【论文阅读(一)】CLIP-IQA: Exploring CLIP for Assessing the Look and Feel of Images_iqa论文
Exploring CLIP for Assessing the Look and Feel of Images
南洋理工大学 AAAI23
概述:本文提出构造正反样本对作为CLIP的Prompt,并移除位置嵌入,提升CLIP在图像质量评价领域的性能。
项目地址:https://github.com/IceClear/CLIP-IQA
一、动机
当人类解读图像时,外观和感觉是两个影响因素。图像的外观通常与直接影响内容交付的可量化属性相关,例如曝光和噪声水平。相比之下,图像的感觉是与内容无关的抽象概念,并且不容易量化,如情感和美学。
现有手工制作的方法在标注数据的情况下与人类感知的相关性更高,但标注数据的繁琐过程和基于学习的方法的任务特定性限制了它们对未知属性的泛化能力,更重要的是,上述方法都是针对质量或抽象感知的,通用性有限。
作者为探索以下概念引入了CLIP(一种基于对比学习的视觉语言预训练方法,能够通过大量图像-文本对在没有显式训练的情况下在文本和视觉实体之间建立语义关系):
(1)不需要手工制作的功能和特定任务的训练,
(2)与人类感知具有高度相关性,
(3)可以处理质量和抽象感知。
为此,作者假设CLIP可以捕获人类语言和视觉感知之间的关系,用于图像评估。
由于CLIP已知对提示符的选择敏感,和感知是一个抽象的概念,没有标准化的形容词,特别是对图像的感觉。因此,CLIP在这项任务上的表现可能是高度不稳定的,这是由于提示的不同选择造成的。
该方法首次尝试探索CLIP在具有挑战性但有意义的感知评估任务中的潜力。作者通过深入研究提示的选择,从而最大限度地减少由于语言歧义造成的潜在模糊性。为此,作者引入了一种提示配对策略,其中成对采用反义词提。该策略证明CLIP可以直接应用于视觉感知评估,而无需任何特定任务的微调。
对于质量感知,作者证明CLIP能够通过简单地使用“好”和“坏”作为提示来评估图像的整体质量,并在常见的IQA数据集中与人类的感知高度相关。
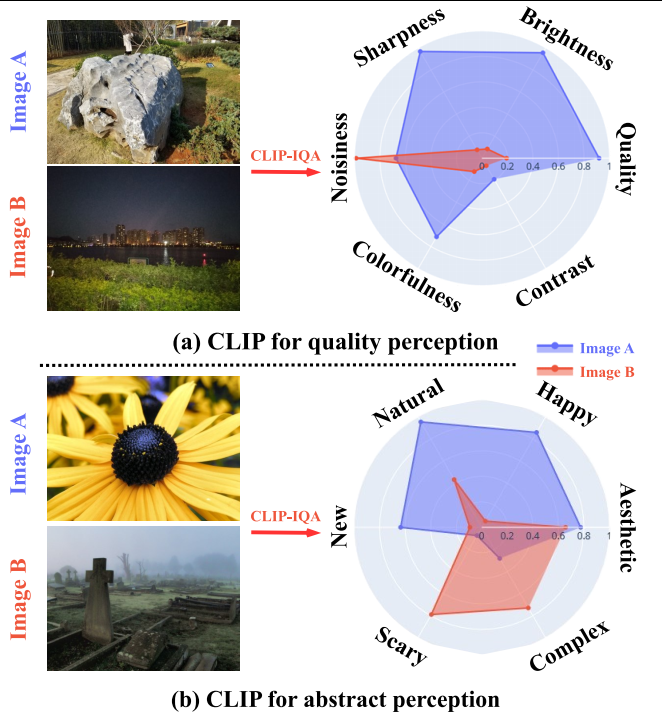
上图a展示了CLIP在评估细粒度质量(如亮度和噪声)方面的能力。
上图b展示了CLIP在感知人类感知的抽象属性(如快乐”和“悲伤”)方面的能力。
本文首先使用精心设计的提示配对策略(称为CLIP-IQA)将CLIP直接适应图像评估,然后进行广泛的实验来检查CLIP的能力边界。证明了CLIP不仅能够评估图像的外观,而且能够在令人满意的程度上评估图像的感觉。
二、方法
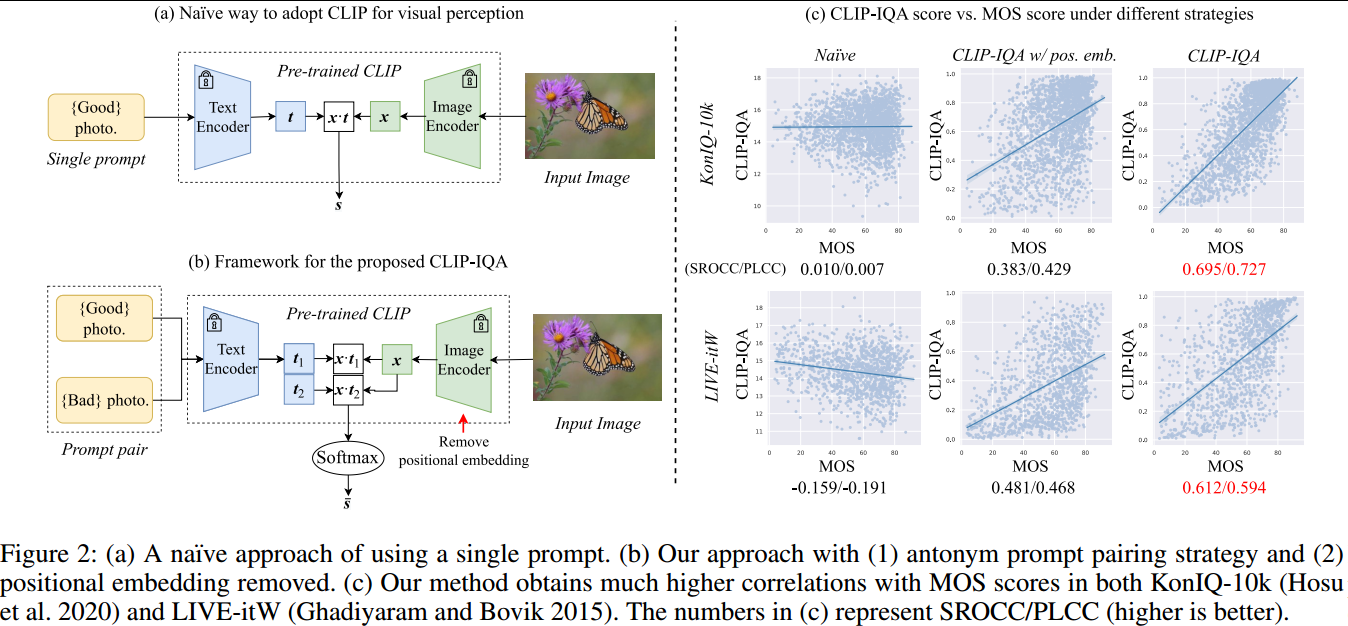
反义词提示配对。如上图(a)所示,利用CLIP进行感知评估的一种简单方法是直接计算给定提示(例如“好照片”)的特征表示与给定图像之间的余弦相似性,如式1。
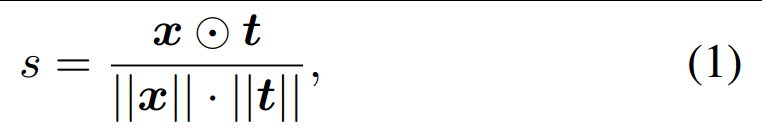
但是上述方法会由于提示词存在歧义导致其不适用于感知评估,例如“丰富图像”既可以指内容丰富的图像,也可以指与财富相关的图像。
如上图(c)所示,使用带有单个提示的CLIP与常见IQA数据集上的人类感知相关性较差。
为了减少歧义,作者对每个预测采用反义词提示(例如“好照片”和“坏照片”)作为一对,并分别计算其余弦相似度,如式2。
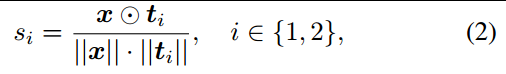
最后使用Softmax得到最终得分:

从上图c第二列可以发现,反义词提示配对显著提高了CLIP的性能,大幅提升了SROCC和PLCC得分,使得CLIP能够预测与人类标记的MOS分数更一致的分数。
移除位置嵌入。CLIP的另一个限制是需要固定大小的输入。这样的要求在感知评估中是不利的,因为调整大小和裁剪操作可能会对输入图像引入额外的失真,从而改变最终得分。
上述限制是由于可学习的位置嵌入造成的,其大小在构造时是固定的。由于感知评估任务的重点是捕捉图像和给定描述之间的感知关系,位置信息对其影响较小,故作者提出移除位置嵌入以放宽尺寸约束。
采用ResNet变体去提供更强的归纳偏差来补充位置信息的去除。上图(c)第三列展示了这种放松进一步提高了与人类感知的相关性。
三、实验
质量感知
CLIP-IQA用于整体质量。作者此处只使用了最常见的反义词之一作为CLIP-IQA的配对提示。
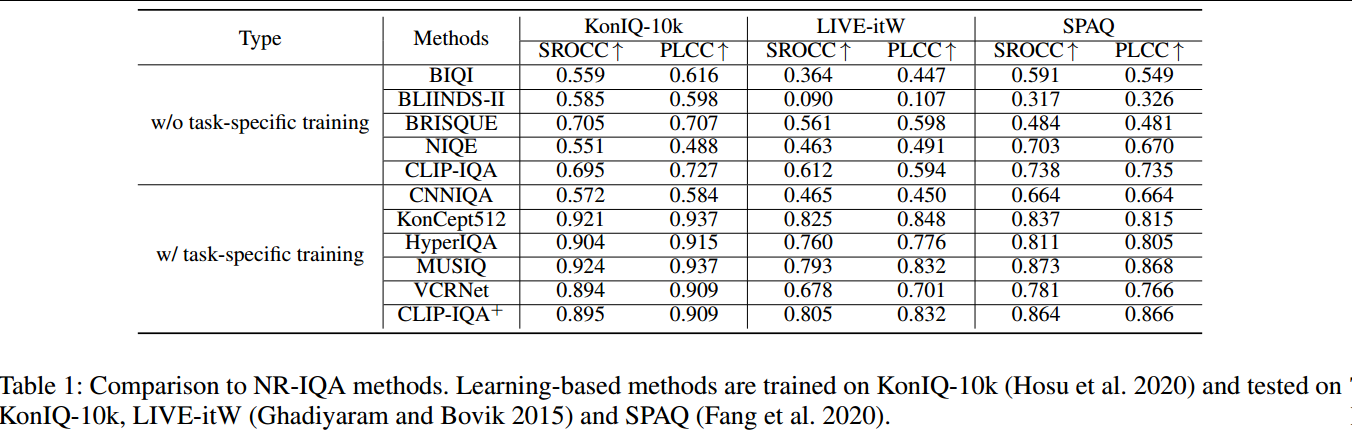
CLIP-IQA在有/无注释训练的良好性能验证了其在NR-IQA任务中的潜力(在有注释的任务中,CLIP-IQA+可以反向传播更新初始化提示)。

图3展示了CLIP-IQA能够区分不同质量图像的能力。
CLIP-IQA用于细粒度质量。人类通常从多个角度(如亮度、噪声和锐度)判断图像,而不是为图像分配一个分数。
作者使用四个代表性属性:亮度、噪声、色彩和锐度的合成数据来测试CLIP-IQA评估细粒度质量的能力。
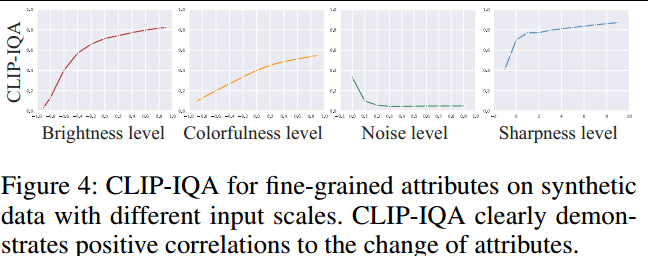
图4可以看出,CLIP-IQA与属性的变化具有很高的相关性。
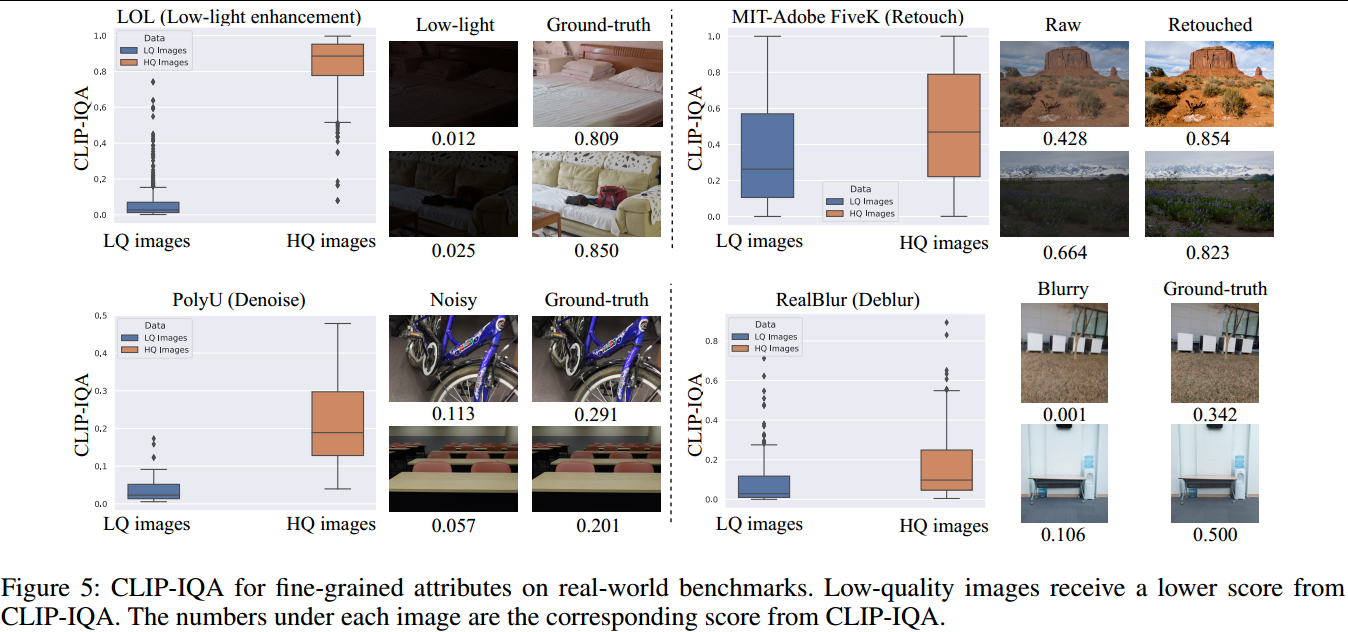
图5展示了真实的四个非合成基准(LOL:低光增强,PolyU:去噪,MIT-Adobe FiveK:修饰,RealBlur:去模糊)上的性能表现,结果显示高质量图像的质量分数明显高于低质量图像,表明CLIP-IQA能够识别细粒度质量。
抽象感知
使用与人类情感和艺术感觉相关的五个属性在AVA基准上来评估CLIP-IQA的性能,即复杂/简单、自然/合成、快乐/悲伤、恐怖/平静和新/旧。

图6中显示的每个属性的得分最高和得分最低的图像,展示了CLIP-IQA能够感知图像的抽象方面。

图7展示了使用25名受试者评分作为基本事实来计算CLIP-IQA的分类准确率,CLIP-IQA在所有五个属性上都达到了约80%的准确率,表明了CLIP-IQA在抽象概念理解方面具有巨大的潜力。
四、讨论
提示设计
提示模板的选择对CLIP-IQA有显著影响。作者比较了现有的三种模版:“[text] photo.”,“A photo of [text].”,“There is [text] in the photo.”。为了简单起见,作者采用了“[text]photo.”,但作者相信存在更复杂的模板可以提高性能。
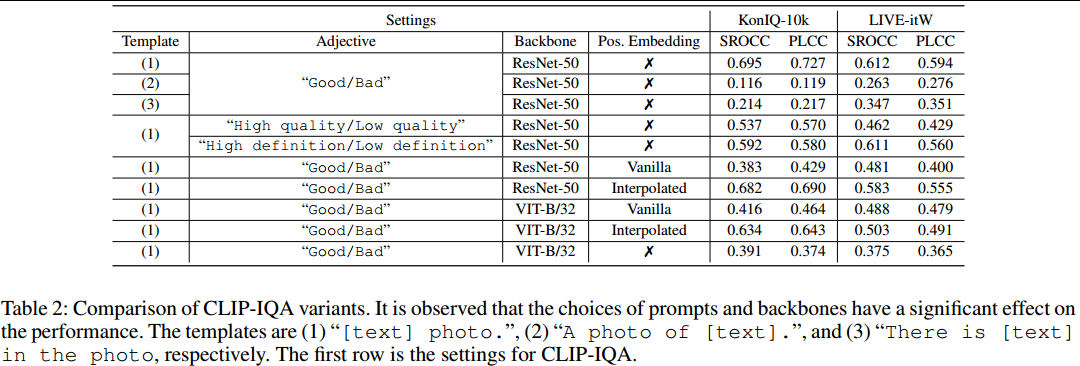
随后,作者还在上述模版的基础上研究了形容词的影响。根据上表结果,作者推测不常见形容词的表现较差(表中数据的第二列前三行)。
图像编码器的主干网络
图像编码器的主干对CLIP-IQA的性能有显著影响。与隐式捕获位置信息的卷积模型不同,Transformer严重依赖位置嵌入来提供此类线索。因此,CLIP的Transformer变体中加入了位置嵌入,以弥补这种归纳偏置的不足。相比之下,ResNet变体对位置嵌入的依赖性较小,在多头注意力过程中仅采用深层嵌入。
如表2所示,虽然Transformer变体在位置嵌入方面比ResNet变体表现出更好的性能,但当移除嵌入时,Transformer变体的性能明显下降(表中数据的第三列后五行)。
作者又比较了位置嵌入去除和位置嵌入插值的性能,从表2可发现位置嵌入去除的性能更好(表中数据的第三列的第一行和七行)。
考虑到在感知评估中接受任意大小的输入的重要性,作者选择了去除位置嵌入的ResNet变体作为CLIP-IQA的主干网络。
局限性
尚未解决的挑战:
首先,CLIP-IQA对提示语的选择很敏感,需开发更系统的提示语选择。
第二,CLIP模型难以识别在人类会话中相对不常见的专业术语。
第三,由于CLIP-IQA缺乏任务特定的结构设计,与现有的任务特定方法相比仍存在一定的差距。
结论
本文在已有研究的基础上,研究了CLIP在感知主观属性方面的有效性。作者发现,CLIP在经过适当的修改后,能够同时理解图像的质量和抽象感知。


