DPO与PPO:强化学习优化算法通俗解析
DPO(DirectPreferenceOptimization)
是一种直接优化偏好数据的强化学习算法,主要用于语言模型微调。以下是其核心流程。
特点
监督微调过程
没有策略采样,没有强化学习交互过程
针对这个问题,计算模型生成优选和劣选答案的概率(生成隐式奖励)
数据准备
收集偏好数据集D={(x,yw,yl)},其中x是输入,yw是优选回答,yl是劣选回答。
模型初始化
使用预训练语言模型πref作为参考模型,初始化待优化策略πθ。
损失函数设计
目标是最小化以下损失函数:
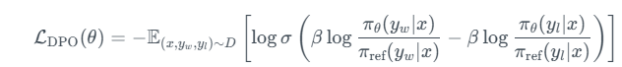
![]()
- 优化过程:
- 通过梯度下降更新πθ,无需显式奖励模型或强化学习循环。
- 直接利用偏好数据调整策略模型输出概率的比值。
- 输出结果:
- 最终得到优化后的策略模型πθ,其生成结果更符合人类偏好。
PPO(ProximalPolicyOptimization)
特点
是RLHF中用于策略优化的核心算法
通过概率比裁剪避免破坏性的大幅度更新
以下是PPO算法单轮迭代中轨迹数据处理与函数计算的完整逻辑流程说明,严格按实际计算顺序展开。
---
1.轨迹数据收集
环境交互
当前策略π_θ控制智能体在环境中执行动作,产生原始数据流
记录字段
-`s_t`:当前状态(环境返回)
-`a_t`:执行动作(策略网络采样结果)
-`r_t`:即时奖励(环境反馈)
-`s_{t+1}`:下一状态(环境返回)
-`done`:终止标志(环境反馈)
-`log_prob`:动作对数概率(策略网络输出)
-`value`:状态价值估计(价值网络输出)
可以理解为:
- 状态(st):当前已生成的token序列(上下文)
- 动作(at):策略模型πθ输出的下一个token(从词表采样)
- 奖励(rt):完整序列生成后由奖励模型计算(非逐token)
- 状态转移:将at追加到st构成st+1
关键特性
-必须完整收集一个episode的连续轨迹
-数据仅来自当前策略(on-policy特性)
示例:原始1000条问答数据会1:1对应生成1000条轨迹数据。每条轨迹包含:
- 状态(问题文本)
- 动作(模型生成的答案)
- 奖励(人工或自动评分)
- 优势估计(通过回报计算得出)
- 旧策略的动作概率(log_probs_old)
轨迹数据示例
标准RL设定(如游戏控制):
-
- 每个动作a_t都对应即时环境反馈r_t
- 轨迹数据:(s0,a0,r0,s1,a1,r1,...)(s0,a0,r0,s1,a1,r1,...)
NLP适配设定(RLHF典型实现):
-
- 仅在序列终止时获得延迟奖励R(由奖励模型计算)
- 轨迹数据形式:(s0,a0,0,s1,a1,0,...,sT,R)(s0,a0,0,s1,a1,0,...,sT,R)
- 实现时需要将最终奖励R分配给所有时间步(通过折扣因子γ调节)
2.优势函数计算
输入数据
-轨迹中的`rewards`序列、`values`序列、`dones`序列
- V(s_t)来自旧价值网络的前向推理
- δ_t的计算需要r_t、V(s_t)、V(s_{t+1})三者的对齐
计算阶段
1.TD残差(δ_t)
-公式:`δ_t=r_t+γ*V(s_{t+1})*(1-done)-V(s_t)`
-物理意义:当前步的即时奖励与价值预测误差
-数据依赖:
-`V(s_t)`:旧价值网络对当前状态的估值
-`V(s_{t+1})`:旧价值网络对下一状态的估值
2.GAE优势(A_t)
-公式:`A_t=Σ(γλ)^lδ_{t+l}`(从t时刻向后加权求和)
-作用:平衡偏差与方差,λ=0时退化为TD误差
-计算方向:必须从轨迹末端向前逆向计算
---
3.策略函数更新
输入数据
-旧动作概率`log_probs_old`(轨迹记录值)
-新动作概率`log_probs_new`(当前策略网络重计算值)
-优势值`A_t`(上一步计算结果)
核心计算
1.概率比(r_t)
-公式:`r_t=exp(log_probs_new-log_probs_old)`
-作用:量化新旧策略差异
2.裁剪损失
-公式:`L=-min(r_t*A_t,clip(r_t,1±ε)*A_t)`
-关键参数:ε通常取0.1~0.3,强制限制策略更新幅度
---
4.价值函数更新
输入数据
-优势值`A_t`(已计算)
-旧价值估计`V(s_t)`(轨迹记录值)
计算流程
目标回报(R_t)
R_t作为Q(s_t,a_t)的无偏估计
-公式:`R_t=A_t+V(s_t)`
-物理意义:优势函数修正后的实际回报估计

价值损失
-公式:`L=(R_t-V_new(s_t))^2`
-优化目标:使价值网络预测逼近修正后的回报
5.联合优化
总损失函数
-总损失=策略损失+c1×价值损失-c2×策略熵
-熵项`H(π)`:策略网络输出动作分布的熵(自动计算)
更新逻辑
-对同一批轨迹数据执行K次小批量更新
-每次更新前需重新计算`log_probs_new`(因策略网络参数变化)
PPO的K次更新是单批数据下的策略精炼,而非重新生成数据的epoch循环
基于1000条原始问答数据的PPO训练过程总结
1.初始化阶段
-加载固定的1000个问题作为状态集
-使用初始策略为每个问题生成第一个答案(动作)
-计算每个问答对的奖励值和优势估计
-记录初始策略生成这些答案的动作概率
2.策略优化循环
-进行K次策略更新迭代(通常3-10次):
a.用当前策略重新计算这1000个答案的生成概率
b.计算新旧策略的概率比
c.应用PPO裁剪机制限制更新幅度
d.结合优势估计计算策略梯度
e.执行梯度下降更新策略参数
3.数据刷新阶段
-用更新后的策略重新为1000个问题生成新答案
-评估新答案的奖励和优势
-选择保留机制(完全替换或混合新旧答案)
4.重复训练
-回到步骤2继续优化
-持续迭代直至模型性能收敛
整个过程通过\"固定问题+动态答案\"的机制,在有限数据上实现高效策略优化。
共执行n次数据刷新,每次刷新后利用相同数据执行k次更新,总更新次数为n×k。
n_epochs=5#数据刷新次数
k_updates=3#每次刷新的更新次数
for_i in range(n_epochs):
#1.数据收集(刷新)
trajectories=collect_data(policy)
#2.使用相同数据执行k次更新
for_i in range(k_updates):
loss=compute_ppo_loss(trajectories)
optimizer.step(loss)
总结
DPO(Direct Preference Optimization)是一种直接基于偏好数据优化语言模型的算法,其核心流程包括:收集带偏好的问答数据集,初始化参考模型,通过概率比值计算隐式奖励,并直接优化策略模型。相比传统RLHF方法,DPO省去了强化学习交互和奖励模型训练环节。PPO(Proximal Policy Optimization)则是RLHF中的核心优化算法,通过概率比裁剪控制更新幅度。其完整流程包含:轨迹数据收集、优势函数计算、策略更新和价值函数更新等步骤,采用\"固定问题+动态答案\"机制实现高效策略优化。两种算法各具优势,为语言模型对齐人类偏好提供了不同解决方案。
宣传结语
在数字化转型的大潮中,小程序、人工智能和CRM系统正成为企业提升竞争力的关键利器。我们工作室专注于这些领域,为中小企业提供定制化的技术解决方案,助力业务升级与创新。
我们的核心服务包括:
-
小程序开发:提供微信等平台的小程序定制开发,让用户无需下载安装即可使用您的服务。
-
人工智能智能体:开发基于AI的智能系统(如智能客服、业务自动化助手),提升业务自动化能力和用户体验。
-
CRM客户管理系统开发:搭建高效可靠的CRM系统,实现客户数据的集中管理与深入分析,助力精细化运营。
我们的团队经验丰富,注重代码质量和系统稳定性,曾为多个行业提供数字化解决方案。在每一个项目中,我们都以专业严谨的态度确保按时、高质量交付。
如果您正寻求数字化转型的技术支持,请随时联系我。
电话:13047605699
邮箱:1768225144@qq.com
我们将竭诚为您提供最适合的技术方案,期待与您合作!

