用Python爬取百度图片:手把手教你写一个图片爬虫
- 💂 网站推荐:【 摸鱼游戏】【神级代码资源网站】【星海网址导航】
前言
最近想收集一些特定主题的图片素材,手动一张张下载实在太费时间了。作为一个懒人程序员,我决定写个爬虫来自动完成这个任务。今天就跟大家分享这个实用的百度图片爬虫,它能自动搜索并下载你想要的任何图片。
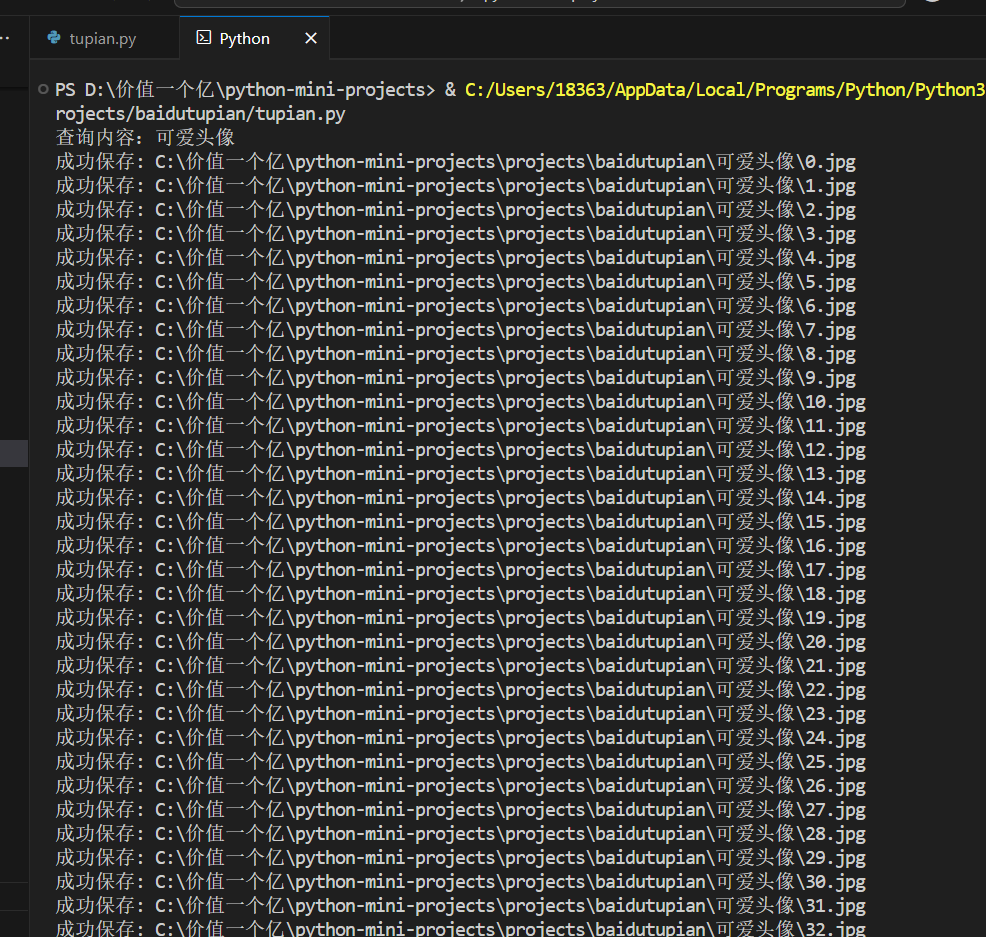
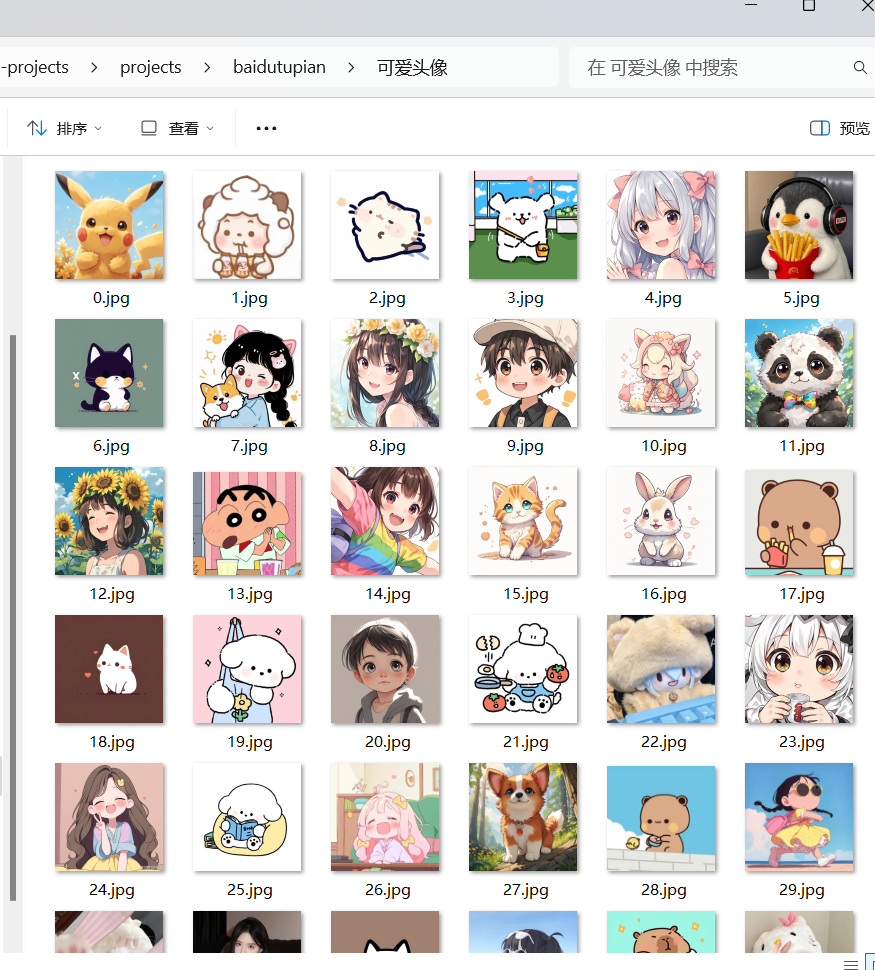
这个爬虫虽然只有100多行代码,但包含了请求处理、JSON解析、文件操作等实用技巧。我会详细解释每个部分的实现思路,让你不仅能使用这个爬虫,还能真正理解它的工作原理。
爬虫整体设计
我们先来看看这个爬虫的总体结构:
class BaiduImageSpider(object): def __init__(self): # 初始化代码 def create_directory(self, name): # 创建保存图片的文件夹 def get_image_link(self, url): # 获取图片链接 def save_image(self, img_link, filename): # 下载并保存图片 def run(self): # 主运行逻辑这个类包含了爬虫的所有功能,结构清晰,每个方法负责一个具体的任务。接下来我会详细讲解每个部分的实现。
初始化设置
def __init__(self): self.json_count = 0 self.url = \'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&queryWord={}&word={}&pn={}&rn=30\' self.directory = r\"C:\\价值一个亿\\python-mini-projects\\projects\\baidutupian\\{}\" self.header = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36\', \'Accept-Language\': \'en-US,en;q=0.5\', \'Referer\': \'https://image.baidu.com\' } self.image_counter = 0 # 新增全局图片计数器初始化方法中,我们设置了几个重要的变量:
json_count:控制要下载多少组图片(每组30张)url:百度图片的API接口地址,使用格式化字符串方便后续替换关键词directory:图片保存路径,使用{}作为占位符方便后续替换header:请求头,模拟浏览器访问,避免被反爬image_counter:图片计数器,用于生成唯一的文件名
创建保存目录
def create_directory(self, name): self.directory = self.directory.format(name) os.makedirs(self.directory, exist_ok=True) self.directory += r\'\\{}\'这个方法负责创建保存图片的文件夹:
- 使用
format方法将搜索关键词插入到路径中 os.makedirs创建目录,exist_ok=True表示如果目录已存在也不报错- 最后在路径后添加
\\{},方便后续格式化文件名
获取图片链接
def get_image_link(self, url): try: response = requests.get( url, headers=self.header, proxies={\"http\": None, \"https\": None}, timeout=10 ) response.raise_for_status() return [item[\'thumbURL\'] for item in response.json().get(\'data\', []) if \'thumbURL\' in item] except Exception as e: print(f\"获取图片链接失败: {e}\") return []这是爬虫的核心方法之一,负责从百度API获取图片链接:
- 使用
requests.get发送HTTP请求 - 设置了请求头和代理(这里禁用了代理)
- 添加了10秒超时设置
raise_for_status()会在请求失败时抛出异常- 使用列表推导式从返回的JSON中提取所有
thumbURL字段 - 添加了异常处理,失败时打印错误信息并返回空列表
下载并保存图片
def save_image(self, img_link, filename): try: res = requests.get( img_link, headers=self.header, proxies={\"http\": None, \"https\": None}, timeout=10 ) res.raise_for_status() with open(filename, \"wb\") as f: f.write(res.content) print(f\"成功保存: {filename}\") except Exception as e: print(f\"下载图片失败: {e}\")这个方法负责下载并保存图片:
- 同样使用
requests.get获取图片内容 - 以二进制写入模式(
wb)打开文件 - 直接将响应内容写入文件
- 添加了异常处理,下载失败时打印错误信息
主运行逻辑
def run(self): searchName = input(\"查询内容:\") searchName_parse = parse.quote(searchName) self.create_directory(searchName) self.image_counter = 0 # 重置计数器 for index in range(self.json_count): pn = index * 30 request_url = self.url.format(searchName_parse, searchName_parse, str(pn)) links = self.get_image_link(request_url) for link in links: filename = os.path.join(self.directory.format(f\"{self.image_counter}.jpg\")) # 使用全局计数器 self.save_image(link, filename) self.image_counter += 1 # 计数器递增 time.sleep(1) print(f\"{searchName}----图像下载完成--------->\")这是爬虫的主控制流程:
- 获取用户输入的搜索关键词
- 对关键词进行URL编码
- 创建保存目录
- 重置图片计数器
- 循环获取多组图片(每组30张)
- 构建请求URL,
pn参数控制分页 - 获取图片链接列表
- 逐个下载图片,文件名使用递增的数字
- 每次下载后暂停1秒,避免请求过于频繁
- 完成后打印提示信息
扩展思路
这个基础爬虫还可以进一步扩展:
-
支持更多搜索引擎:除了百度,还可以添加谷歌、必应等图片搜索的支持
-
图片筛选:根据大小、格式、颜色等条件筛选图片
-
去重功能:使用哈希值检查避免下载重复图片
-
断点续传:记录已下载的图片,程序中断后可以从中断处继续
-
GUI界面:使用PyQt或Tkinter添加图形界面,更方便非技术人员使用
完整代码
import requestsimport jsonfrom urllib import parseimport osimport timeclass BaiduImageSpider(object): def __init__(self): self.json_count = 0 self.url = \'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&queryWord={}&word={}&pn={}&rn=30\' self.directory = r\"C:\\价值一个亿\\python-mini-projects\\projects\\baidutupian\\{}\" self.header = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36\', \'Accept-Language\': \'en-US,en;q=0.5\', \'Referer\': \'https://image.baidu.com\' } self.image_counter = 0 # 新增全局图片计数器 def create_directory(self, name): self.directory = self.directory.format(name) os.makedirs(self.directory, exist_ok=True) self.directory += r\'\\{}\' def get_image_link(self, url): try: response = requests.get( url, headers=self.header, proxies={\"http\": None, \"https\": None}, timeout=10 ) response.raise_for_status() return [item[\'thumbURL\'] for item in response.json().get(\'data\', []) if \'thumbURL\' in item] except Exception as e: print(f\"获取图片链接失败: {e}\") return [] def save_image(self, img_link, filename): try: res = requests.get( img_link, headers=self.header, proxies={\"http\": None, \"https\": None}, timeout=10 ) res.raise_for_status() with open(filename, \"wb\") as f: f.write(res.content) print(f\"成功保存: {filename}\") except Exception as e: print(f\"下载图片失败: {e}\") def run(self): searchName = input(\"查询内容:\") searchName_parse = parse.quote(searchName) self.create_directory(searchName) self.image_counter = 0 # 重置计数器 for index in range(self.json_count): pn = index * 30 request_url = self.url.format(searchName_parse, searchName_parse, str(pn)) links = self.get_image_link(request_url) for link in links: filename = os.path.join(self.directory.format(f\"{self.image_counter}.jpg\")) # 使用全局计数器 self.save_image(link, filename) self.image_counter += 1 # 计数器递增 time.sleep(1) print(f\"{searchName}----图像下载完成--------->\")if __name__ == \'__main__\': spider = BaiduImageSpider() spider.json_count = 10 # 下载10组图片 spider.run()使用说明
-
安装依赖:
pip install requests -
运行方式:
- 直接运行:
tupian.py - 或者导入使用:
- 直接运行:
if __name__ == \'__main__\': spider = BaiduImageSpider() spider.json_count = 10 # 下载10组图片 spider.run()- 创建爬虫实例
- 设置
json_count决定下载多少组图片(每组30张) - 调用
run()方法开始爬取
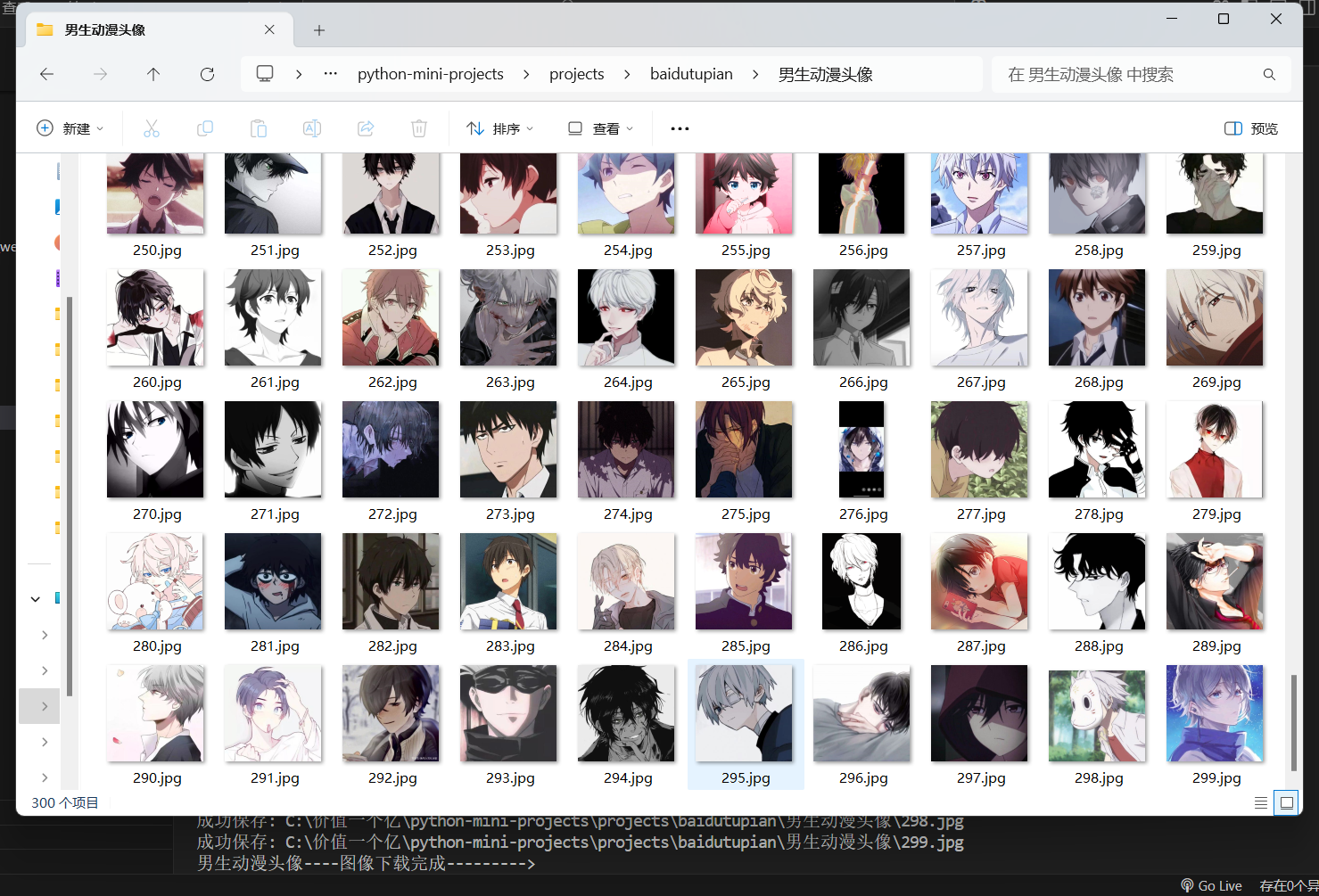
运行后会提示输入搜索关键词,然后就会自动下载图片到指定目录。
高级技巧
-
代理设置:如果需要使用代理,可以修改请求方法:
proxies = { \'http\': \'http://your.proxy:port\', \'https\': \'http://your.proxy:port\'}response = requests.get(url, headers=self.header, proxies=proxies) -
多线程下载:可以使用
concurrent.futures实现:from concurrent.futures import ThreadPoolExecutorwith ThreadPoolExecutor(max_workers=5) as executor: executor.map(self.save_image, links) -
断点续传:记录已下载的URL,程序重启后跳过已下载的图片。
注意事项
- 请遵守百度的robots.txt协议,合理控制请求频率
- 不要用于商业用途,尊重图片版权
- 建议设置合理的
json_count值,避免请求过多被封IP - 下载失败时,程序会自动重试,但大量失败可能是触发了反爬机制
这个改进版的百度图片爬虫具有更好的稳定性、更详细的日志输出和更友好的使用体验。你可以根据自己的需求进一步扩展功能,比如添加图片去重、自动分类等功能。


