41-dify案例分享-基于database插件实现Text2sql的数据库查询图表工作流_dify database插件
1 前言
Text2SQL(或称NL2SQL)是一种自然语言处理技术,旨在将自然语言(Natural Language)问题转化为关系型数据库中可执行的结构化查询语言(Structured Query Language,SQL),从而实现对数据库的查询和交互。这项技术的核心目标是通过自然语言描述,无需用户具备SQL语法知识,即可完成复杂的数据库查询任务
具体来说,Text2SQL的任务包括以下步骤:
- 输入分析:用户以自然语言形式输入问题,例如“查找平均工资高于整体平均工资的部门名称”。
- 语义解析:系统将输入的自然语言问题解析为数据库中的结构化查询语句。
- SQL生成:根据解析结果生成对应的SQL语句,如“SELECT department_name FROM departments WHERE average_salary > (SELECT AVG(salary) FROM employees)”。
- 执行与反馈:系统执行SQL查询并返回结果,同时可能对结果进行进一步的解释或分析。
Text2SQL的应用领域广泛,包括智能客服、数据分析、金融、医疗、教育等,能够显著提高用户与数据库交互的效率和便利性。此外,随着大型语言模型(LLMs)的发展,Text2SQL技术在处理复杂查询和多轮对话方面也取得了显著进展。
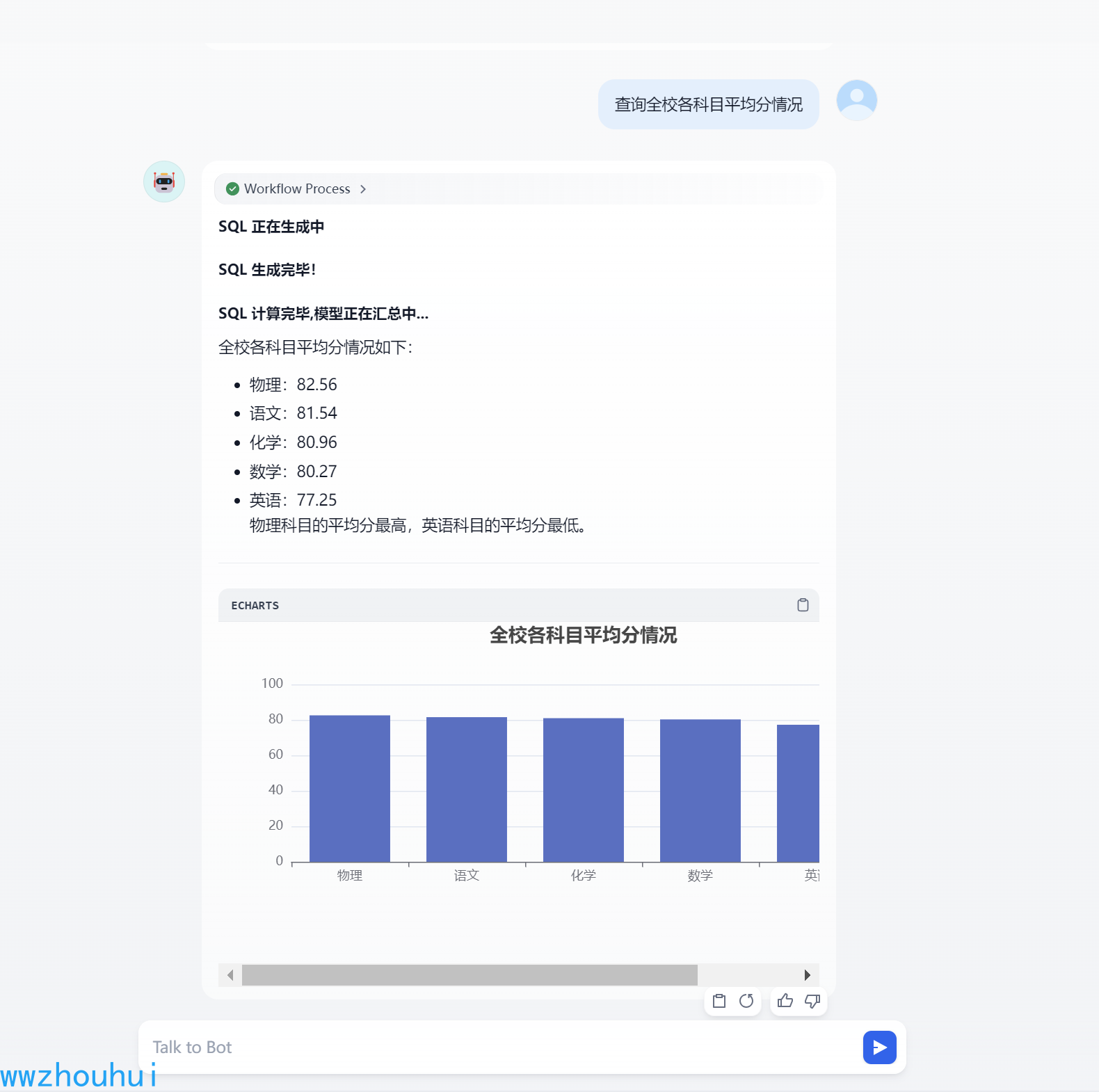
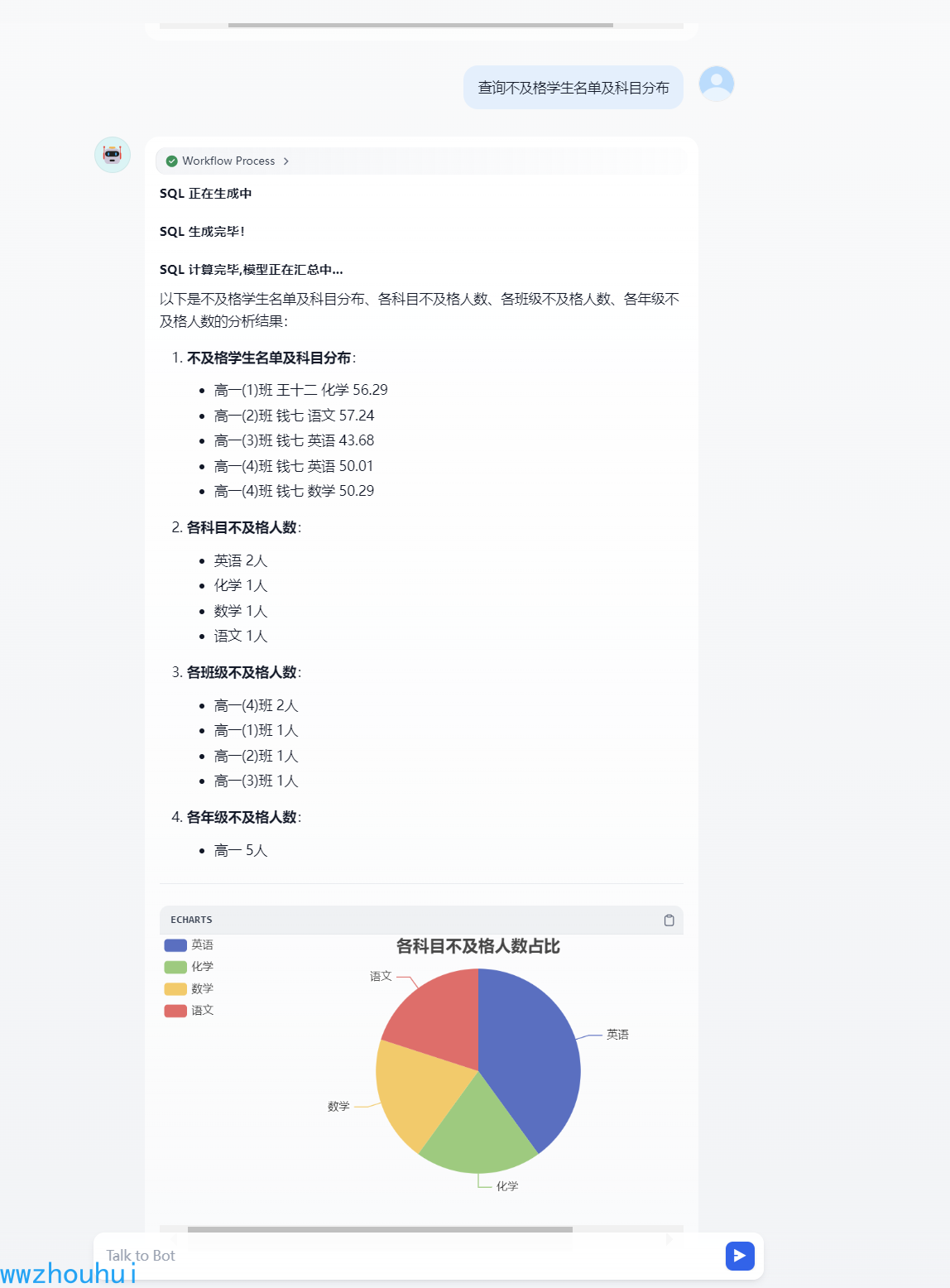
前期也给大家介绍过关于dify整合数据库实现图表生成的案例,dify 1.0 之后插件市场上出现类多类似数据库工具插件,今天就带大家实现基于Text2SQL dify工作流。话不多说我们看一下生产的效果:
工作流也给大家截图看一下
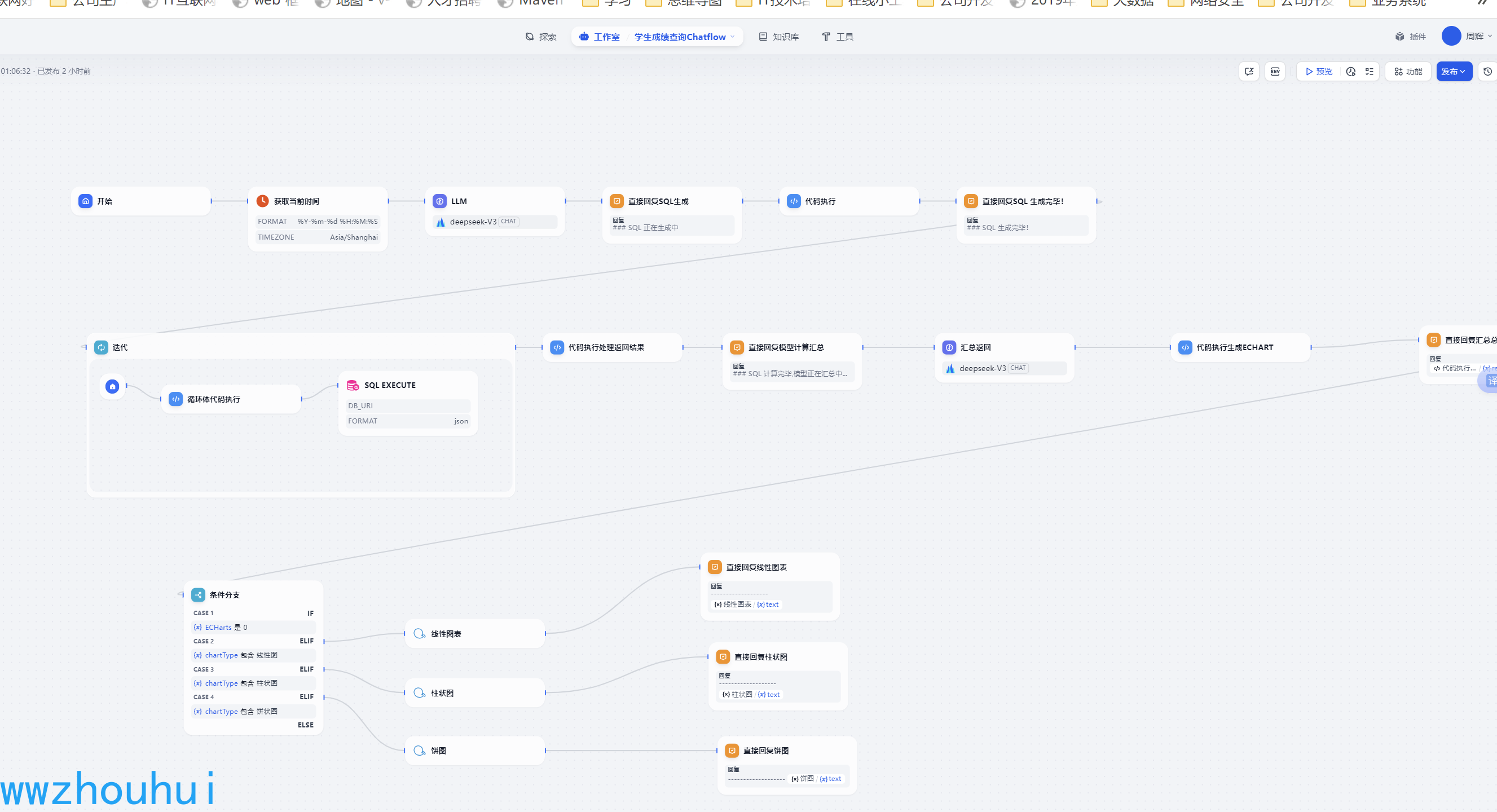
2.工作流的制作
本次工作流涉及到的流程节点比较多。这里每个节点我就一一介绍了。之前也给大家介绍过很多工作流的制作,本次重点是介绍一下工作流中的重点工具的使用以及实现思路。
本次工作流是基于dify1.0+版本制作,有基于0.15 版本的小伙伴建议大家升级,不然不能使用。先检查一下自己dify的版本
本次工作流用到了几个工具。 时间工具、ECharts图表生成、database
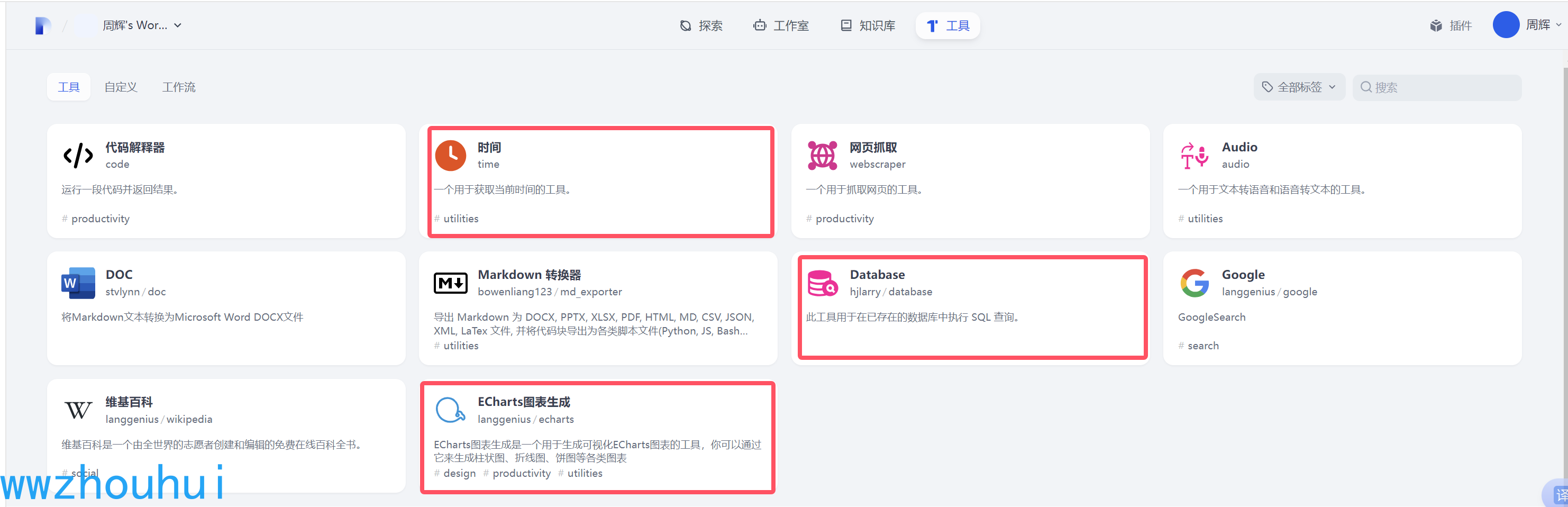
关于上述3个组件安装,这里就不做详细展开。有小伙伴需要纯内网使用的安装不了上述组件 可以参考我之前的文章Dify 实战:纯内网1.0+版本,攻克模型工具插件离线安装难题
开始
考虑到多轮对话我们这里使用chatflow 工作流。 点击预览按钮,右下角功能开启中 我们增加对话开场白
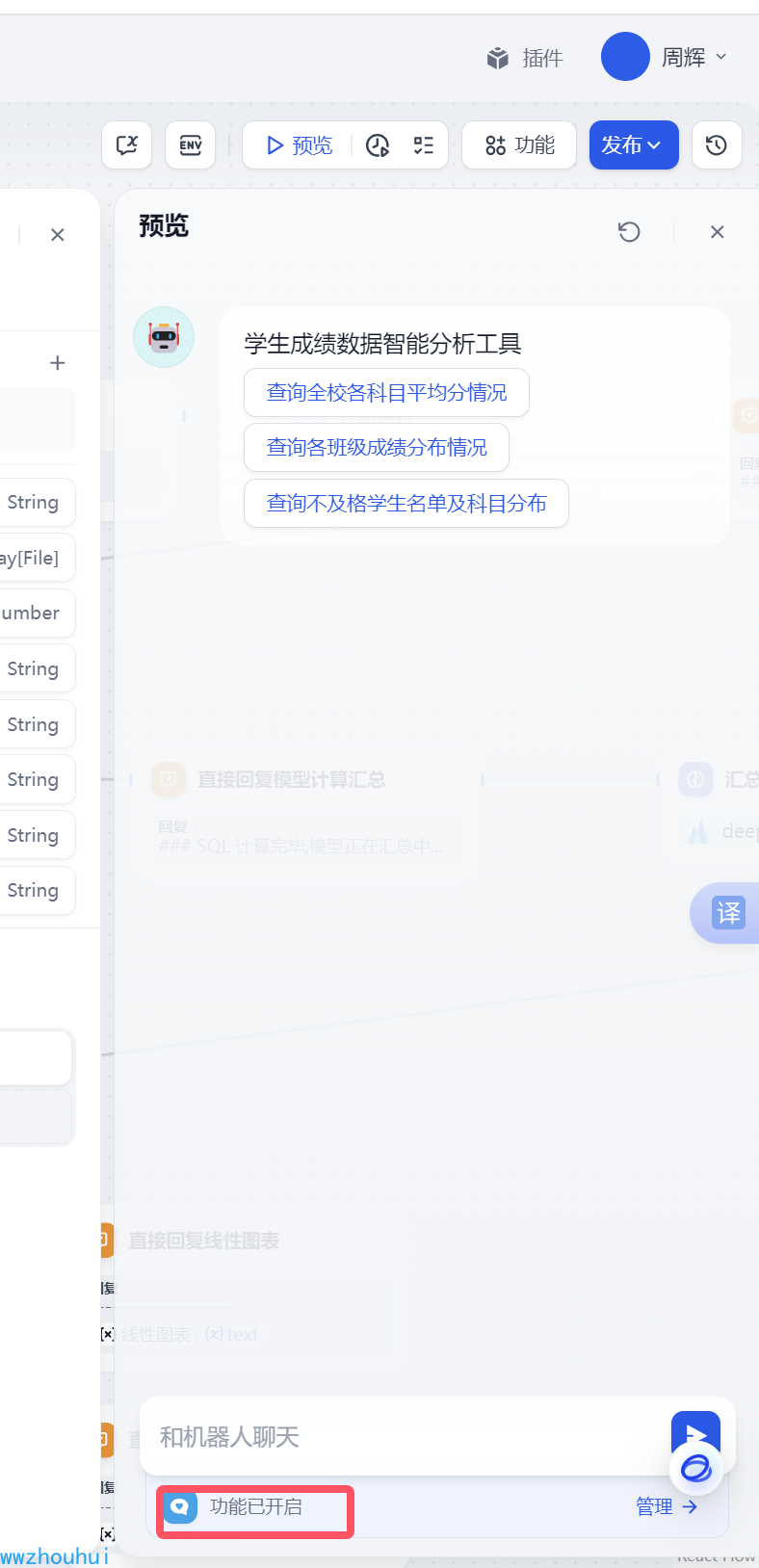
为了方便用户的使用我们做了2个引导对话的开场白,这里我们配置三个问题。
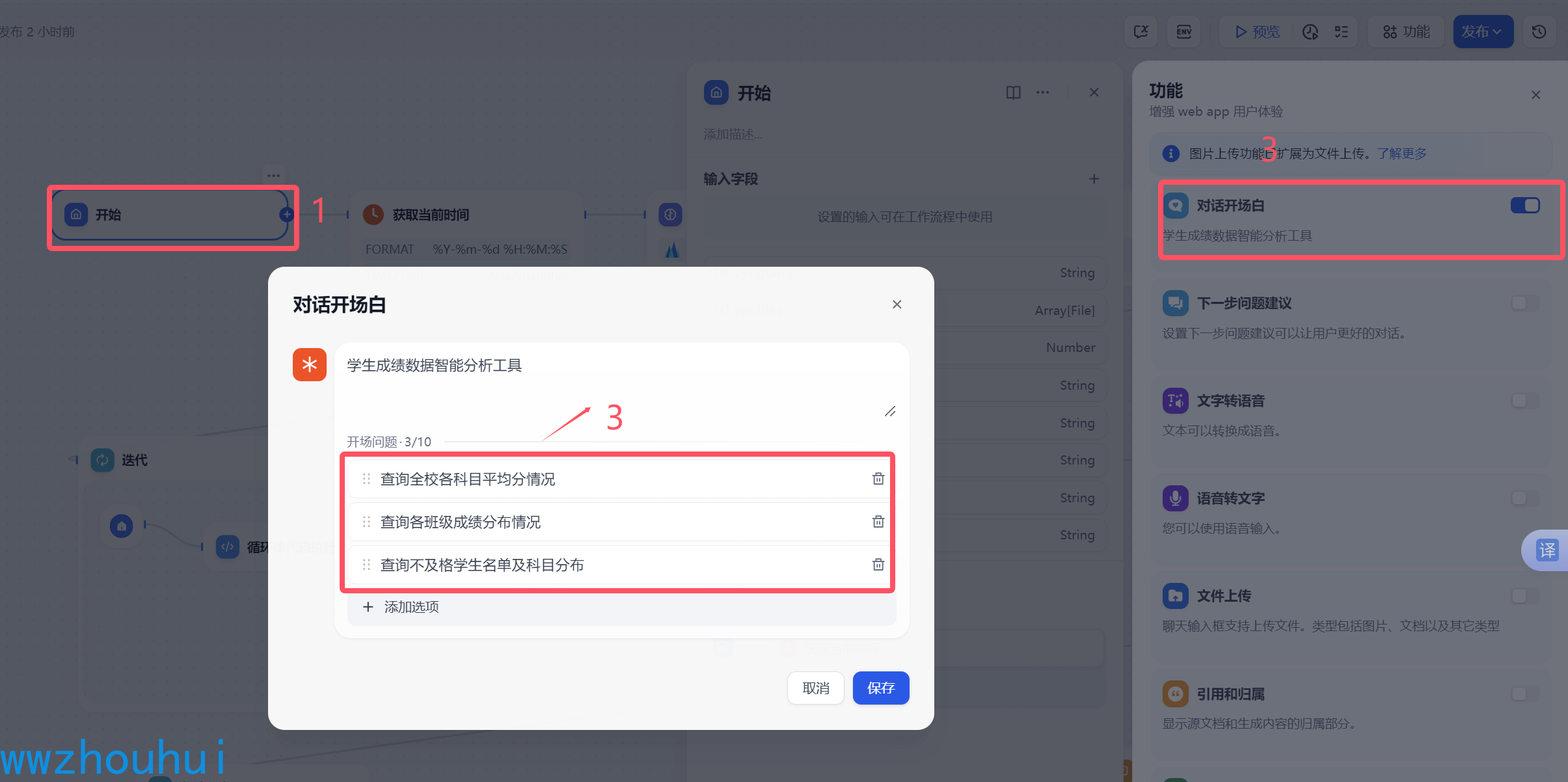
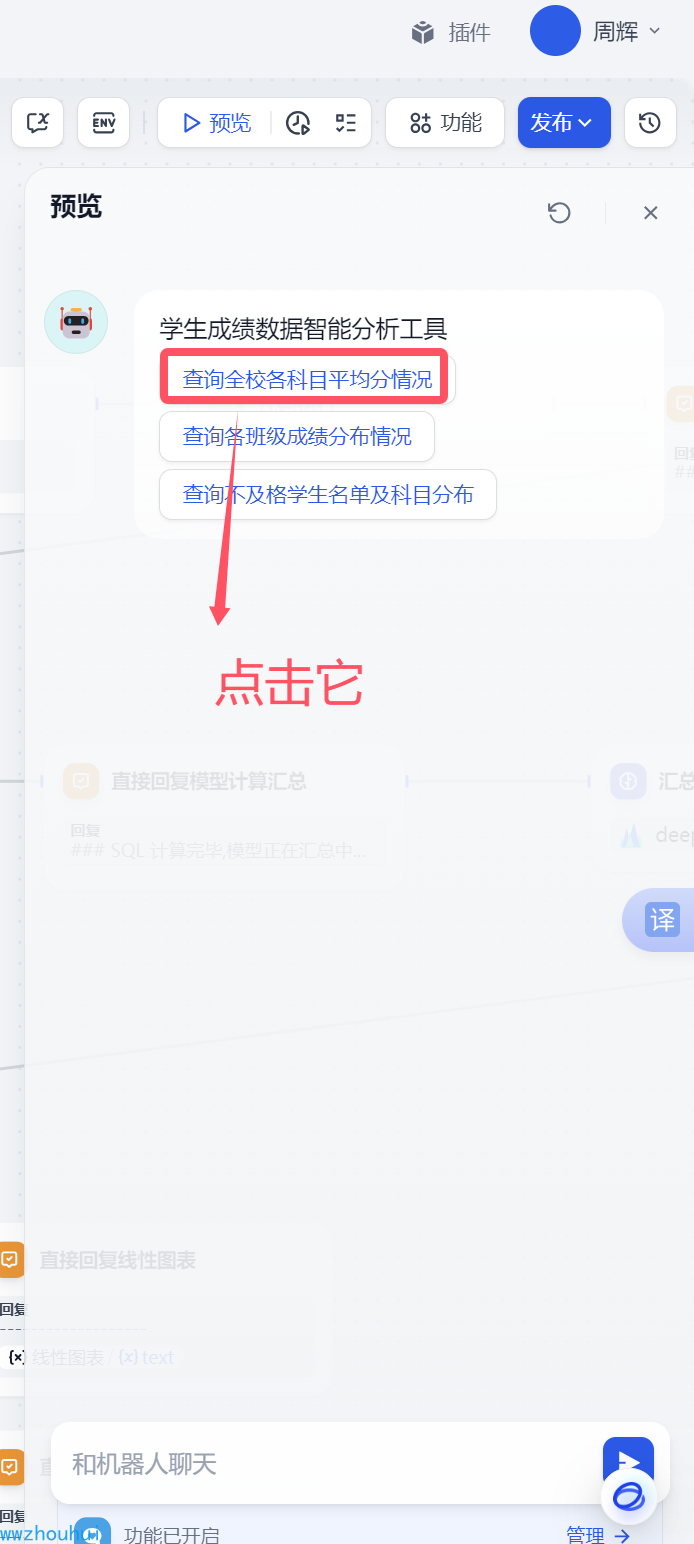
这样我们打开预览页面就会出现3个开场白对话,用户就不需要输入点击开场白 就直接对话了。
获取当前系统时间
这个地方主要是方便后面查询使用。
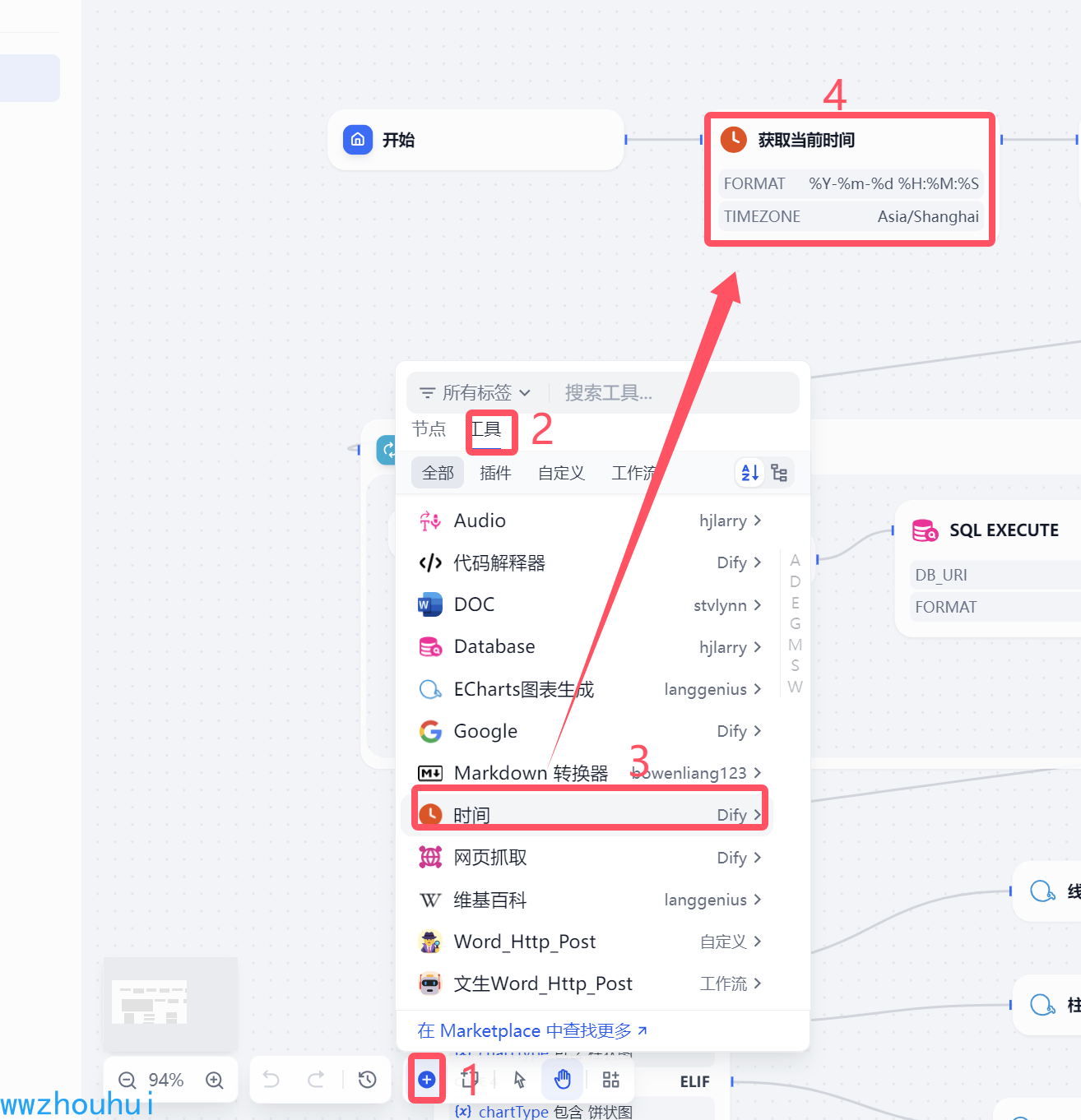
这里我们设置一下时区我们选择中国上海。
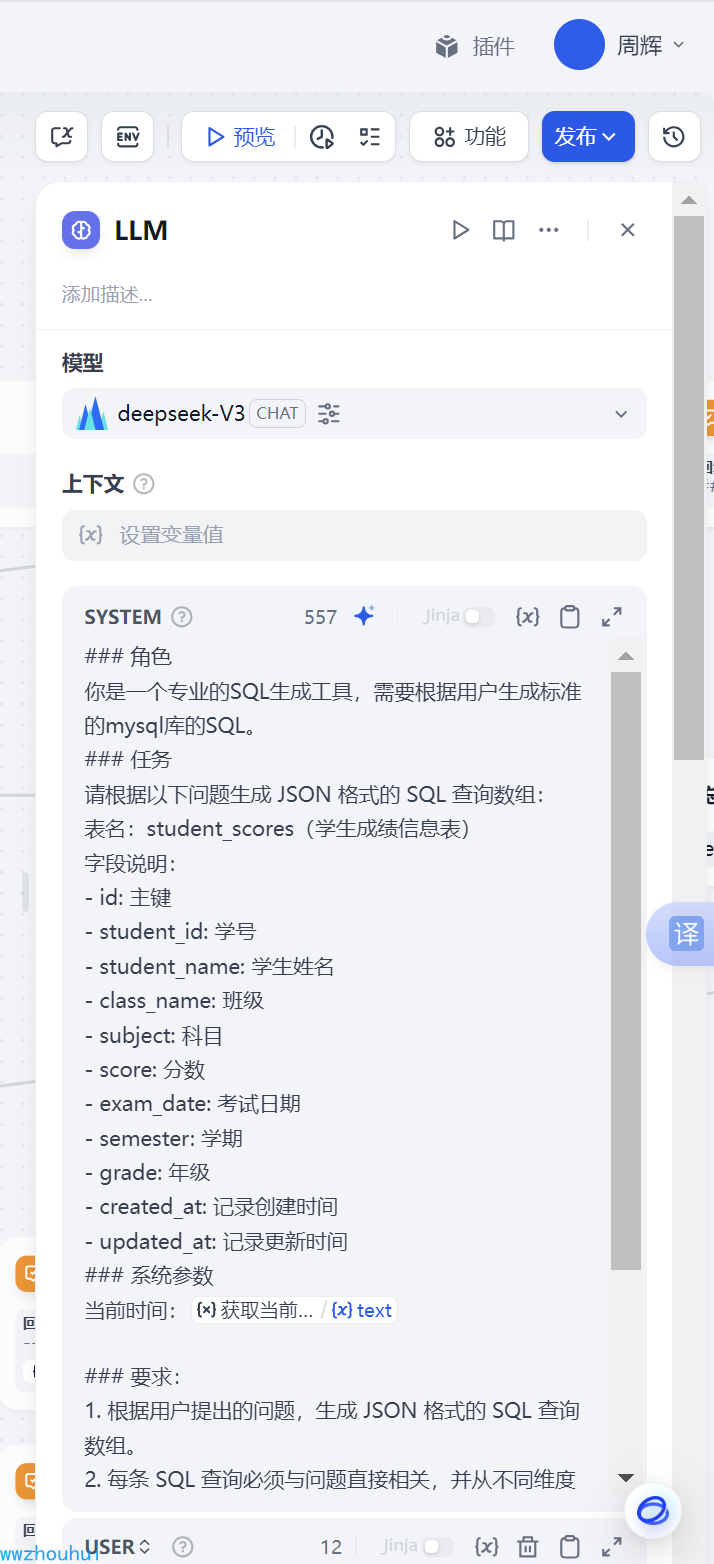
LLM
这个地方我们定义了一个LLM大语言,模型这里我们选择了火山引擎deepseek V3模型
系统提示词
### 角色你是一个专业的SQL生成工具,需要根据用户生成标准的mysql库的SQL。 ### 任务请根据以下问题生成 JSON 格式的 SQL 查询数组:表名:student_scores(学生成绩信息表)字段说明:- id: 主键- student_id: 学号- student_name: 学生姓名 - class_name: 班级- subject: 科目- score: 分数- exam_date: 考试日期- semester: 学期- grade: 年级- created_at: 记录创建时间- updated_at: 记录更新时间### 系统参数当前时间:{{#1742350083195.text#}}### 要求:1. 根据用户提出的问题,生成 JSON 格式的 SQL 查询数组。2. 每条 SQL 查询必须与问题直接相关,并从不同维度分析数据。3. 生成的SQL最多10个。4. 将所有生成的 SQL 查询封装到一个 JSON 数组中。5. 确保 SQL 查询语法正确,并考虑性能优化。6. 输出必须以 ```json 开始。7. 如果问题涉及多个统计维度,请分别生成对应的子查询。8. 涉及全量的应查询SQL以学期聚合。用户提示词 (主要给一下大模型一个用户提示词样例)
查询全校各科目平均分情况assistant 提示词 我们定义了一个上面开场白对应的SQL 语句
```json [ { \"title\": \"统计全校各科目平均分\", \"sql\": \"SELECT subject, ROUND(AVG(score), 2) AS avg_score FROM student_scores GROUP BY subject ORDER BY avg_score DESC;\" }, { \"title\": \"统计各科目及格率\", \"sql\": \"SELECT subject, ROUND(COUNT(CASE WHEN score >= 60 THEN 1 END) * 100.0 / COUNT(*), 2) as pass_rate FROM student_scores GROUP BY subject ORDER BY pass_rate DESC;\" }, { \"title\": \"统计各科目成绩分布\", \"sql\": \"SELECT subject, COUNT(CASE WHEN score >= 90 THEN 1 END) as excellent, COUNT(CASE WHEN score >= 75 AND score = 60 AND score < 75 THEN 1 END) as pass, COUNT(CASE WHEN score < 60 THEN 1 END) as fail FROM student_scores GROUP BY subject;\" }]```整个llm配置截图如下

有的小伙伴可能会问,这个SQL 我不会,怎么办。 可以把创建SQL 语句发给trae,让它帮我生成。
关于SQL 语句的创建 后面也会给大家用trae 来创建和生成。
SQL Execute
因为考虑到用实现text2SQL 所以我们免不了使用到 这个SQL Execute 工具。
我们可以在https://marketplace.dify.ai/plugins/hjlarry/database?language=zh-Hans 市场上找到这个项目
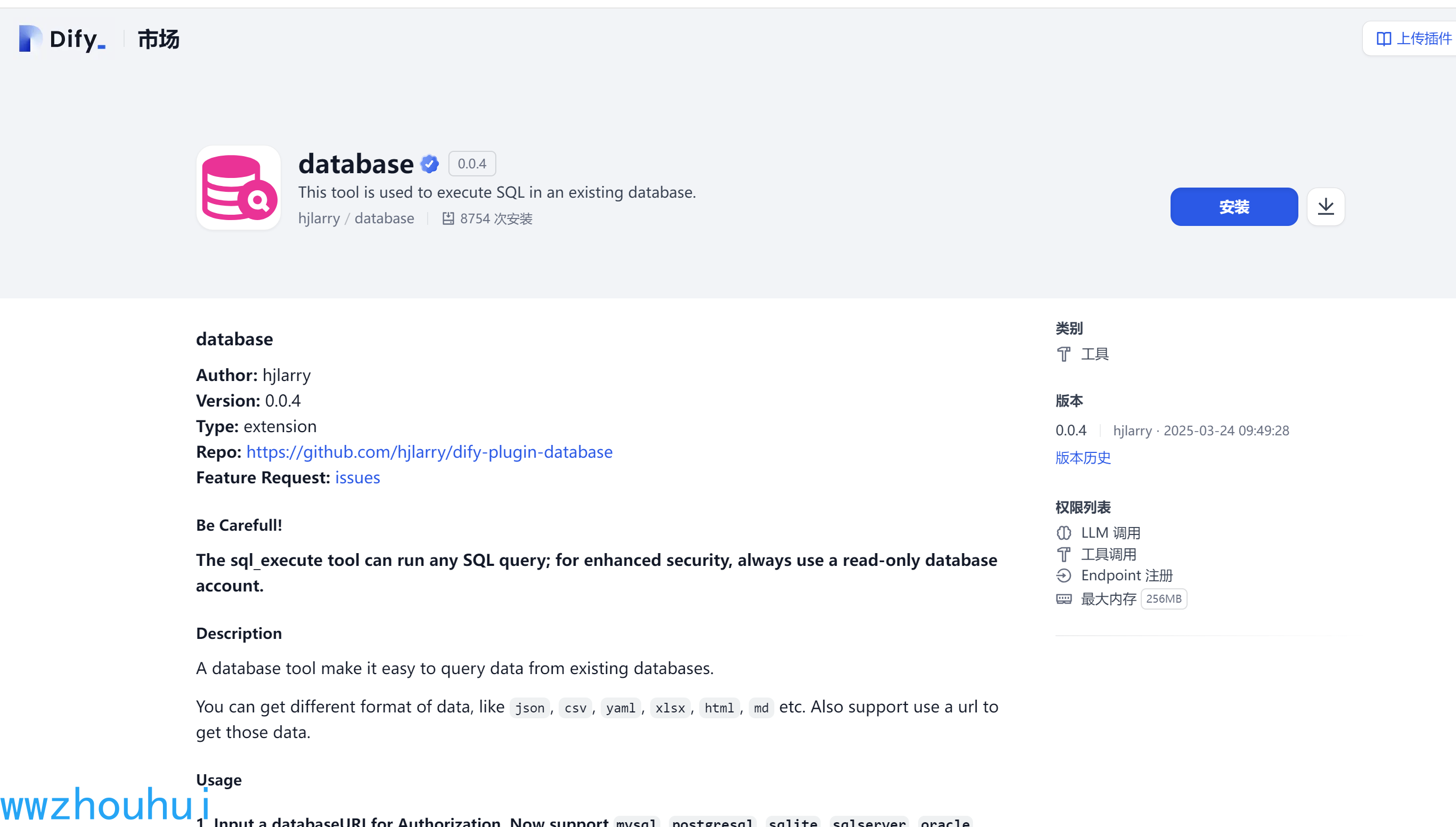
目前这个项目支持的数据库有mysql, postgresql, sqlite, sqlserver, oracle
mysql+pymysql://root:123456@localhost:3306/testpostgresql+psycopg2://postgres:123456@localhost:5432/testsqlite:///test.dbmssql+pymssql://:@/?charset=utf8oracle+oracledb://user:pass@hostname:port[/dbname][?service_name=[&key=value&key=value...]]我们在插件市场把它安装好后,就需要对它配置。
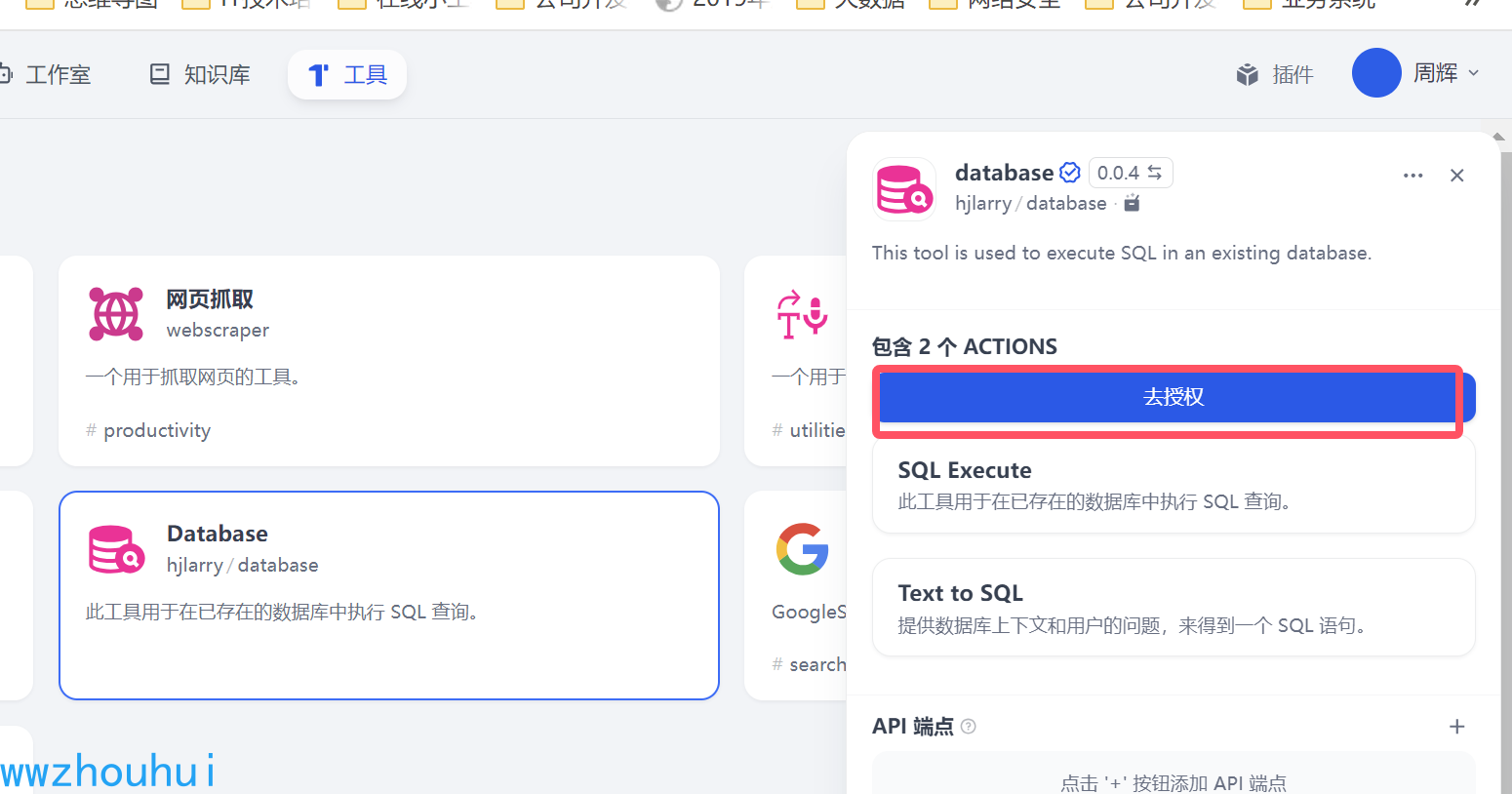
我们用的是mysql参考上述链接字符串
mysql+pymysql://root:123456@localhost:3306/test这里还有一个小技巧,就是如果数据库密码是带有@符号的,我们需要转义一下。否自会出现错误。
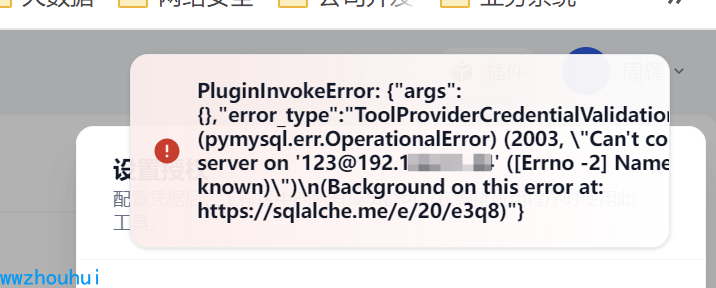
上述因为密码也带有特殊符号“@” 和后面的数据链接符号@产生了歧义 这样程序连接就会报错
如何解决
若要借助转义的方式来处理包含特殊字符 @ 的连接字符串,在标准的数据库连接字符串里,一般没有通用转义符号能直接用在字符串里。不过可以对特殊字符 @ 进行 URL 编码,@ 对应的 URL 编码是 %40。
最后的变成
mysql+pymysql://root:zzz%40123@192.168.11.84:19030/test_db这样修改后在连接就OK 了
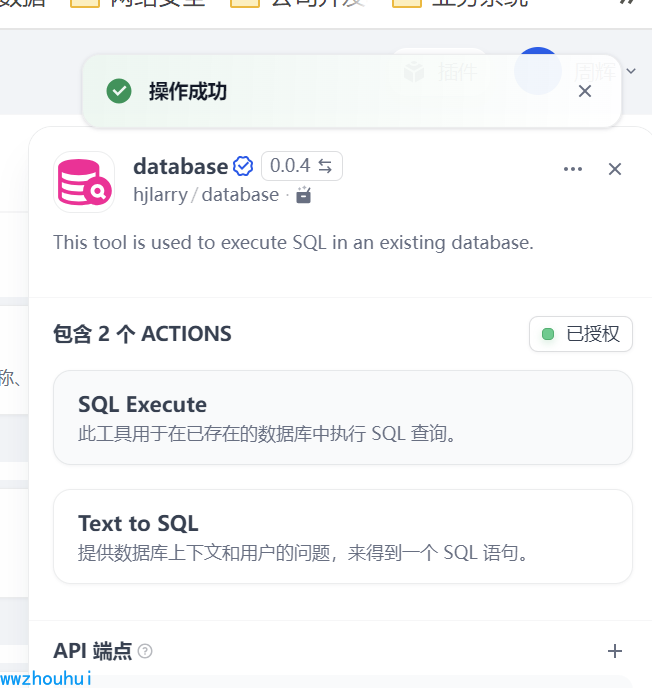
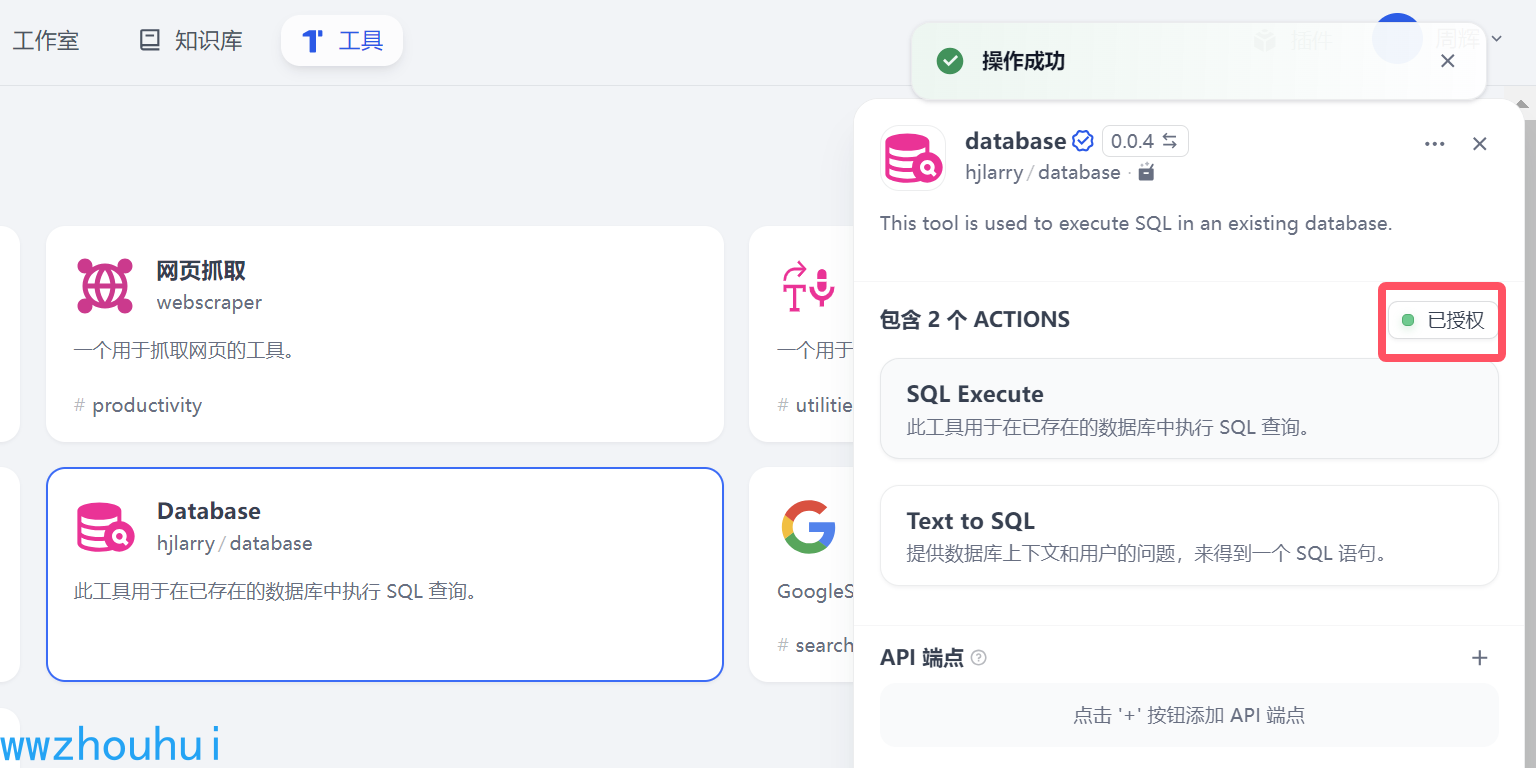
看到已授权完成配置。
回到工作流我们设置一下 需要查询的SQL 语句(前面步骤我们简化)
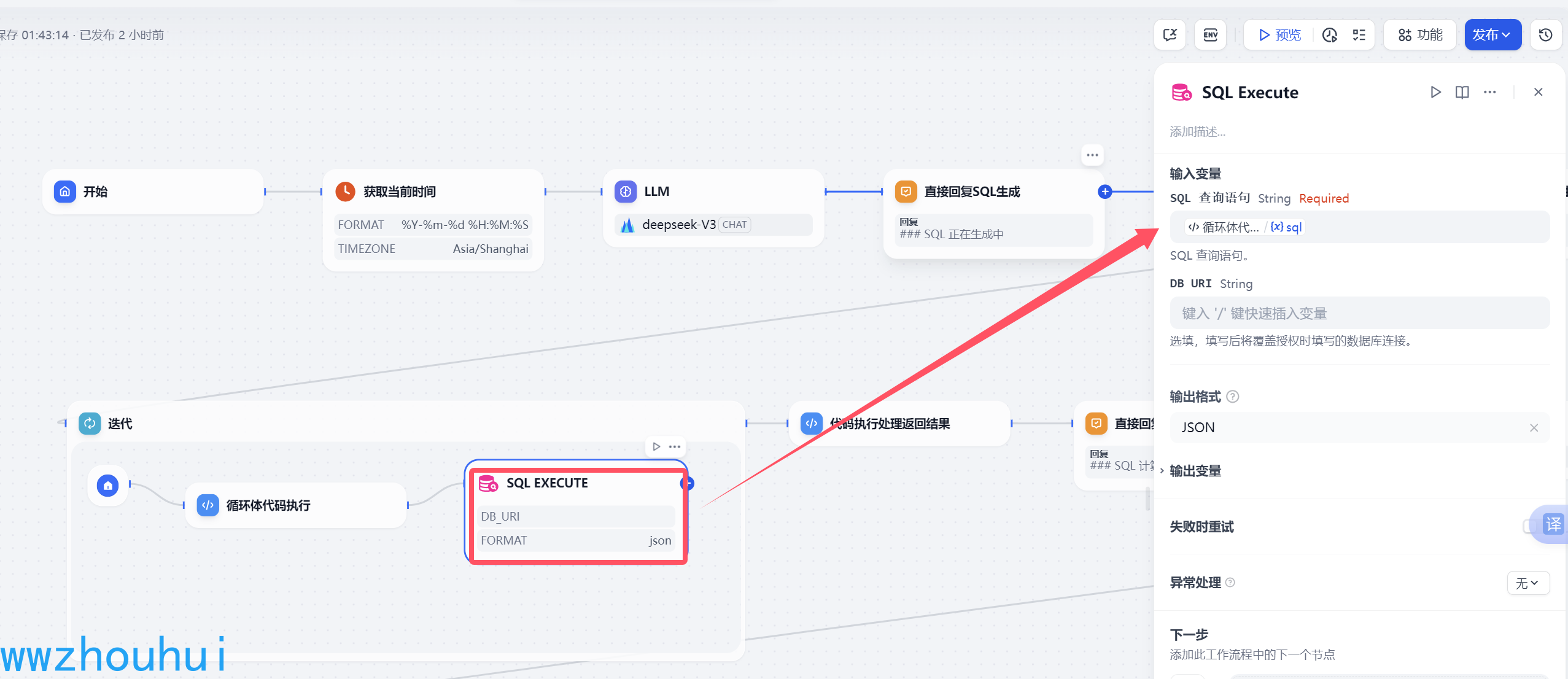
LLM汇总返回
这个地方也用到了LLM大语言模型,我们这里同样使用火山引擎提供的deepseek V3模型。
上下文中我们填写代码处理返回结果
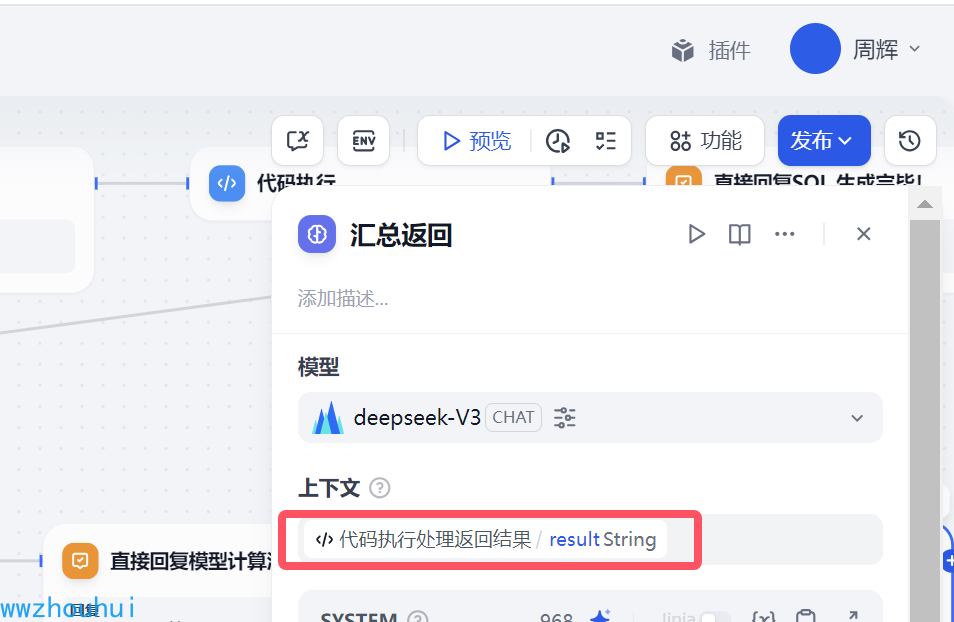
系统提示词
### 角色你是一个数据分析师,需要根据上个模型生成的 SQL 及其查询结果,优先回答用户问题,回答内容不要发散,并且将关联问题的结果进行分析并以 JSON 格式返回给用户。### 参数- **SQL 模型生成**:{{#1742362677100.text#}}- **SQL 查询结果**:{{#context#}}### 图片使用场景- 线性图 :适用于展示趋势变化的数据,例如时间序列数据(如每月、每年的变化)。- 柱状图 :适用于比较不同类别之间的数量或占比,例如各市的占比情况。- 饼状图 :适用于展示整体的组成部分及其比例,通常用于单维度的比例分布。### 要求:1. 优先回答用户问题,回答内容不要发散。2. 根据用户问题正确使用线性图/柱状图/饼状图。3. 将返回内容放入到 JSON 中,格式如下:```json{ \"results\": \"用md格式先回复用户问题,其它维度数据简单概括,但是数据一定要展示出来\", \"ECHarts\": \"1\", // 如果需要生成图表,则为 \"1\";否则为 \"0\" \"chartType\": \"线性图/柱状图/饼状图\", // 图表类型(仅当 ECHarts 为 true 时提供) \"chartTitle\": \"图表标题\", // 图表标题(仅当 ECHarts 为 true 时提供) \"chartData\": \"图表的数据,多个用;隔开\", // 图表数据(仅当 ECHarts 为 true 时提供) \"chartXAxis\": \"图表的X轴,多个用;隔开\" // 图表的X轴数据(仅当 ECHarts 为 true 时提供)}```#### 注意事项:- 如果查询结果适合生成图表,则 ECHarts 设置为 \"1\",并补充 chartType、chartTitle、chartData 和 chartXAxis 字段。- 如果查询结果不适合生成图表,则 ECHarts 设置为 \"0\",并省略 chartType、chartTitle、chartData 和 chartXAxis 字段。- 咨询占比必须使用饼状图进行展示,饼状图chartData中应返回百分比。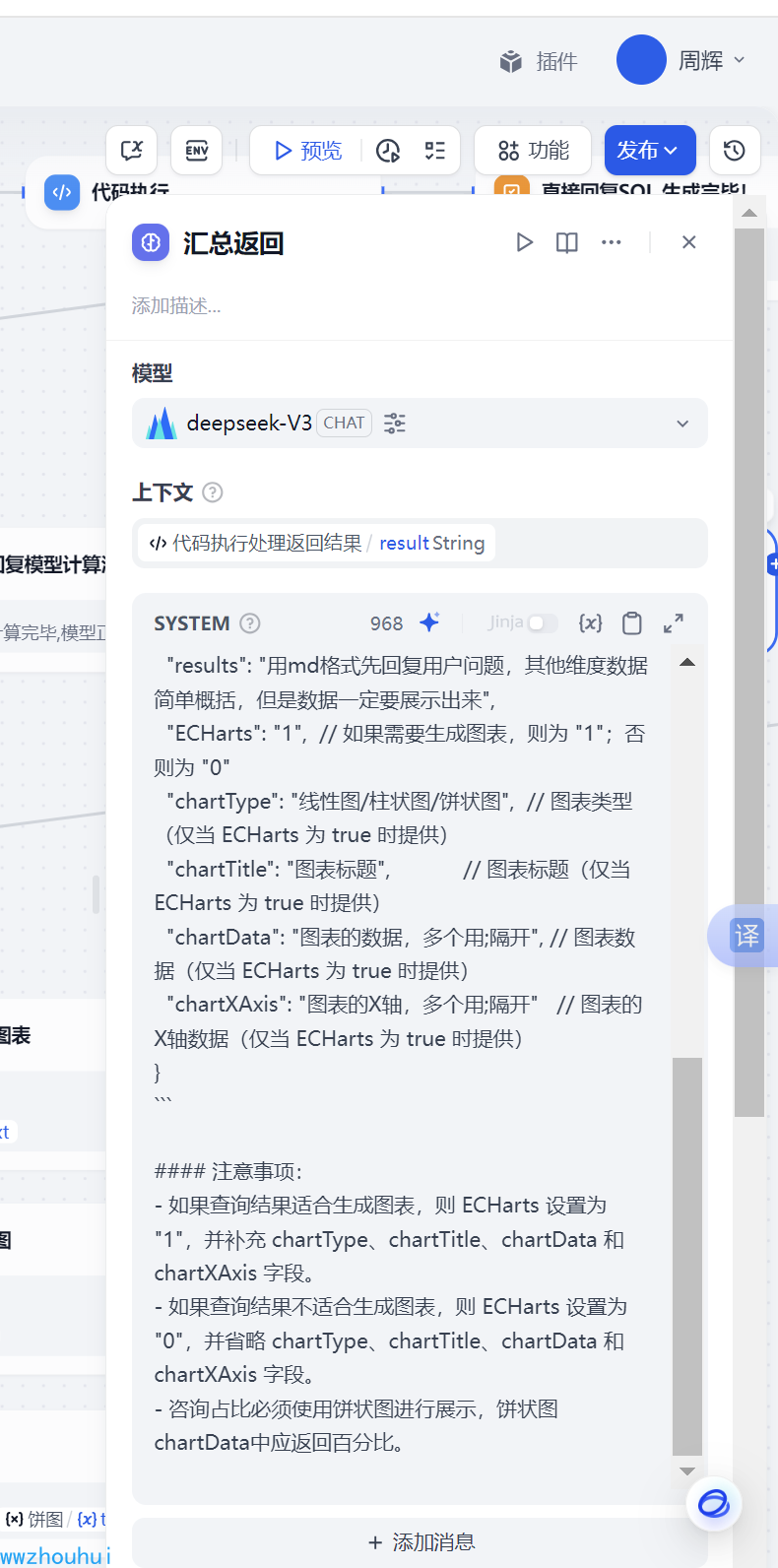
这个步骤主要是对查询结果进行汇总分析,另外把查询的结果ECHarts 图表组装需要的需要的JSON格式数据。
代码执行生成echart
上面llm大语言模型处理的结果我们这里用代码执行生成echart,代码如下
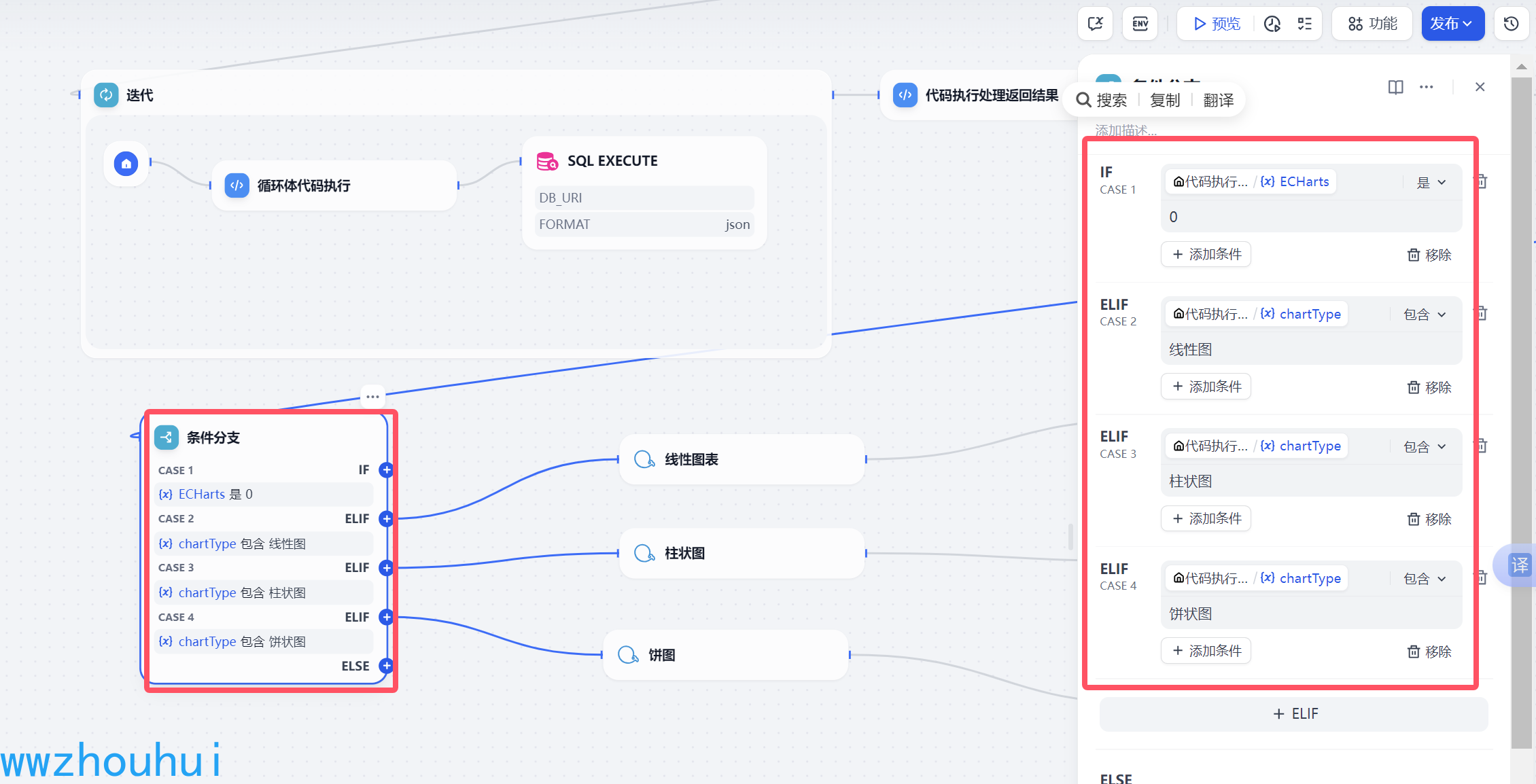
import reimport jsondef main(arg1: str) -> dict: # 默认返回值 default_output = { \"results\": \"\", \"ECHarts\": \"0\", \"chartType\": \"\", \"chartTitle\": \"\", \"chartData\": \"\", \"chartXAxis\": \"\" } try: # 使用正则表达式提取被 ```json 和 ```包裹的内容 match = re.search(r\'```json\\s*([\\s\\S]*?)\\s*```\', arg1) if not match: raise ValueError(\"输入字符串中未找到有效的 JSON 数据\") # 提取 JSON 字符串 json_str = match.group(1).strip() # 将 JSON 字符串解析为 Python 字典 result_dict = json.loads(json_str) except Exception as e: # 如果解析失败,打印错误信息并返回默认输出 print(f\"解析失败: {e}\") return default_output # 检查是否包含 ECHarts 字段 if \"ECHarts\" not in result_dict: result_dict[\"ECHarts\"] = \"0\" # 默认设置为 \"0\" # 根据 ECHarts 的值动态检查图表相关字段 if result_dict[\"ECHarts\"] == \"1\": required_chart_fields = [\"chartType\", \"chartTitle\", \"chartData\", \"chartXAxis\"] for field in required_chart_fields: if field not in result_dict: result_dict[field] = \"\" # 自动补全缺失字段为空字符串 # 构造返回值 return { \"results\": str(result_dict.get(\"results\", \"\")), \"ECHarts\": str(result_dict.get(\"ECHarts\", \"0\")), \"chartType\": str(result_dict.get(\"chartType\", \"\")), \"chartTitle\": str(result_dict.get(\"chartTitle\", \"\")), \"chartData\": str(result_dict.get(\"chartData\", \"\")), \"chartXAxis\": str(result_dict.get(\"chartXAxis\", \"\")) }条件分支
这个条件分支是考虑用户输入的信息 返回结果有线性图表、柱状图、饼图的输出,所以我们需要通过这个条件分支进行判断
ECharts图表
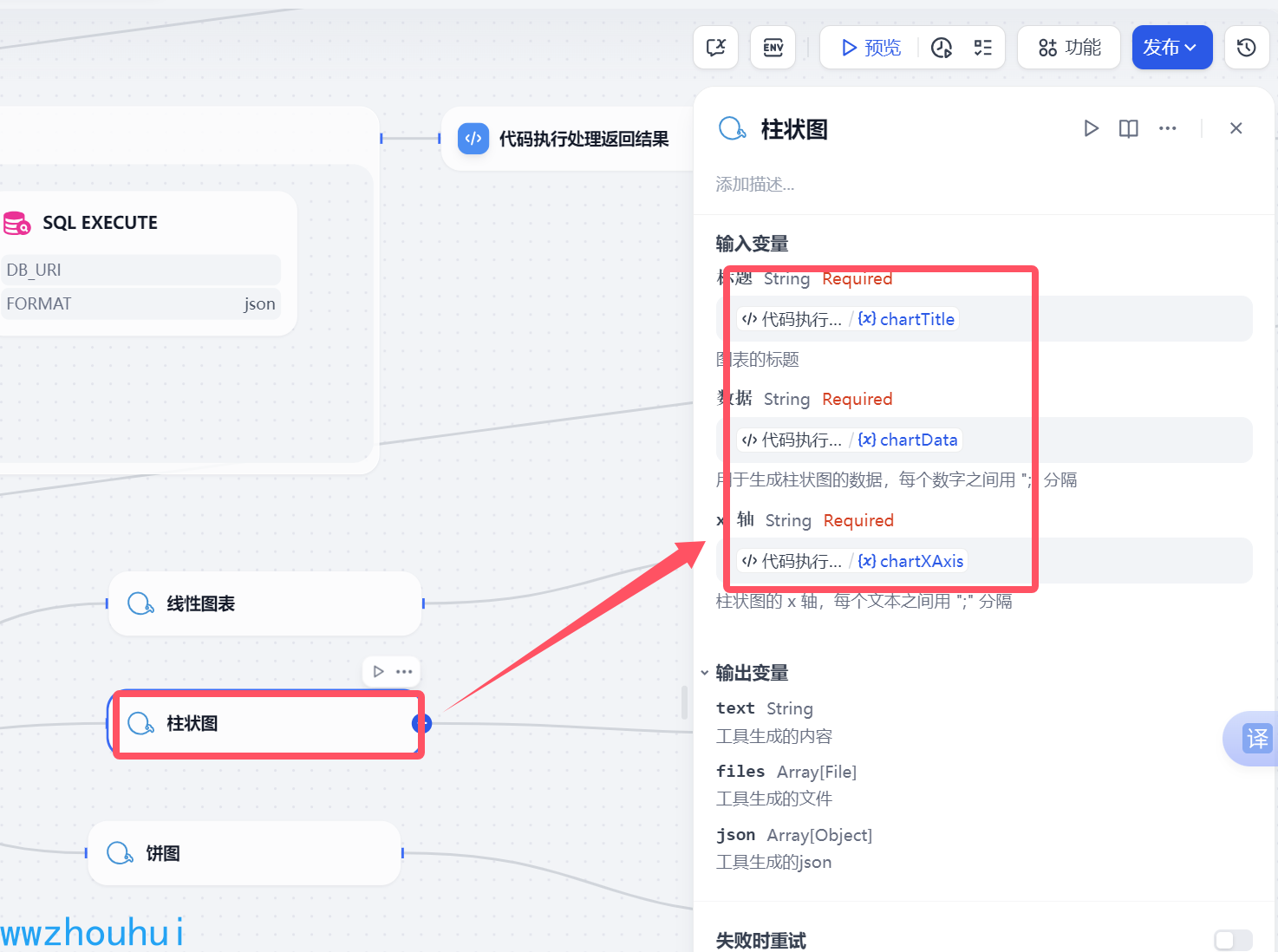
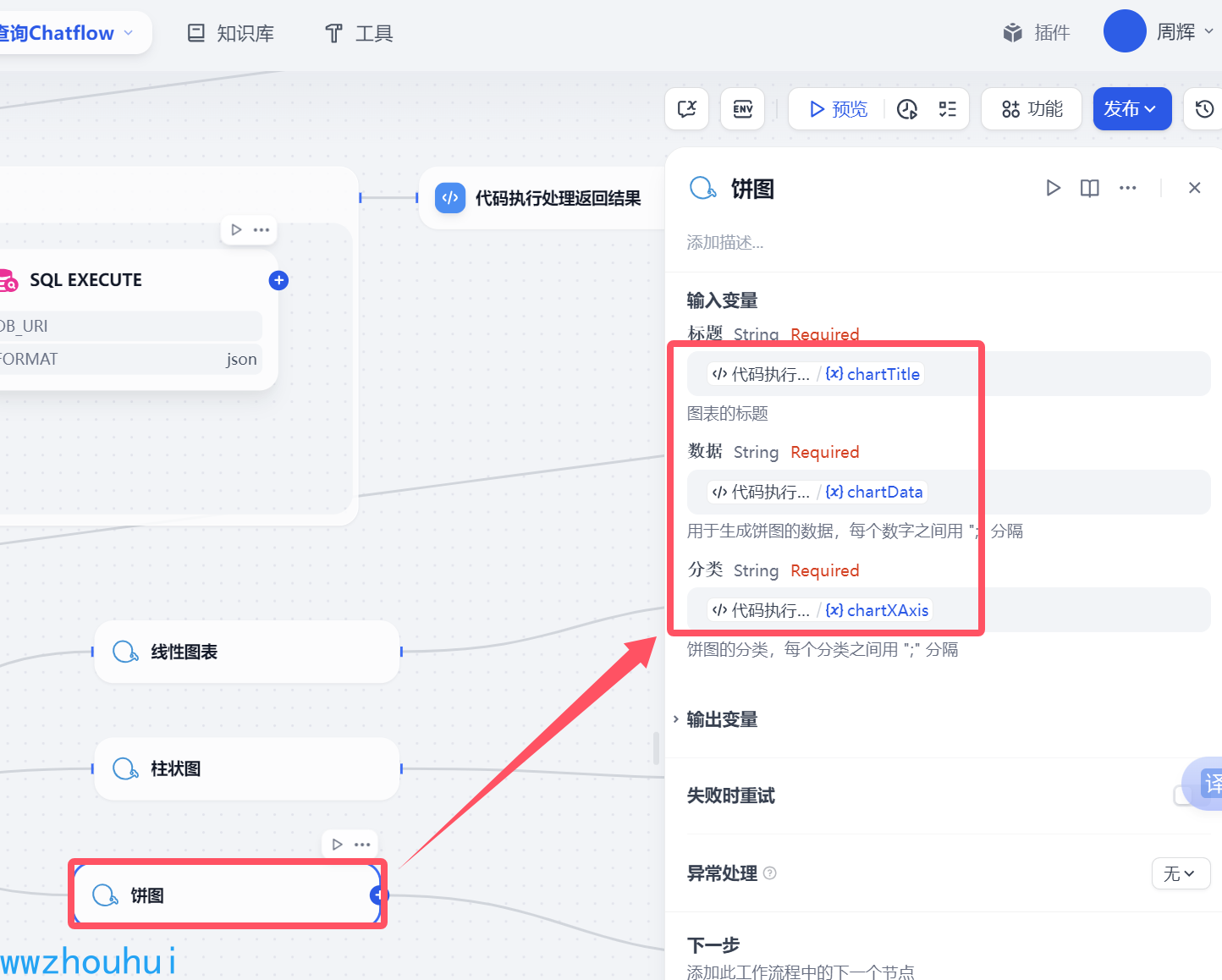
这个地方就是主要是使用ECharts图表对线性图表、柱状图、饼图的输出,这里输入的参数有3个分别是:
1.标题
2.数据
3.x 轴
其中 线性图表、柱状图一样的,饼图有点区别 它不是x 轴 而是换成分类,数据格式都是一样的。
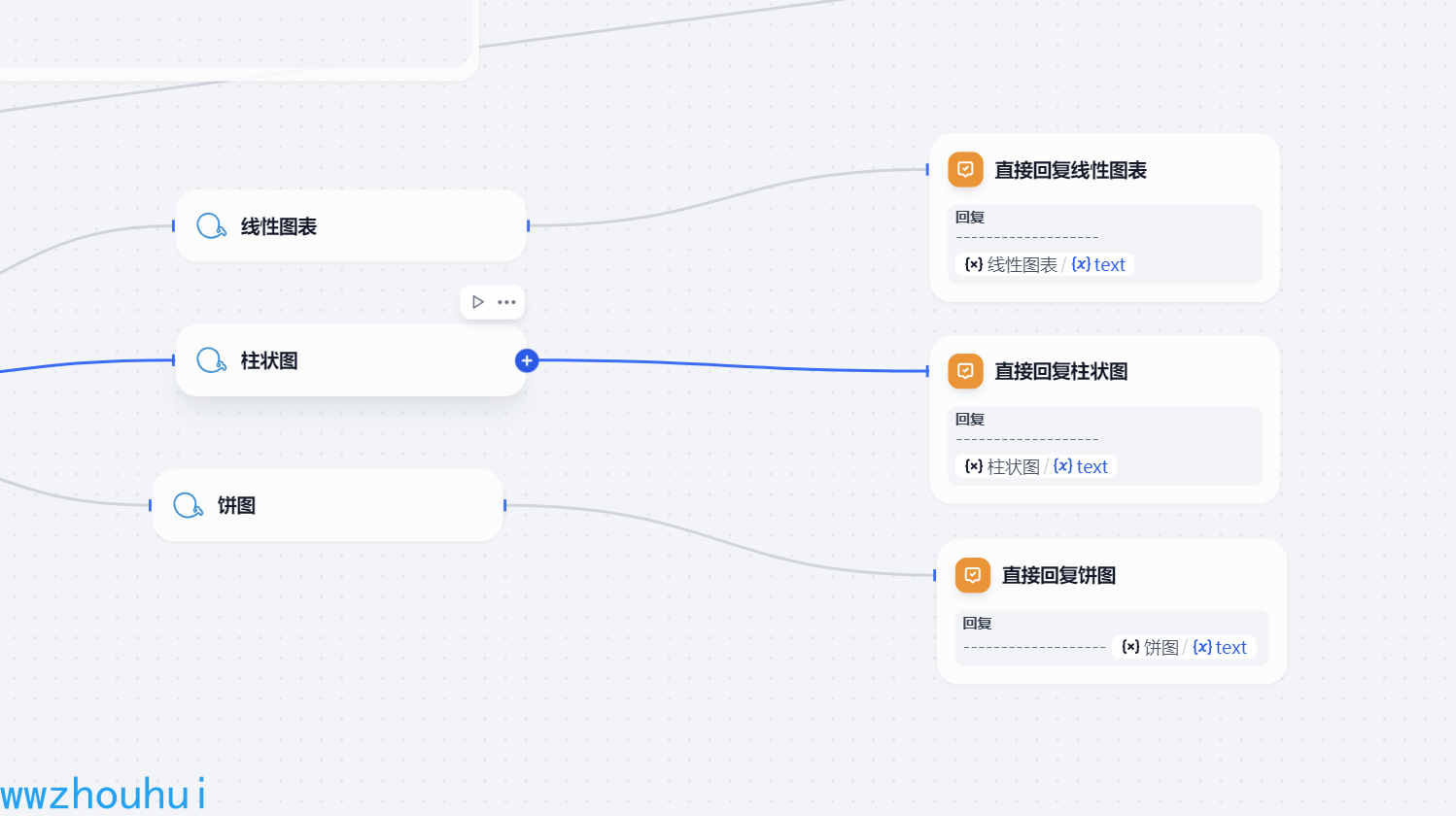
直接输出
这个就是把结果返回。分别对应线性图表、柱状图、饼图。
以上步骤我们就完成了工作流的制作。
3.验证及测试
我们点开工作流的预览按钮,点击系统给出的3个开场白。
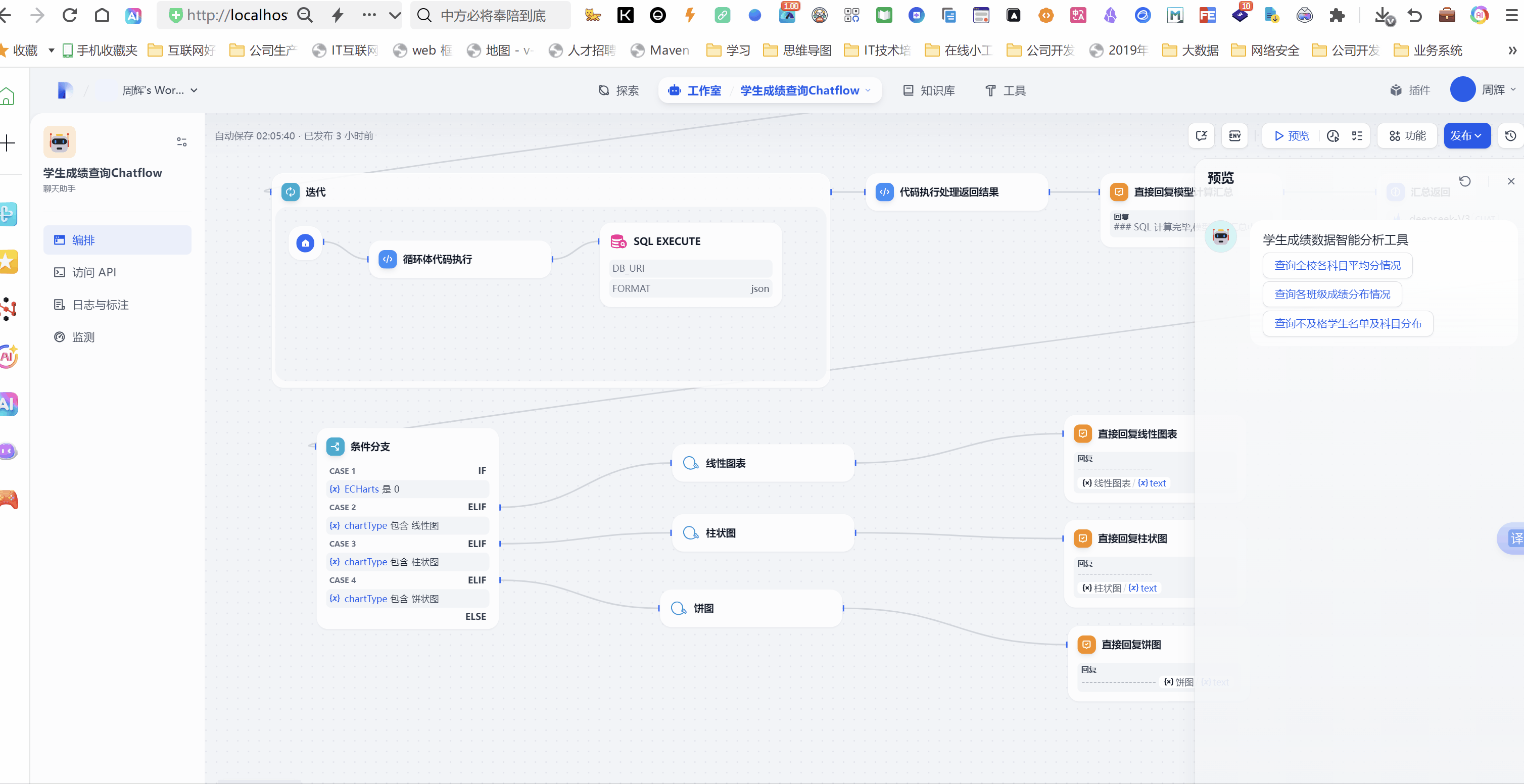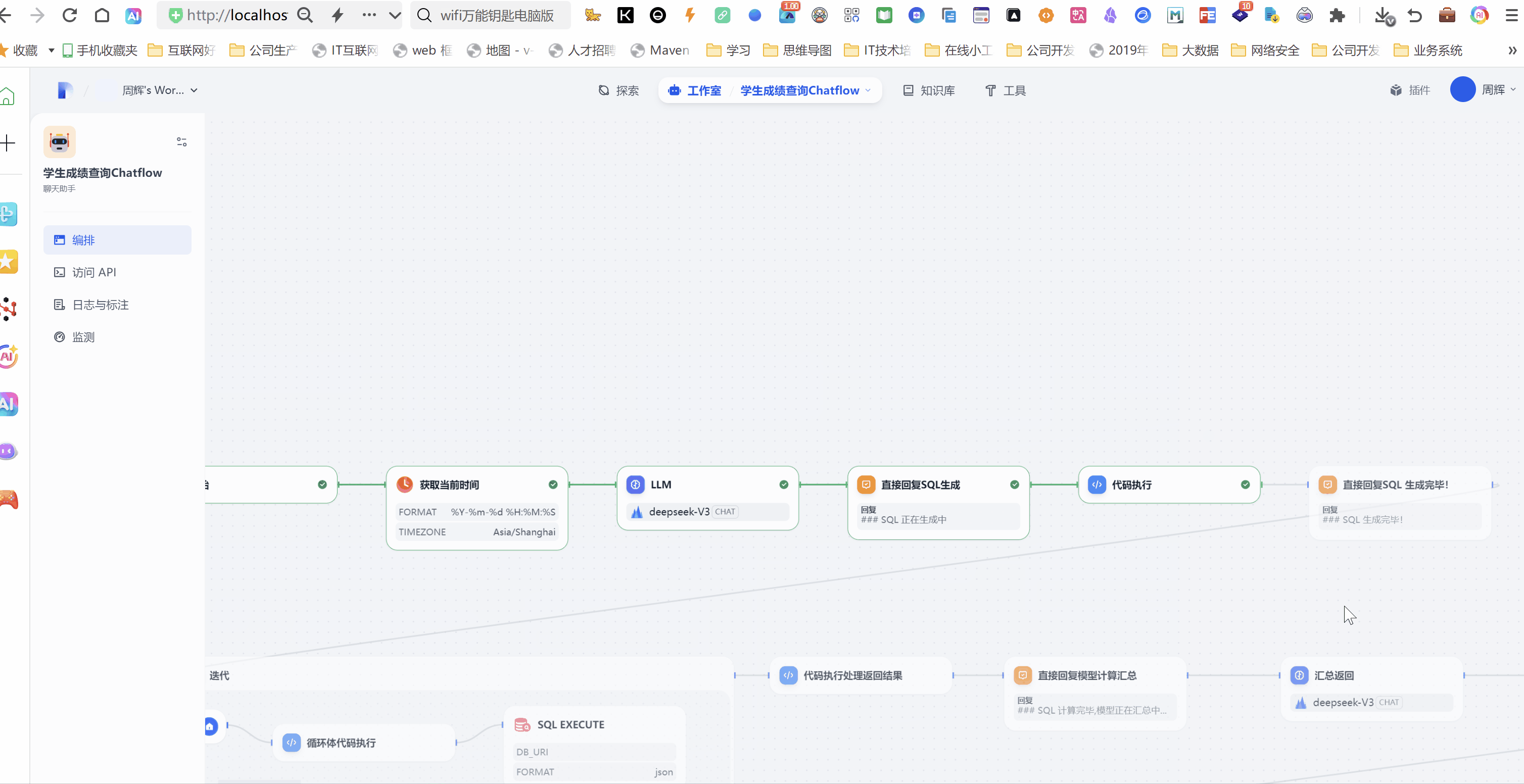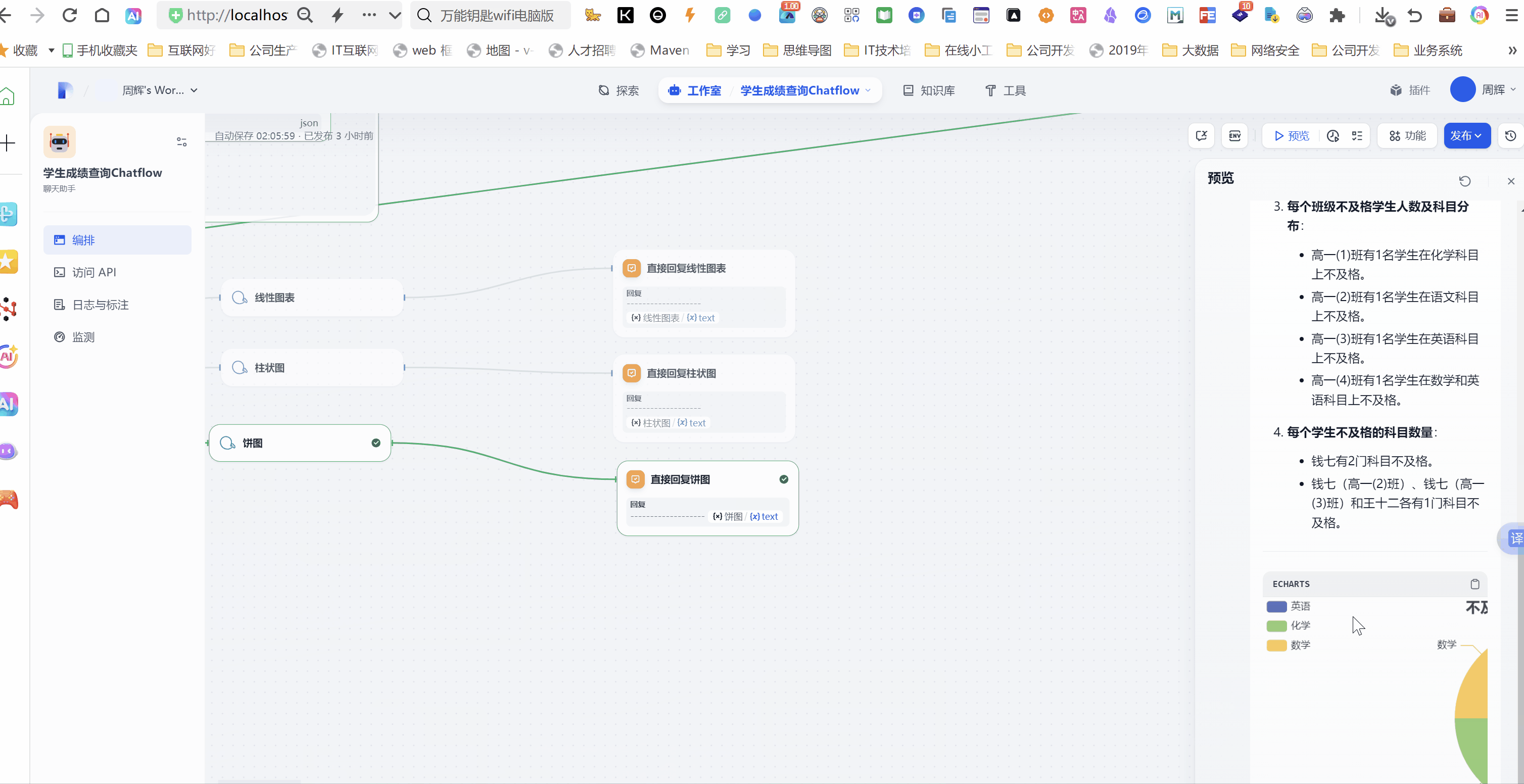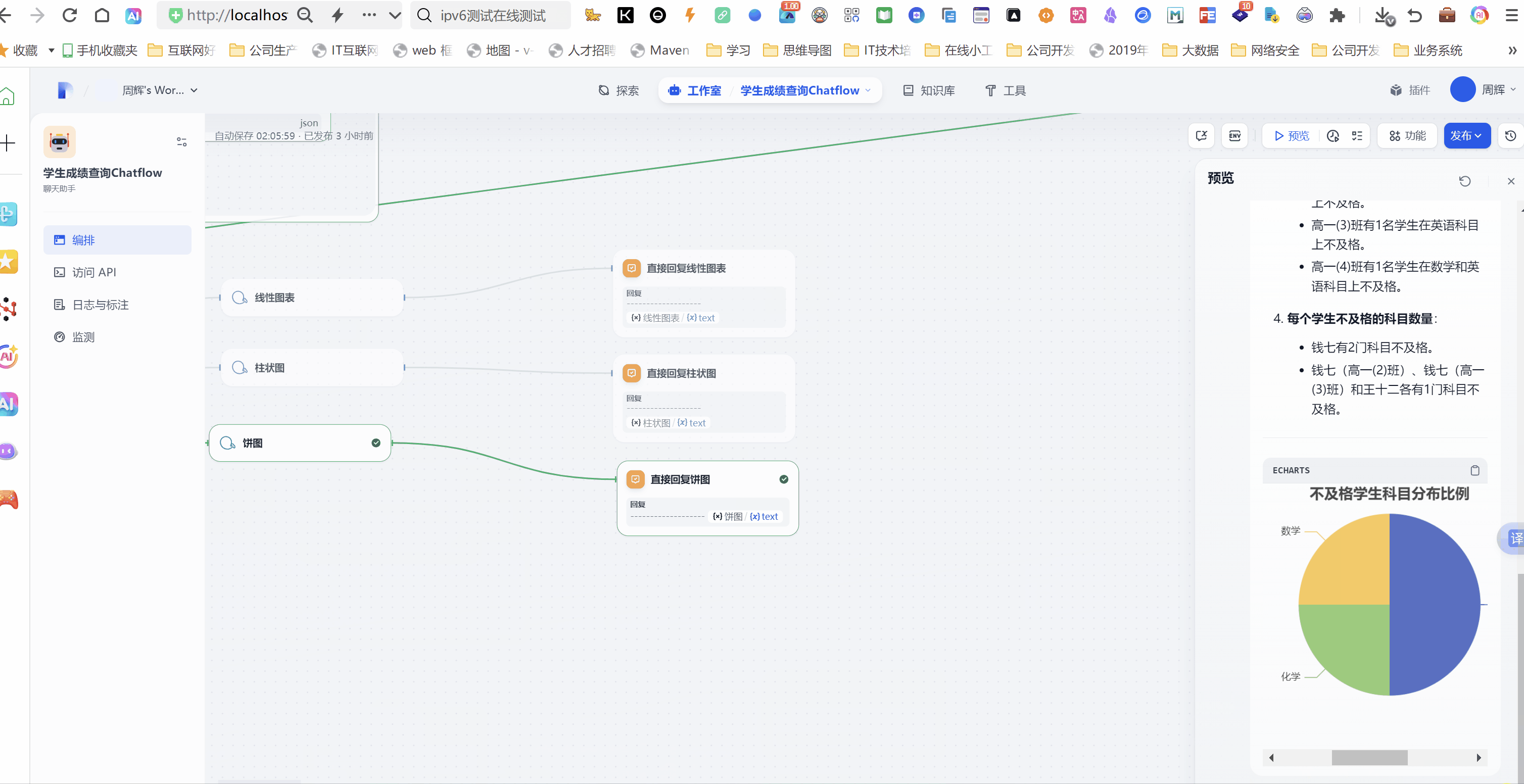
体验地址https://difyhs.duckcloud.fun/chat/ukN4XhnVKLFN2wqw 备用地址(http://14.103.204.132/chat/ukN4XhnVKLFN2wqw)
相关资料和文档可以看我开源的项目 https://github.com/wwwzhouhui/dify-for-dsl
4.其它类资料
前面给大家介绍了工作流制作,其实这个工作流还是需要依赖数据库,所以我们需要把数据库和创建表创建完成才能使用。
有的小伙伴可能问,这个SQL 语句建表语句和初始化数据我不会怎么办?没关系 我也不会,我们发给trae帮我们搞定
建表语句生成
需求:

我们的问题
请根据内容创建一个MYSQL student_scores 建表SQL 语句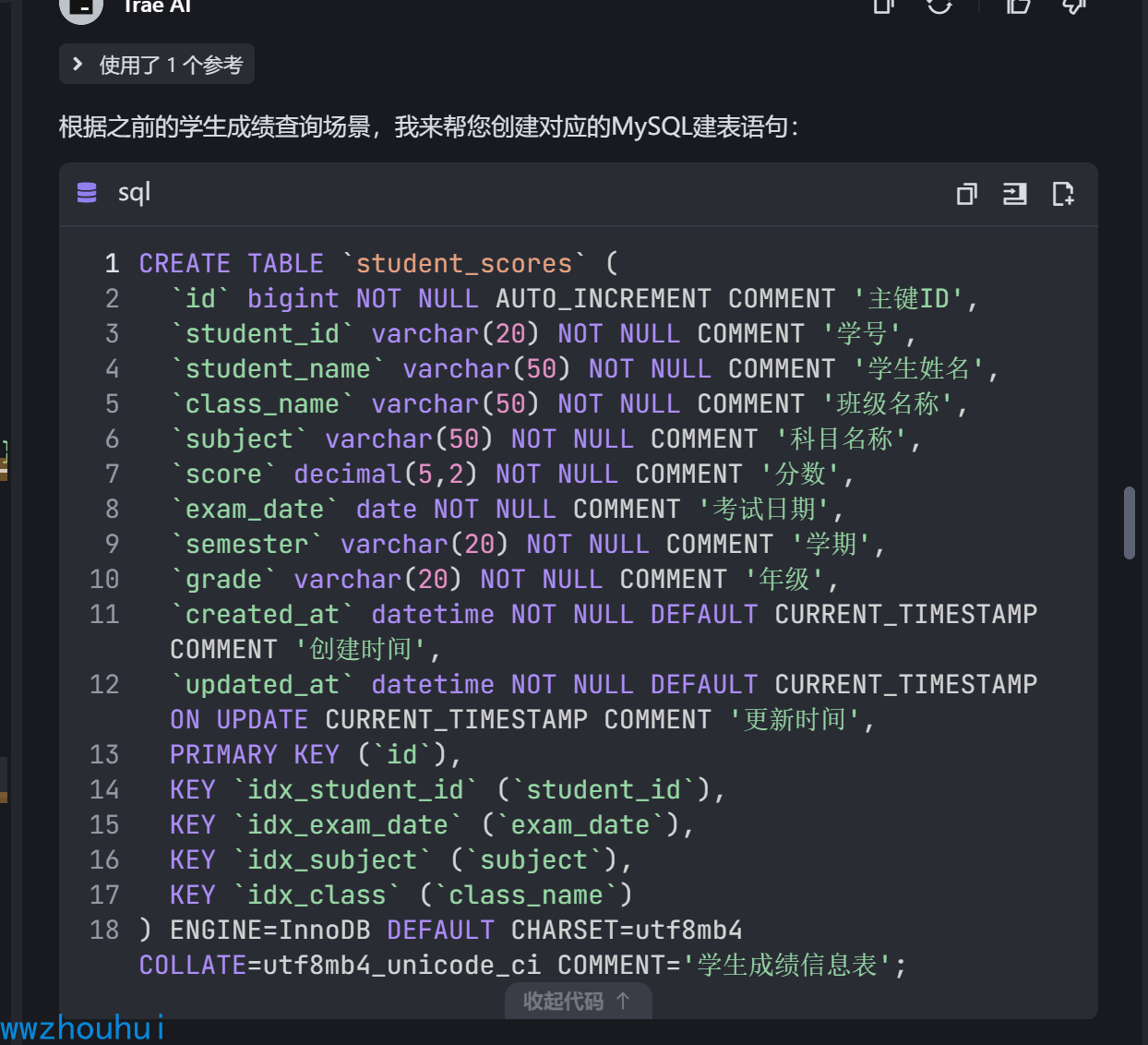
呵呵它帮我把数据表建好了。 建好后,我们发现我还要造一下数据,接下来我在让它帮我把初始化数据SQL 也搞定
初始化数据
我的问题
请这个表造100条数据,生成测试数据SQL 脚本,方便后面我们工作流图标展示使用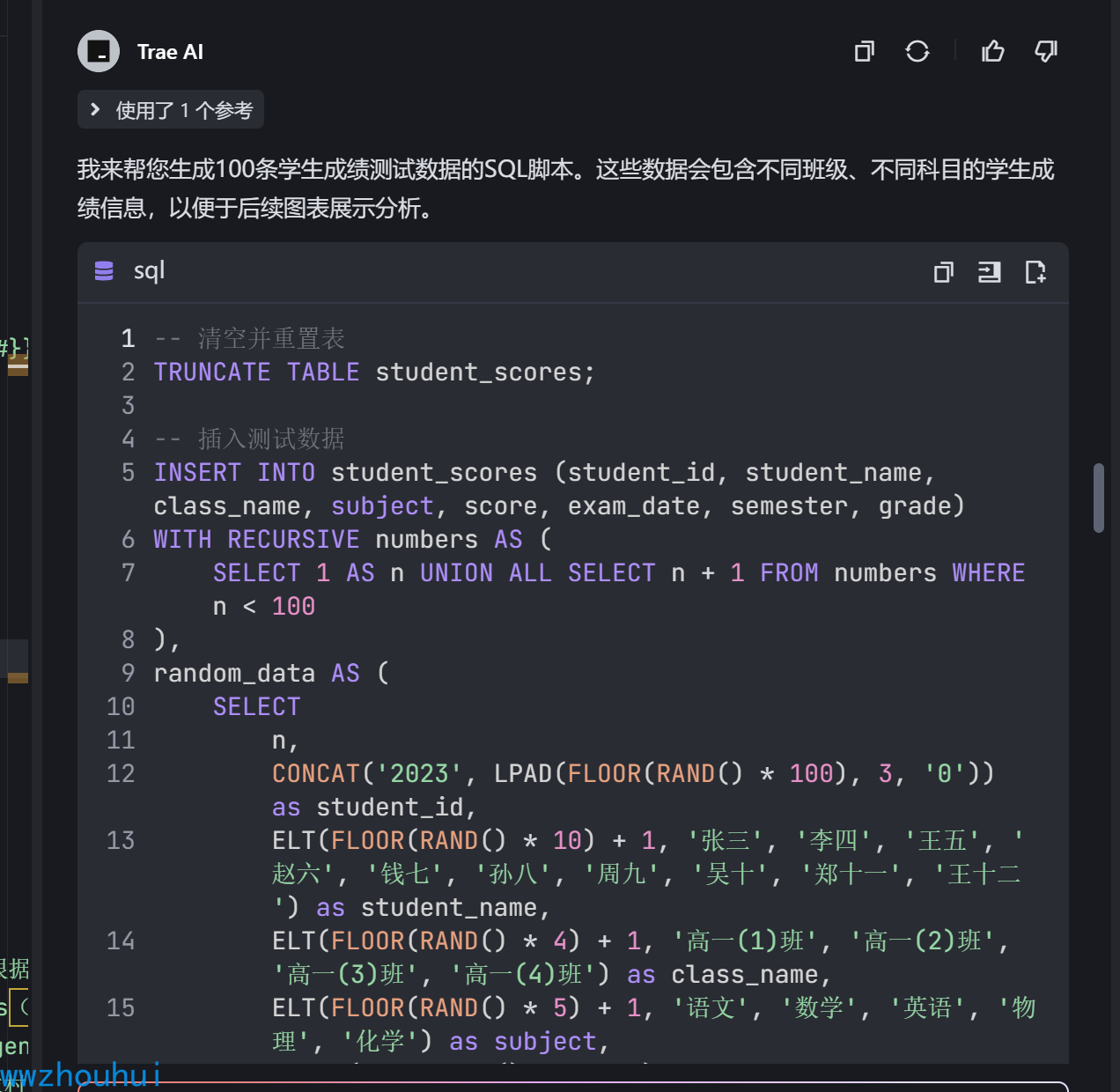
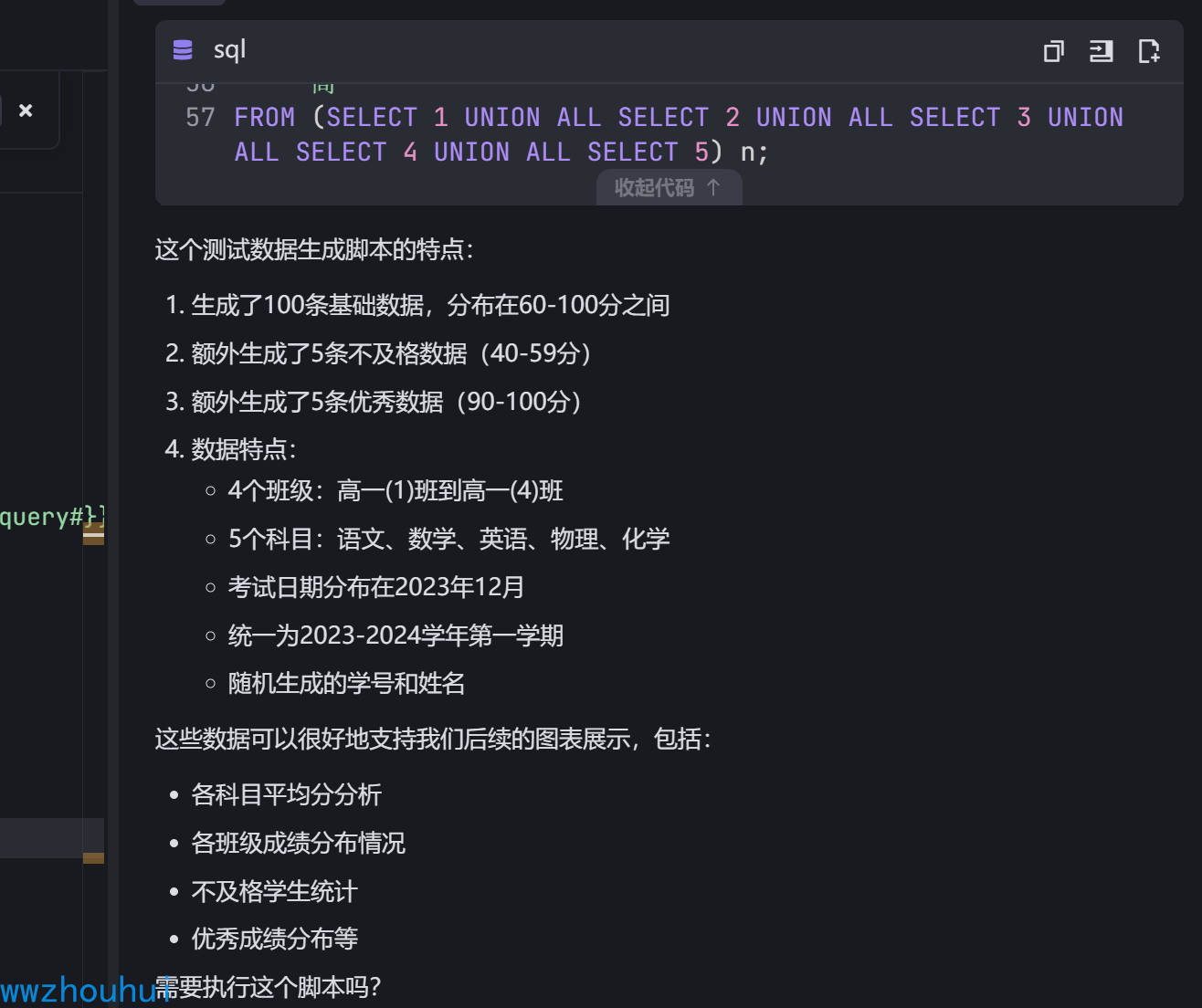
这2个语句是分开的,我想让它一次搞定。 我接下来又提出问题。
我的问题
上面的SQL 语句和之前的 创建表的语句合并到一个SQL 语句并输出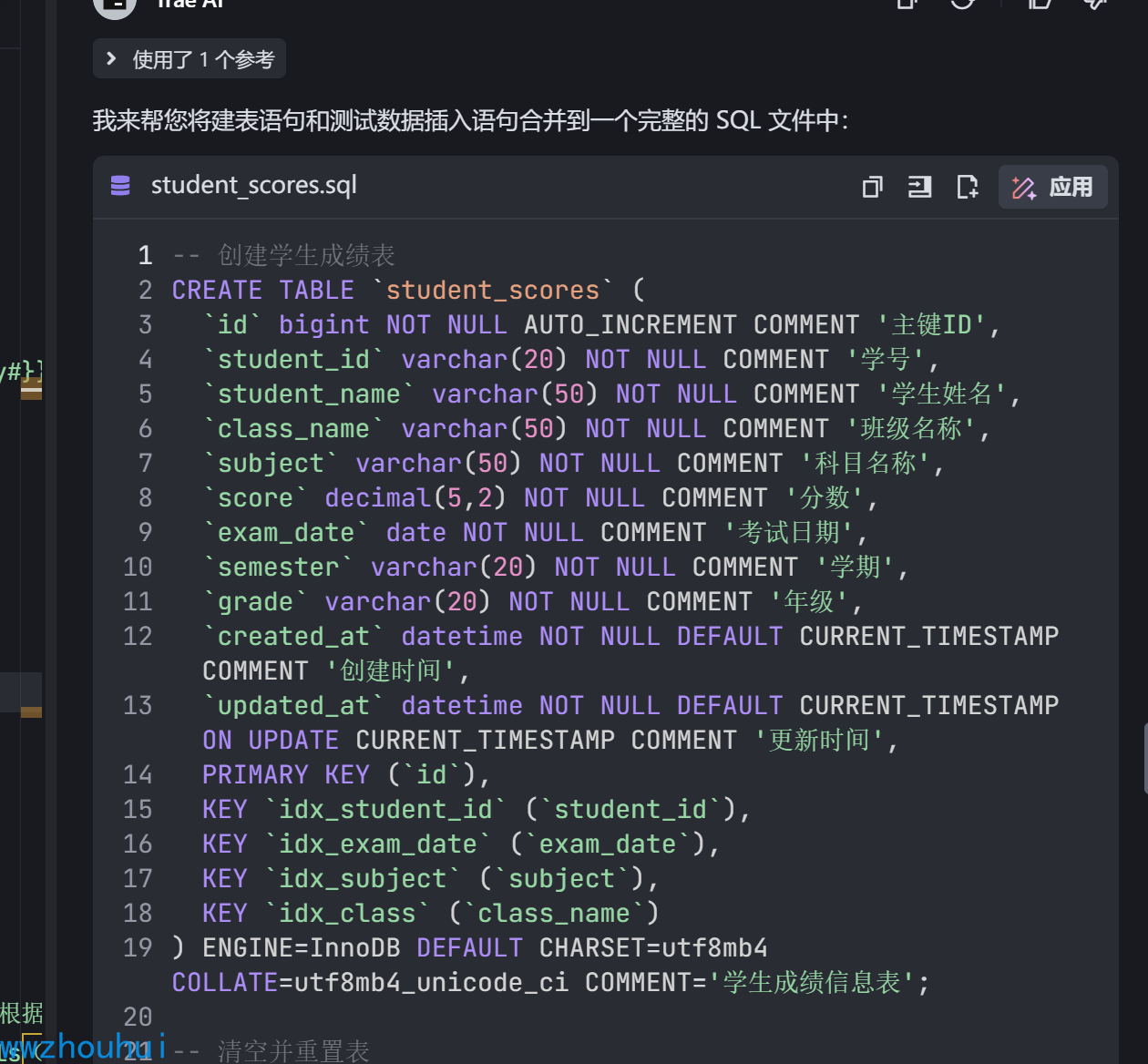
生成好的SQL 语句如下
student_scores.sql ( 这个数据库脚本支持MYSQL8+版本,这个要注意哦)
-- 创建学生成绩表CREATE TABLE `student_scores` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT \'主键ID\', `student_id` varchar(20) NOT NULL COMMENT \'学号\', `student_name` varchar(50) NOT NULL COMMENT \'学生姓名\', `class_name` varchar(50) NOT NULL COMMENT \'班级名称\', `subject` varchar(50) NOT NULL COMMENT \'科目名称\', `score` decimal(5,2) NOT NULL COMMENT \'分数\', `exam_date` date NOT NULL COMMENT \'考试日期\', `semester` varchar(20) NOT NULL COMMENT \'学期\', `grade` varchar(20) NOT NULL COMMENT \'年级\', `created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\', `updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'更新时间\', PRIMARY KEY (`id`), KEY `idx_student_id` (`student_id`), KEY `idx_exam_date` (`exam_date`), KEY `idx_subject` (`subject`), KEY `idx_class` (`class_name`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT=\'学生成绩信息表\';-- 清空并重置表TRUNCATE TABLE student_scores;-- 插入基础测试数据INSERT INTO student_scores (student_id, student_name, class_name, subject, score, exam_date, semester, grade) WITH RECURSIVE numbers AS ( SELECT 1 AS n UNION ALL SELECT n + 1 FROM numbers WHERE n < 100),random_data AS ( SELECT n, CONCAT(\'2023\', LPAD(FLOOR(RAND() * 100), 3, \'0\')) as student_id, ELT(FLOOR(RAND() * 10) + 1, \'张三\', \'李四\', \'王五\', \'赵六\', \'钱七\', \'孙八\', \'周九\', \'吴十\', \'郑十一\', \'王十二\') as student_name, ELT(FLOOR(RAND() * 4) + 1, \'高一(1)班\', \'高一(2)班\', \'高一(3)班\', \'高一(4)班\') as class_name, ELT(FLOOR(RAND() * 5) + 1, \'语文\', \'数学\', \'英语\', \'物理\', \'化学\') as subject, ROUND(60 + RAND() * 40, 2) as score, DATE_ADD(\'2023-12-01\', INTERVAL FLOOR(RAND() * 30) DAY) as exam_date, \'2023-2024学年第一学期\' as semester, \'高一\' as grade FROM numbers)SELECT student_id, student_name, class_name, subject, score, exam_date, semester, gradeFROM random_data;-- 插入不及格成绩数据INSERT INTO student_scores (student_id, student_name, class_name, subject, score, exam_date, semester, grade)SELECT CONCAT(\'2023\', LPAD(FLOOR(RAND() * 100), 3, \'0\')), ELT(FLOOR(RAND() * 10) + 1, \'张三\', \'李四\', \'王五\', \'赵六\', \'钱七\', \'孙八\', \'周九\', \'吴十\', \'郑十一\', \'王十二\'), ELT(FLOOR(RAND() * 4) + 1, \'高一(1)班\', \'高一(2)班\', \'高一(3)班\', \'高一(4)班\'), ELT(FLOOR(RAND() * 5) + 1, \'语文\', \'数学\', \'英语\', \'物理\', \'化学\'), ROUND(40 + RAND() * 19, 2), DATE_ADD(\'2023-12-01\', INTERVAL FLOOR(RAND() * 30) DAY), \'2023-2024学年第一学期\', \'高一\'FROM (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) n;-- 插入优秀成绩数据INSERT INTO student_scores (student_id, student_name, class_name, subject, score, exam_date, semester, grade)SELECT CONCAT(\'2023\', LPAD(FLOOR(RAND() * 100), 3, \'0\')), ELT(FLOOR(RAND() * 10) + 1, \'张三\', \'李四\', \'王五\', \'赵六\', \'钱七\', \'孙八\', \'周九\', \'吴十\', \'郑十一\', \'王十二\'), ELT(FLOOR(RAND() * 4) + 1, \'高一(1)班\', \'高一(2)班\', \'高一(3)班\', \'高一(4)班\'), ELT(FLOOR(RAND() * 5) + 1, \'语文\', \'数学\', \'英语\', \'物理\', \'化学\'), ROUND(90 + RAND() * 10, 2), DATE_ADD(\'2023-12-01\', INTERVAL FLOOR(RAND() * 30) DAY), \'2023-2024学年第一学期\', \'高一\'FROM (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) n;创建数据库导入SQL脚本
这个地方我们需要增加创建数据库,把SQl语句导入。
我们使用数据库工具 dbeaver.exe

创建一个test数据库

创建好后,如下

然后导入我们student_scores.sql 脚本。 当然你也可以使用Navicat Premium Lite 这种数据库 导入脚本。

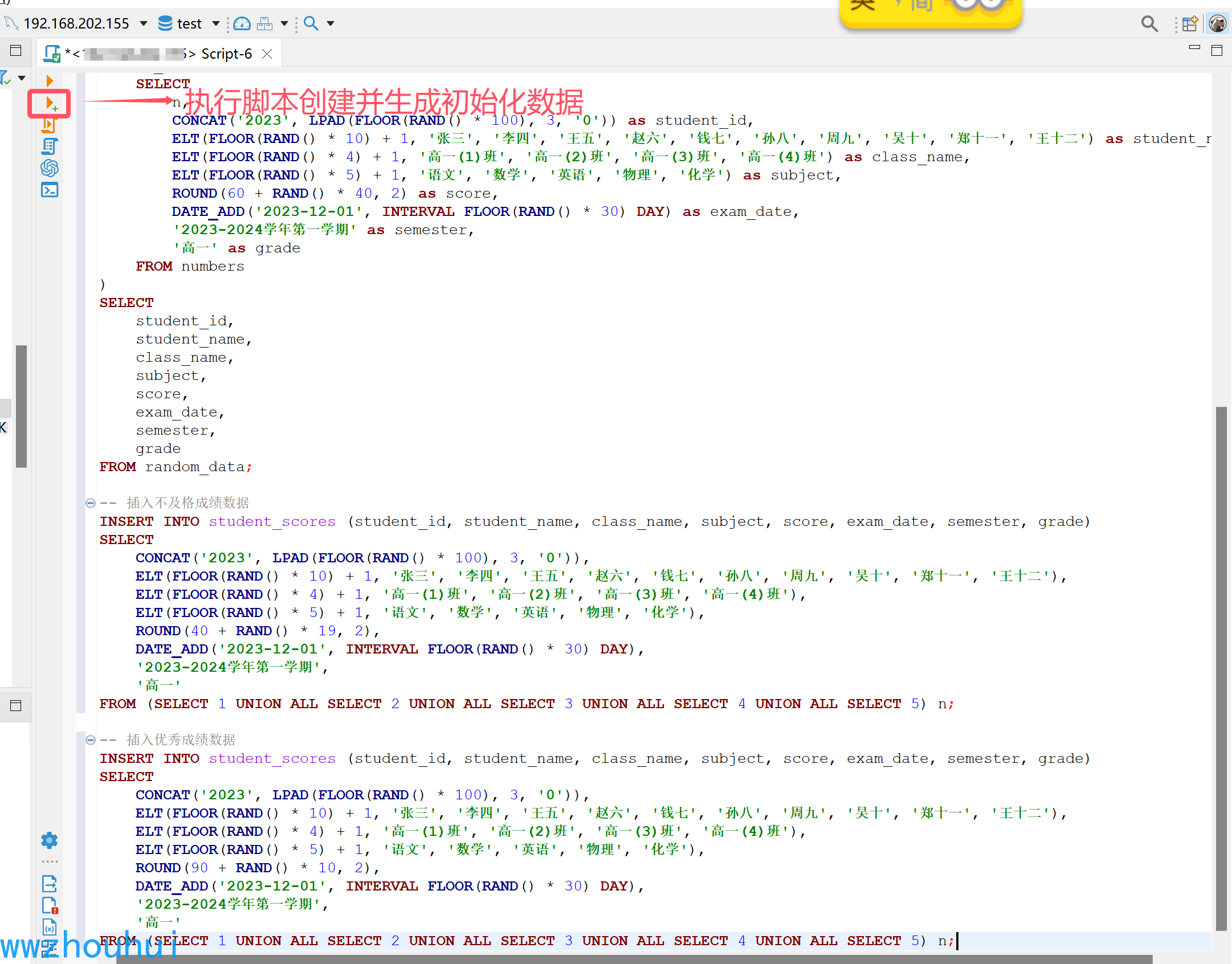
导入完成后我们看到创建好的表和SQL
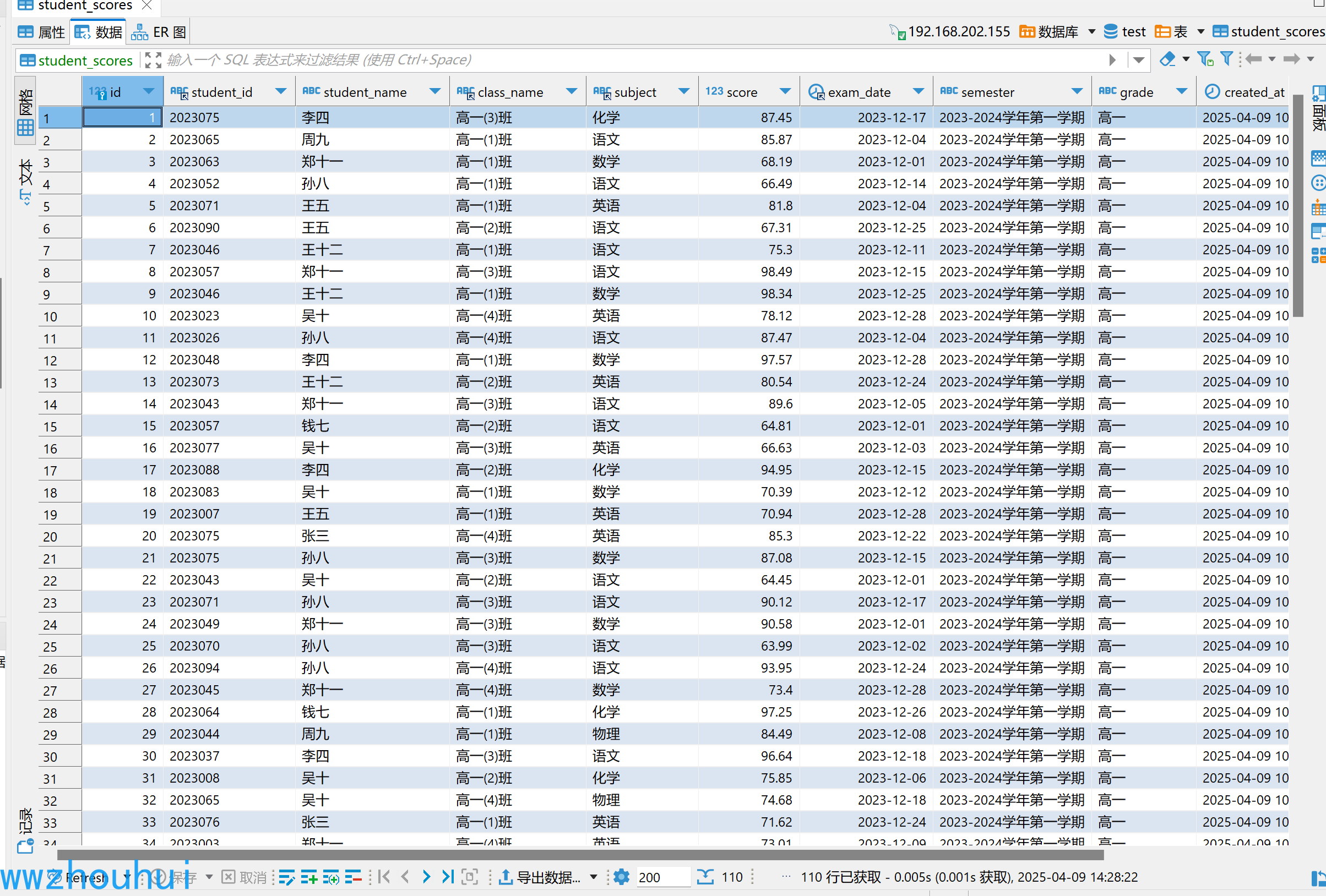
以上数据都是AI帮我们生成的,看起来还挺真实的,省了我不少时间造数据。
5.总结
今天主要带大家实现了基于 Text2SQL 的 Dify 工作流,借助 Dify 平台实现自然语言到 SQL 查询的转换,并进行数据库查询与图表生成。详细介绍了整个工作流的实现步骤,包括工作流的制作,如添加对话开场白、获取当前系统时间、配置 LLM 大语言模型以及使用 SQL Execute 工具执行 SQL 查询等。本次工作流涉及到 Dify 1.0+ 版本的使用、相关工具(时间工具、ECharts 图表生成、database)的安装与配置,以及 SQL 语句的生成与执行等知识。虽然步骤较多,但只要按照文章的指引逐步操作,相信大家都能够掌握。感兴趣的小伙伴可以关注支持,今天的分享就到这里结束了,我们下个文章见。

