pyecharts二手房数据可视化分析(含3D图)
目录
引言
数据读取和处理
预处理
柱状图代码
效果展示
二手房数量热力2D地图
代码展示
效果展示
二手房数量分布3D地图
代码展示
效果展示
方位-城市房价分布3D柱状图
代码展示
效果展示
户型对比雷达图
代码展示
效果展示
户型数量对比饼图
代码展示
效果展示
建造年份-均价折线图
代码展示
效果展示
标题关键词词云图
代码展示
效果展示
总结
引言
本文用到的是之前在安居客采集到的广西二手房数据,现在我来简单分析一下
可视化大屏:https://blog.csdn.net/weijiayi040512/article/details/149233738?spm=1001.2014.3001.5502
爬虫博客:基于Python的安居客二手房数据爬虫开发实践-CSDN博客
主要涉及的python库有:
pandas:一个开源的Python数据分析库,提供了高效、灵活的数据结构,特别适合处理结构化数据。它的核心是两种数据结构:Series(一维数组,带标签)和DataFrame(二维表格,类似Excel或SQL表)。其中的groupby()函数是我接下来主要用的
PyMySQL: 是一个纯 Python 实现的 MySQL 客户端库,用于 Python 程序与 MySQL 数据库的交互。它是 MySQLdb 的替代品,兼容 Python 3.x,并且不需要编译任何 C 扩展。
PyEcharts :一个基于 ECharts 的 Python 数据可视化库,允许开发者使用 Python 生成 ECharts 的各种交互式图表。它提供了简洁的 API,能够轻松创建美观的、可交互的网页图表。
jieba(结巴分词):一个强大的中文分词工具,广泛应用于自然语言处理(NLP)、文本分析和搜索引擎等地方。它支持精确模式、全模式和搜索引擎模式三种分词方式,并提供了关键词提取、词性标注等功能。
数据读取和处理
首先,对MySQL数据库添加新列\"城市\",其实在采集数据的时候可以做这步,但是我忘了!!!为什么不读取了再添加新列,数据在之后还有用!!
import pymysqldef column_exists(conn, table, column): with conn.cursor() as cursor: cursor.execute(f\"\"\" SELECT COUNT(*) FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = DATABASE() AND TABLE_NAME = \'{table}\' AND COLUMN_NAME = \'{column}\' \"\"\") return cursor.fetchone()[0] > 0# 连接数据库conn = pymysql.connect( host=\'localhost\', user=\'root\', password=\'123456\', database=\'ershoufang\')try: # 检查并添加列 if not column_exists(conn, \'ershoufang_list\', \'城市\'): with conn.cursor() as cursor: cursor.execute(\"\"\" ALTER TABLE ershoufang_list ADD COLUMN 城市 VARCHAR(20) DEFAULT NULL \"\"\") conn.commit() # 定义城市分配范围 city_updates = [ (\"UPDATE ershoufang_list SET 城市 = \'南宁\' WHERE id BETWEEN 1 AND 10653\"), (\"UPDATE ershoufang_list SET 城市 = \'柳州\' WHERE id BETWEEN 10654 AND 20552\"), (\"UPDATE ershoufang_list SET 城市 = \'桂林\' WHERE id BETWEEN 20553 AND 30037\"), (\"UPDATE ershoufang_list SET 城市 = \'梧州\' WHERE id BETWEEN 30038 AND 36026\"), (\"UPDATE ershoufang_list SET 城市 = \'北海\' WHERE id BETWEEN 36027 AND 44048\"), (\"UPDATE ershoufang_list SET 城市 = \'防城港\' WHERE id BETWEEN 44049 AND 49150\"), (\"UPDATE ershoufang_list SET 城市 = \'钦州\' WHERE id BETWEEN 49151 AND 54780\"), (\"UPDATE ershoufang_list SET 城市 = \'贵港\' WHERE id BETWEEN 54781 AND 63839\"), (\"UPDATE ershoufang_list SET 城市 = \'榆林\' WHERE id BETWEEN 63840 AND 71179\"), (\"UPDATE ershoufang_list SET 城市 = \'百色\' WHERE id BETWEEN 71180 AND 74809\"), (\"UPDATE ershoufang_list SET 城市 = \'贺州\' WHERE id BETWEEN 74810 AND 77409\"), (\"UPDATE ershoufang_list SET 城市 = \'河池\' WHERE id BETWEEN 77410 AND 79429\"), (\"UPDATE ershoufang_list SET 城市 = \'来宾\' WHERE id BETWEEN 79430 AND 81873\"), (\"UPDATE ershoufang_list SET 城市 = \'崇左\' WHERE id BETWEEN 81874 AND 82644\"), (\"UPDATE ershoufang_list SET 城市 = \'玉林\' WHERE id BETWEEN 82645 AND 83124\")] # 执行所有更新 with conn.cursor() as cursor: for update in city_updates: cursor.execute(update) conn.commit() print(\"城市列添加和分配完成\")finally: conn.close()导出为csv文件
import pandas as pdimport pymysql# 数据库连接配置config = { \'host\': \'localhost\', \'user\': \'root\', \'password\': \'123456\', \'database\': \'ershoufang\', \'charset\': \'utf8mb4\' # 确保使用UTF-8编码连接}# 连接数据库conn = pymysql.connect(**config)# 读取数据df = pd.read_sql(\'SELECT * FROM ershoufang_list\', conn)# 导出为CSV,确保UTF-8编码csv_file = \'E:/ershoufang_data.csv\'df.to_csv(csv_file, index=False, encoding=\'utf_8_sig\') # utf_8_sig可解决Excel打开乱码问题conn.close()print(f\"数据已成功导出到 {csv_file}\")读取取csv文件,查看关键信息
df = pd.read_csv(\'E:/ershoufang_data.csv\') df.info()
由上图知,数据有13列·,楼层和时间(建造时间)有缺失值,面积和总价和均价要转为数值类型
预处理
删除缺失的行
df.dropna(inplace=True)df.reset_index(drop=True, inplace=True)提取均价的数值
def extract_price(price_str): match = re.search(r\'(\\d+)\', price_str) if match: return float(match.group(1)) return Nonedf[\'均价\'] = df[\'均价\'].apply(extract_price)extract_price函数:它就像个\"数字探测器\",在一堆文字里找第一个出现的完整数字,df[\'均价\'].apply(extract_price) 就是让表格里\"均价\"这一列每个格子都过一遍这个数字探测器,面积和总价的方法一样,我就不展示了
二手房数量/均价柱状图
city_counts = df[\'城市\'].value_counts().reset_index()city_counts.columns = [\'city\',\'total\']这段代码是用来统计 DataFrame 里各个城市出现的次数,然后整理成干净的统计表格。我解释下:
-
df[\'城市\'].value_counts()-
就像你有一堆订单数据,每个订单写了城市名
-
这行代码就是帮你数一数:北京有多少个、上海有多少个...自动从多到少排好序
-
-
.reset_index()-
默认统计结果是个\"孤单的数字列表\",这步给它加上序号(相当于加个表头)
-
比如原来只有
[100, 80, 50],现在变成两列:城市名和对应的数量
-
-
改列名
-
默认列名太丑(可能是
index和城市) -
columns = [\'city\',\'total\']就是给两列起个清爽的新名字:-
第一列叫 \'city\'(城市名)
-
第二列叫 \'total\'(该城市出现的总次数)
-
-
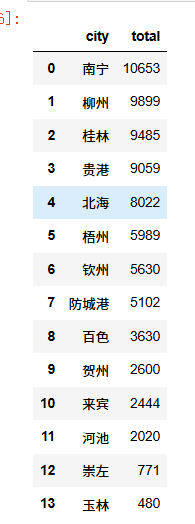
柱状图代码
from pyecharts import options as optsfrom pyecharts.charts import Barimport pandas as pd# 创建柱形图bar = ( Bar(init_opts=opts.InitOpts(width=\"1000px\", height=\"500px\")) .add_xaxis(city_counts[\'city\'].tolist()) # X轴:城市名称 .add_yaxis( series_name=\"房源数量\", y_axis=city_counts[\'total\'].tolist(), # Y轴:数量 label_opts=opts.LabelOpts(is_show=True), # 显示柱顶数值 itemstyle_opts=opts.ItemStyleOpts(color=\"#5470C6\") # 柱体颜色 ) .set_global_opts( title_opts=opts.TitleOpts( title=\"各城市房源数量对比\", pos_left=\"center\", pos_top=\"20px\" # 标题位置微调 ), xaxis_opts=opts.AxisOpts( name=\"城市\", axislabel_opts=opts.LabelOpts(rotate=0) # X轴标签不旋转 ), yaxis_opts=opts.AxisOpts( name=\"房源数量(套)\", splitline_opts=opts.SplitLineOpts(is_show=True) # 显示Y轴网格线 ), tooltip_opts=opts.TooltipOpts( trigger=\"axis\", formatter=\"{b}
数量: {c}套\" # 悬停提示格式 ), legend_opts=opts.LegendOpts(is_show=False) # 单系列无需图例 ))# 在Jupyter中显示bar.render_notebook()# 保存为HTML文件# bar.render(\"各城市房源数量对比.html\")效果展示
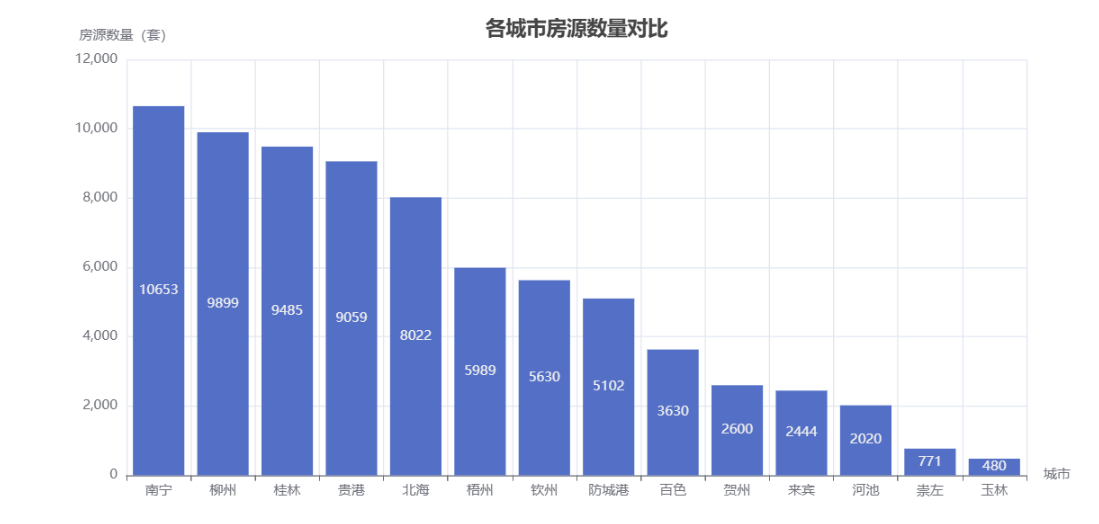
由上图可看出:
-
南宁一枝独秀:柱子明显最高,房源量约12,000套,远超其他城市(可能是省会效应)
-
柳州/桂林第二梯队:7,000-8,000套左右(广西重要经济/旅游城市)
-
尾部城市差异小:比如贺州、来宾等,数量在3,000-4,000套区间
这个图添加了横向滚动条(城市多时有用)
datazoom_opts=[opts.DataZoomOpts()] 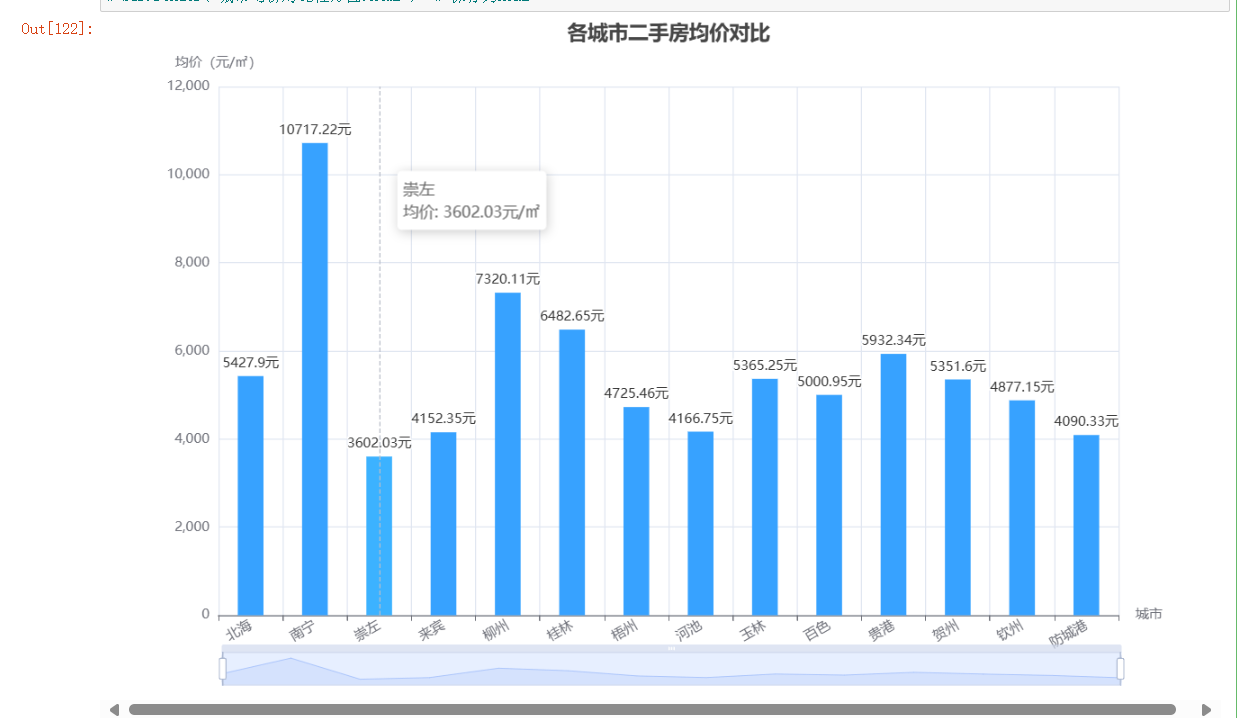
接下来我们通过2D地图和3D地图看各区域房价在地图上的分布
二手房数量热力2D地图
代码展示
注意:把城市名和对应的房源数量组合成 [[\"南宁市\", 12000], [\"柳州市\", 8500],...] 这样的格式;给城市名后面加\"市\"字是为了匹配地图内置的地名(比如\"南宁\"要写成\"南宁市\")
from pyecharts import options as optsfrom pyecharts.charts import Mapmap_data = [[city+\"市\", float(total)] for city, total in zip(city_counts[\"city\"], city_counts[\"total\"])]mp = ( Map() .add(\"房源\", map_data, maptype=\"广西\", is_map_symbol_show=False) # 使用广西省地图 .set_global_opts( title_opts=opts.TitleOpts(title=\"广西各城市二手房房源数量分布\"), legend_opts=opts.LegendOpts(is_show=False), visualmap_opts=opts.VisualMapOpts( # 视觉映射配置 min_=0, max_=12000, is_piecewise=False, # 设置颜色映射的最小值和最大值 range_color=[\"#FFFFE0\", \"#FFA500\", \"#FF4500\", \"#BB0000\"], ) ) .set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 显示城市名称)# 渲染地图到文件mp.render_notebook()效果展示
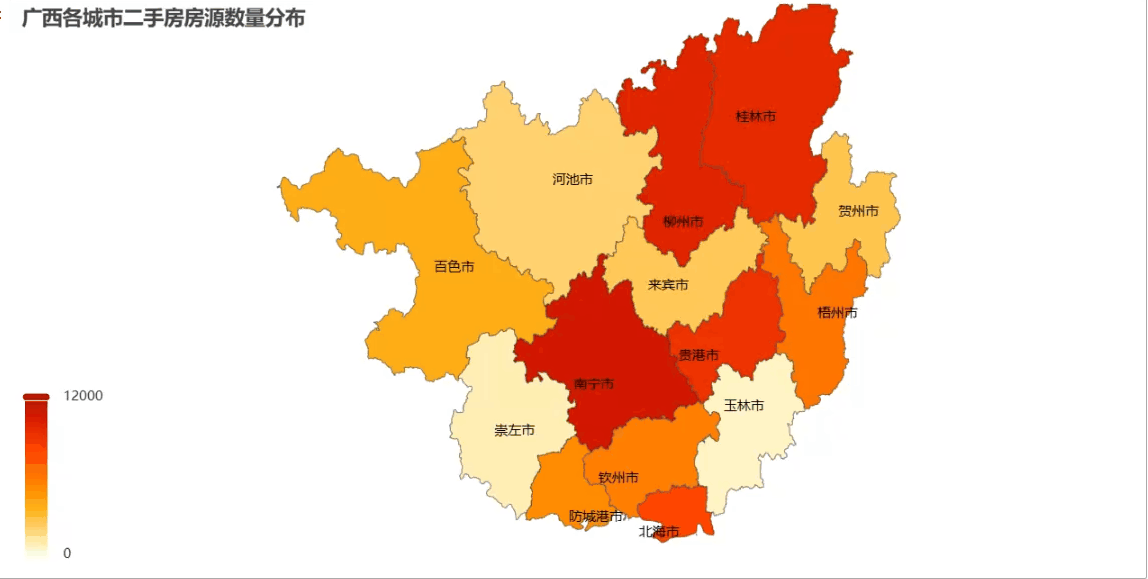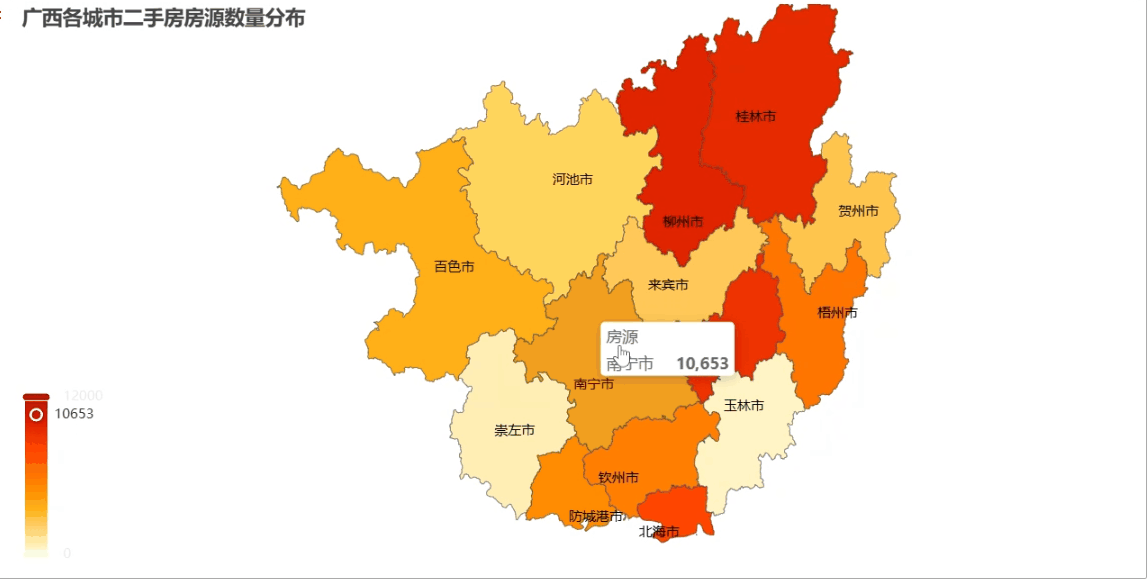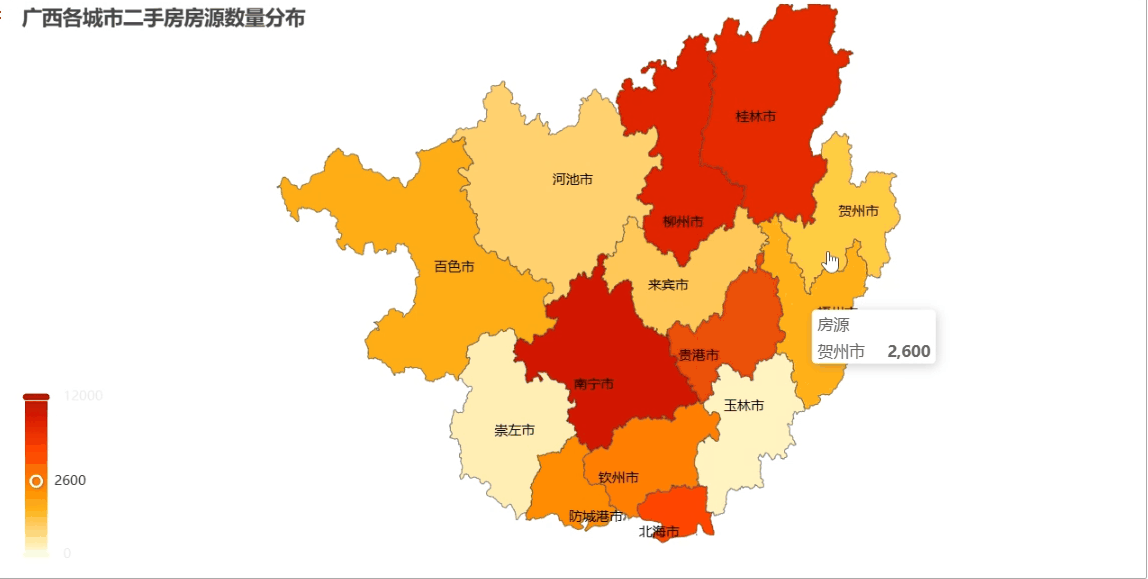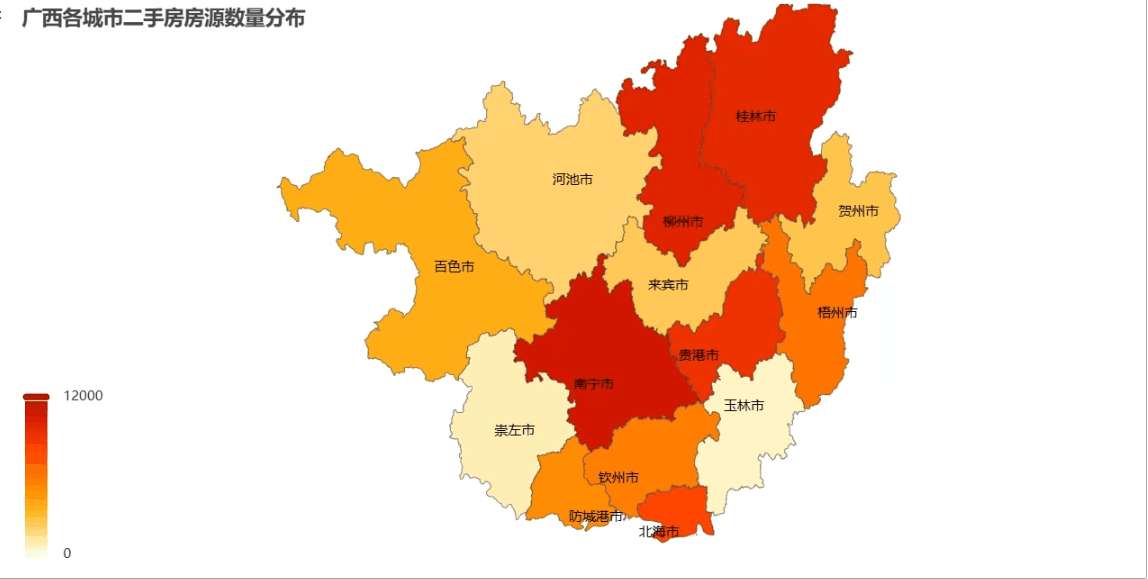
这种地图比柱状图更直观,一眼就能看出哪个区域的房源市场更活跃!
二手房数量分布3D地图
代码展示
-
先定义了广西14个地级市的经纬度坐标(精确到小数点后4位)
-
把房源数量数据转换成 3D 地图需要的格式:
[城市名, [经度, 纬度, 柱高]] -
特别处理:将实际数量除以5(避免柱子太高显得突兀)
from pyecharts import options as optsfrom pyecharts.charts import Map3Dfrom pyecharts.globals import ChartTypefrom pyecharts.commons.utils import JsCode# 广西各市经纬度坐标(主要城市)guangxi_coords = { \"南宁市\": [108.479, 23.1152], \"柳州市\": [109.4282, 24.3269], \"桂林市\": [110.3055, 25.2736], \"梧州市\": [111.3055, 23.4856], \"北海市\": [109.1369, 21.4813], \"防城港市\": [108.3636, 21.6869], \"钦州市\": [108.6388, 21.9817], \"贵港市\": [109.6137, 23.1118], \"玉林市\": [110.1647, 22.6366], \"百色市\": [106.6318, 23.9013], \"贺州市\": [111.5526, 24.4116], \"河池市\": [108.0854, 24.6929], \"来宾市\": [109.2318, 23.7418], \"崇左市\": [107.3579, 22.4151]}# 准备3D地图数据map3d_data = []for city, total in zip(city_counts[\"city\"], city_counts[\"total\"]): city_name = city + \"市\" if city_name in guangxi_coords: # 将数据值缩小一定比例 height = total / 5 # 可根据实际情况调整这个系数 map3d_data.append((city_name, [guangxi_coords[city_name][0], guangxi_coords[city_name][1], height]))# 创建3D地图c = ( Map3D() .add_schema( maptype=\"广西\", itemstyle_opts=opts.ItemStyleOpts( color=\"rgb(5,101,123)\", opacity=1, border_width=0.8, border_color=\"rgb(62,215,213)\", ), map3d_label=opts.Map3DLabelOpts( is_show=False, formatter=JsCode(\"function(data){return data.name + \" \" + data.value[2];}\"), ), emphasis_label_opts=opts.LabelOpts( is_show=False, color=\"#fff\", font_size=10, background_color=\"rgba(0,23,11,0)\", ), light_opts=opts.Map3DLightOpts( main_color=\"#fff\", main_intensity=1.2, main_shadow_quality=\"high\", is_main_shadow=False, main_beta=10, ambient_intensity=0.3, ), ) .add( series_name=\"二手房总数/5\", data_pair=map3d_data, type_=ChartType.BAR3D, bar_size=1, shading=\"lambert\", label_opts=opts.LabelOpts( is_show=False, formatter=JsCode(\"function(data){return data.name + \' \' + data.value[2];}\"), ), ) .set_global_opts(title_opts=opts.TitleOpts(title=\"广西二手房数据分布\")) .render(\"map3d_with_bar3d.html\"))效果展示
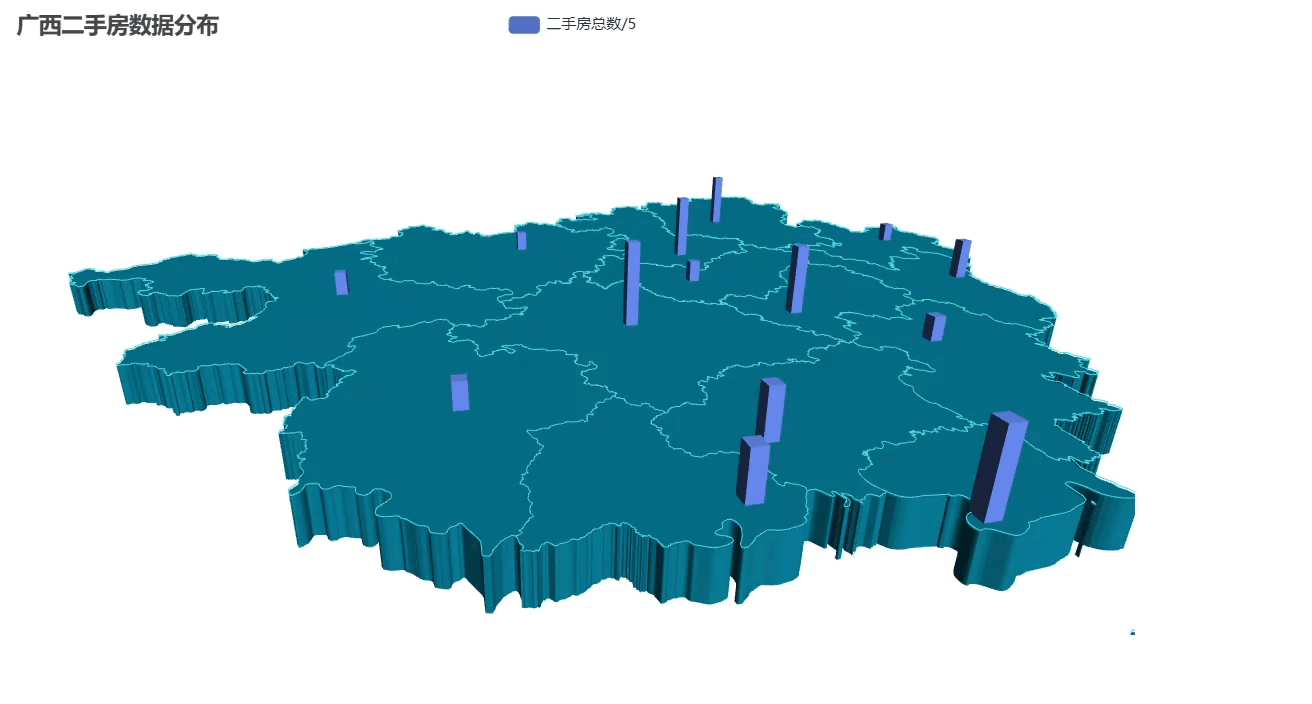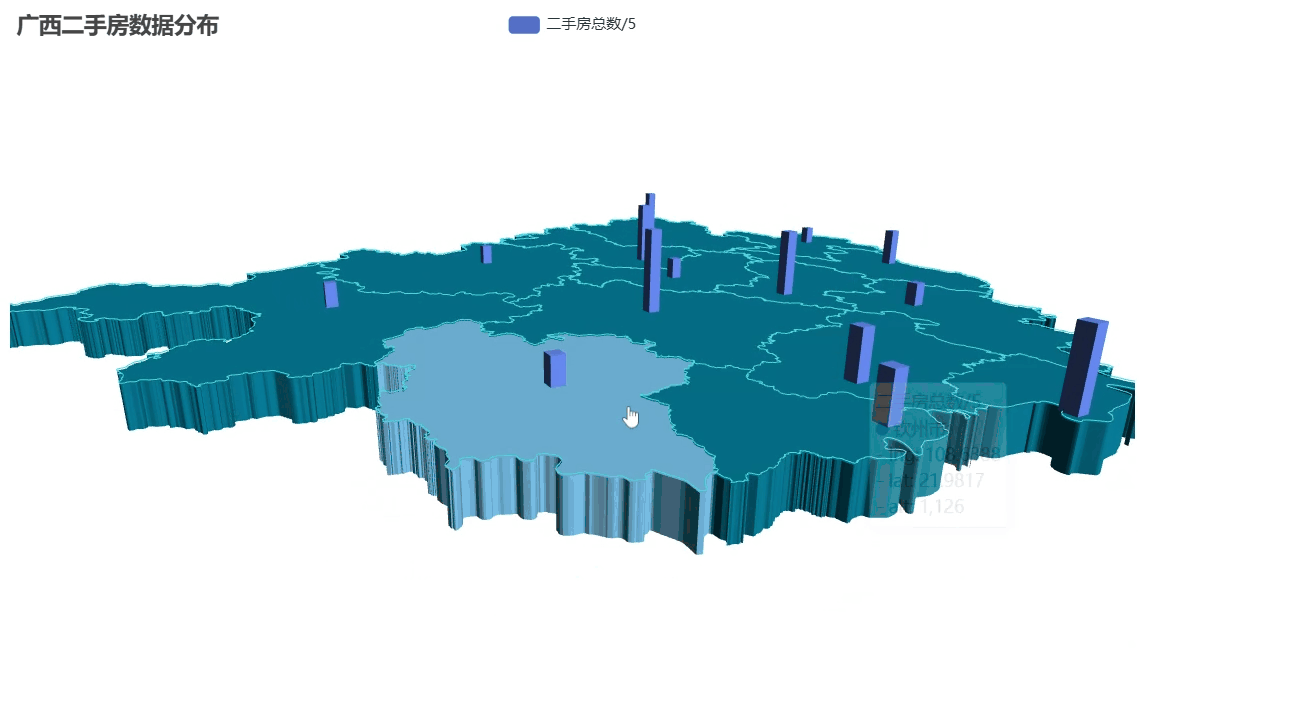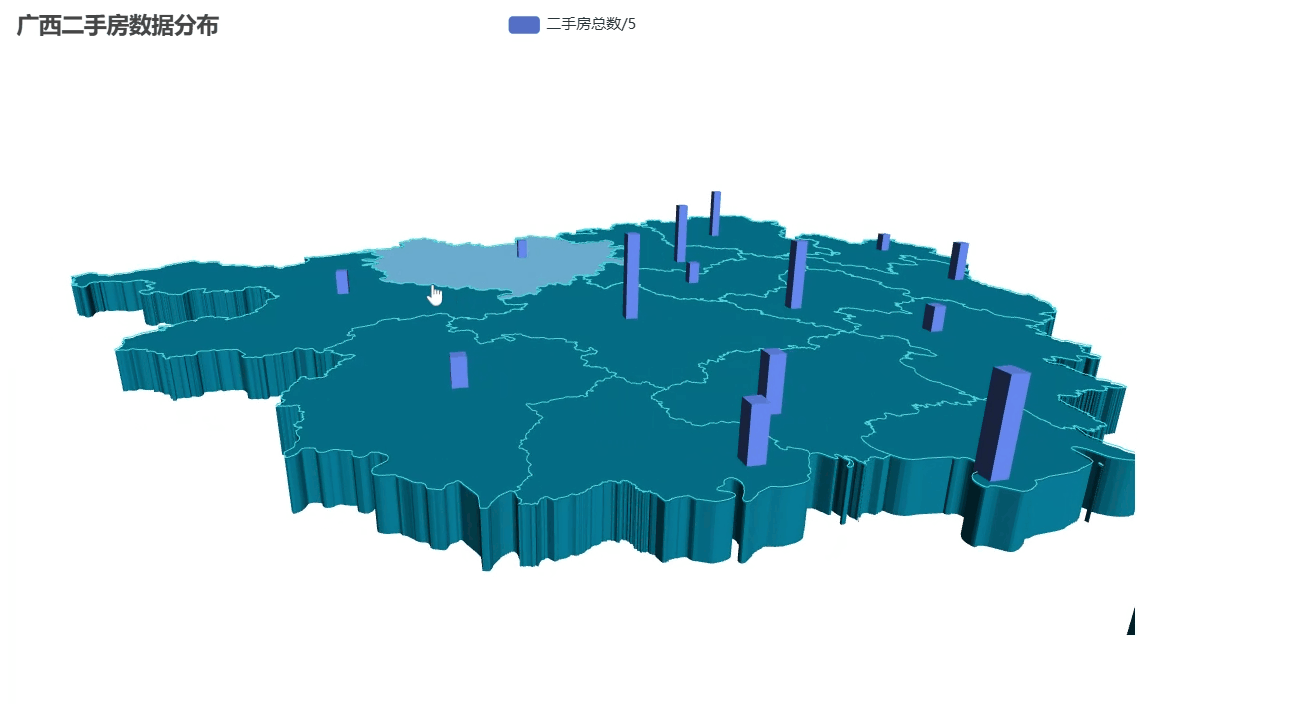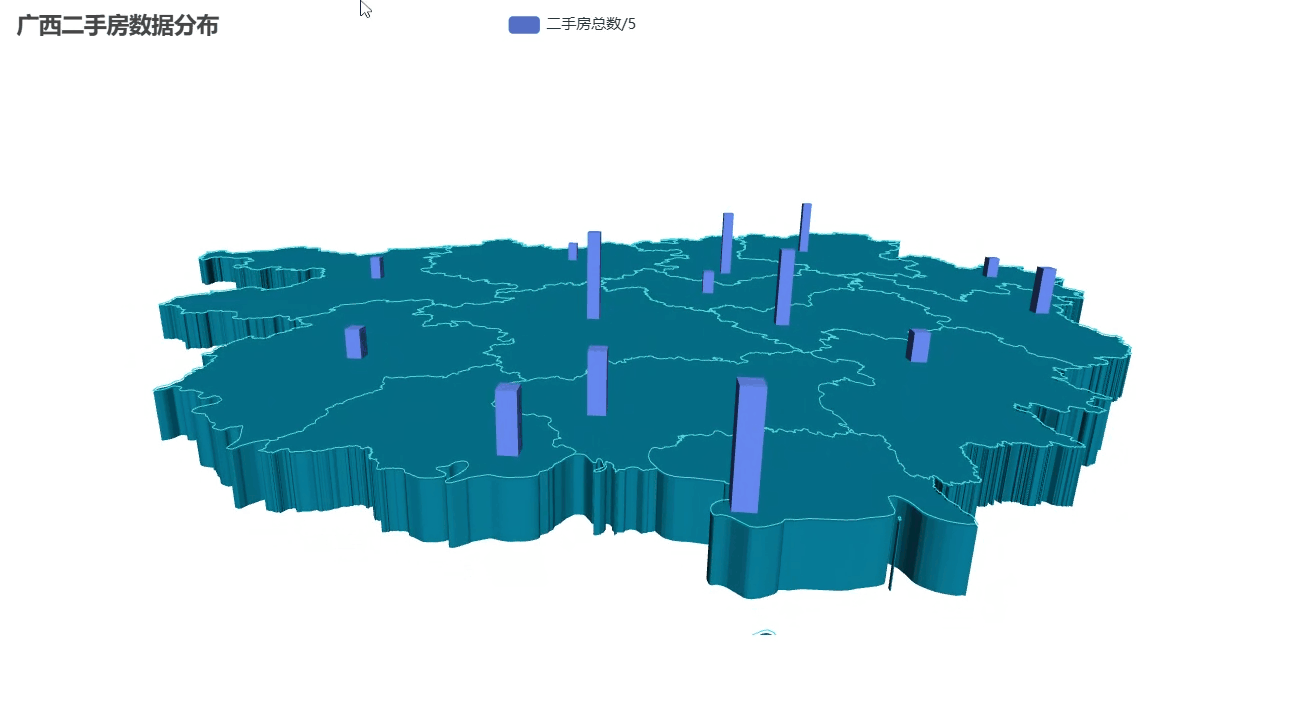
这种可视化特别适合演示汇报,比普通平面地图更有冲击力!更高大上!!如果想调整:
-
修改
/5这个系数可以控制柱子高度 -
调整
range_color可以改变柱子颜色渐变 -
在
light_opts里玩转光影效果
方位-城市房价分布3D柱状图
代码展示
-
先把原始数据按\"方位\"和\"城市\"分组,计算每个组合的平均房价
-
比如:\"南宁+东\"均价12000,\"桂林+北\"均价8500这样
-
把方位和城市名称转换成数字索引(因为3D图表需要数字坐标)
import pyecharts.options as optsfrom pyecharts.charts import Bar3Dimport pandas as pd# 按方位和城市分组计算均价均值grouped = df.groupby([\'方位\', \'城市\'])[\'均价\'].mean().round(2).reset_index()# 准备3D条形图数据# 数据格式: [x轴索引, y轴索引, z轴值]data_for_chart = []directions = sorted(grouped[\'方位\'].unique()) # x轴 - 方位cities = sorted(grouped[\'城市\'].unique()) # y轴 - 城市# 创建映射字典direction_to_idx = {d: i for i, d in enumerate(directions)}city_to_idx = {c: i for i, c in enumerate(cities)}# 创建反向映射字典,用于工具提示idx_to_direction = {i: d for d, i in direction_to_idx.items()}idx_to_city = {i: c for c, i in city_to_idx.items()}for _, row in grouped.iterrows(): x_idx = direction_to_idx[row[\'方位\']] y_idx = city_to_idx[row[\'城市\']] data_for_chart.append([x_idx, y_idx, row[\'均价\']])# 创建3D条形图( Bar3D(init_opts=opts.InitOpts(width=\"1200px\", height=\"800px\")) .add( series_name=\"均价(元/㎡)\", data=data_for_chart, xaxis3d_opts=opts.Axis3DOpts( type_=\"category\", data=sorted(grouped[\'方位\'].unique()), # X轴:方位 name=\"方位\", axislabel_opts=opts.LabelOpts(interval=0, rotate=0) # X轴标签不旋转 ), yaxis3d_opts=opts.Axis3DOpts( type_=\"category\", data=sorted(grouped[\'城市\'].unique()), # Y轴:城市 name=\"城市\", axislabel_opts=opts.LabelOpts( interval=0, # 显示所有标签 rotate=45, # 旋转45度避免重叠 font_size=10 # 调整字体大小 ) ), zaxis3d_opts=opts.Axis3DOpts(type_=\"value\", name=\"均价\"), ) .set_global_opts( title_opts=opts.TitleOpts(title=\"各城市不同方位房价分布3D图\"), visualmap_opts=opts.VisualMapOpts( max_=grouped[\'均价\'].max(), min_=grouped[\'均价\'].min(), range_color=[ \"#313695\", \"#4575b4\", \"#74add1\", \"#abd9e9\", \"#e0f3f8\", \"#ffffbf\", \"#fee090\", \"#fdae61\", \"#f46d43\", \"#d73027\", \"#a50026\" ], ), tooltip_opts=opts.TooltipOpts( ) ) .render(\"方位_城市_房价_3D图.html\"))效果展示
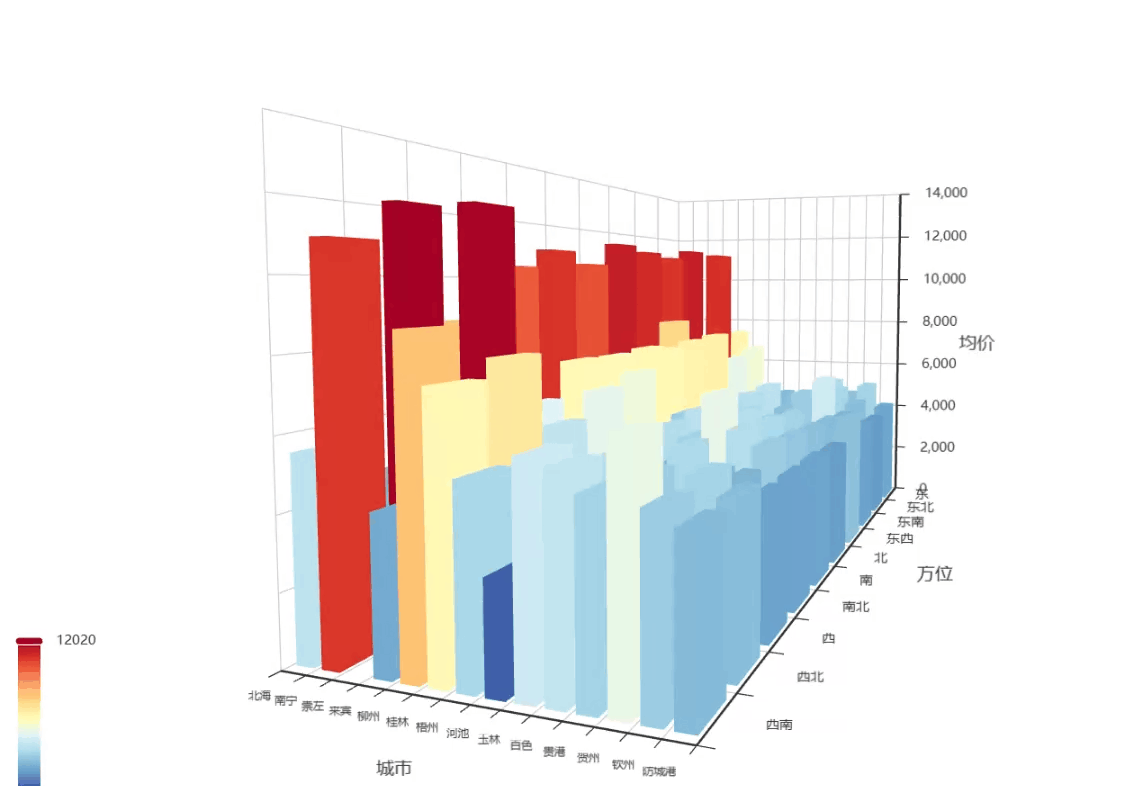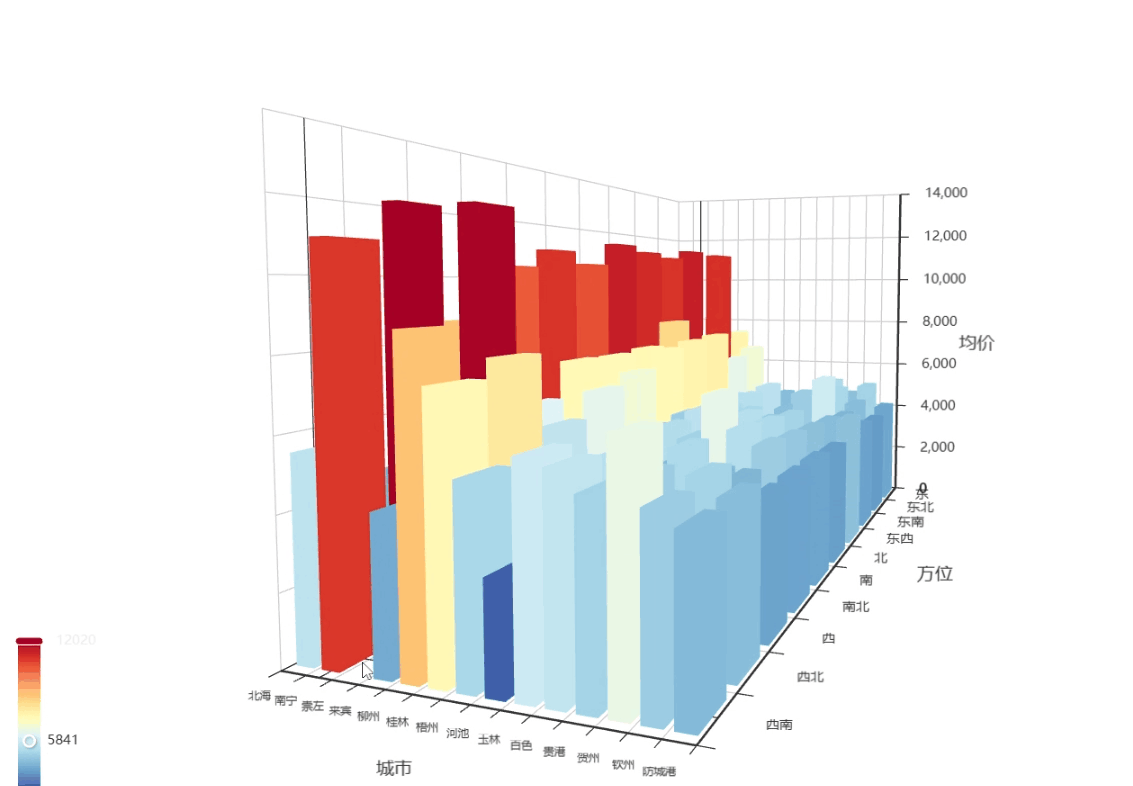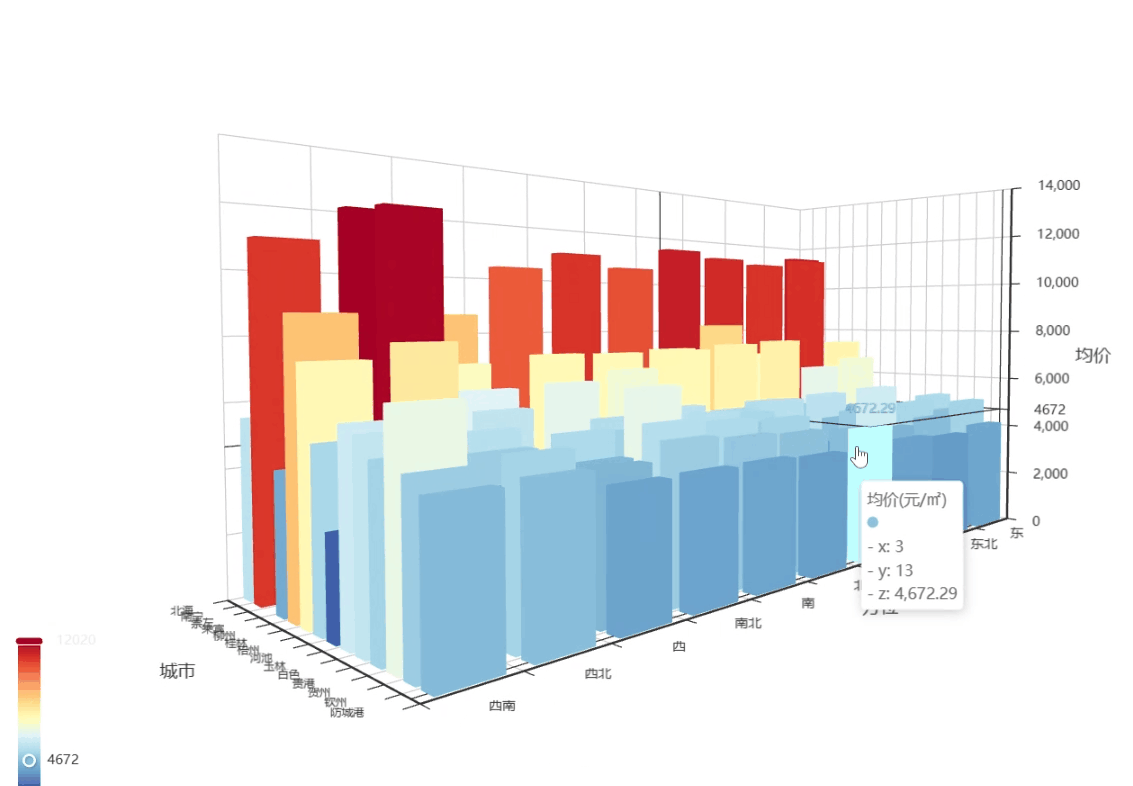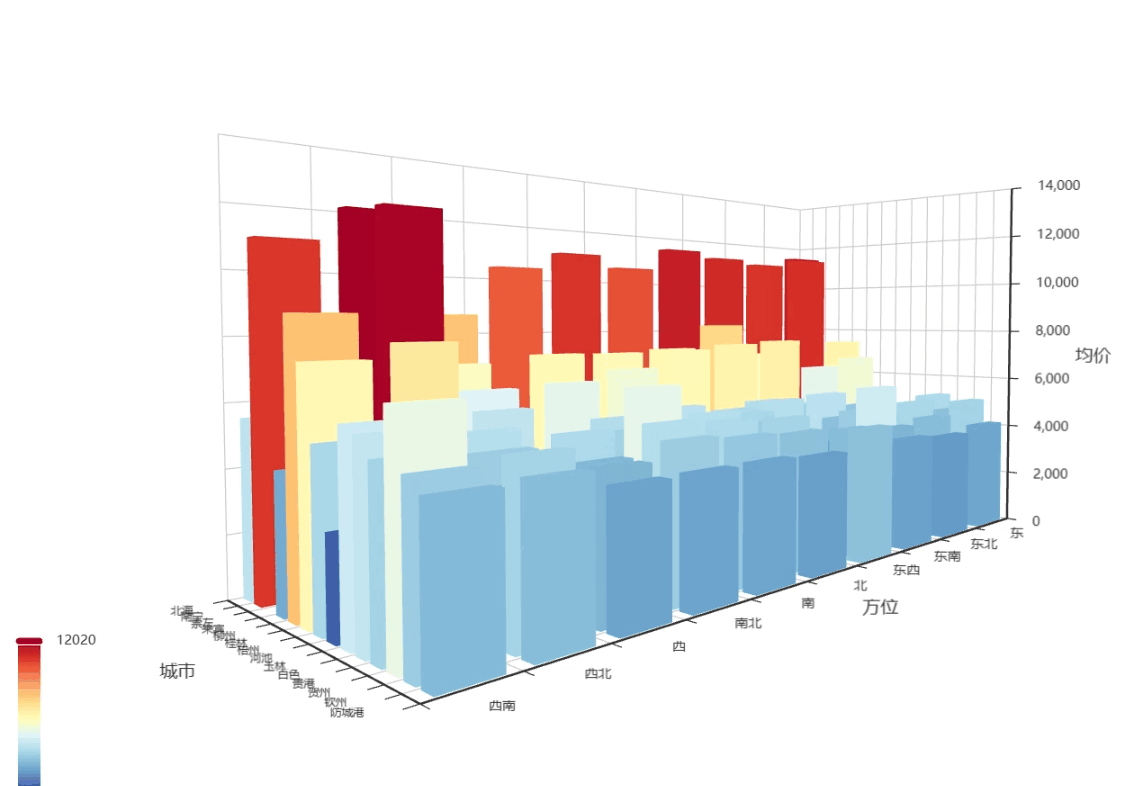
-
X轴(左右):表示方位(东/南/西/北)
-
Y轴(前后):表示城市(南宁/桂林/柳州...)
-
Z轴(上下):柱子高度表示房价
这gif不清晰,我去原图看,就拿南宁和柳州来说,南宁面朝西,相较于其他方位,价格较低,柳州面朝东北和西北的价格比其他方位高了很多,可能要可能要进一步了解所属区域,才能知道原因了,但是在这篇里我不分析单个城市
户型对比雷达图
代码展示
我之前分析就看出户型有100多种(也不知道怎么来的),所以我把第五行以下的都归为其他户型
huxin_counts = df[\'户型\'].value_counts().reset_index()huxin_counts.columns = [\'huxin\', \'total\']# 复制前5行top_huxin = huxin_counts.head(5).copy()# 计算第6行及以后行的总和other_total = huxin_counts.iloc[5:][\'total\'].sum()# 创建\"其他户型\"行other_row = pd.DataFrame({\'huxin\': [\'其他户型\'], \'total\': [other_total]})# 合并前5行和其他行huxin_counts_modified = pd.concat([top_huxin, other_row], ignore_index=True)# 结果现在有6行:前5个户型+其他户型huxin_counts_modified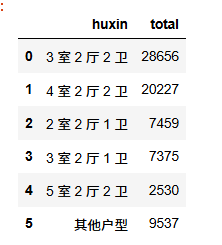
from pyecharts import options as optsfrom pyecharts.charts import Radarimport pandas as pd# 准备雷达图数据huxin_list = huxin_counts_modified[\'huxin\'].tolist()total_values = huxin_counts_modified[\'total\'].tolist()# 雷达图坐标系配置schema = [ {\"name\": huxin, \"max\": max(total_values) +2000 } # 设置最大值(加20避免贴边) for huxin in huxin_list]# 创建雷达图radar = ( Radar(init_opts=opts.InitOpts(width=\"800px\", height=\"500px\")) .add_schema(schema=schema) .add( series_name=\"户型数量\", data=[total_values], color=\"#FF6600\", areastyle_opts=opts.AreaStyleOpts(opacity=0.3), # 填充区域透明度 linestyle_opts=opts.LineStyleOpts(width=2), # 线条宽度 ) .set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 显示数值标签 .set_global_opts( title_opts=opts.TitleOpts(title=\"户型数量对比雷达图\"), legend_opts=opts.LegendOpts(is_show=False) # 单系列无需图例 ))# 生成HTML文件(默认会在当前目录生成 render.html)#radar.render(\"户型雷达图.html\")# 直接在Jupyter Notebook中显示(如果是Jupyter环境)radar.render_notebook()-
huxin_list:存储所有户型名称(比如 [\"一居\",\"二居\",\"三居\"...]) -
total_values:对应户型的房源数量(比如 [500, 1200, 800...])
效果展示
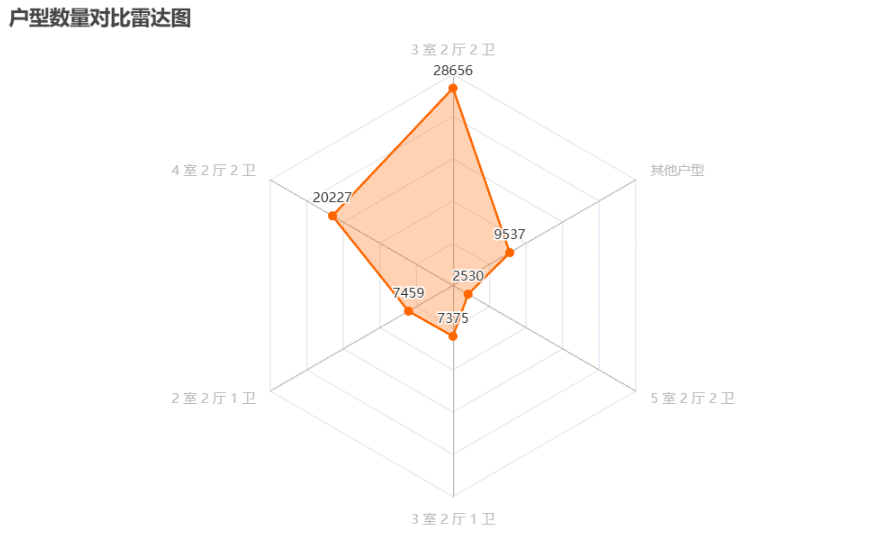
由雷达图可以看出现在主流户型还是3室2厅2卫,4室2厅2卫
户型数量对比饼图
这饼图用的数据和雷达图的一样,就是注意饼图的数据还需要一些处理,还有饼图改一下中心占比就是环形图了
代码展示
data_pie 把户型数据和对应数量打包成列表,格式类似:[(\'一居\', 1500), (\'二居\', 4500), (\'三居\', 3000)...]
from pyecharts import options as optsfrom pyecharts.charts import Pieimport pandas as pddata_pie = list(zip(huxin_counts_modified[\'huxin\'], huxin_counts_modified[\'total\']))# 创建饼图pie = ( Pie(init_opts=opts.InitOpts(width=\"800px\", height=\"600px\")) .add( series_name=\"户型分布\", data_pair=data_pie, radius=[\"0%\", \"70%\"], # 内外半径(控制环形宽度) center=[\"50%\", \"50%\"], # 圆心位置 label_opts=opts.LabelOpts( formatter=\"{b}: {c} ({d}%)\", # 显示格式:户型: 数量 (百分比) font_size=12, color=\"#333\" ), itemstyle_opts=opts.ItemStyleOpts( border_width=1, # 边框宽度 border_color=\"#fff\" # 边框颜色(避免视觉粘连) ) ) .set_global_opts( title_opts=opts.TitleOpts( title=\"户型分布饼图\", subtitle=f\"总计 {huxin_counts_modified[\'total\'].sum()} 套房源\", pos_left=\"center\" ), legend_opts=opts.LegendOpts( orient=\"vertical\", # 图例垂直排列 pos_left=\"left\", item_width=10, # 图例标记宽度 item_height=10 # 图例标记高度 ), tooltip_opts=opts.TooltipOpts( trigger=\"item\", # 悬停触发类型 formatter=\"{a}
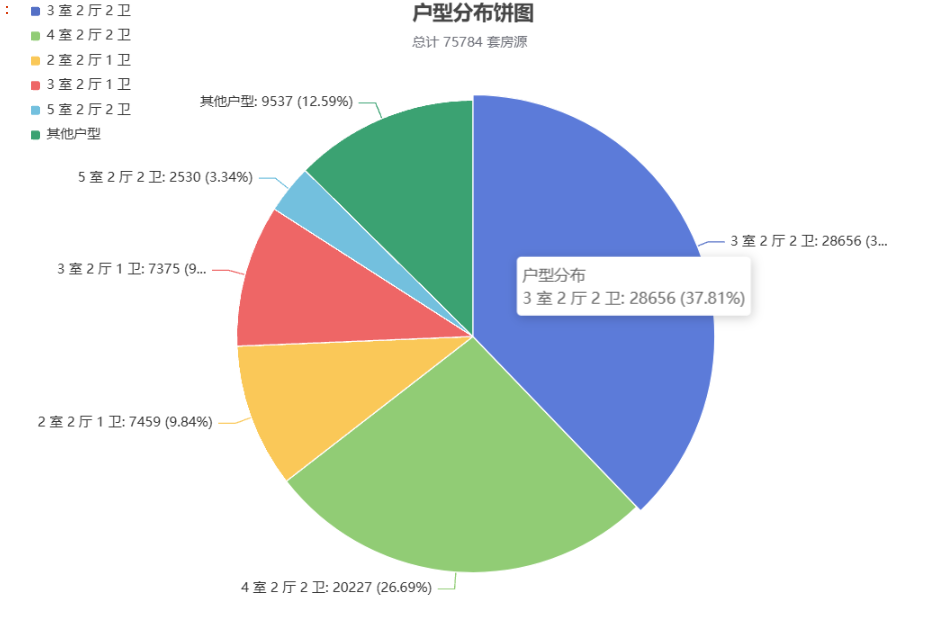
{b}: {c} ({d}%)\" # 悬停提示格式 ) ) .set_series_opts( emphasis_opts=opts.EmphasisOpts( # 移除了 scale 参数 label_opts=opts.LabelOpts(font_size=14) ) ))# 在Jupyter中直接显示pie.render_notebook()效果展示
建造年份-均价折线图
不是很了解房子,采集的数据房子的建造年份竟然还有45年以前的,所以我提取了近十年的来分析一下
代码展示
-
从原始数据中提取了第35-45年的数据(对应
set_time.iloc[34:45]) -
按建造年份分组计算了均价平均值
import pandas as pdfrom pyecharts import options as optsfrom pyecharts.charts import Line# 假设 df 是原始数据(示例数据)# 按时间分组计算均价均值set_time = df.groupby([\'时间\'])[\'均价\'].mean().round(2).reset_index()# 提取35-45行数据(注意Python从0开始索引,实际是34-44)data_subset = set_time.iloc[34:45] # 第35行到45行(含)print(data_subset)# 创建折线图line = ( Line(init_opts=opts.InitOpts(width=\"1000px\", height=\"500px\")) .add_xaxis(data_subset[\'时间\'].tolist()) # X轴:建造年份 .add_yaxis( series_name=\"\", y_axis=data_subset[\'均价\'].tolist(), # Y轴:均价 symbol=\"circle\", # 数据点显示为圆点 symbol_size=8, label_opts=opts.LabelOpts(is_show=True), # 显示数值标签 linestyle_opts=opts.LineStyleOpts(width=3), # 线条宽度 itemstyle_opts=opts.ItemStyleOpts(color=\"#FF6600\") # 线条颜色 ) .set_global_opts( title_opts=opts.TitleOpts( title=\"广西二手房建造年份与均价关系\", subtitle=\"数据范围:第35-45年\", pos_left=\"center\", # 标题居中 pos_top=\"10px\" # 标题距离顶部10像素(防止重叠) ), xaxis_opts=opts.AxisOpts( name=\"建造年份\", axislabel_opts=opts.LabelOpts(rotate=45) # X轴标签旋转45度防重叠 ), yaxis_opts=opts.AxisOpts( name=\"均价(元/㎡)\", splitline_opts=opts.SplitLineOpts(is_show=True) # 显示网格线 ), tooltip_opts=opts.TooltipOpts( trigger=\"axis\", # 悬停触发类型 formatter=\"{b}年
均价: {c}元/㎡\" ) ))# 在Jupyter中显示line.render_notebook()# 保存为HTML文件# line.render(\"广西二手房_年份-均价折线图.html\")-
X轴:建造年份(自动从数据中读取)
-
年份标签旋转45度,防止挤在一起
-
-
Y轴:均价(单位:元/㎡)
-
带灰色网格线,方便查看具体数值
-
效果展示
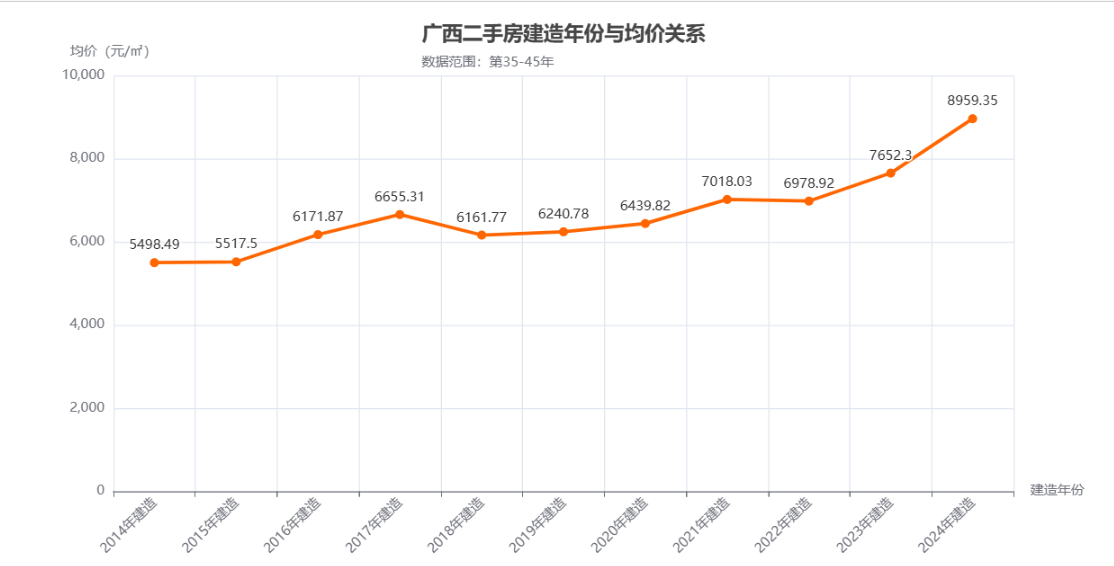
不难看出建造年份离本年越近的房子,价格是越高的
标题关键词词云图
代码展示
-
先用
jieba把标题拆成词语(比如\"朝阳精装三居\" → [\"朝阳\",\"精装\",\"三居\"]) -
过滤掉没意义的词(比如\"的\"、\"是\"这种)
-
统计每个词出现的次数,取前50名高频词
import pandas as pdimport jiebafrom collections import Counterfrom pyecharts import options as optsfrom pyecharts.charts import WordCloud# 中文分词 + 统计词频def get_top_keywords(texts, top_n=50): words = [] for text in texts: words.extend(jieba.lcut(text)) # 过滤单字和无意义词(可选) stopwords = [\'的\', \'是\', \'和\', \'在\', \'有\'] # 自定义停用词 words_filtered = [ word for word in words if len(word) > 1 and word not in stopwords ] # 返回前top_n个高频词 return Counter(words_filtered).most_common(top_n)# 获取前50个高频词word_freq = get_top_keywords(df[\'标题\'], top_n=50)print(word_freq) # 打印前10个示例输出# 创建词云wordcloud = ( WordCloud() .add( series_name=\"标题关键词\", data_pair=word_freq, word_size_range=[12, 60], # 词语字体大小范围 shape=\"circle\", # 词云形状(可选:circle, cardioid, diamond, triangle等) mask_image=None, # 自定义形状图片路径(如需特定形状) word_gap=10, # 词语间距 rotate_step=45, # 旋转角度间隔 tooltip_opts=opts.TooltipOpts( formatter=\"{b}: {c}\" # 悬停显示格式:关键词: 频率 ) ) .set_global_opts( title_opts=opts.TitleOpts(title=\"标题关键词词云\"), tooltip_opts=opts.TooltipOpts(is_show=True) ))# 在Jupyter中显示wordcloud.render_notebook()# 保存为HTML文件# wordcloud.render(\"标题关键词词云.html\")效果展示

由词云可以看出精装,电梯,南北,急售,楼层等都是卖点
总结
以上做的分析不是为了卖房,而且都是一些简单的分析,主要是为了之后的可视化大屏和系统,做一点基本图表,想要更多图表可以去看pyecharts的官网,加纳

