AI【应用 02】STT 工具 OpenAI Whisper Windows环境安装测试(入门版本)_openai windows安装
官方的《README》文档内容很详细,包含原理、安装、模型说明、使用方法等,大家可以参考,以下内容是基于博主《@Major Tom》的《本地部署Whisper实现语言转文字》整理,进行了一些细节的补充,操作更加简单。简单说一下环境,用的 Windows 台式机,装的的有 Anaconda。
OpenAI Whisper Windows环境安装测试
- 1.安装
-
- 1.1 chocolatey(目的是安装工具 ffmpeg)
- 1.2 ffmpeg
- 1.3 Whisper
- 2.使用
- 3.实例
- 4.总结
https://blog.csdn.net/m0_52474839/article/details/139188780
https://blog.csdn.net/weixin_69087874/article/details/148155979
https://www.cnblogs.com/liupiaos/p/18465211
官方的《README》文档内容很详细,包含原理、安装、模型说明、使用方法等,大家可以参考,以下内容是基于博主《@Major Tom》的《本地部署Whisper实现语言转文字》整理,进行了一些细节的补充,操作更加简单。简单说一下环境,用的 Windows 台式机,装的的有 Anaconda。
1.安装
官方《安装说明》的 ffmpeg 部分内容:
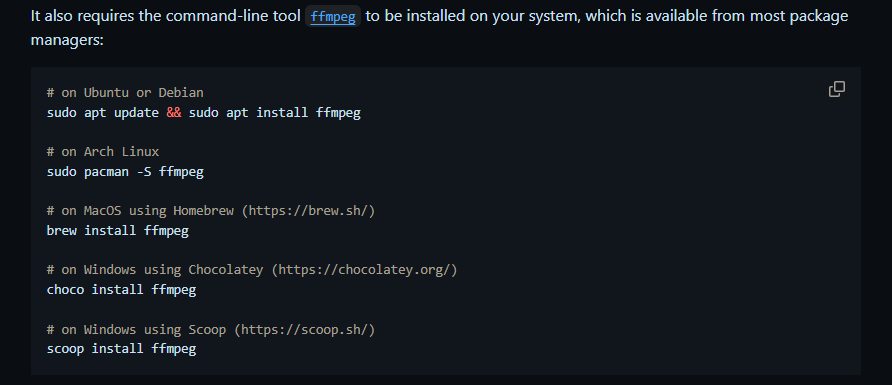
1.1 chocolatey(目的是安装工具 ffmpeg)
- 使用 Powershell 安装 chocolatey
Shift+鼠标右键 --> 在此处打开 Powershell 窗口(S) --> 输入一下文本
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString(\'https://community.chocolatey.org/install.ps1\'))- 安装过程输出
Forcing web requests to allow TLS v1.2 (Required for requests to Chocolatey.org)Getting latest version of the Chocolatey package for download.Not using proxy.Getting Chocolatey from https://community.chocolatey.org/api/v2/package/chocolatey/2.4.3.Downloading https://community.chocolatey.org/api/v2/package/chocolatey/2.4.3 to C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\chocolatey\\chocoInstall\\chocolatey.zipNot using proxy.Extracting C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\chocolatey\\chocoInstall\\chocolatey.zip to C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\chocolatey\\chocoInstallInstalling Chocolatey on the local machineCreating ChocolateyInstall as an environment variable (targeting \'Machine\') Setting ChocolateyInstall to \'C:\\ProgramData\\chocolatey\'WARNING: It\'s very likely you will need to close and reopen your shell before you can use choco.Restricting write permissions to AdministratorsWe are setting up the Chocolatey package repository.The packages themselves go to \'C:\\ProgramData\\chocolatey\\lib\' (i.e. C:\\ProgramData\\chocolatey\\lib\\yourPackageName).A shim file for the command line goes to \'C:\\ProgramData\\chocolatey\\bin\' and points to an executable in \'C:\\ProgramData\\chocolatey\\lib\\yourPackageName\'.Creating Chocolatey CLI folders if they do not already exist.chocolatey.nupkg file not installed in lib. Attempting to locate it from bootstrapper.PATH environment variable does not have C:\\ProgramData\\chocolatey\\bin in it. Adding...警告: Not setting tab completion: Profile file does not exist at\'D:\\Documents\\WindowsPowerShell\\Microsoft.PowerShell_profile.ps1\'.Chocolatey CLI (choco.exe) is now ready.You can call choco from anywhere, command line or powershell by typing choco.Run choco /? for a list of functions.You may need to shut down and restart powershell and/or consoles first prior to using choco.Ensuring Chocolatey commands are on the pathEnsuring chocolatey.nupkg is in the lib folder1.2 ffmpeg
- 安装命令
choco install ffmpeg- 安装过程输出
Chocolatey v2.4.3Installing the following packages:ffmpegBy installing, you accept licenses for the packages.Downloading package from source \'https://community.chocolatey.org/api/v2/\'Progress: Downloading ffmpeg 7.1.1... 100%ffmpeg v7.1.1 [Approved]ffmpeg package files install completed. Performing other installation steps.The package ffmpeg wants to run \'chocolateyInstall.ps1\'.Note: If you don\'t run this script, the installation will fail.Note: To confirm automatically next time, use \'-y\' or consider:choco feature enable -n allowGlobalConfirmationDo you want to run the script?([Y]es/[A]ll - yes to all/[N]o/[P]rint): YExtracting 64-bit C:\\ProgramData\\chocolatey\\lib\\ffmpeg\\tools\\ffmpeg-release-essentials.7z to C:\\ProgramData\\chocolatey\\lib\\ffmpeg\\tools...C:\\ProgramData\\chocolatey\\lib\\ffmpeg\\toolsRemoving extracted archive.Sleeping for 2 seconds to allow anti-viruses to finish scanning...Renaming ffmpeg directory to common name (Try 1 / 3)Successfully renamed directory. ShimGen has successfully created a shim for ffmpeg.exe ShimGen has successfully created a shim for ffplay.exe ShimGen has successfully created a shim for ffprobe.exe The install of ffmpeg was successful. Deployed to \'C:\\ProgramData\\chocolatey\\lib\\ffmpeg\\tools\'Chocolatey installed 1/1 packages. See the log for details (C:\\ProgramData\\chocolatey\\logs\\chocolatey.log).1.3 Whisper
官方《安装说明》的 Setup 部分内容:
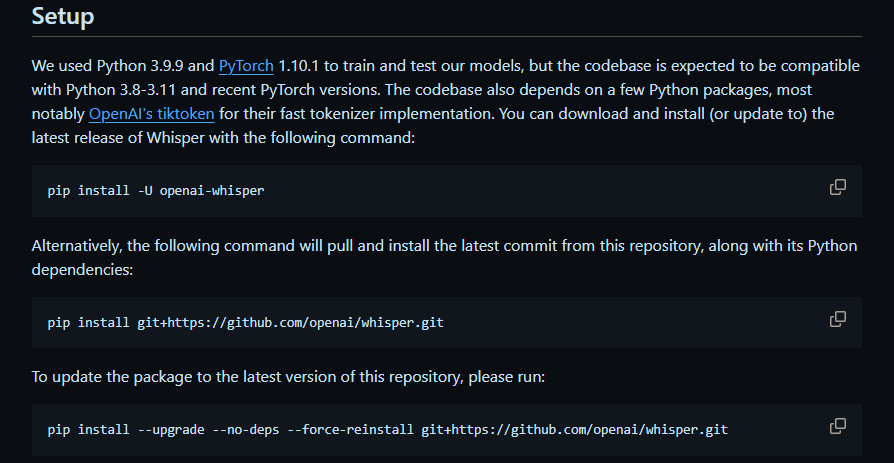
我用的是Anaconda创建的虚拟环境,相关依赖版本如下:
python 3.9.18 h1aa4202_0 defaultspytorch 2.3.1 cpu_py39h0ce1571_0 defaults- 使用最简单的方式
pip install -U openai-whisper- 安装过程输出
WARNING: Ignoring invalid distribution -rotobuf (e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages)Looking in indexes: http://mirrors.aliyun.com/pypi/simple/Collecting openai-whisper Downloading http://mirrors.aliyun.com/pypi/packages/f5/77/952ca71515f81919bd8a6a4a3f89a27b09e73880cebf90957eda8f2f8545/openai-whisper-20240930.tar.gz (800 kB) ---------------------------------------- 800.5/800.5 kB 4.2 MB/s eta 0:00:00 Installing build dependencies ... done Getting requirements to build wheel ... done Preparing metadata (pyproject.toml) ... doneRequirement already satisfied: numba in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from openai-whisper) (0.59.0)Requirement already satisfied: numpy in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from openai-whisper) (1.26.0)Requirement already satisfied: torch in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from openai-whisper) (2.2.1)Requirement already satisfied: tqdm in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from openai-whisper) (4.65.0)Collecting more-itertools (from openai-whisper) Downloading http://mirrors.aliyun.com/pypi/packages/2b/9f/7ba6f94fc1e9ac3d2b853fdff3035fb2fa5afbed898c4a72b8a020610594/more_itertools-10.7.0-py3-none-any.whl (65 kB) ---------------------------------------- 65.3/65.3 kB 3.4 MB/s eta 0:00:00Collecting tiktoken (from openai-whisper) Downloading http://mirrors.aliyun.com/pypi/packages/70/22/e8fc1bf9cdecc439b7ddc28a45b976a8c699a38874c070749d855696368a/tiktoken-0.9.0-cp39-cp39-win_amd64.whl (894 kB) ---------------------------------------- 894.2/894.2 kB 4.0 MB/s eta 0:00:00Requirement already satisfied: llvmlite<0.43,>=0.42.0dev0 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from numba->openai-whisper) (0.42.0)Requirement already satisfied: regex>=2022.1.18 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from tiktoken->openai-whisper) (2023.10.3)Requirement already satisfied: requests>=2.26.0 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from tiktoken->openai-whisper) (2.31.0)Requirement already satisfied: filelock in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from torch->openai-whisper) (3.12.4)Requirement already satisfied: typing-extensions>=4.8.0 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from torch->openai-whisper) (4.8.0)Requirement already satisfied: sympy in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from torch->openai-whisper) (1.12)Requirement already satisfied: networkx in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from torch->openai-whisper) (3.1)Requirement already satisfied: jinja2 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from torch->openai-whisper) (3.1.2)Requirement already satisfied: fsspec in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from torch->openai-whisper) (2023.10.0)Requirement already satisfied: colorama in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from tqdm->openai-whisper) (0.4.6)Requirement already satisfied: charset-normalizer<4,>=2 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from requests>=2.26.0->tiktoken->openai-whisper) (2.0.4)Requirement already satisfied: idna<4,>=2.5 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from requests>=2.26.0->tiktoken->openai-whisper) (3.4)Requirement already satisfied: urllib3<3,>=1.21.1 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from requests>=2.26.0->tiktoken->openai-whisper) (2.0.5)Requirement already satisfied: certifi>=2017.4.17 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from requests>=2.26.0->tiktoken->openai-whisper) (2023.7.22)Requirement already satisfied: MarkupSafe>=2.0 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from jinja2->torch->openai-whisper) (2.1.3)Requirement already satisfied: mpmath>=0.19 in e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages (from sympy->torch->openai-whisper) (1.3.0)Building wheels for collected packages: openai-whisper Building wheel for openai-whisper (pyproject.toml) ... done Created wheel for openai-whisper: filename=openai_whisper-20240930-py3-none-any.whl size=803437 sha256=5a47002d0dfc48e09be5402d7e934e6910cbcb00b5328cb6b55b6f34487f0a04 Stored in directory: c:\\users\\administrator\\appdata\\local\\pip\\cache\\wheels\\92\\5b\\c7\\b99c19e9966d6d455c6301d62efccc73b39366509094f9fe87Successfully built openai-whisperWARNING: Ignoring invalid distribution -rotobuf (e:\\programdata\\anaconda3\\envs\\deepface\\lib\\site-packages)Installing collected packages: more-itertools, tiktoken, openai-whisperSuccessfully installed more-itertools-10.7.0 openai-whisper-20240930 tiktoken-0.9.02.使用
- 帮助信息获取
whisper --help- 使用说明(有点儿长)
usage: whisper [-h] [--model MODEL] [--model_dir MODEL_DIR] [--device DEVICE] [--output_dir OUTPUT_DIR] [--output_format {txt,vtt,srt,tsv,json,all}] [--verbose VERBOSE] [--task {transcribe,translate}] [--language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,yue,zh,Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,Bulgarian,Burmese,Cantonese,Castilian,Catalan,Chinese,Croatian,Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,French,Galician,Georgian,German,Greek,Gujarati,Haitian,Haitian Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,Mandarin,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,Vietnamese,Welsh,Yiddish,Yoruba}] [--temperature TEMPERATURE] [--best_of BEST_OF] [--beam_size BEAM_SIZE] [--patience PATIENCE] [--length_penalty LENGTH_PENALTY] [--suppress_tokens SUPPRESS_TOKENS] [--initial_prompt INITIAL_PROMPT] [--condition_on_previous_text CONDITION_ON_PREVIOUS_TEXT] [--fp16 FP16] [--temperature_increment_on_fallback TEMPERATURE_INCREMENT_ON_FALLBACK] [--compression_ratio_threshold COMPRESSION_RATIO_THRESHOLD] [--logprob_threshold LOGPROB_THRESHOLD] [--no_speech_threshold NO_SPEECH_THRESHOLD] [--word_timestamps WORD_TIMESTAMPS] [--prepend_punctuations PREPEND_PUNCTUATIONS] [--append_punctuations APPEND_PUNCTUATIONS] [--highlight_words HIGHLIGHT_WORDS] [--max_line_width MAX_LINE_WIDTH] [--max_line_count MAX_LINE_COUNT] [--max_words_per_line MAX_WORDS_PER_LINE] [--threads THREADS] [--clip_timestamps CLIP_TIMESTAMPS] [--hallucination_silence_threshold HALLUCINATION_SILENCE_THRESHOLD] audio [audio ...]positional arguments: audio audio file(s) to transcribeoptional arguments: -h, --help show this help message and exit --model MODEL name of the Whisper model to use (default: turbo) --model_dir MODEL_DIR the path to save model files; uses ~/.cache/whisper by default (default: None) --device DEVICE device to use for PyTorch inference (default: cpu) --output_dir OUTPUT_DIR, -o OUTPUT_DIR directory to save the outputs (default: .) --output_format {txt,vtt,srt,tsv,json,all}, -f {txt,vtt,srt,tsv,json,all} format of the output file; if not specified, all available formats will be produced (default: all) --verbose VERBOSE whether to print out the progress and debug messages (default: True) --task {transcribe,translate} whether to perform X->X speech recognition (\'transcribe\') or X->English translation (\'translate\') (default: transcribe) --language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,yue,zh,Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,Bulgarian,Burmese,Cantonese,Castilian,Catalan,Chinese,Croatian,Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,French,Galician,Georgian,German,Greek,Gujarati,Haitian,Haitian Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,Mandarin,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,Vietnamese,Welsh,Yiddish,Yoruba} language spoken in the audio, specify None to perform language detection (default: None) --temperature TEMPERATURE temperature to use for sampling (default: 0) --best_of BEST_OF number of candidates when sampling with non-zero temperature (default: 5) --beam_size BEAM_SIZE number of beams in beam search, only applicable when temperature is zero (default: 5) --patience PATIENCE optional patience value to use in beam decoding, as in https://arxiv.org/abs/2204.05424, the default (1.0) is equivalent to conventional beam search (default: None) --length_penalty LENGTH_PENALTY optional token length penalty coefficient (alpha) as in https://arxiv.org/abs/1609.08144, uses simple length normalization by default (default: None) --suppress_tokens SUPPRESS_TOKENS comma-separated list of token ids to suppress during sampling; \'-1\' will suppress most special characters except common punctuations (default: -1) --initial_prompt INITIAL_PROMPT optional text to provide as a prompt for the first window. (default: None) --condition_on_previous_text CONDITION_ON_PREVIOUS_TEXT if True, provide the previous output of the model as a prompt for the next window; disabling may make the text inconsistent across windows, but the model becomes less prone to getting stuck in a failure loop (default: True) --fp16 FP16 whether to perform inference in fp16; True by default (default: True) --temperature_increment_on_fallback TEMPERATURE_INCREMENT_ON_FALLBACK temperature to increase when falling back when the decoding fails to meet either of the thresholds below (default: 0.2) --compression_ratio_threshold COMPRESSION_RATIO_THRESHOLD if the gzip compression ratio is higher than this value, treat the decoding as failed (default: 2.4) --logprob_threshold LOGPROB_THRESHOLD if the average log probability is lower than this value, treat the decoding as failed (default: -1.0) --no_speech_threshold NO_SPEECH_THRESHOLD if the probability of the <|nospeech|> token is higher than this value AND the decoding has failed due to `logprob_threshold`, consider the segment as silence (default: 0.6) --word_timestamps WORD_TIMESTAMPS (experimental) extract word-level timestamps and refine the results based on them (default: False) --prepend_punctuations PREPEND_PUNCTUATIONS if word_timestamps is True, merge these punctuation symbols with the next word (default: \"\'“¿([{-) --append_punctuations APPEND_PUNCTUATIONS if word_timestamps is True, merge these punctuation symbols with the previous word (default: \"\'.。,,!!??::”)]}、) --highlight_words HIGHLIGHT_WORDS (requires --word_timestamps True) underline each word as it is spoken in srt and vtt (default: False) --max_line_width MAX_LINE_WIDTH (requires --word_timestamps True) the maximum number of characters in a line before breaking the line (default: None) --max_line_count MAX_LINE_COUNT (requires --word_timestamps True) the maximum number of lines in a segment (default: None) --max_words_per_line MAX_WORDS_PER_LINE (requires --word_timestamps True, no effect with --max_line_width) the maximum number of words in a segment (default: None) --threads THREADS number of threads used by torch for CPU inference; supercedes MKL_NUM_THREADS/OMP_NUM_THREADS (default: 0) --clip_timestamps CLIP_TIMESTAMPS comma-separated list start,end,start,end,... timestamps (in seconds) of clips to process, where the last end timestamp defaults to the end of the file (default: 0) --hallucination_silence_threshold HALLUCINATION_SILENCE_THRESHOLD (requires --word_timestamps True) skip silent periods longer than this threshold (in seconds) when a possible hallucination is detected (default: None)3.实例
- 测试文件
- 开始测试
# STT whisper .\\whisper_test.mp3 --language Chinese第一次进行 STT 会下载模型,模型文件存储在 用户目录的.cache\\whisper\\下,文件为 large-v3-turbo.pt。

如果想下载其他模型可以执行如下命令,比如使用 small模型:
whisper audio.flac audio.mp3 audio.wav --model small# 输出信息【此时是在下载模型】 1%|▎ | 15.7M/1.51G [00:09<2:26:01, 183kiB/s]我是用的 Windows 台式机,没有显卡,性能也不行,所以换了一个半分钟的录音,测试结果如下:
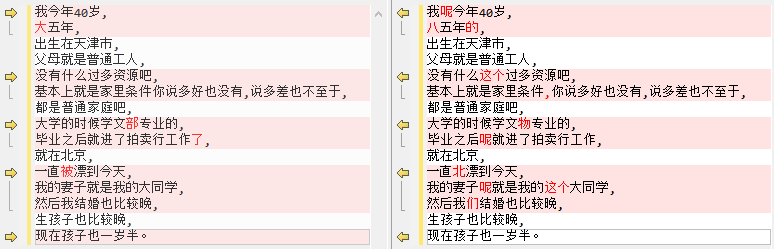
E:\\ProgramData\\anaconda3\\envs\\deepface\\lib\\site-packages\\whisper\\transcribe.py:126: UserWarning: FP16 is not supported on CPU; using FP32 instead warnings.warn(\"FP16 is not supported on CPU; using FP32 instead\")[00:00.000 --> 00:26.140] 我今年40岁,大五年,出生在天津市,父母就是普通工人,没有什么过多资源吧,基本上就是家 里条件你说多好也没有,说多差也不至于,都是普通家庭吧,大学的时候学文部专业的,毕业之后就进了拍卖行工作了,就在 北京,一直被漂到今天,我的妻子就是我的大同学,然后我结婚也比较晚,生孩子也比较晚,现在孩子也一岁半。实际的内容如下:
我呢今年40岁,85年的,出生在天津市,父母就是普通工人,没有什么这个过多资源吧,基本上就是家里条件,你说多好也没有,说多差也不至于,都是普通家庭吧,大学的时候学文物专业的,毕业之后呢就进了拍卖行工作,就在北京,一直北漂到今天,我的妻子呢就是我的这个大同学,然后我们结婚也比较晚,生孩子也比较晚,现在孩子也一岁半。对比结果:
4.总结
简单总结一下,我测试过在只有 CPU 和有 GPU 的服务器上运行的大模型,输出的结果区别很大,这个是在 Windows 台式机上进行的测试,没有 GPU 且性能也不好,实际内容我也是听了好多遍才转录下来的,整体正确率还是挺高的,如果有 GPU 效果应该更好。

