Elasticsearch 向量之semantic_text、dense_vector 与 sparse_vector 深入解析
随着人工智能和自然语言处理技术的飞速发展,向量搜索(Vector Search)已经成为提升信息检索效果的利器。
Elasticsearch 作为强大的搜索和分析引擎,提供了semantic_text、dense_vector和sparse_vector三种字段类型来支持嵌入(Embedding)向量的存储和查询。
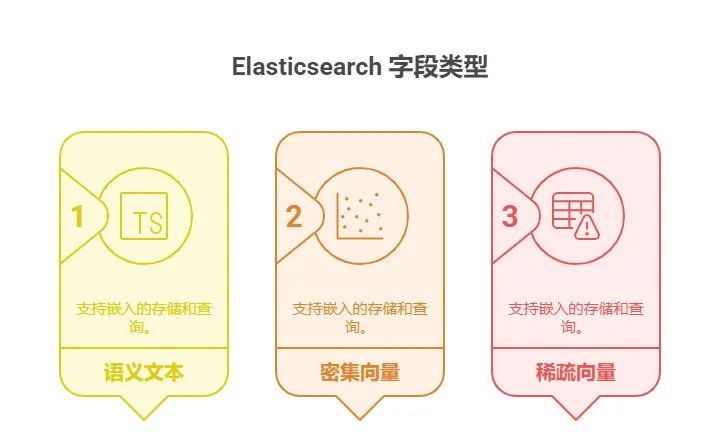
本文将以通俗易懂的方式,结合 Elasticsearch 最新9.X 版本,深入探讨这三种字段类型的特点、使用场景以及如何与嵌入向量生成相关联,帮助读者快速上手并选择适合自己业务场景的映射方式。
1. 什么是嵌入(Embedding)向量?
嵌入向量是将文本、图像等非结构化数据转化为数值向量的一种表示方式。这些向量能够捕捉数据的语义信息,使得计算机可以通过数学运算(例如余弦相似度)来比较数据之间的相似性。
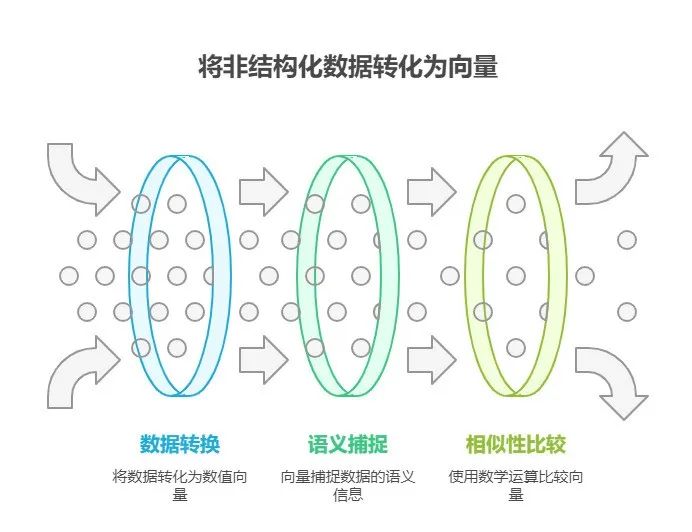
Elasticsearch 通过支持嵌入向量的字段类型,允许开发者存储和查询这些向量,从而实现更智能的搜索体验。
在Elasticsearch中,嵌入向量可以分为两种主要类型:
1.1 密集向量(Dense Vector)
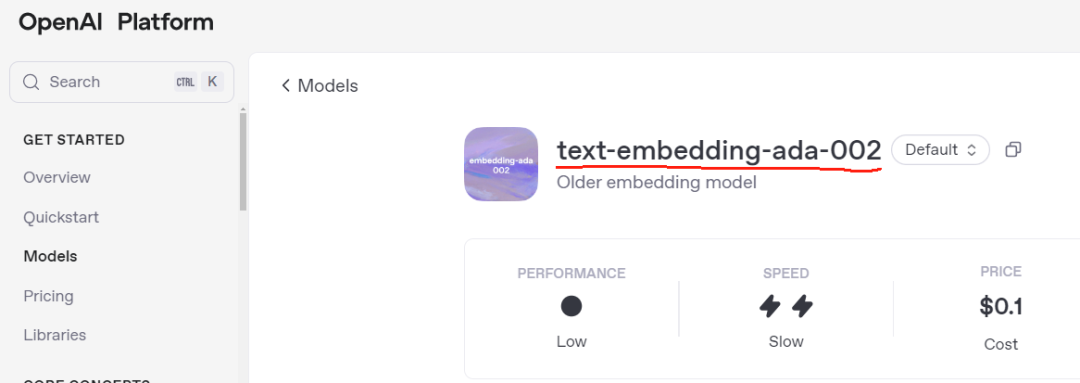
由语言模型(如OpenAI的text-embedding-ada-002或Hugging Face的all-MiniLM-L6-v2)生成,几乎所有维度都有非零值,通常用于捕捉文本的整体语义。
1.2 稀疏向量(Sparse Vector)
大部分值为零,只有少数关键维度有值,通常基于词项(Token)生成,适合需要词级精准匹配的场景。
Elasticsearch提供了三种字段类型来处理这些嵌入:dense_vector、sparse_vector和semantic_text。

接下来,我们将逐一解析它们的特性和适用场景。
2. 三种字段类型详解
2.1 dense_vector:灵活的密集向量存储
什么是dense_vector?
dense_vector字段类型用于存储密集向量,这些向量通常由深度学习模型生成,例如 OpenAI 的 text-embedding-ada-002(1536维)或 all-MiniLM-L6-v2(384维)。
密集向量能够捕捉文本的整体语义,即使文本之间没有相同的词,也可以比较它们的相似性。
什么时候使用dense_vector?
-
需要外部生成嵌入
如果你已经有一个外部嵌入生成管道(例如使用Hugging Face或Cohere模型),dense_vector是存储这些预生成向量的最佳选择。
-
需要自定义相似性计算
支持cosineSimilarity、dotProduct和l2norm等多种相似性计算方式,适合需要精细调整排名的场景。
-
复杂搜索场景
例如 RAG(检索增强生成)、推荐系统或个性化搜索,dense_vector提供了高度的灵活性和控制力。

如何查询 dense_vector?
dense_vector字段通常通过kNN(k最近邻)查询来实现向量搜索。
以下是一个简单的kNN查询示例:
POST test/_search{ \"knn\": { \"field\": \"my_dense_vector\", \"k\": 10, \"num_candidates\": 50, \"query_vector\": [ 0.1, 0.2, -0.3 ] }}如果需要更复杂的评分逻辑,可以使用 script_score查询结合相似性函数。
例如:
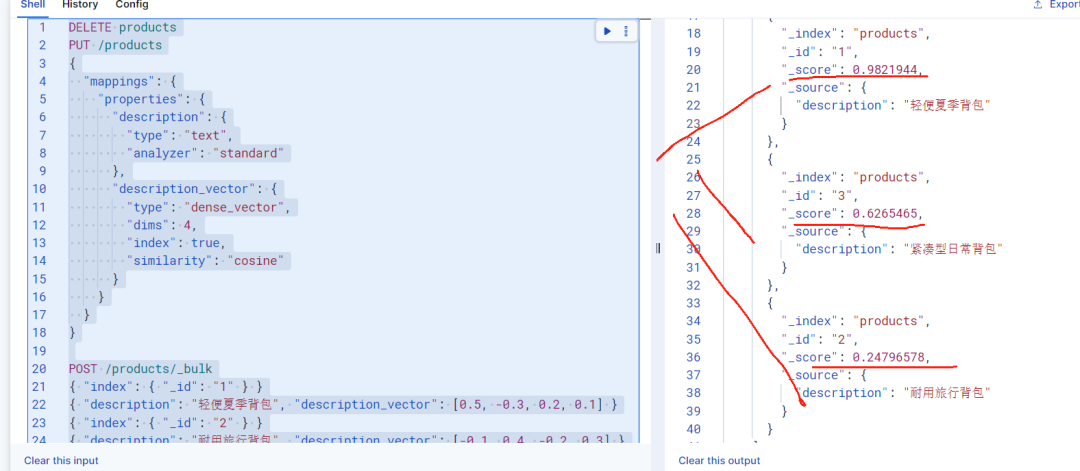
DELETE productsPUT /products{\"mappings\": { \"properties\": { \"description\": { \"type\": \"text\", \"analyzer\": \"standard\" }, \"description_vector\": { \"type\": \"dense_vector\", \"dims\": 4, \"index\": true, \"similarity\": \"cosine\" } } }}POST /products/_bulk{ \"index\": { \"_id\": \"1\" } }{ \"description\": \"轻便夏季背包\", \"description_vector\": [0.5, -0.3, 0.2, 0.1] }{ \"index\": { \"_id\": \"2\" } }{ \"description\": \"耐用旅行背包\", \"description_vector\": [-0.1, 0.4, -0.2, 0.3] }{ \"index\": { \"_id\": \"3\" } }{ \"description\": \"紧凑型日常背包\", \"description_vector\": [0.3, 0.1, -0.4, 0.2] }POST /products/_search{\"knn\": { \"field\": \"description_vector\", \"query_vector\": [0.4, -0.2, 0.3, 0.1], \"k\": 3, \"num_candidates\": 10 },\"_source\": [\"description\"]}优点与局限
-
优点:灵活性高,支持外部模型,适合高级用例。
-
局限:需要手动生成和存储向量,配置和维护成本较高。
2.2 sparse_vector:词级精准的稀疏向量
什么是 sparse_vector?
sparse_vector 字段类型用于存储稀疏向量,这类向量大部分维度为零,只有少数关键词(Token)具有非零权重。
稀疏向量常见于基于词项的模型,如Elasticsearch的 ELSER或 SPLADE 模型。
什么时候使用 sparse_vector?
-
需要词级精准匹配
稀疏向量以词为单位,适合需要精确匹配特定关键词的场景,同时保留一定的语义理解能力。
-
混合搜索策略
可以与
dense_vector结合使用,实现语义和词级搜索的平衡。 -
存储效率高
由于只存储非零值,稀疏向量在存储和查询时效率更高。
-
透明性强
可以清楚地看到哪些词对搜索结果的贡献最大,便于调试和优化。
如何查询 sparse_vector?
sparse_vector字段支持基于词/权重的查询方式。以下是一个手动指定词权重的查询示例:
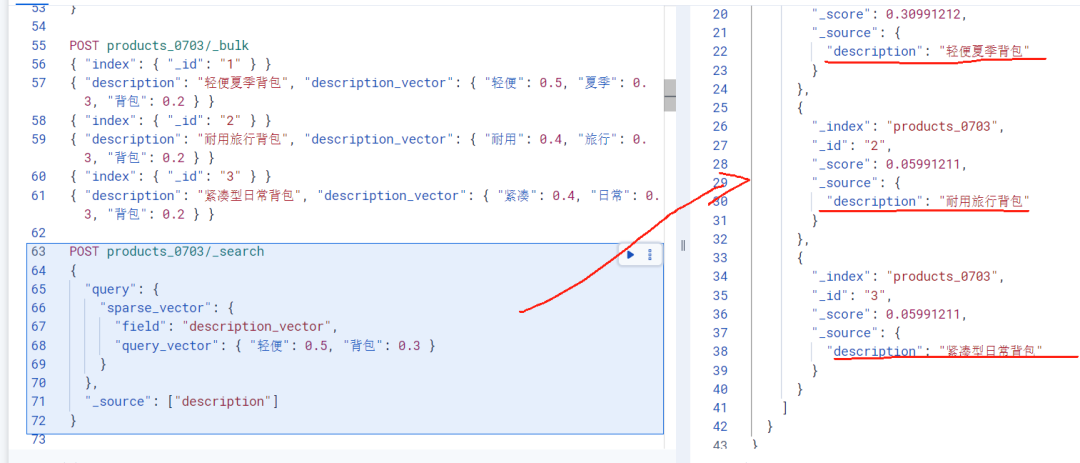
PUT products_0703{\"mappings\": { \"properties\": { \"description\": { \"type\": \"text\", \"analyzer\": \"standard\" }, \"description_vector\": { \"type\": \"sparse_vector\" } } }}POST products_0703/_bulk{ \"index\": { \"_id\": \"1\" } }{ \"description\": \"轻便夏季背包\", \"description_vector\": { \"轻便\": 0.5, \"夏季\": 0.3, \"背包\": 0.2 } }{ \"index\": { \"_id\": \"2\" } }{ \"description\": \"耐用旅行背包\", \"description_vector\": { \"耐用\": 0.4, \"旅行\": 0.3, \"背包\": 0.2 } }{ \"index\": { \"_id\": \"3\" } }{ \"description\": \"紧凑型日常背包\", \"description_vector\": { \"紧凑\": 0.4, \"日常\": 0.3, \"背包\": 0.2 } }POST products_0703/_search{\"query\": { \"sparse_vector\": { \"field\": \"description_vector\", \"query_vector\": { \"轻便\": 0.5, \"背包\": 0.3 } } },\"_source\": [\"description\"]}如果使用训练好的模型,可以通过推理端点自动生成稀疏向量:
{ \"query\": { \"sparse_vector\": { \"field\": \"field_sparse\", \"inference_id\": \"elser_inference\", \"query\": \"搜索文本\" } }}优点与局限
-
优点:存储效率高,词级匹配精准,适合混合搜索。
-
局限:需要支持稀疏向量的模型,生成逻辑相对复杂。
2.3 semantic_text:简单易用的语义搜索
什么是 semantic_text?
semantic_text 是 Elasticsearch 最新引入的字段类型,专为简化语义搜索设计。它通过推理端点自动处理嵌入向量的生成和存储,开发者无需手动管理向量。这是个付费 License 功能。
什么时候使用semantic_text?
-
快速上手:
如果你是语义搜索的新手,或者希望以最小的配置成本实现智能搜索,semantic_text是首选。
-
自动嵌入向量生成
无需外部生成向量,Elasticsearch在索引和查询时自动完成嵌入向量生成。
-
支持长文本分片:
置文本分块(Text Chunking)功能,适合处理长文档。
-
简化开发流程
预配置映射和推理端点,减少工程复杂性。
如何查询semantic_text?
semantic_text字段使用semantic查询,自动生成查询向量并与索引中的嵌入向量进行比较。
示例:
{\"query\": {\"semantic\": {\"field\": \"semantic_text_field\",\"query\": \"搜索文本\"}}}优点与局限
-
优点:简单易用,自动嵌入向量生成,适合快速开发。
-
局限:不支持外部生成嵌入向量,灵活性较低,仅限于 Elasticsearch 支持的推理模型。
3. 如何选择合适的字段类型?
选择semantic_text、dense_vector还是sparse_vector,需要根据你的业务场景、数据处理能力和技术栈成熟度来决定。
字段类型
使用场景
优点
局限性
-
外部生成嵌入向量(如 OpenAI、Hugging Face 模型)
-
复杂搜索逻辑(如 RAG、推荐系统)
-
需要自定义相似性计算(如 cosineSimilarity)
-
灵活性高,支持多种模型
-
可自定义排名逻辑
-
适用于语义相似性搜索
-
需要手动生成并存储向量
-
配置和维护成本较高
-
词级精准匹配(如 ELSER、SPLADE 模型)
-
混合搜索策略
-
需要透明度和存储效率
-
存储效率高,仅保存非零值
-
词级匹配精准,易于调试
-
适合混合语义和词级搜索
-
依赖稀疏模型,生成复杂
-
语义覆盖可能不足
-
快速开发,简化语义搜索配置
-
长文本处理(自动分块)
-
无需手动管理向量
-
简单易用,自动嵌入向量生成
-
支持推理端点,减少工程复杂性
-
内置文本分块功能
-
付费功能
-
依赖推理端点,不支持外部向量
-
灵活性较低,仅限支持模型
4. 嵌入向量生成与字段类型的关联
嵌入向量生成是使用Elasticsearch向量搜索的核心环节,不同字段类型对嵌入向量生成方式有不同的要求:
-
dense_vector:
需要外部生成密集向量(例如通过 OpenAI 或 Hugging Face 模型),然后将向量存储到Elasticsearch中。
-
sparse_vector:
通常由基于词项的模型(如 ELSER 或 SPLADE)生成,Elasticsearch 支持通过推理端点自动生成。
-
semantic_text:
完全依赖 Elasticsearch 的推理端点,索引和查询时自动生成嵌入向量,无需外部干预。
在实际应用中,你可能需要结合多种字段类型。
例如,可以使用semantic_text快速构建原型,使用dense_vector和sparse_vector优化复杂搜索逻辑。
5. 实战案例:构建智能搜索系统
假设你正在为一个电商平台构建商品搜索功能,用户可能输入模糊的查询(如“夏季轻便背包”),你希望返回语义相关的结果。以下是一个可能的实现路径:
-
1.快速原型
根据需求,使用semantic_text字段,配置一个推理端点(如all-MiniLM-L6-v2),快速实现语义搜索。——酌情选型!
-
2.优化性能
引入dense_vector字段,使用外部模型生成更高质量的嵌入向量,并通过kNN查询优化排名。
-
3.混合搜索
结合sparse_vector字段,使用ELSER模型增强词级匹配能力,提升搜索精准度。
6. 总结
Elasticsearch的semantic_text、dense_vector和sparse_vector字段类型为开发者提供了强大的工具来实现智能搜索。
semantic_text适合快速上手,dense_vector适合需要高灵活性的场景,sparse_vector则在词级精准匹配和混合搜索中表现出色。
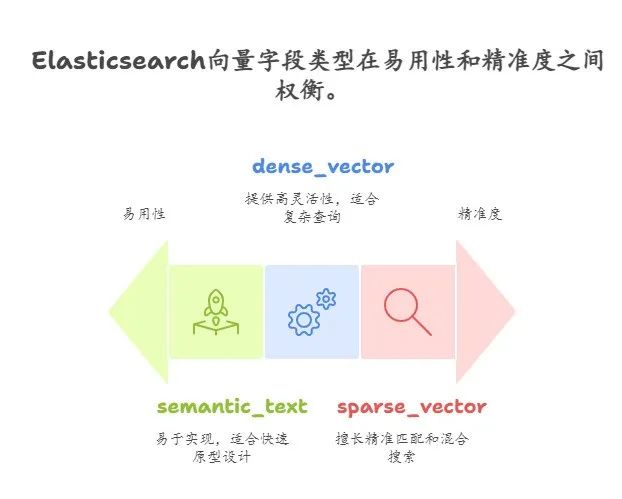
选择合适的字段类型需要综合考虑你的业务需求、技术能力以及对嵌入向量生成过程的控制需求。
希望这篇文章能帮助你更好地理解和应用Elasticsearch的嵌入向量映射功能!
如果有更多问题,欢迎随时交流。
参考资料
-
Elasticsearch Semantic Text Field Type
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-semantic-query.html
-
Dense Vector Field Type
https://www.elastic.co/docs/reference/elasticsearch/mapping-reference/dense-vector
-
Sparse Vector Field Type
https://www.elastic.co/docs/reference/elasticsearch/mapping-reference/sparse-vector
-
Elasticsearch Semantic Query
https://www.elastic.co/docs/reference/query-languages/query-dsl/query-dsl-semantic-query
-
Elasticsearch 8.X 如何利用嵌入向量提升搜索能力?
-
Elasticsearch 8.X 向量检索和普通检索能否实现组合检索?如何实现?
-
干货 | 详述 Elasticsearch 向量检索发展史
-
高维向量搜索:在 Elasticsearch 8.X 中利用 dense_vector 的实战探索

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!

