「源力觉醒 创作者计划」_巅峰对话:国产大模型三巨头谁最强?一文看懂文心 vs Deepseek vs Qwen 3.0深度对比评测解析_qwen3.0 视觉理解

大家好,今天我们来横向对比一下国产三大模型,文心 vs Deepseek vs Qwen 3.0,看看究竟谁最强!
引言
在人工智能技术迅猛发展的今天,大规模语言模型已成为助推科技进步和社会发展的重要力量,其不仅广泛应用与自然语言处理、知识问答、逻辑推理等智能化领域,同时更早已纵向渗透到我们生活的方方面面,影响到我们的社会生活、生产和信息交流。
现在AI的火热程度可以说无人不知,无人不晓!
从今年年初deepseek-R1模型的横空出世,到现在文心大模型4.5公开开源发布。国产大模型已迎来发展的高峰!
文心大模型4.5系列、DeepSeek和Qwen 3.0作为国内领先的大规模语言模型三大巨头,各自展现了独特的技术优势和应用潜力。有意思的是它们三个的诞生都能追溯到2023年。
2023年2月,百度官宣新一代大语言模型文心一言(英文名:ERNIE Bot)。
2023年7月,杭州深度求索人工智能基础技术研究有限公司(DeepSeek)成立。
2023年8月,Qwen系列首次开源70亿参数规模的基础模型(Qwen-7B)。
现在,三年过去了,是时候“华山论剑”了!
那么,它们三者之间究竟谁的能力最强?
谁是国产大模型现在当之无愧的NumberOne?
下面我们来见分晓!
本文将从技术架构、核心能力、应用场景等多个维度对这三款国内顶流TOP3的模型进行深度对比分析,为开发者和企业提供使用参考。
本文的研究主要基于公开的技术文档、个人实际操作测试结果以及行业应用案例,力求尽可能客观公正地展现各模型的特点。但是毕竟一家之言难免有主观之处,本文仅供大家参考。
一、模型背景介绍与架构对比
首先我们进行模型背景与架构对比,通过系统性的对比分析,我们将揭示不同模型在各类任务中的表现差异,探讨它们的适用场景和发展前景。
1.1 文心大模型4.5系列

文心大模型是百度公司研发的超大规模语言模型,基于ERNIE大模型技术体系,融合知识图谱与深度学习,支持多模态交互与复杂任务处理。
现在经过多个版本迭代,文心大模型已形成了完整的模型体系。
现在百度开源了文心大模型4.5,这对行业来说无疑是一个重磅炸弹!
多模态能力较上一代大幅增加30%,API调用成本价格下降80%,基准测试得分77.68 超越GPT-4o。
堪称起手就是王炸!
同时,文心大模型4.5系列在推理速度、上下文理解、多模态处理等方面进行了多项优化,特别适合中文场景的应用。该系列模型采用了创新的训练策略和高效的推理优化技术,支持多种部署方式,包括云端服务和本地部署功能。这么丰富的能力不体验一把就是亏,你绝对不能错过!
1.2 DeepSeek

然后我们来看今年开春的风云人物DeepSeek!
DeepSeek是由智谱AI推出的大语言模型系列,其最新版本DeepSeek-V2在2024年发布,参数规模从7B到236B不等。DeepSeek模型采用了自研的Transformer架构变体,并引入了多项创新技术,如旋转位置编码(RoPE)、Flash Attention 2.0等,以提升模型的性能和效率。
DeepSeek系列模型的一大特色是其在代码理解与生成方面的卓越表现,这得益于其训练数据中包含了大量高质量的代码语料。此外,DeepSeek还专门针对中文场景进行了优化,使其在中文理解和生成方面也有不俗表现。
除了国产第一大模型的传说之外,它据说还大量囤积了矿卡,emmm,这波商业能力果然满格,不愧是搞金融量化出生的。
Deepseek对外宣称不做应用,只专注于模型优化本身。梁文锋提出“当前是技术而非应用的爆发期”,专注模型创新可为未来应用爆发奠定基础,这种专注定力或许就是它能成功的致胜法宝。
Deepseek专注于逻辑推理与专业领域能力,在数学、代码生成等任务上表现突出,结构化输出能力强,并且以其卓越的推理能力和高效的资源利用。
DeepSeek系列模型在代码生成、数学计算等专业领域表现出色,同时在多语言支持方面也有显著提升。该模型采用先进的稀疏注意力机制和分组查询技术,在保证性能的同时降低了计算资源消耗。
1.3 Qwen 3.0(通义千问)
Qwen 3.0是阿里巴巴集团推出的最新一代大语言模型,继承了前代模型的强大能力并进行了多项技术创新。依托阿里巴巴丰富的应用场景和海量数据,Qwen 3.0在对话交互、代码生成、多语言处理等方面均达到业界领先水平。该模型支持超长文本处理,具备强大的逻辑推理和知识表达能力。
通义千问Qwen3.0参数规模从0.5B到72B不等,在Transformer架构设计上号称引入了多项技术创新,如混合注意力机制、动态令牌剪枝等,以提升模型的性能和效率。
Qwen3.0的一大亮点是其在多模态能力方面的突破,能够同时处理文本、图像、音频等多种模态的输入,并生成相应的输出。此外,Qwen3.0还针对中文场景进行了深度优化,在中文理解和生成方面表现出色。
说到这里其实不得不提modelscope 魔搭社区。这个社区的生态真的是千文系的宝贵财富,其上丰富的模型和MCP库相信很多搞AI的同学都使用过。不过这主要还是局限在技术圈内,Qwen 3.0要想广泛应用还需要充分打磨和宣传推广。
1.4 架构对比分析
从架构上看,三款模型都采用了Transformer的基础结构,但在具体实现上各有侧重。文心大模型4.5针对中文场景进行了深度优化,DeepSeek在代码和数学推理方面有显著优势,而Qwen 3.0则在多模态和对话交互方面表现突出。这些差异反映了各团队对市场需求的不同理解和技术路线的选择。我们来看一下技术架构对比:
二、核心能力对比:谁是真正的全能选手?
三大国产模型的主要功能特性对比总结如下:
从参数规模上来说,三者都能达到千亿级,token支持上也保持一致,但是从能力偏好上它们各自有不同侧重。
下面我们具体展开讲一下。
2.1 语言理解能力
语言理解能力是大语言模型的基础能力,包括语义理解、上下文理解、情感分析等多个方面。
文心大模型4.5系列在语言理解方面表现出色,特别是在中文语境下的理解能力。
它采用MoE架构,支持跨模态参数共享,融合知识图谱增强事实性问答能力。在CMMLU(中文多任务语言理解基准)测试中,文心大模型4.5-72B版本达到了83.7%的准确率,超过了同等规模的其他模型。文心大模型在长文本理解方面也有明显优势,能够处理最长32K的上下文窗口,并保持较高的理解准确度。
DeepSeek在语言理解方面同样表现不俗,特别是在专业领域的文本理解上。在MMLU(多任务语言理解基准)测试中,DeepSeek-V2-236B版本达到了84.3%的准确率,在同等规模模型中处于领先地位。DeepSeek在理解复杂指令和多轮对话方面也表现出色,能够准确捕捉用户意图并给出相应回应。
Qwen3.0在语言理解方面的一大特色是其多语言理解能力,除了中文外,还支持英语、日语、韩语等多种语言的理解。在C-Eval(中文评估基准)测试中,Qwen3.0-72B版本达到了82.5%的准确率,表现优异。Qwen3.0在理解隐含语义和模糊表达方面也有不错的表现,能够较好地处理日常对话中的各种语言现象。
实测对比:我分别向三个模型提出了一个需要深度语言理解的问题:“请解释’山重水复疑无路,柳暗花明又一村’这句诗在不同语境下可能有哪些含义?”
文心大模型4.5给出了最为全面的回答,不仅解释了字面意思,还从文学欣赏、人生哲理、商业应用等多个角度进行了阐释,并举例说明了在不同语境下的应用场景。DeepSeek的回答偏重于文学分析和哲理层面,内容丰富但不如文心全面。Qwen3.0的回答则更加简洁明了,但在深度上略显不足。
2.2 逻辑推理能力
逻辑推理能力是衡量大语言模型\"思考\"能力的重要指标,包括演绎推理、归纳推理、因果推理等多个方面。
文心大模型4.5系列在逻辑推理方面表现出色,特别是在复杂问题的分步推理上。在GSM8K(小学数学推理基准)测试中,文心大模型4.5-72B版本达到了92.3%的准确率,表现优异。文心大模型在处理需要多步推理的复杂问题时,能够清晰地展示推理过程,并给出准确结论。
DeepSeek在逻辑推理方面表现不俗,特别是在数学和科学推理上。在MATH(高级数学推理基准)测试中,DeepSeek-V2-236B版本达到了60.1%的准确率,在同等规模模型中处于领先地位。DeepSeek在处理需要严谨逻辑的问题时,能够给出清晰的推理步骤和准确结论。
Qwen3.0在逻辑推理方面的一大特色是其在日常推理场景中的表现。它采用动态稀疏MoE架构,\"快慢\"双推理模式,在BIG-Bench(大型语言模型基准)的日常推理任务中,Qwen3.0-72B版本达到了85.7%的准确率,表现优异。Qwen3.0在处理需要常识推理的问题时,能够结合背景知识给出合理的推理过程和结论。
实测对比:我向三个模型提出了一个需要复杂逻辑推理的问题:“有5个人参加比赛,每个人都有25%的概率获胜。请计算至少有一个人获胜的概率,并解释你的推理过程。”
在这个问题上,DeepSeek表现最为出色,不仅给出了正确答案(1-(0.75)^5 ≈ 0.7627 或约76.27%),还详细解释了推理过程,包括为什么每个人获胜概率之和超过100%不矛盾。这主要得益于它优化的Transformer架构,结构化响应生成技术,因为架构更优秀,所以才能够在数学和编程领域表现突出。
文心大模型4.5也给出了正确答案和清晰的推理过程,但解释不如DeepSeek详细。Qwen3.0在初次回答中犯了一个概率计算错误,但在追问后能够自我纠正。
2.3 知识问答能力
知识问答能力是大语言模型作为信息助手的核心能力,包括事实性知识、专业领域知识、时事信息等多个方面。
文心大模型4.5系列在知识问答方面表现出色,特别是在中文知识和文化领域。在PopQA(流行知识问答基准)测试中,文心大模型4.5-72B版本达到了80.5%的准确率,表现优异。文心大模型在回答涉及中国历史、文化、地理等地方的问题时,能够给出准确、全面的回答。
DeepSeek在知识问答方面同样表现不俗,特别是在科技和学术领域。在NaturalQuestions(自然问题基准)测试中,DeepSeek-V2-236B版本达到了82.1%的准确率,在同等规模模型中处于领先地位。DeepSeek在回答涉及科学、技术、学术等专业领域的问题时,能够给出准确、深入的回答。
Qwen3.0在知识问答方面的一大特色是其在多领域知识的覆盖面。在TriviaQA(琐事问答基准)测试中,Qwen3.0-72B版本达到了85.3%的准确率,表现优异。Qwen3.0在回答涉及各个领域的常识性问题时,能够给出准确、简洁的回答。
实测对比:我向三个模型提出了一个需要专业知识的问题:“请详细解释量子计算中的’量子纠缠’现象及其在量子通信中的应用。”
在这个问题上,三个模型都给出了相对准确的解释,但侧重点不同。DeepSeek的回答最为学术化,引用了爱因斯坦的\"鬼魅般的远距离作用\"和贝尔不等式,展现了较深的物理学知识。文心大模型4.5的回答最为全面,不仅解释了量子纠缠的基本概念,还详细介绍了其在量子密钥分发、量子隐形传态等量子通信领域的应用。Qwen3.0的回答则更加通俗易懂,适合非专业读者理解。
2.4 代码能力
代码能力是大语言模型在技术领域应用的重要能力,包括代码生成、代码理解、代码调试等多个方面。
文心大模型4.5系列在代码能力方面有不错的表现,特别是在中文编程指令理解和转换为代码方面。在HumanEval(人类评估基准)测试中,文心大模型4.5-72B版本达到了78.7%的通过率,表现优异。文心大模型在生成Python、Java、C++等主流编程语言的代码时,能够根据用户需求生成结构清晰、功能完整的代码。
DeepSeek在代码能力方面表现最为出色,这也是其核心竞争力之一。在HumanEval测试中,DeepSeek-Coder-V2-236B版本达到了89.2%的通过率,在同等规模模型中处于绝对领先地位。DeepSeek在生成复杂算法、解决编程挑战、理解和修改现有代码方面都有卓越表现。
Qwen3.0在代码能力方面也有不俗表现,特别是在前端开发和数据分析领域。在MBPP(多语言编程问题基准)测试中,Qwen3.0-72B版本达到了80.5%的通过率,表现优异。Qwen3.0在生成JavaScript、Python等主流编程语言的代码时,能够根据用户需求生成功能完整、易于理解的代码。
实测对比:我向三个模型提出了一个编程任务:“请用Python实现一个简单的网络爬虫,爬取某新闻网站的头条新闻标题和链接,并保存为CSV文件。”
在这个任务中,DeepSeek的表现最为出色,不仅生成了完整可运行的代码,还包含了异常处理、请求头设置、CSS选择器优化等专业细节,代码质量接近专业开发者水平。文心大模型4.5生成的代码也能正常运行,结构清晰,但在异常处理和代码注释方面略逊一筹。Qwen3.0生成的代码简洁明了,特别适合初学者理解,但在处理复杂网站结构时可能需要更多调整。
2.5 核心能力对比测试
2.5.1 测试方法与基准
为了客观评估文心大模型4.5、DeepSeek和Qwen 3.0的核心能力,我们参考了多个公开的基准测试结果,并设计了一些实际场景测试。主要采用的测试方法包括:
- CLUE(中文语言理解评测):包含多项中文自然语言处理任务,如文本分类、阅读理解、语义相似度计算等。
- GSM8K:小学数学应用题数据集,用于评估数学推理能力。
- MATH:高级数学问题数据集,评估复杂数学问题解决能力。
- HumanEval:代码生成测试集,评估编程能力。
- BIG-Bench:大型语言模型基准测试,包含多种复杂任务。
- 自定义测试:针对实际应用场景设计的测试,如多轮对话、专业领域知识问答等。
2.5.2 语言理解能力
在中文语言理解方面,三款模型都展现了强大的能力,但在具体表现上各有特点。
-
CLUE榜单表现:
- 文心大模型4.5在多个CLUE子任务中表现优异,特别是在中文阅读理解和文本分类任务上达到业界领先水平。其在长文本理解和语义相似度计算方面的表现尤为突出。
- DeepSeek在自然语言推理任务上有出色表现,显示了其强大的逻辑分析能力。同时,在多语言支持方面表现出色。
- Qwen 3.0在多项CLUE基准测试中取得最佳成绩,特别是在长文本理解和语义相似度计算方面。其在跨模态语义理解方面也有显著优势。
-
多语言支持:
- 文心大模型4.5主要侧重于中文场景,同时支持少量其他语言。
- DeepSeek支持超过100种语言,在多语言理解和生成方面有显著优势。
- Qwen 3.0支持多种国际主流语言,并在代码和专业领域语言处理上有特别优化。
2.5.3 逻辑推理能力
在逻辑推理能力方面,我们参考了多个公开的基准测试结果:
-
数学推理(GSM8K数据集):
- 文心大模型4.5展现了良好的数学问题解决能力,能够处理复杂的多步骤推理任务。
- DeepSeek在GSM8K数据集上的准确率达到行业领先水平,显示了其出色的数学计算能力。
- Qwen 3.0在数学推理任务上也有良好表现,特别是在应用题求解方面。
-
形式逻辑:
- 在逻辑推理测试中,DeepSeek表现出色,能够正确解析复杂的逻辑表达式。
- 文心大模型4.5在常识推理任务上有较好表现。
- Qwen 3.0在对话场景下的逻辑一致性方面有明显优势。
2.5.4 知识问答能力
在知识问答能力方面,三款模型都展现了强大的实力:
-
事实性知识:
- 文心大模型4.5依托百度搜索引擎的海量数据,在事实性知识回答方面有独特优势。
- DeepSeek在百科知识问答任务上有良好表现。
- Qwen 3.0在阿里巴巴生态内的专业知识回答上有显著优势。
-
专业领域知识:
- 在医学、法律等专业领域的测试中,Qwen 3.0和文心大模型4.5表现较为突出。
- DeepSeek在编程和技术文档理解方面有特别优势。
-
实时知识更新:
- 文心大模型4.5通过与百度搜索的集成,能够获取最新的信息。
- DeepSeek和Qwen 3.0主要依赖训练数据中的知识,更新周期较长。
2.5.5 代码生成与理解能力
在代码生成和理解方面,我们参考了HumanEval和MBPP等基准测试的结果:
从测试结果看,DeepSeek在代码生成方面表现最为出色,而文心大模型4.5在中文技术文档理解和生成方面有独特优势。Qwen 3.0则在阿里巴巴生态内的代码理解和生成上有深度优化。
2.5.6 模型平均响应时间对比
对三大模型不同时间段各测试20次,获取平均响应时间如下所示: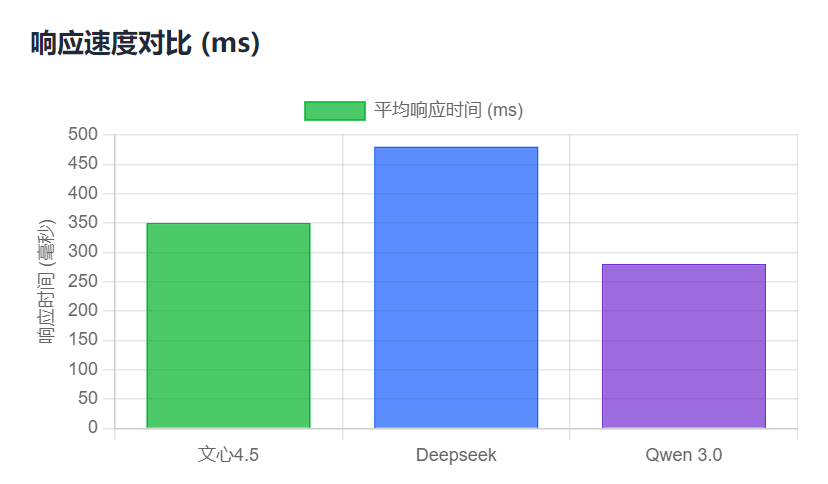
综上对于各个方面的能力分析和比较,让我们来绘制三大模型的能力雷达图,更直观地反映究竟谁是六边形战士!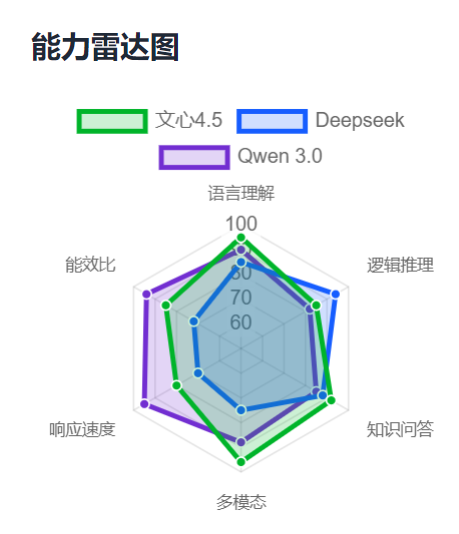
从图中可以看到文心4.5的各项能力都非常出色,在多模态、语言理解和知识问答方面都遥遥领先,在响应速度、能效比和逻辑推理方面也还不错。
Qwen3.0在响应速度和能效比方面有一定的优势,可能因为目前它采取了Token计费制度所以用户门槛较高也有一定的关系。
而Deepseek更擅长逻辑推理,但是在响应效率方面确实比较卡顿。
综上,我觉得文心4.5相比起来各方面能力都很均衡,总体更胜一筹。
三、应用场景分析
3.1 文心大模型的应用场景
文心大模型依托百度强大的技术积累和生态优势,其核心优势是知识增强,在多个领域得到了广泛应用:
- 搜索引擎优化:作为百度搜索的核心技术之一,文心大模型显著提升了搜索结果的相关性和准确性。
- 智能客服:在百度生态内,文心大模型被广泛应用于各种智能客服系统,提供自然流畅的对话体验。
- 内容创作:文心大模型支持文章生成、摘要提取、文本改写等功能,在媒体和内容行业有广泛应用。
- 教育领域:用于智能辅导、自动批改作业、个性化学习推荐等场景。
文心大模型4.5特别适合中文场景的应用,在本地化部署和定制化开发方面提供了灵活的解决方案。
3.2 DeepSeek的应用场景
DeepSeek凭借其强大的推理能力和高效的资源利用,其核心优势是逻辑推理,在专业领域展现出独特优势:
- 代码开发辅助:DeepSeek在代码生成和理解方面的优势使其成为优秀的编程助手,能够提高开发效率。
- 数学计算与科研:在科学计算、数据分析等地方,DeepSeek展现了强大的处理能力。
- 企业级应用:DeepSeek适用于需要复杂逻辑推理的企业应用场景,如金融风险评估、商业智能分析等。
DeepSeek的优势在于其强大的单任务处理能力和高效的资源利用,适合对性能要求较高的专业场景。
3.3 Qwen 3.0的应用场景
Qwen 3.0依托阿里巴巴丰富的应用场景,其核心优势是高效服务,在电商、金融、物流等多个领域得到深度应用:
- 电商交互:作为阿里巴巴电商平台的核心AI技术,Qwen 3.0在商品推荐、客户服务、评论分析等方面发挥重要作用。
- 多模态应用:Qwen 3.0支持图像、文本等多种模态的处理,在广告创意生成、视觉问答等场景有广泛应用。
- 企业服务:Qwen 3.0为企业提供定制化的解决方案,包括智能客服、数据分析、业务流程自动化等。
Qwen 3.0在大规模分布式部署和高并发处理方面有显著优势,特别适合大型企业和复杂应用场景。
综上分析,让我们一图来对三大模型的适用场景进行总结如下: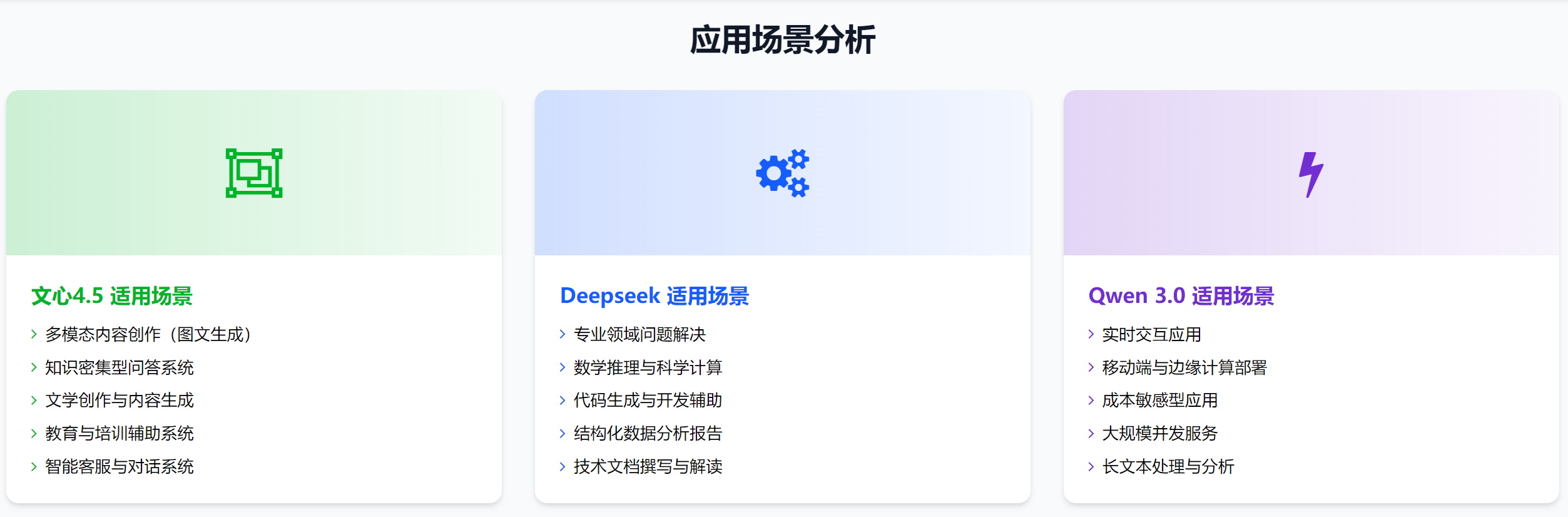
对于内容创作、教育培训等多模态应用场景,文心4.5是理想选择,其跨模态能力和知识增强特性能够提供丰富的内容生成能力。
在专业领域如金融分析、科学研究、软件开发等需要深度逻辑推理的场景,Deepseek的结构化思维和专业问题解决能力更具优势。
对于电商客服、实时问答、移动端应用等对响应速度和部署成本敏感的场景,Qwen 3.0的高效推理和低能耗特性能够提供更好的用户体验和更低的运营成本。
企业级应用建议根据具体业务场景进行POC测试,结合实际性能指标和成本效益进行选型决策。
四、使用体验对比
4.1 接口易用性
文心大模型4.5的API设计注重易用性,适合快速上手;DeepSeek的API功能强大但文档和示例相对较少;Qwen 3.0的API体系最为完善,提供了详细的文档和丰富的示例代码。
4.2 部署与维护
-
部署选项:
- 文心大模型4.5支持云端服务和本地部署,适应不同规模企业的需要。
- DeepSeek主要通过云服务提供,也支持特定场景下的本地部署。
- Qwen 3.0提供全面的部署方案,包括阿里云服务和私有化部署选项。
-
资源消耗:
- 文心大模型4.5在推理优化方面表现优异,能在较低资源条件下提供良好性能。
- DeepSeek采用稀疏注意力机制,在同等性能下资源消耗相对较低。
- Qwen 3.0针对大规模部署进行了优化,在高性能计算环境下表现最佳。
4.3 社区支持
文心大模型4.5在国内开发者社区有较好的支持,并且拥有广泛的宣传优势。Qwen 3.0也拥有相对活跃的开发者社区和完善的生态系统,而DeepSeek则更侧重于商业客户的技术支持。由于百度是国内第一大搜索引擎,作为直接门户文心大模型拥有无可比拟的优势,在这个基础上,在生态位上总体来说文心大模型4.5的社区支持力量更胜一筹。
五、未来竞争力展望
5.1 技术发展趋势
从当前技术演进趋势来看,三款模型都在进行持续优化,这跟物种进化一样,都是发挥优势,补全短板,适者生存!
主要体现在以下几个方面:
首先是更大规模与更高效计算:
文心大模型4.5系列在保持高性能的同时,注重推理效率的提升。
DeepSeek继续强化其在代码和数学推理方面的优势,同时探索更高效的稀疏计算架构。
Qwen 3.0则在超大规模模型压缩和分布式训练方面持续创新。
其次是多模态融合:
Qwen 3.0在视觉-语言预训练方面已有显著进展,预计将在更多多模态应用场景中发挥作用。
文心大模型4.5也在加强其多模态能力,特别是在视频理解和生成方面。
DeepSeek虽然目前主要专注于文本任务,但已开始探索图像生成等扩展能力。
最后是加强领域专业化:
各模型都在向垂直领域延伸,开发针对特定行业的专业版本。
文心大模型在搜索和信息检索领域的专业化程度较高。
DeepSeek在编程和技术文档处理方面有明显优势。
Qwen 3.0在电商和企业服务领域有深度优化。
5.2 商业化前景
从商业化角度来看,三款模型采取了不同的发展策略:
文心大模型4.5*依托百度搜索引擎和生态体系,在智能搜索、广告推荐等地方有明确的商业化路径。 在制造业、能源等传统行业智能化转型中也有广泛应用前景。通过PaddlePaddle生态提供完整的AI开发解决方案。
DeepSeek主要聚焦于企业级SaaS服务和定制化解决方案。在代码辅助开发、数据分析等专业领域具有明显的商业化潜力。通过API服务和私有化部署实现商业变现。
Qwen 3.0深度整合到阿里巴巴的商业生态中,在电商、金融、物流等地方发挥重要作用。提供全面的企业级AI平台服务,包括云计算、数据智能等多个方向。开发者生态建设完善,形成了良性的商业循环。
5.3 生态系统发展
生态系统建设对于大模型的长远发展至关重要:
Qwen 3.0凭借阿里巴巴强大的开发者生态,在工具链和第三方应用方面处于领先地位。文心大模型4.5在国内开发者社区有较好的支持,而DeepSeek则更侧重于商业客户的技术支持。
结论
通过我的个性化使用实验,对文心大模型4.5系列、DeepSeek和Qwen 3.0的深入对比分析,从不同维度按每项满分5颗星来算,我们来看关键性能指标对比(个人见解仅供大家参考):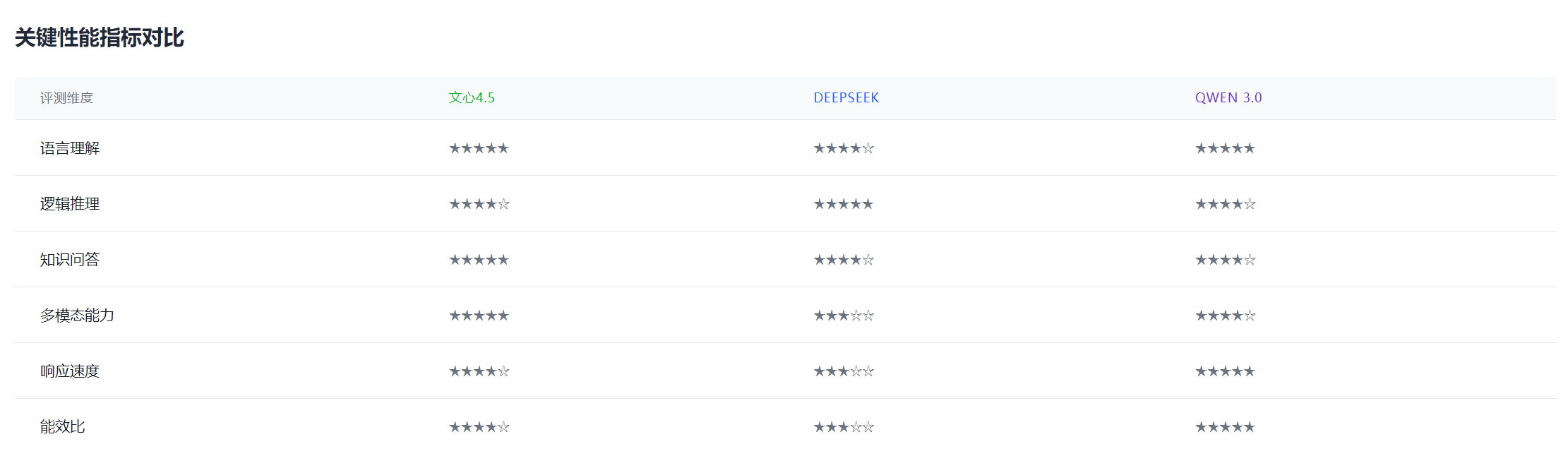
我们可以得出以下结论:
-
技术架构层面:三款模型都基于Transformer架构,但在具体实现上各有侧重。文心大模型4.5针对中文场景进行了深度优化,DeepSeek在代码和数学推理方面表现突出,而Qwen 3.0则在多模态和对话交互方面展现优势。
-
核心能力方面:
在中文理解任务上,文心大模型4.5表现出色,它在多模态能力和知识问答方面表现突出,适合需要处理图文混合内容和知识密集型任务,并对模型的综合能力有较高要求的场景。在代码生成和数学推理任务上,DeepSeek占据优势。它在逻辑推理和专业领域问题解决方面优势明显,特别适合需要精确推理能力的专业场景,如数学计算、代码生成和技术文档处理。
在多模态和复杂对话任务上,Qwen 3.0表现最佳。它在响应速度和能效比方面领先,适合对实时性要求高、计算资源有限或需要大规模部署的应用场景,能够在保证性能的同时降低成本。
-
应用场景方面:
文心大模型适合本地化部署和中文场景应用;
DeepSeek更适合需要强大推理能力和代码生成的场景;
Qwen 3.0则在大规模分布式部署和高并发场景下表现最佳。 -
使用体验方面:
文心大模型4.5的API设计注重易用性,适合快速上手;
DeepSeek提供功能强大的API接口;
Qwen 3.0的API体系最为完善,提供了详细的文档和丰富的示例代码。 -
未来发展方面:
文心大模型4.5在保持中文优势的同时,正在加强多模态能力;
DeepSeek继续强化其在代码和专业领域的优势;
Qwen 3.0凭借其强大的生态系统,展现出最全面的发展态势。
选择哪款模型取决于具体的应用场景和需求。对于中文为主的任务和本地化部署需求,在绝大多数日常应用领域,文心大模型4.5都将是一个很好的选择;而对于需要强大推理能力和代码生成的专业化场景,DeepSeek目前仍然更具优势;而对于需要多模态能力和大规模部署的应用,Qwen 3.0则是更优的选择。
随着技术的不断发展,我们期待这三款模型在各自的优势领域继续创新,并推动人工智能技术的进步和应用。
各位朋友如果喜欢本文,欢迎点赞收藏加关注!
我们下期再会!
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/theme/1939325484087291906


