自动化框架 Selenium 的使用
介绍
Selenium 是一个用于自动化 Web 浏览器的开源工具套件,主要用于 Web 应用程序测试,也可用于网页抓取和自动化 Web 任务。
早期的 selenium RC 已经被现在的 webDriver 所替代,可以简单的理解为 selenium1.0+webdriver 构成现在的Selenium2.0 。现在我们说起 selenium ,一般指的是 Selenium2.0 。它有由 Selenium IDE ,Webdriver, Selenium Grid 组成。
Selenium IDE
Selenium IDE 一个用于 Selenium 测试的完成集成开发环境,可以直接录制在浏览器的用户操作,并且能回放,编辑和调试测试脚本。调试过程中可以逐步进行或调整执行的速度,并且可以在底部浏览日志出错信息。录制的测试脚本可以以多种语言导出,比如java, C# , Python , Ruby 等,方便掌握不同语言的测试人员操作。
Webdriver
Selenium RC 在浏览器中运行 JavaScript 应用,会存在环境沙箱问题,而 WebDriver 可以跳JavaScript的沙箱,针对不同的浏览器创建更健壮的,分布式的,跨平台的自动化测试脚本。基于特定语言(Java , C# , Python , Ruby , Perl , JavaScript 等)绑定来驱动浏览器对 Web 元素进行操作和验证。
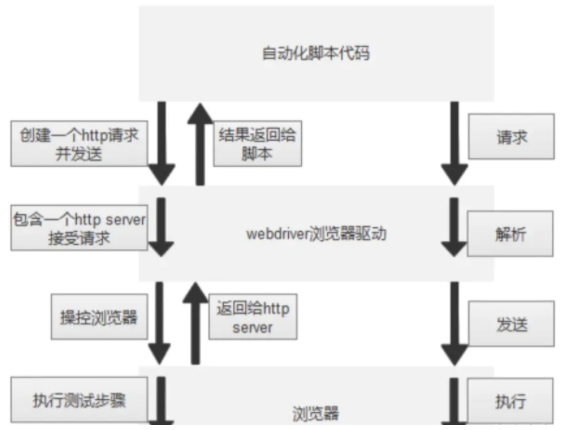
webdriver的工作原理
- 启动浏览器后,webdriver会将目标浏览器绑定到特定的端口,启动后的浏览器则作为webdriver的remote server。
- 客户端(也就是测试脚本),借助ComandExecutor发送HTTP请求给sever端(通信协议:The WebDriver Wire Protocol,在HTTP request的body中,会以WebDriver Wire协议规定的JSON格式的字符串来告诉Selenium我们希望浏览器接下来做什么事情)。
- Sever端需要依赖原生的浏览器组件,转化Web Service的命令为浏览器native的调用来完成操作。
Selenium Grid
selenium Grid是一个服务器,提供对浏览器实例访问的服务器列表,管理各个节点的注册和状态信息。可以实现在同一时刻不同服务器上执行不同的测试脚本,即可以分布式执行测试,支持并行跨浏览器测试, 提高测试效率。
搭建自动化环境
安装驱动管理
WebDriver-Manager 是一个用于自动化管理 Web 驱动程序的工具库,它可以自动下载、配置和维护 Selenium WebDriver 所需的各种浏览器驱动(如 ChromeDriver、GeckoDriver、EdgeDriver 等),极大简化了自动化测试和 Web 应用程序开发中的驱动管理问题。
pip install webdriver-manager安装selenium库
selenium版本很多,统⼀使⽤selenium 4.0.0版本
pip install selenium==4.0.0新建一个项目,需要注意的是使用解释器时选择继承已有解释器的包,这样就可以在设置模块查看 python 解释器存在以上两个包,则可以新建一个文件运行以下代码来查看是否能正常运行。
import timefrom selenium import webdriverfrom selenium.webdriver.chrome.service import Service as ChromeServicefrom selenium.webdriver.common.by import Byfrom webdriver_manager.chrome import ChromeDriverManager#驱动程序管理的⾃动化#创建驱动对象#1.打开浏览器driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))#2.输⼊百度⽹址:https://www.baidu.comdriver.get(\"https://www.baidu.com\")#3、找到输⼊框并输⼊“迪丽热巴”driver.find_element(By.CSS_SELECTOR,\"#kw\").send_keys(\"迪丽热巴\")#4、找到“百度⼀下”按钮并点击driver.find_element(By.CSS_SELECTOR,\"#su\").click()time.sleep(5)#5、关闭浏览器driver.quit()需要注意的是由于 ChromeDriver 的下载服务器(https://chromedriver.storage.googleapis.com)在国外,所以需要使用代理服务器才能正常运行。
常用函数的使用
元素的定位
find_element 是 Selenium WebDriver 中最常用的元素定位方法之一,用于在网页上查找并返回 第一个匹配 指定条件的元素。以下是详细介绍:
def find_element(self, by=By.ID, value=None) -> WebElement-
作用:查找并返回页面上 第一个 符合定位条件的元素。
-
返回值:WebElement 对象(可直接操作,如点击、输入文本等)。
-
异常:若未找到匹配元素,抛出 NoSuchElementException。
-
定位方式:支持多种定位策略,通过 By 类指定:如
By.ID和By.CSS_SELECTOR等。
示例代码:
driver.find_element(By.CSS_SELECTOR,\"#kw\")操作测试对象
点击/提交对象
click()
#找到百度⼀下按钮并点击driver.find_element(By.CSS_SELECTOR, \"#su\").click()模拟按键输⼊
send_keys(\"\")
driver.find_element(By.CSS_SELECTOR, \"#kw\").send_keys(\"迪丽热巴\")清除文本内容
输⼊⽂本后⼜想换⼀个新的关键词,这⾥就需要⽤到 clear()
driver.find_element(By.CSS_SELECTOR, \"#kw\").send_keys(\"迪丽热巴\")time.sleep(1)driver.find_element(By.CSS_SELECTOR,\"#kw\").clear()time.sleep(1)driver.find_element(By.CSS_SELECTOR, \"#kw\").send_keys(\"古⼒娜扎\")获取文本信息
如果判断获取到的元素对应的⽂本是否符合预期呢?获取元素对应的⽂本并打印⼀下~~
text=driver.find_element(By.CSS_SELECTOR,\"#hotsearch-content-wrapper > li:nth-child(1) > a\").textprint(text)问题:是否可以通过 text 获取到“百度⼀下按钮”上的文字“百度⼀下”呢? 注意:⽂本和属性值不要混淆了。获取属性值需要使⽤⽅法 get_attribute(\" 属性名称 \") ;
text=driver.find_element(By.CSS_SELECTOR,\"#su\").get_attribute(\"value\")print(text)获取当前页面标题
title
title = driver.title获取当前页面URL
current_url
url = driver.current_url窗⼝
打开⼀个新的⻚⾯之后获取到的title和URL仍然还是前⼀个⻚⾯的? 当我们⼿⼯测试的时候,我们可以通过眼睛来判断当前的窗⼝是什么,但对于程序来说它是不知道当前最新的窗⼝应该是哪⼀个。对于程序来说它怎么来识别每⼀个窗⼝呢?每个浏览器窗⼝都有⼀个唯⼀的属性句柄(handle)来表⽰,我们就可以通过句柄来切换。
切换窗口
1)获取当前⻚⾯句柄: driver.current_window_handle
2)获取所有⻚⾯句柄: driver.window_handles
3)切换当前句柄为最新⻚⾯:
curWindow = driver.current_window_handleallWindows = driver.window_handlesfor window in allWindows: if window != curWindow: driver.switch_to.window(window)注意:执⾏了 driver.close() 之前需要切换到未被关闭的窗口
窗口设置大小
#窗⼝最⼤化driver.maximize_window()#窗⼝最⼩化driver.minimize_window()#窗⼝全屏driver.fullscreen_window()#⼿动设置窗⼝⼤⼩driver.set_window_size(1024,768)屏幕截图
我们的⾃动化脚本⼀般部署在机器上⾃动的去运⾏,如果出现了报错,我们是不知道的,可以通过抓拍来记录当时的错误场景
driver.save_screenshot(\'../images/image.png\')代码演⽰
#简单版本driver.save_screenshot(\'../images/image.png\')#⾼阶版本filename = \"autotest-\"+datetime.datetime.now().strftime(\'%Y-%m-%d-%H%M%S\')+\'.png\'driver.save_screenshot(\'../images/\'+filename)关闭窗⼝
driver.close() 注意:窗⼝关闭后 driver 要重新定义
弹窗
弹窗是在页面是找不到任何元素的,这种情况怎么处理?使⽤selenium提供的Alert接⼝ 
alert = driver.switchTo.alert//确认alert.accept()//取消alert.dismiss()等待
通常代码执⾏的速度⽐页面渲染的速度要快,如果避免因为渲染过慢出现的⾃动化误报的问题呢?可以使⽤selenium中提供的三种等待⽅法:
强制等待
time.sleep () 优点:使⽤简单,调试的时候⽐较有效 缺点:影响运⾏效率,浪费⼤量的时间
隐式等待
隐式等待是⼀种智能等待,他可以规定在查找元素时,在指定时间内不断查找元素。如果找到则代码继续执⾏,直到超时没找到元素才会报错。 implicitly_wait () 参数:秒 ⽰例:
#隐式等待5秒driver.implicitly_wait(5)隐式等待 作⽤域 是整个脚本的所有元素。即只要driver对象没有被释放掉( driver.quit() ),隐式等待就⼀直⽣效。 优点:智能等待,作⽤于全局
显式等待
显式等待也是⼀种智能等待,在指定超时时间范围内只要满⾜操作的条件就会继续执⾏后续代码
WebDriverWait(driver,sec).until(functions)functions :涉及到selenium.support.ui.ExpectedConditions包下的 ExpectedConditions 类 由于写法复杂,这里不一一详细介绍
浏览器参数设置
设置无头模式
options = webdriver.ChromeOptions()options.add_argument(\"-headless\")driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),options=options)页面加载策略
options.page_load_strategy = \'加载⽅式\'⻚⾯加载⽅式主要有三种类型:
options = webdriver.ChromeOptions()options.page_load_strategy = \'eager\'driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),options=options)
