YOLOV11改进策略【最新注意力机制】CVPR2025局部区域注意力机制LRSA-增强局部区域特征之间的交互_lrsa注意力机制
1.1网络结构
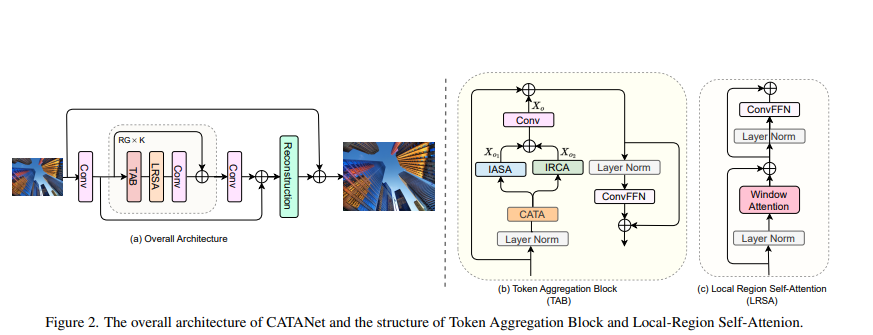
1.2 添加过程
1.2.1 核心代码
import torchimport torch.nn as nnimport torch.nn.functional as Ffrom einops import rearrangedef patch_divide(x, step, ps): \"\"\"Crop image into patches. Args: x (Tensor): Input feature map of shape(b, c, h, w). step (int): Divide step. ps (int): Patch size. Returns: crop_x (Tensor): Cropped patches. nh (int): Number of patches along the horizontal direction. nw (int): Number of patches along the vertical direction. \"\"\" b, c, h, w = x.size() if h == ps and w == ps: step = ps crop_x = [] nh = 0 for i in range(0, h + step - ps, step): top = i down = i + ps if down > h: top = h - ps down = h nh += 1 for j in range(0, w + step - ps, step): left = j right = j + ps if right > w: left = w - ps right = w crop_x.append(x[:, :, top:down, left:right]) nw = len(crop_x) // nh crop_x = torch.stack(crop_x, dim=0) # (n, b, c, ps, ps) crop_x = crop_x.permute(1, 0, 2, 3, 4).contiguous() # (b, n, c, ps, ps) return crop_x, nh, nwdef patch_reverse(crop_x, x, step, ps): \"\"\"Reverse patches into image. Args: crop_x (Tensor): Cropped patches. x (Tensor): Feature map of shape(b, c, h, w). step (int): Divide step. ps (int): Patch size. Returns: ouput (Tensor): Reversed image. \"\"\" b, c, h, w = x.size() output = torch.zeros_like(x) index = 0 for i in range(0, h + step - ps, step): top = i down = i + ps if down > h: top = h - ps down = h for j in range(0, w + step - ps, step): left = j right = j + ps if right > w: left = w - ps right = w output[:, :, top:down, left:right] += crop_x[:, index] index += 1 for i in range(step, h + step - ps, step): top = i down = i + ps - step if top + ps > h: top = h - ps output[:, :, top:down, :] /= 2 for j in range(step, w + step - ps, step): left = j right = j + ps - step if left + ps > w: left = w - ps output[:, :, :, left:right] /= 2 return outputclass PreNorm(nn.Module): \"\"\"Normalization layer. Args: dim (int): Base channels. fn (Module): Module after normalization. \"\"\" def __init__(self, dim, fn): super().__init__() self.norm = nn.LayerNorm(dim) self.fn = fn def forward(self, x, **kwargs): return self.fn(self.norm(x), **kwargs)class Attention(nn.Module): \"\"\"Attention module. Args: dim (int): Base channels. heads (int): Head numbers. qk_dim (int): Channels of query and key. \"\"\" def __init__(self, dim, heads, qk_dim): super().__init__() self.heads = heads self.dim = dim self.qk_dim = qk_dim self.scale = qk_dim ** -0.5 self.to_q = nn.Linear(dim, qk_dim, bias=False) self.to_k = nn.Linear(dim, qk_dim, bias=False) self.to_v = nn.Linear(dim, dim, bias=False) self.proj = nn.Linear(dim, dim, bias=False) def forward(self, x): q, k, v = self.to_q(x), self.to_k(x), self.to_v(x) q, k, v = map(lambda t: rearrange(t, \'b n (h d) -> b h n d\', h=self.heads), (q, k, v)) out = F.scaled_dot_product_attention(q, k, v) # scaled_dot_product_attention 需要PyTorch2.0之后版本 out = rearrange(out, \'b h n d -> b n (h d)\') return self.proj(out)class dwconv(nn.Module): def __init__(self, hidden_features, kernel_size=5): super(dwconv, self).__init__() self.depthwise_conv = nn.Sequential( nn.Conv2d(hidden_features, hidden_features, kernel_size=kernel_size, stride=1,padding=(kernel_size - 1) // 2, dilation=1,groups=hidden_features), nn.GELU()) self.hidden_features = hidden_features def forward(self, x, x_size): x = x.transpose(1, 2).view(x.shape[0], self.hidden_features, x_size[0], x_size[1]).contiguous() # b Ph*Pw c x = self.depthwise_conv(x) x = x.flatten(2).transpose(1, 2).contiguous() return xclass ConvFFN(nn.Module): def __init__(self, in_features, hidden_features=None, out_features=None, kernel_size=5, act_layer=nn.GELU): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.dwconv = dwconv(hidden_features=hidden_features, kernel_size=kernel_size) self.fc2 = nn.Linear(hidden_features, out_features) def forward(self, x, x_size): x = self.fc1(x) x = self.act(x) x = x + self.dwconv(x, x_size) x = self.fc2(x) return xclass LRSA(nn.Module): \"\"\"Attention module. Args: dim (int): Base channels. num (int): Number of blocks. qk_dim (int): Channels of query and key in Attention. mlp_dim (int): Channels of hidden mlp in Mlp. heads (int): Head numbers of Attention. \"\"\" def __init__(self, dim, qk_dim=36, mlp_dim=96, heads=4): super().__init__() self.layer = nn.ModuleList([ PreNorm(dim, Attention(dim, heads, qk_dim)), PreNorm(dim, ConvFFN(dim, mlp_dim))]) def forward(self, x, ps=16): step = ps - 2 crop_x, nh, nw = patch_divide(x, step, ps) # (b, n, c, ps, ps) b, n, c, ph, pw = crop_x.shape crop_x = rearrange(crop_x, \'b n c h w -> (b n) (h w) c\') attn, ff = self.layer crop_x = attn(crop_x) + crop_x crop_x = rearrange(crop_x, \'(b n) (h w) c -> b n c h w\', n=n, w=pw) x = patch_reverse(crop_x, x, step, ps) _, _, h, w = x.shape x = rearrange(x, \'b c h w-> b (h w) c\') x = ff(x, x_size=(h, w)) + x x = rearrange(x, \'b (h w) c->b c h w\', h=h) return x1.2.2 添加过程
第一步:在nn文件夹下面创建一个新的文件夹,名字叫做Addmodules, 然后再这个文件夹下面创建LRSA.py文件,然后将LRSA的核心代码放入其中。
第二步:继续在Addmodules文件夹下面创建__init__.py文件,输入以下代码:
from .LRSA import LRSA__all__ = ( \"LRSA\",)第三步:在task.py文件中导入LRSA
from .Addmodules import LRSA elif m is LRSA: c1 = ch[f] args = [c1, *args]第四步:修改yaml文件
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs# Model docs: https://docs.ultralytics.com/models/yolo11# Task docs: https://docs.ultralytics.com/tasks/detect# Parametersnc: 1 # number of classesscales: # model compound scaling constants, i.e. \'model=yolo11n.yaml\' will call yolo11n.yaml with scale \'n\' # [depth, width, max_channels] n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs s: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs m: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs l: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs x: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbonebackbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 2, C3k2, [256, False, 0.25]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 2, C3k2, [512, False, 0.25]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 2, C3k2, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 2, C3k2, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 - [-1, 2, C2PSA, [1024]] # 10 - [-1, 3, LRSA, [1024]]# YOLO11n headhead: - [-1, 1, nn.Upsample, [None, 2, \"nearest\"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 2, C3k2, [512, False]] # 13 - [-1, 1, nn.Upsample, [None, 2, \"nearest\"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 2, C3k2, [256, False]] # 16 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 13], 1, Concat, [1]] # cat head P4 - [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium) - [-1, 1, Conv, [512, 3, 2]] - [[-1, 10], 1, Concat, [1]] # cat head P5 - [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large) - [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)请多多关注!!!


