【学习笔记】Py网络爬虫学习记录(更新到selenium)_slbvpv
目录
一、入门实践——爬取百度网页
二、网络基础知识
1、两种渲染方式
2、HTTP解析
三、Request入门
1、get方式 - 百度搜索/豆瓣电影排行
2、post方式 - 百度翻译
四、数据解析提取三种方式
1、re正则表达式解析
(1)常用元字符
(2)常用量词
(3)贪婪匹配和惰性匹配
(4)re模块
(5)re实战1:自定义爬取豆瓣排行榜
(6)re实战2:爬取电影天堂
2、Bs4解析
(1)创造一个beautifulsoup对象
(2)获取标签/文本
(3)获取文本
(4)标签定位
(5)Bs4实战:爬取图片网站
3、Xpath解析
(1)Xpath 选取节点
(2)使用Xpath小技巧
(3)Xpath实战:爬取猪八戒网
五、selenium
1、环境搭建
2、基本操作
(1)引入expected_condition类和WebDriverWait类
(2)点击某标签
(3)提取数据信息
3、窗口之间切换
4、无头浏览器
一、入门实践——爬取百度网页
from urllib.request import urlopenurl = \"http://www.baidu.com\"resp = urlopen(url)with open(\"mybaidu.html\", mode=\"w\",encoding=\"utf-8\") as f: # 使用with语句打开(或创建)一个名为\"mybaidu.html\"的文件 # 打开模式为写入(\"w\"),编码为UTF - 8(\"utf-8\") # 文件对象被赋值给变量f # with语句确保文件在代码块结束后会自动关闭 f.write(resp.read().decode(\"utf-8\"))这段代码的功能是从百度首页获取HTML内容,并将其保存到本地文件\"mybaidu.html\"中
爬取结果 ↓(被禁了哈哈)

二、网络基础知识
1、两种渲染方式
服务器渲染:
- 在服务器就直接把数据和html整合在一起,统一返回给浏览器在页面源代码中能看到数据
客户端渲染:
- 第一次请求只要一个html骨架
- 第二次请求拿到数据,进行数据展示在页面源代码中,看不到数据
2、HTTP解析
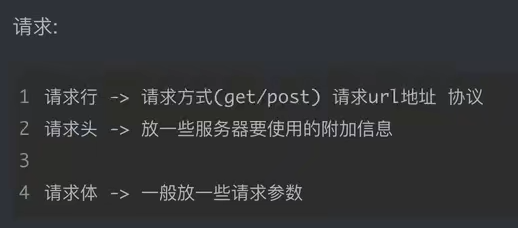
请求头中最常见重要内容(爬虫需要)
- User-Agent身份标识:请求载体的身份标识(用啥发送的请求)
- Referer防盗链:(这次请求是从哪个页面来的?反爬会用到)
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
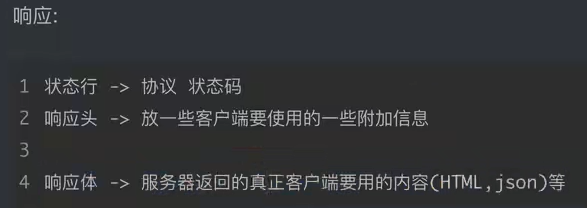
响应头中一些重要的内容
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
- 各种莫名其妙的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬)
三、Request入门
1、get方式 - 百度搜索/豆瓣电影排行
import requestsquery = input(\"请输入想查询的内容!\")url = f\"https://www.baidu.com/s?wd={query}\"resp = requests.get(url)dic = {\"User-Agent\":\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit\"}resp = requests.get(url=url, headers=dic) #伪装成浏览器print(resp.text)resp.close()爬了一下百度,成功啦!
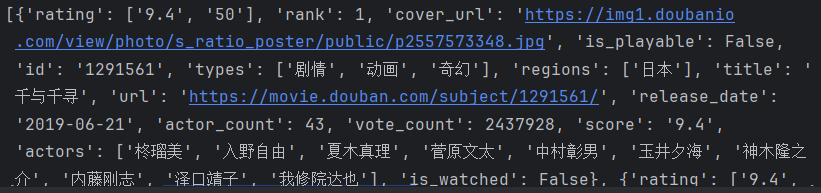
import requestsurl = f\"https://movie.douban.com/j/chart/top_list\"parm= { \"type\": 25, \"interval_id\": \"100:90\", \"action\":\"\", \"start\": 0, \"limit\": 20,}dic={\"User-Agent\":\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit\"}resp = requests.get(url=url,params=parm,headers=dic)print(resp.json())resp.close()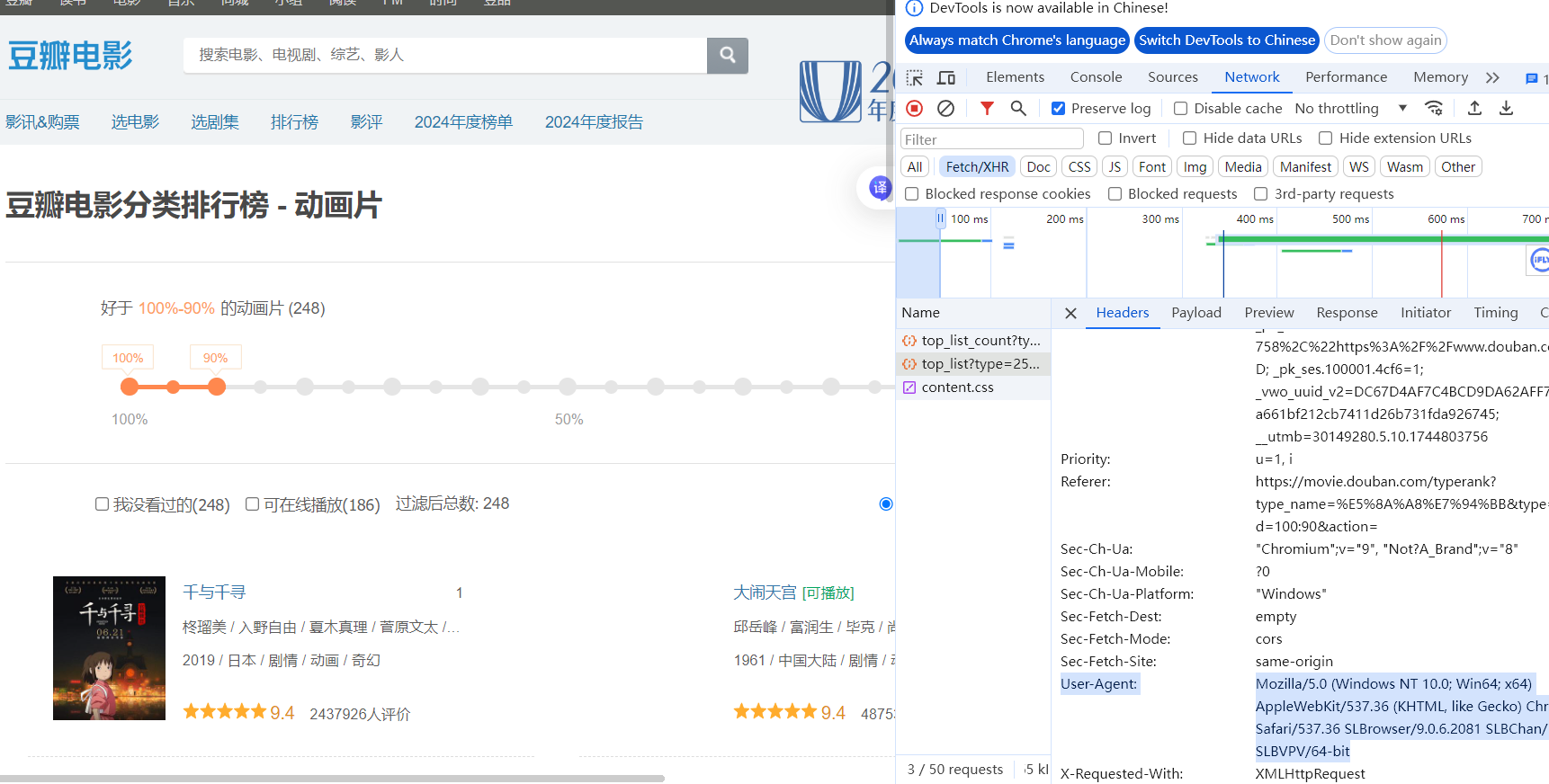
2、post方式 - 百度翻译
发送post请求,发送的数据必须放在字典里,通过data参数进行传递
import requestss = input(\"请输入想查询的内容!\")url = f\"https://fanyi.baidu.com/sug\"dat = { \"kw\":s}resp = requests.get(url)#发送post请求,发送的数据必须放在字典里,通过data参数进行传递resp = requests.post(url=url,data=dat)print(resp.json()) resp.close()
四、数据解析提取三种方式
上述内容算入门了抓取整个网页的基本技能,但大多数情况下,我们并不需要整个网页的内容,只是需要那么一小部分,这就涉及到了数据提取的问题。
三种解析方式:
- re解析
- bs4解析
- xpath解析
1、re正则表达式解析
正则表达式是一种使用表达式的方式对字符串进行匹配的语法规则
抓取到的网页源代码本质上就是一个超长的字符串,想从里面提取内容,用正则再合适不过
在线正则表达式测试
(1)常用元字符
. 匹配除换行符以外的任意字符 \\w 匹配字母或数字或下划线 \\s 匹配任意的空白符 \\d 匹配数字 \\n 匹配一个换行符 \\t 匹配一个制表符 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \\W 匹配非字母或数字或下划线 \\D
匹配非数字 \\S 匹配非空白符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示一个组 [...] 匹配字符组中的字符 [a-zA-Z0-9] [^...] 匹配除了字符组中字符的所有字符
(2)常用量词
* 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
(3)贪婪匹配和惰性匹配
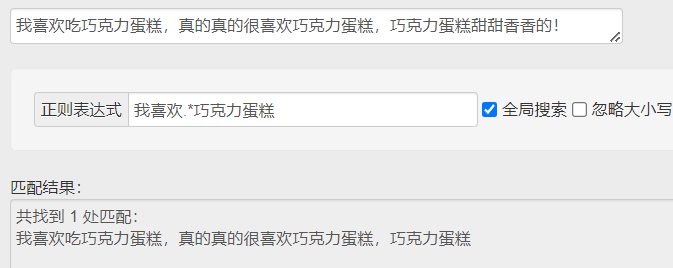
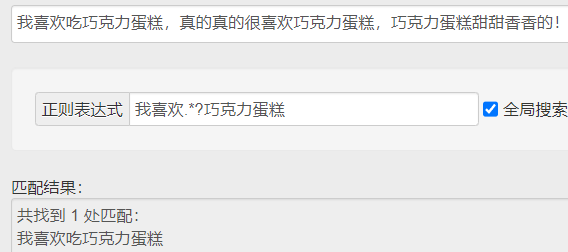
.* 贪婪匹配(尽可能多的匹配) .*? 惰性匹配(尽可能少的匹配)
↑ 贪婪匹配就是尽可能长地匹配
↑ 惰性匹配就是尽可能短地匹配
(4)re模块
- findall:匹配字符串中所有符合正则的内容
- finditer:匹配字符串中所有内容【返回的是迭代器】,从迭代器中拿到内容要.group
import re#findall:匹配字符串中所有符合正则的内容list = re.findall(r\"\\d+\",\"我的学号是20250102,他的学号是20240105\")print(list)#finditer:匹配字符串中所有内容【返回的是迭代器】,从迭代器中拿到内容要.groupit = re.finditer(r\"\\d+\",\"我的学号是20250102,他的学号是20240105\")for i in it: print(i.group())
- search:找到一个结果就返回,返回的结果是match对象,拿数据要.group()
- match:从头开始匹配
- 预加载正则表达式
import re#search:找到一个结果就返回,返回的结果是match对象,拿数据要.group()s = re.search(r\"\\d+\",\"我的学号是20250102,他的学号是20240105\")print(s.group())#match:从头开始匹配m = re.search(r\"\\d+\",\"20250102,他的学号是20240105\")print(s.group())#预加载正则表达式obj = re.compile(r\"\\d+\") #相对于把头写好,后面直接补上字符串ret = obj.finditer(\"我的学号是20250102,他的学号是20240105\")for i in ret: print(i.group())
- ?P正则表达式:给提取的内容起别名,例如?P.*?,给.*?匹配到的内容起别名name
s = \"\"\"凯蒂猫史努比杰瑞小鲤鱼\"\"\"obj = re.compile(r\"<div class=\'(?P.*?)\'><span id=\'(?P.*?)\'>(?P.*?)
(5)re实战1:自定义爬取豆瓣排行榜
通过request拿到页面源代码,用re正则匹配提取数据

import reimport csvimport requests#request获取页面源代码url = \"https://movie.douban.com/top250?start=%d&filter=\"num = int(input(\"请问您想要查询豆瓣电影Top榜单前多少页的信息:\"))for i in range(0,num): #第1页=0*25,第二页=1*25…… range范围[a,b) i=i*25new_url = format(url%i) #用值i替换url中的变量,形成新的urldic = {\"User-Agent\":\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit\"}resp = requests.get(url=new_url,headers=dic)page_content = resp.text#re提取数据obj = re.compile(r\'.*?.*?(?P.*?)\' r\'.*?(?P.*?) .*?
(?P.*?) .*?\' r\'\' r\'.*?(?P.*?)人评价\',re.S)res = obj.finditer(page_content)f = open(\"movie.csv\",\"a\",encoding=\"utf-8\")csvWriter = csv.writer(f) #将文件转为csv写入for item in res: dic = item.groupdict() #把获取的数据转换成字典 dic[\'year\'] = dic[\'year\'].strip() #去除字符串首尾的指定字符 dic[\'daoyan\'] = dic[\'daoyan\'].strip() csvWriter.writerow(dic.values())f.close()resp.close()print(\"over!\")
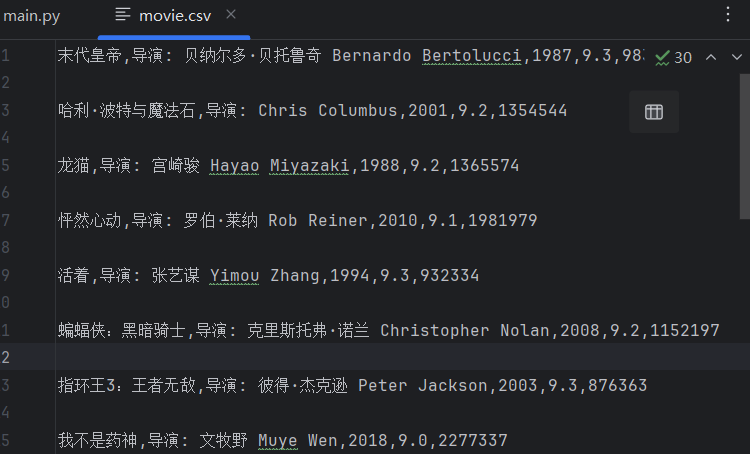
(6)re实战2:爬取电影天堂


import reimport csvfrom urllib.parse import urljoinimport requests#request获取页面源代码domain_url = \"https://dydytt.net/index.htm\"dic = {\"User-Agent\":\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit\"}resp = requests.get(url=domain_url,headers=dic,verify=False)resp.encoding = \"gb2312\"main_page_ct = resp.text#re匹配数据obj1 = re.compile(r\"最新电影更新.*?(?P.*?)
\",re.S)obj2 = re.compile(r\"<a href=\'(?P.*?)\'>\",re.S)obj3 = re.compile(r\'(?P.*?) \' r\'.*?磁力链下载器:<a href=\"(?P.*?) target=\"_blank\" title=\"qBittorrent\">\',re.S)res1 = obj2.finditer(main_page_ct)f = open(\"dyttmovie.csv\",\"a\",encoding=\"utf-8\")csvWriter = csv.writer(f) #将文件转为csv写入#1.提取页面子链接res2 = obj2.finditer(main_page_ct)child_href_list = []for i in res2: #拼接子页面连接 child_url = urljoin(domain_url,i.group(\'href\')) child_href_list.append(child_url)#2.提取子页面内容for i in child_href_list: child_resp = requests.get(url=i,headers=dic,verify=False) #获取子页面url child_resp.encoding = \'gb2312\' res3 = obj3.search(child_resp.text) #提取子页面数据 tdic = res3.groupdict() csvWriter.writerow(tdic.values()) #存入文件f.close()resp.close()print(\"over!\")
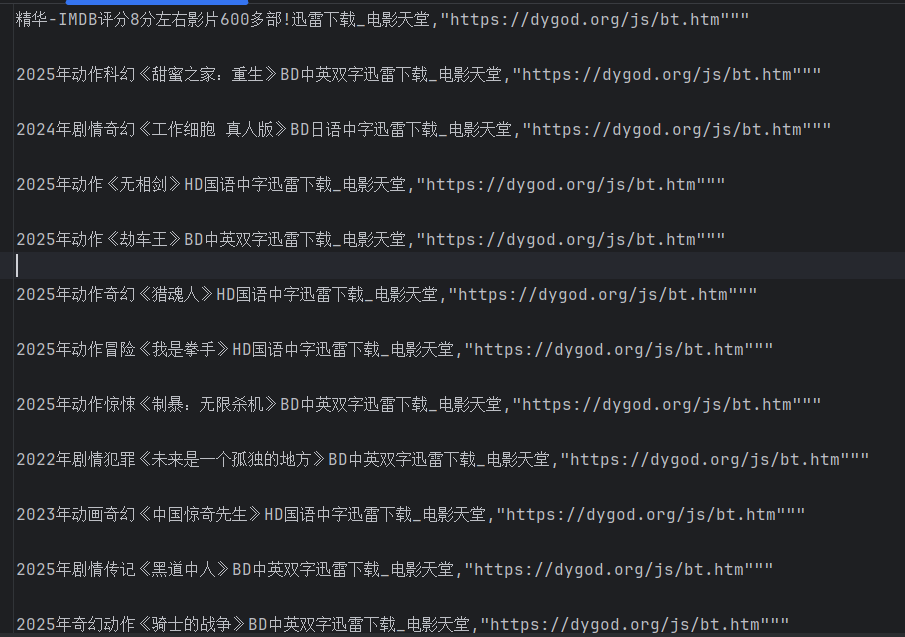
2、Bs4解析
Beautiful Soup 4 (BS4) 是 Python 的 HTML/XML 解析库,用于快速从网页提取数据,支持多种解析器,适合爬虫和数据抓取
Bs4解析数据原理:
- 实现一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
- 通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
(1)创造一个beautifulsoup对象
soup = BeautifulSoup(html, “html.parser”)

(2)获取标签/文本
# 获取第一个标签p_tag = soup.p# 获取所有标签a_tags = soup.find_all(\'a\')# 获取标签名称tag_name = p_tag.name# 获取标签属性tag_attrs = p_tag.attrstag_class = p_tag[\'class\'] # 获取class属性
(3)获取文本
# 获取标签内文本text = p_tag.text # 包含所有子标签的文本text = p_tag.string # 仅当前标签的直接文本
(4)标签定位
# 查找第一个divdiv = soup.find(\'div\')# 查找所有class为\"example\"的divdivs = soup.find_all(\'div\', class_=\'example\')# 多条件查找items = soup.find_all(\'a\', {\'class\': \'external\', \'target\': \'_blank\'})# 限制查找数量first_three = soup.find_all(\'p\', limit=3)
(5)Bs4实战:爬取图片网站
第一步:获取主页面源代码,通过beautifulsoup生成bs对象,在bs对象中找到子图片的标签(div class=\"taotu-main\"),再在子标签区域定位到a标签,生成list列表
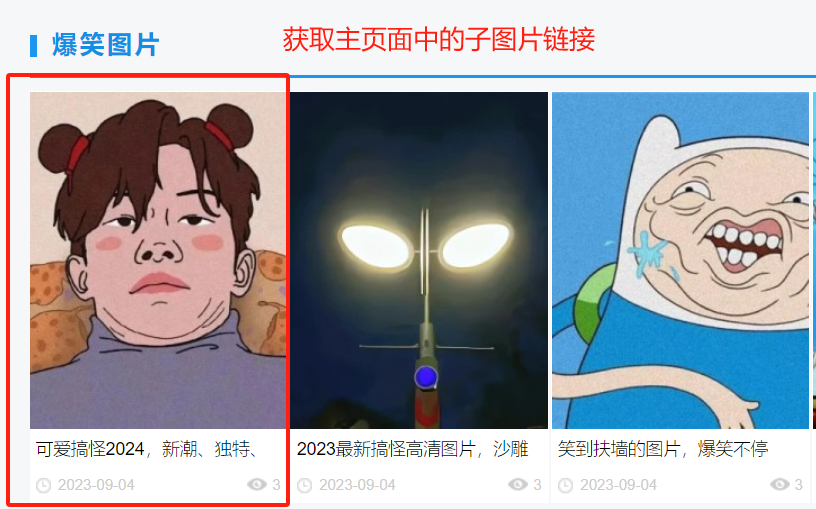

#request获取页面源代码url = \"https://www.umei.cc/gaoxiaotupian/\"dic = {\"User-Agent\":\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit\"}resp = requests.get(url=url,headers=dic)resp.encoding = \"UTF-8\"m_page_ct = resp.text#把主页面源代码交给BeautifulSoup进行处理,生成bs对象m_page = BeautifulSoup(m_page_ct, \"html.parser\")#从bs对象中查找数据a_list = m_page.find(\"div\",class_=\"taotu-main\").find_all(\"a\")#↑ 找到类型为taotu-main的div标签,再在里面找到所有a标签
第二步:list列表内存着所有的a标签,从每个a标签内获取href子链接,拿到子页面源代码并生成bs对象,定位到子链接中图片下载链接(div class=\"big-pic\" - img- src),最后获取图片下载链接进行下载

for i in a_list: #拼接子链接 new_url = urljoin(url,i.get(\"href\")) #拿到子页面源代码 child_page_resp = requests.get(new_url,headers=dic) child_page_resp.encoding = \"UTF-8\" #从子页面获取图片的下载路径 child_page = BeautifulSoup(child_page_resp.text, \"html.parser\") #定位到图片下载链接的标签 p = child_page.find(\"div\",class_=\"big-pic\") img = p.find(\"img\") src = img[\"src\"]#相对于img.get(\"src\") #下载图片 img_resp = requests.get(src,headers=dic) img_name = src.split(\"/\")[-1] #截取url中最后一个/以后的内容 with open(\"img/\"+img_name,\"wb\") as f: f.write(img_resp.content) #把图片内容写入文件 print(\"over!!!!\",img_name) time.sleep(1)
import reimport csvimport timefrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSoup#request获取页面源代码url = \"https://www.umei.cc/gaoxiaotupian/\"dic = {\"User-Agent\":\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit\"}resp = requests.get(url=url,headers=dic)resp.encoding = \"UTF-8\"m_page_ct = resp.text#1.把主页面源代码交给BeautifulSoup进行处理,生成bs对象m_page = BeautifulSoup(m_page_ct, \"html.parser\")#从bs对象中查找数据a_list = m_page.find(\"div\",class_=\"taotu-main\").find_all(\"a\")#↑ 找到类型为taotu-main的div标签,再在里面找到所有a标签for i in a_list: #拼接子链接 new_url = urljoin(url,i.get(\"href\")) #拿到子页面源代码 child_page_resp = requests.get(new_url,headers=dic) child_page_resp.encoding = \"UTF-8\" #从子页面获取图片的下载路径 child_page = BeautifulSoup(child_page_resp.text, \"html.parser\") #定位到图片下载链接的标签 p = child_page.find(\"div\",class_=\"big-pic\") img = p.find(\"img\") src = img[\"src\"]#相对于img.get(\"src\") #下载图片 img_resp = requests.get(src,headers=dic) img_name = src.split(\"/\")[-1] #截取url中最后一个/以后的内容 with open(\"img/\"+img_name,\"wb\") as f: f.write(img_resp.content) #把图片内容写入文件 print(\"over!!!!\",img_name) time.sleep(1)resp.close()print(\"all over!\")
3、Xpath解析
XPath是一种用于在 XML 文档中定位和选择节点的查询语言,也可用于 HTML 文档。
首先在终端安装lxml模块
pip install lxml
(1)Xpath 选取节点
表达式
描述
举例
/
表示从根节点开始绝对路径匹配(严格匹配)
/book/name/text()
找到所有下的内容
//
表示全局搜索,不管节点在文档的哪一层,只要匹配就会被选中(无论多深都能匹配到)
//ul/li//a
找到所有
下
- 里的所有标签
.
选取当前节点
.//span
找到当前节点下所有标签
..
选取当前节点的父节点
//p/../span
找到所有
的父节点里的标签
@
选取属性
//div[@class=\"content\"]
找到所有class=content的
标签
//a/@href
找到所有标签下href属性的内容
contains
用于检查某个属性值或文本内容是否包含指定的子字符串
//div[contains(@class, \'menu\')]
查找class属性包含\'menu\'的div元素
//a[contains(text(), \'登录\')]
查找文本包含\"登录\"的链接
//a[contains(@href, \'product\')]
查找href包含\"product\"的链接
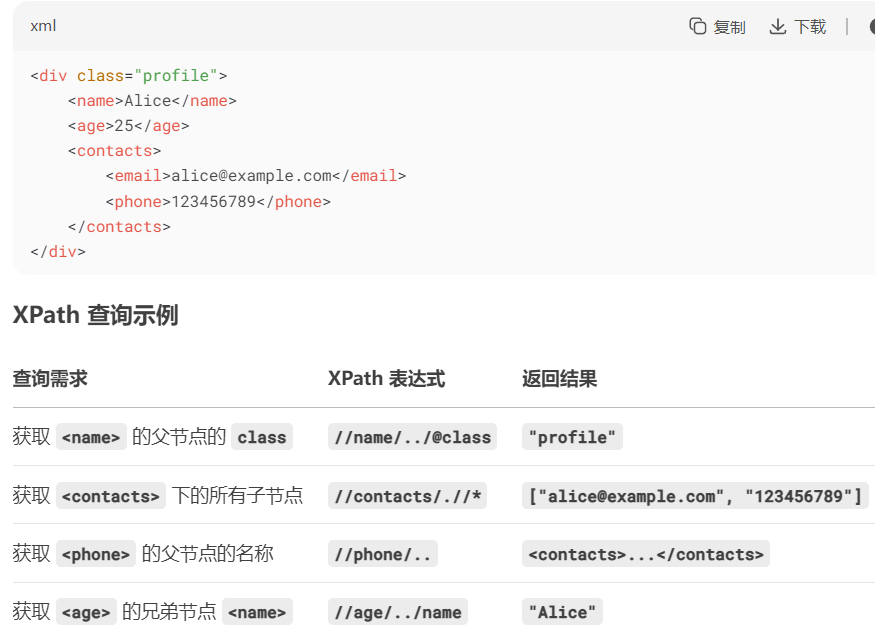
-- 案例1 --
from lxml import etreexml=\"\"\" 1 面包真好吃 2.33 咖喱饭 雷雷 莉莉 木木 嘎嘎 热热 盒盒 容宝宝 容不宝宝 \"\"\" #准备 一个xml文本tree = etree.XML(xml)# / 表示层级,第一个/是根节点,text()拿文本res = tree.xpath(\"/book/name/text()\") #输出[\'面包真好吃\']# // 选择文档里所有匹配的节点,不考虑位置(无论位置多深都找到)res1 = tree.xpath(\"/book/author//nick/text()\") #输出[\'雷雷\', \'莉莉\', \'木木\', \'嘎嘎\', \'热热\', \'盒盒\']# 相当于查询下所有中的文本res2 = tree.xpath(\"/book//nick/text()\") #输出[\'咖喱饭\', \'雷雷\', \'莉莉\', \'木木\', \'嘎嘎\', \'热热\', \'盒盒\', \'容宝宝\', \'容不宝宝\']# 相当于查询所有中的文本res3 = tree.xpath(\"//nick/text()\") #输出[\'咖喱饭\', \'雷雷\', \'莉莉\', \'木木\', \'嘎嘎\', \'热热\', \'盒盒\', \'容宝宝\', \'容不宝宝\']# * 任意节点,通配符(只占一层,并不像//无论多深都找到)res4 = tree.xpath(\"/book/author/*/nick/text()\") #输出[\'热热\', \'盒盒\']print(res4)
-- 案例2 --
Title 工作 三文鱼
from lxml import etreetree = etree.parse(\"b.html\")# 相当于查询所有下- 下的标签中的文本res = tree.xpath(\"//ul/li/a/text()\") #输出[\'百度\', \'谷歌\', \'哔哩哔哩\']# 相当于查询所有
下第一个- 下的标签中的文本res1 = tree.xpath(\"//ul/li[1]/a/text()\") #输出[\'百度\']# 相当于查询所有
(2)使用Xpath小技巧
我们可以按F12打开检查,选中想要爬取的标签,可以看到源代码
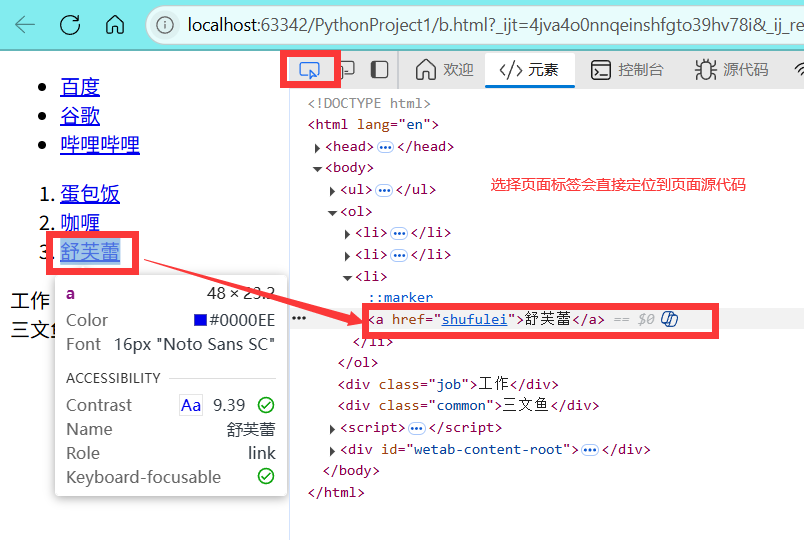
右键源代码,选择【复制Xpath】,即可获取Xpath语句
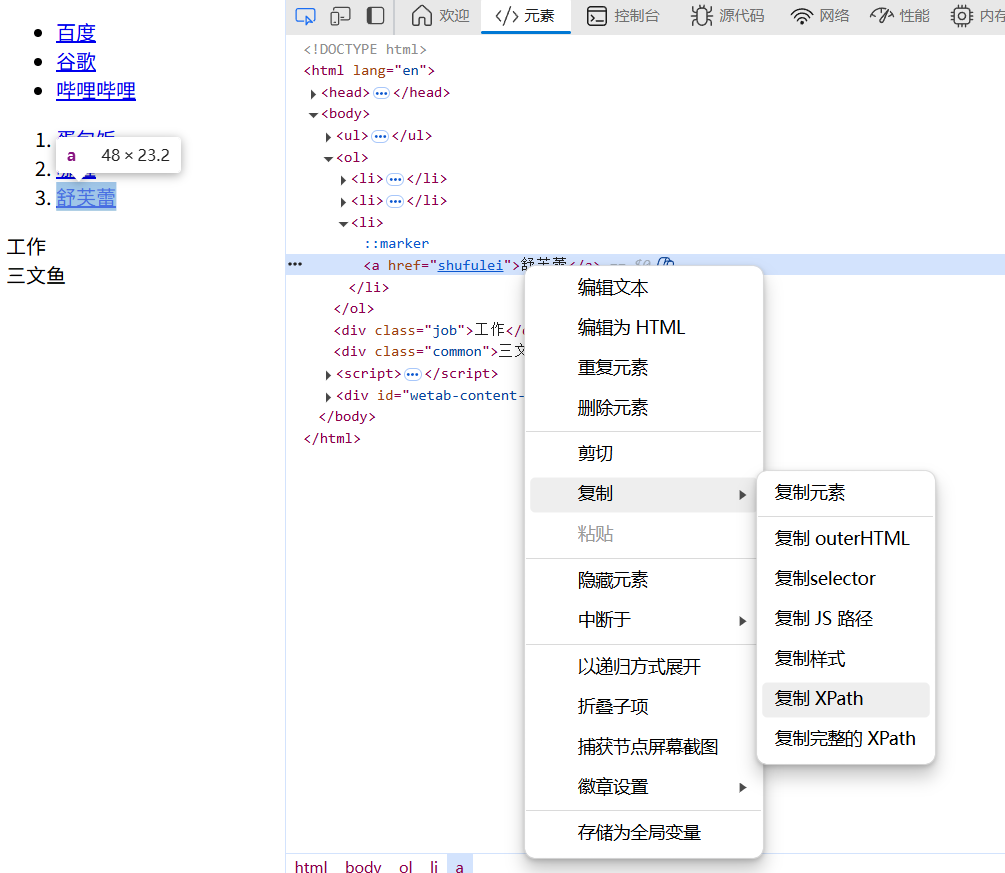
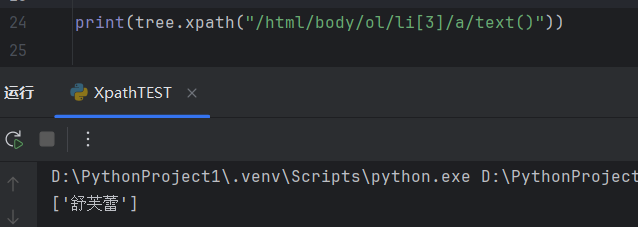
我们在编译器粘贴即可获取标签
(3)Xpath实战:爬取猪八戒网
第一步:按F12获取一个商品框,获取源代码,右键复制Xpath语句
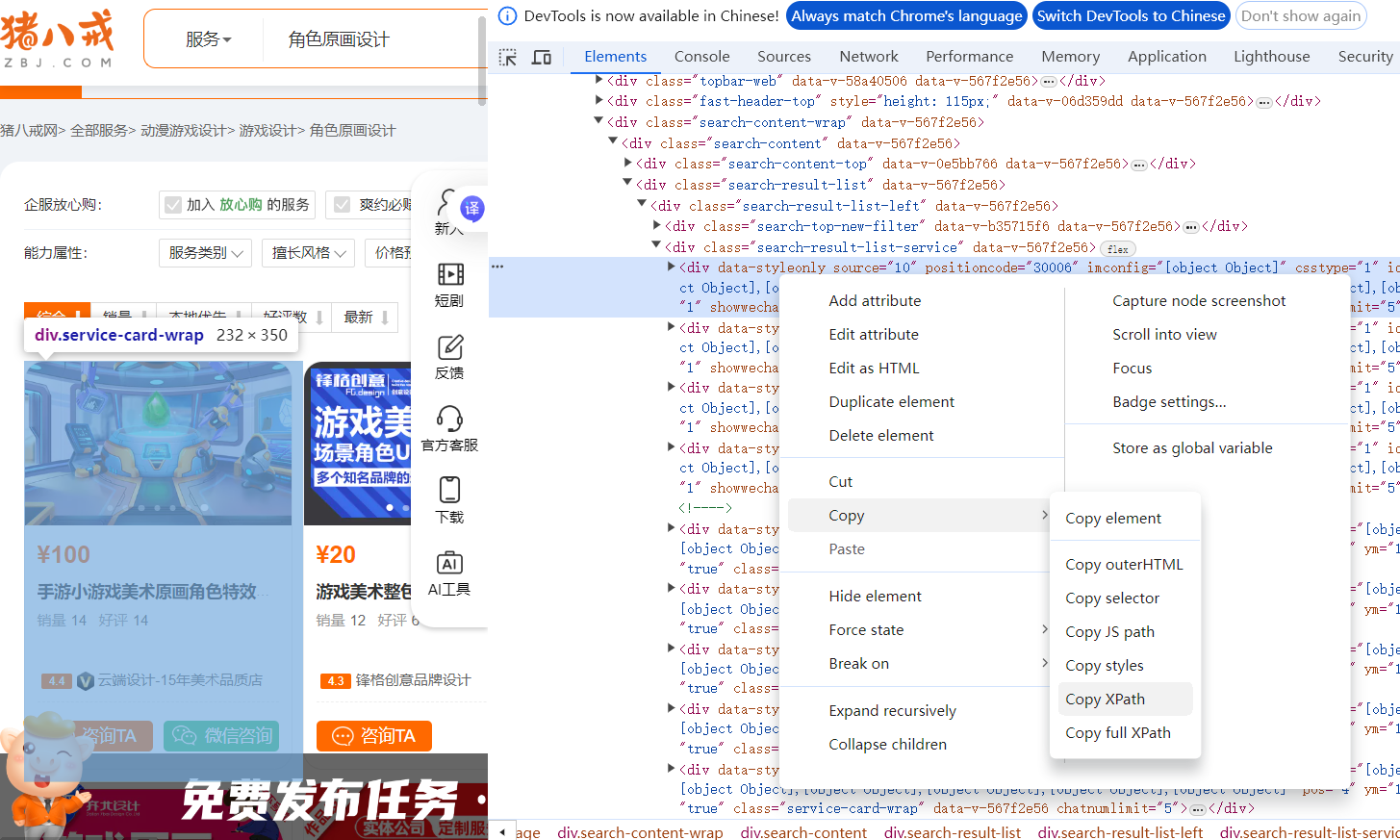
第二步:获取价格标签的具体路径

# 拿到页面源代码import requestsfrom lxml import etreeurl = \"https://movie.douban.com/chart\"resp = requests.get(url)# 解析html = etree.HTML(resp.text)# 拿到一个商家的标签bqs = html.xpath(\"/html/body/div[2]/div/div/div[3]/div[1]/div[4]/div/div[2]/div/div[2]/div[1]\")for i in bqs: price = i.xpath(\"./div/div[3]/div[1]/span/text()\") title = i.xpath(\"./div/div[3]/div[2]/div/span/text()\") shangjia = i.xpath(\"./div/div[5]/div/div/div/text()\") print(price, title, shangjia)
注意!现在已经爬不出来了,这里只是简单举例!!!
然而现在网站升级,没办法直接爬取,如果网站是动态加载的(即数据通过 JavaScript/Ajax 异步加载),仍然可以使用 XPath,但不能直接用 requests + lxml 解析原始 HTML,因为初始 HTML 不包含动态数据。
但是xpath初始步骤是这样的,这里就不再赘述
五、selenium
Selenium 是一个用于 Web 应用程序测试的强大工具集合,它支持多种编程语言和浏览器,主要用于自动化 Web 浏览器交互。我们可以通过selenium直接提取网页上的各种信息。
1、环境搭建
(1)在Pycharm终端下载selenium
pip install selenium
(2)下载浏览器驱动
我的浏览器是Edge,其他的浏览器驱动可参考Selenium 安装 | 菜鸟教程
在Edge设置中找到自己浏览器的版本

下载对应版本的驱动 Microsoft Edge WebDriver | Microsoft Edge Developer
下载好的驱动压缩包解压并打开,将exe文件放入py解释器对应文件夹
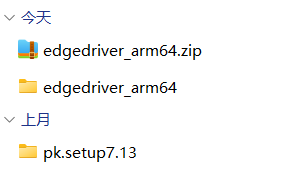

(3)如何查询py解释器位置?
运行下面的代码即可获取
import sysimport osprint(\'当前 Python 解释器路径:\' + sys.executable)print(\'当前 Python 解释器目录:\' + os.path.dirname(sys.executable))
把驱动文件放入解释器文件夹
(4)验证配置
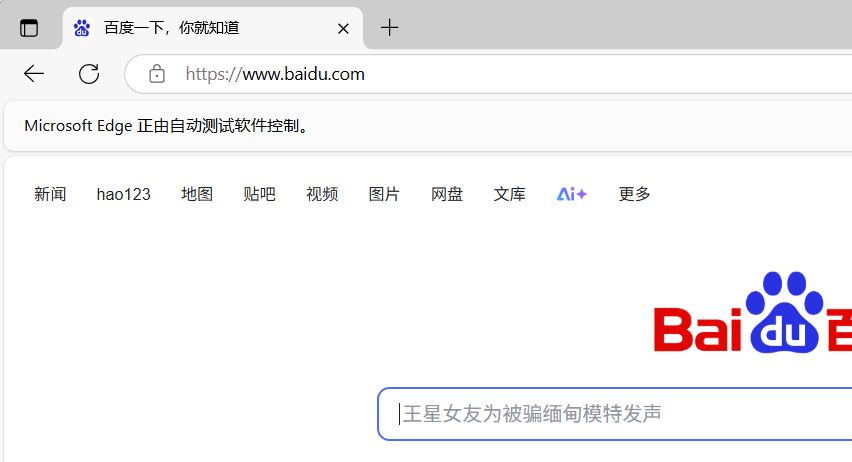
通过运行下面的代码进行验证
import timefrom selenium import webdriver# edgedriver = webdriver.Edge()driver.get(\"http://www.baidu.com\")time.sleep(10)
如果允许这段代码,自动唤起浏览器,并显示【Edge 正由自动测试软件控制】,即配置成功
2、基本操作
在网站找到想要点击的标签,按F12选择并右键复制Xpath路径
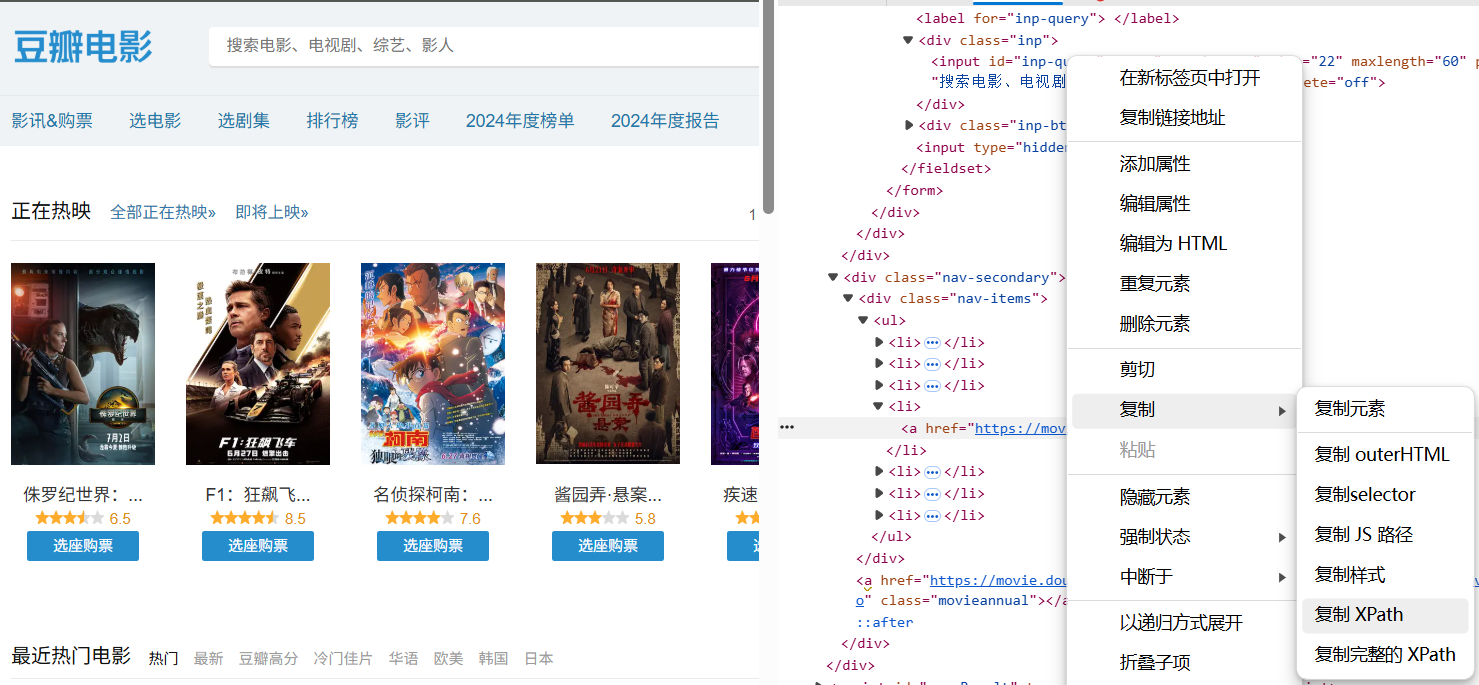
(1)引入expected_condition类和WebDriverWait类
导入显示等待类,现代网页大量使用AJAX和动态加载,EC提供了等待元素出现的标准方法,避免因元素未加载完成而导致的,NoSuchElementException错误,通常结合WebDriverWait类一起使用,形成完整的等待机制
from selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.ui import WebDriverWait
条件方法
作用
使用场景
presence_of_element_located
元素存在于DOM中
等待元素加载
visibility_of_element_located
元素可见且可交互
点击/输入前检查
element_to_be_clickable
元素可点击
按钮点击操作前
title_contains
页面标题包含特定文本
页面跳转验证
text_to_be_present_in_element
元素文本包含特定内容
动态文本加载验证
invisibility_of_element_located
元素不可见或不存在
等待加载动画消失
(2)点击某标签
下面代码功能是:选择网页导航栏【电影】并点击,这里利用xpath获取标签位置
driver = webdriver.Edge()driver.get(\"https://movie.douban.com/\")# 使用显式等待wait = WebDriverWait(driver, 10)# 点击\"电影\"导航项 - 使用更稳定的XPathwait.until(EC.element_to_be_clickable( (By.XPATH, \'//a[contains(@href, \"/movie\") and contains(text(), \"电影\")]\'))).click()# 在整个HTML文档中,查找所有同时满足以下条件的标签:# href属性值中包含\'/movie\'# 显示文本中包含\'电影\'二字
(2)输入并搜索
下面代码功能是:在输入框中输入\"千与千寻\"并按回车搜索
# 搜索电影 - 使用更简单的定位方式search_box = wait.until(EC.presence_of_element_located( (By.XPATH, \'//input[@id=\"inp-query\"]\')))search_box.send_keys(\"千与千寻\", Keys.ENTER)
(3)提取数据信息
下面代码功能是:爬取电影的标题、简介、评分、观影人数、封面
# 等待搜索结果加载wait.until(EC.presence_of_element_located( (By.XPATH, \'//div[contains(@class, \"item-root\")]\')))# 更稳定的搜索结果定位方式movie_items = driver.find_elements(By.XPATH, \'//div[contains(@class, \"item-root\")]\')for item in movie_items: try: # 电影标题 title = item.find_element(By.XPATH, \'.//a[@class=\"title-text\"]\').text # 电影信息(年份/类型/导演等) info = item.find_element(By.XPATH, \'.//div[@class=\"meta abstract\"]\').text try: # 评分 score = item.find_element(By.XPATH, \'.//span[@class=\"rating_nums\"]\').text except : score = \"暂无评分\" # 评论信息 peo = item.find_element(By.XPATH, \'.//span[@class=\"pl\"]\').text # 图片 imgg = item.find_element(By.XPATH, \'.//img[@class=\"cover\"]\').get_attribute(\"src\") print(f\"电影名称: {title}\") print(f\"电影信息: {info}\\n\") print(f\"评分: {score}\\n\") print(f\"评价人数: {peo}\\n\") print(f\"封面: {imgg}\\n\") except Exception as e: print(f\"提取数据时出错: {e}\")driver.quit()
成功爬取数据

完整代码
from selenium.webdriver.common.by import Byfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECimport timedriver = webdriver.Edge()driver.get(\"https://movie.douban.com/\")# 使用显式等待wait = WebDriverWait(driver, 10)# 点击\"电影\"导航项 - 使用更稳定的XPathwait.until(EC.element_to_be_clickable( (By.XPATH, \'//a[contains(@href, \"/movie\") and contains(text(), \"电影\")]\'))).click()# 在整个HTML文档中,查找所有同时满足以下条件的标签:# href属性值中包含\'/movie\'# 显示文本中包含\'电影\'二字time.sleep(1)# 搜索电影 - 使用更简单的定位方式search_box = wait.until(EC.presence_of_element_located( (By.XPATH, \'//input[@id=\"inp-query\"]\')))search_box.send_keys(\"千与千寻\", Keys.ENTER)# 等待搜索结果加载wait.until(EC.presence_of_element_located( (By.XPATH, \'//div[contains(@class, \"item-root\")]\')))# 更稳定的搜索结果定位方式movie_items = driver.find_elements(By.XPATH, \'//div[contains(@class, \"item-root\")]\')for item in movie_items: try: # 电影标题 title = item.find_element(By.XPATH, \'.//a[@class=\"title-text\"]\').text # 电影信息(年份/类型/导演等) info = item.find_element(By.XPATH, \'.//div[@class=\"meta abstract\"]\').text try: # 评分 score = item.find_element(By.XPATH, \'.//span[@class=\"rating_nums\"]\').text except : score = \"暂无评分\" # 评论信息 peo = item.find_element(By.XPATH, \'.//span[@class=\"pl\"]\').text # 图片 imgg = item.find_element(By.XPATH, \'.//img[@class=\"cover\"]\').get_attribute(\"src\") print(f\"电影名称: {title}\") print(f\"电影信息: {info}\\n\") print(f\"评分: {score}\\n\") print(f\"评价人数: {peo}\\n\") print(f\"封面: {imgg}\\n\") except Exception as e: print(f\"提取数据时出错: {e}\")driver.quit()
3、窗口之间切换
在Selenium中,当点击操作触发新窗口或新标签页打开时,WebDriver默认仍会停留在原始窗口。为了在新窗口中操作,必须显式切换窗口上下文
driver.switch_to.window(driver.window_handles[-1])# 用于切换到最新打开的浏览器窗口/标签页的代码
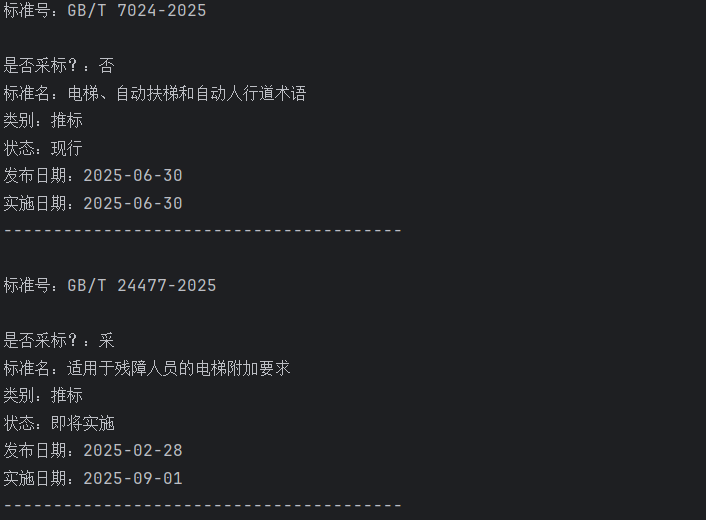
我们爬取国家标准网试一试
from selenium.webdriver.common.by import Byfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECimport timedriver = webdriver.Edge()driver.get(\"https://openstd.samr.gov.cn/bzgk/gb/\")# 使用显式等待wait = WebDriverWait(driver, 10)# 点击搜索框触发wait.until(EC.presence_of_element_located( (By.XPATH, \'//input[@id=\"searchInput\"]\'))).click()time.sleep(1)# 输入关键词search_box = driver.find_element(By.XPATH,\'//*[@id=\"searchInput\"]\')search_box.clear()search_box.send_keys(\"电梯\")# 模拟点击搜索按钮wait.until( EC.element_to_be_clickable((By.XPATH, \'//*[@id=\"searchBtn\"]\'))).click()# 切换进入到新窗口driver.switch_to.window(driver.window_handles[-1])# 获取标准列表bz_list = driver.find_elements(By.XPATH, \'//*[@id=\"stage\"]/div/div[2]/div/div/div/div[2]/table/tbody[2]/tr\')for bz in bz_list: bzh = bz.find_element(By.XPATH,\'./td[2]/a\').text print(f\"标准号:{bzh}\\n\") try: cb = bz.find_element(By.XPATH,\'./td[3]/span\').text except : cb = \"否\" print(f\"是否采标?:{cb}\") name = bz.find_element(By.XPATH,\'./td[4]/a\').text print(f\"标准名:{name}\") lb = bz.find_element(By.XPATH,\'./td[5]\').text print(f\"类别:{lb}\") zt = bz.find_element(By.XPATH,\'./td[6]/span\').text print(f\"状态:{zt}\") fb_date = bz.find_element(By.XPATH,\'./td[7]\').text print(f\"发布日期:{fb_date}\") ss_date = bz.find_element(By.XPATH,\'./td[8]\').text print(f\"实施日期:{ss_date}\") print(\"----------------------------------------\\n\")time.sleep(3)driver.quit()
爬取成功
4、无头浏览器
无头浏览器像一个看不见的机器人,它能帮你做所有电脑上的网页操作(比如打开网页、点按钮、填表格、抓数据),但全程没有浏览器窗口弹出,甚至看不到它在动,但它确实在后台默默完成了所有任务,适合自动化任务。

(1)无头浏览器格式
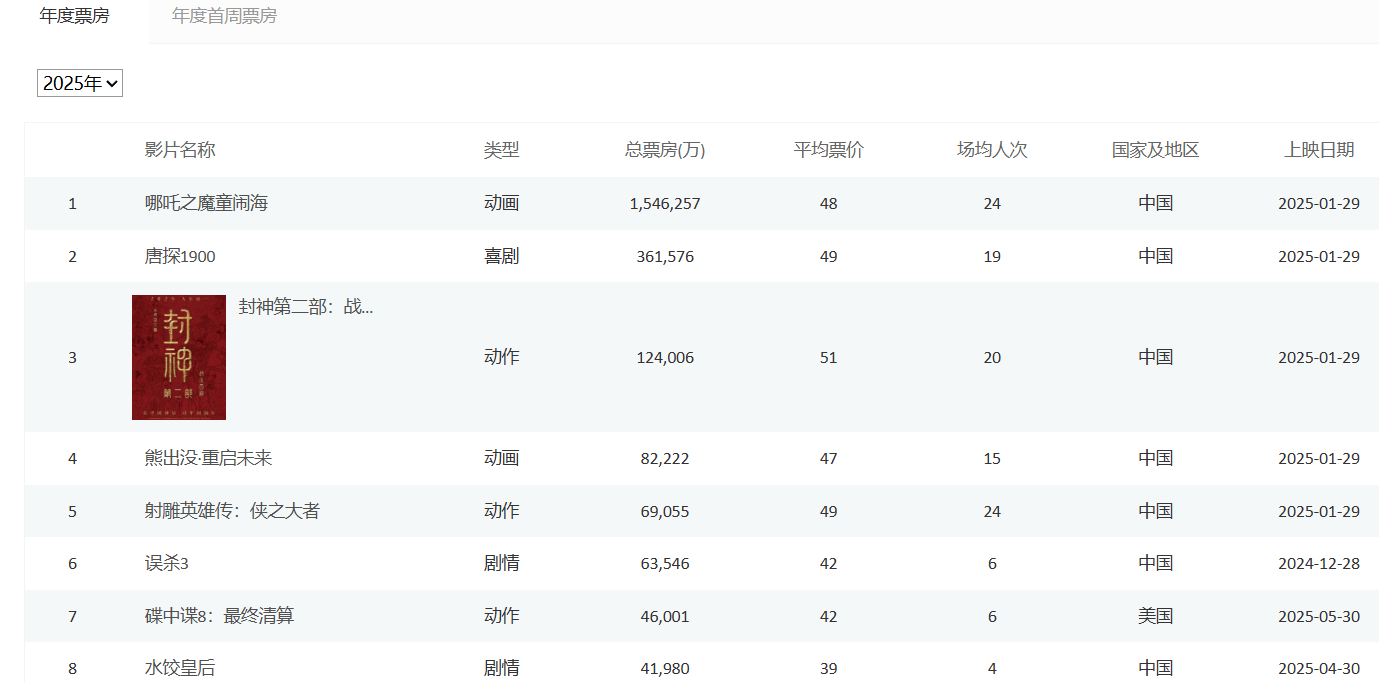
# 设置无头浏览器的配置opt = Options()opt.add_argument(\"--headless\")driver = webdriver.Edge(options=opt)driver.get(\"https://www.endata.com.cn/BoxOffice/BO/Year/index.html\")
这样设置后,爬取数据时浏览器就不会弹出来,而是在后台自动运行
(2)下拉列表爬取方式
首先用xpath定位到下拉列表的标签,接着利用Select对下拉列表进行包装,for循环遍历选项,获取数据。
Selenium 提供了三种选择下拉框选项的方法
方法
示例
适用场景
select_by_index(i)
sel.select_by_index(1)
按序号选择(从0开始)
select_by_value(\"value\")
sel.select_by_value(\"2021\")
按 value属性选择
select_by_visible_text(\"text\")
sel.select_by_visible_text(\"2021年\")
按选项的可见文本选择
爬取代码如下
from selenium.webdriver.common.by import Byfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support.select import Selectfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.edge.options import Optionsimport time# 设置无头浏览器的配置opt = Options()opt.add_argument(\"--headless\")driver = webdriver.Edge(options=opt)driver.get(\"https://www.endata.com.cn/BoxOffice/BO/Year/index.html\")# 定位到下拉列表sel_el = driver.find_element(By.XPATH,\'//*[@id=\"OptionDate\"]\')# 对元素进行包装,包装成下拉列表sel = Select(sel_el)# 让浏览器遍历选项for i in range(len(sel.options)): sel.select_by_index(i) # 按照索引进行切换 time.sleep(1) table = driver.find_element(By.XPATH, \'//*[@id=\"TableList\"]/table\') print(table.text) print(\"---------------------------------------------------------\")print(\"运行完毕\")driver.quit()
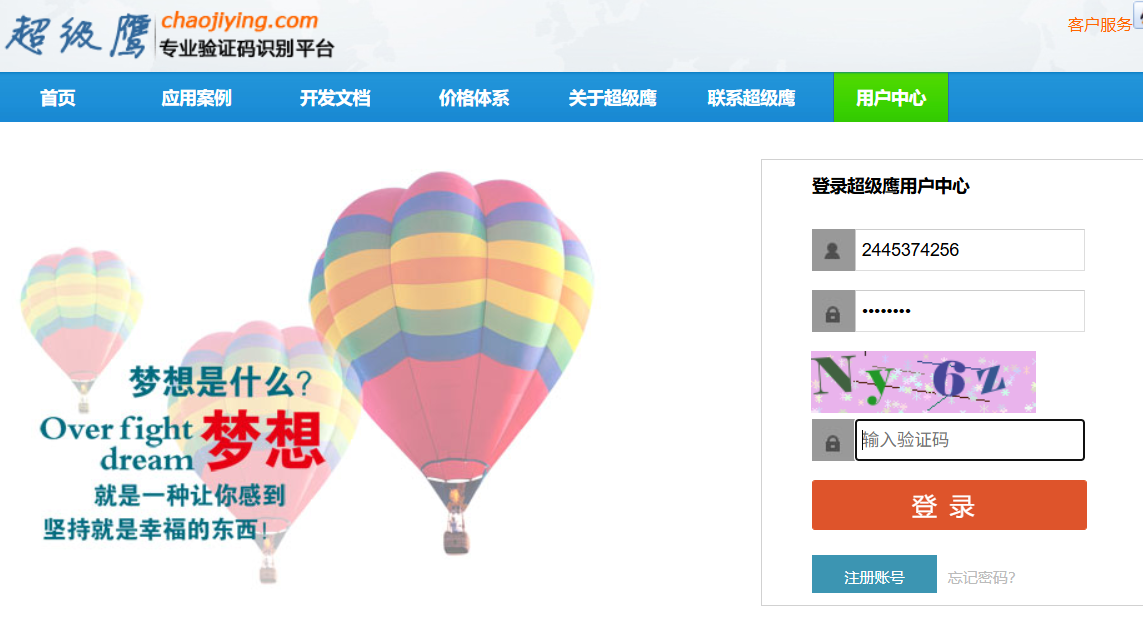
5、验证码(简单版)
网站经常会有登录界面,验证码也是一种常见的安全验证方式,我们需要借助第三方破解验证码的接口对验证码进行破解
超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大
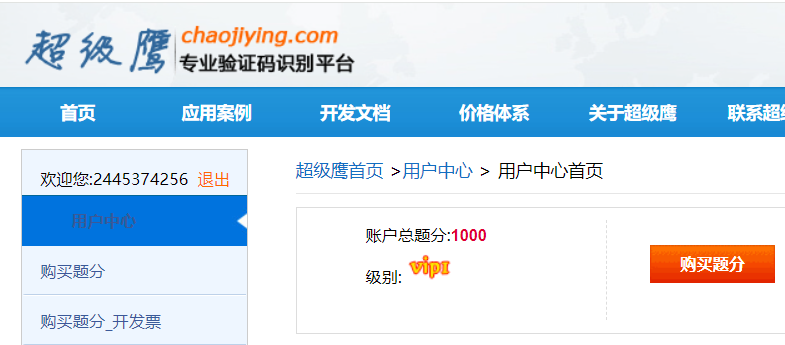
因为破解验证码需要付费,因此我们可以扫二维码免费获得1000题分用于测试
(1)超级鹰使用方法
在注册好用户后,我们在 用户中心 > 软件ID 中,设置一个ID,为了让被爬网站验证
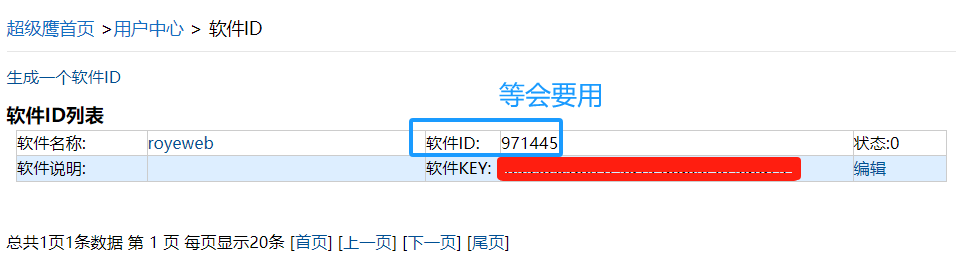
接着点击 开发文档,获取接口
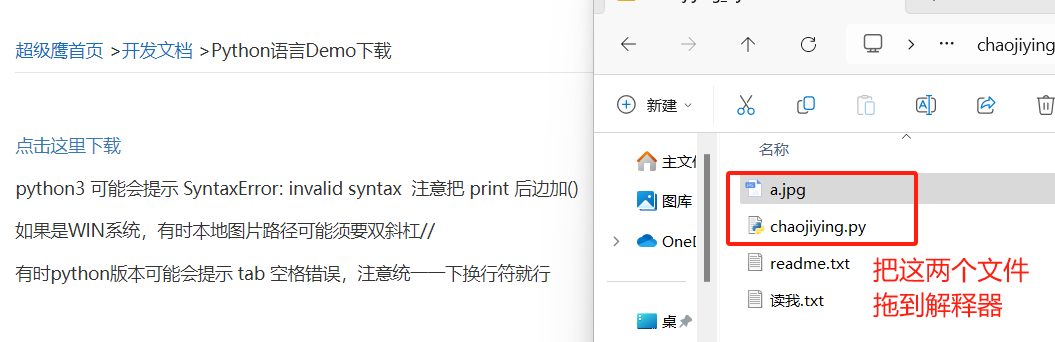
在下载的chaojiying.py中修改参数
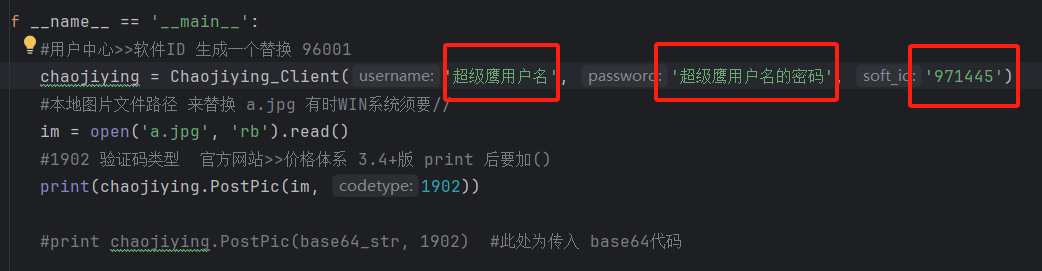
注意:这里codetype可以在 价格体系 里找到对应的验证码类型

运行这段代码,就可以破解图片验证码
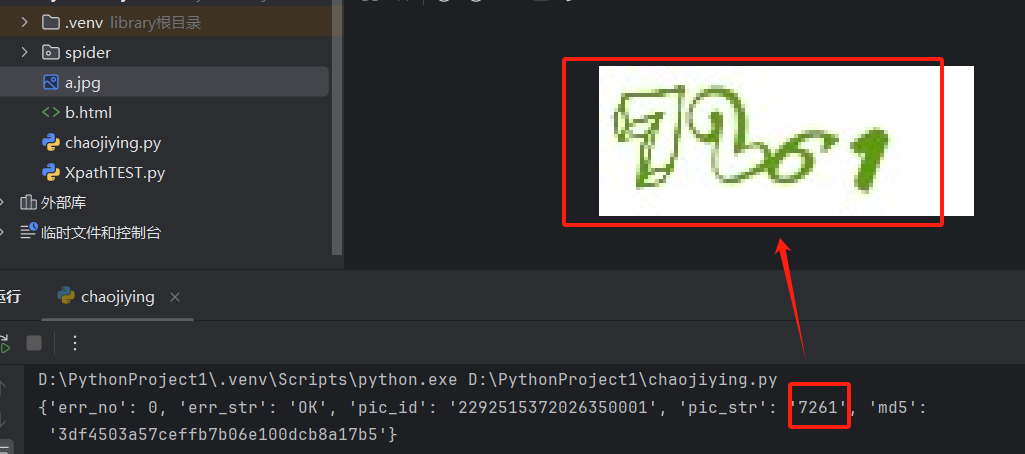
(2)实战:破解超级鹰的验证码
首先处理验证码,用超级鹰接口破解获取验证码,再通过selenium输入用户名和密码还有验证码,最后点击登录即可
from selenium.webdriver.common.by import Byfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support.select import Selectfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.edge.options import Optionsfrom chaojiying import Chaojiying_Clientimport time# 设置无头浏览器的配置# opt = Options()# opt.add_argument(\"--headless\")driver = webdriver.Edge()#options=optdriver.get(\"https://www.chaojiying.com/user/login/\")# 处理验证码# 获取验证码图片img = driver.find_element(By.XPATH,\'/html/body/div[3]/div/div[3]/div[1]/form/div/img\').screenshot_as_pngchaojiying = Chaojiying_Client(\'2445374256\', \'vjoe7y86\', \'971445\')dic = chaojiying.PostPic(img,1920) # 调用PostPic方法提交验证码图片进行识别verify_code = dic[\'pic_str\'] # 从返回结果中提取识别出的验证码字符串# 向页面中填入用户名,密码,验证码driver.find_element(By.XPATH,\'/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input\').send_keys(\"2445374256\")driver.find_element(By.XPATH,\'/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input\').send_keys(\"vjoe7y86\")driver.find_element(By.XPATH,\'/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input\').send_keys(verify_code)time.sleep(3)# 点击登录driver.find_element(By.XPATH,\'/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input\').click()print(\"运行完毕\")driver.quit()
六、Scrapy
Scrapy 是一个强大的 Python 爬虫框架,专门用于高效地抓取网页数据并进行结构化提取。
它采用 异步处理 架构,适合大规模数据采集,广泛应用于爬虫开发、数据挖掘和监测等地方。
首先下载scrapy,在终端输入命令
pip install scrapy -i https://mirrors.aliyun.com/pypi/simple/
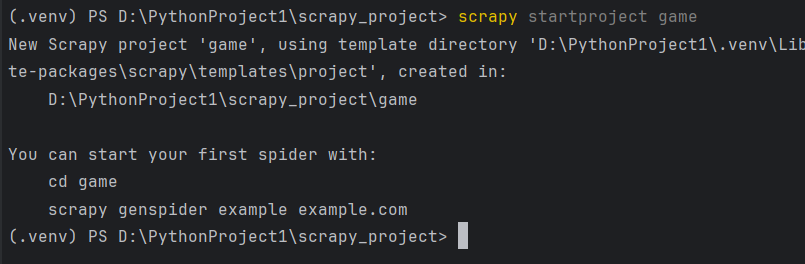
1、scrapy创建入门
第一步:在文件夹下右键打开终端
第二步:在终端输入创建代码
scrapy startproject game