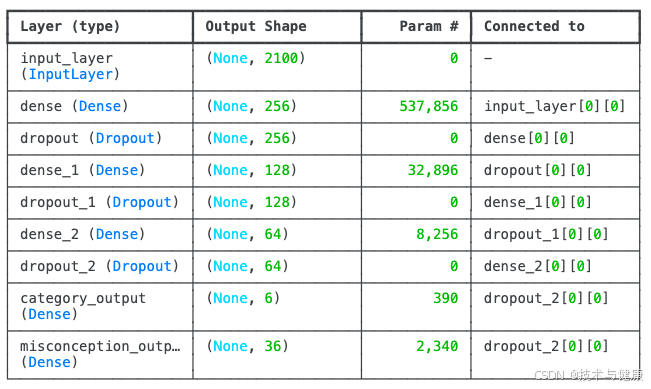
!pip install xgboost scikit-learn matplotlib pandas scipy tensorflow optunaimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split, StratifiedKFoldfrom sklearn.preprocessing import LabelEncoderfrom sklearn.metrics import classification_report, accuracy_score, confusion_matrix, ConfusionMatrixDisplay, f1_scorefrom sklearn.feature_extraction.text import TfidfVectorizerimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers, models, optimizers, callbacks import optuna file_path = \'/kaggle/input/map-charting-student-math-misunderstandings/train.csv\'df_train = pd.read_csv(file_path)df_train[\'Misconception\'] = df_train[\'Misconception\'].fillna(\'No_Misconception\')df_train[\'CombinedText\'] = df_train[\'QuestionText\'] + \" \" + df_train[\'MC_Answer\'] + \" \" + df_train[\'StudentExplanation\']print(\"--- 正在加载 GloVe 词向量 ---\")glove_file_path = \'/kaggle/input/glove-global-vectors-for-word-representation/glove.6B.100d.txt\'word_embeddings = {}embedding_dim = 100try: with open(glove_file_path, \'r\', encoding=\'utf-8\') as f: for line in f: values = line.split() word = values[0] vector = np.asarray(values[1:], dtype=\'float32\') word_embeddings[word] = vector print(f\"已加载 {len(word_embeddings)} 个词的 GloVe 词向量 (维度: {embedding_dim})。\")except FileNotFoundError: print(f\"错误: GloVe 文件 \'{glove_file_path}\' 未找到。请确保文件已上传或路径正确。\") print(\"将跳过词嵌入,使用一个简化的特征提取器进行演示。\") word_embeddings = {\"dummy\": np.zeros(embedding_dim)} embedding_dim = 100def get_embedding_features(texts, word_embeddings, embedding_dim): \"\"\" 将文本列表转换为词嵌入特征矩阵。 每个文本的特征是其所有词向量的平均值。 \"\"\" features_matrix = np.zeros((len(texts), embedding_dim)) for i, text in enumerate(texts): words = text.lower().split() word_vectors = [] for word in words: if word in word_embeddings: word_vectors.append(word_embeddings[word]) if word_vectors: features_matrix[i] = np.mean(word_vectors, axis=0) return features_matrixprint(\"--- 正在使用 TF-IDF 和词嵌入提取文本特征并拼接 ---\")tfidf_vectorizer = TfidfVectorizer(max_features=2000, ngram_range=(1, 2))X_tfidf = tfidf_vectorizer.fit_transform(df_train[\'CombinedText\'])X_embeddings = get_embedding_features(df_train[\'CombinedText\'].astype(str).tolist(), word_embeddings, embedding_dim)X_text = np.hstack((X_tfidf.toarray().astype(np.float32), X_embeddings.astype(np.float32)))print(f\"组合后的文本特征矩阵形状: {X_text.shape}\")le_category = LabelEncoder()le_category.fit(df_train[\'Category\'])y_category = le_category.transform(df_train[\'Category\'])num_category_classes = len(le_category.classes_)le_misconception = LabelEncoder()le_misconception.fit(df_train[\'Misconception\'])y_misconception = le_misconception.transform(df_train[\'Misconception\'])num_misconception_classes = len(le_misconception.classes_)def mean_average_precision_at_k(y_true, y_pred_proba, k=3): \"\"\" 计算 Mean Average Precision @ K (MAP@K)。 \"\"\" average_precisions = [] for i in range(len(y_true)): true_label = y_true[i] probas_for_sample = y_pred_proba[i] top_k_indices = np.argsort(probas_for_sample)[::-1][:k] precision_at_k = 0 num_correct = 0 for j, predicted_index in enumerate(top_k_indices): if predicted_index == true_label: num_correct += 1 precision_at_k += num_correct / (j + 1) if true_label in top_k_indices: average_precisions.append(precision_at_k / num_correct if num_correct > 0 else 0) else: average_precisions.append(0) return np.mean(average_precisions)def build_multi_task_model(input_shape, num_category_classes, num_misconception_classes, shared_units=256, dropout_rate=0.3): \"\"\" 构建一个多任务学习的Keras模型。 增加了共享层的深度。 \"\"\" input_layer = keras.Input(shape=(input_shape,)) shared_dense_1 = layers.Dense(shared_units, activation=\'relu\')(input_layer) shared_dropout_1 = layers.Dropout(dropout_rate)(shared_dense_1) shared_dense_2 = layers.Dense(shared_units // 2, activation=\'relu\')(shared_dropout_1) shared_dropout_2 = layers.Dropout(dropout_rate)(shared_dense_2) shared_dense_3 = layers.Dense(shared_units // 4, activation=\'relu\')(shared_dropout_2) shared_dropout_3 = layers.Dropout(dropout_rate)(shared_dense_3) category_output = layers.Dense(num_category_classes, activation=\'softmax\', name=\'category_output\')(shared_dropout_3) misconception_output = layers.Dense(num_misconception_classes, activation=\'softmax\', name=\'misconception_output\')(shared_dropout_3) model = keras.Model(inputs=input_layer, outputs=[category_output, misconception_output]) return modelinput_shape = X_text.shape[1]multi_task_model = build_multi_task_model(input_shape, num_category_classes, num_misconception_classes)multi_task_model.summary()multi_task_model.compile( optimizer=optimizers.Adam(learning_rate=0.001), loss={ \'category_output\': \'sparse_categorical_crossentropy\', \'misconception_output\': \'sparse_categorical_crossentropy\' }, loss_weights={ \'category_output\': 1.0, \'misconception_output\': 1.0 }, metrics={ \'category_output\': [\'accuracy\'], \'misconception_output\': [\'accuracy\'] })print(\"\\n--- 正在训练多任务模型并进行评估 ---\")X_train, X_test, y_train_cat_split, y_test_cat_split, y_train_mis_split, y_test_mis_split = train_test_split( X_text, y_category, y_misconception, test_size=0.2, random_state=42, stratify=y_category )early_stopping = callbacks.EarlyStopping( monitor=\'val_loss\', patience=15, restore_best_weights=True )history = multi_task_model.fit( X_train, {\'category_output\': y_train_cat_split, \'misconception_output\': y_train_mis_split}, validation_data=(X_test, {\'category_output\': y_test_cat_split, \'misconception_output\': y_test_mis_split}), epochs=100, batch_size=32, callbacks=[early_stopping], verbose=1)print(\"\\n多任务模型训练完成。\")print(\"\\n--- 在测试集上评估多任务模型 ---\")eval_results = multi_task_model.evaluate( X_test, {\'category_output\': y_test_cat_split, \'misconception_output\': y_test_mis_split}, verbose=0)print(f\"总损失: {eval_results[0]:.4f}\")print(f\"Category 损失: {eval_results[1]:.4f}\")print(f\"Misconception 损失: {eval_results[2]:.4f}\")print(f\"Category 准确率: {eval_results[3]:.4f}\")print(f\"Misconception 准确率: {eval_results[4]:.4f}\")y_pred_proba_category, y_pred_proba_misconception = multi_task_model.predict(X_test)map_at_3_cat_test = mean_average_precision_at_k(y_test_cat_split, y_pred_proba_category, k=3)print(f\"\\nCategory 模型测试集 Mean Average Precision @3 (MAP@3): {map_at_3_cat_test:.4f}\")map_at_3_mis_test = mean_average_precision_at_k(y_test_mis_split, y_pred_proba_misconception, k=3)print(f\"\\nMisconception 模型测试集 Mean Average Precision @3 (MAP@3): {map_at_3_mis_test:.4f}\")y_pred_category_labels = np.argmax(y_pred_proba_category, axis=1)unique_cat_labels = np.unique(np.concatenate((y_test_cat_split, y_pred_category_labels)))cat_target_names_for_report = le_category.inverse_transform(unique_cat_labels)print(\"\\nCategory 模型测试集分类报告:\")print(classification_report(y_test_cat_split, y_pred_category_labels, labels=unique_cat_labels, target_names=cat_target_names_for_report)) print(\"\\nCategory 模型测试集混淆矩阵:\")cm_category_test = confusion_matrix(y_test_cat_split, y_pred_category_labels, labels=unique_cat_labels)disp_cat_test = ConfusionMatrixDisplay(confusion_matrix=cm_category_test, display_labels=cat_target_names_for_report)fig_cat_test, ax_cat_test = plt.subplots(figsize=(8, 6))disp_cat_test.plot(cmap=plt.cm.Blues, ax=ax_cat_test)ax_cat_test.set_title(\'Category 模型测试集混淆矩阵 (MTL Keras)\')plt.show()y_pred_misconception_labels = np.argmax(y_pred_proba_misconception, axis=1)unique_mis_labels = np.unique(np.concatenate((y_test_mis_split, y_pred_misconception_labels)))mis_target_names_for_report = le_misconception.inverse_transform(unique_mis_labels)print(\"\\nMisconception 模型测试集分类报告:\")print(classification_report(y_test_mis_split, y_pred_misconception_labels, labels=unique_mis_labels, target_names=mis_target_names_for_report)) print(\"\\nMisconception 模型测试集混淆矩阵:\")cm_misconception_test = confusion_matrix(y_test_mis_split, y_pred_misconception_labels, labels=unique_mis_labels)disp_mis_test = ConfusionMatrixDisplay(confusion_matrix=cm_misconception_test, display_labels=mis_target_names_for_report)fig_mis_test, ax_mis_test = plt.subplots(figsize=(15, 12))disp_mis_test.plot(cmap=plt.cm.Blues, ax=ax_mis_test)ax_mis_test.set_title(\'Misconception 模型测试集混淆矩阵 (MTL Keras)\')plt.show()print(\"\\n--- 正在加载 test.csv 并进行预测 ---\")testfile_path = \'/kaggle/input/map-charting-student-math-misunderstandings/test.csv\'try: df_test = pd.read_csv(testfile_path)except FileNotFoundError: print(\"错误: \'test.csv\' 文件未找到。请确保文件已上传。\") df_test = pd.DataFrame({ \'row_id\': [100000, 100001, 100002], \'QuestionId\': [99999, 88888, 77777], \'QuestionText\': [ \"What is 5 + 3?\", \"If x = 10, what is 2x?\", \"What is the capital of France?\" ], \'MC_Answer\': [ \"8\", \"20\", \"Paris\" ], \'StudentExplanation\': [ \"5 and 3 makes 8.\", \"2 times 10 is 20.\", \"It is the city of lights.\" ] }) print(\"已创建示例测试数据进行演示。\")df_test[\'CombinedText\'] = df_test[\'QuestionText\'] + \" \" + df_test[\'MC_Answer\'] + \" \" + df_test[\'StudentExplanation\']X_test_tfidf = tfidf_vectorizer.transform(df_test[\'CombinedText\'])X_test_embeddings = get_embedding_features(df_test[\'CombinedText\'].astype(str).tolist(), word_embeddings, embedding_dim)X_test_transformed_for_prediction = np.hstack((X_test_tfidf.toarray().astype(np.float32), X_test_embeddings.astype(np.float32)))df_test[\'Category:Misconception\'] = Nonetest_pred_proba_category, test_pred_proba_misconception = multi_task_model.predict(X_test_transformed_for_prediction)for index in range(len(df_test)): proba_category = test_pred_proba_category[index] proba_misconception = test_pred_proba_misconception[index] category_names = le_category.classes_ misconception_names = le_misconception.classes_ all_combinations = [] for i, cat_name in enumerate(category_names): for j, mis_name in enumerate(misconception_names): combined_prob = proba_category[i] * proba_misconception[j] all_combinations.append((f\"{cat_name}:{mis_name}\", combined_prob)) all_combinations.sort(key=lambda x: x[1], reverse=True) predictions_list_str = [] for k_val in range(min(3, len(all_combinations))): predictions_list_str.append(f\"{all_combinations[k_val][0]}\") df_test.at[index, \'Category:Misconception\'] = \" \".join(predictions_list_str)print(\"\\n测试数据预测完成。\")print(\"\\n预测结果示例 (前5行):\")print(df_test[[\'row_id\', \'Category:Misconception\']].head().to_markdown(index=False, numalign=\"left\", stralign=\"left\"))df_test.to_csv(\'submission.csv\', index=False, columns=[\'row_id\', \'Category:Misconception\'])print(\"\\n预测结果已保存到 \'submission.csv\'。\")


