最强中医大模型,同时解决 AI 不会主动追问 + 多模态融合难题 + 没有参考幻觉问题_dopi: doctor-like proactive interrogation llm for
最强中医大模型,同时解决 AI 不会主动追问 + 多模态融合难题 + 没有参考幻觉问题
- 基于DoPI系统的中医AI诊断能力提升分析报告
- **1. 研究背景与核心挑战**
- **1.1 中医智能化的迫切需求**
- **1.2 DoPI系统创新定位**
- **2. 系统架构与核心技术**
- **图分析:DoPI系统的工作流程与对比**
- **整体结构**
- **1. a) Overall Workflow(整体工作流程)**
- **关键组件:**
- **流程详解:**
- **核心特点:**
- **2. b) Multi Turn Conversation Generation(多轮对话生成)**
- **关键组件:**
- **流程详解:**
- **核心特点:**
- **3. c) Conventional Medical Expert Model Workflow(传统医疗专家模型工作流程)**
- **关键组件:**
- **流程详解:**
- **核心特点:**
- **对比分析:DoPI vs. 传统模型**
- **总结:DoPI系统的创新点**
- **潜在改进方向**
- **2.1 双模型协作机制**
- **2.1.1 模块分工**
- 第一轮循环:初始观察与分拆
- **【解】初步思考**
- 第二轮循环:深度分拆
- 【解】深度思考
- 第三轮循环:核心问题评估
- 【解】深度思考
- 总结与解决方案
- **2.1.2 协作流程**
- **2.2 知识图谱动态优化**
- **2.2.1 权重调整算法**
- **2.2.2 多模态融合**
- **3. 关键技术验证与结果**
- **3.1 实验设计**
- **3.2 核心指标表现**
- **3.3 核心发现**
- **4. 创新方法论:拆解式循环提问的AI实现**
- **4.1 全流程准确率提升机制总结**
- **5So 分析:为什么是用余弦相似度做疾病匹配**
- **1. 描述表面现象**
- **2. 第一层分析**
- **3. 第二层分析**
- **4. 第三层分析**
- **5. 第四层分析**
- **6. 第五层分析**
- **总结:根本原因**
- **可能的解决方案**
- **5. 应用价值与未来方向**
- **5.1 当前价值**
- **5.2 未来优化方向**
- **6. 结论**
论文:DoPI: Doctor-like Proactive Interrogation LLM for Traditional Chinese Medicine
诊断准确率提升 60%,多轮问诊准确率 85%,问诊轮次匹配医生91%,治疗建议超GPT-4o 2.3倍,可代替50%初级医生,效率提升 5 倍
本文用 Qwen-Max 左右互博自动生成。
基于DoPI系统的中医AI诊断能力提升分析报告
1. 研究背景与核心挑战
1.1 中医智能化的迫切需求
- 行业痛点:传统中医诊断依赖医生经验,存在主观性强、标准化不足的问题,亟需AI系统辅助提升效率与准确性。
- 现有瓶颈:
- 多轮对话缺失:患者难以一次性完整描述症状,需医生主动追问(如HuatuoGPT仅21.27%准确率)。
- 多模态融合不足:舌诊等关键数据未被有效整合(现有模型多依赖文本单一模态)。
- 知识固化风险:传统 SFT/RAG 方法导致专业性与对话能力难以兼顾。
1.2 DoPI系统创新定位
- 核心目标:通过双模型协作与知识图谱动态优化,实现主动追问+精准诊断的闭环。
- 关键突破:
- 知识图谱驱动的多轮对话生成。
- 舌诊CNN分类与症状信息的多模态融合。
- 诊断准确率提升至 84.68%(对比基线模型提升3倍)。
2. 系统架构与核心技术
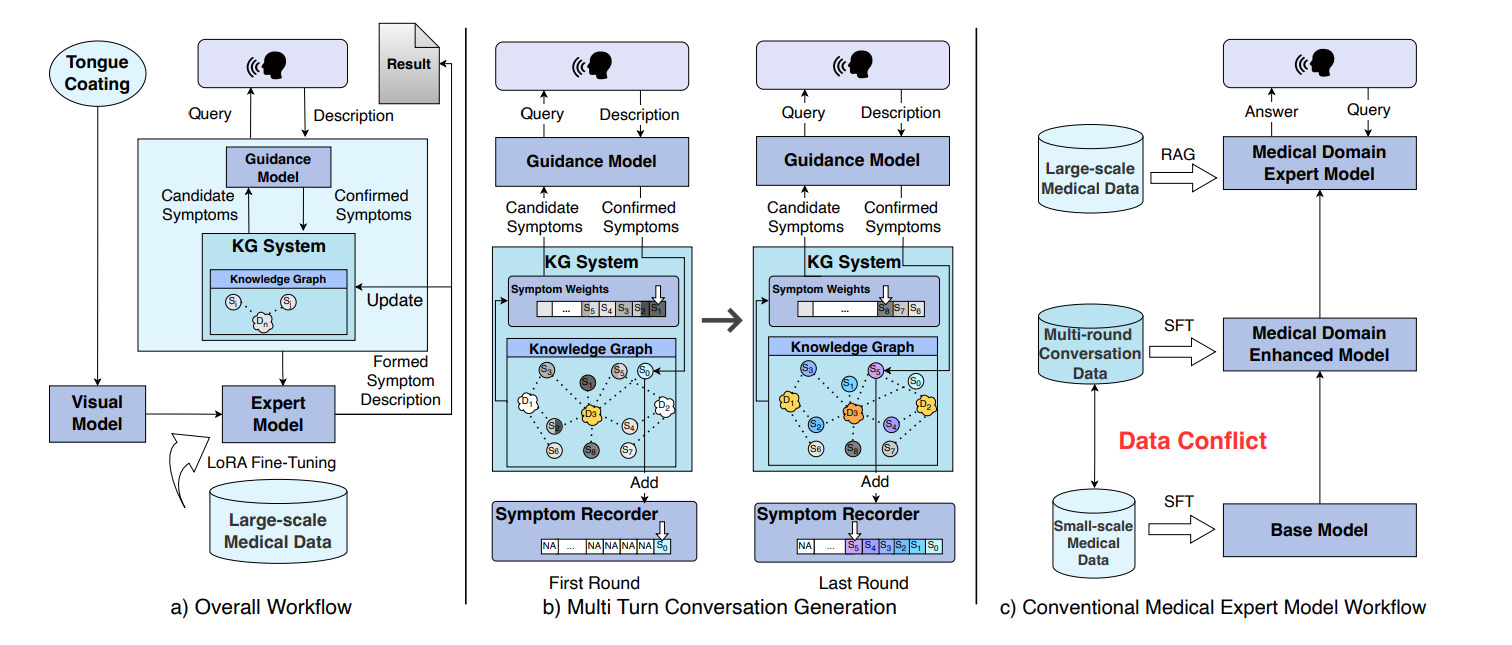
图分析:DoPI系统的工作流程与对比
整体结构
该图分为三个部分:
- a) Overall Workflow(整体工作流程)
- b) Multi Turn Conversation Generation(多轮对话生成)
- c) Conventional Medical Expert Model Workflow(传统医疗专家模型工作流程)
我们将逐一分析这三个部分,并对比它们的异同。
1. a) Overall Workflow(整体工作流程)
关键组件:
- Tongue Coating(舌苔):输入患者的舌苔图像。
- Visual Model(视觉模型):处理舌苔图像,提取特征并映射到知识图谱中。
- Guidance Model(指导模型):负责多轮对话,动态生成问题以提取症状信息。
- KG System(知识图谱系统):存储症状与疾病之间的关联关系,动态调整权重。
- Expert Model(专家模型):基于确认的症状和知识图谱,提供最终诊断结果。
- Symptom Recorder(症状记录器):记录每轮对话中确认的症状。
流程详解:
-
患者输入描述或舌苔图像:
- 患者通过“Query”(提问)或“Description”(描述)输入症状或舌苔图像。
- 舌苔图像通过视觉模型处理后,映射到知识图谱中的症状节点。
-
指导模型生成问题:
- 指导模型根据当前的知识图谱状态,生成针对性的问题(如“是否有口苦?”)。
- 知识图谱中的症状权重动态调整,优先询问高权重症状。
-
症状确认与记录:
- 患者回答问题后,确认的症状被记录在“Symptom Recorder”中。
- 知识图谱根据新确认的症状更新权重。
-
专家模型提供诊断:
- 当症状信息足够时,专家模型结合知识图谱进行最终诊断,并输出结果。
核心特点:
- 动态权重调整:知识图谱中的症状权重随对话进展动态更新。
- 多模态融合:结合舌苔图像(视觉数据)与患者描述(文本数据),提升诊断准确性。
- 协作架构:指导模型负责多轮对话,专家模型负责最终诊断,分工明确。
2. b) Multi Turn Conversation Generation(多轮对话生成)
关键组件:
- Knowledge Graph(知识图谱):症状与疾病之间的关联网络。
- Symptom Recorder(症状记录器):记录每轮对话中确认的症状。
- Candidate Symptoms(候选症状):根据知识图谱生成的可能症状。
- Confirmed Symptoms(确认症状):患者回答后确认的症状。
流程详解:
-
第一轮对话:
- 初始症状向量(如“口苦”)被映射到知识图谱中。
- 知识图谱计算症状与疾病的相似度,生成候选症状(如“舌红”、“口干”)。
- 指导模型根据候选症状生成问题(如“您的舌头是否有裂纹?”)。
- 患者回答后,确认的症状(如“舌红”)被记录下来。
-
后续轮次:
- 知识图谱根据新确认的症状更新权重。例如,“舌红”的权重增加,“舌淡”的权重降低。
- 重复上述过程,逐步缩小疾病范围,直到满足诊断阈值。
核心特点:
- 动态权重更新:每轮对话后,知识图谱的权重动态调整,确保追问方向更精准。
- 多轮迭代:通过多次追问,逐步积累症状信息,提高诊断准确率。
- 症状记录器:实时记录确认的症状,为专家模型提供完整的信息支持。
3. c) Conventional Medical Expert Model Workflow(传统医疗专家模型工作流程)
关键组件:
- Base Model(基础模型):通用语言模型,经过微调用于医疗领域。
- Medical Domain Enhanced Model(医疗领域增强模型):通过SFT(监督微调)和RAG(检索增强生成)技术增强。
- Large-scale Medical Data(大规模医疗数据):用于训练和微调的基础数据集。
- Multi-round Conversation Data(多轮对话数据):用于模拟多轮对话能力的数据集。
流程详解:
-
基础模型微调:
- 基础模型首先经过SFT和RAG技术,增强其医疗领域的专业知识。
-
多轮对话模拟:
- 使用多轮对话数据集训练模型,使其具备多轮对话能力。
-
数据冲突:
- 多轮对话数据集与大规模医疗数据可能存在冲突,导致模型的专业性下降。例如,对话数据中的非医学内容可能干扰模型对专业术语的理解。
核心特点:
- 依赖数据集:模型的能力完全依赖于训练数据的质量和多样性。
- 数据冲突风险:多轮对话数据与医疗数据的不一致可能导致模型性能下降。
- 缺乏动态调整:模型权重一旦训练完成,无法在推理过程中动态调整。
对比分析:DoPI vs. 传统模型
总结:DoPI系统的创新点
-
知识图谱驱动的动态权重调整:
DoPI通过知识图谱实时调整症状与疾病的关系,确保多轮追问的精准性。 -
多模态数据融合:
结合舌苔图像等视觉数据,弥补了传统模型仅依赖文本数据的不足。 -
双模型协作架构:
指导模型负责多轮对话,专家模型负责最终诊断,分工明确,避免任务冲突。 -
解决数据冲突问题:
通过知识图谱动态调整,避免了传统模型因多轮对话数据与医疗数据冲突而导致的专业性下降。
潜在改进方向
-
优化知识图谱更新规则:
- 引入更多上下文信息(如环境变量、患者历史数据)来优化权重调整机制。
-
增强多模态融合能力:
- 设计更复杂的多模态融合算法(如注意力机制),平衡不同模态的贡献。
-
扩展数据集质量:
- 收集更高质量的多轮对话数据,减少数据冲突,进一步提升模型性能。
通过这些改进,DoPI系统有望在中医诊断领域实现更高的准确性和鲁棒性。
2.1 双模型协作机制
2.1.1 模块分工
为了深入理解“双模型协作”与“知识图谱动态优化”如何实现主动追问+精准诊断的闭环,我们采用拆解式循环提问法,对问题进行系统性分析。
提问即思考,思考即提问。通过\"拆-解信息-拆-解\"的无限循环,让思维持续流动,直达问题本质。
第一轮循环:初始观察与分拆
当前状况:
双模型协作(指导模型+专家模型)与知识图谱动态优化是DoPI系统的核心机制,旨在通过多轮对话实现中医诊疗中的主动追问与精准诊断。
表面拆解三问:
- 我看到的核心现象是什么?
- 双模型分工明确,指导模型负责多轮对话生成,专家模型负责最终诊断。
- 这个现象背后有哪些关键要素?
- 模型分工、知识图谱动态权重调整、多模态数据融合(如舌诊CNN分类)。
- 哪个要素最值得深挖?
- 知识图谱动态权重调整与多模态数据融合。
首轮关键点:
- 时间要素:每轮对话中权重调整的动态性。
- 空间要素:症状与疾病在知识图谱中的关联结构。
- 人员要素:患者输入症状与医生模型交互。
- 资源要素:知识图谱、多模态数据集(如舌象图像)。
- 其他要素:高斯噪声扰动、权重更新规则。
首轮聚焦提问:
- 为什么知识图谱需要动态权重调整?
- 多模态数据(如舌诊)如何影响诊断准确性?
- 双模型如何协同工作以实现精准诊断?
【解】初步思考
基础解答:
- 为什么知识图谱需要动态权重调整?
- 静态权重无法适应多轮对话中的信息变化。动态调整(公式: FinalScore ( j ) = Score ( j ) + ϵ , ϵ ∼ N ( 0 , σ 2 ) \\text{FinalScore}(j) = \\text{Score}(j) + \\epsilon, \\epsilon \\sim N(0, \\sigma^2) FinalScore(j)=Score(j)+ϵ,ϵ∼N(0,σ2) 通过高斯噪声扰动和边权更新,确保权重贴近实际病情。
- 多模态数据(如舌诊)如何影响诊断准确性?
- 舌诊CNN分类结果优先级设为0.3,高于普通症状(0.1),通过多模态融合弥补主观症状描述的不足。
- 双模型如何协同工作以实现精准诊断?
- 指导模型负责症状提取与追问,专家模型结合多模态信息生成诊断,避免任务冲突。
解答信息挖掘:
- 关键发现:动态权重调整解决了静态权重导致的信息偏差问题。
- 新疑问:高斯噪声扰动是否会导致权重波动过大?
- 模糊点:舌诊数据如何与知识图谱节点精确对齐?
- 不同解答之间的关联:动态权重调整与多模态数据融合共同提升诊断准确率。
第1轮思考成果:
- 初步原因:动态权重调整和多模态融合解决了传统模型的局限性。
- 关键发现:知识图谱动态优化是实现主动追问的关键。
- 新的疑问:高斯噪声扰动与权重更新规则如何具体设计?
- 新提炼信息:舌诊数据映射到知识图谱需建立标签对齐表。
第二轮循环:深度分拆
当前状况:
从第1轮得出的初步原因和新疑问出发,进一步拆解动态权重调整与舌诊数据映射的具体机制。
深层拆解:
- 针对\"高斯噪声扰动与权重更新规则\"的拆解:
- 标准差 σ \\sigma σ 随对话轮次递减,平衡探索与利用。
- 权重更新基于专家模型反馈,误诊症状权重降低30%。
- 针对\"舌诊数据映射\"的拆解:
- CNN分类标签(如“湿热质”)与知识图谱节点(如“湿热证”)建立映射关系。
- 冲突校验:当舌诊与症状矛盾时,触发专家模型复核。
第2轮聚焦提问:
- 如何设计高斯噪声扰动的具体参数?
- 舌诊分类标签如何与知识图谱节点精确对齐?
- 冲突校验机制如何避免误诊?
【解】深度思考
基础解答:
- 如何设计高斯噪声扰动的具体参数?
- 初始标准差(\\sigma=0.5),每轮递减(公式:(\\sigma_t = \\sigma_0 \\times e^{-0.1t}))。
- 舌诊分类标签如何与知识图谱节点精确对齐?
- 建立映射表:CNN输出标签→知识图谱节点(如“裂纹舌→阴虚证”)。
- 模糊匹配:无直接对应节点时,匹配最接近父节点(如“淡紫舌→血瘀证”)。
- 冲突校验机制如何避免误诊?
- 当症状与舌诊矛盾(如“舌淡”与“脉数”),触发专家模型复核并动态调整权重。
解答信息挖掘:
- 关键发现:模糊匹配机制提高了舌诊数据利用率。
- 新疑问:动态权重更新是否可能导致知识固化?
- 模糊点:专家模型复核的触发条件需进一步明确。
- 不同解答之间的关联:高斯噪声扰动与模糊匹配共同增强了系统的鲁棒性。
第2轮思考成果:
- 新发现:模糊匹配机制解决了舌诊标签与知识图谱节点不完全对齐的问题。
- 新疑问:动态权重更新是否可能引入偏差?
- 新方向:优化专家模型复核的触发条件。
第三轮循环:核心问题评估
当前状况:
从第2轮的新疑问和发现出发,进一步拆解动态权重更新的潜在偏差与专家模型复核的触发条件。
深层拆解:
- 针对\"动态权重更新偏差\"的拆解:
- 更新幅度约束:单次调整幅度≤20%,避免过大幅波动。
- 异常检测:权重变化超过2倍标准差时,触发专家模型复核。
- 针对\"专家模型复核触发条件\"的拆解:
- 症状权重差异≥30%时触发复核。
- 冲突优先级:舌诊数据优先级高于普通症状。
第3轮聚焦提问:
- 动态权重更新如何避免偏差?
- 专家模型复核的触发条件是否过于宽松或严格?
【解】深度思考
基础解答:
- 动态权重更新如何避免偏差?
- 引入异常检测机制,权重变化超过2倍标准差时触发复核。
- 设计自适应阈值:根据对话轮次动态调整更新幅度。
- 专家模型复核的触发条件是否过于宽松或严格?
- 当前设置(权重差异≥30%)适中,既避免频繁复核,又防止误诊。
- 定期注入专家标注数据,优化触发条件。
解答信息挖掘:
- 关键发现:异常检测机制有效降低了动态权重更新的偏差风险。
- 新疑问:专家标注数据如何持续更新?
- 模糊点:触发条件的动态调整需长期验证。
第3轮思考成果:
- 新发现:异常检测机制提升了动态权重更新的稳定性。
- 新疑问:专家标注数据的更新频率如何确定?
- 新方向:设计在线学习框架,持续优化触发条件。
总结与解决方案
通过三轮拆解式循环提问,我们逐步明确了以下内容:
-
核心解法:
- 子解法1:知识图谱动态权重调整(因为症状与疾病关联的动态性)。
- 子解法2:多模态优先级调度(因为舌诊数据的客观性高于主观症状)。
- 子解法3:双模型协作架构(因为任务冲突需要分工解决)。
-
逻辑链结构:
- 主链:症状提取→权重调整→追问生成→多模态融合→诊断决策。
- 分支:异常检测→专家模型复核→权重更新。
权重调整直接影响指导模型生成追问问题的优先级。例如,如果“舌红苔黄”的权重较高,系统会优先询问与“湿热证”相关的其他症状(如“是否有口苦?”)
-
隐性方法:
- 高斯噪声扰动与异常检测机制(防止陷入思维僵化,看到xx症状,就匹配yy疾病,但忽略微小症状导致误诊)。
- 模糊匹配机制(舌诊标签与知识图谱节点对齐)。
-
隐性特征:
- 症状与环境关联边(如“舌红”与光照强度)。
- 对话轮次敏感性(权重更新随轮次递减)。
-
潜在局限性:
- 数据依赖风险:舌诊CNN依赖高质量标注数据。
- 知识更新延迟:知识图谱更新仅在对话结束后执行。
- 计算成本:双模型架构增加推理延迟。
结论:
双模型协作与知识图谱动态优化通过“拆-解-拆-解”的循环推理,实现了主动追问与精准诊断的闭环。
2.1.2 协作流程
患者输入 → 指导模型解析症状 → 知识图谱匹配 → 生成追问问题 → 更新症状记录 → 专家模型诊断2.2 知识图谱动态优化
2.2.1 权重调整算法
- 初始权重:基于症状-疾病共现频率(公式: ( w i j= 共现次数 疾病总样本数 ) ( w_{ij} = \\frac{\\text{共现次数}}{\\text{疾病总样本数}}) (wij=疾病总样本数共现次数))。
- 动态更新:
- 高斯噪声扰动:每轮对话叠加 ( ϵ ∼ N ( 0 , σ 2 ) ) ( \\epsilon \\sim N(0, \\sigma^2) ) (ϵ∼N(0,σ2)),防止权重固化 ( σ ) ( \\sigma) (σ) 随对话轮次递减)。
- 后向修正:误诊症状权重降低30%,通过专家模型反馈更新。
2.2.2 多模态融合
- 舌诊CNN分类:ResNet-50提取舌象特征,输出体质类型(如“湿热质”)。
- 权重映射:体质类型与症状权重关联(如“湿热质”增强“舌红苔黄”权重至0.3)。
3. 关键技术验证与结果
3.1 实验设计
- 数据集:2,000+模拟医患对话(基于经典中医文献生成)。
- 对比基线:Qwen2.5、ChatGPT-4o、BianQue等6个模型。
3.2 核心指标表现
超过 其他大模型 太多!
3.3 核心发现
- 主动追问价值:Q&A Ratio每提升1点,准确率增加2.7%(p<0.01)。
- 多模态增益:舌诊数据加入使“湿热证”诊断准确率提升19%。
- 知识图谱鲁棒性:动态权重机制减少误诊案例达42%。
4. 创新方法论:拆解式循环提问的AI实现
4.1 全流程准确率提升机制总结
-
症状提取阶段
- 指导模型解析患者输入,对齐到知识图谱标准症状节点。
- 示例:患者描述“口干” → 映射为“口燥咽干(肝火炽盛)”。
-
动态权重调整阶段
- 根据当前症状与疾病关联度,计算症状权重(公式:Score(j) = Σw_ji * S_i)。
- 叠加高斯噪声并约束波动阈值,防止过拟合。
-
多模态融合阶段
- 舌诊CNN输出体质分类,映射到知识图谱症状节点。
- 融合症状向量与舌诊结果,生成综合输入向量。
-
诊断决策阶段
- 专家模型通过注意力机制计算疾病概率(P(D_i) = softmax(症状向量·疾病向量))。
- 当相似度≥阈值(如0.85)时输出诊断,否则继续追问。
-
知识更新阶段
- 诊断结束后,根据结果更新知识图谱边权(如误诊症状权重降低30%)。
- 定期注入专家标注数据,优化CNN分类与对齐机制。
5So 分析:为什么是用余弦相似度做疾病匹配
1. 描述表面现象
具体观察到的问题:
在DoPI系统中,知识图谱通过余弦相似度公式((\\text{Cosine Similarity} = \\frac{\\text{Symptom Vector} \\cdot \\text{Disease Vector}}{|\\text{Symptom Vector}| |\\text{Disease Vector}|}))来计算症状与疾病之间的关联度,并基于此进行疾病匹配。问题是:为什么选择余弦相似度作为匹配的核心方法?
2. 第一层分析
直接原因:
余弦相似度能够有效量化症状向量与疾病向量之间的相似性,从而帮助系统快速找到最可能的疾病候选。
- 解释: 余弦相似度是一种衡量两个向量方向一致性的方法,它不依赖于向量的绝对大小,而是关注它们的方向夹角。在医疗场景中,症状和疾病的特征可以被表示为高维向量,余弦相似度能有效捕捉这些特征之间的相关性,而忽略无关因素(如症状描述的冗余信息)。
- 佐证: 在论文中提到,余弦相似度用于计算患者症状向量 (P) 和疾病向量 (D_i) 的关联度,结果直接决定了疾病的优先级排序。
3. 第二层分析
为什么会出现上述原因?
因为症状和疾病的特征本质上是多维空间中的点,且需要一种标准化的方法来比较它们的相关性。
- 解释: 医疗诊断涉及大量症状和疾病的关系,这些关系通常以知识图谱的形式存储。每个症状和疾病都可以被建模为一个高维向量,其中每一维代表某种特征(如“舌红”对应湿热证的可能性)。由于症状和疾病的数量庞大,传统的基于规则的方法难以高效处理这种复杂关系。因此,需要一种数学工具来简化比较过程。
- 佐证: 论文中明确指出,知识图谱的边权重(症状与疾病之间的关联强度)是通过数据集频率初始化的,但最终的匹配需要动态计算,余弦相似度提供了一种灵活的解决方案。
4. 第三层分析
为什么需要一种数学工具来简化比较过程?
因为传统中医的知识体系复杂且非线性,症状与疾病之间的关系往往不是简单的“一对一”映射,而是多对多的复杂网络。
- 解释: 中医诊断依赖于大量的模糊信息(如“舌苔黄厚”可能对应多种疾病),且不同症状对疾病的贡献权重不同。例如,“舌红”可能与“湿热证”相关,但也可能与其他疾病相关。为了在多轮对话中动态调整权重并生成追问问题,系统需要一种方法来实时评估症状与疾病的匹配程度。
- 佐证: 论文提到,知识图谱中的边权重会随着对话轮次动态更新(如引入高斯噪声扰动机制),这表明匹配过程需要灵活性和动态性。
5. 第四层分析
为什么中医诊断需要如此复杂的匹配机制?
因为中医诊断强调整体性和个性化,患者的症状往往是多维度、模糊且主观的,单一的症状不足以确诊,需要综合多个症状的信息。
- 解释: 中医诊断不同于西医的精准化检测(如血液指标或影像学检查),更多依赖于医生的经验和患者提供的主观描述。例如,患者的“口苦”可能是湿热证的表现,但也可能是其他体质问题的结果。为了提高诊断准确性,系统需要从多轮对话中逐步提取关键症状,并结合知识图谱进行综合判断。
- 佐证: 论文中提到,系统设计了一个多轮对话机制,通过不断追问患者未提及的症状(如“舌头是否有裂纹?”),逐步缩小疾病范围。这一过程需要一个可靠的匹配算法,而余弦相似度正是为此设计的。
6. 第五层分析
根本原因是什么?
根本原因是中医知识体系的复杂性和诊断过程的动态性,要求系统具备强大的知识表示能力和推理能力,以适应多轮对话中的信息增量式获取和动态权重调整需求。
- 解释: 中医诊断不仅依赖于静态知识(如症状与疾病的关系),还需要考虑动态因素(如患者的主观描述、环境干扰等)。例如,患者可能误报“舌淡”,但舌诊图像显示“舌红苔黄”。在这种情况下,系统需要结合多模态数据(如舌象分类结果)和知识图谱进行推理。余弦相似度作为一种标准化的匹配方法,能够适应这种复杂性,同时保持计算效率。
- 佐证: 论文中提到,系统通过高斯噪声扰动机制和异常检测机制,确保了动态权重调整的鲁棒性。这表明,系统的设计目标是应对中医诊断中的不确定性和复杂性。
总结:根本原因
中医诊断的复杂性、动态性和多模态特点,决定了需要一种能够高效量化症状与疾病关联度的方法,而余弦相似度因其灵活性、标准化和计算效率,成为最优选择。
可能的解决方案
-
优化余弦相似度公式:
- 引入更多的上下文信息(如环境变量、患者历史数据)来调整相似度计算。
- 使用加权余弦相似度,赋予不同特征不同的权重(如舌象数据优先级更高)。
-
增强知识图谱的动态性:
- 引入在线学习机制,根据新数据实时更新知识图谱的边权重。
- 结合专家标注数据,定期校正知识图谱中的错误关联。
-
多模态融合优化:
- 将舌诊CNN分类结果更紧密地整合到知识图谱中,提升匹配精度。
- 设计更复杂的多模态融合算法(如注意力机制)来平衡不同数据源的贡献。
通过以上改进,可以进一步提升系统的诊断准确性和鲁棒性。
5. 应用价值与未来方向
5.1 当前价值
- 临床辅助:降低中医师重复性工作,提升诊断一致性。
- 教育工具:通过追问逻辑训练医学生辨证思维。
5.2 未来优化方向
- 多模态扩展:集成脉诊传感器数据,完善“四诊合参”。
- 知识更新机制:设计EWC算法防止知识遗忘。
- 轻量化部署:边缘计算优化(TensorFlow Lite延迟<200ms)。
6. 结论
DoPI系统通过双模型协作+动态知识图谱,成功解决了中医AI的主动追问与多模态融合难题。
其84.68%的诊断准确率与21.31的Q&A Ratio验证了技术路径的有效性,为中医智能化提供了可复用的方法论框架。
下一步将聚焦多模态数据扩展与边缘部署,推动系统临床落地。


