【全网最详细!十万字解析】黑马SpringAI+Deepseek大模型应用开发实战笔记-下半(进阶+详细+完整代码)_黑马程序员chatpdf
上半部分连接
https://blog.csdn.net/2201_75669520/article/details/148834250?spm=1001.2014.3001.5502
最新消息,Redis向量库的问题解决了,重新加载下项目,或者清空下缓存,重新关闭启动下Redis,把这些步骤走一走,就奇妙的解决了,最后也是成功的可以访问向量库当中的数据进行检索了
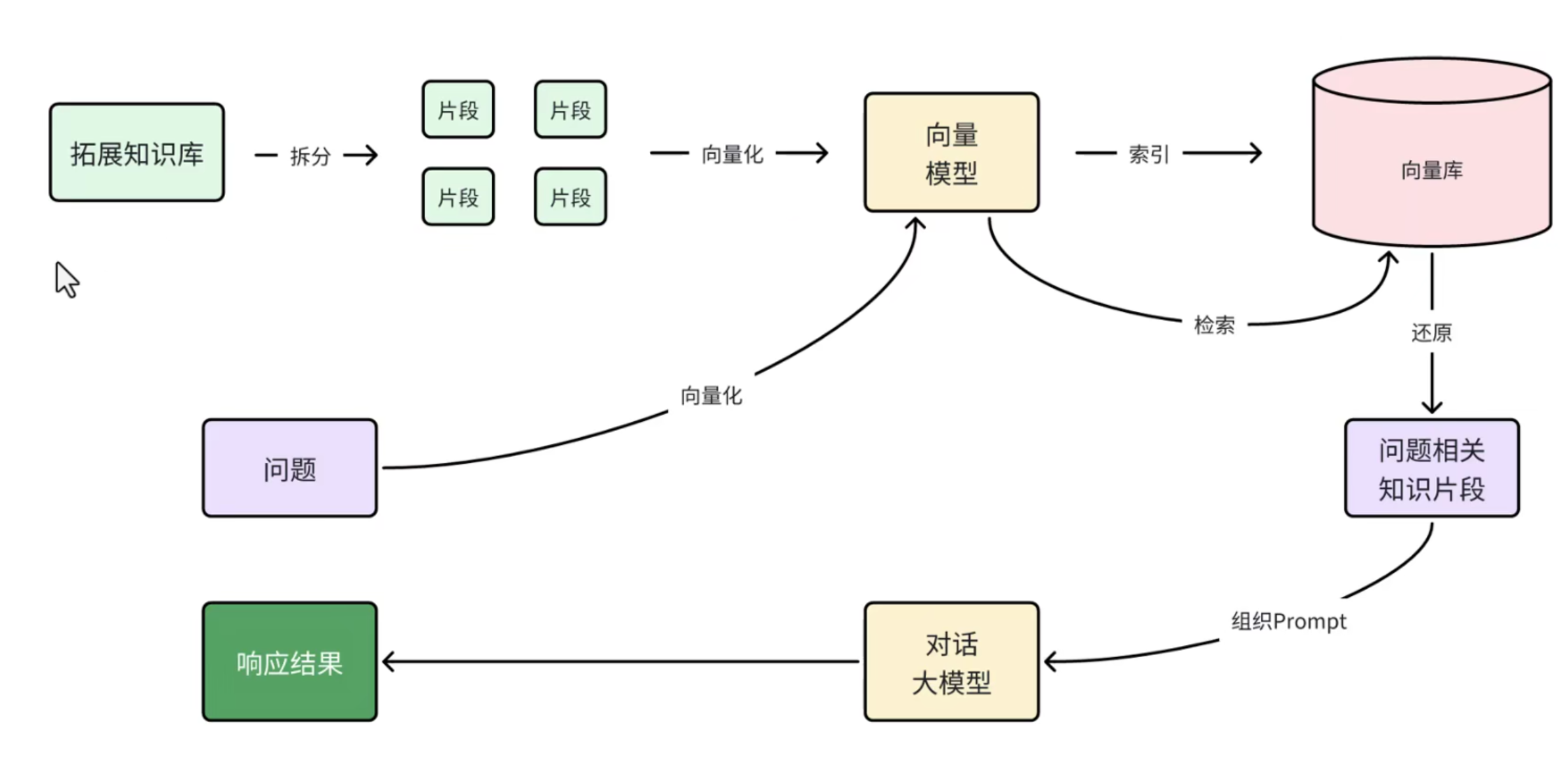
4.1.5 RAG原理总结
OK,现在我们有了这些工具:
- PDFReader:读取文档并拆分为片段
- 向量大模型:将文本片段向量化
- 向量数据库:存储向量,检索向量
让我们梳理一下要解决的问题和解决思路:
- 要解决大模型的知识限制问题,需要外挂知识库
- 受到大模型上下文限制,知识库不能简单的直接拼接在提示词中
- 我们需要从庞大的知识库中找到与用户问题相关的一小部分,再组装成提示词
- 这些可以利用文档读取器、向量大模型、向量数据库来解决。
所以RAG要做的事情就是将知识库分割,然后利用向量模型做向量化,存入向量数据库,然后查询的时候去检索:
第一阶段(存储知识库):
- 将知识库内容切片,分为一个个片段
- 将每个片段利用向量模型向量化
- 将所有向量化后的片段写入向量数据库
第二阶段(检索知识库):
- 每当用户询问AI时,将用户问题向量化
- 拿着问题向量去向量数据库检索最相关的片段
第三阶段(对话大模型):
- 将检索到的片段、用户的问题一起拼接为提示词
- 发送提示词给大模型,得到响应
4.2 PDF上传、下载、向量化
既然是ChatPDF,也就是说所有知识库都是PDF形式的,由用户提交给我们。所以,我们需要先实现一个上传PDF的接口,在接口中实现下列功能:
- 校验文件格式是否为PDF
- 保存文件信息
- 保存文件(可以是oss或本地保存)
- 保存会话ID和文件路径的映射关系(方便查询会话历史的时候再次读取文件)
- 文档拆分和向量化(文档太大,需要拆分为一个个片段,分别向量化)
另外,将来用户查询会话历史,我们还需要返回pdf文件给前端用于预览,所以需要实现一个下载PDF接口,包含下面功能:
- 读取文件
- 返回文件给前端
4.2.1 PDF文件管理
由于将来要实现PDF下载功能,我们需要记住每一个chatId对应的PDF文件名称。
所以,我们定义一个类,记录chatId与pdf文件的映射关系,同时实现基本的文件保存功能。
现在Repository包下定义一个FileRepository接口
package com.hfut.ai.repository;import org.springframework.core.io.Resource;public interface FileRepository { /** * 保存文件,还要记录chatId与文件的映射关系 * @param chatId 会话id * @param resource 文件 * @return 上传成功,返回true; 否则返回false */ boolean save(String chatId, Resource resource); /** * 根据chatId获取文件 * @param chatId 会话id * @return 找到的文件 */ Resource getFile(String chatId);}再写一个实现类:LocalPdfFileRepository
这里要注意一下,原教程是通过Properties进行chatid和pdf文件名之间映射关系,以及向量库的持久化
我这里进阶了一下,通过mysql数据库保存映射关系,通过Redis向量库保存向量数据
数据库表设计
CREATE TABLE chat_file_mapping ( id BIGINT AUTO_INCREMENT PRIMARY KEY, chat_id VARCHAR(255) NOT NULL, file_name VARCHAR(255) NOT NULL, UNIQUE (chat_id));PO类
package com.hfut.ai.entity.po;import com.baomidou.mybatisplus.annotation.TableName;import com.baomidou.mybatisplus.annotation.IdType;import com.baomidou.mybatisplus.annotation.TableId;import java.io.Serializable;import lombok.Data;import lombok.EqualsAndHashCode;import lombok.experimental.Accessors;/** * * *
* * @author GM * @since 2025-06-23 */@Data@EqualsAndHashCode(callSuper = false)@Accessors(chain = true)@TableName(\"chat_file_mapping\")public class ChatFileMapping implements Serializable { private static final long serialVersionUID = 1L; @TableId(value = \"id\", type = IdType.AUTO) private Long id; private String chatId; private String fileName;}LocalPdfFileRepository
package com.hfut.ai.repository;import com.hfut.ai.entity.po.ChatFileMapping;import com.hfut.ai.mapper.ChatFileMappingMapper;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.core.io.FileSystemResource;import org.springframework.core.io.Resource;import org.springframework.stereotype.Component;import java.io.*;import java.nio.file.Files;import java.util.Objects;@Slf4j@Component@RequiredArgsConstructorpublic class LocalPdfFileRepository implements FileRepository { private final ChatFileMappingMapper chatFileMappingMapper; @Override public boolean save(String chatId, Resource resource) { // 保存到本地磁盘 String filename = resource.getFilename(); File target = new File(Objects.requireNonNull(filename)); if (!target.exists()) { try { Files.copy(resource.getInputStream(), target.toPath()); } catch (IOException e) { log.error(\"Failed to save PDF resource.\", e); return false; } } // 保存映射关系到数据库 ChatFileMapping mapping = new ChatFileMapping(); mapping.setChatId(chatId); mapping.setFileName(filename); chatFileMappingMapper.insert(mapping); // 插入数据库 return true; } @Override public Resource getFile(String chatId) { // 使用 LambdaQueryWrapper 通过 chatId 字段查询 LambdaQueryWrapper queryWrapper = new LambdaQueryWrapper(); queryWrapper.eq(ChatFileMapping::getChatId, chatId); // 查询对应的映射记录 ChatFileMapping mapping = chatFileMappingMapper.selectOne(queryWrapper); if (mapping != null) { return new FileSystemResource(mapping.getFileName()); } return null; }}4.2.2 上传文件响应结果
前端严格设置了这个响应结果的格式,跟着教程走就行了
在vo包下新建个Result类就行
package com.hfut.ai.entity.vo;import lombok.Data;import lombok.NoArgsConstructor;@Data@NoArgsConstructorpublic class Result { private Integer ok; private String msg; private Result(Integer ok, String msg) { this.ok = ok; this.msg = msg; } public static Result ok() { return new Result(1, \"ok\"); } public static Result fail(String msg) { return new Result(0, msg); }}这个类用来规范我们的返回格式,相信写过项目或者公司业务的同学都不陌生
4.2.3 文件上传、下载(Controller)
这里没什么太多好说的,看代码吧
package com.hfut.ai.controller;import com.hfut.ai.entity.vo.Result;import com.hfut.ai.repository.FileRepository;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j;import org.springframework.ai.document.Document;import org.springframework.ai.reader.ExtractedTextFormatter;import org.springframework.ai.reader.pdf.PagePdfDocumentReader;import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.core.io.Resource;import org.springframework.http.MediaType;import org.springframework.http.ResponseEntity;import org.springframework.web.bind.annotation.*;import org.springframework.web.multipart.MultipartFile;import java.io.IOException;import java.net.URLEncoder;import java.nio.charset.StandardCharsets;import java.util.List;import java.util.Objects;@Slf4j@RequiredArgsConstructor@RestController@RequestMapping(\"/ai/pdf\")public class PdfController { private final FileRepository fileRepository; private final VectorStore vectorStore; /** * 文件上传 */ @RequestMapping(\"/upload/{chatId}\") public Result uploadPdf(@PathVariable String chatId, @RequestParam(\"file\") MultipartFile file) { try { // 1. 校验文件是否为PDF格式 if (!Objects.equals(file.getContentType(), \"application/pdf\")) { return Result.fail(\"只能上传PDF文件!\"); } // 2.保存文件 boolean success = fileRepository.save(chatId, file.getResource()); if(! success) { return Result.fail(\"保存文件失败!\"); } // 3.写入向量库 this.writeToVectorStore(file.getResource()); return Result.ok(); } catch (Exception e) { log.error(\"Failed to upload PDF.\", e); return Result.fail(\"上传文件失败!\"); } } /** * 文件下载 */ @GetMapping(\"/file/{chatId}\") public ResponseEntity download(@PathVariable(\"chatId\") String chatId) throws IOException { // 1.读取文件 Resource resource = fileRepository.getFile(chatId); if (!resource.exists()) { return ResponseEntity.notFound().build(); } // 2.文件名编码,写入响应头 String filename = URLEncoder.encode(Objects.requireNonNull(resource.getFilename()), StandardCharsets.UTF_8); // 3.返回文件 return ResponseEntity.ok() .contentType(MediaType.APPLICATION_OCTET_STREAM) .header(\"Content-Disposition\", \"attachment; filename=\\\"\" + filename + \"\\\"\") .body(resource); } private void writeToVectorStore(Resource resource) { // 1.创建PDF的读取器 PagePdfDocumentReader reader = new PagePdfDocumentReader( resource, // 文件源 PdfDocumentReaderConfig.builder() .withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()) .withPagesPerDocument(1) // 每1页PDF作为一个Document .build() ); // 2.读取PDF文档,拆分为Document List documents = reader.read(); // 3.写入向量库 vectorStore.add(documents); }}需要注意的就是下载的操作,但是这些都与RAG无关,本质上是文件IO的一些知识点,下面的AI交互才是重点
4.2.4 上传大小限制
配置一下SpringMVC的文件大小限制
修改application.yaml文件,添加配置:
spring: servlet: multipart: max-file-size: 104857600 max-request-size: 1048576004.2.5 暴露响应头
默认情况下跨域请求的响应头是不暴露的,这样前端就拿不到下载的文件名,我们需要修改CORS配置,暴露响应头:
@Overridepublic void addCorsMappings(CorsRegistry registry) { registry.addMapping(\"/**\") // 允许所有路径 .allowedOrigins(\"*\") // 允许所有域 .allowedMethods(\"GET\", \"POST\", \"PUT\", \"DELETE\", \"OPTIONS\", \"HEAD\") // 允许所有请求方法 .allowedHeaders(\"*\") // 允许所有请求头 .exposedHeaders(\"*\"); // 允许所有响应头}4.3 配置ChatClient
如果说上面的4.1-4.2都是在了解RAG的原理,和运用向量大模型去解析我们上传的PDF文件
那么下面就和前面三节的内容很相似了,也就是实现RAG的对话流程
我们要理解整个实现逻辑顺序:
-
用户在页面选择文件上传,文件会保存到项目的根目录下,同时会把chatId和文件名保存到mysql,再写入向量库
-
文件下载,指的是,通过chatId,去数据库获取文件名后,从本地输出返回到页面上
此时,才完成了第一步
-
后续,就是用户输入文本提问,然后把问题文本向量化,交给向量模型和向量库里面的片段进行检索
-
向量库返回问题相关的知识片段,然后交给对话大模型,对话大模型响应结果到页面
这一步其实也就是我们在测试当中进行的,只不过文本变成了用户输入的,然后返回结果由控制台返回变成了交给对话大模型
-
还有就是,对话大模型这一块,用户提的问题和大模型返回的结果,做一个持久化的处理,这一点第一节就学过了
流程图如下
这里需要注意,
理论上来说,我们每次与AI对话的完整流程是这样的:
- 将用户的问题利用向量大模型做向量化 OpenAiEmbeddingModel
- 去向量数据库检索相关的文档 VectorStore
- 拼接提示词,发送给大模型
- 解析响应结果
不过,SpringAI同样基于AOP技术帮我们完成了全部流程,用到的是一个名QuestionAnswerAdvisor的Advisor。我们只需要把VectorStore配置到Advisor即可。
简单来说就是,在Configuration当中配一下ChatClient就好了,然后持久化就是把Client里面的ChatMemory换成我们自己写的保存到mysql的Memory。
什么?你忘记什么是Client了?忘记什么是Memory了?说明没有认真看我之前写的笔记,罚回去重看(3.7存储到数据库再详谈)
/** * 配置pdf文件对话用ChatClient对象,用于处理用户输入的pdf文件,并返回处理结果 * @param model 使用OpenAI的模型 * @param inSqlChatMemory 通过数据库进行会话历史存储 * @param vectorStore 通过向量库进行相似度搜索 * @return */ @Bean public ChatClient pdfChatClient(OpenAiChatModel model, InSqlChatMemory inSqlChatMemory, VectorStore vectorStore) { return ChatClient .builder(model)// 选择模型 .defaultSystem(SystemConstants.PDF_SYSTEM_PROMPT)// 系统设置 .defaultAdvisors(new SimpleLoggerAdvisor())// 添加日志记录 .defaultAdvisors(MessageChatMemoryAdvisor.builder(inSqlChatMemory).build())// 添加会话记忆功能 .defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore).// 添加向量库 searchRequest(SearchRequest.builder().similarityThreshold(0.6).// 设置相似度阈值 topK(2).// 设置返回文档数量 build()).build()) .build(); }这里要注意几个问题,首先是添加QuestionAnswerAdvisor的Advisor,每个版本的设置是不一样的,需要去查阅官方文档
读文档是一个程序员必须具备的能力!!!
我这里对应的版本是SpringAI1.0.0正式版的配置写法
当然,如果你能力强也可以去看源码,底层都是用的工厂模式
除此之外,也可以不使用封装好的RAG的Advisor,自定义的方法可以去看官方文档
https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html
另外,要使用QuestionAnswerAdvisor的Advisor,还需要加入一个新的依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-advisors-vector-store</artifactId></dependency>4.4 对话接口
最后,就是对接前端,然后与大模型对话了。修改PdfController,添加一个接口:
private final ChatClient pdfChatClient; // pdf模型@Autowired@Qualifier(\"inSqlChatHistoryRepository\") // 使用数据库存储会话idprivate ChatHistoryRepository chatHistoryRepository;/** * pdf模型会话接口 * @param prompt * @param chatId * @return */@RequestMapping(value = \"/chat\", produces = \"text/html;charset=UTF-8\")public Flux chat(@RequestParam(\"prompt\") String prompt, @RequestParam(\"chatId\") String chatId) { // 从数据库当中通过chatId获取文件名字 Resource file = fileRepository.getFile(chatId); if (!file.exists()) { // 文件不存在,不回答 throw new RuntimeException(\"会话文件不存在!\"); } // 保存会话ID chatHistoryRepository.save(ChatType.PDF.getValue(), chatId); // 请求模型 return pdfChatClient .prompt(prompt) .advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId)) .advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, \"file_name == \'\"+file.getFilename()+\"\'\")) .stream() .content();}这里和之前的相比,就是加了一个advisor,因为我们设置文件的过滤器是需要动态设置的,也就是通过我们的chatId去数据库拿文件名
这里也就加深了理解,其实ChatMemory、QuestionAnswerAdvisor在Controller里面配置的advisors也可以在我们的Configuration里面配置,但是我们为了动态设置,在Controller里接收了前端的参数之后再进行设置
至此,我们就开发完毕,接下来就是测试接口了
4.5 接口测试
打开浏览器,访问http://localhost:5173
点击ChatPDF卡片,进入对应页面
上传一个PDF文件(可以拖拽上传,也可以点击上传)
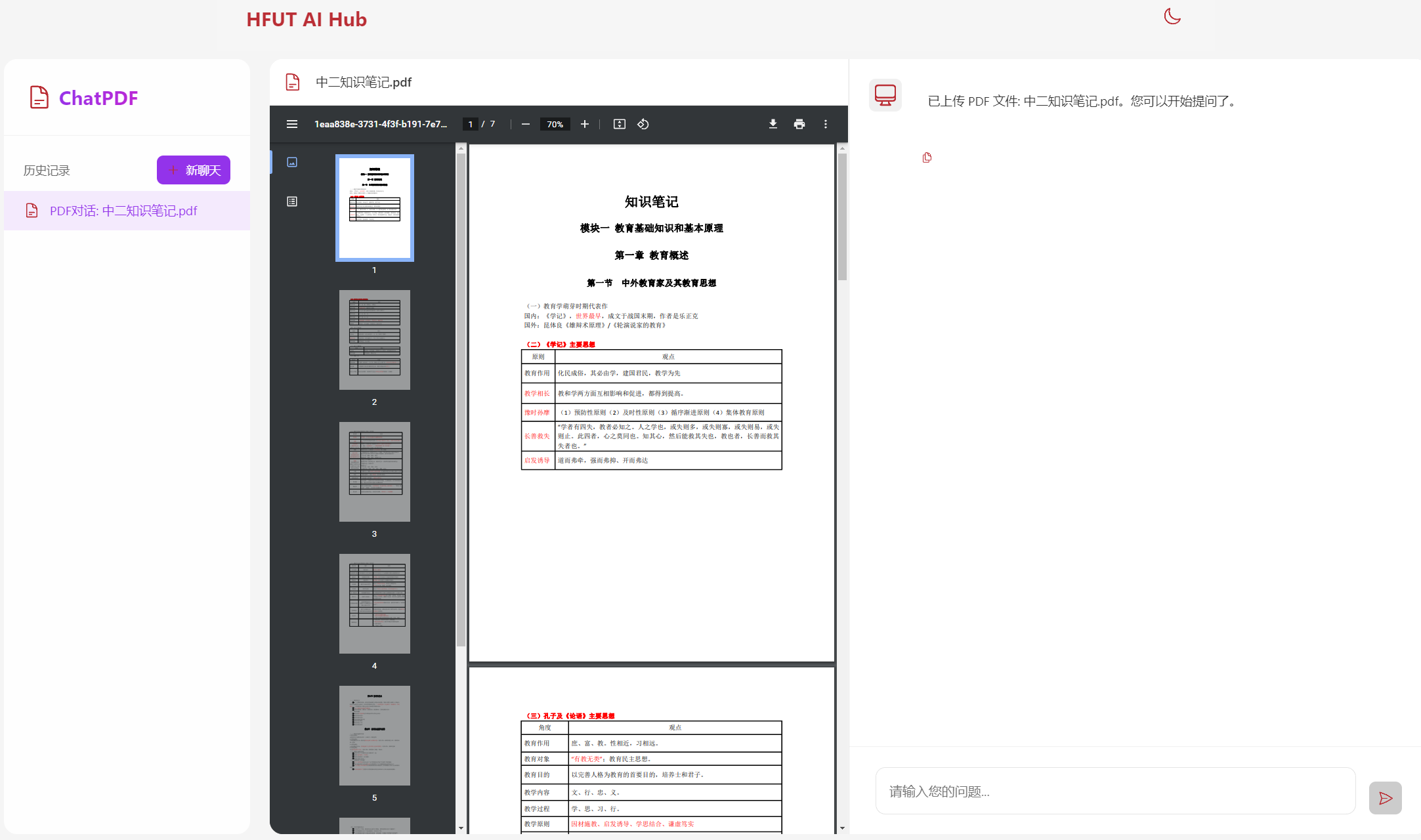
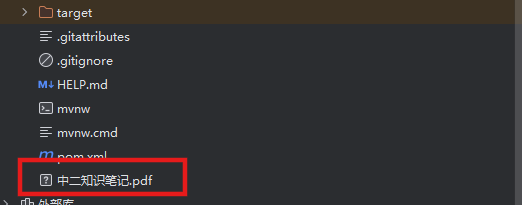
上传完成之后,会看到页面有相应的展示,同时根目录下会有下载好的pdf文件,代表着我们的文件上传功能是正常的
同时,我们可以去查看Redis和mysql的数据库
Redis
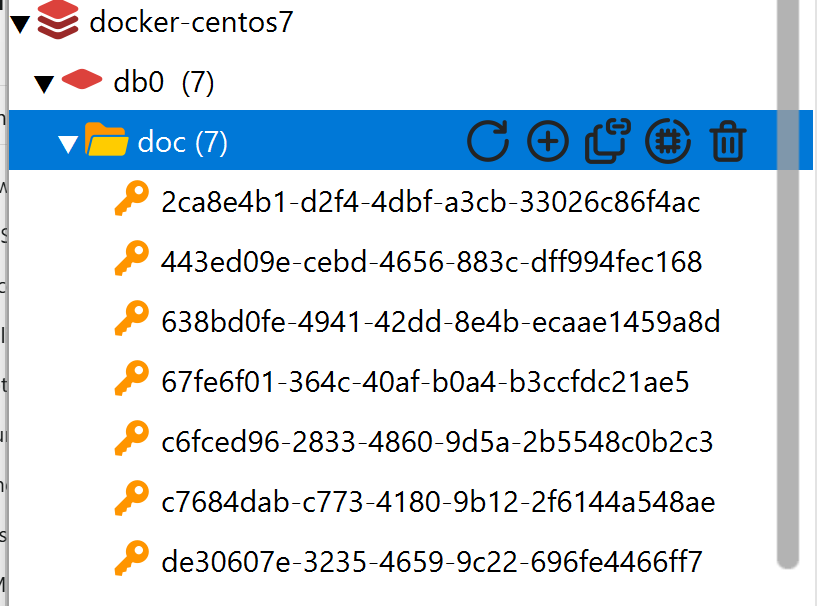
向量库写入成功
MySQL
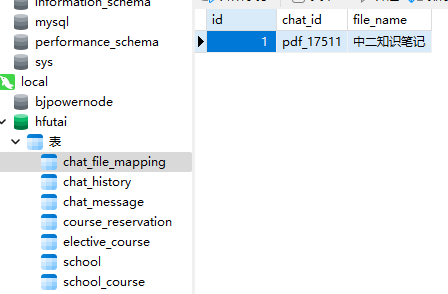
chatId和pdf文件名都保存进去了
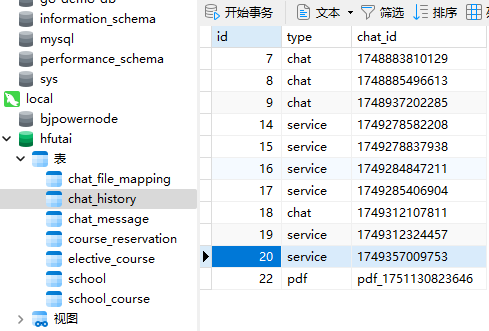
我们退出页面再回去,可以看到之前的文件会重新加载,看MySQL数据库里也保存了会话历史
可以证明,文件下载的功能是正常的
4.6 优化
4.6.1 自定义QuestionAnswerAdvisor
我在向大模型提问的时候,发现他并没有从向量库里获取上下文

去控制台可以看见,本来用来放置上下文的占位符不在了
去查看官方文档和看原教程可以发现,这里本来应该是这样的
经过我排查之后,我认为可能是QuestionAnswerAdvisor失效了
因为查看官方的文档,这个Advisor版本貌似是0.8,我个人怀疑是版本不兼容的问题
同时,我在网上查阅各种资料都没有找到解决办法,因此我这里选择弃用QuestionAnswerAdvisor
我这里在后文已经提到,失效的原因是不能加 QuestionAnswerAdvisor.FILTER_EXPRESSION
RedisVectorStore貌似不能支持文件名筛选,一旦筛选就无法获取向量库数据了
但是下面的自定义QuestionAnswerAdvisor还是值得看的
如果了解了我在4.3提到的流程图,我们可以发现,这个QuestionAnswerAdvisor不是必需品
我们是完全可以手动实现的,其实唯一需要做的就是像测试方法那样
- 自己手动构建一下SearchRequest
- 交给向量库进行similaritySearch
- 将返回的Document集合提取融合到prompt当中
我们自己写一个Util类PromptUtils
package com.hfut.ai.utils;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.document.Document;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.beans.factory.annotation.Autowired;import java.util.List;public class PromptUtils { @Autowired private VectorStore vectorStore; // 定义问答模板 private final String PROMPT_BLUEPRINT = \"\"\" 严格参考提供的上下文回答查询: {context} Query: {query} 如果您从提供的上下文中没有任何答案,只需说: 很抱歉,我没有您要找的信息。 \"\"\"; // 获取上下文 private List getContext(String query, String fileName) { // 根据用户输入的查询和文件名获取上下文 SearchRequest request = SearchRequest.builder() .query(query) // 查询 .topK(2) // 返回的相似文档数量 .similarityThreshold(0.6) // 相似度阈值 .filterExpression(\"file_name == \'\"+fileName+\"\'\") // 过滤条件 .build(); // 通过向量数据库搜索获取上下文 List docs = vectorStore.similaritySearch(request); return docs; } public String getPrompt(String query, String fileName) { // 获取上下文 List docs = getContext(query, fileName); PromptTemplate promptTemplate = new PromptTemplate(PROMPT_BLUEPRINT); promptTemplate.add(\"context\", docs); promptTemplate.add(\"query\", query); return promptTemplate.render(); }}写好之后,在Controller那里,传入用户输入的Prompt和获取到的fileName即可获取到组装好的Prompt了
而在这一步测试的时候,我发现依旧无法从向量库里获取到上下文
然后,我发现了根本的原因,使用RedisVectorStore向量库,不能使用filterExpression进行过滤
同样,如果使用QuestionAnswerAdvisor也不能使用FILTER_EXPRESSION进行过滤,把过滤条件删掉就解决了
至此,自定义实现了,同时,之前的方案把过滤器删掉也可以运行!
4.6.2 向量库重复写入问题
/** * 文件上传 */@RequestMapping(\"/upload/{chatId}\")public Result uploadPdf(@PathVariable String chatId, @RequestParam(\"file\") MultipartFile file) { try { // 1. 校验文件是否为PDF格式 if (!Objects.equals(file.getContentType(), \"application/pdf\")) { return Result.fail(\"只能上传PDF文件!\"); } // 2.保存文件 boolean success = fileRepository.save(chatId, file.getResource()); if(! success) { return Result.fail(\"保存文件失败!\"); } // 3.写入向量库 this.writeToVectorStore(file.getResource()); return Result.ok(); } catch (Exception e) { log.error(\"Failed to upload PDF.\", e); return Result.fail(\"上传文件失败!\"); }}我们重新来看文件上传的代码
用户每次开启新对话,都需要上传一份文件
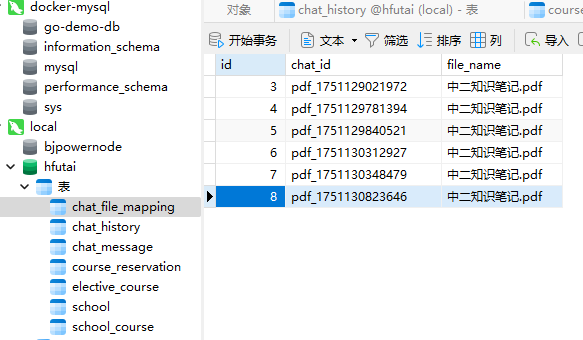
可以看到,我在测试的时候,开启了多个会话,每个会话都传入了相同的文件“中二知识笔记.pdf”
每段对话都记录对应的文件,这是没问题的
但是问题出在,每次上传新文件,都会向向量库里写入数据,即使是同一份文件,都要写入多次
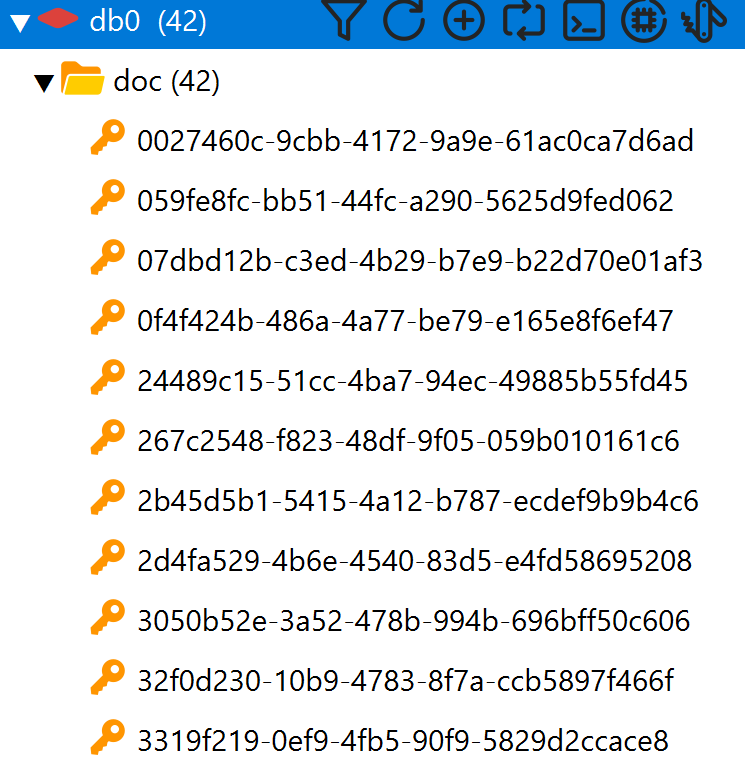
可以看到,我测试的时候,同一份文件,一份7页,但是向量库里却有42条数据,很明显这样是会大量额外占用内存空间的
我们需要对这个地方进行优化
很简单,有两种实现方式
第一种:保存文件调用save方法返回一个标记值,在save方法中可以查询这个文件是否之前上传过,如果上传过,那么就不再写入向量库
第二种:把写入向量库的逻辑,也放入save方法当中
我这里选择第二种方式
@Overridepublic boolean save(String chatId, Resource resource) { // 保存到本地磁盘 String filename = resource.getFilename(); // 默认保存到当前项目的目录下,也就是D:\\JavaStudy\\013-AIchat\\hfut-ai\\.pdf File target = new File(Objects.requireNonNull(filename)); if (!target.exists()) { try { Files.copy(resource.getInputStream(), target.toPath()); } catch (IOException e) { log.error(\"Failed to save PDF resource.\", e); return false; } // 如果文件是第一次保存,则保存到向量库 writeToVectorStore(resource); } // 使用 LambdaQueryWrapper 通过实体类属性名查询 LambdaQueryWrapper queryWrapper = new LambdaQueryWrapper(); queryWrapper.eq(ChatFileMapping::getChatId, chatId); // 查询是否存在记录 ChatFileMapping existingMapping = chatFileMappingMapper.selectOne(queryWrapper); // 如果不存在,才保存新的映射关系 if (existingMapping == null) { ChatFileMapping mapping = new ChatFileMapping(); mapping.setChatId(chatId); mapping.setFileName(filename); chatFileMappingMapper.insert(mapping); // 插入数据库 } return true;}这样改写之后,每次新的文件存入根目录下,才会把对应文件的数据保存到向量库
RedisVectorStore默认的TTL是-1,也就是持久化保存,所以说不用担心数据丢失问题
当然我们也可以写一个脚本,定期去删除根目录下的文件,然后把这个定的时间设置为Redis的TTL即可,就不过多阐述了,与RAG无关
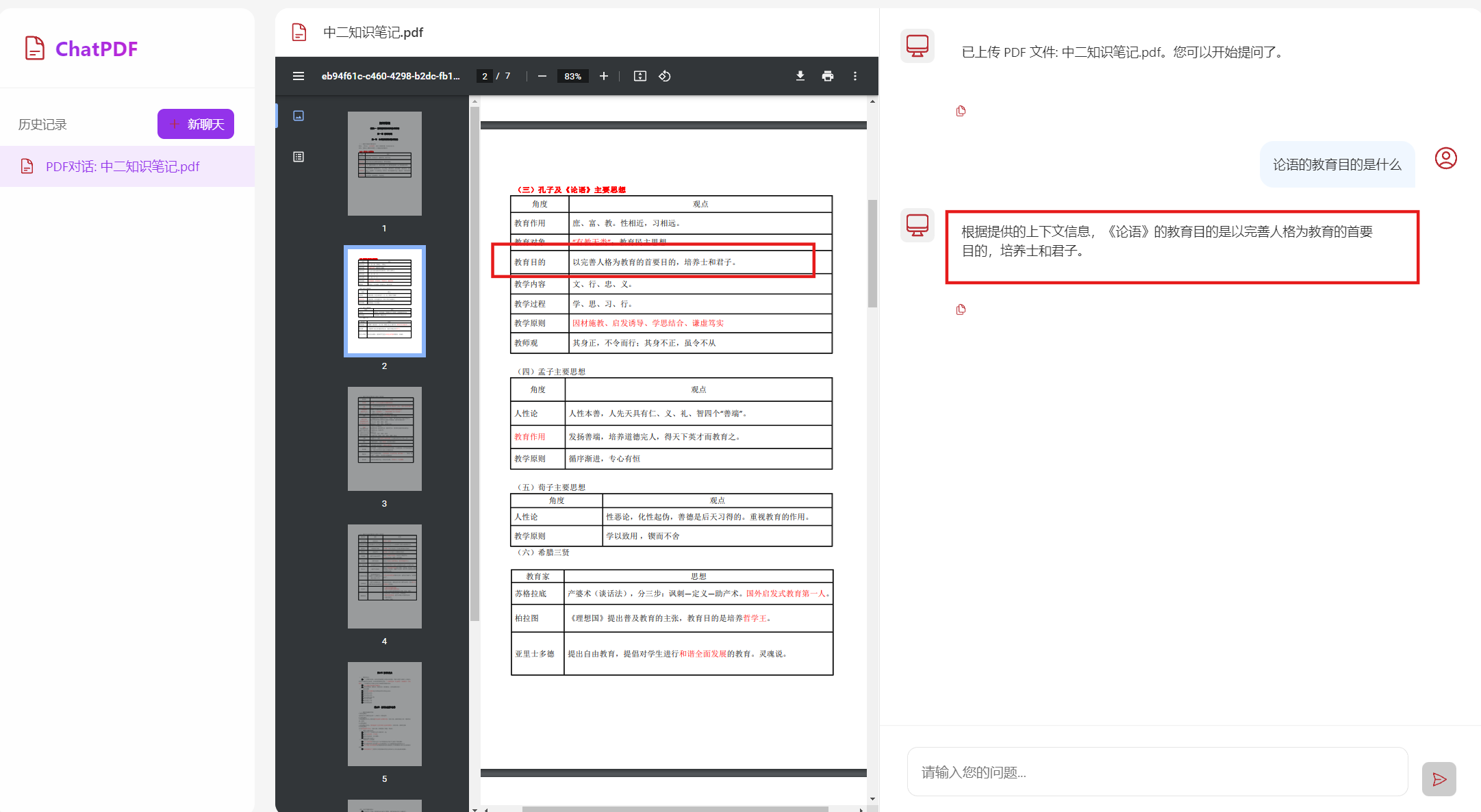
优化之后,可以正常提问
我开启新聊天后,去查看向量数据库
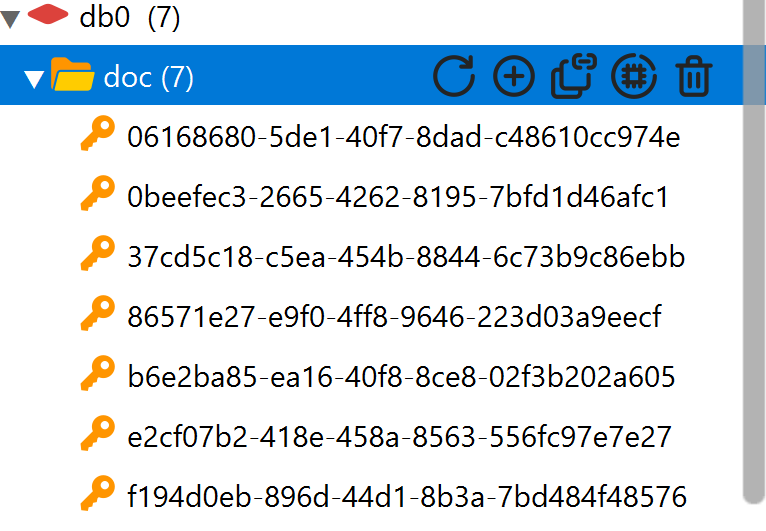
仍是7条,没有变化
成功解决了向量库重复写入的问题
4.7 总结
RAG这一块说实话,需要自己实现的代码没有第三节Function Calling多
当然,也是因为我们之前就做好了持久化的设计,这里直接调用就好
我们重新捋一下流程
-
设计了PDF的上传下载
-
上传,就是客户端传文件,后端接收之后,将文件本地化,然后chatId和对应文件名的关系存入MySQL
-
下载,就是客户端退出重新进入页面,通过chatId拿到对应文件名,然后重新从本地加载到客户端
这一步其实和之前的History的操作本质是一样的
-
-
PDF的向量化
-
这一步其实代码实现很简单,主要是理解向量化和向量化作用的原理,具体实现其实SpringAI已经帮我们封装好了
向量化的原理,或者说RAG的原理,可以细看4.1
-
只不过和原视频不同的是,我们向量库用的是RedisVectorStore
-
-
会话模型与向量库的结合
- 最后一步其实本质上,可以理解为,用户传入提示词,然后把提示词作为搜索条件,拿去向量库检索,向量库返回结果之后,通过内部封装的QuestionAnswerAdvisor,把结果和原本提示词组合在一起,组成新的提示词,然后拿去问会话模型
- 一句话总结就是:用户问题+向量库片段 = 组合后的提示词 —> 询问大模型
- 我在4.6.1当中也写了不使用Spring提供的Advisor,自己实现的方式
-
当前的代码其实还不够完善
- 存在使用Redis向量库,无法使用筛选器的情况,一旦向量库里东西存多了,那么不进行文件筛选的话,速度就会很慢,这个问题有待解决,如果有后续我也会发出来的
5.多模态
多模态是指不同类型的数据输入,如文本、图像、声音、视频等。目前为止,我们与大模型交互都是基于普通文本输入,这跟我们选择的大模型有关。
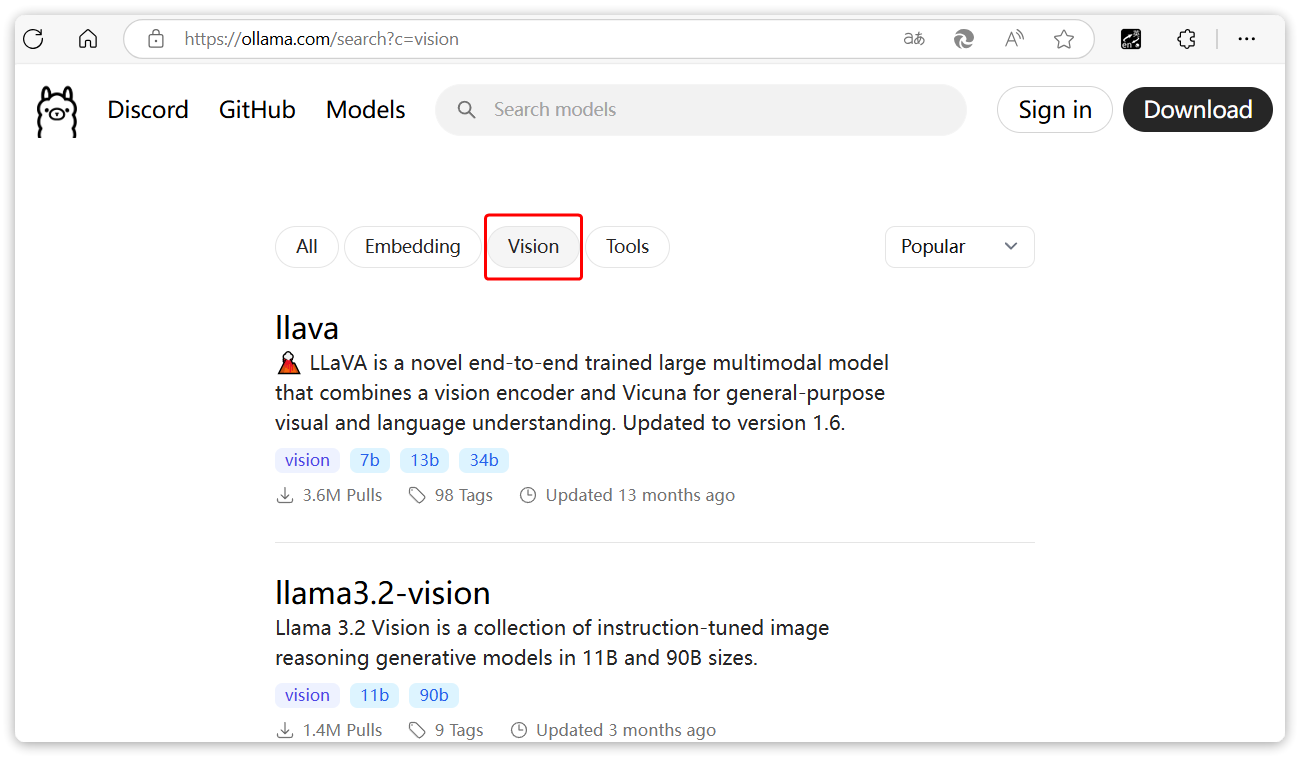
deepseek、qwen-max等模型都是纯文本模型,在ollama和百炼平台,我们也能找到很多多模态模型。
以ollama为例,在搜索时点击vison,就能找到支持图像识别的模型:
在阿里云百炼平台也一样:
阿里云的qwen-omni模型是支持文本、图像、音频、视频输入的全模态模型,还能支持语音合成功能,非常强大。
这一章我们要做的,就是优化我们的AI聊天板块,让其可以接入多模态的大模型,处理其他类型的输入
5.1切换模型
首先,我们需要修改CommonConfiguration中用于AI对话的ChatClient,将模型修改为OpenAIChatModel,不仅如此,由于其它业务使用的是qwen-max模型,不能改变。所以这里我们还需添加自定义配置,将模型改为qwen-omni-turbo:
/** * AI对话用ChatClient对象,用于处理用户输入的文本,并返回处理结果 * @param model 使用本地的模型 * @param inSqlChatMemory 通过数据库进行会话历史存储 * @return */@Beanpublic ChatClient chatClient(OpenAiChatModel model, InSqlChatMemory inSqlChatMemory) { return ChatClient .builder(model)// 选择模型 .defaultOptions(ChatOptions.builder().model(\"qwen-omni-turbo\").build())// 单独设置模型为 qwen-omni-turbo 多模态模型 .defaultSystem(\"你是合肥工业大学的一名资深老学长,十分熟悉校园,请以该身份的语气和性格回答问题\")// 系统设置 .defaultAdvisors(new SimpleLoggerAdvisor())// 添加日志记录 .defaultAdvisors(MessageChatMemoryAdvisor.builder(inSqlChatMemory).build())// 添加会话记忆功能 .build();}5.2 对话接口设置
接下来,我们需要修改原来的/ai/chat接口,让它支持文件上传和多模态对话。
修改ChatController:
/** * 聊天控制器 * @author GM */@Slf4j@RequiredArgsConstructor@RestController@RequestMapping(\"/ai\")public class ChatController { private final ChatClient chatClient; /*@Autowired @Qualifier (\"inMemoryChatHistoryRepository\") // 使用内存存储会话id private ChatHistoryRepository chatHistoryRepository;*/ @Autowired @Qualifier (\"inSqlChatHistoryRepository\") // 使用数据库存储会话id private ChatHistoryRepository chatHistoryRepository; @RequestMapping(value = \"/chat\", produces = \"text/html;charset=utf-8\") // @CrossOrigin(\"http://localhost:5173\") public Flux chat( @RequestParam(\"prompt\") String prompt, @RequestParam(\"chatId\") String chatId, @RequestParam(value = \"files\", required = false) List files) { // 保存会话ID chatHistoryRepository.save(ChatType.CHAT.getValue(), chatId); // 请求模型 if (files != null && !files.isEmpty()) { // 有附件,多模态聊天 return multiModalChat(prompt, chatId, files); } else { // 没有附件,纯文本聊天 return textChat(prompt, chatId); } } private Flux multiModalChat(String prompt, String chatId, List files) { // 1.解析多媒体文件 List medias = files.stream() .map(file -> new Media( MimeType.valueOf(Objects.requireNonNull(file.getContentType())), file.getResource() ) ) .toList(); // 2.请求模型 return chatClient.prompt() .user(p -> p.text(prompt).media(medias.toArray(Media[]::new)))// 设置用户输入 .advisors(a->a.param(ChatMemory.CONVERSATION_ID,chatId))// 设置会话ID .stream()// 开启流式对话 .content();// 获取对话内容 } private Flux textChat(String prompt, String chatId) { return chatClient.prompt() .user(prompt)// 设置用户输入 .advisors(a->a.param(ChatMemory.CONVERSATION_ID,chatId))// 设置会话ID .stream()// 开启流式对话 .content();// 获取对话内容 }}5.3 测试
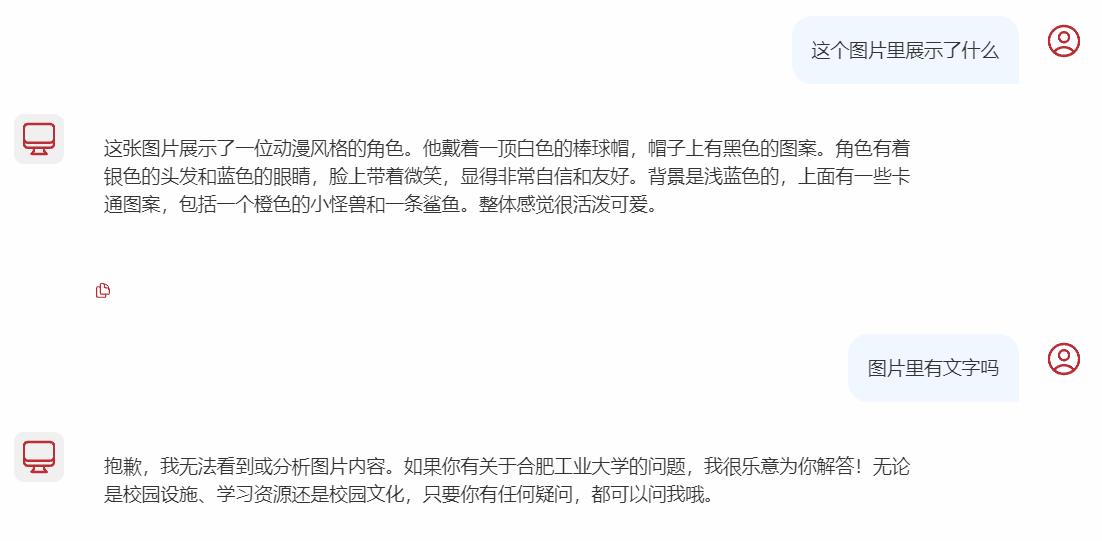
测试图片

测试结果
5.4 存在问题
对多模态大模型的使用,会发现存在一点问题
- 上传的附件无法联想记忆,因为我是自己写了一个Memory,把会话内容都保存到数据库,但是很明显,图片无法进行保存,也就是说,每次上传的图片都是一次性的,前端也没有做响应的图片展示,这一点上是值得优化的。或者说直接使用自带的ChatMemory保存在内存当中,是支持保存图片的
- 音频无法识别的问题,这个问题源于OpenAI的大模型和阿里的大模型在一些接口上存在不兼容的问题,说直白一点,就是一些参数格式的要求不同。FunctionCalling之前存在不能流式输出的问题正式版SpringAI已经解决了,但是音频的问题还没有解决。音频识别中的数据格式,阿里云百炼的qwen-omni模型要求的参数格式为data:;base64,${media-data},而OpenAI是直接{media-data}
想要解决音频的问题,我会单独发一篇非原创文章,因为我自己没有去写,我会直接把黑马原课程的笔记发出来
5.5 总结
多模态这一块,原课程讲的也很少,其实本质上是换了个不同的大模型,只不过因为上传的类型变多了,不同的类型,我们需要保存,处理,分析的方式就变了。具体的一些个人感悟我会在结语里面详谈,也是完结撒花了
6.结语(MCP粗谈)
也是终于把全部内容写完了,原视频的整个课程差不多10小时左右。我学习的周期差不多压缩在一周之内就学完了。因为做了很多个人的思考和拓展,时间稍微长了一点,本来的课程其实挺简单好懂的,因为SpringAI很多东西都封装好了,原课程学下来估计3天就能拿下。为什么拖了这么久才把笔记写完呢,是因为作者在开始实习了,平时都要上班,开始实习之前就把Function Calling学完了,RAG开了个头,觉得后面很简单就没有继续更新了
我最开始之所以学习这套课程,是因为还没去实习前,leader告诉我,可以了解下大模型应用这块的知识,然后就选择了SpringAI这套课程。整体学完之后我谈谈我的感受吧
首先SpringAI这个框架,目前肯定还是比较不成熟的,黑马这个课里采用的是M6的测试版本,因此和现在的1.0正式版之间,就会有很多出入的地方,我的笔记里面也强调过很多次,多去看官方文档!!!
如果说,我对这个项目和SpringAI的学习,收获最大的地方是什么?其实并非是对SpringAI本身的应用,而是学习了大模型和大模型应用的整体开发思路。从Prompt设计,到Function Calling的原理和实现,再到RAG原理的理解和实战,对这种前沿技术的理解,让我在实习的时候,能更快的上手,部门需要的大模型相关开发
整套课程学习下来,以及这段时间对其他技术的了解,我认为其中的第三节,也就是Function Calling是最关键的,其实从整个笔记的篇幅就可以看出来,扯到Function Calling或者说Tools,就必须要讲接下来我打算学习的一门技术:MCP
最开始对MCP不了解,以为是一门新的技术,其实学习完Tools之后,就明白了,MCP无非就是给编写Tools(Function Calling)加上了行业规范而已,MCP全称本来也就是模型上下文协议
可以看到,我在实现Tools功能的时候,最核心的地方,其实就是让大模型去知道,什么时候去调用什么函数方法,为此,需要编写及其严谨复杂的提示词,并且需要编写多个函数方法去面对不同的情况
那么我们在实际开发的过程中,每开一个新的项目,或者新的功能,就又要去编写新的提示词,编写新的方法吗?这显然是很恶心的,我这一个如此简单的项目,当时写方法和提示词就已经焦头烂额了,我们可以发现,很多提示词和方法都是可以共用的
举个很简单的例子,一个功能,是用来查询天气的,那么我们需要去编写让大模型调用这个功能配套的提示词和函数,这个工具在很多地方都可以用到,那么我们可不可以把他封装起来,然后反复调用呢?
答案是可以的,而这就是MCP的最大作用:实现Tool的复用
这么讲可能还是比较晦涩难懂,我再简单一点讲,MCP是一种协议,或者说开发规则,还是那个查询天气的功能,我把他封装好,打包成一个库,让所有人都可以调用,但是调用它的方式是MCP来定的,MCP规范了FunctionCalling的格式,让所有的功能都可以打包好,然后用统一的方式进行调用
而学习MCP,其实本质上就是去学习这套规则下,如何调用别人开发好的FunctionCalling功能,以及学习如何自己开发符合MCP规范的FunctionCalling功能让别人调用
MCP的功能简单来讲就一个:提高代码复用,减少重复开发
大家可以类比封装和AOP的那种设计思想去理解,一句话总结就是,规定FunctionCalling的开发,让所有人可以直接像导包一样,拿来即用
这里可以放一个传统FunctionCalling和MCP规范后的对比图
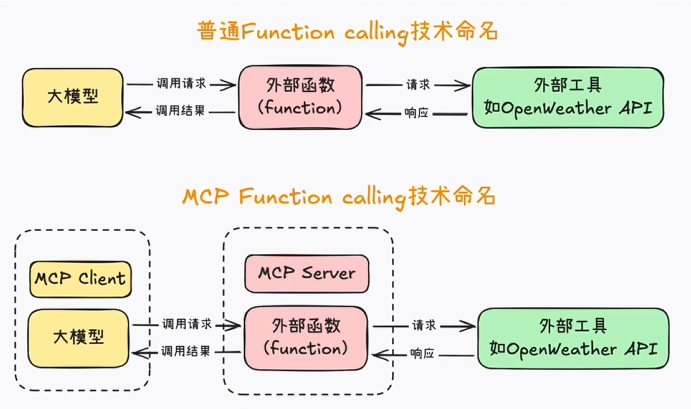
MCP中,主要就是规范了提示词的设计和Function的编写,而这两点,我上面也提到了,是FunctionCalling最难搞的地方,规范之后,大家写好的函数+提示词就被统一打包成MCP Server,也就是MCP服务器,然后就可以被各种大模型复用了
这里的服务器和传统的服务器不一样,我个人更喜欢把他理解成工具包,我认为和引入一个依赖没有什么区别。这就是我个人对MCP技术的理解了
完结撒花!!!


