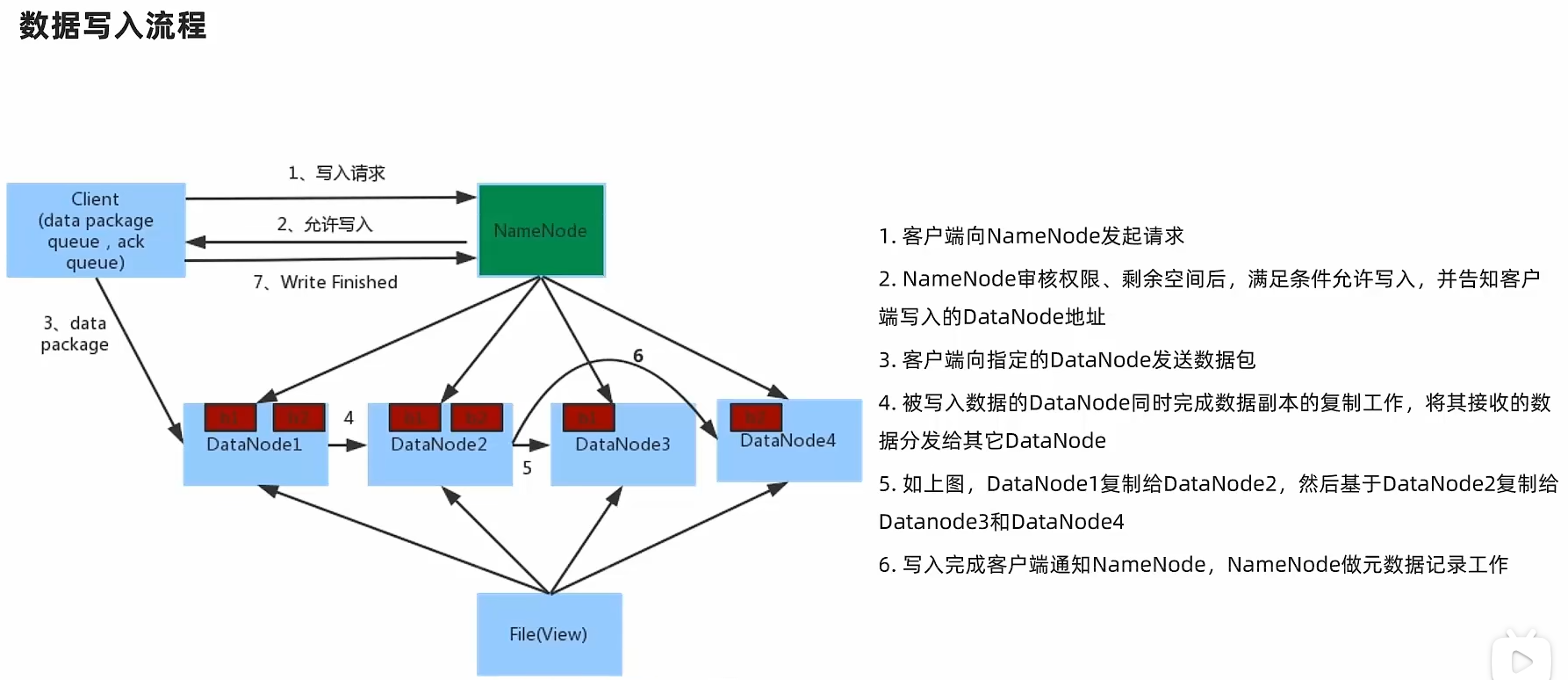

副本存储节点选择(以三个副本为例):
第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本在另一个机架的随机一个节点
第三个副本在第二个副本所在机架的随机节点
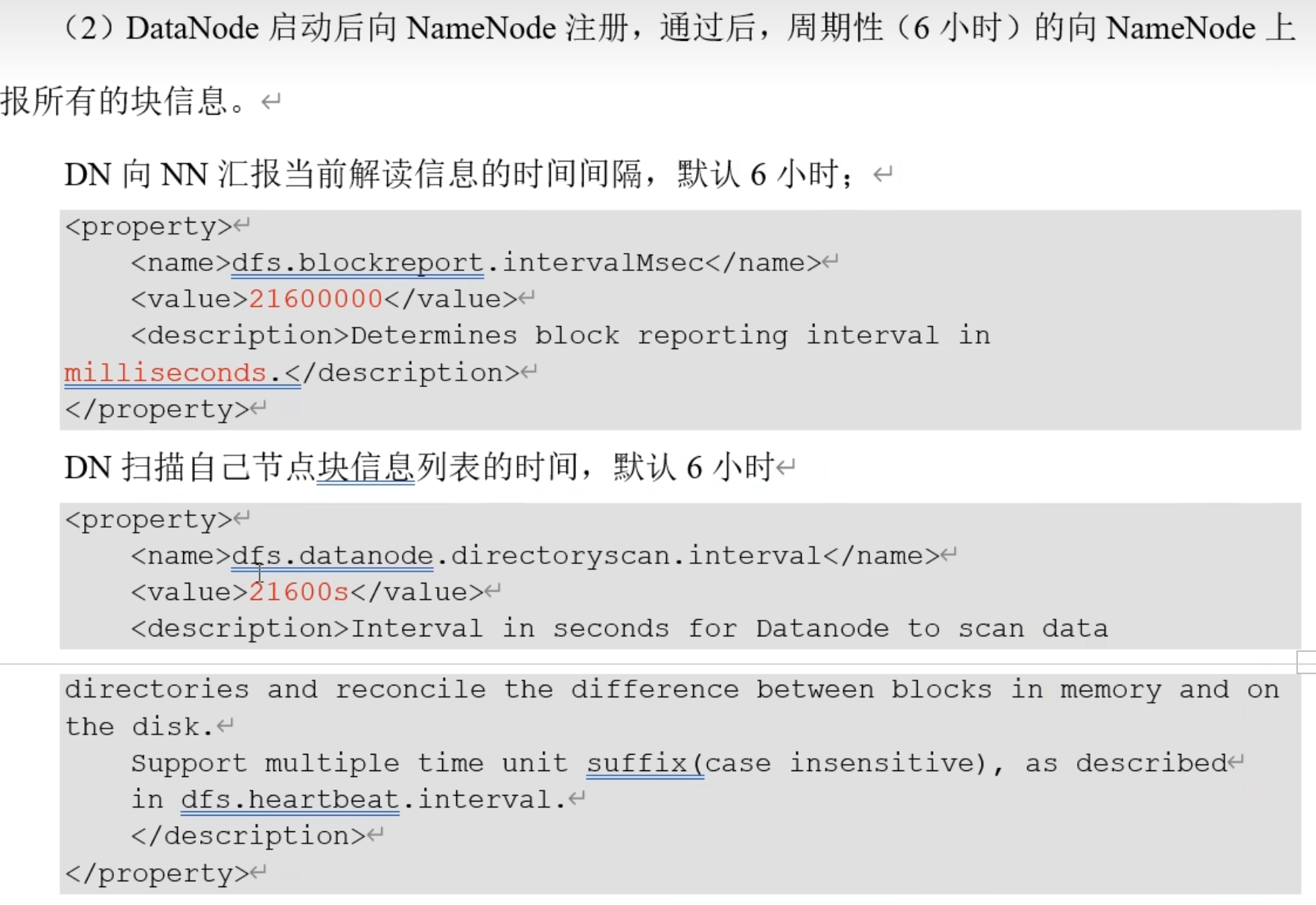
3.5.4 DataNode 的工作机制
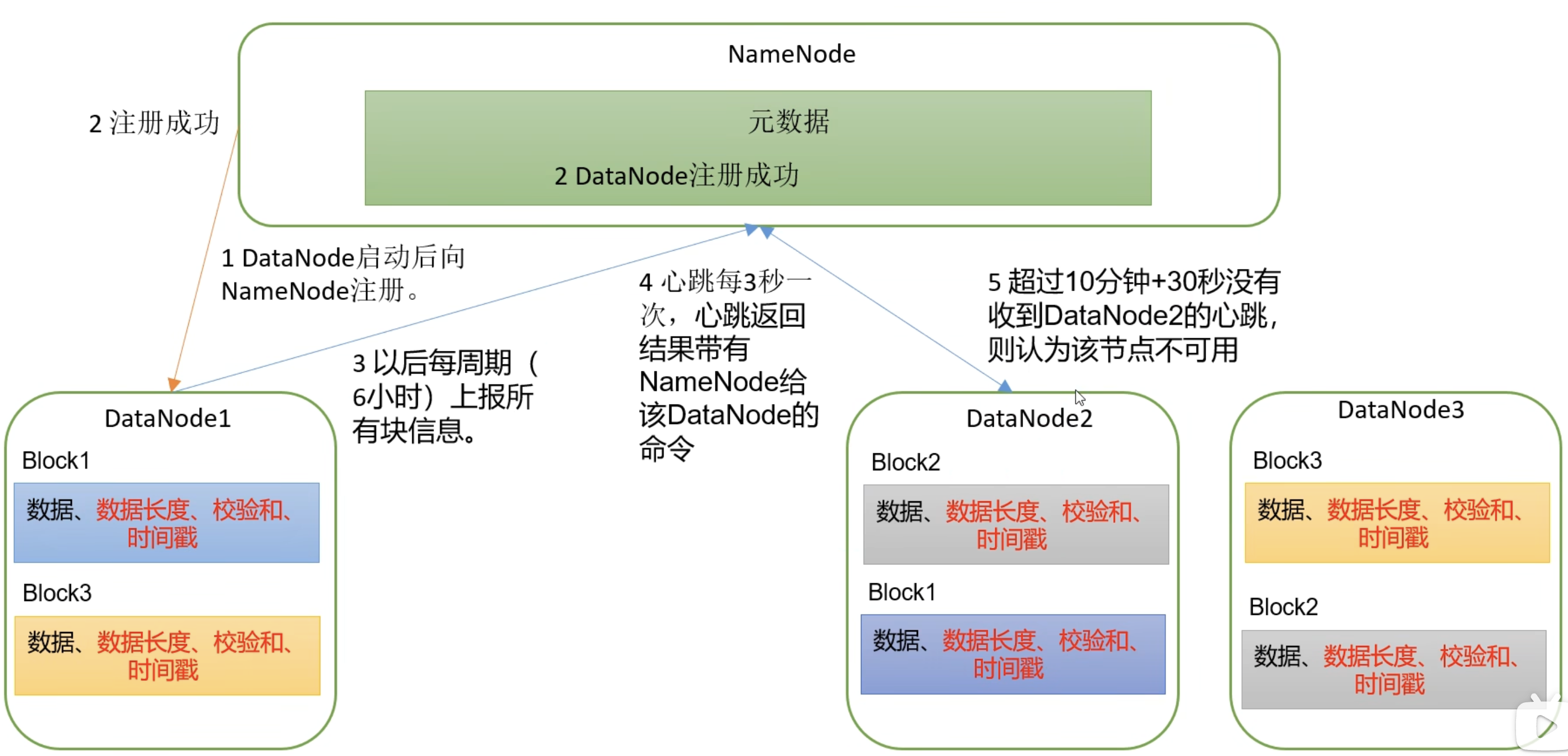
一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳)。
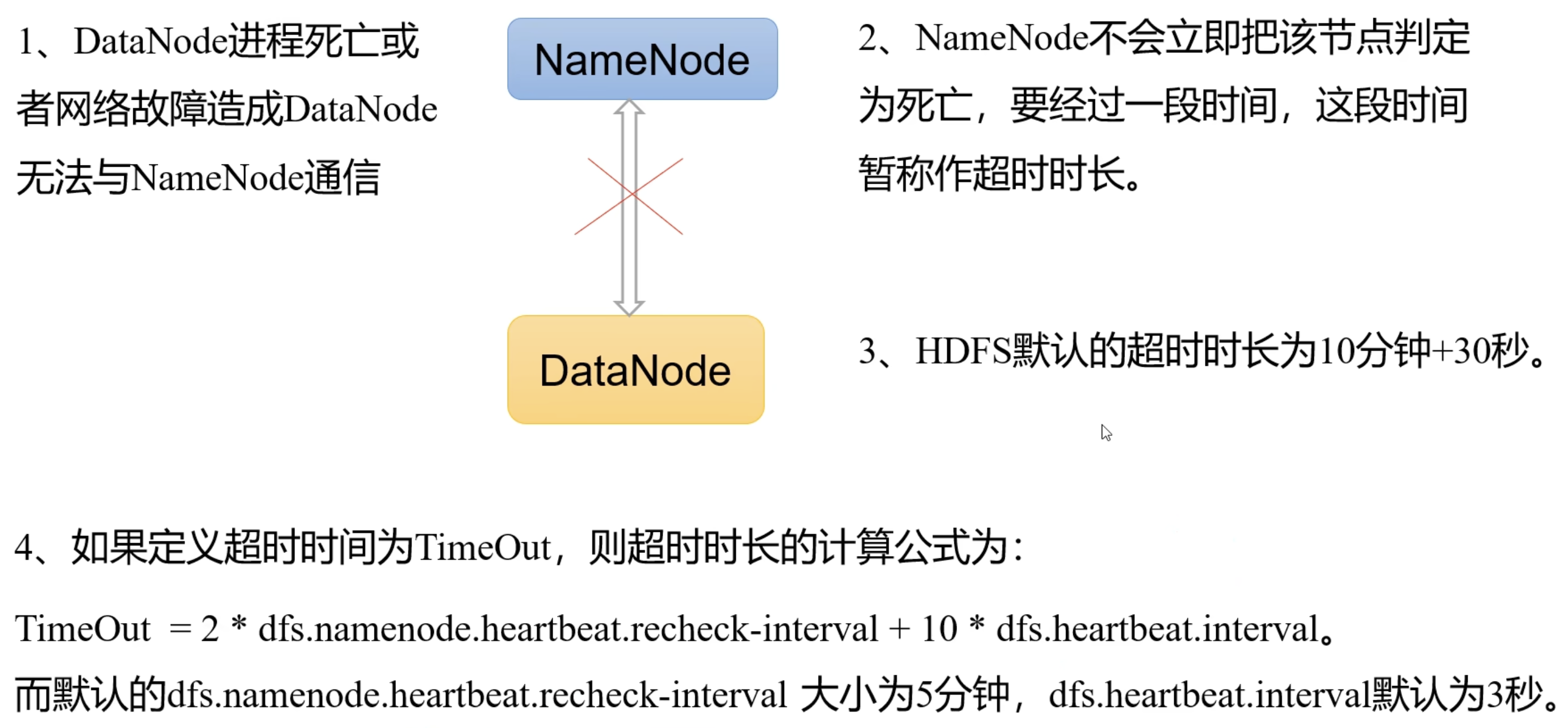
3.5.5 数据完整性



