搞懂TCP KeepAlive保活机制_tcp keepalive机制
目录
1.TCP KeepAlive的初衷
2.TCP Keepalive工作原理
2.1技术原理
2.2具体使用举例
3.TCP Keepalive和HTTP Keep-Alive的区别
3.1HTTP Keep-Alive
3.2总结
1.TCP KeepAlive的初衷
采用TCP连接的C/S模式应用中,当连接的双方在连接空闲状态时,如果任意一方意外崩溃、宕机、网线断开或路由器故障,另一方无法得知TCP连接已经失效。
那么,连接的另一方并不知道对端的情况,它会一直维护这个连接。而作为“服务端”来说,长时间的积累会导致非常多的半连接打开,造成系统资源的消耗和浪费,且有可能导致在一个无效的数据链路层面发送业务数据,结果就是发送失败。
所以各端要做到快速感知失败,减少无效连接操作,这就有了TCP的KeepAlive保活探测机制。
2.TCP Keepalive工作原理
2.1技术原理
当一个TCP连接建立之后,启用TCP Keepalive的一端便会启动一个计时器,当这个计时器数值到达0之后(也就是经过tcp_keepalive_time时间后,这个参数之后会讲到),一个TCP探测包便会被发出,这个TCP探测包是一个纯ACK包(RFC 1122#TCP Keep-Alives规范建议:不应该包含任何数据,但也可以包含1个无意义的字节,比如0x0)其Seq号与上一个包是重复的,所以其实探测保活报文不在窗口控制范围内。
如果一个给定的连接在两小时内(默认时长)没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于下表中的4个状态之一:
直观来说,TCP KeepAlive的交互过程大致如下图所示:
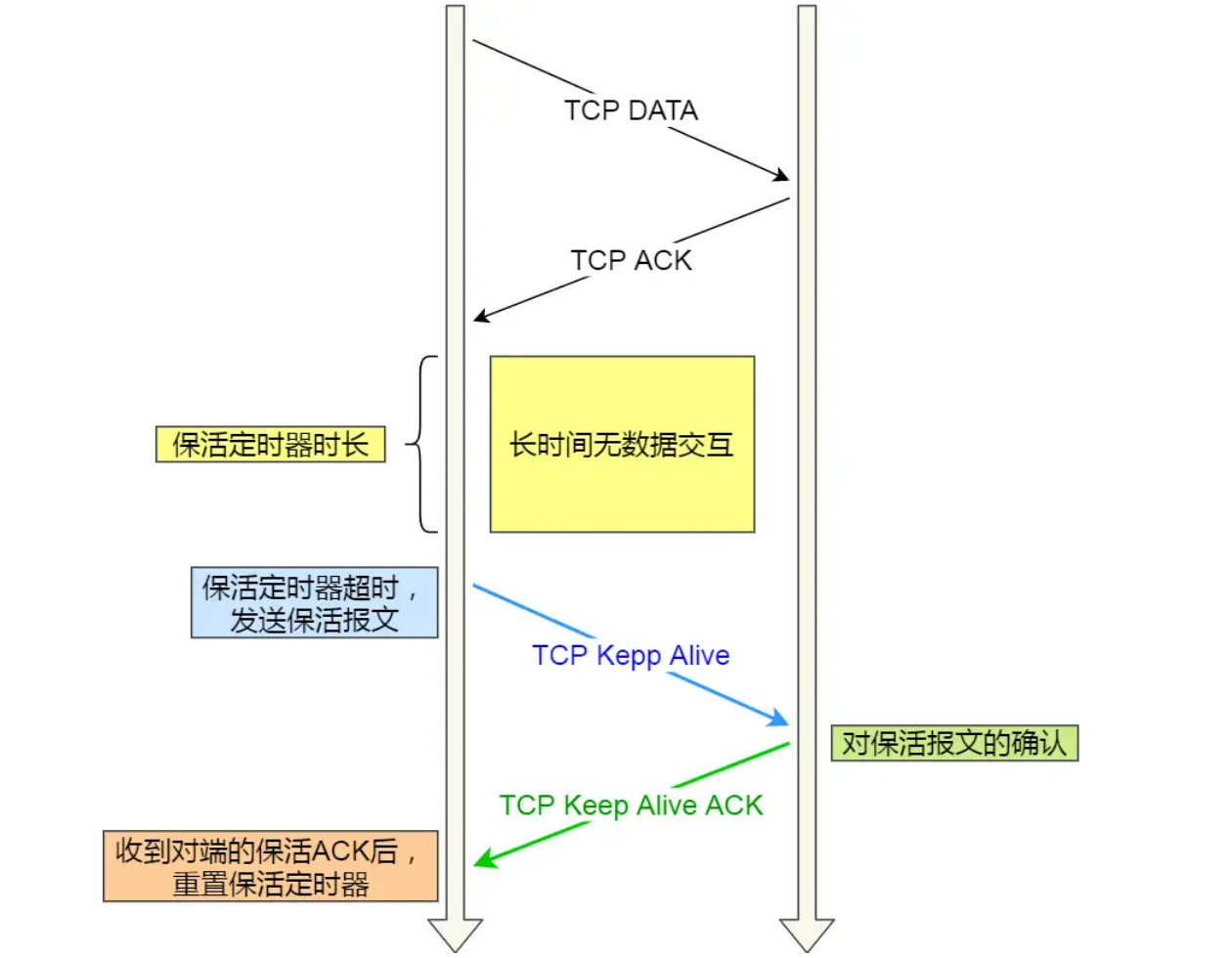
2.2具体使用举例
以linux内核为例,应用程序若想使用TCP Keepalive,需要设置SO_KEEPALIVE套接字选项才能生效。对应的,有三个重要参数:
3.TCP Keepalive和HTTP Keep-Alive的区别
3.1HTTP Keep-Alive
在HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的Web页面包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
但从 HTTP/1.1起,默认使用长连接,用以保持连接特性,使用长连接的HTTP协议,会在响应头加上Connection:Keep-Alive字段。
HTTP的Keep-Alive可以使用同一个TCP连接来发送和接收多个HTTP请求/应答,避免了连接建立和释放的开销,提高通信效率。
3.2总结
- HTTP的Keep-Alive是为了让TCP连接活得更久一点,在发起多个http请求时能复用同一个连接,提高通信效率;
- TCP的KeepAlive机制在于探测连接的对端是否存活,是一种检测TCP连接状况的保鲜机制。

